Physicians spend an average of two hours on documentation for every one hour of direct patient care. The downstream consequences are staggering: burnout rates above 50%, reduced throughput, increased medical errors from fatigue, and an estimated $150 billion in annual waste from administrative overhead across the US healthcare system. Ambient clinical documentation — the technology that listens to the doctor-patient encounter and automatically generates structured clinical notes — has emerged as one of the most capital-intensive categories in healthtech. Microsoft acquired Nuance for $19.7 billion, largely on the strength of DAX (Dragon Ambient eXperience). Abridge raised $250 million in 2024. Nabla, Suki, DeepScribe, and a dozen others have collectively raised over $1 billion. The market signal is clear: whoever solves documentation wins the physician's workflow.
But the engineering behind ambient clinical documentation is orders of magnitude harder than "put a microphone in the room and call an LLM." It requires a real-time, multi-stage pipeline that spans audio engineering, speech recognition, clinical NLP, large language models, medical ontology mapping, and deep EHR integration. This post breaks down the full architecture — every stage, every latency target, every failure mode — for engineering teams building or evaluating these systems.
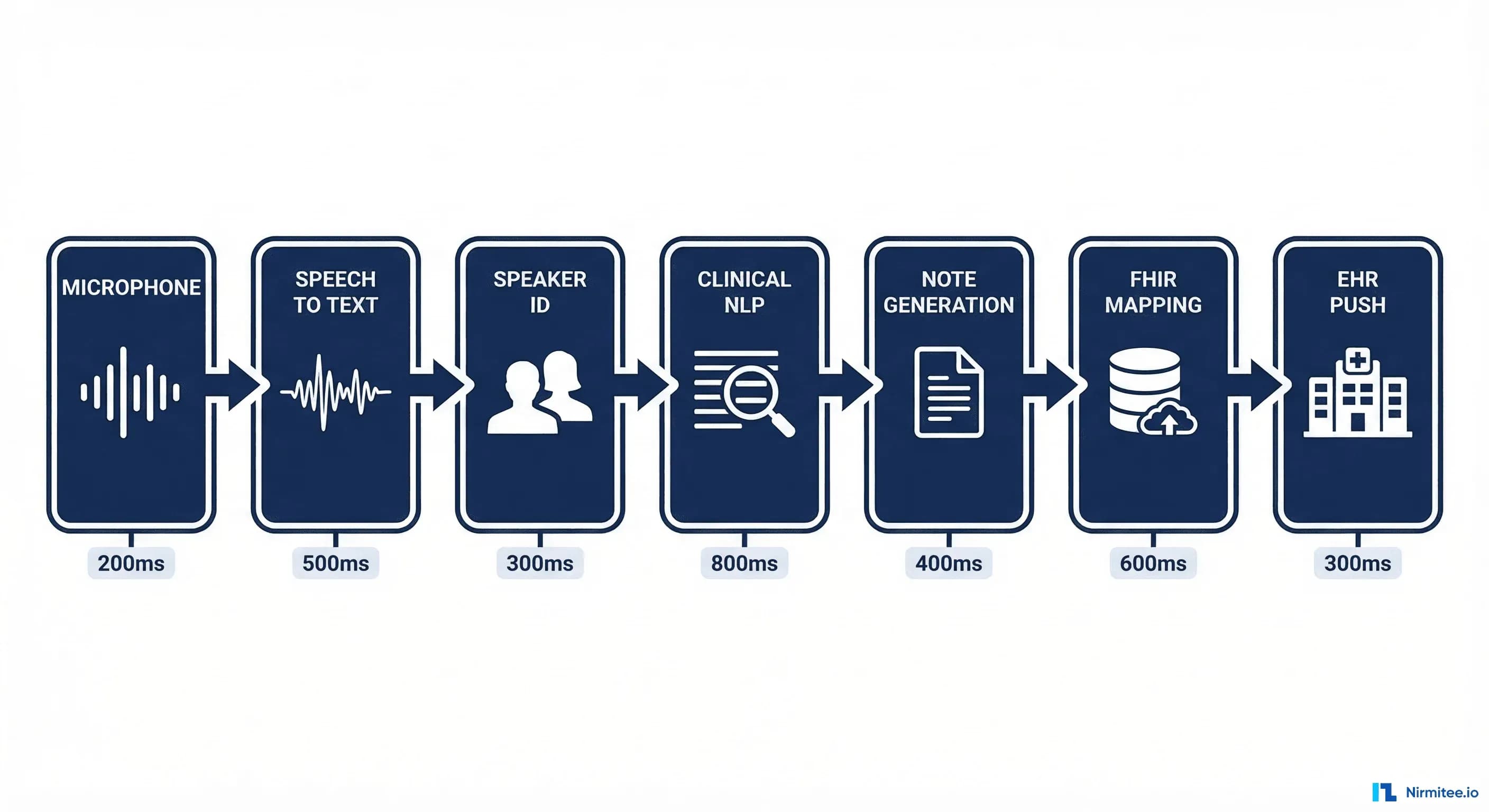
The 7-Stage Pipeline
An ambient clinical documentation system is fundamentally a data pipeline with seven distinct stages, each with its own technical challenges, latency constraints, and failure modes:
- Audio Capture — Acquire the raw audio stream from the clinical encounter
- Speech-to-Text (ASR) — Convert audio to transcript with medical vocabulary accuracy
- Speaker Diarization — Identify who said what (doctor, patient, nurse, family member)
- Clinical NLP — Extract structured clinical data from unstructured conversation
- Note Generation — Generate a complete clinical note in SOAP or other format
- FHIR Resource Mapping — Transform structured data into interoperable FHIR resources
- EHR Integration — Push the note and structured data into the electronic health record
End-to-end latency target: the clinician should see a draft note within 60 seconds of the encounter ending. For a 15-minute primary care visit, the pipeline processes roughly 4,500 words of conversation and produces a 400–800 word clinical note with 15–30 structured data elements. Here is how each stage works.
Stage 1: Audio Capture
The audio capture layer is deceptively complex. Unlike consumer voice applications (Siri, Alexa), clinical environments present unique acoustic challenges: multiple simultaneous speakers, background noise from medical equipment (IV pumps, monitors, ventilators), varying room acoustics across exam rooms, and conversations that can last anywhere from 5 minutes (urgent care) to 60 minutes (psychiatry intake).
Architecture Choices
- Browser-based: WebRTC with
getUserMedia()for web applications. Advantages: zero install, works on any device. Disadvantages: browser tab must stay open, microphone quality varies wildly across laptops. - Native mobile SDK: iOS AVAudioEngine / Android AudioRecord for dedicated apps. Advantages: background recording, access to hardware-level noise cancellation, consistent audio quality. Disadvantages: app install friction, platform-specific code.
- Dedicated hardware: Purpose-built microphone arrays (what Abridge uses with their ambient device). Advantages: far-field pickup, beamforming for speaker separation. Disadvantages: hardware logistics, per-room cost ($200–$500/device).
Consent and Compliance
Recording clinical conversations triggers legal requirements that consumer voice apps do not face. Thirteen US states require two-party consent for recording. HIPAA requires that audio recordings be treated as Protected Health Information (PHI). The system must implement explicit consent capture — typically a verbal acknowledgment recorded at the start of the encounter — and maintain an auditable consent log tied to each recording session. Audio must be encrypted in transit (TLS 1.3) and at rest (AES-256), with configurable retention policies (many health systems require deletion within 24–72 hours post-note-generation).
Latency target: <100ms from sound wave to digitized audio chunk available for streaming to ASR. This is achievable with standard WebRTC or native audio APIs using 20ms audio frames.
Stage 2: Speech-to-Text (ASR)
Medical speech recognition is not general-purpose ASR. A general model hears "the patient takes met forming five hundred milligrams bid" and transcribes exactly that. A medical ASR model must output "metformin 500mg BID" — the correct drug name, dosage with units, and frequency abbreviation. The word error rate (WER) gap between general and medical ASR is substantial: general models achieve ~5–8% WER on medical speech, while specialized models push below 4%.
Model Options
- OpenAI Whisper (fine-tuned): Open-source base model, fine-tunable on clinical speech corpora. Whisper Large V3 achieves ~4.2% WER on medical dictation after fine-tuning on 10,000+ hours of clinical audio. Cost: self-hosted GPU inference (~$0.006/minute on A100).
- Nuance Dragon Medical: The incumbent. 25+ years of medical vocabulary tuning. WER as low as 2.5% for structured dictation. Licensing: per-provider per-month, typically $100–$200/provider/month.
- Google Cloud Medical ASR: chirp_2 model with medical adaptation. Streaming support with interim results. WER ~3.8% on clinical speech. Pricing: $0.024/minute (streaming).
- AWS Transcribe Medical: Purpose-built medical model. Supports streaming and batch. WER ~4.5% on general clinical. Pricing: $0.0194/minute.
Streaming vs Batch
Streaming ASR provides real-time transcript updates during the encounter, enabling live display and early-stage NLP processing. Batch ASR processes the complete audio after the encounter ends, typically achieving 10–15% better accuracy due to full-context language model rescoring. The optimal architecture uses both: streaming for real-time display and early feature extraction, batch for the final high-accuracy transcript used in note generation.
// Streaming ASR architecture (simplified)
const stream = mediaRecorder.start(250); // 250ms chunks
stream.on('data', async (chunk) => {
const interim = await asrClient.streamingRecognize(chunk);
updateLiveTranscript(interim);
extractEarlyFeatures(interim); // chief complaint detection
});
encounter.on('end', async () => {
const finalTranscript = await asrClient.batchRecognize(fullAudio);
generateNote(finalTranscript); // uses higher-accuracy batch result
});Latency target: Streaming interim results within 300ms of speech. Final batch transcript within 15 seconds of encounter end for a 15-minute visit.
Stage 3: Speaker Diarization
Diarization — determining who said what — is critical because the clinical note structure depends entirely on speaker identity. The patient's own words populate the Subjective section ("I've been having chest pain for three days"). The doctor's examination findings populate the Objective section. Misattributing a symptom from patient to doctor (or vice versa) produces a clinically dangerous note.
Technical Approaches
- Speaker embedding models: Extract speaker embeddings (d-vectors or x-vectors) from short audio segments and cluster them. Models like pyannote.audio achieve ~8% Diarization Error Rate (DER) on general conversation. Clinical settings are harder due to short turns and overlapping speech — expect 10–15% DER without fine-tuning.
- Channel separation: If using a multi-microphone setup, spatial audio processing can separate speakers physically. Beamforming arrays reduce DER to <5% in controlled room configurations.
- Turn-taking detection: Clinical conversations have predictable turn-taking patterns: the doctor asks questions, the patient responds. Combining acoustic diarization with conversational pattern models (who is likely speaking given the conversation flow) improves accuracy by 3–5 percentage points.
- Enrollment-based: Record a 10-second sample of each speaker at the start of the encounter. This anchors the embedding clusters and reduces DER to 3–6% even in challenging acoustic environments.
For production systems, the enrollment-based approach combined with turn-taking detection delivers the best results. The 10-second enrollment adds minimal friction ("Doctor, please say your name and today's date") and dramatically improves downstream note accuracy.
Latency target: Diarization labels applied within 2 seconds of transcript segment availability. Can run in parallel with ASR in streaming mode.
Stage 4: Clinical NLP
This is the hardest stage in the pipeline. The system must extract structured clinical information from a free-flowing conversation that includes small talk, interruptions, tangential discussions, and implicit medical reasoning that the physician never states aloud.
What Gets Extracted
- Chief Complaint (CC): The primary reason for the visit. Usually stated in the first 60 seconds. "I've been having this pain in my lower back for about a week."
- History of Present Illness (HPI): Onset, location, duration, character, aggravating/alleviating factors, radiation, timing, severity (OLDCARTS mnemonic).
- Review of Systems (ROS): Pertinent positives and negatives across organ systems. "No chest pain, no shortness of breath" is as clinically important as positive findings.
- Physical Exam: Doctor's examination findings, often stated as running commentary. "Lungs are clear bilaterally, heart regular rate and rhythm, no murmurs."
- Assessment: The diagnostic reasoning — what the doctor thinks is going on.
- Plan: Orders, prescriptions, referrals, follow-up instructions.
Ontology Mapping
Raw extracted text must be mapped to standard clinical terminologies:
- ICD-10-CM for diagnoses: "low back pain" → M54.5 (Low back pain)
- SNOMED CT for clinical findings: "lungs clear bilaterally" → 48348007 (Clear breath sounds)
- CPT for procedures: "we'll do an X-ray of the lumbar spine" → 72100
- RxNorm for medications: "let's start you on ibuprofen 600 three times a day" → RxCUI 310965 (ibuprofen 600 MG Oral Tablet)
- LOINC for lab orders: "let's check a CBC and a BMP" → 58410-2 (CBC panel), 51990-0 (Basic metabolic panel)
Production systems typically use a combination of rule-based extractors for high-precision tasks (medication parsing, vital sign extraction) and transformer-based models for complex reasoning (differential diagnosis extraction, implicit finding detection). The hybrid approach achieves F1 scores of 0.85–0.92 on structured extraction benchmarks, compared to 0.78–0.85 for pure LLM approaches and 0.70–0.80 for pure rule-based systems.
Latency target: Complete clinical extraction within 10 seconds of final transcript availability.
Stage 5: Note Generation
The LLM generates a structured clinical note — typically in SOAP format (Subjective, Objective, Assessment, Plan) — from the extracted clinical data and the diarized transcript. This is where the system becomes most visible to the clinician, and where trust is won or lost.
Critical Requirements
- Source citations: Every statement in the generated note must link back to a specific segment of the transcript. "Patient reports lower back pain for 7 days" → [Transcript 02:14–02:31]. This allows the clinician to verify any claim with one click.
- Confidence indicators: Statements derived from explicit patient/doctor speech get high confidence. Inferred findings ("patient appears to be in mild distress" based on speech patterns) must be flagged as low confidence.
- AI-generated markers: The note must contain metadata indicating it was AI-generated, per AMA guidelines and emerging state regulations. Typical implementation: a structured header field and per-section provenance tags.
- Completeness without hallucination: The note must include everything clinically relevant from the encounter but must never fabricate findings. This is the fundamental tension — LLMs are optimized for fluent completion, but in clinical documentation, a confident hallucination can directly harm a patient.
Clinician Review Workflow
No production ambient documentation system auto-finalizes notes. The workflow is always: AI generates draft → clinician reviews in 30–90 seconds → clinician edits/approves → note is finalized. The review interface must support inline editing, section-level accept/reject, and a "regenerate section" option. Tracking edit rates by section provides a continuous quality signal — if clinicians consistently rewrite the Assessment section, the model needs improvement in diagnostic reasoning.
// Note generation prompt structure (simplified)
{
"system": "You are a clinical documentation assistant. Generate a SOAP note from the provided encounter data. Rules: (1) Only include findings explicitly supported by the transcript. (2) Cite transcript timestamps for every clinical statement. (3) Flag any inferred findings with [INFERRED]. (4) Never fabricate examination findings.",
"user": {
"transcript": "[diarized transcript with timestamps]",
"extracted_data": {
"chief_complaint": "...",
"hpi": { ... },
"ros": { ... },
"exam": { ... },
"assessment": ["..."],
"plan": ["..."]
},
"note_template": "SOAP",
"provider_preferences": { "verbosity": "concise", "style": "bullet" }
}
}Latency target: Draft note generated within 8 seconds using a fast inference model (GPT-4o, Claude 3.5 Sonnet, or fine-tuned Llama 3 70B). Streaming the note to the review UI as it generates reduces perceived latency to <2 seconds.
Stage 6: FHIR Resource Mapping
A clinical note sitting in a text field is useful but not interoperable. The structured data extracted in Stage 4 must be transformed into FHIR (Fast Healthcare Interoperability Resources) resources that conform to standard profiles. This enables downstream systems — billing, quality reporting, population health, clinical decision support — to consume the data programmatically.
Resource Mapping
A single 15-minute primary care encounter typically generates 8–15 FHIR resources:
- Encounter: The visit itself — date, type (office visit, telehealth), participants, reason for visit.
- Condition: Each diagnosis, linked to ICD-10-CM codes. A visit for "low back pain with sciatica" generates two Condition resources (M54.5, M54.3).
- Observation: Vital signs (blood pressure, heart rate, temperature), physical exam findings, social history observations. Each gets its own LOINC code.
- MedicationRequest: Prescriptions with RxNorm coding, dosage, frequency, duration. "Ibuprofen 600mg TID for 14 days" becomes a fully structured MedicationRequest.
- Procedure: Any procedures performed or ordered, with CPT codes.
- ServiceRequest: Lab orders, imaging orders, referrals.
- DocumentReference: The note itself as a document, with the full text attached and metadata linking to all related resources.
- AllergyIntolerance: If allergies are mentioned or confirmed during the encounter.
Profile Conformance
FHIR resources must conform to implementation guide profiles relevant to the deployment context:
- US Core (v6.1.0): Mandatory for ONC-certified systems in the United States. Requires specific must-support elements, terminology bindings, and search parameters.
- ABDM FHIR profiles: Required for India's Ayushman Bharat Digital Mission. Different profile constraints, different terminology requirements (ICD-10 used, but SNOMED CT adoption is earlier-stage).
- IPS (International Patient Summary): For cross-border interoperability in the EU and beyond.
// FHIR Condition resource from ambient documentation
{
"resourceType": "Condition",
"meta": {
"profile": ["http://hl7.org/fhir/us/core/StructureDefinition/us-core-condition-problems-health-concerns"]
},
"clinicalStatus": {
"coding": [{ "system": "http://terminology.hl7.org/CodeSystem/condition-clinical", "code": "active" }]
},
"category": [{
"coding": [{ "system": "http://terminology.hl7.org/CodeSystem/condition-category", "code": "encounter-diagnosis" }]
}],
"code": {
"coding": [
{ "system": "http://hl7.org/fhir/sid/icd-10-cm", "code": "M54.5", "display": "Low back pain" },
{ "system": "http://snomed.info/sct", "code": "279039007", "display": "Low back pain" }
]
},
"subject": { "reference": "Patient/example" },
"encounter": { "reference": "Encounter/ambient-12345" },
"recordedDate": "2026-03-13",
"note": [{ "text": "AI-generated from ambient encounter documentation. Source: transcript 02:14-02:31." }]
}Latency target: FHIR resource bundle generated within 3 seconds. Validation against profiles within 1 second.
Stage 7: EHR Integration
The final mile — getting the note and structured data into the EHR where the clinician works. This is where elegant architectures meet the messy reality of healthcare IT.
SMART on FHIR Write-Back
The ideal integration path uses SMART on FHIR — the clinician launches the ambient documentation app from within the EHR, the app receives a FHIR access token scoped to the current patient and encounter, and writes resources back via the FHIR API. In practice, EHR FHIR write support varies dramatically:
- Epic: Supports FHIR R4 writes for a subset of resources (DocumentReference, Condition, Observation). Requires App Orchard approval. Custom resource types require proprietary APIs. Turnaround for app approval: 3–6 months.
- Oracle Health (Cerner): Broader FHIR write support including MedicationRequest. Millennium API supplements gaps. Code Console marketplace review: 2–4 months.
- MEDITECH Expanse: FHIR write support is newer and more limited. Many workflows still require HL7v2 ADT/ORU messages.
- Allscripts/Veradigm: FHIR support varies by product line. TouchWorks has better API coverage than Professional EHR.
Fallback Strategies
When FHIR write is not available or not sufficient, production systems implement fallback integration patterns:
- CDA document generation: Generate a C-CDA (Consolidated Clinical Document Architecture) document and push via standard document exchange. Supported by virtually every certified EHR.
- HL7v2 ORU message: Package the note as an ORU (Observation Result) message for HL7v2 interfaces. Legacy but ubiquitous — 95% of US hospitals have HL7v2 interfaces.
- Direct clipboard integration: As a last resort, format the note as rich text and push to the system clipboard for paste into the EHR's note editor. Not ideal, but it works everywhere and clinicians are used to it.
Latency target: FHIR write-back within 5 seconds. CDA/HL7v2 fallback within 10 seconds. Clipboard push is instantaneous.
Why This Is Hard (And Where Startups Fail)
Having built and evaluated these systems, the failure modes cluster into five categories:
1. Medical Terminology Accuracy
General-purpose LLMs confuse similar drug names (metoprolol vs metformin), hallucinate dosages, and sometimes invent plausible-sounding but nonexistent diagnoses. The tolerance for error in clinical documentation is effectively zero — a wrong medication in a note can lead to a wrong prescription, an adverse drug event, and a malpractice claim. Fine-tuning on clinical text helps, but the long tail of rare conditions, off-label drug uses, and specialty-specific terminology requires ongoing human-in-the-loop correction and model updates.
2. Multi-Language and Accent Handling
In the US, 25 million patients have limited English proficiency. In India, a single hospital may serve patients speaking Hindi, Marathi, Tamil, and English — sometimes within the same sentence (code-switching). ASR models trained primarily on standard American English degrade significantly on accented speech and code-switched conversations. WER can jump from 4% to 15–20% for non-native English speakers. Building robust multi-language support requires dedicated training data for each language pair and accent profile — a data acquisition problem as much as a modeling problem.
3. Real-Time vs Quality Tradeoff
Clinicians want the note immediately after the encounter. But accuracy improves with more compute time — batch ASR is better than streaming, multi-pass NLP extraction is better than single-pass, and larger LLMs generate better notes than smaller ones. The production solution is a two-phase approach: generate a fast draft (streaming ASR + small model) for immediate review, then silently upgrade to a high-accuracy version (batch ASR + large model) within 2–3 minutes. If the clinician has not yet reviewed the draft, they see the upgraded version. If they have already started editing, merge the improvements selectively.
4. Clinician Trust Gap
The biggest adoption barrier is not technical — it is trust. Physicians are legally responsible for every word in the note. An AI-generated note that the physician signs becomes, legally, the physician's note. Early ambient documentation products suffered from the "black box" problem: the note appeared fully formed with no way to trace claims back to what was actually said. The solution is radical transparency: source citations for every statement, explicit confidence levels, clear AI-generated markers, and easy access to the original transcript. Systems that achieve >90% first-draft acceptance rates (clinician approves with minimal edits) build trust rapidly; those below 70% get abandoned within weeks.
5. Regulatory Classification
When does an AI documentation tool cross the line from "administrative support" (not regulated) to "clinical decision support" (FDA-regulated)? If the system extracts diagnoses and suggests ICD-10 codes, is it making a diagnostic recommendation? The current FDA guidance (2023) suggests that documentation tools that present information for clinician review without making independent clinical recommendations are not classified as medical devices. But the line is blurry, and regulatory frameworks in the EU (AI Act), India (CDSCO guidelines), and other jurisdictions add complexity. Most startups operate under the "administrative tool" classification and are careful to never frame their outputs as clinical recommendations — a distinction that is technically meaningful but practically subtle.
The Bottom Line
Ambient clinical documentation is a systems engineering problem disguised as an AI problem. The LLM that generates the note is perhaps 20% of the total engineering effort. The other 80% is audio engineering, ASR tuning, speaker diarization, clinical NLP, terminology mapping, FHIR conformance, EHR integration, consent management, and the clinician review workflow that makes the whole system trustworthy. The companies that win this market will not be the ones with the best model — they will be the ones that nail every stage of the pipeline and earn clinician trust through relentless accuracy, transparency, and workflow integration.
For engineering teams evaluating or building ambient documentation: start from the EHR integration backward. Understand what your target EHR systems actually accept, what profile conformance they require, and what the clinician review workflow needs to look like. Then design your pipeline to serve those constraints. The most elegant NLP pipeline in the world is worthless if you cannot get the output into Epic.
Looking to build a robust healthcare platform? Our Healthcare Software Product Development team turns complex requirements into production-ready systems. We also offer specialized Agentic AI for Healthcare services. Talk to our team to get started.