Clinical documentation eats 2 hours of every doctor's day. AI scribes — tools that listen to patient consultations and automatically generate clinical notes — are the most tangible, most immediately valuable application of AI in healthcare. And here is the thing: the demo version is shockingly easy to build.
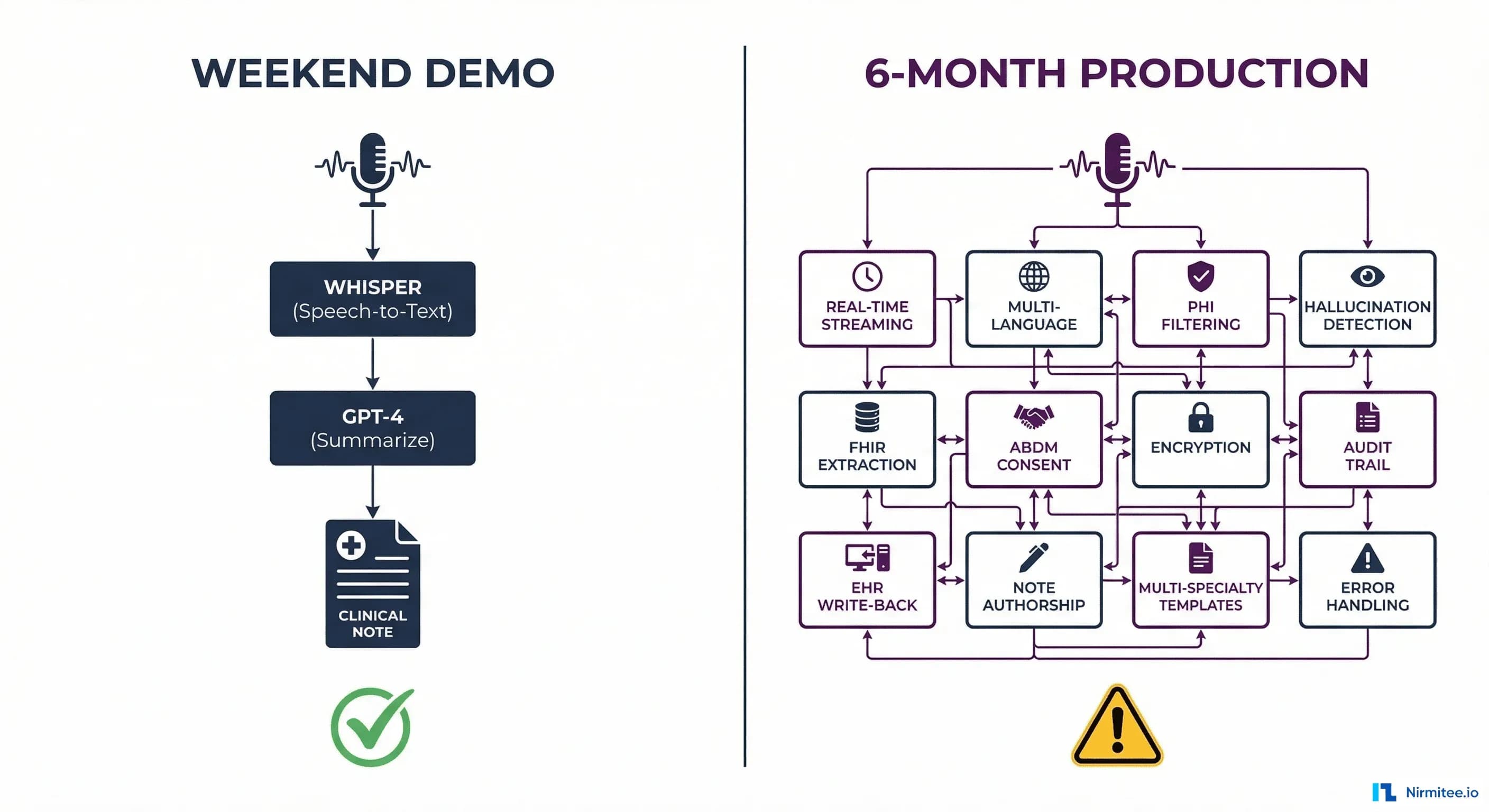
A motivated developer can wire together OpenAI's Whisper (speech-to-text) and GPT-4 (summarization) in a weekend and have a working prototype that listens to a mock consultation and produces a decent SOAP note. It is impressive. It feels like the future.
And then reality hits. Taking that weekend prototype to a system that a hospital can actually use in production takes 6 to 12 months — not because the AI is wrong, but because of everything around it: EHR integration, FHIR compliance, consent management, medicolegal authorship, hallucination detection, multilingual support, patient privacy, and audit trails.
This article walks you through both sides. First, we will build the demo. Then we will break down the 12 production problems that separate a prototype from a deployed product. If you are a hospital, a health-tech founder, or an IT leader evaluating AI scribes, this is what you need to understand before you invest.
Part 1: Build the Demo in a Weekend
The demo is three components. That is it.
Component 1: Audio Capture
Use the browser's built-in MediaRecorder API or a simple Python script to capture audio from a microphone. Nothing fancy — just WAV or WebM audio chunks.
# Record audio from microphone (Python)
import sounddevice as sd
import numpy as np
import scipy.io.wavfile as wav
duration = 300 # 5 minutes
sample_rate = 16000
print("Recording consultation...")
audio = sd.rec(int(duration * sample_rate), samplerate=sample_rate, channels=1)
sd.wait()
wav.write("consultation.wav", sample_rate, audio)Component 2: Speech-to-Text with Whisper
Send the audio to OpenAI's Whisper API. It returns a transcript. Whisper handles multiple accents reasonably well and supports several Indian languages.
# Transcribe with Whisper
from openai import OpenAI
client = OpenAI()
with open("consultation.wav", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="text"
)
print(transcript)Component 3: Clinical Note Generation with GPT-4
Send the transcript to GPT-4 with a prompt that asks for a structured SOAP note.
# Generate SOAP note
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": """You are a medical scribe. Given a
doctor-patient consultation transcript, generate a structured SOAP note:
- Subjective: Patient complaints, history
- Objective: Vitals, examination findings mentioned
- Assessment: Likely diagnosis
- Plan: Treatment, medications, follow-up"""},
{"role": "user", "content": transcript}
]
)
soap_note = response.choices[0].message.content
print(soap_note)That is the entire demo. About 30 lines of Python. Record audio, transcribe it, summarize it into a SOAP note. It works. Show it to a doctor and they will be impressed — the note captures the key clinical details, the format is familiar, and it took seconds instead of the 10-15 minutes they normally spend on documentation.
So why can't you just deploy this in a hospital on Monday?
Part 2: The 12 Production Problems
The demo is the tip of the iceberg. Here is what sits below the waterline.
Problem 1: EHR Write-Back
The demo displays a note on screen. A production system must write that note into the hospital's Electronic Health Record (HIS/EMR) — tagged to the correct patient, the correct encounter, the correct department, by the correct author, in the correct format.
Every HIS has a different API (or no API at all). Some accept HL7 CDA documents. Some have proprietary REST endpoints. Some require direct database inserts. Your integration layer must handle each HIS vendor's write-back contract — field validation, required identifiers (encounter ID, department code, provider ID), and document type codes.
This single problem can take 2-3 months to solve per HIS vendor.
Problem 2: FHIR Structured Data Extraction
The demo produces free text. A production system must extract structured, coded clinical data from the consultation:
- Diagnoses → ICD-10 codes
- Procedures → SNOMED CT codes
- Medications → RxNorm codes with dosage and frequency
- Lab orders → LOINC codes
- Vitals → Standardized FHIR Observation resources
This structured data must be packaged as a FHIR R4 Composition resource conforming to NRCeS profiles (in India) or US Core profiles. The FHIR bundle is what gets written to the EHR, shared via ABDM, and used for billing, analytics, and clinical decision support. Free text is useless for all of these.
Getting an LLM to reliably extract structured codes from conversational speech is significantly harder than generating a summary. Hallucinated ICD-10 codes are not just wrong — they are dangerous for billing and clinical decision-making.
Problem 3: Multi-Accent and Multilingual Speech
India alone has consultations happening in Hindi, Tamil, Telugu, Kannada, Malayalam, Bengali, Marathi, and English — often mixed within a single consultation (code-switching). The doctor might say "patient ko fever hai last 3 din se, with associated myalgia" — that is Hindi-English code-switching in one sentence.
Whisper handles major languages decently, but struggles with:
- Code-switching within sentences
- Strong regional accents on medical terminology
- Low-resource Indian languages
- Background noise in busy OPDs
Production systems need language detection, specialized fine-tuned models, and fallback strategies when transcription confidence is low.
Problem 4: Speaker Diarization
The demo treats the audio as one stream. In production, you must distinguish who is speaking — the doctor vs. the patient vs. a family member. The clinical note must attribute statements correctly: "Patient reports 3 days of fever" is clinical data. "Doctor explains the treatment plan" is counseling documentation. Mixing them up is a documentation error.
Speaker diarization (identifying who spoke when) requires specialized models that run alongside the speech-to-text pipeline. This adds latency, complexity, and cost.
Problem 5: ABDM Consent and Compliance
Under India's ABDM framework, clinical documentation that becomes part of the patient's health record must comply with:
- Patient consent for recording and processing the consultation audio
- FHIR R4 format conforming to NRCeS profiles for data sharing
- Consent artefact management if the note will be shared with other providers via ABDM's HIP/HIU mechanism
- Data encryption (Fidelius ECDH) for any data that flows through ABDM
The demo has zero compliance. A production system must have ABDM integration baked in from day one — not bolted on later.
Problem 6: Medicolegal Note Authorship
When an AI generates a clinical note, who is the legal author? In every medical regulatory framework, a licensed clinician must be the author of record. The AI is a tool, not a practitioner.
This means the production system must:
- Generate the note as a draft
- Present it to the clinician for review and editing
- Capture the clinician's explicit approval (digital signature or equivalent)
- Record the timestamp of approval and the identity of the approving clinician
- Store both the AI-generated version and the clinician-approved version for audit comparison
This is not a UX nicety — it is a medicolegal requirement. If the note is ever questioned in a malpractice review, the hospital must prove a human clinician reviewed and approved it.
Problem 7: Patient Privacy and Ambient Listening
An ambient AI scribe listens to everything in the consultation room. This raises critical privacy concerns:
- Informed consent: The patient must explicitly consent to being recorded. This consent must be documented
- Data minimization: The system should process and discard the audio after transcription — storing raw audio recordings of patient consultations is a massive liability
- Bystander capture: If a family member or another patient is in the room, their speech may be captured. The system must handle this
- Network security: If audio is sent to a cloud API (like OpenAI's Whisper), patient audio is leaving the hospital network. Some hospitals require on-premise speech processing for compliance. This means self-hosted Whisper models on local GPUs — a significant infrastructure investment
Problem 8: Hallucination in Clinical Context
LLMs hallucinate. In a consumer chatbot, a hallucination is an inconvenience. In a clinical note, a hallucination is a medical record falsification.
Examples of dangerous clinical hallucinations:
- The AI adds "no known allergies" when the doctor never mentioned allergies
- The AI generated a medication dosage that was not discussed
- The AI invents a physical examination finding
- The AI assigns an ICD-10 code for a condition that was only mentioned as a differential, not a diagnosis
Mitigation requires: Grounding every generated statement against the original transcript. If a statement in the note cannot be traced back to something that was actually said, it must be flagged. This requires a verification layer that runs after generation — comparing the note against the transcript for factual consistency.
Problem 9: Specialty-Specific Templates
A SOAP note works for general medicine. But a hospital has dozens of specialties, each with different documentation requirements:
- Ophthalmology: Visual acuity charts, IOP measurements, slit lamp findings
- Orthopedics: Range of motion, imaging correlations, surgical planning
- Psychiatry: Mental status examination, risk assessments, therapy progress notes
- Obstetrics: Gestational age tracking, fetal monitoring, risk stratification
Each specialty needs its own note template, its own extraction rules, and its own LLM prompt. A one-size-fits-all SOAP prompt produces notes that specialists reject as inadequate.
Problem 10: Real-Time Streaming
The demo records first, then processes. A production scribe should work in near real-time — generating the note as the consultation progresses, so the doctor can review it immediately after the patient leaves.
This requires streaming audio to the speech-to-text engine, processing in chunks, maintaining context across chunks, and updating the note incrementally. The latency budget is tight: the note should be ready within 30 seconds of the consultation ending.
Problem 11: Error Recovery and Graceful Degradation
What happens when Whisper returns a garbled transcript because of background noise? What happens when GPT-4 is down? What happens when the hospital's network drops mid-consultation?
A production system must:
- Buffer audio locally until upload succeeds
- Detect low-confidence transcription and flag for manual review
- Fall back to a simpler summarization model if the primary model is unavailable
- Never lose a consultation recording due to a network glitch
Problem 12: Audit Trail and Observability
Every production AI scribe session must log:
- Who was the patient, which encounter, which clinician
- Audio processing duration and transcription confidence
- LLM model used, tokens consumed, generation time
- Hallucination check results
- Whether the clinician approved, edited, or rejected the note
- What the clinician changed (diff between AI draft and approved version)
This audit trail is non-negotiable for regulatory compliance and is essential for improving the system over time — clinician edits are the best training signal for making the AI better.
What Production Actually Looks Like
Here is the production pipeline — from microphone to medical record:
| Stage | Demo | Production |
|---|---|---|
| Audio capture | Browser mic, single file | Streaming WebRTC, noise cancellation, local buffer, patient consent recorded |
| Speech-to-text | Whisper API (cloud) | On-premise Whisper or hybrid, multi-language, speaker diarization, confidence scoring |
| Clinical NLP | None | ICD-10/SNOMED/LOINC extraction, coded medications, structured vitals |
| Note generation | GPT-4, generic SOAP prompt | Specialty-specific templates, grounded against transcript, hallucination flagging |
| Output format | Plain text on screen | FHIR R4 Composition (NRCeS profile), structured + narrative sections |
| Review workflow | None | Clinician review, edit, digital signature, draft→approved state machine |
| Storage | None | EHR write-back via system-specific API, ABDM consent-gated sharing |
| Audit | None | Full trace: audio→transcript→AI draft→edits→approved version, per session |
| Privacy | Audio sent to OpenAI | Audio processed on-premise or in compliant cloud, auto-deleted post-processing |
| Cost | Pay-per-use API | Self-hosted models for volume, API fallback, cost tracking per consultation |
Who Is Doing This at Scale?
Several companies have crossed the demo-to-production chasm and offer insight into what it actually takes:
| Company | Scale | Key Differentiator |
|---|---|---|
| Abridge (YC-backed) | Deployed across 100+ health systems in the US | Deep EHR integration with Epic and other major platforms, structured data extraction, real-time generation |
| Sully.ai | AI scribe as part of a multi-agent suite (triage, coding, pharmacy) | Multi-agent orchestration — the scribe feeds the coder, which feeds the biller. Integration across the entire clinical workflow |
| Nuance DAX (Microsoft) | Major EHR vendor partnerships, enterprise scale | Ambient listening with deep Epic/Cerner integration, specialty-specific models |
The common thread: none of them succeeded by building a better LLM. They succeeded by solving the integration, compliance, and workflow problems around the LLM.
The Decision Framework: Build, Buy, or Partner?
If you are a hospital or health-tech company evaluating AI scribes, here is how to think about it:
| Approach | When It Makes Sense | Watch Out For |
|---|---|---|
| Build the demo | Learning, internal hackathon, evaluating feasibility | Do not confuse a working demo with a deployable product. The 12 problems above still apply |
| Buy a product (Abridge, Nuance, etc.) | US hospitals on Epic/Cerner with budget for enterprise licenses | Most products are US-centric. Indian hospital systems (HIS vendors, ABDM compliance, Indian languages) are not supported |
| Partner with an integrator | Indian hospitals, custom HIS/LIMS environments, ABDM requirements | Ensure the partner understands both the AI layer AND the integration layer. An AI company without integration expertise will hit the same walls you would |
How Nirmitee Approaches AI Scribes
At Nirmitee, we have built and deployed clinical documentation AI across hospital environments. Our approach starts with the integration layer, not the AI model:
- Integration-first: We connect to your HIS, LIMS, and pharmacy systems first. The AI scribe writes back through the same middleware that handles all your ABDM data flows — not through a separate, fragile integration
- FHIR-native output: Every AI-generated note produces a FHIR R4 Composition with coded clinical data (ICD-10, SNOMED, LOINC) — ready for EHR storage, ABDM sharing, and downstream analytics
- ABDM-compliant from day one: Patient consent, data encryption, audit trails — all handled by the same middleware that manages your M2/M3 compliance
- Specialty-configurable: Template system that adapts to each department's documentation requirements without rebuilding the pipeline
- Clinician-in-the-loop: Draft → review → approve workflow with digital signature, edit tracking, and version history for medicolegal protection
- Model-agnostic: We are not locked to one LLM provider. The speech and summarization models can be swapped — GPT-4, Claude, open-source clinical models, or on-premise deployments — without changing the integration or compliance infrastructure
The weekend demo proves the concept. The 6-month production journey proves the execution. If you are ready to move from prototype to production, talk to our team about building it on a foundation that actually works in a hospital.
Struggling with healthcare data exchange? Our Healthcare Interoperability Solutions practice helps organizations connect clinical systems at scale. We also offer specialized Healthcare Software Product Development services. Talk to our team to get started.