In March 2024, a mid-sized hospital network in Ohio deployed an AI agent that flagged 340 potentially dangerous drug interactions in its first 90 days of operation. Every single flag was clinically validated by a pharmacist before reaching the patient. That system took 14 months to build, not because the machine learning was hard, but because integrating safely with live clinical data through FHIR R4, enforcing HIPAA-compliant access controls, and building reliable human-in-the-loop workflows demanded far more engineering rigor than anyone on the team initially expected.
This guide walks you through the exact eight steps required to build a healthcare AI agent that can operate in a clinical environment. Each step includes working code, architecture decisions, and the specific pitfalls that cause most healthtech AI projects to fail during pilot or regulatory review.
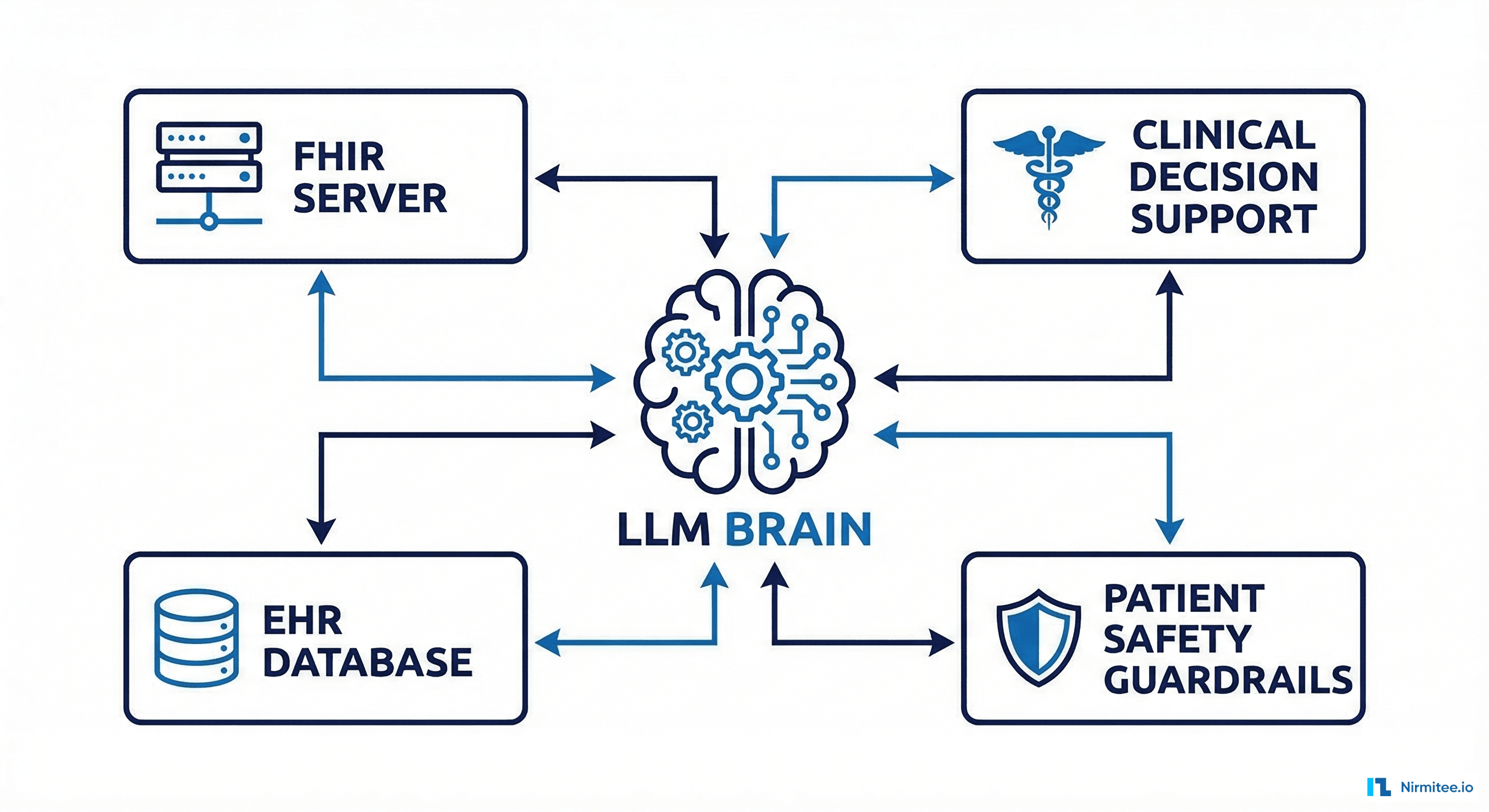 FHIR server, clinical decision support, EHR database, and safety guardrails" width="1024" />
FHIR server, clinical decision support, EHR database, and safety guardrails" width="1024" />
Step 1: Define the Clinical Workflow You Are Automating
Most failed healthcare AI projects skip this step entirely. They start with a model and go looking for a problem. The correct approach is to shadow clinicians, document the exact workflow steps, identify where cognitive load is highest, and determine which decisions are both high-frequency and rule-driven enough for an AI agent to handle safely.
Conducting a Workflow Audit
Spend at least one week observing the target clinical environment. Track every decision point, data source consulted, and handoff between systems. The goal is a process map that answers three questions:
- What data does the clinician look at? Chart review, lab results, imaging, medication history, insurance eligibility. Understand not just the data but the sequence in which clinicians access it, because this sequence reflects clinical reasoning patterns your agent will need to mirror.
- What decision does the clinician make? Dosage adjustment, referral, order entry, documentation. Classify each decision as algorithmic (can be encoded in rules), probabilistic (requires statistical reasoning), or judgment-based (requires experience and contextual knowledge). AI agents are best suited for the first two categories.
- What is the consequence of a wrong decision? This determines your safety tier: advisory-only, semi-autonomous, or fully autonomous with guardrails. A wrong suggestion in a clinical documentation agent is inconvenient. A wrong dosage recommendation for a blood thinner can kill a patient.
For a medication reconciliation agent, the workflow typically looks like this: patient arrives, nurse pulls medication list from three sources (EHR, pharmacy benefit manager, patient self-report), pharmacist reviews discrepancies, physician confirms final list. The AI agent targets the discrepancy identification step, reducing pharmacist review time from 22 minutes to 4 minutes per patient according to data from ONC HealthIT pilot programs.
Defining Agent Scope and Safety Classification
Use the FDA SaMD classification framework to determine your regulatory tier early. A decision-support tool that provides information to clinicians (Class I/II) has fundamentally different engineering requirements than one that autonomously executes clinical actions (Class III). Getting this classification wrong means rebuilding your architecture at the worst possible time, right before clinical validation.
| Safety Tier | AI Agent Behavior | Human Oversight | Regulatory Path |
|---|---|---|---|
| Advisory | Surfaces insights and suggestions | Clinician reviews all outputs | FDA 510(k) or exempt |
| Semi-autonomous | Executes low-risk actions, flags high-risk | Approval required for flagged items | FDA De Novo or 510(k) |
| Autonomous | Executes within defined clinical boundaries | Post-action audit review | FDA PMA or Breakthrough |
Step 2: Set Up FHIR Data Access
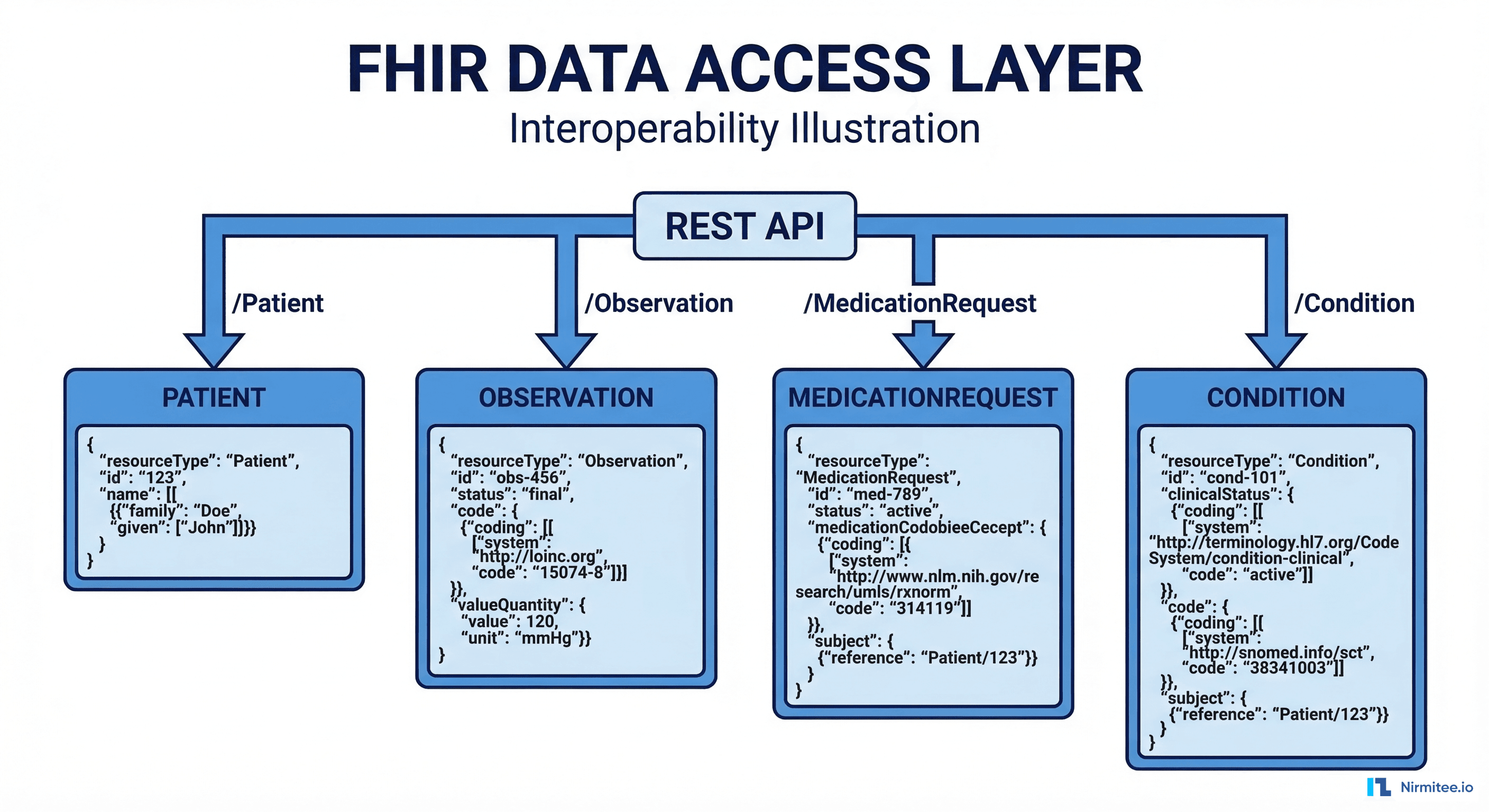
Every healthcare AI agent needs access to clinical data. The HL7 FHIR R4 specification is the industry standard API for reading and writing clinical data. If you are building against Epic, Cerner (Oracle Health), or any EHR certified under ONC 21st Century Cures Act requirements, FHIR R4 endpoints are available.
The practical reality is that FHIR data quality varies enormously across EHR implementations. Epic's FHIR API returns well-structured US Core-compliant resources. Some smaller EHRs return technically valid FHIR with missing codes, free-text values where coded values belong, and inconsistent terminology. Your agent must handle both extremes gracefully.
Connecting to a FHIR Server
Use a mature FHIR client library. In Python, fhirclient handles resource parsing and pagination. Here is a working example that retrieves a patient's active medications and handles the pagination edge case that trips up most implementations:
import requests
class FHIRClient:
def __init__(self, base_url: str, access_token: str):
self.base_url = base_url.rstrip('/')
self.session = requests.Session()
self.session.headers.update({
'Authorization': f'Bearer {access_token}',
'Accept': 'application/fhir+json'
})
def get_active_medications(self, patient_id: str) -> list:
"""Fetch active MedicationRequests for a patient.
Handles pagination to ensure complete results."""
url = f"{self.base_url}/MedicationRequest"
params = {
'patient': patient_id,
'status': 'active',
'_include': 'MedicationRequest:medication',
'_count': 100
}
all_resources = []
while url:
response = self.session.get(url, params=params)
response.raise_for_status()
bundle = response.json()
all_resources.extend([
entry['resource']
for entry in bundle.get('entry', [])
if entry['resource']['resourceType'] == 'MedicationRequest'
])
# Handle pagination
next_link = next(
(link['url'] for link in bundle.get('link', [])
if link.get('relation') == 'next'),
None
)
url = next_link
params = None # Next URL includes params
return all_resources
def get_patient_conditions(self, patient_id: str) -> list:
"""Fetch active conditions (problem list) for a patient."""
url = f"{self.base_url}/Condition"
params = {
'patient': patient_id,
'clinical-status': 'active'
}
response = self.session.get(url, params=params)
response.raise_for_status()
bundle = response.json()
return [
entry['resource']
for entry in bundle.get('entry', [])
]
def get_recent_observations(self, patient_id: str,
category: str = 'laboratory',
days: int = 30) -> list:
"""Fetch recent observations by category."""
from datetime import datetime, timedelta
cutoff = (datetime.utcnow() - timedelta(days=days)).strftime('%Y-%m-%d')
url = f"{self.base_url}/Observation"
params = {
'patient': patient_id,
'category': category,
'date': f'ge{cutoff}',
'_sort': '-date',
'_count': 100
}
response = self.session.get(url, params=params)
response.raise_for_status()
return [e['resource'] for e in response.json().get('entry', [])]A critical pitfall: FHIR servers implement pagination differently. Epic returns a maximum of 100 resources per page and uses Bundle.link with relation: next for pagination. Cerner uses a different cursor format. Always implement pagination handling from day one, or your agent will silently miss data for patients with more than 100 records of a given type. This silent data loss is particularly dangerous for medication lists, where missing a single active medication can lead to an undetected drug interaction.
Step 3: Implement SMART on FHIR Authorization
Healthcare AI agents cannot use static API keys. The SMART on FHIR protocol provides OAuth 2.0-based authorization that enforces patient-level and clinician-level access scopes. Your agent must request only the minimum scopes needed for its clinical function.
There are three SMART on FHIR launch patterns, and choosing the wrong one is a common source of delays during EHR vendor review:
- EHR Launch: The EHR initiates the app launch and provides context (which patient, which encounter). Best for agents embedded in clinician workflows.
- Standalone Launch: The app launches independently and the user selects the patient context. Best for standalone analytics dashboards.
- Backend Services: Server-to-server with no user interaction. Best for batch processing agents and automated surveillance systems.
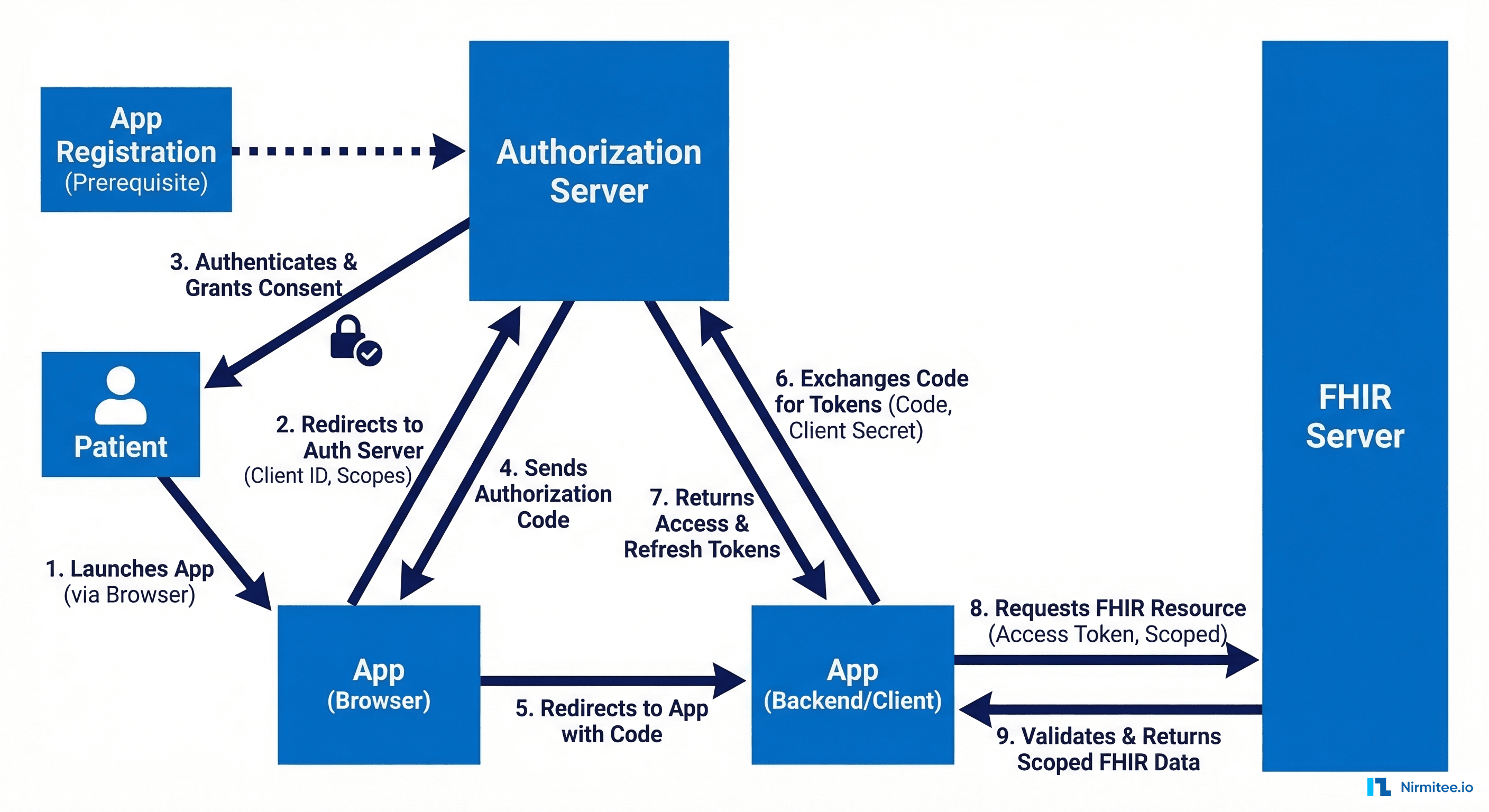
Implementing the Backend Services Flow
For server-to-server AI agents that operate without a user in the browser, use the SMART Backend Services authorization flow. This uses asymmetric JWT client assertions instead of client secrets:
import jwt
import time
import requests
from cryptography.hazmat.primitives import serialization
class SMARTBackendAuth:
def __init__(self, client_id: str, private_key_path: str,
token_endpoint: str, fhir_base: str):
self.client_id = client_id
self.token_endpoint = token_endpoint
self.fhir_base = fhir_base
with open(private_key_path, 'rb') as f:
self.private_key = serialization.load_pem_private_key(
f.read(), password=None
)
self._token = None
self._token_expiry = 0
def get_access_token(self, scopes: list[str]) -> str:
"""Exchange JWT assertion for access token with caching."""
if self._token and time.time() < self._token_expiry - 60:
return self._token
now = int(time.time())
assertion = jwt.encode({
'iss': self.client_id,
'sub': self.client_id,
'aud': self.token_endpoint,
'exp': now + 300,
'jti': f"{self.client_id}-{now}"
}, self.private_key, algorithm='RS384')
response = requests.post(self.token_endpoint, data={
'grant_type': 'client_credentials',
'scope': ' '.join(scopes),
'client_assertion_type':
'urn:ietf:params:oauth:client-assertion-type:jwt-bearer',
'client_assertion': assertion
})
response.raise_for_status()
token_data = response.json()
self._token = token_data['access_token']
self._token_expiry = now + token_data.get('expires_in', 300)
return self._tokenCommon mistake: requesting overly broad scopes. An agent that only reads medications should request system/MedicationRequest.read, not system/*.read. Overly broad scopes will be rejected by most production FHIR servers and will raise red flags during security review. Epic specifically rejects scope requests that are broader than what was approved during app registration.
Step 4: Build Agent Tools (FHIR Read/Write and External APIs)
Healthcare AI agents need structured tools that the LLM can invoke. Each tool should be a well-defined function with typed inputs, validated outputs, and comprehensive error handling. This is where frameworks like LangChain or LlamaIndex become useful, though many production healthcare teams build custom tool layers to maintain tighter control over PHI handling.
The tool design principle for healthcare is strict: every tool must return structured data from a known source, never allow the LLM to generate clinical data from its parametric knowledge. The LLM's role is reasoning and synthesis; the tools provide the facts.
Here is a tool definition for checking drug interactions using the NLM RxNorm API:
from typing import TypedDict
import requests
class DrugInteraction(TypedDict):
drug_pair: tuple[str, str]
severity: str # 'critical', 'major', 'moderate', 'minor'
description: str
source: str
def check_drug_interactions(
rxcui_list: list[str]
) -> list[DrugInteraction]:
"""Check interactions between a list of RxNorm CUIs.
Uses NLM Interaction API (free, no key required).
Returns empty list if fewer than 2 drugs."""
if len(rxcui_list) < 2:
return []
url = "https://rxnav.nlm.nih.gov/REST/interaction/list.json"
params = {'rxcuis': '+'.join(rxcui_list)}
resp = requests.get(url, params=params, timeout=10)
resp.raise_for_status()
data = resp.json()
interactions = []
for group in data.get('fullInteractionTypeGroup', []):
for itype in group.get('fullInteractionType', []):
pair = itype.get('minConcept', [])
for ipair in itype.get('interactionPair', []):
interactions.append(DrugInteraction(
drug_pair=(pair[0]['name'], pair[1]['name'])
if len(pair) >= 2 else ('unknown', 'unknown'),
severity=ipair.get('severity', 'N/A'),
description=ipair.get('description', ''),
source=group.get('sourceName', '')
))
return interactions
def resolve_medication_to_rxcui(medication_text: str) -> str:
"""Resolve free-text medication name to RxNorm CUI.
Essential for agents working with non-coded medication data."""
url = "https://rxnav.nlm.nih.gov/REST/approximateTerm.json"
params = {'term': medication_text, 'maxEntries': 1}
resp = requests.get(url, params=params, timeout=10)
resp.raise_for_status()
candidates = resp.json().get('approximateGroup', {}).get('candidate', [])
if candidates:
return candidates[0].get('rxcui', '')
return ''Step 5: Add Safety Guardrails
This is where healthcare AI agents diverge fundamentally from general-purpose AI applications. Every output of the agent must pass through clinically-validated safety checks before it reaches a clinician or triggers any downstream action. The guardrail layer is not a post-processing step you add at the end; it is a core architectural component that shapes the entire system design.
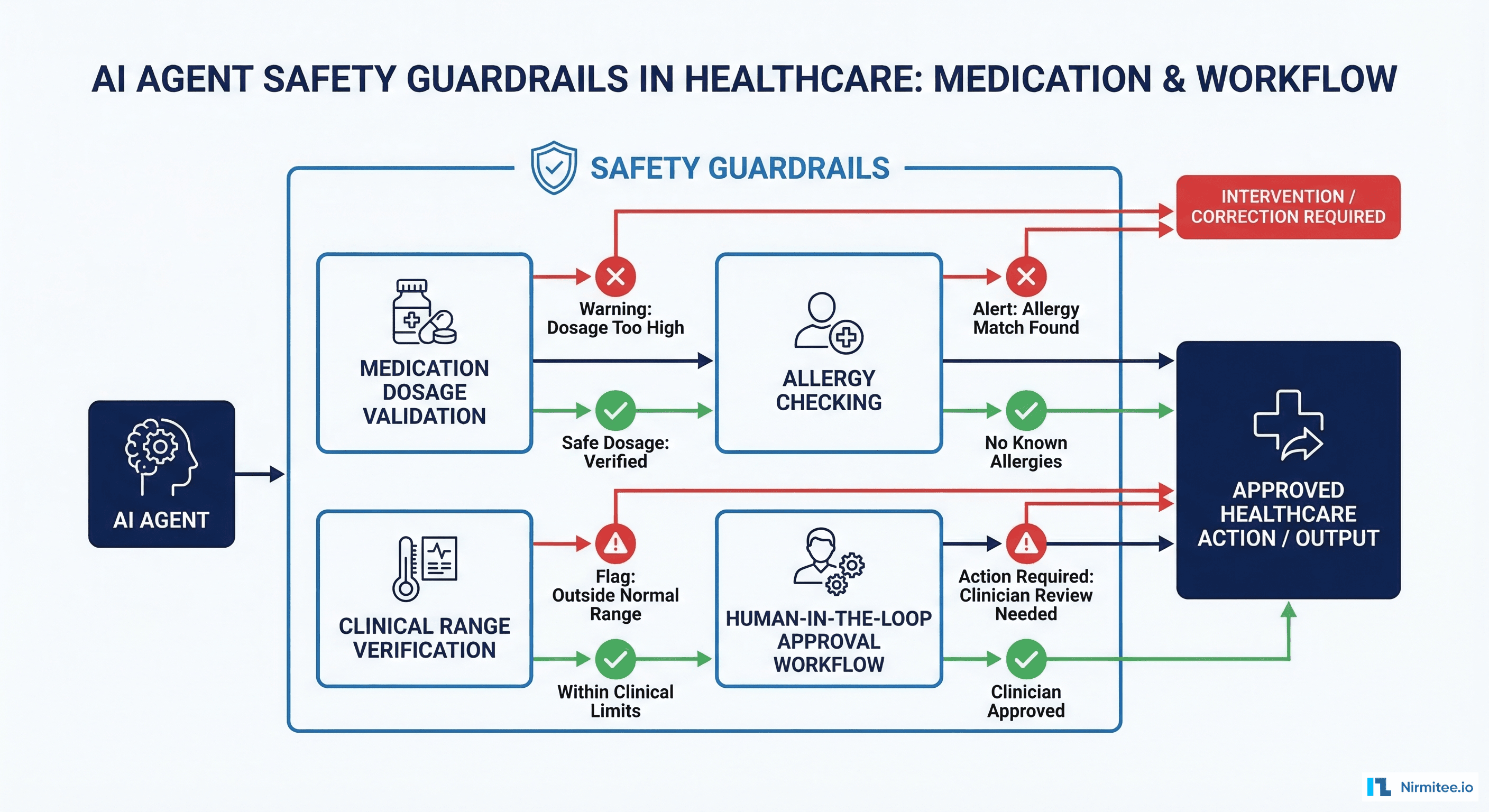
Implementing Output Validation
Build a guardrail pipeline that checks every agent output against clinical rules. These are not optional nice-to-haves. According to Joint Commission standards, any clinical decision support tool must have documented validation logic and fail-safe behavior.
| Guardrail Type | What It Checks | Failure Action |
|---|---|---|
| Dosage Range | Recommended dose within FDA-approved range | Block + alert pharmacist |
| Allergy Cross-Check | Suggested medication not in allergy list | Block + alert prescriber |
| Lab Value Validation | Referenced lab values exist and are recent (<24h) | Flag stale data warning |
| Contraindication Check | No active contraindications for suggestion | Block + provide alternatives |
| Hallucination Detection | Referenced medications/conditions exist in patient record | Reject output entirely |
The hallucination detection guardrail deserves special attention. When an LLM generates a clinical recommendation that references a medication the patient is not actually taking, that is a potentially fatal error. Cross-reference every clinical entity mentioned in the agent's output against the actual FHIR data retrieved in the tool calls. Build a structured output parser that extracts all clinical entity references (medication names, RxNorm codes, SNOMED codes, ICD-10 codes) from the agent response and validates each one against the patient's FHIR records.
A second critical guardrail is temporal validation. If the agent recommends adjusting a warfarin dose based on an INR value, verify that the INR observation is from the last 24 hours. Clinical decisions based on stale lab data are one of the most common sources of medical errors, and AI agents can accelerate this failure mode by confidently presenting outdated data as current.
Step 6: Implement Human-in-the-Loop Review
For any healthcare AI agent operating above the advisory tier, you need an approval workflow that routes agent outputs to qualified clinicians for review before execution. This is not just a regulatory requirement under HIPAA and FDA guidance; it is the single most important safety mechanism in your system.
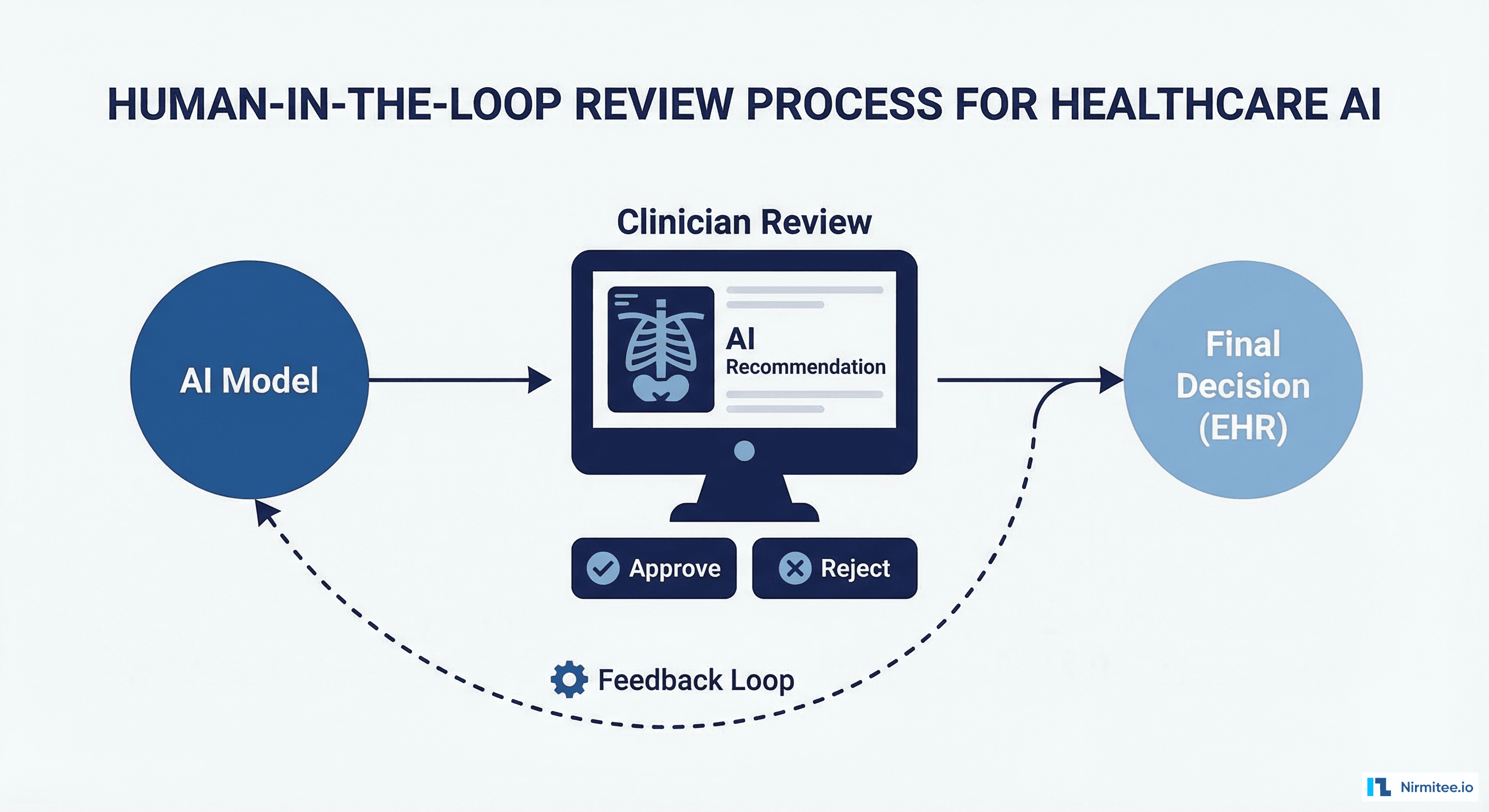
Design the review interface so clinicians can approve, modify, or reject agent recommendations in under 30 seconds. If the review process takes longer than the manual workflow, clinicians will bypass it. Present the agent's reasoning alongside the source data (the actual FHIR resources) so the clinician can verify without navigating to another screen.
Track approval rates and modification patterns. If clinicians are modifying more than 15% of agent outputs, your model needs retraining or your tool definitions need refinement. If they are rubber-stamping everything without review, you have an automation complacency problem and need to add friction (randomized verification prompts, mandatory acknowledgment of high-risk items).
Build feedback capture into the review workflow. Every clinician modification or rejection should generate a structured training signal that feeds into your model improvement pipeline. Over time, this feedback loop is what drives your agent from 85% accuracy to 97% accuracy. Without it, your agent's performance plateaus or degrades as clinical guidelines and patient populations change.
Step 7: Deploy with Production Monitoring
Healthcare AI agents require monitoring that goes beyond standard application performance metrics. You need clinical performance tracking alongside infrastructure observability. A latency spike in a payment processing system costs money; a latency spike in a clinical AI system can delay a time-sensitive medication recommendation.
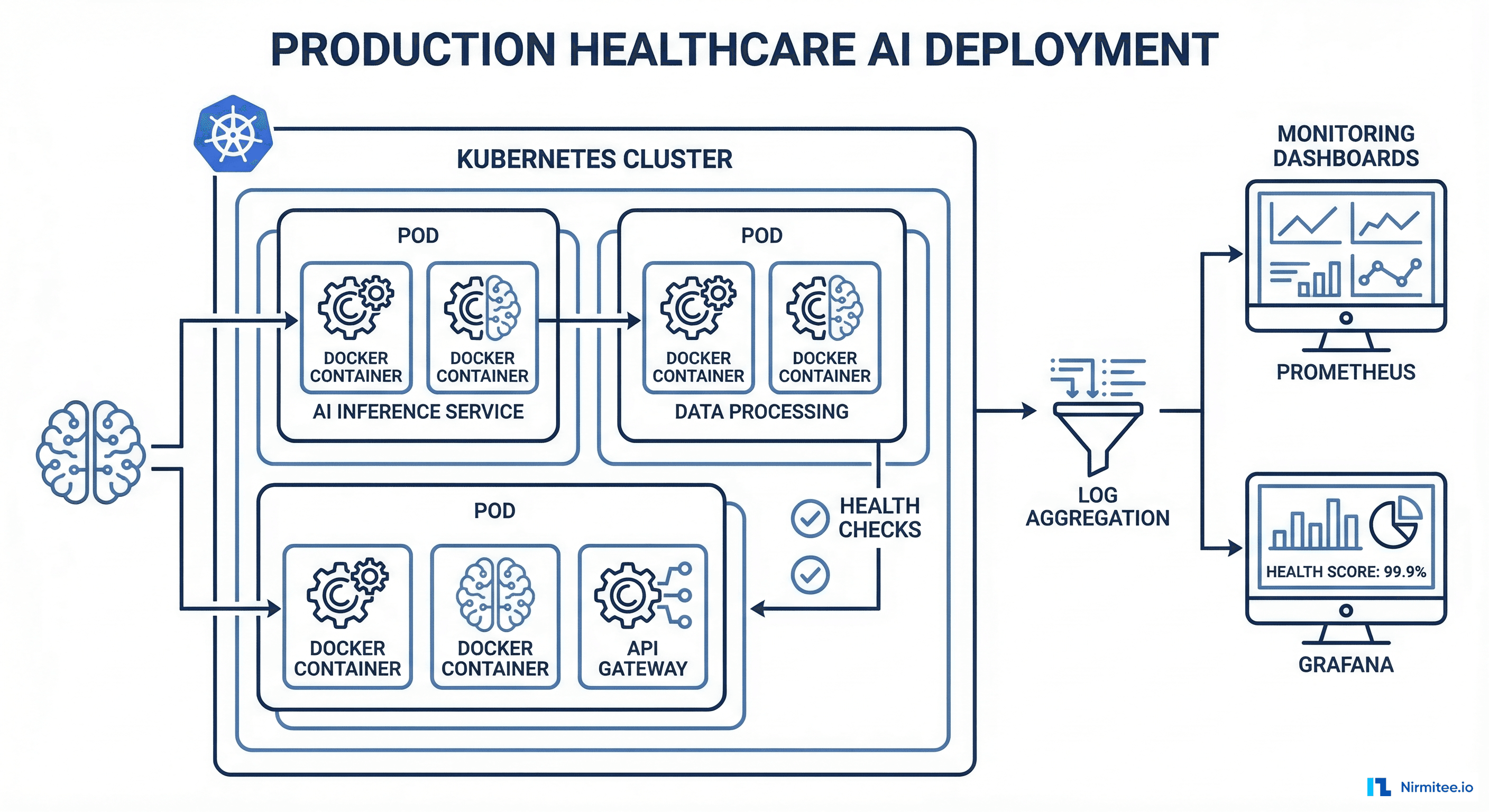
Infrastructure Monitoring
Deploy with Prometheus and Grafana for real-time dashboards. Track these healthcare-specific metrics alongside standard latency and throughput:
- FHIR API response time by resource type -- degraded EHR performance directly impacts patient care timelines
- Token refresh failure rate -- SMART on FHIR tokens expire; failed refreshes mean the agent goes silent with no visible error to the clinician
- Guardrail trigger rate by type -- a spike in dosage-range blocks may indicate a model drift problem or a formulary change the model has not learned about
- Clinician approval/rejection ratio -- the single most important metric for clinical accuracy, tracked per recommendation type
- Time from agent recommendation to clinician action -- measures clinical workflow integration and whether the agent is actually saving time
- LLM token usage and cost per clinical encounter -- healthcare AI agents can consume significant token volumes when processing long patient histories
Set alerting thresholds that account for clinical urgency. A 5-minute FHIR API outage during a normal business day warrants a warning. The same outage during a mass casualty event or ICU rounding warrants a page. Build context-aware alerting that considers the clinical environment, not just infrastructure metrics.
Step 8: Clinical Validation and Ongoing Evaluation
Before any healthcare AI agent goes live with real patients, it must pass a structured clinical validation process. This is not a single event; it is an ongoing cycle of evaluation, refinement, and re-validation that continues for the entire operational life of the agent.
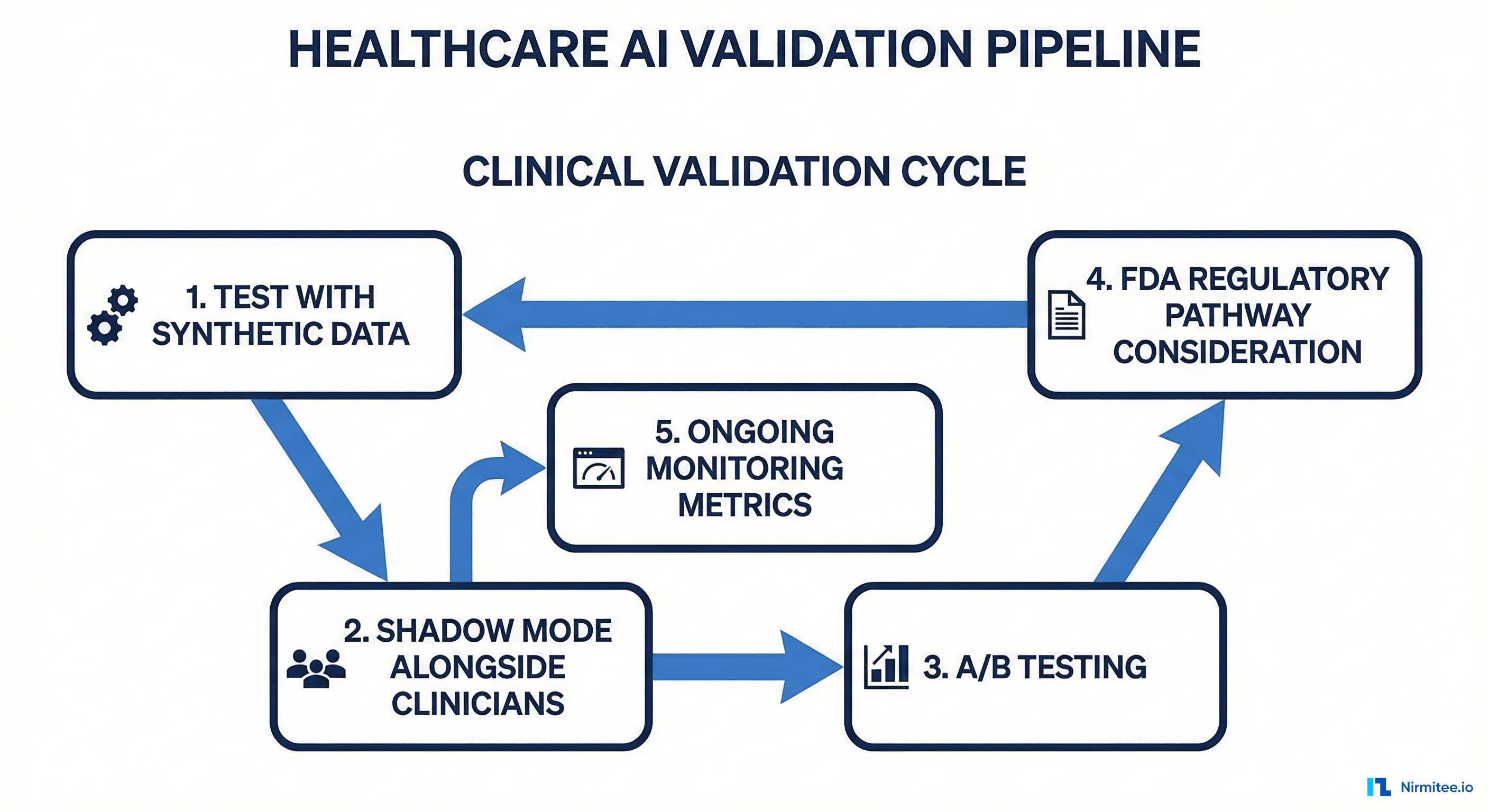
The Four-Phase Validation Protocol
Phase 1: Synthetic Data Testing. Run the agent against de-identified patient datasets. The Synthea patient generator produces realistic FHIR bundles for testing. Generate at least 10,000 synthetic patient encounters covering the demographic and clinical diversity your agent will encounter in production. Measure precision, recall, and F1 score against known-correct clinical decisions. Target a minimum F1 of 0.92 for advisory-tier agents and 0.97 for semi-autonomous agents.
Phase 2: Shadow Mode. Deploy the agent alongside clinicians but do not surface its outputs. Record what the agent would have recommended and compare against actual clinician decisions after the fact. Run shadow mode for a minimum of 30 days or 1,000 clinical encounters, whichever comes first. Analyze disagreements between the agent and clinicians, classifying each as agent-correct, clinician-correct, or ambiguous. Shadow mode is also where you discover data quality issues specific to your production FHIR environment that synthetic data did not reveal.
Phase 3: Supervised Pilot. Surface agent recommendations to a small cohort of trained clinicians with mandatory review. Collect structured feedback on every recommendation. Analyze discrepancies between agent suggestions and clinician final decisions. Measure the impact on clinical workflow time, documentation quality, and patient safety indicators.
Phase 4: Monitored Production. Full deployment with ongoing statistical monitoring. Use CUSUM charts to detect performance degradation over time. Establish a quarterly clinical review board that evaluates agent performance against defined quality metrics. Define clear criteria for when the agent should be automatically disabled (e.g., accuracy drops below threshold, error rate exceeds limit).
Common Pitfalls That Kill Healthcare AI Projects
After working with over 40 healthcare organizations on AI integration, here are the failure patterns we see repeatedly at Nirmitee:
- Starting with the model instead of the workflow. Teams spend months fine-tuning a model, then discover the clinical workflow does not support the interaction pattern they built. Always start with Step 1.
- Ignoring FHIR data quality issues. Production FHIR data is messy. Missing codes, inconsistent terminology, deprecated value sets, and free-text entries where coded values belong. Budget 30% of your development time for data normalization and handling edge cases.
- Treating HIPAA compliance as a checkbox. Access controls, audit logging, data minimization, breach notification procedures, and business associate agreements must be designed into the architecture from the first sprint, not bolted on after the pilot.
- Skipping the human-in-the-loop during pilot pressure. Stakeholders will push to remove the clinician review step to improve throughput metrics. Resist this pressure until you have at least 6 months of production data showing consistent agent accuracy above 95%.
- No plan for model updates. Clinical guidelines change. New drug interactions are discovered. FDA labeling updates occur quarterly. Your agent needs a retraining and revalidation pipeline that runs continuously, not a one-time model deployment that gradually drifts out of date.
- Underestimating EHR vendor review timelines. Getting your SMART on FHIR app approved by Epic, Cerner, or other EHR vendors takes 3-6 months. Factor this into your project timeline from day one.
Architecture Reference: Putting It All Together
The complete healthcare AI agent architecture connects these eight steps into a production system. The data flows from FHIR server through SMART on FHIR auth, into the agent's tool layer, through safety guardrails, into the human-in-the-loop review queue, and finally to clinical action with full audit logging at every step.
Each component should be independently deployable, testable, and replaceable. Use event-driven architecture (Kafka or similar) between the agent output and the review queue so you can replay and audit the complete decision trail for any patient encounter. This auditability is not optional; it is a HIPAA Security Rule requirement for systems that access protected health information.
Separate the LLM inference layer from the clinical logic layer. Your guardrails, tool definitions, and review workflows should function independently of which LLM you use. This separation lets you upgrade from GPT-4 to GPT-5 or switch to Claude or Gemini without rebuilding your entire clinical safety infrastructure. In an industry where the best available model changes every six months, this architectural flexibility is essential.
Next Steps
Building a healthcare AI agent is a 6-12 month engineering effort for a production-ready system. The technical implementation is only half the challenge; the other half is clinical validation, regulatory navigation, and workflow integration with existing clinical processes.
If you need experienced healthcare integration engineers who have built FHIR-connected AI systems for US hospital networks, contact the Nirmitee team. We specialize in healthcare interoperability and AI integration services that meet the rigorous requirements of production clinical environments.
Building production-grade healthcare AI agents requires careful architecture. Our Agentic AI for Healthcare team ships agents that meet clinical and compliance standards. We also offer specialized Healthcare AI Solutions services. Talk to our team to get started.