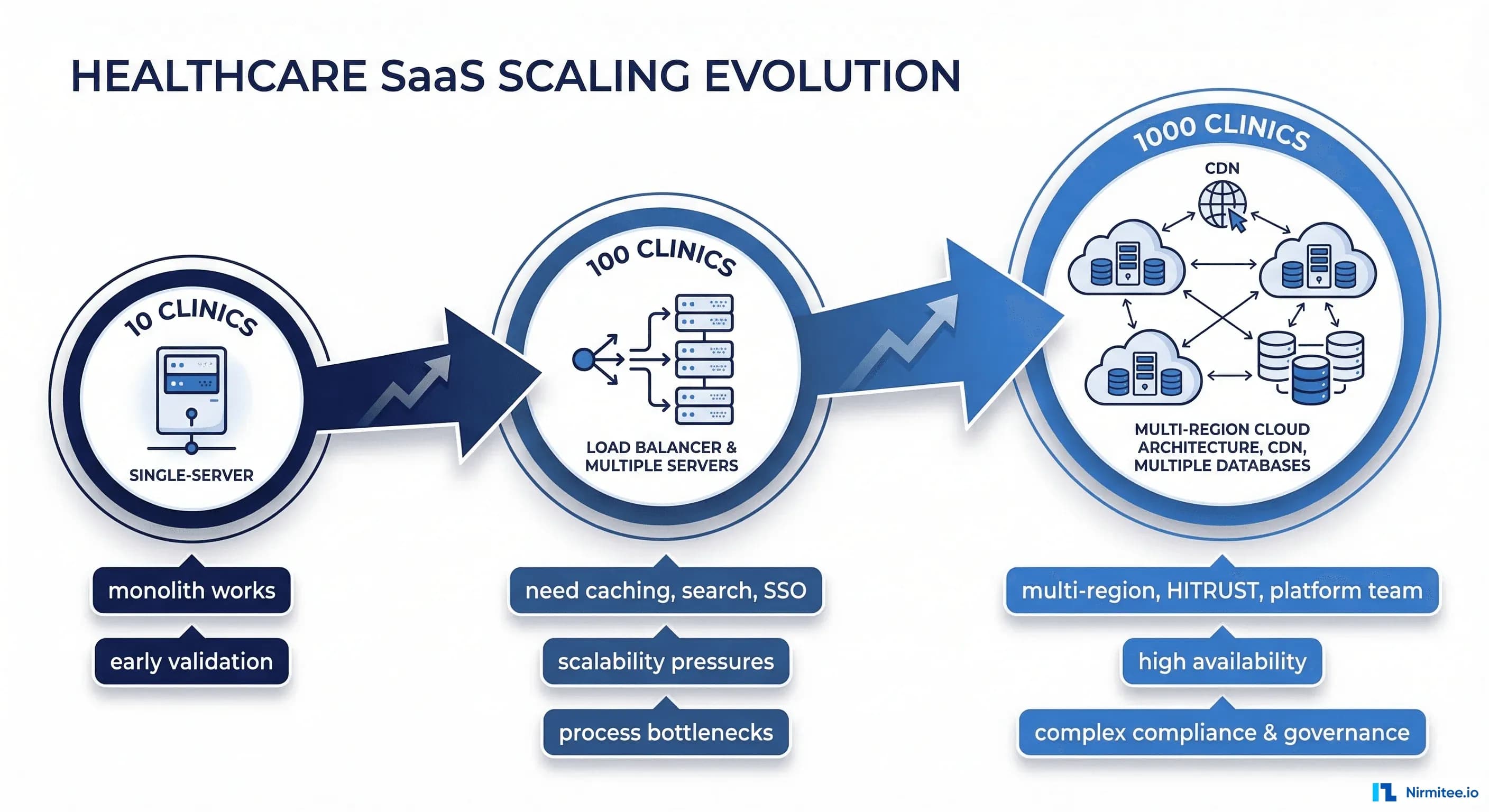
Your 10-Clinic Product Is About to Break
Your healthcare SaaS works beautifully with 10 pilot clinics. The demo is polished. The customers are happy. Your Series A deck shows 98% uptime and strong NPS scores. Then a health system with 200 locations signs. Then another with 500. Then a third with 300.
Suddenly you're not running a product for 10 clinics. You're running infrastructure for 1,000 locations, tens of thousands of concurrent users, and hundreds of millions of patient records. And everything that worked perfectly at small scale starts failing in ways you never anticipated.
This isn't a theoretical exercise. We've helped healthtech companies navigate this exact transition — from comfortable Series A with a handful of clinics to Series B with enterprise health system contracts that demand a completely different engineering foundation. Here's everything that breaks and how to fix it before it costs you a customer.
Database — Queries That Worked at 10 Clinics Timeout at 1,000
This is always the first thing to break. Always.
The Problem
At 10 clinics, you have maybe 50,000 patient records. Your queries scan a manageable dataset. Response times are fast. Nobody notices that your most complex dashboard query does a full table scan because the table fits in memory.
At 1,000 clinics, you have 5 million patient records, 50 million encounters, and 200 million clinical observations. That full table scan now takes 30 seconds. Your connection pool is exhausted because 15 long-running queries are blocking everything else. Your application returns 502 errors during morning clinic hours when everyone logs in simultaneously.
The specific patterns that kill you:
- Single-tenant queries scanning all rows: Your query filters by
tenant_idin the WHERE clause, but without a composite index, PostgreSQL scans the entire table before filtering. At 200 million rows, this is catastrophic. - Missing composite indexes: You have an index on
tenant_idand a separate index oncreated_at. But your most common query filters by both. Without a composite index on(tenant_id, created_at), the database can't efficiently serve this query at scale. - N+1 query patterns: Loading a patient dashboard that fetches the patient, then loops through 20 encounters, each fetching 10 observations. That's 201 queries per page load. Invisible at small scale. At 1,000 concurrent users, that's 200,000 queries hitting your database simultaneously.
- Connection pool exhaustion: Your default connection pool is 20 connections. Each long-running report query holds a connection for 10 seconds. When 20 reports run concurrently, new requests queue and eventually timeout.
The Fix
Start with visibility. You cannot fix what you cannot measure.
-- Enable pg_stat_statements for query analysis
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
-- Find your slowest queries
SELECT query,
calls,
mean_exec_time::numeric(10,2) as avg_ms,
total_exec_time::numeric(10,2) as total_ms,
rows
FROM pg_stat_statements
ORDER BY mean_exec_time DESC
LIMIT 20;Then systematically address each problem:
- Tenant-scoped composite indexes: Every table that participates in tenant-filtered queries needs
(tenant_id, ...)as the leading columns in its indexes. This is non-negotiable for multi-tenant healthcare SaaS. - Eager loading and query batching: Replace N+1 patterns with batch queries. Load all encounters for a patient in one query, all observations in a second query, and join in application code.
- Read replicas for reporting: Route all analytics, dashboards, and report queries to read replicas. Keep your primary database for transactional workloads (creating encounters, updating records).
- Connection pooling with PgBouncer: Put PgBouncer in front of PostgreSQL. Use transaction-level pooling. This lets you serve 1,000 application connections with 50 actual database connections.
Budget reality: Plan for a 2-3 month database optimization sprint before signing your first 500+ clinic contract. This is not feature work — this is keeping-the-lights-on work.
Search — SQL LIKE Is Not a Search Engine
Patient search is the single most-used feature in any clinical application. And SELECT * FROM patients WHERE name LIKE '%john%' stops working the moment you cross 500,000 records.
The Problem
Healthcare search requirements are brutally complex:
- Fuzzy matching: Patients misspell their own names. "Johnathan" vs "Jonathan" vs "Jonathon." "Smith" vs "Smyth." Your search needs to find all of them.
- Transliterated names: In markets like India and the Middle East, names are transliterated from non-Latin scripts. "Mohammed" has at least 15 common English spellings. "Krishnamurthy" vs "Krishnamurti" vs "Krishnamurthi."
- Phonetic matching: "Catherine" and "Katherine" sound identical. Front-desk staff searching by what they heard on the phone need to find both.
- Performance at scale: A LIKE query with a leading wildcard cannot use an index. At 5 million patient records, this query will scan every single row. Every single time.
The Fix
Deploy Elasticsearch or OpenSearch with tenant-scoped indexes. This is not optional at scale — it's a requirement.
Key architecture decisions:
- Index per tenant or tenant field: For HIPAA compliance and data isolation, use either separate indexes per tenant or a single index with a mandatory
tenant_idfield that is enforced at the query layer. We prefer the tenant field approach for operational simplicity, but separate indexes provide stronger isolation guarantees. - Analyzers for healthcare: Configure custom analyzers that combine standard tokenization, phonetic analysis (Double Metaphone or Beider-Morse), and n-gram tokenization. This gives you fuzzy, phonetic, and partial matching in a single query.
- RBAC enforcement: This is critical and frequently overlooked. A user at Clinic A must never see search results from Clinic B, even within the same health system, unless they have explicit cross-clinic access. Enforce this at the query level with mandatory filters, not at the application level with post-query filtering.
- Sync strategy: Use change data capture (Debezium or similar) to keep Elasticsearch in sync with your primary database. Never make Elasticsearch your source of truth — it's a search index, not a database.
Auth — Per-Clinic Roles Become a Nightmare
At 10 clinics, your auth model is simple: users belong to a clinic, users have a role (admin, provider, nurse, front desk), done. At 1,000 clinics organized into 50 health systems, this model collapses.
The Problem
- Organizational hierarchy: A health system admin needs access to all 200 clinics in their system. A regional director needs access to 50 clinics in their region. A clinic admin needs access to one clinic. Your flat user-clinic-role model can't represent this without duplicating user records across 200 clinics.
- SSO/SAML integration: Enterprise health systems don't create accounts in your application. They require SSO integration with their identity provider (Active Directory, Okta, OneLogin). Each health system has their own IdP. You need to support 50 different SAML/OIDC configurations.
- Role inheritance: Health system admin inherits all permissions of clinic admin, who inherits all permissions of provider, and so on. But a health system admin from System A must never have any access to System B, even though they share the same application instance.
- MFA enforcement: Some health systems mandate MFA for all users. Others mandate it only for admin roles. Your auth layer needs per-tenant MFA policy configuration.
The Fix
Invest in a proper identity layer. That represents something to build from scratch.
- Identity providers: Auth0 or Keycloak with tenant-aware configuration. Each health system gets its own "organization" or "realm" with its own SSO connection, MFA policy, and role definitions.
- Hierarchical RBAC: Model your authorization as a tree: Health System → Region → Clinic → Department. Users are assigned roles at a node in the tree and inherit access to all child nodes. This is a well-solved problem — don't reinvent it.
- Just-in-time provisioning: When a user authenticates via SSO, automatically create their account in your system with the correct clinic assignments and roles based on SAML attributes or SCIM provisioning. Manual account creation doesn't scale past 100 clinics.
// Hierarchical role model
{
"organization": "mercy-health-system",
"hierarchy": [
{
"level": "system",
"roles": ["system_admin", "system_viewer"]
},
{
"level": "region",
"roles": ["regional_director"]
},
{
"level": "clinic",
"roles": ["clinic_admin", "provider", "nurse", "front_desk"]
}
],
"inheritance": "system_admin > regional_director > clinic_admin > provider"
}Timeline: A proper identity layer migration takes 3-4 months. Start this before you need it — retrofitting auth is one of the most disruptive changes you can make to a running product.
Integrations — Every Hospital Has a Different EHR
At 10 clinics, you built one integration — probably Epic or Cerner. It works. It's custom. It handles that specific EHR's quirks. Then you sign 50 health systems, and you discover the fragmented reality of healthcare IT.
The Problem
- EHR diversity: Epic, Cerner (now Oracle Health), Allscripts, Athenahealth, eClinicalWorks, NextGen, Greenway, MEDITECH — each with different API styles, different FHIR implementations (if any), different HL7v2 message formats, and different auth flows.
- FHIR is a standard with asterisks: Every EHR vendor implements FHIR slightly differently. Epic's FHIR API returns patient names as
family+given[]. Some smaller EHRs return a singletextfield. Allergy resources have different coding systems. Medication resources use different terminologies (RxNorm vs NDC vs proprietary). - HL7v2 variations: HL7v2 ADT messages from Hospital A put the attending physician in PV1-7. Hospital B puts them in PV1-8. Hospital C sends the physician name as "LASTNAME^FIRSTNAME" while Hospital D sends "FIRSTNAME LASTNAME" in a single component. These aren't bugs — they're "implementation variations."
- Custom builds don't scale: If each integration takes 4-6 weeks of engineering time, connecting to 20 different EHR systems requires 80-120 weeks of engineering. That's 2+ years of integration work before you can serve your contracted health systems.
The Fix
Build an integration abstraction layer with the adapter pattern.
- Internal canonical model: Define your own FHIR-aligned data model. Every integration adapter normalizes incoming data to this model and transforms outgoing data from this model. Your application code never deals with EHR-specific quirks.
- Adapter pattern: Each EHR gets an adapter that handles its specific API, auth flow, data mapping, and error handling. New EHR support means writing a new adapter, not modifying your core application.
- Integration engine: Consider tools like Mirth Connect, Rhapsody, or cloud-based solutions like Redox or Health Gorilla. These handle the low-level HL7v2/FHIR/API translation and let you focus on business logic. At 50+ health system integrations, the build-vs-buy calculation strongly favors buy.
- Integration testing infrastructure: Build a test harness that simulates each EHR's behavior. When you release a new version, run it against every integration adapter's test suite. An update that fixes an Epic integration but breaks Cerner is worse than no update at all.
Cost reality: A mature integration layer with 10+ EHR adapters requires 3-5 dedicated integration engineers. Budget $500K-$800K annually for this team. It's a significant investment, but it's the cost of being an enterprise healthcare vendor.
Deployment — Single Region Stops Working
Your MVP runs in us-east-1. It's fine for your first 10 clinics in the Northeast. But enterprise healthcare contracts have requirements that a single-region deployment cannot satisfy.
The Problem
- Data residency: US hospital systems want their data in the US. Canadian hospitals require data to stay in Canada (PIPEDA). EU health systems require EU hosting (GDPR). Indian hospitals increasingly require in-country hosting (DPDP Act). A single region cannot satisfy all of these simultaneously.
- Latency: A clinic in Seattle hitting a database in Virginia experiences 70-90ms of network latency on every request. Multiply that by 20 API calls per page load. Clinicians notice — and they complain.
- Disaster recovery: Enterprise contracts require documented DR plans with specific RPO (Recovery Point Objective) and RTO (Recovery Time Objective) targets. "We use AWS so we're fine" is not a DR plan. A typical enterprise healthcare contract demands RPO of 1 hour and RTO of 4 hours.
The Fix
- Multi-region deployment: Deploy your application in 2-3 regions minimum (e.g., us-east-1, us-west-2, eu-west-1). Route tenants to their assigned region. This satisfies data residency requirements and reduces latency.
- Per-tenant region configuration: Store each tenant's assigned region in your configuration. When a user authenticates, route them to the correct region. This is simpler than global data replication and avoids the consistency nightmares of cross-region databases.
- Cross-region DR: Replicate data asynchronously to a secondary region for disaster recovery. Test failover quarterly — not just in documentation, but actually fail over and run production traffic from the secondary region. The first time you test failover should not be during an actual outage.
# Per-tenant region routing (simplified)
TENANT_REGIONS = {
"mercy-health": {"primary": "us-east-1", "dr": "us-west-2"},
"nhs-trust-london": {"primary": "eu-west-1", "dr": "eu-central-1"},
"apollo-hospitals": {"primary": "ap-south-1", "dr": "ap-southeast-1"}
}
def route_request(tenant_id):
region = TENANT_REGIONS[tenant_id]["primary"]
return get_regional_endpoint(region)Cost impact: Multi-region deployment roughly doubles your infrastructure cost. Budget for this when pricing enterprise contracts — don't absorb it as margin compression.
Compliance — SOC 2 and HITRUST Become Mandatory
At 10 clinics, security questionnaires are manageable. "Do you encrypt data at rest? Do you have a privacy policy? Do you do background checks?" Check, check, check.
At 1,000 clinics, enterprise health systems demand formal certifications.
The Problem
- SOC 2 Type II: Most enterprise health systems require a SOC 2 Type II report. This isn't a checklist — it's a 3-6 month audit of your actual operating controls by an independent auditor. They review your CI/CD pipeline, access management, incident response, change management, and monitoring. Budget $50K-$150K depending on your auditor and scope complexity.
- HITRUST: The gold standard for healthcare security certification. Many large health systems require HITRUST CSF certification. Budget $200K-$500K and 6-12 months. This is a significant investment, but it eliminates security questionnaires from individual health systems — they accept HITRUST as proof of compliance.
- BAA requirements: Every health system will require a Business Associate Agreement. Your infrastructure, subprocessors, and third-party services all need to be covered by BAAs. That analytics tool you love? If it touches PHI and the vendor won't sign a BAA, you need a different tool.
The Fix
- Start with SOC 2 Type I: This is a point-in-time assessment (controls are designed appropriately). It's faster and cheaper than Type II. Use it as a stepping stone while you prepare for the full Type II audit.
- Use compliance automation platforms: Tools like Vanta, Drata, or Secureframe automate evidence collection, policy management, and continuous monitoring. They reduce the manual effort of SOC 2 maintenance by 60-80% and cost $15K-$30K/year.
- Plan HITRUST certification strategically: Start the HITRUST process 12 months before you need it. The certification itself takes 6-12 months, but the remediation work to get your controls ready can add another 3-6 months. If you're pursuing Series B with enterprise health system traction, HITRUST readiness should be in your fundraising plan.
Team — You Need Platform Engineers, Not Just Feature Developers
At 10 clinics, a team of 5 full-stack engineers can do everything: build features, manage deployments, handle scaling, fix production issues. Notably, at this model fails.
The Problem
Feature development velocity drops to zero because your engineers are spending all their time on operational issues. Deployment takes 4 hours because nobody automated it. A database migration fails at 3 AM and nobody knows how to recover. A security vulnerability is discovered and nobody has time to patch it because they're all building features for the next health system contract.
The Fix
You need specialized roles:
- Platform/infrastructure engineers (2-3): Own deployment pipelines, Kubernetes/ECS configuration, database administration, monitoring, and alerting. These engineers ensure that the platform can handle 10x growth without feature engineers needing to think about infrastructure.
- Security engineers (1-2): Own compliance (SOC 2, HITRUST), vulnerability management, penetration testing coordination, and security architecture review. In healthcare, this isn't optional — it's a contract requirement.
- Integration engineers (2-4): Own EHR adapters, HL7v2/FHIR pipelines, and integration monitoring. These engineers live at the boundary between your system and the healthcare ecosystem.
- SRE function (1-2): Own incident response, runbooks, SLO/SLA monitoring, capacity planning, and on-call rotation. At 1,000 clinics across multiple time zones, 24/7 operational coverage is a contractual obligation.
Hiring timeline: Start hiring platform and security engineers when you're at 50-100 clinics, not when you're at 1,000. These roles take 3-6 months to fill and another 3 months to ramp. If you wait until things are breaking, you're already 6-9 months behind.
The Scaling Checklist
Here's what to prioritize at each stage of growth. Not everything needs to happen at once — but everything needs to happen before you need it.
10 to 100 Clinics
- Add composite database indexes on tenant_id + frequently queried columns
- Implement connection pooling (PgBouncer or equivalent)
- Set up query performance monitoring (pg_stat_statements, APM tooling)
- Replace SQL LIKE search with Elasticsearch/OpenSearch
- Implement RBAC with role hierarchy (move beyond flat role tables)
- Begin SOC 2 Type I preparation
- Hire first platform engineer
- Establish CI/CD pipeline with automated testing
- Implement structured logging and centralized log aggregation
100 to 500 Clinics
- Deploy read replicas for reporting and analytics workloads
- Build integration abstraction layer (adapter pattern for EHR connections)
- Implement SSO/SAML support for enterprise health systems
- Achieve SOC 2 Type II certification
- Plan multi-region deployment architecture
- Hire security engineer and integration engineers
- Implement automated database migrations with rollback capability
- Build integration test harness for all EHR adapters
- Establish on-call rotation and incident response runbooks
- Implement tenant-level feature flags and configuration
500 to 1,000 Clinics
- Deploy to multiple regions with per-tenant routing
- Implement cross-region disaster recovery with tested failover
- Begin HITRUST certification process
- Build dedicated SRE function with 24/7 coverage
- Implement capacity planning and auto-scaling
- Build self-service tenant provisioning (onboarding a new clinic should take minutes, not days)
- Implement tenant-level SLA monitoring and reporting
- Build customer-facing status page and incident communication process
- Implement data archival strategy for historical records
- Establish formal change management process for production deployments
The Bottom Line
Scaling a healthcare SaaS from 10 to 1,000 clinics is fundamentally an engineering challenge, not a sales challenge. The sales team can sign the contracts, but if the platform can't handle the load, maintain compliance, and integrate with the healthcare ecosystem, those contracts become liabilities instead of revenue.
The companies that scale successfully are the ones that invest in platform engineering before they need it. They hire infrastructure and security engineers at 50 clinics, not at 500. They build integration abstraction layers for their second EHR, not their tenth. They start SOC 2 at 30 clinics, not when a health system makes it a contract requirement.
The cost of scaling proactively is measured in engineering headcount and infrastructure spend. The cost of scaling reactively is measured in lost contracts, SLA penalties, security incidents, and — in healthcare — patient safety risks.
If you're a healthtech CTO navigating this transition, we'd like to hear from you. We've helped companies at every stage of this journey — from database optimization sprints to multi-region architecture design to HITRUST certification preparation. The engineering is hard, but it's solvable.
From architecture to production, our Healthcare Software Product Development team builds healthcare platforms that perform at scale. Talk to our team to get started.