In January 2026, a 400-bed health system in the Midwest quietly pulled the plug on its cloud LLM contract. Not because the AI wasn't working — it was. The problem was that every clinical note, every patient summary, every medication reconciliation was leaving their network, traversing the public internet, and landing on infrastructure they didn't control. Their CISO couldn't sleep. Their compliance team couldn't answer the auditor's question: "Where exactly is that PHI right now?"
They aren't alone. According to HealthVerity's 2026 AI trends analysis, sovereign AI — the principle that organizations control where their data is stored, where models run, and where AI workloads execute — has become the defining infrastructure theme for healthcare this year. Deloitte's 2026 Global Healthcare Outlook confirms that over 80% of health care executives expect generative AI to deliver significant value, while 85% plan to increase AI investment in the next two to three years. The question is no longer whether to deploy LLMs — it's where.
This guide is for the CISOs, infrastructure architects, and engineering leads at US health systems who are evaluating on-premise LLM deployment. We'll cover the real reasons to self-host, the models and hardware that actually work, a transparent cost analysis, and the architecture patterns that keep PHI exactly where it belongs — inside your network.
Why Health Systems Are Moving LLMs On-Premise
1. HIPAA Data Sovereignty: PHI Never Leaves Your Network
Every API call to a cloud LLM provider sends PHI across network boundaries you don't control. Even with a BAA in place, you're trusting a third party's infrastructure, their logging policies, their data retention, and their incident response. With a self-hosted model, the inference happens on your GPU, in your VPC, behind your firewall. The prompt goes in, the response comes out, and the data never crosses a network boundary. This isn't just a compliance checkbox — it's a fundamentally different security posture.
As the Deloitte agentic AI report notes, healthcare organizations operating under strict privacy and data residency rules need sovereign AI approaches to manage regulatory risk while building confidence with patients and regulators.
2. Latency: Local Inference in 200ms vs 2+ Seconds
Cloud API calls carry network round-trip overhead, rate limiting, and shared infrastructure contention. A well-configured local vLLM instance serving Llama 3.1 8B on an A100 delivers first-token latency under 200ms. For clinical workflows — an ambient scribe generating a note in real time, a medication interaction checker running during order entry, a diagnostic suggestion during a patient encounter — that latency difference is the difference between a tool clinicians use and one they abandon.
3. Cost at Scale: Self-Hosted Wins Above 50K Calls/Month
At low volumes, cloud APIs are cheaper. At scale, they're not even close. We'll break down the exact numbers below, but the crossover point sits around 50,000 LLM calls per month — a volume that a single 200-bed hospital generating clinical summaries, discharge notes, and prior authorization drafts will hit within the first quarter of production deployment.
4. No BAA Dependency on Third-Party LLM Providers
BAAs with LLM providers are a relatively new construct. The terms are evolving, the liability caps are often surprisingly low, and the 2026 HIPAA Security Rule updates are tightening requirements around AI-specific data processing. Self-hosting eliminates this entire dependency. You don't need a BAA with your own GPU cluster.
5. Full Audit Control and No Vendor Lock-In
With a self-hosted model, every prompt and response can be logged to your own audit infrastructure — the same SIEM and compliance tooling you already use. You control model versions, rollback policies, and can switch between open-weight models without renegotiating contracts or migrating APIs. Your observability and compliance dashboards get full visibility into every inference.
The Models You Can Self-Host Today
The open-weight model ecosystem has matured dramatically. Here are the models that matter for clinical workloads in 2026:
| Model | Parameters | License | Clinical Benchmark | VRAM Required | Best For |
|---|---|---|---|---|---|
| Llama 3.1 70B | 70B | Meta (open) | ~85% USMLE | 140 GB (FP16) | Clinical reasoning, summarization |
| Llama 3.1 8B | 8B | Meta (open) | ~72% USMLE | 16 GB (FP16) | Fast inference, high-throughput tasks |
| Mistral 7B | 7B | Apache 2.0 | ~70% USMLE | 14 GB | Balanced performance/efficiency |
| Mixtral 8x7B | 46.7B (MoE) | Apache 2.0 | ~82% USMLE | 90 GB | Complex reasoning, multi-step tasks |
| BioMistral 7B | 7B | Apache 2.0 | Competitive on PubMedQA | 14 GB | Clinical NLP, biomedical extraction |
| Med42 70B | 70B | Open (M42) | ~95% USMLE | 140 GB | Medical QA, clinical decision support |
| Phi-3 Medium | 14B | MIT | ~75% USMLE | 28 GB | Edge deployment, resource-constrained |
| Qwen 2.5 72B | 72B | Apache 2.0 | ~83% USMLE | 144 GB | Multilingual clinical workflows |
Key finding: Med42-Llama3.1-70B has emerged as the standout for clinical applications, surpassing base Llama 3.1 70B on five of seven clinical tasks and approaching 95% USMLE accuracy — competitive with GPT-4's reported performance. For organizations that need strong clinical reasoning without cloud dependency, this is the model to evaluate first.
Practical recommendation: Start with Llama 3.1 8B for development and evaluation (runs on a single L4 GPU). Graduate to Med42 70B or Llama 3.1 70B for production clinical workloads. Use BioMistral 7B when you need a lightweight model specifically tuned for biomedical text extraction and NLP tasks.
Infrastructure: Serving Frameworks
Choosing the right serving framework matters as much as choosing the right model. The performance differences are dramatic.
vLLM — The Production Standard
vLLM uses PagedAttention and continuous batching to achieve the highest throughput among open-source serving frameworks. In recent benchmarks, vLLM running Llama 3.1 8B on an RTX 4090 delivered 140 tokens/second for a single user and 800 tokens/second total at 10 concurrent users. At 50 concurrent users, vLLM delivered approximately 6x the total throughput of Ollama with p99 latency under 3 seconds, compared to Ollama's 24.7-second p99. Stripe reported a 73% reduction in inference costs after migrating to vLLM, processing 50 million daily API calls on one-third of their previous GPU fleet.
TGI (HuggingFace Text Generation Inference)
TGI provides solid performance with built-in safety filters and excellent documentation. However, HuggingFace put TGI into maintenance mode in December 2025, now recommending vLLM or SGLang for new deployments. If you're already running TGI in production, it works — but plan your migration path.
Ollama — Development and Testing
Ollama wins on simplicity: one command to install, one command to run a model. It's excellent for local development, model evaluation, and prototyping. But at 65 tokens/second single-user and severe degradation under concurrency, it's not a production serving framework. Use it for your dev/test environments alongside vLLM for production.
TensorRT-LLM (NVIDIA)
Maximum GPU utilization with kernel-level optimizations, but it requires NVIDIA hardware exclusively and has a steeper setup curve. Best for organizations with dedicated GPU ops teams running H100 clusters where squeezing every last token/second matters.
GPU Hardware: Choosing Your Tier
| Tier | GPU | VRAM | Cloud Cost/hr | Monthly (24/7) | Best For |
|---|---|---|---|---|---|
| Dev/Test | NVIDIA L4 | 24 GB | ~$0.80 | ~$580 | 7B-8B models, Ollama, prototyping |
| Production | NVIDIA A100 | 80 GB | ~$2.00 | ~$1,440 | 70B models, vLLM, 50+ concurrent users |
| High-Perf | NVIDIA H100 | 80 GB | ~$3.50 | ~$2,520 | 2x A100 throughput, TensorRT-LLM, critical workloads |
For most health systems starting out: Two A100 80GB GPUs running vLLM give you redundancy, handle 70B-parameter models, and support 100+ concurrent inference requests. Total monthly GPU lease: approximately $2,880. Add ops overhead (monitoring, on-call, updates) and you're looking at $3,000-$4,000/month all-in — the number we'll use in the cost comparison below.
Cost Crossover Analysis: API vs Self-Hosted
This is the analysis that matters. Let's use real 2026 pricing.
Assumptions: Average 1,500 tokens per call (prompt + completion). GPT-4o pricing at $2.50/M input + $10/M output tokens (2026 rates). Self-hosted: 2x A100 80GB lease + ops = ~$3,200/month fixed cost.
| Monthly Calls | Tokens (est.) | Cloud API (GPT-4o) | Self-Hosted (2x A100) | Savings |
|---|---|---|---|---|
| 10,000 | 15M | ~$300 | ~$3,200 | API cheaper by $2,900 |
| 25,000 | 37.5M | ~$750 | ~$3,200 | API cheaper by $2,450 |
| 50,000 | 75M | ~$1,500 | ~$3,200 | API cheaper by $1,700 |
| 100,000 | 150M | ~$3,000 | ~$3,200 | Roughly break-even |
| 250,000 | 375M | ~$7,500 | ~$3,200 | Self-hosted saves $4,300/mo |
| 500,000 | 750M | ~$15,000 | ~$3,200 | Self-hosted saves $11,800/mo |
The real crossover: On pure cost, the break-even is around 100K calls/month. But factor in the compliance value — eliminating BAA dependency, gaining full audit control, removing data sovereignty risk — and the effective crossover drops to around 50K calls/month. A 200-bed hospital generating clinical summaries, prior auth drafts, and discharge notes will reach 50K calls within weeks of production deployment.
Hidden costs to account for: GPU ops engineering time (0.25-0.5 FTE), model update and testing cycles, monitoring infrastructure, and the reality that most self-hosted GPUs run at 30-40% average utilization due to traffic variability. Budget for a 2.5x multiplier on raw GPU costs to get your true all-in number.
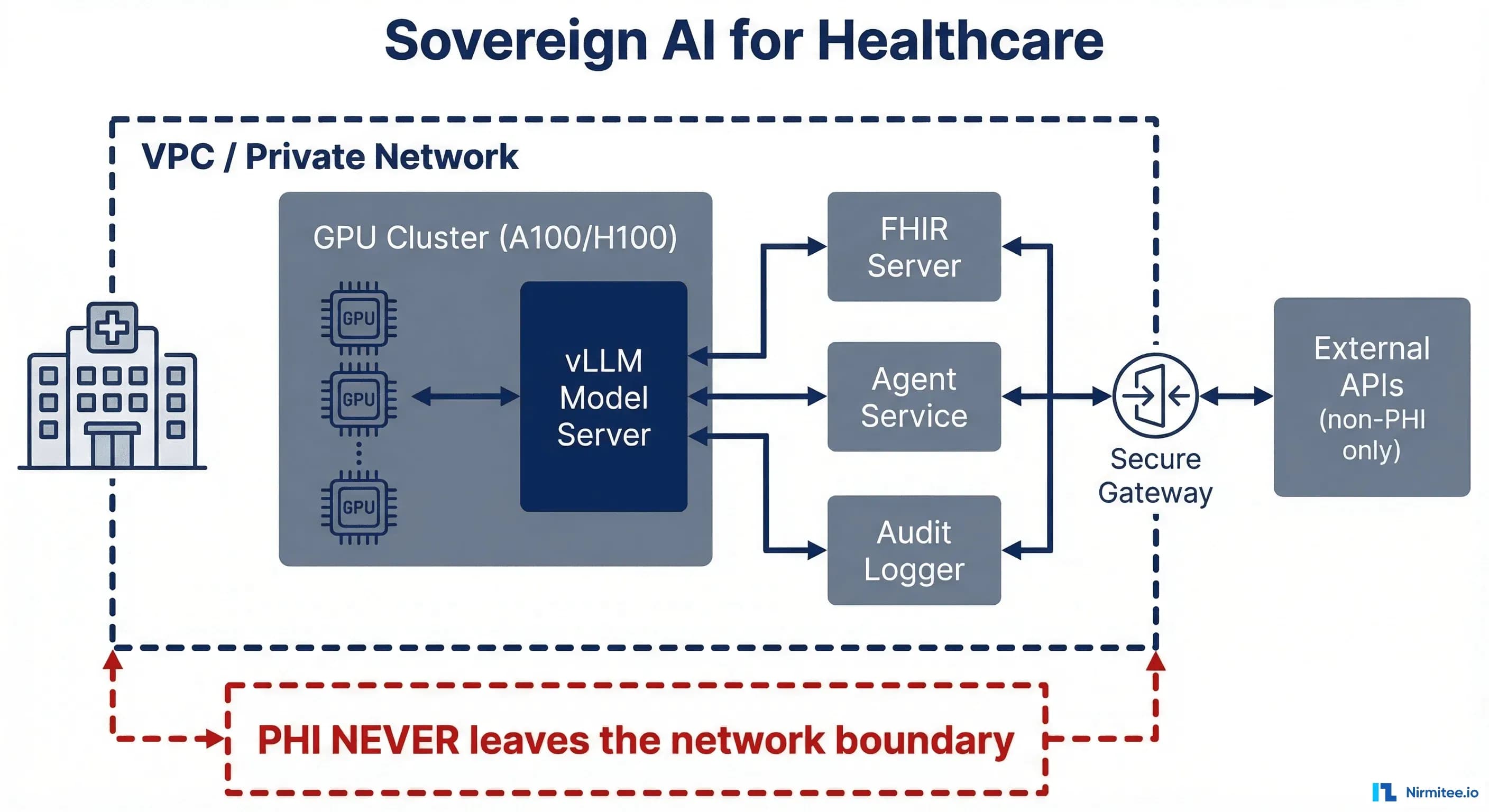
Architecture: VPC-Isolated Deployment
Here's the reference architecture that keeps PHI inside your perimeter while enabling AI-powered clinical workflows:
The Core Pattern
VPC boundary: Everything that touches PHI runs inside a single VPC — your GPU cluster, model serving layer, FHIR server, agent service, and audit logger. No PHI crosses the VPC boundary. Period.
Component layout:
- GPU Cluster (A100/H100): Runs vLLM with your chosen model (Med42 70B, Llama 3.1 70B). Exposed only on internal VPC endpoints.
- Load Balancer: Internal ALB distributes inference requests across GPU instances. Health checks ensure failover.
- FHIR Server: Your EHR integration layer — reads patient data, writes back clinical notes. Same VPC as the model server.
- Agent Service: The orchestration layer that constructs prompts from FHIR data, calls the local model endpoint, parses responses, and applies clinical safety guardrails before writing results back.
- Audit Logger: Every prompt, every response, every model version, every user — logged to your compliance infrastructure. Full chain of custody for every AI-generated clinical artifact.
Network Rules
Security groups enforce that GPU instances accept connections only from the agent service and load balancer. No internet egress from GPU instances. The FHIR server communicates only with the agent service and your EHR. Audit logs stream to your existing SIEM via internal endpoints.
# Example: vLLM serving behind internal load balancer
# GPU instance security group — no internet access
aws ec2 create-security-group --group-name llm-gpu-sg --description "LLM GPU cluster - internal only" --vpc-id vpc-healthcare-prod
# Allow only agent service to reach vLLM (port 8000)
aws ec2 authorize-security-group-ingress --group-id sg-llm-gpu --protocol tcp --port 8000 --source-group sg-agent-service
# vLLM startup with model
python -m vllm.entrypoints.openai.api_server --model m42-health/med42-v2-llama3.1-70b --tensor-parallel-size 2 --host 0.0.0.0 --port 8000 --max-model-len 8192
What You Lose Going Self-Hosted
Intellectual honesty matters. Self-hosting isn't free lunch. Here's what you give up:
- No automatic model updates. When a new model version drops with better clinical performance, you evaluate, test, validate, and deploy it yourself. Budget 2-4 weeks per major model update for testing and evaluation.
- No provider-side safety filters. OpenAI and Anthropic invest heavily in output safety. Self-hosted models come with whatever safety tuning was applied at training time. You need to build your own guardrail layer — content filtering, clinical validation, hallucination detection.
- GPU ops expertise required. Someone on your team needs to understand CUDA versions, driver compatibility, model quantization, memory management, and vLLM configuration. This is a real skill set that's currently in short supply.
- Higher upfront infrastructure cost. Even with cloud GPU leases, you're committing to fixed monthly spend regardless of utilization. API costs scale linearly — you pay only for what you use.
- Slower iteration. Swapping between GPT-4o, Claude, and Gemini via API takes minutes. Downloading, converting, and deploying a new 70B model takes hours.
The Hybrid Approach: Best of Both Worlds
The most pragmatic architecture isn't all-or-nothing. It's a PHI-aware router that classifies requests and routes accordingly:
Self-Hosted Zone (PHI-Touching)
- Clinical note summarization
- Patient data analysis and risk stratification
- Medication reconciliation and interaction checking
- Diagnostic support and differential generation
- Prior authorization narrative drafting
- Discharge summary generation
Cloud API Zone (Non-PHI)
- Patient education content generation
- General medical knowledge Q&A (no patient context)
- Administrative template generation
- Research literature search and summarization
- Staff training material creation
- Policy document drafting
The router sits at the agent service layer. Before any LLM call, it inspects the prompt for PHI indicators — patient identifiers, clinical data, dates of service — and routes to the appropriate backend. PHI-touching requests go to the local vLLM instance. Non-PHI requests go to the cloud API (cheaper, faster iteration, auto-updated models). This gives you the compliance posture of self-hosting where it matters and the convenience of APIs where it doesn't.
Implementation Checklist for CISOs
If you're evaluating this path, here's the decision framework:
- Audit your current LLM usage. How many calls/month? What percentage touch PHI? What's your current API spend?
- Evaluate the 50K threshold. If you're above 50K PHI-touching calls/month (or will be within 6 months), self-hosting has a clear ROI case.
- Start with evaluation. Spin up Ollama on an L4, load Med42 or Llama 3.1 8B, and run your clinical prompts through it. Measure quality against your current cloud provider.
- Architect the VPC. Design the network topology before selecting hardware. The security architecture drives everything.
- Build the eval suite. You need clinical accuracy benchmarks specific to your workflows before going to production. Generic benchmarks won't tell you if the model handles your specialty-specific terminology correctly.
- Plan for hybrid. Don't try to self-host everything on day one. Start with the highest-PHI-risk workloads and expand.
- Budget for ops. 0.25-0.5 FTE of GPU/ML ops engineering. This isn't optional.
Where This Is Headed
The trend is clear. As open-weight models close the quality gap with proprietary APIs — Med42's 95% USMLE score makes that gap paper-thin for clinical use cases — the economic and compliance case for self-hosting becomes overwhelming for any health system processing significant AI volume.
The organizations that build this infrastructure now will have a 12-18 month head start on those still evaluating. They'll have their clinical data pipelines tuned, their eval suites mature, and their operations teams experienced — advantages that compound over time.
Nirmitee helps health systems architect and implement sovereign AI infrastructure — from FHIR-native data pipelines to VPC-isolated model serving to the agent orchestration layer that ties it all together. If you're evaluating on-premise LLM deployment, we'd welcome the conversation.
FAQ: Sovereign AI for Healthcare
Can self-hosted models match GPT-4 quality for clinical tasks?
For specific clinical tasks, yes. Med42-Llama3.1-70B achieves ~95% USMLE accuracy, comparable to GPT-4. The gap is narrower for focused clinical workflows (summarization, extraction, QA) than for open-ended general reasoning.
What's the minimum hardware to run a 70B model in production?
Two NVIDIA A100 80GB GPUs with tensor parallelism via vLLM. This gives you redundancy and handles 50+ concurrent inference requests. Monthly cost: approximately $2,880 for GPU leases alone.
How long does deployment take from decision to production?
Typical timeline: 2-4 weeks for infrastructure setup, 4-6 weeks for model evaluation and clinical validation, 2-4 weeks for integration testing. Plan for 8-14 weeks total, with clinical validation being the longest phase.
Is quantization safe for clinical workloads?
4-bit quantization (GPTQ, AWQ) reduces VRAM requirements by ~75% but can degrade clinical accuracy by 2-5% on benchmarks. For production clinical workloads, we recommend FP16 or BF16 — the accuracy tradeoff isn't worth the hardware savings when patient care is involved.
What about the FDA's stance on self-hosted clinical AI?
The FDA's January 2025 guidance on Predetermined Change Control Plans applies regardless of where the model runs. Self-hosting doesn't exempt you from FDA oversight if your AI tool qualifies as a medical device — but it gives you complete control over model versioning and change management, which actually simplifies PCCP compliance.
Building interoperable healthcare systems is complex. Our Healthcare Interoperability Solutions team has deep experience shipping production integrations. We also offer specialized Agentic AI for Healthcare services. Talk to our team to get started.