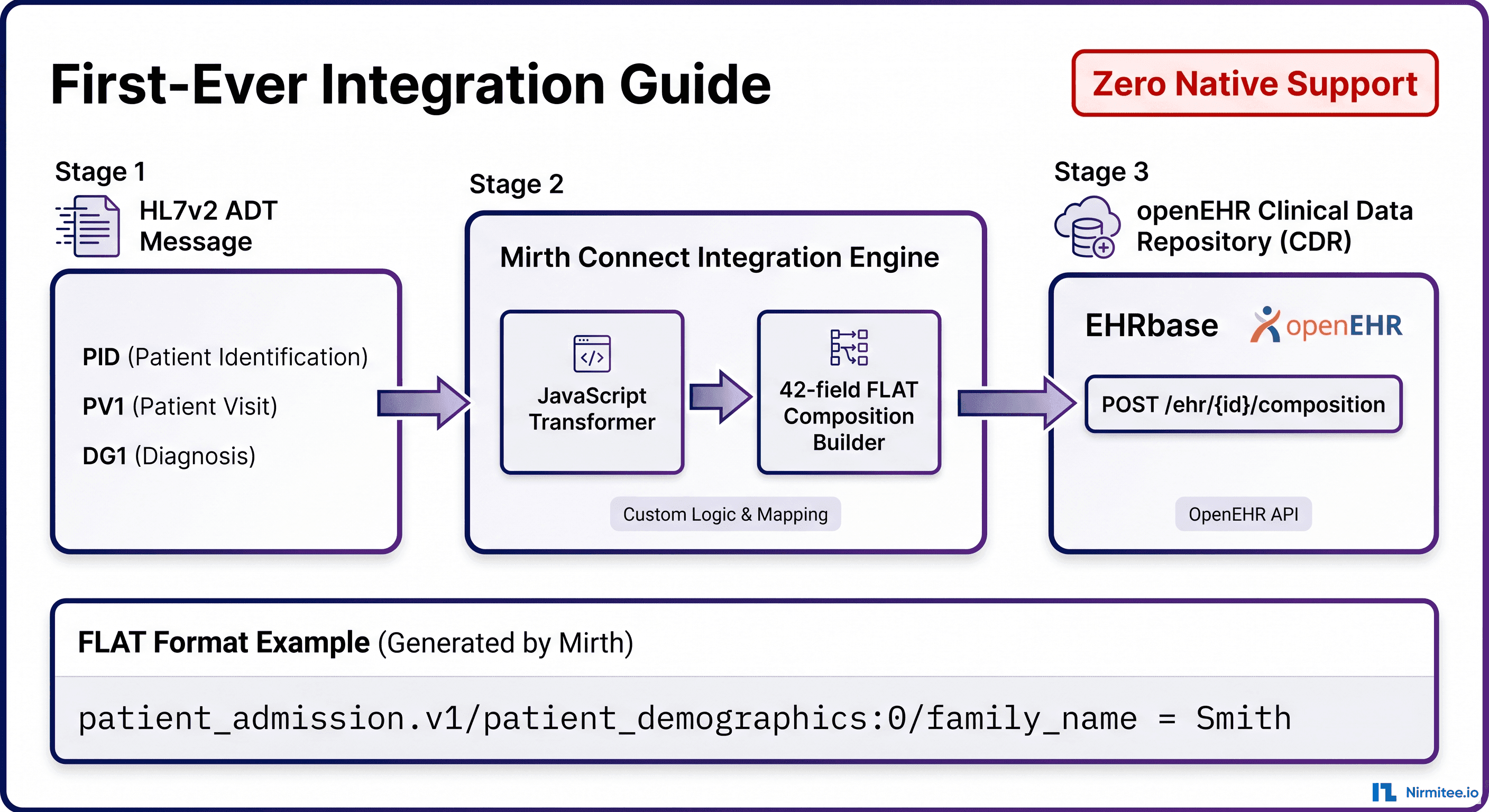
When Mirth Connect is configured well, it's a workhorse. It moves HL7 messages reliably, keeps interfaces stable, and gives engineering teams full control over routing and transformations. But when it's not engineered with the right practices, even a small oversight can break an entire downstream workflow, sometimes without warning.
In hospitals and digital health systems, these failures translate to real operational risks: missing ADT events, delayed results, misrouted orders, duplicate encounters, or stuck queues that no one notices until clinicians start escalating. Most Mirth issues aren't due to the tool being weak; they're due to integrations built without the guardrails of enterprise healthcare demands.
After working across multiple interoperability environments, I've identified the 10 most common Mirth Connect failures and the approaches that prevent them from recurring.
1. Channel Architecture Designed Without Scalability in Mind
One of the quickest ways to create performance issues is by designing channels that try to do everything inside a single flow. When channels become bloated, multiple transformations, routing decisions, conditional handling, processing time spikes, and debugging become painful.
Common mistakes:
- One channel handling several message types
- Business logic is mixed directly into transformers
- Multiple destinations are doing unrelated tasks
- No separation of responsibilities
How to prevent it:
Design channels the way you design software: modular, focused, and predictable. Use separate channels for routing, transformation, and delivery. Keep logic reusable through Global Scripts. A clean architecture makes scaling far easier, especially in high-volume environments.
2. Weak Error Handling and No Message Recovery
Plenty of integration issues start with a simple assumption: the receiving system will always be available. It won't. Systems go down, links break, databases restart, ports get blocked, and acknowledgements fail.
When error handling is missing:
- Messages get dropped
- Queues fill silently
- ADT feeds stop updating EHRs
- Lab results never reach clinical systems
How to prevent it:
Enable message queues on every critical connector. Implement retry intervals. Handle ACK/NACK responses properly. And always maintain a reprocessing flow so failed messages aren't lost; you should be able to replay them safely without manual editing.
3. HL7 Messages Sent Over Unsecured Channels
One of the most serious issues in U.S. healthcare integrations is unsecured HL7 traffic. HL7 v2 is plain text by design; running LLP without encryption means PHI is exposed on the wire.
Common risks:
- TCP listeners without TLS
- Admin console is accessible publicly accessible
- Weak firewall segmentation
- Credentials stored in clear text
How to prevent it:
Secure every channel with TLS. Use VPN or IPSec tunnels for partner systems. Restrict access to the Mirth Admin Console. Apply RBAC. Audit connections regularly.
4. Inefficient or Incorrect HL7 Transformations
Transformers can become a bottleneck when logic is handled inefficiently. Engineers often use heavy loops, unnecessary string operations, or copy/paste scripts that become impossible to maintain. The bigger problem? Incorrect mappings that quietly break workflows.
Typical issues:
- PID, OBR, or OBX values are mapped incorrectly
- Hardcoded fields are causing consistency errors
- Missing segment validation
- Slow JavaScript routines
How to prevent it:
Design transformations systematically. Validate segments before touching them. Use helper functions and Global Scripts to keep mapping consistent. Avoid repeated string parsing inside loops. And always align your mappings with the receiving system's specification sheet.
5. No Monitoring, Alerting, or Visibility Into Channel Health
A Mirth environment without monitoring is a time bomb. Channels will fail, but without monitoring, no one knows until it's too late. This is one of the most common issues in hospital environments.
Symptoms:
- Channels stop processing overnight
- Storage fills up and halts Mirth
- Messages queue indefinitely
- JVM memory hits limits
How to prevent it:
Enable built-in alerts for errors and queue thresholds. Monitor JVM metrics, CPU, disk, and RAM. Integrate logs into ELK, Prometheus, or Grafana if possible. A monitoring dashboard for Mirth is not optional; it's part of running an integration engine safely.
6. Overgrown Message Logs and Database Bloat
By default, Mirth stores messages aggressively. Without cleanup policies, message logs grow into millions of records, and once the database becomes heavy, the entire system slows down.
Common symptoms:
- Slow channel browsing
- Timeout errors
- Sluggish message search
- Database consuming 50 - 100GB+
How to prevent it:
Implement scheduled purging. Archive older messages externally. Move metadata storage to a dedicated database server. Define policies for how long to keep processed messages. A healthy Mirth system does not store everything forever.
7. Incorrect HL7 Mapping or Missing Required Fields
HL7 is flexible, and every vendor implements it differently. A seemingly small mapping error, like missing PID.3 or splitting OBX segments incorrectly, can break downstream workflows in surprising ways.
Common issues:
- Misaligned OBX segments
- Missing MSH metadata
- Wrong patient identifiers
- Incorrect value types or data types
How to prevent it:
Use mapping templates. Test against the receiving system's documentation. Validate message structure before routing. Build transformation logic with strict checks. Always test with real sample messages from the partner system.
8. Limited Testing or Happy Path Only Validation
A surprising number of integrations go live after testing a single message type, usually ADT^A01 or ORU^R01. Real systems produce thousands of variations. Sending only perfect messages through testing leads to fragile integrations.
Real-world failures often come from:
- Unexpected segment orders
- Missing optional fields
- Malformed messages
- High-volume traffic spikes
How to prevent it:
Test across multiple HL7 events, not just one. Perform load testing. Validate ACK/NACK flows. Use malformed messages intentionally to test robustness. The goal is not that it works; the goal is that it doesn't break under real conditions.
9. Manual Deployments and Poor Configuration Governance
Without version control, channel drift becomes inevitable. One engineer updates a channel in production, someone else changes staging, and another edits a transformer manually. Now, no one knows which version is correct.
Problems this creates:
- Channels behave differently across environments
- Rollbacks become difficult
- Debugging takes far longer
How to prevent it:
Treat channels like code. Use Git. Maintain a Dev - QA - Stage - Prod workflow. Export channels into version-controlled repositories. Use CI/CD pipelines where possible. Governance saves hours of troubleshooting every month.
10. Mirth Environment Not Designed for Growth
A single Mirth instance can handle a lot, but not everything. As message volumes rise, especially in hospitals or EHR-to-HIE integration systems begin to choke without proper scaling.
Common bottlenecks:
- One server handling all message types
- JVM memory exhaustion
- No load balancing
- Single-database latency
How to prevent it:
Scale horizontally with multiple Mirth instances. Isolate high-volume interfaces. Use AWS ECS/EKS or Kubernetes. Implement load balancers for demanding workflows. Give Mirth the infrastructure it needs to keep up with enterprise demand.
Conclusion
Most Mirth Connect failures are preventable. They come from taking shortcuts, skipping governance, or assuming HL7 systems will behave perfectly. When you design your channels like software, secure your message flows, monitor everything, and test beyond the happy path, your integration becomes stable, predictable, and easier to scale.
For teams handling mission-critical healthcare data, stability isn't optional. A well-engineered Mirth environment protects patient care, reduces operational friction, and gives your interoperability team confidence even during peak loads.
Related guides
This article is part of our complete guide to Mirth Connect: What Is Mirth Connect? Complete 2026 Guide for Healthcare Leaders. Related deep-dives: