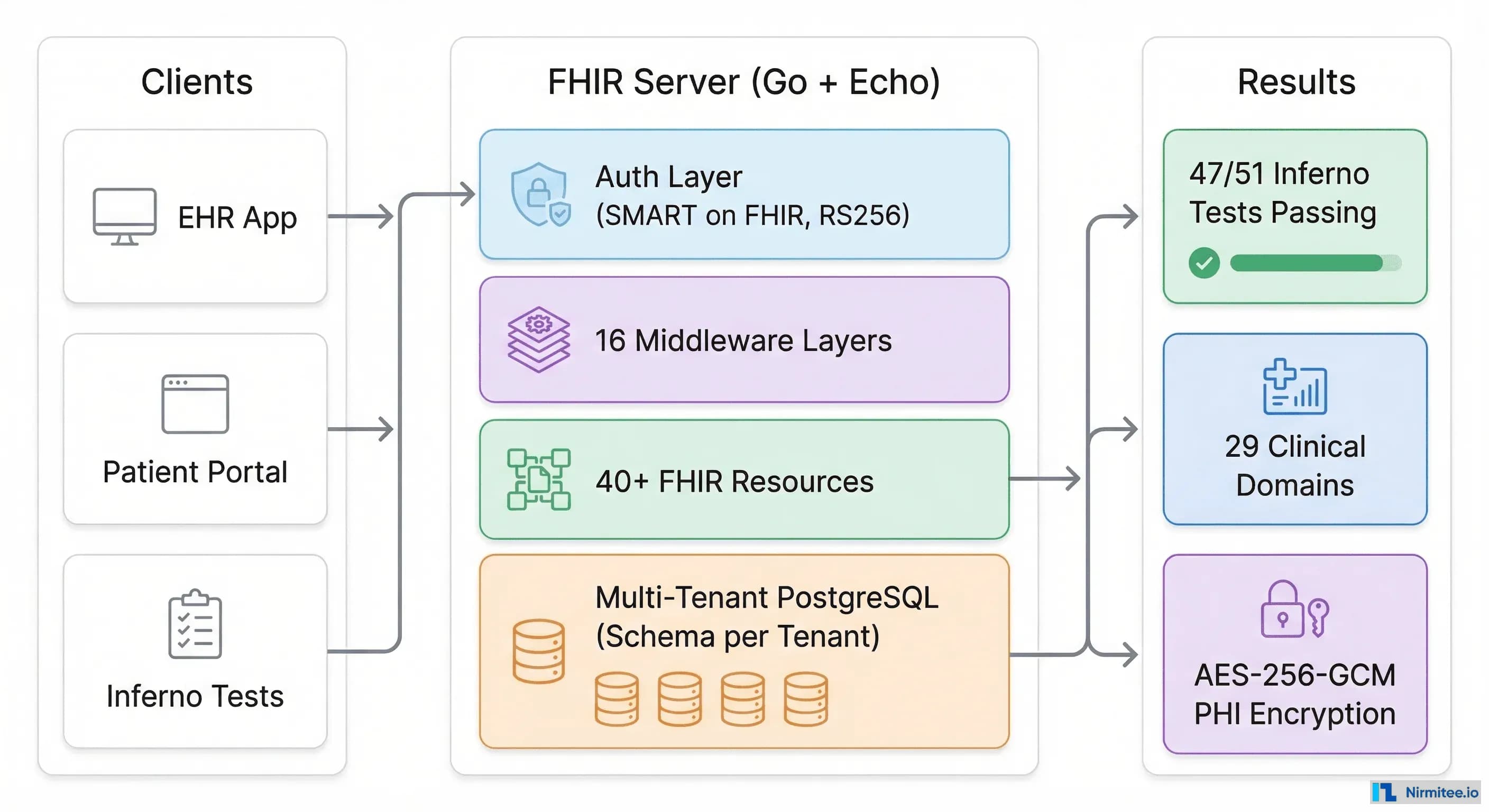
Why We Built Our Own FHIR Server
Every healthcare startup faces the same crossroads: build your own FHIR infrastructure or buy it off the shelf. We chose to build. Not because we wanted to — because we had to.
The off-the-shelf FHIR servers we evaluated fell into two camps: open-source projects that handled the spec but not production realities (multi-tenancy, HIPAA-grade encryption, SMART on FHIR auth), and commercial products that charged per-API-call and locked us into their ecosystem. Neither worked for what we were building — a multi-tenant EHR platform where integration is the product, not a feature.
This is the story of building a FHIR R4 server in Go that passes Inferno testing, supports 40+ FHIR resource types, implements SMART on FHIR standalone launch, and handles multi-tenant data isolation at the PostgreSQL level. Every architectural decision is here — including the ones we got wrong the first time.
The Stack: Go + Echo + PostgreSQL
We chose Go for three reasons that matter in healthcare:
- Single binary deployment. No JVM, no Node runtime, no dependency hell. In healthcare environments where IT teams control the infrastructure, a single binary with zero dependencies is worth its weight in compliance paperwork.
- Concurrency without complexity. FHIR servers handle concurrent requests from EHRs, patient apps, and background sync jobs simultaneously. Go's goroutines and channels handle this natively — no thread pool tuning, no async/await chains.
- Type safety for healthcare data. FHIR resources have strict schemas. Go's type system catches schema violations at compile time, not at 3 AM in production.
For the HTTP framework, we went with Echo — lightweight, fast, and minimalist. Healthcare APIs don't need GraphQL subscriptions or real-time WebSocket magic. They need reliable request/response handling with solid middleware support. Echo delivers exactly that.
PostgreSQL was non-negotiable. Healthcare data needs ACID transactions, row-level security, and the ability to run complex queries across clinical data. We use pgx for connection pooling — max 20, min 5 connections per tenant — which handles the bursty traffic patterns of clinical workflows.
Multi-Tenancy: Schema-Per-Tenant With Row-Level Security
This is where most FHIR server tutorials stop and real-world healthcare begins. A production FHIR server serves multiple organizations — hospitals, clinics, health systems — each with complete data isolation requirements.
We evaluated three approaches:
- Database-per-tenant: Maximum isolation, operational nightmare at scale. Managing 200 PostgreSQL databases means 200 migration runs, 200 backup schedules, 200 connection pools.
- Shared tables with tenant_id column: Simplest to implement, scariest for compliance. One missed WHERE clause and you've got a HIPAA breach.
- Schema-per-tenant (our choice): Each tenant gets their own PostgreSQL schema —
tenant_default,tenant_acme, etc. Tables are identical across schemas. Queries automatically scope to the right tenant.
The implementation uses PostgreSQL session variables for enforcement:
SET search_path = tenant_acme, shared, public;
SET app.current_tenant_id = 'acme';
SET app.current_user_id = 'dr-smith';
SET app.current_user_roles = 'physician';Row-Level Security policies then enforce isolation at the SQL level — even if application code has a bug, PostgreSQL won't return data from the wrong tenant. This is defense-in-depth that compliance officers actually understand.
The tenant middleware resolves the tenant from the request (subdomain, header, or JWT claim) and sets the search path before any query executes. Every downstream handler sees only their tenant's data without writing a single tenant-filtering query.
40+ FHIR Resources: Domain-Driven Design That Scales
Our server implements 40+ FHIR R4 resource types across 29 clinical domains. Here's how we organized it without drowning in code:
Each domain follows a consistent pattern:
internal/domain/clinical/
handler.go — Echo HTTP handlers with RBAC
service.go — Business logic
model.go — Data structures + FHIR mappings
repo.go — Repository interface
repo_pg.go — PostgreSQL implementationEvery FHIR resource gets both a REST API endpoint and a FHIR-compliant endpoint:
// REST API
GET /api/conditions
GET /api/conditions/:id
// FHIR R4 compliant
GET /fhir/Condition
GET /fhir/Condition/:id
GET /fhir/Condition/:id/_history/:vid
POST /fhir/Condition/_searchThe key resources we implemented:
- Identity: Patient, Practitioner, PractitionerRole, Organization, Location
- Clinical: Condition, Observation, AllergyIntolerance, Procedure, ClinicalImpression
- Encounter: Encounter, EpisodeOfCare
- Medication: MedicationRequest, MedicationAdministration, MedicationDispense, MedicationStatement
- Diagnostics: ServiceRequest, DiagnosticReport, ImagingStudy, Specimen
- Scheduling: Appointment, Schedule, Slot
- Billing: Coverage, Claim, ClaimResponse, ExplanationOfBenefit
- Care Management: CarePlan, Goal, CareTeam
- Documents: Consent, DocumentReference, Composition
The CapabilityStatement is built dynamically at startup — as we register each domain's routes, the capability statement automatically includes the resource type, supported search parameters, and available operations. No manual maintenance of a separate capability document.
SMART on FHIR: The Auth Implementation That Took Longer Than Expected
SMART on FHIR authentication was the single most time-consuming part of the build. Not because the spec is complex — it is — but because the spec doesn't tell you about the edge cases that break in practice.
Our server supports three auth modes, selectable by environment:
- Development mode: No auth, admin by default. For local development only.
- Standalone mode: Built-in SMART on FHIR server with RS256 signing. No external IdP needed.
- External mode: Delegates to Keycloak/Auth0 with JWKS caching. For production with existing identity infrastructure.
The standalone mode is where the interesting engineering happened.
RS256 Key Management
We generate a 2048-bit RSA key pair at startup:
rsaKey, err := rsa.GenerateKey(rand.Reader, 2048)The key ID (kid) is derived from the SHA256 hash of the public key modulus — 8 bytes, base64url-encoded. This gives us a deterministic, collision-resistant key ID without maintaining a key registry.
For production persistence, the private key can be provided via the SMART_RSA_KEY environment variable (base64-encoded PKCS#8 PEM). Without this, a server restart generates a new key and invalidates all outstanding tokens. We learned this the hard way during our first multi-day test run.
Manual JWT Signing
We deliberately chose NOT to use the golang-jwt/jwt library. Instead, we implement RS256 signing manually:
// 1. Build header
header := base64url({"alg":"RS256","kid":"...","typ":"JWT"})
// 2. Build payload with claims
payload := base64url({"sub":"patient-123","iss":"http://...",
"scope":"patient/*.read","fhirUser":"Patient/123",...})
// 3. Sign
hash := SHA256(header + "." + payload)
signature := RSA_PKCS1v15_Sign(privateKey, hash)
// 4. Assemble
token := header + "." + payload + "." + base64url(signature)Why manual? Full control over the claims structure. SMART on FHIR has specific claim requirements — fhirUser, patient, launch_state — that don't map cleanly to standard JWT libraries' claim structures. Manual signing means we control exactly what goes into the token.
OIDC Discovery and JWKS
The /.well-known/openid-configuration endpoint publishes all OAuth endpoints and supported capabilities:
{
"authorization_endpoint": "/auth/authorize",
"token_endpoint": "/auth/token",
"jwks_uri": "/auth/jwks",
"scopes_supported": ["launch", "launch/patient", "openid",
"fhirUser", "offline_access", "patient/*.read", "user/*.*"],
"code_challenge_methods_supported": ["S256"],
"capabilities": ["launch-standalone", "client-public",
"client-confidential-symmetric", "sso-openid-connect",
"context-standalone-patient", "permission-offline"]
}The JWKS endpoint serves the RSA public key in JWK format. Inferno — and any SMART client — uses this to verify token signatures without needing the private key.
Passing Inferno: 47 out of 51 Tests
The Inferno Testing Tool is the ONC-recognized test suite for FHIR server compliance. It's the closest thing to a certification exam for FHIR implementations.
We ran the SMART App Launch (Standalone Patient App) test group — the most comprehensive test of FHIR + SMART integration. Results:
- 47 tests passing — all functional tests
- 4 tests failing — all TLS-related (expected in HTTP development mode)
The TLS failures are deliberate. In development, we run over HTTP. In production behind a reverse proxy (nginx/Caddy), TLS termination happens at the proxy level. Inferno's TLS tests check for HTTPS at the application level, which our architecture handles at the infrastructure level. This is a deployment choice, not a code deficiency.
The Tests That Were Hardest to Pass
Token refresh flow: Inferno tests that a refresh token actually returns a new access token with the same scopes. Our initial implementation generated new refresh tokens on each refresh (rotating tokens for security). Inferno expected the original refresh token to remain valid. We added support for both patterns, configurable per client.
OpenID Connect: Inferno validates that the id_token contains the fhirUser claim and that it resolves to a valid FHIR resource. Our first implementation used internal user IDs instead of FHIR resource references. The fix: fhirUser must be a relative reference like Patient/patient-john-smith, not a UUID.
PKCE enforcement: Inferno tests that public clients MUST use PKCE (S256). Our authorization endpoint initially accepted requests without a code challenge from public clients. Adding the enforcement was straightforward — but discovering we needed it required a failed Inferno run.
5-minute OAuth timeout: Inferno has a 5-minute window to complete the OAuth flow. If your auth server requires manual user interaction (login page, consent screen), you need to complete the entire flow within 5 minutes. We automated the patient selection step for test clients to avoid timeout failures.
The Middleware Stack: 16 Layers of Healthcare Reality
Here's our full middleware stack, in execution order:
- Recovery — Panic handling (don't crash the server)
- Security Headers — X-Frame-Options, X-Content-Type-Options
- Input Sanitization — XSS prevention
- Request Timeout — 30-second global timeout
- Request ID — X-Request-ID propagation for tracing
- Structured Logger — zerolog with request context
- CORS — Configurable origins
- Body Limit — 1MB normal, 10MB multipart
- Auth Middleware — Dev/Standalone/External (mode-dependent)
- Tenant Middleware — Schema selection + session variables
- Audit Middleware — FHIR AuditEvent for every write
- Break-Glass — Emergency access override with full logging
- Rate Limit — Per-client, per-endpoint
- FHIR Scope Middleware — SMART scope enforcement
- ABAC Middleware — Attribute-based access control
- Consent Enforcement — Data use consent checking
The order matters. Auth before tenant (you need identity before you can determine tenant). Audit after tenant (audit events need tenant context). Scopes after auth (scopes come from the JWT). ABAC after scopes (ABAC refines what scopes allow). Consent last (consent is the final filter on data access).
One layer deserves special mention: Break-Glass. In emergency clinical scenarios, a physician needs to access patient data outside their normal authorization. The break-glass middleware elevates roles when the X-Break-Glass header is present — but every break-glass access is logged as a FHIR AuditEvent with the reason. Compliance officers can audit every override.
Auth Bridging: Making Three Auth Modes Look Like One
The most elegant architectural decision we made was the auth bridging pattern. Regardless of whether auth comes from our built-in SMART server, an external OIDC provider like Keycloak, or development mode — every downstream handler sees the same context:
// All auth modes set these context values
ctx.Set("user_id", "dr-smith")
ctx.Set("user_roles", []string{"physician"})
ctx.Set("user_scopes", []string{"patient/Patient.read", "user/Observation.*"})
ctx.Set("tenant_id", "acme-hospital")The standalone auth middleware bridges SMART-specific claims to these context values. The role inference logic:
user/*.*orsystem/*.*→ admin roleuser/<Resource>.*→ physician rolepatient/<Resource>.read→ patient role- MedicationRequest/MedicationDispense scopes → pharmacist role
- DiagnosticReport/Observation scopes → lab_tech role
This means domain handlers never need to know which auth mode is active. A Condition handler checks RequireRole("admin", "physician") and it works identically in development, standalone, and external auth modes.
PHI Encryption: AES-256-GCM at the Field Level
HIPAA requires encryption of Protected Health Information. Most implementations encrypt the disk or the database connection. We went further: field-level encryption using AES-256-GCM.
Specific fields — patient names, dates of birth, SSNs, contact information — are encrypted before they hit PostgreSQL. The encryption key is a 256-bit key provided via environment variable, validated at startup. Even if someone gains access to the database directly, PHI fields are encrypted ciphertext.
The trade-off: you can't search encrypted fields with SQL LIKE queries. We handle this with separate search indexes that store hashed (not encrypted) values for exact-match lookups, and cleartext search fields for non-PHI data like medical record numbers.
What We'd Do Differently
No war story is complete without the retrospective:
- FHIR search parameters: We underestimated the complexity of FHIR search. Date ranges, token search, chained parameters, reverse includes — each is its own SQL generation challenge. If starting over, we'd use a dedicated FHIR search library instead of building the query generator from scratch.
- Version history: FHIR requires
_historyendpoints. We generate_historytables automatically per resource. This works but creates a lot of tables. A single history table with JSONB payloads would be simpler to manage. - Test data seeding: Inferno needs real clinical data to test against. We spent days creating seed data for
patient-john-smithwith enough clinical history to satisfy all test assertions. Build your seed data generator early — you'll need it for every test run.
The Numbers
| Metric | Value |
|---|---|
| FHIR resource types | 40+ |
| Clinical domains | 29 |
| Inferno tests passing | 47/51 |
| Middleware layers | 16 |
| Auth modes supported | 3 |
| Language | Go |
| Framework | Echo v4 |
| Database | PostgreSQL (pgx) |
| Encryption | AES-256-GCM (field-level) |
| Multi-tenancy | Schema-per-tenant + RLS |
What This Means For You
If you're evaluating whether to build or buy a FHIR server, here's our honest take after doing it:
Build if: FHIR is your core product, you need full control over the data layer, you have Go/Java engineers who understand healthcare data, and you're prepared for 6-12 months of focused engineering.
Buy if: You need FHIR data access, not FHIR infrastructure. Your product is clinical workflows, patient engagement, or analytics — not the platform itself.
Partner with us if: You need production-grade FHIR infrastructure without the 6-12 month build. We've made these decisions, passed these tests, and learned these lessons. Let's talk about building yours.
Shipping healthcare software that scales requires deep domain expertise. See how our Healthcare Software Product Development practice can accelerate your roadmap. We also offer specialized Healthcare Interoperability Solutions services. Talk to our team to get started.