The Framework Decision That Keeps Healthcare CTOs Up at Night
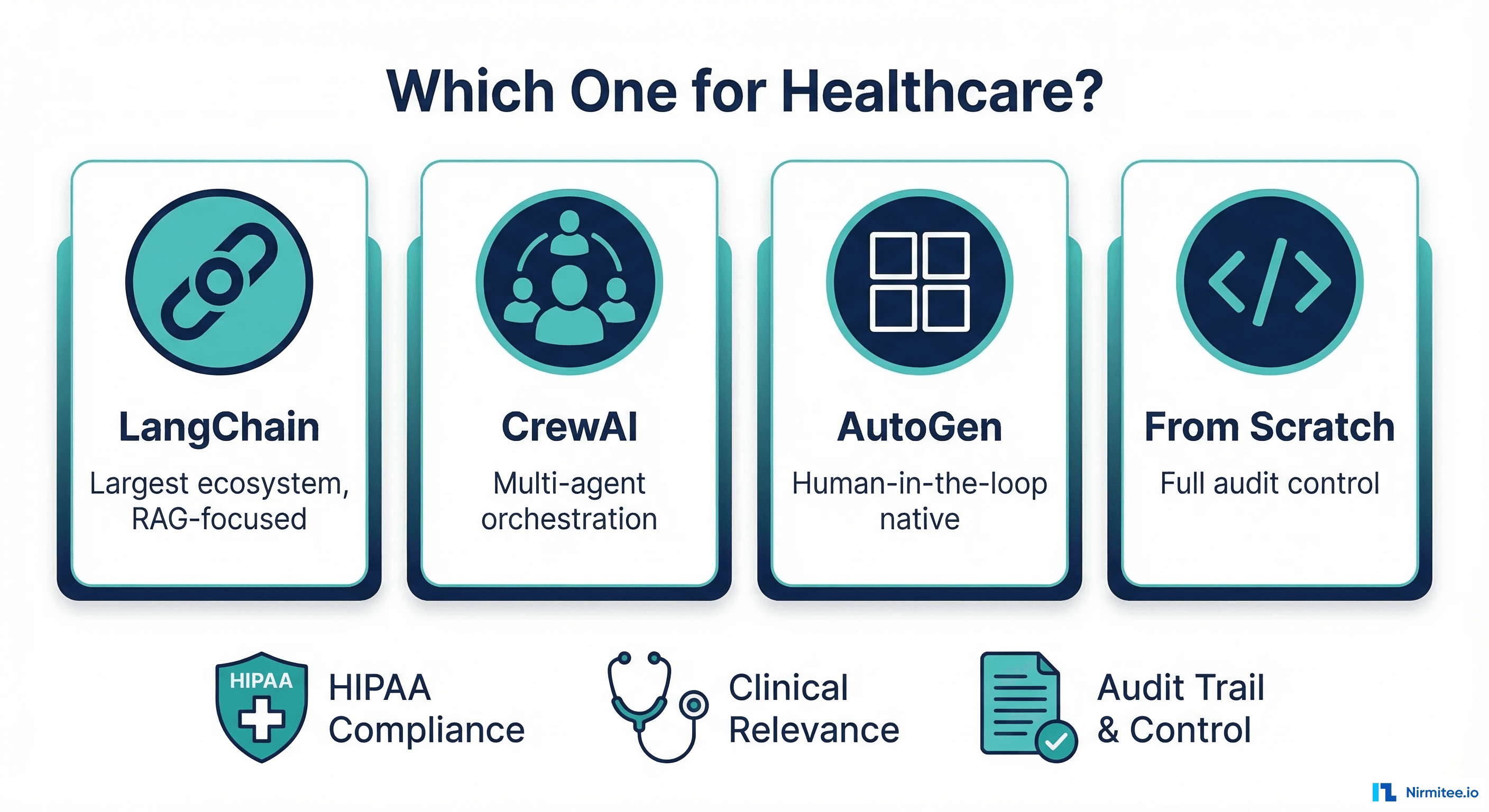
Every engineering team building AI agents for healthcare hits the same crossroads: do you adopt an established framework like LangChain, CrewAI, or AutoGen, or do you build your own orchestration layer from scratch?
In most software domains, this is a matter of preference. In healthcare, it is a compliance decision. The framework you choose determines how you audit every LLM interaction, how you validate outputs before they reach a clinician, how you handle errors when a drug interaction check fails mid-workflow, and whether your deployment can run inside a BAA-covered environment. HIPAA audit requirements for AI agents are not optional add-ons; they are architectural constraints that must be baked in from day one.
This guide is not a generic framework comparison. It is a healthcare-specific evaluation of LangChain/LangGraph, CrewAI, AutoGen, Claude Agent SDK, and building from scratch, measured against the criteria that actually matter in regulated clinical environments.
Why Healthcare Agent Selection Is Fundamentally Different
Before comparing frameworks, you need to understand why generic "best AI framework" articles are almost useless for healthcare engineering teams. The constraints are categorically different.
HIPAA Audit Requirements
Every interaction between your agent and an LLM must be logged with timestamps, user context, patient identifiers (or their absence), input tokens, and output tokens. This is not optional observability; it is a regulatory requirement under the 2026 HIPAA Security Rule updates. If your framework abstracts away the LLM call in a way that makes it difficult to intercept and log, you have a compliance problem.
Deterministic Tool Calling for Clinical Safety
When an agent calls a tool to check drug interactions via RxNorm or query a patient record via FHIR, that tool call must succeed or fail definitively. There is no "retry with a slightly different prompt and hope it works." A failed drug interaction check on warfarin and aspirin cannot be silently swallowed. The framework must surface tool failures as first-class errors, not buried exceptions. Healthcare agent building is an orchestration problem, and your framework's error model is the foundation.
Output Validation Before Display
No LLM output should reach a clinician without passing through a validation layer. This means structured output parsing, schema validation against expected clinical data types, and content safety checks. Your framework needs hooks between "LLM generates response" and "response is displayed to user." Frameworks that treat the LLM response as the final output are dangerous in clinical contexts.
Error Handling That Cannot "Retry and Hope"
In e-commerce, if a recommendation agent fails, you show a fallback. In healthcare, if a prior authorization agent fails mid-workflow, you need to preserve state, notify the appropriate human, and create an audit record of the failure. Your framework's error recovery model matters more than its happy-path performance.
LangChain and LangGraph: The Ecosystem Giant
What It Does Well
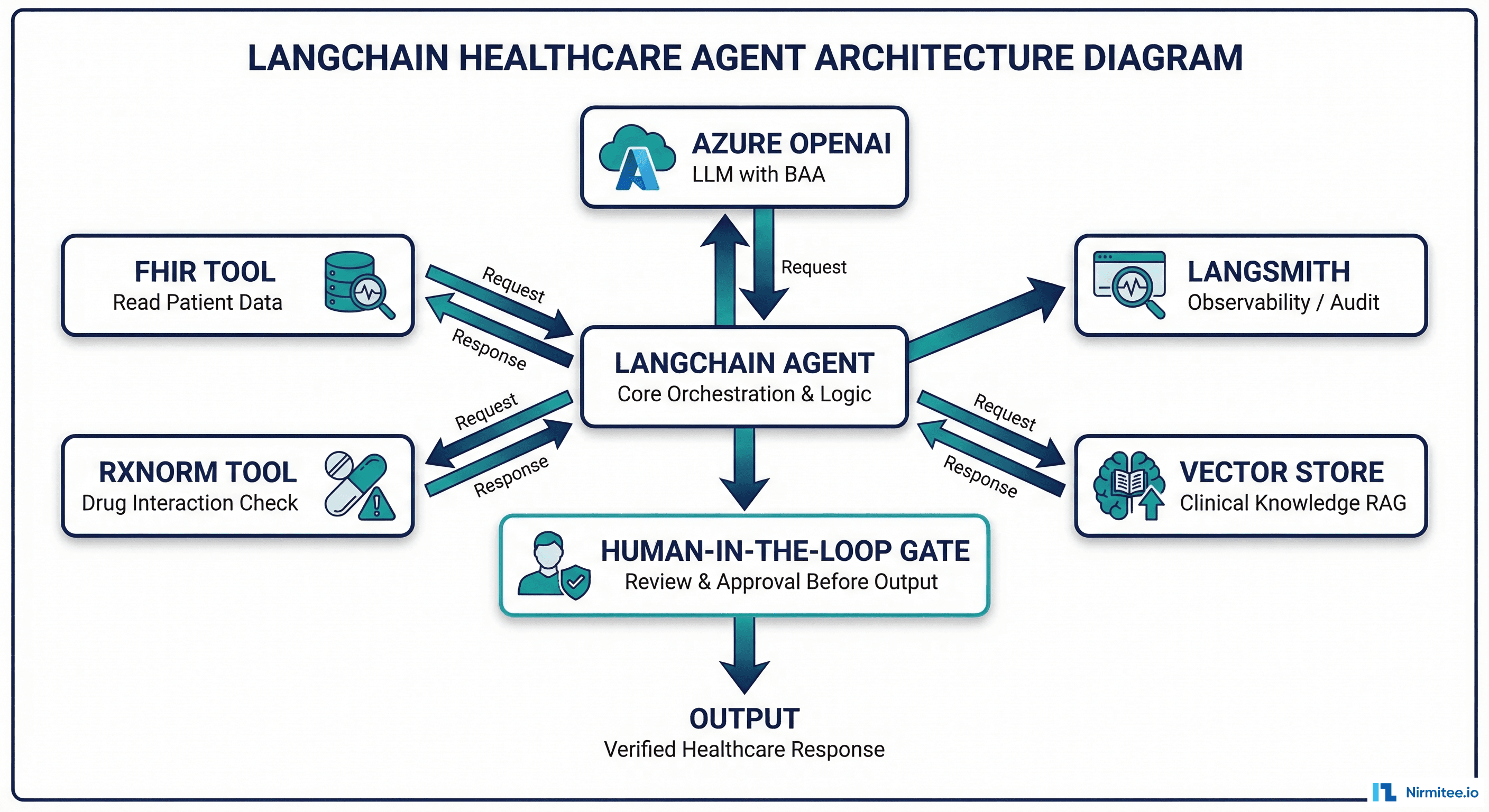
Largest ecosystem by far. LangChain has more tool integrations, more community examples, and more third-party extensions than any other framework. If you need a FHIR client tool, a vector store for clinical guidelines, and an RxNorm API wrapper, someone has probably built it or something close.
LangSmith for observability. LangSmith provides trace-level observability for every chain execution, including token counts, latencies, tool call inputs/outputs, and error traces. For HIPAA audit logging, this is a significant head start. You can self-host LangSmith or use the cloud version with a BAA in place.
LangGraph for stateful workflows. LangGraph extends LangChain with graph-based workflow orchestration, checkpointing, and human-in-the-loop gates. For clinical workflows that need state persistence across sessions (a prior auth that spans multiple days), LangGraph's built-in checkpointing is valuable.
Where It Falls Short for Healthcare
Abstraction complexity. LangChain's abstraction layers (Chains, Agents, Tools, Callbacks, Runnables, LCEL) create a learning curve that slows teams down. When something breaks in production, debugging through five layers of abstraction to find why a FHIR tool call failed is painful. In healthcare, you need to understand exactly what your code is doing at every step.
Rapid API changes. LangChain's API has changed significantly across versions. If you build on v0.1 patterns, you may find them deprecated by v0.3. In regulated environments where you need to validate every change, this velocity is a liability.
Over-engineered for simple agents. If you need a single agent that takes a patient question, retrieves relevant clinical guidelines via RAG, and generates a summarized response, LangChain works but brings enormous dependency weight. You are importing an aircraft carrier to cross a river.
Healthcare Fit
LangChain is strongest for RAG-heavy clinical summarization agents where you need to query large clinical knowledge bases (UpToDate, clinical guidelines, formularies) and synthesize responses. The vector store integrations and retrieval chain patterns are mature. Pair with LangSmith for audit compliance and LangGraph if you need multi-step workflows with checkpointing.
CrewAI: Multi-Agent Orchestration Done Simply
What It Does Well
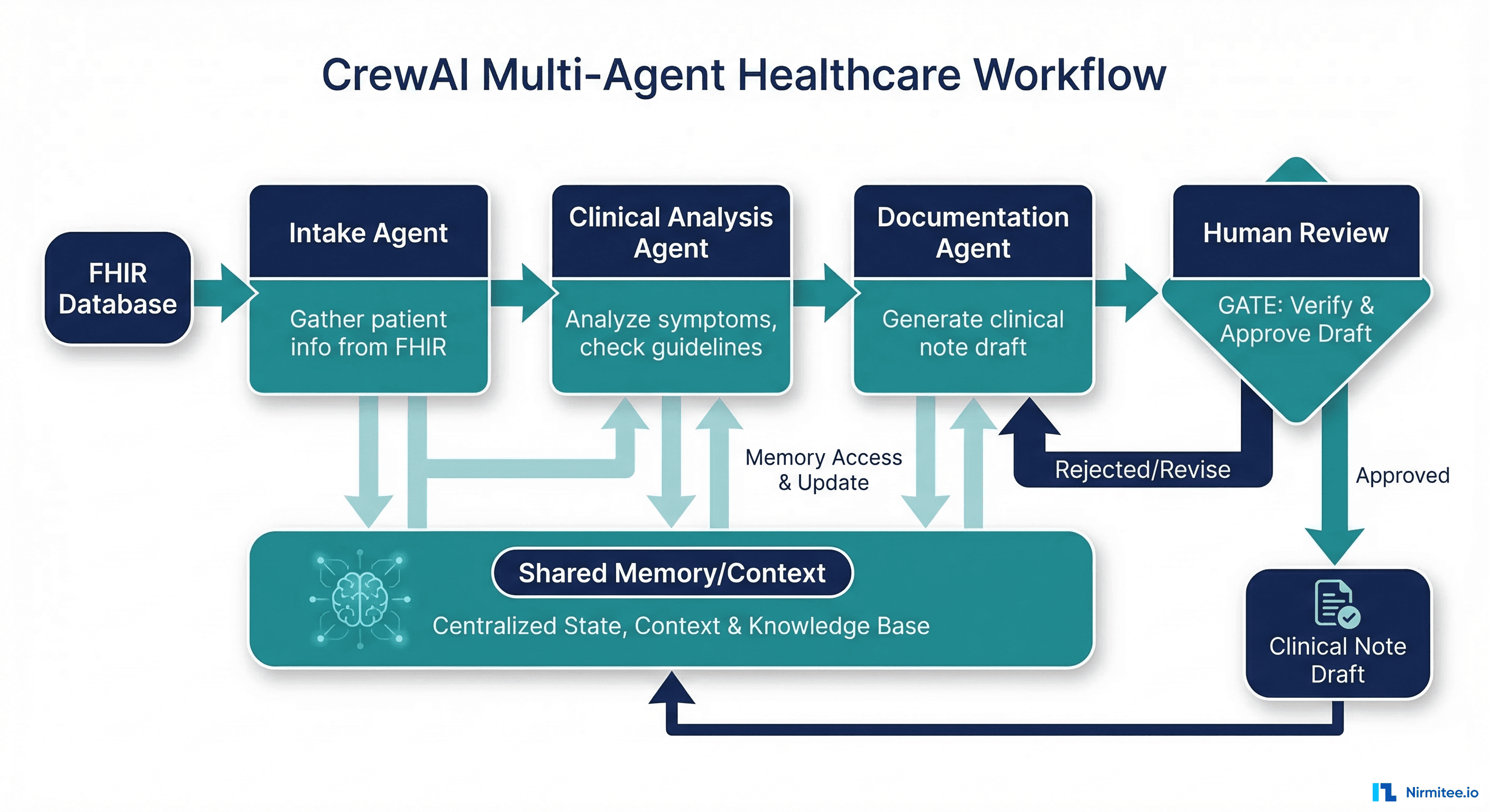
Role-based multi-agent orchestration. CrewAI's core abstraction is agents with defined roles, goals, and backstories working together as a "crew." For healthcare workflows that naturally decompose into specialized roles (intake coordinator, clinical analyst, documentation specialist), this maps cleanly. Each agent has a clear responsibility boundary, which helps with human-in-the-loop review at each stage.
Clean, readable API. CrewAI's API is significantly simpler than LangChain's. Defining an agent, its tools, and its task takes a few lines of clear Python. For healthcare teams where clinicians may need to review agent configurations, readability matters.
Built-in task delegation. Agents can delegate subtasks to other agents, which models real clinical workflows well. A care coordination agent can delegate insurance verification to a specialized eligibility agent while continuing its own workflow.
Where It Falls Short for Healthcare
Less mature ecosystem. CrewAI has fewer tool integrations, fewer production deployments at scale, and a smaller community. Healthcare-specific tooling (FHIR clients, clinical terminology services, drug databases) must be built as custom tools.
Limited observability. CrewAI does not have a LangSmith equivalent. Audit logging must be implemented via custom callbacks or middleware. For HIPAA compliance, this is additional build work.
Newer framework risk. CrewAI is newer than LangChain and AutoGen. API stability, long-term maintenance, and production hardening are less proven. In healthcare, adopting a framework that might change significantly or lose momentum is a risk.
Healthcare Fit
CrewAI excels at multi-step clinical workflows where distinct agent roles map to real healthcare processes. Prior authorization, care coordination, and clinical documentation workflows with 3-5 specialized agents are CrewAI's sweet spot. Budget for building custom audit logging.
AutoGen (Microsoft): Human-in-the-Loop Native
What It Does Well
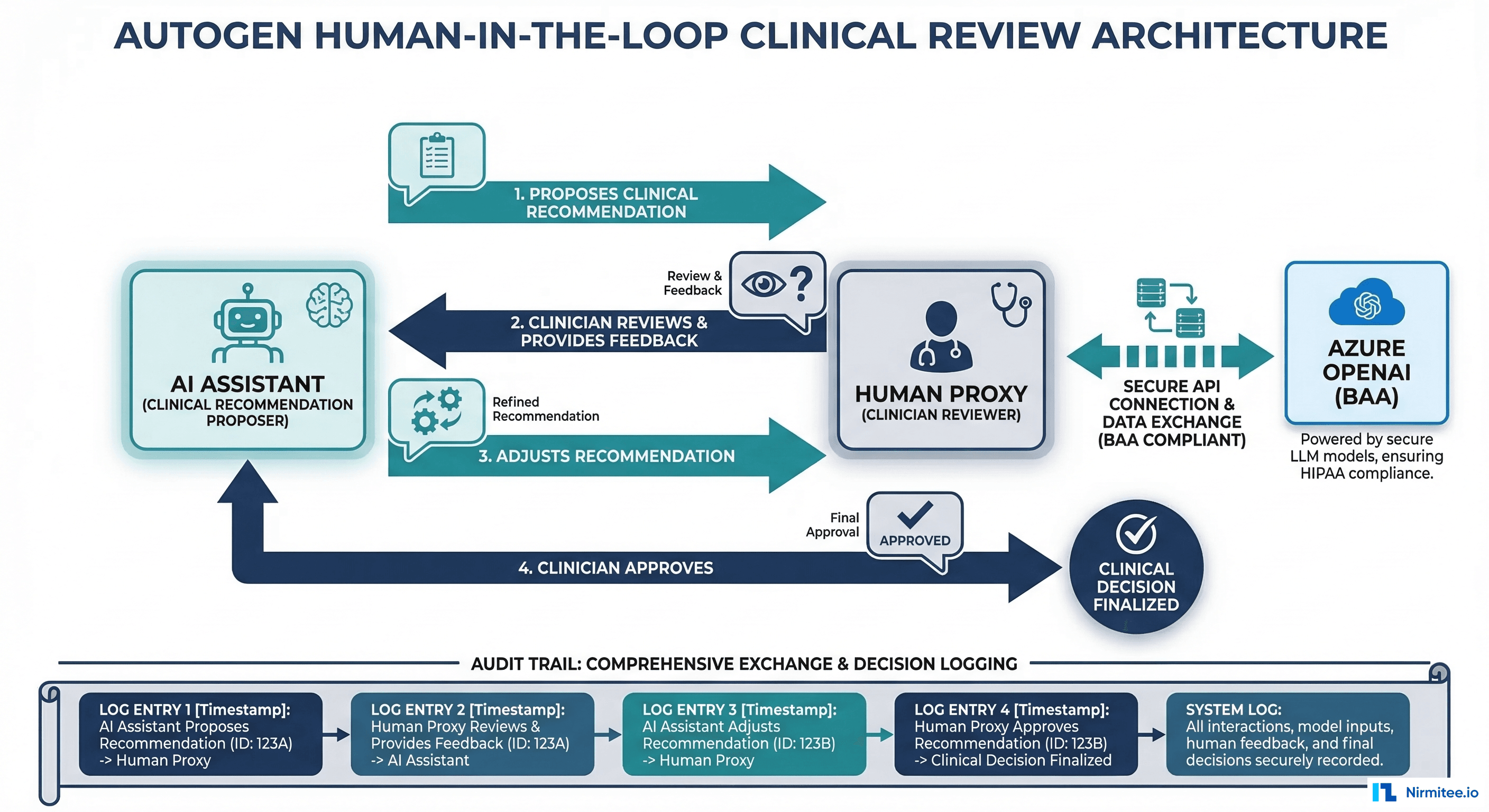
Conversation-based multi-agent architecture. AutoGen models agent interaction as conversations between agents, including a "UserProxy" agent that represents a human. This maps naturally to clinical workflows where an AI assistant proposes and a clinician reviews, adjusts, and approves.
Azure integration and BAA eligibility. AutoGen is a Microsoft project with first-class Azure OpenAI integration. Azure OpenAI offers Business Associate Agreements (BAAs), making it one of the few LLM deployment options that is straightforwardly HIPAA-compliant. If your organization is already in the Microsoft/Azure ecosystem, AutoGen reduces integration friction significantly.
Built-in human-in-the-loop. The UserProxy agent pattern means human review is not bolted on; it is a core architectural concept. For clinical review workflows where every AI recommendation must be approved by a licensed clinician before action, this is exactly the right abstraction.
Where It Falls Short for Healthcare
Microsoft-centric ecosystem. AutoGen works best with Azure OpenAI. Using it with other LLM providers (Anthropic, open-source models) is possible but less smooth. If your organization wants LLM provider flexibility, this is a constraint.
Heavier infrastructure. AutoGen's multi-agent conversation patterns can require more compute and memory than simpler single-agent approaches. For cost-sensitive healthcare deployments, this matters.
Steeper learning curve for simple use cases. If you need a single agent that answers patient questions, AutoGen's conversation-based architecture adds unnecessary complexity. It is designed for multi-agent collaboration, not solo agents.
Healthcare Fit
AutoGen is the strongest choice for human-in-the-loop clinical review workflows where AI proposes and clinicians approve. Radiology report review, clinical decision support with mandatory physician sign-off, and clinical agent MVPs that need built-in approval gates all map cleanly to AutoGen's architecture. Best for organizations already on Azure with BAAs in place.
Claude Agent SDK (Anthropic): Focused Reasoning Power
What It Does Well
Exceptional reasoning for clinical contexts. Claude's extended thinking and strong instruction-following make it particularly effective for clinical agents that need to reason through complex scenarios: differential diagnosis support, medication reconciliation, or interpreting clinical guidelines in context. The Agent SDK provides a clean Python interface for tool use with minimal abstraction overhead.
Simple, direct API. The Claude Agent SDK is intentionally minimal. You define tools, give the agent instructions, and let it reason. There are no chains, runnables, or graph abstractions to learn. For healthcare teams that want transparency into exactly what the agent is doing, this simplicity is a feature.
Strong tool use. Claude's tool calling is reliable and well-structured. When you define a FHIR query tool or drug interaction checker, Claude follows the tool schemas precisely, which matters for deterministic behavior in clinical workflows.
Where It Falls Short for Healthcare
Newer, smaller ecosystem. The Claude Agent SDK has fewer pre-built integrations and community tools compared to LangChain. Healthcare-specific tool libraries must be built in-house.
Single-provider dependency. Using the Claude Agent SDK ties you to Anthropic's API. Unlike framework-agnostic tools (LangChain supports multiple LLMs), switching providers requires more refactoring.
Limited multi-agent patterns. The SDK is designed for focused single-agent use cases. Complex multi-agent orchestration requires custom code on top.
Healthcare Fit
Claude Agent SDK is ideal for focused clinical agents that need strong reasoning: clinical summarization, medication review, guideline interpretation, and patient communication. When the quality of reasoning matters more than multi-agent orchestration, and you want minimal framework overhead, this is a strong choice.
Building From Scratch: Maximum Control for Maximum Compliance
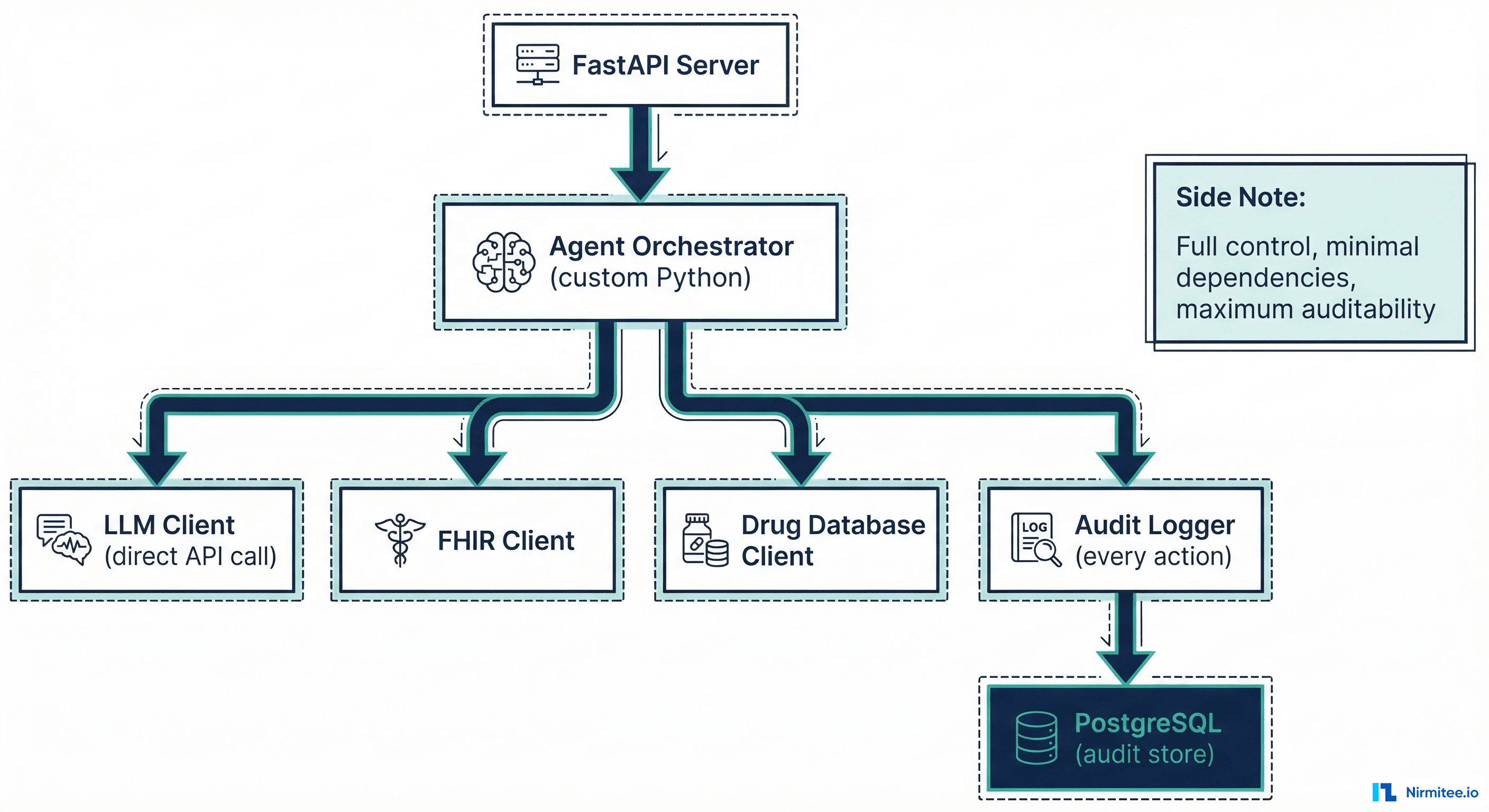
When It Makes Sense
Building from scratch makes sense when you need full audit control over every LLM interaction, minimal dependencies in a regulated environment (every dependency is a security review), and specific security requirements that no framework satisfies out of the box.
The pattern is straightforward: Python + FastAPI + direct LLM API calls + custom tool executor + audit logging at every step. Here is what the core looks like compared to the same agent in LangChain.
Code Comparison: Drug Interaction Check Agent
LangChain version:
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_openai import AzureChatOpenAI
from langchain.tools import tool
from langsmith import traceable
@tool
def check_drug_interaction(drug_a: str, drug_b: str) -> dict:
"""Check interaction between two drugs via RxNorm API."""
response = requests.get(
f"https://rxnav.nlm.nih.gov/REST/interaction/list.json",
params={"rxcuis": f"{get_rxcui(drug_a)}+{get_rxcui(drug_b)}"}
)
return response.json()
llm = AzureChatOpenAI(model="gpt-4o", temperature=0)
agent = create_tool_calling_agent(llm, [check_drug_interaction], prompt)
executor = AgentExecutor(agent=agent, tools=[check_drug_interaction])
# Audit logging handled by LangSmith callback
result = executor.invoke({"input": "Check warfarin and aspirin interaction"})From-scratch version:
import httpx
import json
from datetime import datetime, timezone
async def check_drug_interaction(drug_a: str, drug_b: str) -> dict:
"""Check interaction via RxNorm with explicit error handling."""
async with httpx.AsyncClient(timeout=10.0) as client:
resp = await client.get(
"https://rxnav.nlm.nih.gov/REST/interaction/list.json",
params={"rxcuis": f"{get_rxcui(drug_a)}+{get_rxcui(drug_b)}"}
)
resp.raise_for_status() # Fail loud, not silent
return resp.json()
TOOLS = {"check_drug_interaction": check_drug_interaction}
async def run_agent(user_input: str, patient_id: str):
# 1. Log the request
audit_id = await audit_log("agent_request", {
"input": user_input, "patient_id": patient_id,
"timestamp": datetime.now(timezone.utc).isoformat()
})
# 2. Call LLM with tool definitions
response = await llm_client.chat(
model="claude-sonnet-4-20250514",
messages=[{"role": "user", "content": user_input}],
tools=[TOOL_SCHEMAS["check_drug_interaction"]]
)
# 3. Execute tool calls with individual audit logs
for tool_call in response.tool_calls:
tool_fn = TOOLS[tool_call.name]
try:
result = await tool_fn(**tool_call.arguments)
await audit_log("tool_success", {
"audit_id": audit_id, "tool": tool_call.name,
"args": tool_call.arguments, "result_summary": summarize(result)
})
except Exception as e:
await audit_log("tool_failure", {
"audit_id": audit_id, "tool": tool_call.name,
"error": str(e), "action": "escalate_to_human"
})
return {"status": "error", "escalate": True, "reason": str(e)}
# 4. Validate output before returning
validated = validate_clinical_output(response.content)
await audit_log("agent_response", {
"audit_id": audit_id, "output": validated,
"validation_passed": validated.is_valid
})
return validatedThe from-scratch version is longer but every step is visible: audit logging, error handling, tool execution, output validation. There is no abstraction hiding behavior. For regulated healthcare environments where RPA already failed due to opacity, this transparency is valuable.
The Tradeoff
Building from scratch means you own everything: authentication, rate limiting, retry logic, conversation memory, multi-turn state management, prompt versioning. You also own all the bugs. For a small team, this is significant maintenance burden. For a team with strict compliance requirements and dedicated engineering resources, it is worth it.
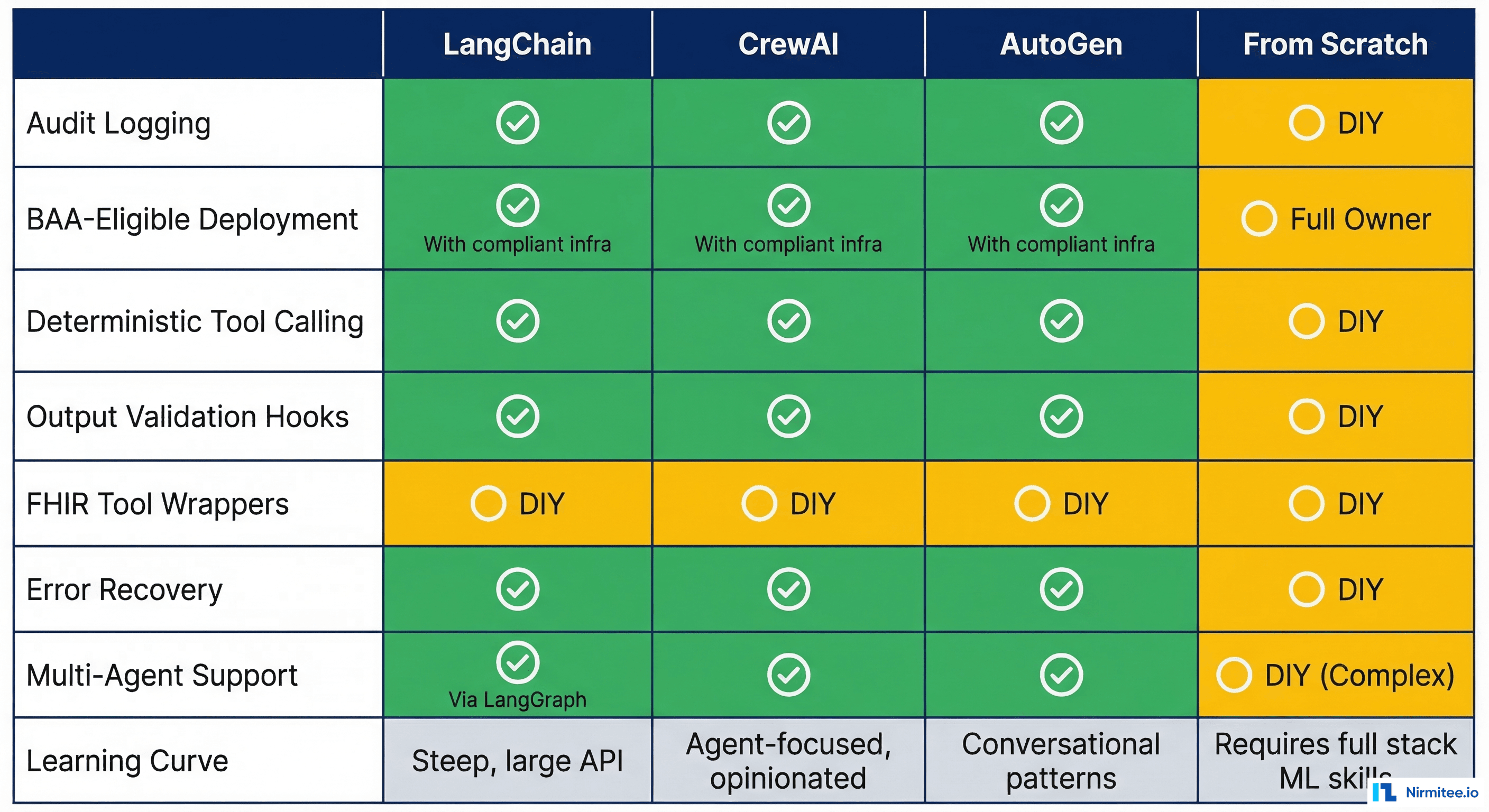
Healthcare-Specific Comparison Table
| Criteria | LangChain | CrewAI | AutoGen | Claude SDK | From Scratch |
|---|---|---|---|---|---|
| Audit Logging | Built-in (LangSmith) | DIY via callbacks | Conversation logs | DIY | Full custom control |
| BAA-Eligible Deploy | Self-host or Azure | Self-host only | Azure native (BAA) | Anthropic API (BAA) | Any cloud (your BAA) |
| Deterministic Tool Calling | Good (structured output) | Good | Good | Excellent | Full control |
| Output Validation Hooks | Callbacks/middleware | Task output parsing | Reply validation | Custom post-process | Full control |
| FHIR Tool Wrappers | Community tools exist | Custom build | Custom build | Custom build | Custom build |
| Error Recovery | Retry/fallback chains | Task retry | Conversation repair | Tool error handling | Full custom control |
| Multi-Agent Support | LangGraph (excellent) | Native (excellent) | Native (excellent) | Limited | Custom build |
| Learning Curve | Steep | Moderate | Moderate-Steep | Low | Low (but maintenance high) |
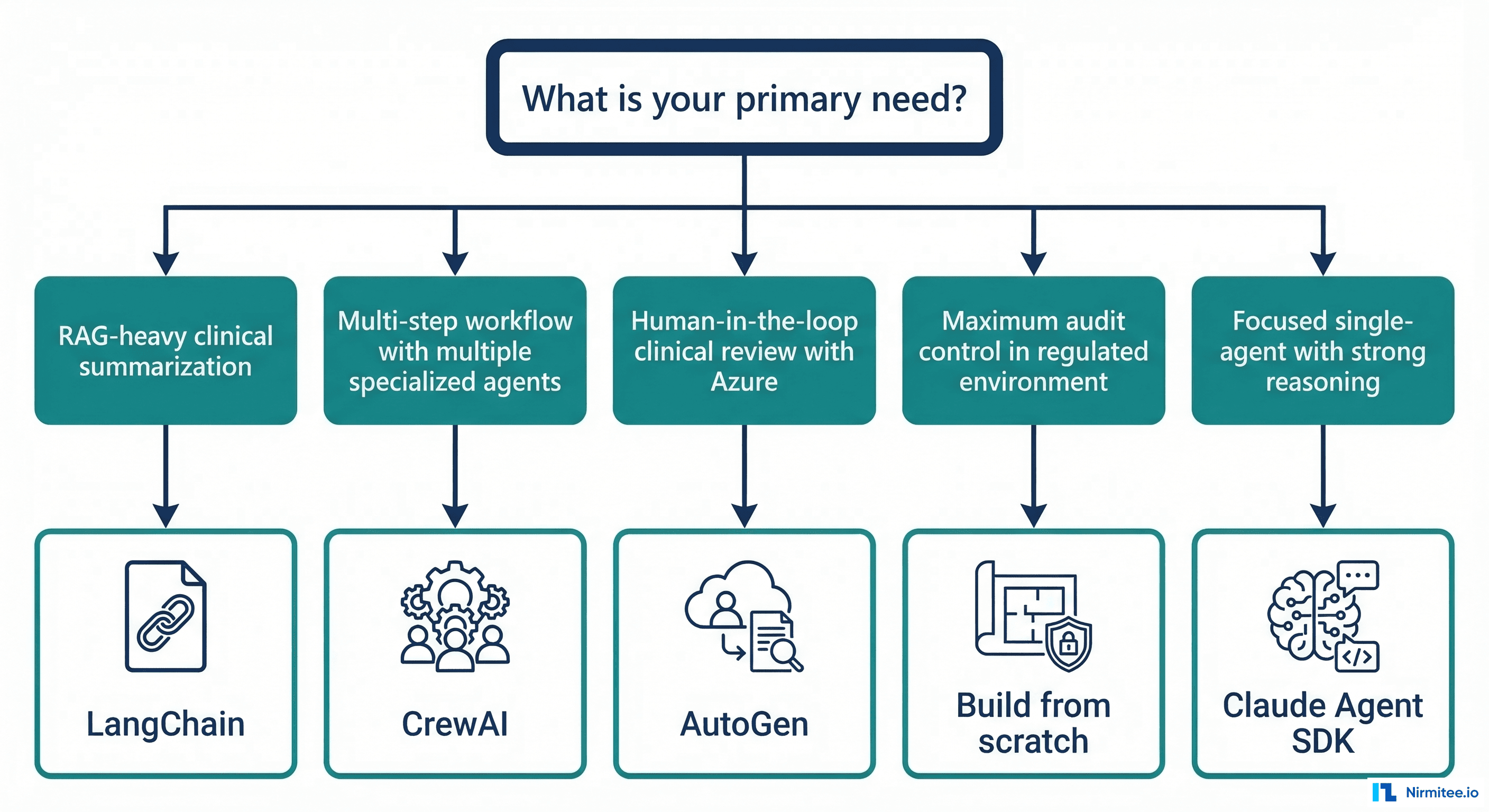
Decision Framework: If You Need X, Choose Y
Use this decision framework to cut through the noise:
If you need RAG-heavy clinical summarization (querying clinical knowledge bases, synthesizing guideline recommendations, patient record summarization): Choose LangChain/LangGraph. The vector store integrations, retrieval chains, and LangSmith observability give you the fastest path to production. Budget for the learning curve.
If you need multi-step workflows with specialized agent roles (prior authorization with intake/verification/approval agents, care coordination across departments): Choose CrewAI. The role-based agent model maps cleanly to healthcare team structures. Budget for building custom audit logging.
If you need human-in-the-loop clinical review with Azure (clinical decision support requiring physician approval, radiology report review, any workflow where AI proposes and humans approve): Choose AutoGen. The UserProxy pattern and Azure integration make this the path of least resistance for organizations already in the Microsoft ecosystem.
If you need a focused single agent with strong clinical reasoning (medication reconciliation, differential diagnosis support, clinical note generation from transcripts): Choose Claude Agent SDK. When reasoning quality matters more than orchestration complexity, Claude's thinking capabilities shine. AI scribes and clinical documentation are a natural fit.
If you need maximum audit control in a highly regulated environment (FDA-regulated clinical software, environments where every dependency requires security review, organizations with custom compliance frameworks): Build from scratch. The Python + FastAPI + direct API pattern gives you full transparency and control. Budget for the maintenance cost.
If you are a startup building your first healthcare agent: Start with Claude Agent SDK or from-scratch for a single focused agent. Do not start with a multi-agent framework until you have proven the value of one agent. Ship one agent on day one, not five in V2.
What We Have Learned Building Healthcare Agents at Nirmitee
At Nirmitee, we have built healthcare agents across FHIR-based data pipelines, clinical AI/ML pipelines, and eligibility verification workflows. Our experience across these projects has taught us a consistent lesson: the framework matters less than the audit architecture around it.
Every framework on this list can be made HIPAA-compliant with enough engineering effort. The real question is how much of that compliance infrastructure comes built-in versus how much you build yourself. LangSmith gives you observability for free. AutoGen gives you human-in-the-loop for free. Building from scratch gives you auditability for free. Nothing gives you everything for free.
Pick the framework that gives you the most important healthcare capability built-in, and build the rest. Then focus your energy on what actually matters: the clinical workflow your agent is automating and the human-in-the-loop design that keeps clinicians in control.
Frequently Asked Questions
Can I use LangChain with HIPAA-compliant infrastructure?
Yes. LangChain itself is a Python library that runs in your infrastructure. Pair it with Azure OpenAI (which offers BAAs) or self-hosted models, self-host LangSmith for audit logging, and ensure your vector stores are in BAA-covered environments. The framework does not inherently violate HIPAA; the deployment architecture determines compliance.
Is AutoGen only for Azure?
No. AutoGen supports multiple LLM providers including OpenAI, Anthropic, and local models. However, its deepest integration and easiest path to BAA-compliant deployment is through Azure OpenAI. Using other providers requires more configuration and you lose some Azure-specific features.
How much does it cost to build from scratch versus using a framework?
Initial development from scratch typically takes 2-3x longer than framework-based development for the same feature set. However, ongoing maintenance is often lower because you have fewer dependencies to update and no framework version migrations to manage. For a single-agent use case, from-scratch may be faster. For multi-agent workflows, frameworks save significant time.
Which framework has the best FHIR integration?
None have production-ready FHIR integrations out of the box. LangChain has community-contributed FHIR tools, but they typically cover basic read operations. For production healthcare agents, plan to build your own SMART on FHIR client as a custom tool regardless of framework choice.
Can I switch frameworks later?
Switching is possible but expensive. Your tool implementations (FHIR clients, drug databases, audit loggers) are portable. Your orchestration logic, prompt templates, and state management are framework-specific. Design your tools as standalone modules from day one to minimize switching costs.