The VP of Innovation at a 12-hospital system in the Southeast showed me a slide deck last October. Page one: their ambient documentation AI pilot across two clinics. 94% physician satisfaction. 62% reduction in after-hours charting. 41 seconds average note generation time. The pilot ran for 90 days. It was, by every metric they tracked, a resounding success.
Page fourteen told a different story. Six months into system-wide deployment: 73% physician satisfaction (dropped 21 points), 38% reduction in charting (down from 62%), and three patient safety near-misses where the AI hallucinated medication dosages that made it into draft notes. The board pulled the plug at month eight.
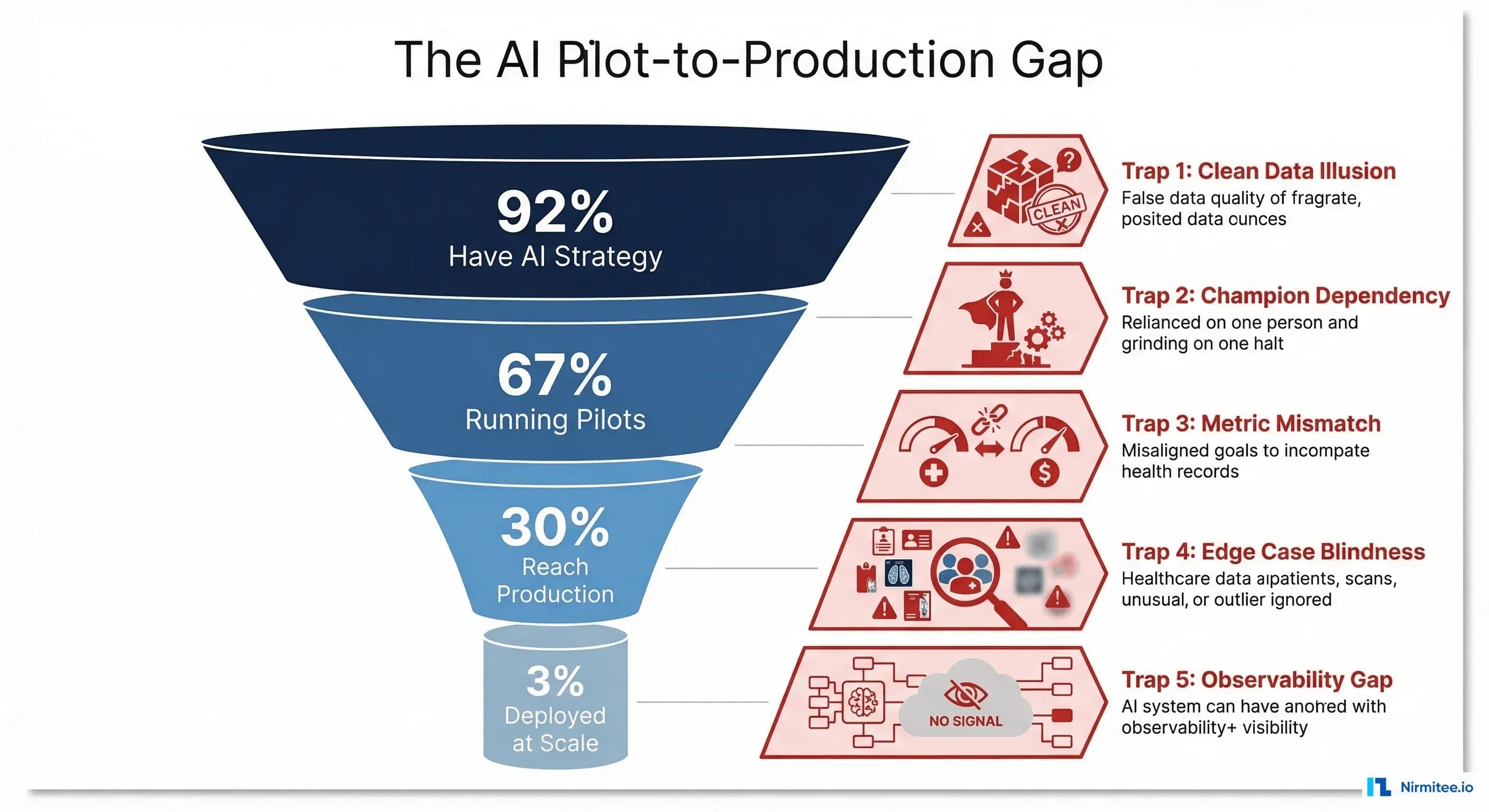
This is not an outlier. According to HealthTech Digital, 80% of healthcare AI projects fail to scale beyond the pilot phase. HIT Consultant declared the AI pilot era officially over in their 2026 predictions—not because pilots are working, but because organizations are finally acknowledging that pilots and production are fundamentally different problems.
Here are the five traps that kill healthcare AI deployments after successful pilots, and the engineering and organizational patterns that prevent each one.
The Numbers: Where Healthcare AI Actually Stands
Before diving into the traps, the landscape context matters. IntuitionLabs reports that 92% of healthcare leaders have prioritized AI, but only 3% have deployed it across more than 50% of their operations. Menlo Ventures found that only 30% of AI pilots in healthcare reach production, held back by data readiness, governance, and organizational capability gaps.
The pattern is consistent across modalities: ambient documentation pilots show 30% in system-wide deployment; clinical decision support tools are at roughly 16% organizational adoption; and only 3% of revenue cycle AI is deployed at scale despite proven ROI in agent-based pipelines.
| AI Category | Running Pilots | Production Deployment | At-Scale (>50%) |
|---|---|---|---|
| Ambient Documentation | 40% | 30% | 12% |
| Clinical Decision Support | 35% | 16% | 6% |
| Revenue Cycle Automation | 28% | 14% | 3% |
| Patient Communication | 42% | 22% | 8% |
| Imaging/Diagnostics | 38% | 20% | 9% |
The gap between "running pilots" and "at-scale" ranges from 3x to 9x. That gap is where the five traps live.
Trap 1: Your Pilot Data Was Clean. Production Data Is Not.
This is the most technically devastating trap, and it hits within the first week of production deployment.
What Happens in the Pilot
Your data science team curates a dataset. They select 5,000-10,000 records from a single department, a single EHR instance, with consistent documentation practices. They clean the data: remove duplicates, normalize date formats, handle missing fields. The model trains on this manicured dataset and achieves 95% accuracy on the holdout set.
What Happens in Production
The model encounters data from four different EHR systems acquired through mergers, each with different customization layers. Date fields come in five formats. Allergy records include both structured codes and free-text entries like "pt states bad rxn to PCN." Lab results from the legacy system use local codes that do not map cleanly to LOINC. 23% of patient records have missing demographic fields that the model assumed would always be present.
A HIT Consultant analysis found that bad data is the primary factor undermining AI implementations in healthcare. A diagnostic AI achieving 95% accuracy on lab datasets might struggle to maintain 70% accuracy when processing real patient data.
The Fix: Data Quality as Infrastructure
Build a data quality layer that sits between your EHR and your AI models. This is not a one-time data cleaning project—it is a permanent piece of infrastructure.
class HealthcareDataQualityPipeline:
def __init__(self, source_systems: list[str]):
self.validators = {
"demographics": DemographicValidator(),
"clinical": ClinicalDataValidator(),
"coding": TerminologyMapper()
}
self.quality_metrics = DataQualityDashboard()
def process_record(self, record: dict, source: str) -> dict:
"""Validate, normalize, and score each record."""
quality_score = 0.0
issues = []
# Normalize date formats across EHR systems
record = self.normalize_dates(record, source)
# Map local codes to standard terminologies
record = self.validators["coding"].map_to_standard(
record, source_system=source
)
# Validate required fields and flag missing data
for domain, validator in self.validators.items():
result = validator.validate(record)
quality_score += result.score
issues.extend(result.issues)
record["_quality_score"] = quality_score / len(self.validators)
record["_quality_issues"] = issues
# Route low-quality records for human review
if record["_quality_score"] < 0.7:
self.quality_metrics.flag_for_review(record)
return recordThe critical difference: pilots filter out bad data. Production systems must handle bad data—gracefully degrade, flag for review, or route to fallback logic. Your model needs a confidence threshold below which it refuses to make a prediction and escalates to a human.
Trap 2: Your Pilot Had a Dedicated Champion. Production Needs Change Management.
Every successful pilot has a champion—the chief medical informatics officer who personally onboarded each physician, the nurse manager who adjusted workflows in real-time, the IT director who provided same-day support for technical issues.
What Happens in the Pilot
Dr. Sarah Chen, the CMIO, personally trained 14 physicians at two pilot clinics. She was available on Slack, adjusted prompts weekly based on feedback, and handled every edge case within hours. Physician adoption hit 94% because Dr. Chen made it her personal mission.
What Happens in Production
Dr. Chen cannot personally train 800 physicians across 12 hospitals. The training gets delegated to the IT training team, who create a 45-minute recorded webinar. Physicians watch it at 2x speed during lunch. When the AI generates an incorrect note, the physician does not know who to contact—the help desk ticket sits in a queue for 72 hours. Adoption drops to 41% within three months.
According to Frontiers in Digital Health, change management, cross-departmental coordination, and user training are the critical factors that determine whether AI tools become part of clinical workflows or become shelfware.
The Fix: Productize the Champion
Turn the champion's behaviors into systems:
- Tiered training program: Super-users (2 per department, 8-hour training) who become local experts; standard users (90-minute hands-on session, not a webinar); and late adopters (paired with super-users for 1:1 sessions)
- Feedback loops with SLAs: Every AI output includes a one-click feedback button. Negative feedback gets triaged within 4 hours, not 72. Weekly digest of top feedback themes goes to the product team
- Workflow integration, not workflow addition: The AI should be embedded in the existing clinical workflow (inside the EHR, not a separate tab). If physicians have to switch windows, adoption will decay
- Clinical governance committee: Monthly review of AI performance, safety events, and clinician feedback. This gives physicians a voice in how the tool evolves, building ownership instead of resentment
Trap 3: Your Pilot Measured Accuracy. Production Needs ROI.
This trap kills deployments at the budget review, not in the clinic.
What Happens in the Pilot
The team reports: 94% accuracy, 95th percentile latency of 1.2 seconds, 87% user satisfaction. The board approves production deployment based on these technical metrics.
What Happens in Production
Six months in, the CFO asks: "What is the return on our $2.4 million investment?" The team scrambles. They can show accuracy metrics, but they cannot draw a line from accuracy to dollars. Did the 62% reduction in charting time translate to more patient visits? Did the coding suggestions actually increase revenue? Did reduced documentation time decrease physician burnout-driven turnover, and if so, by how much?
A Strativera analysis found that organizations using AI business transformation frameworks achieved 3.2x ROI and 30% efficiency gains—but only when they designed for financial measurement from the start, not as an afterthought.
The Fix: Build a Financial Model Before You Build a Model
Define the value equation before the pilot begins. Every healthcare AI deployment should track these four financial levers:
| Financial Lever | Pilot Metric | Production Metric | How to Measure |
|---|---|---|---|
| Revenue increase | Coding accuracy % | Net revenue per encounter delta | Compare coded revenue pre/post per provider |
| Cost reduction | Time saved per task | FTE reallocation or headcount avoidance | Track actual staffing changes, not theoretical time |
| Risk mitigation | Error detection rate | Malpractice claims, safety events, compliance findings | 12-month trailing comparison |
| Throughput improvement | Task completion speed | Patient volume, wait time, bed turnover | Operational metrics from scheduling and ADT systems |
The pilot should be designed to generate the data needed for the production financial model. If your pilot does not track revenue impact, your production deployment will not survive budget season.
Trap 4: Your Pilot Ignored Edge Cases. Production Breaks on Them.
Edge cases are where healthcare AI becomes a patient safety issue.
What Happens in the Pilot
The pilot runs in a general internal medicine clinic. Patients are mostly English-speaking adults with common chronic conditions. The AI handles 95% of encounters smoothly. The 5% that fail are manually handled, and nobody tracks them systematically.
What Happens in Production
Production includes pediatrics (different medication dosing, different normal ranges for every vital sign by age), geriatrics (polypharmacy, atypical presentations), patients with limited English proficiency (the AI's NLP accuracy drops significantly), psychiatric encounters (documentation requires different clinical frameworks), and trauma cases (rapid, non-linear documentation workflows). The 5% edge case rate in the pilot becomes 25% in production because "production" means "all of medicine."
The Fix: Edge Case Engineering
class EdgeCaseRouter:
"""Route encounters through appropriate AI paths based on complexity."""
COMPLEXITY_THRESHOLDS = {
"standard": 0.85, # High confidence - full AI workflow
"assisted": 0.60, # Medium confidence - AI draft + human review
"manual": 0.0 # Low confidence - human primary, AI suggestions
}
def __init__(self):
self.complexity_model = EncounterComplexityClassifier()
self.edge_case_registry = EdgeCaseRegistry()
def route(self, encounter: dict) -> str:
"""Determine AI involvement level for this encounter."""
complexity = self.complexity_model.predict(encounter)
# Check known edge case patterns
known_edge = self.edge_case_registry.match(encounter)
if known_edge:
return known_edge.recommended_route
# Age-based routing
if encounter["patient_age"] < 2 or encounter["patient_age"] > 90:
return "assisted" # Neonatal and extreme geriatric
# Medication count routing (polypharmacy)
if len(encounter.get("active_medications", [])) > 15:
return "assisted"
# Language routing
if encounter.get("preferred_language") != "en":
complexity *= 0.8 # Reduce confidence for non-English
# Standard threshold routing
for level, threshold in self.COMPLEXITY_THRESHOLDS.items():
if complexity >= threshold:
return level
return "manual"The pattern: do not try to make the AI handle everything. Build a routing layer that knows what the AI is good at, what it needs help with, and what it should not touch. Track the "assisted" and "manual" routes—they are your product roadmap for the next 12 months.
Trap 5: Your Pilot Had No Monitoring. Production Needs Observability.
The most insidious trap because its consequences are delayed. The AI degrades slowly, and without monitoring, nobody notices until a safety event or a dramatic performance drop.
What Happens in the Pilot
The team checks the dashboard weekly. Performance looks stable because the pilot is 90 days in a controlled environment. There is no drift because the data distribution does not change much in 90 days at two clinics. There is no monitoring infrastructure because the team is watching it manually.
What Happens in Production
Month 3: A payer changes their coding guidelines. The AI's coding suggestions are now 15% wrong for that payer, but nobody notices because the monitoring only tracks aggregate accuracy. Month 5: A new EHR module is deployed that changes the format of clinical notes. The AI's note quality degrades for 30% of encounters. Month 8: Seasonal flu surge changes the patient mix. The model's predictions drift because the training data underrepresented respiratory illness presentations. Nobody discovers the drift until a physician publishes an angry post on the internal forum.
As research published on arXiv demonstrates, runtime observability in clinical AI systems must include dashboarding for input quality, data and model drift, clinician override rates, and business KPIs with automated rollback triggers.
The Fix: Production Observability Stack
Healthcare AI monitoring requires four layers, each building on OpenTelemetry instrumentation principles:
- Input monitoring: Track data quality scores for every record entering the pipeline. Alert when quality drops below threshold. Data quality is the prerequisite for everything else
- Model performance monitoring: Track accuracy, confidence distributions, and prediction latency by segment (department, payer, encounter type). Use drift detection to catch degradation before clinicians notice
- Clinical impact monitoring: Track clinician override rates (if physicians are overriding the AI 30% of the time, something is wrong), time-to-complete with versus without AI, and safety events
- Business impact monitoring: Track the financial levers from Trap 3—revenue per encounter, cost per transaction, throughput changes. This is what keeps the CFO supportive
Set automated alerts with escalation paths. A 5% drop in accuracy triggers an engineering review. A 10% drop triggers a clinical governance review. A 15% drop triggers automatic rollback to the previous model version. This is the same incident management discipline that clinical systems require.
The Production Readiness Checklist
Before promoting any healthcare AI from pilot to production, every item on this checklist must have a concrete answer—not "we will figure it out later":
- Data pipeline resilience: Can the system handle data from all EHR instances, including legacy systems with non-standard formats?
- Graceful degradation: What happens when the model's confidence is low? Is there a clear fallback to human workflows?
- Change management plan: Who trains each department? What is the support escalation path? How is feedback collected and acted on?
- Financial measurement: Can you show ROI within 6 months? Do you have baseline metrics from before deployment?
- Edge case catalog: Have you documented the known failure modes and built routing for them?
- Monitoring and alerting: Is there a production dashboard with automated alerts for drift, quality degradation, and safety events?
- Rollback procedure: Can you revert to the previous state within minutes if something goes wrong?
- Governance approval: Has the clinical governance committee reviewed and approved the deployment scope, monitoring plan, and incident response protocol?
The Path Forward: From Pilot to Production in 120 Days
The organizations that successfully scale healthcare AI follow a consistent pattern:
- Days 1-30: Deploy data quality infrastructure. Connect all source systems, build normalization pipelines, establish quality baselines. This is unglamorous work that prevents Trap 1
- Days 31-60: Build the monitoring stack. Get observability in place before the model goes live. This prevents Trap 5 and provides the data for Trap 3
- Days 61-90: Phased rollout with edge case routing. Start with the departments closest to the pilot population, expand to adjacent populations, and use the complexity router to manage edge cases (Trap 4)
- Days 91-120: Full deployment with super-user network activated. Change management program running (Trap 2). First ROI report delivered to the CFO (Trap 3)
The key insight: the pilot-to-production transition is not a technology problem. It is an engineering systems problem that requires the same rigor health systems apply to clinical operations. Only 16% of healthcare organizations have system-wide AI governance frameworks. The organizations that build those frameworks are the ones that make it past the pilot.
At Nirmitee, we specialize in taking healthcare AI from pilot to production. We have seen every one of these traps, and we have built the infrastructure, monitoring, and change management frameworks to prevent them. If your pilot succeeded but your deployment is stalling, reach out—we can diagnose which traps you are hitting and build the path to production-scale deployment.
Related reading
For more insights, explore our guides on what AI agents do in healthcare and FHIR in Modern Healthcare.
You may also find value in EHR Software Development Guide and Building a Healthtech App.