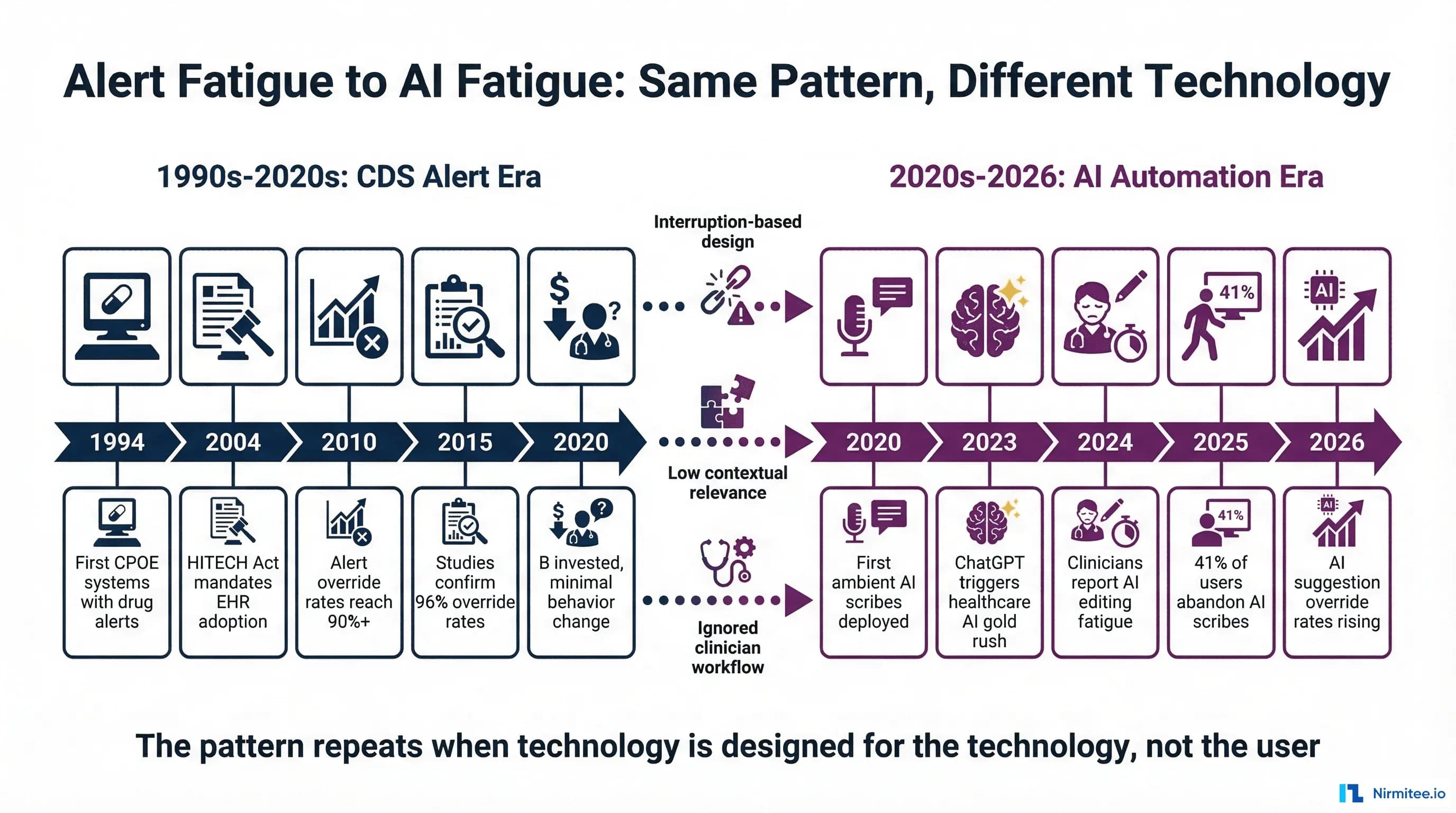
In the early 2000s, hospitals across America invested billions of dollars in clinical decision support systems. The premise was irresistible: computer algorithms would catch dangerous drug interactions, flag allergic reactions, and prevent dosing errors that killed an estimated 7,000 to 9,000 Americans annually. The technology worked exactly as designed. It generated alerts. Thousands of them. Tens of thousands per physician per month.
Then physicians started ignoring them. Not some alerts. Nearly all of them. Study after study documented override rates between 49% and 96%, with most hovering above 90%. The most critical, potentially life-threatening alerts were dismissed in under two seconds. A landmark study published in BMC Medical Informatics found that alert acceptance dropped 30% for each additional reminder per encounter. The technology designed to save lives had become background noise.
Now, three decades later, healthcare is making the same mistake with artificial intelligence. The symptoms are different but the underlying pathology is identical: technology designed for the technology, not for the humans who must use it. Ambient AI scribes generate notes that clinicians spend significant time editing instead of authoring. AI suggestion engines fire recommendations that physicians dismiss without reading. Clinical copilots are abandoned after initial enthusiasm fades.
This is not a coincidence. It is a predictable consequence of the same design errors that created alert fatigue, repeated with a more sophisticated technology stack. Understanding why CDS alerts failed, truly understanding the human factors research, provides the clearest blueprint for ensuring healthcare AI does not follow the same trajectory.
The Alert Fatigue Story: Three Decades of Ignored Warnings (1994-2024)
The Promise (1994-2004)
Computerized physician order entry (CPOE) systems emerged in the mid-1990s as the answer to a genuine patient safety crisis. The 1999 Institute of Medicine report To Err is Human estimated that medical errors caused between 44,000 and 98,000 deaths annually in US hospitals, with medication errors representing the single largest category of preventable harm.
Early CPOE implementations at academic medical centers like Brigham and Women's Hospital, Partners HealthCare, and Vanderbilt University Medical Center showed genuinely promising results. Drug-drug interaction checking caught real errors. Dose-range alerts prevented genuine overdoses. Allergy cross-referencing flagged dangerous prescriptions. The Agency for Healthcare Research and Quality noted that these systems could reduce serious medication errors by up to 55% when properly implemented.
The success was real but narrow. It worked in controlled academic environments with carefully curated alert libraries, close collaboration between informaticists and clinicians, and relatively low alert volumes. What happened next was predictable in retrospect: the technology scaled, but the curation did not.
The Mandate and the Flood (2004-2015)
The HITECH Act of 2009 committed $35.4 billion in incentive payments for electronic health record adoption, with Meaningful Use criteria requiring clinical decision support functionality. By 2015, EHR adoption among non-federal acute care hospitals reached 96%, up from 9.4% in 2008. The mandate was effective. The implementation was catastrophic for alert design.
Commercial EHR vendors, facing regulatory deadlines and customer pressure, implemented broad alert libraries with minimal customization. Drug interaction databases expanded from hundreds to thousands of potential combinations. Alert sensitivity was set to maximum because vendors feared liability for missed alerts more than they feared alert fatigue. The result: physicians in a typical hospital began receiving 50 to 100 alerts per shift, with some specialties seeing over 300.
A systematic review in the Journal of the American Medical Informatics Association documented the consequences: override rates between 49% and 96% across 15 studies, with the vast majority reporting rates above 80%. At Brigham and Women's Hospital, the institution that pioneered CPOE, researchers found that 73.3% of patient allergy, drug-drug interaction, and duplicate drug alerts were overridden. Among specific alert types, duplicate medication alerts were overridden 98% of the time.
The Numbers That Should Have Changed Everything
The research data accumulated over two decades is damning. These are not isolated findings from a single institution. They represent a consistent pattern across hundreds of hospitals, multiple EHR platforms, and thousands of physicians:
- Overall override rates: 49-96% across all alert types, with most studies reporting 80%+ (JMIR systematic review, 2020)
- Drug-drug interaction alerts: Median acceptance rate of 0.0-0.3% in some systems, meaning over 99% were dismissed (BMC Medical Informatics, 2017)
- Best Practice Advisories: Median acceptance rate of 19.4%, declining by 30% for each additional reminder per encounter
- Time-to-override: Most alerts dismissed in under 3 seconds, with critical high-severity alerts dismissed in under 2 seconds
- Repeat alert prevalence: One-quarter of clinical reminders were repeats for the same patient within the same year, and nearly one-third of drug alerts represented within-patient repeats
- Cognitive mechanism: Research confirmed cognitive overload rather than simple desensitization as the primary mechanism. Clinicians did not gradually stop caring. They were overwhelmed from the start.
- Role variation: Nurse practitioners were 4 times as likely to accept drug alerts as physicians in adjusted analyses, suggesting that the alert design was particularly misaligned with physician workflow patterns
The financial investment was enormous. HITECH alone committed $35.4 billion. Hospitals spent additional billions on EHR implementation, customization, and maintenance. Clinical informatics departments dedicated years of effort to alert optimization. And yet, as the AHRQ Patient Safety Network concluded: "Alert fatigue is now recognized as a major unintended consequence of the computerization of health care."
Why Alerts Failed: The Four Design Errors
Alert fatigue was not caused by bad intentions or incompetent engineers. It was caused by four fundamental design errors that prioritized technical correctness over human factors. Understanding these errors is critical because every single one is being repeated in healthcare AI design today.
Error 1: Interruption-Based Architecture
CDS alerts were designed as interruptions. The physician performs an action (ordering a medication), the system detects a potential issue, and a modal dialog blocks the workflow until the physician responds. This model assumes that the alert represents the most important piece of information at that moment, that the physician has the cognitive capacity to evaluate it, and that stopping the workflow is an acceptable cost for safety.
All three assumptions are wrong. Emergency department physicians average 1.4 task switches per minute. In an acute care unit, the rate rises to 1.5 switches per minute. Each interruption requires the physician to context-switch from the current clinical decision, evaluate the alert, decide whether to override, provide a reason, and then resume the original task. The cognitive cost of this context-switching is not zero. It compounds across dozens of alerts per hour.
Error 2: Low Contextual Relevance
The same drug-drug interaction alert fires whether the patient is a 25-year-old healthy adult or an 85-year-old with multiple comorbidities. The same dose-range alert fires whether the physician is a first-year resident or a board-certified specialist who has prescribed this medication 10,000 times. The alert system has no context about the clinical situation, the prescribing physician's expertise, or whether this particular interaction has already been evaluated and accepted for this patient.
The BMC Medical Informatics study found that alert acceptance was not related to general workload (number of patients, encounters per year) but was strongly related to work complexity. BPA acceptance dropped 10% for every 5 percentage point increase in repeated alerts. The system could not distinguish between an alert that conveyed genuinely new information and one that repeated something the clinician already knew and had already decided about.
Error 3: Sensitivity Over Specificity
Alert libraries were calibrated for maximum sensitivity (catching every possible issue) at the expense of specificity (minimizing false positives). This calibration made sense from a liability perspective: if a system fails to alert on a genuine drug interaction that harms a patient, the vendor faces legal exposure. If the system generates 1,000 false alarms for every true positive, that is a workflow problem, not a legal one.
The consequence: as the AHRQ notes, "the vast majority of alerts generated by CPOE systems are clinically inconsequential, meaning that in most cases, clinicians should ignore them." When clinicians learn that most alerts are not actionable, they rationally develop heuristics to dismiss alerts quickly. These heuristics occasionally catch true positives in the dismissal pattern, but the aggregate override rate is a rational response to an irrational signal-to-noise ratio.
Error 4: No Feedback Loop
Perhaps the most damaging design failure: alert systems had no mechanism to learn from overrides. When a physician dismissed an alert 50 times for the same drug combination, the system did not reduce the alert frequency, adjust the severity classification, or route the pattern to an informaticist for review. Every override was treated as an isolated event rather than a data point in a learning system.
The result was a static system in a dynamic environment. As clinical practice evolved, as new evidence emerged, and as physicians gained experience, the alert library remained frozen. The gap between what the system thought was important and what clinicians knew was important widened over time.
History Repeating: AI Tools Showing the Same Patterns
Healthcare AI in 2026 is exhibiting symptoms that are disturbingly familiar to anyone who studied alert fatigue in the 2010s. The technology is different. The human factors are identical.
Ambient AI Scribe Fatigue
Ambient AI scribes represent the most widely deployed healthcare AI technology, with the clinical documentation AI market reaching $600 million in 2025 spending. The technology listens to patient-clinician conversations and generates clinical notes. In theory, this eliminates the documentation burden that consumes 43-52% of a physician's workday.
In practice, the evidence is more complex. A comprehensive review published in PMC found that documentation time savings ranged from just 0.7 to 2.1 minutes per encounter, far less than the marketing claims suggest. More concerning:
- Adoption and abandonment: In a study of 3,442 participants, only 28% used ambient scribes more than 100 times in 10 weeks. In another study, 41% of users stopped or lost privileges due to low utilization. When scribe technology is widely available, actual adoption rates are typically 20-50%.
- Editing burden: Clinicians report spending significant time editing AI-generated documentation instead of authoring it themselves. Optum Advisory partners have documented that providers become editors rather than authors, and the time spent validating AI-generated notes partially offsets the documentation time saved.
- Accuracy concerns: A random sample of 35 AI-generated documents revealed significant errors in clinical documentation accuracy. Speech recognition tools showed nearly twice the error rate for African American speakers, raising both quality and equity concerns.
- Physician perspective: A JAMIA study on clinician perspectives found that physician views on accuracy and style were "largely negative," particularly regarding note length and editing requirements.
The parallel to alert fatigue is precise: a technology deployed at scale, generating outputs that clinicians increasingly dismiss or heavily modify, with adoption rates that plateau well below universal use.
AI Suggestion Overload
Beyond ambient scribes, healthcare organizations are deploying AI across clinical workflows: diagnostic suggestions, treatment recommendations, order sets, coding assistance, prior authorization support. Each system generates its own stream of suggestions, recommendations, and notifications.
A Menlo Ventures analysis found that 22% of healthcare organizations have implemented domain-specific AI tools as of 2025, a 7x increase over 2024. But only 19% of institutions reported a high degree of success for AI used in clinical diagnosis, despite the FDA approving numerous AI-based imaging solutions. More than 80% of AI projects fail across healthcare, squandering billions in resources and eroding trust.
The aggregate effect is a new version of the alert fatigue problem: multiple AI systems, each generating recommendations, each demanding physician attention, each interrupting clinical workflow. The individual systems may be accurate. The aggregate cognitive load is overwhelming.
Clinical Copilot Abandonment
Enterprise AI copilots for healthcare are experiencing the same adoption curve that CDS alerts followed: initial enthusiasm, peak usage, and gradual abandonment. Research on AI and healthcare workforce dynamics found that it is premature to assert that AI tools will reduce physician burnout. If the copilot disrupts workflows or feels intrusive, adoption drops quickly.
The pattern mirrors alert fatigue almost exactly: technology that works in controlled demonstrations fails in the messy reality of clinical practice, where physicians are managing multiple patients, interrupted every 40 seconds, and making thousands of decisions per shift. A tool that adds even a small amount of cognitive overhead to each decision becomes intolerable at the volume of decisions a physician makes daily.
The Cognitive Burden Research: Why More Technology Creates More Problems
The assumption underlying both CDS alerts and healthcare AI is that technology reduces cognitive burden. The research says otherwise.
Before EHR: Paper-Based Practice
In the paper-chart era, physicians spent approximately 55% of their time gazing at patients during encounters and 15% of their day on documentation. Task-switching rates averaged 0.5 per minute in outpatient settings. After-hours documentation was minimal because paper charts stayed at the hospital. The workflow was inefficient by modern standards, but it was human-paced and human-scaled.
After EHR: The Screen-Time Explosion
The American Medical Association documented that physicians now spend 5.8 hours in their EHR for every 8 hours of scheduled patient time. Primary care physicians average 2.7 hours of "pajama time," uncompensated after-hours EHR work that directly correlates with burnout risk. A JMIR systematic review on EHR cognitive load confirmed the scale of the problem:
- Patient gaze time: Dropped from 55% to 45.6% during EHR visits, with 35.2% of physician time spent gazing at medical records instead of the patient
- Documentation time: Now consumes 43-52% of the physician workday
- Task switches: 1.4 per minute on average, rising to 1.5 in acute care settings. Internal medicine interns spent 43% of 24-hour shifts using the EHR, typically in sessions lasting less than 90 seconds before switching tasks
- Click burden: Emergency department physicians perform over 4,000 mouse clicks in a 10-hour shift, or roughly 400 clicks per hour
- Information overload: Each additional hour of documentation burden led to a 7.1% decrease in the likelihood of primary care physicians accessing outside patient records, suggesting that documentation burden crowds out clinical thinking
After AI: The Editing and Validation Tax
AI was supposed to reverse the EHR documentation burden. The early data suggests a more nuanced reality. Clinicians using ambient AI tools spent 8.5% less total time in the EHR than matched controls, with a 15% decrease in time spent composing notes specifically. These are real but modest improvements.
Meanwhile, new forms of cognitive burden are emerging:
- Validation burden: Clinicians are now responsible for reviewing and validating AI-generated notes for accuracy, completeness, and clinical correctness. This is a new task that did not exist in the pre-AI workflow. Physicians report that reviewing someone else's work (even an AI's) requires different cognitive effort than creating their own documentation.
- Error detection fatigue: When AI notes are mostly correct (say 90-95% accurate), clinicians face a detection task similar to alert fatigue: scanning large volumes of mostly correct content for occasional errors. The cognitive science literature on vigilance decrement shows that humans perform poorly at sustained attention tasks with low signal rates, which is exactly what AI note review requires.
- Style mismatch: Physicians develop documentation styles over years of practice that encode clinical reasoning patterns. AI-generated notes often produce different structures, word choices, and reasoning flows. Adapting to the AI's style, or editing every note to match the physician's preferred style, adds cognitive overhead that is rarely measured in time-motion studies.
- Multi-tool switching: With ambient AI, coding AI, clinical decision support, and inbox management AI all running simultaneously, clinicians now manage multiple AI systems, each with its own interface, accuracy profile, and failure modes. The aggregate cognitive cost of managing these tools may exceed the cognitive cost of the tasks they automate.
The Fundamental Design Error: Technology-Centered vs. Workflow-Centered
Both CDS alerts and healthcare AI suffer from the same fundamental design error: they are technology-centered rather than workflow-centered. This distinction, first articulated in human-computer interaction research decades ago, explains why technically impressive systems fail in practice.
Technology-Centered Design (The Pattern That Fails)
Push-based architecture: The system decides when to deliver information, regardless of whether the clinician needs it at that moment. CDS alerts push warnings when orders are placed. AI scribes push generated notes after encounters. AI suggestion engines push recommendations when data is available. In every case, the timing is driven by system events, not clinical need.
Accuracy as the primary metric: Technology-centered design optimizes for technical accuracy. Is the drug interaction real? Is the AI-generated note factually correct? Is the diagnostic suggestion clinically valid? These are necessary conditions, but they are wildly insufficient. An alert can be 100% accurate and 100% useless if the clinician already knows the information, has already evaluated the risk, or is managing a more urgent clinical priority.
One-size-fits-all delivery: The same interface, the same alert format, and the same level of detail are presented regardless of the user's role, specialty, experience level, or current cognitive state. A first-year resident and a 30-year specialist see identical AI outputs. An emergency physician managing a cardiac arrest and a dermatologist conducting a routine skin check receive the same type of interruption.
Workflow-Centered Design (What Actually Works)
Pull-based architecture: Information is available when the clinician needs it, in the location where they are already looking, in the format that matches their current task. Instead of interrupting with a drug interaction alert, the information is visible in the medication review screen where the clinician is already evaluating the patient's medication list. Instead of pushing AI-generated notes for review, the draft is silently available when the clinician opens the documentation interface.
Cognitive fit as the primary metric: Does the system reduce cognitive load or increase it? Does the information appear at the right moment in the clinical workflow? Does the format match the clinician's decision-making process? These questions matter more than raw accuracy because even a perfectly accurate system that adds cognitive burden will be ignored.
Contextual adaptation: The system adjusts its behavior based on the clinical context: patient acuity, clinician experience, time of day, workload level, and whether the information is genuinely new or a repeat of something already evaluated. An alert about a critical drug interaction for a patient with no prior evaluation history is important. The same alert for a patient whose specialist has already documented awareness and acceptance of the interaction risk is noise.
What Actually Works: Design Principles for Healthcare AI That Doesn't Get Ignored
The 30-year history of alert fatigue provides a remarkably clear set of design principles for healthcare AI. These are not theoretical suggestions. They are lessons paid for with billions of dollars of failed investment and decades of clinician frustration.
Principle 1: Contextual Relevance (Only Fire When Meaningful)
The single most important principle: do not deliver information that the user already knows or has already decided about. This requires the AI system to maintain context about what has already been evaluated, what the clinician's decision-making history shows for similar situations, and whether the current piece of information represents genuine novelty.
In practice, this means:
- Track which AI suggestions have been reviewed and accepted or rejected for each clinician
- Suppress repeated suggestions for the same patient-condition combination
- Adjust suggestion frequency based on the clinician's demonstrated expertise in the specific domain
- Present information only when the clinical context has changed in a way that makes the information newly relevant
The BMC Medical Informatics study found that BPA acceptance dropped 30% for each additional alert per encounter and 10% for every 5 percentage point increase in repeated alerts. The lesson is clear: every unnecessary delivery actively degrades the value of necessary ones.
Principle 2: Workflow Integration (Don't Interrupt, Augment)
The most successful healthcare technologies are the ones clinicians do not notice. They enhance existing workflows rather than creating new ones. They provide information in the location where the clinician is already looking rather than demanding a context switch.
Examples of workflow-integrated AI design:
- Passive CDS that works: A PMC study on replacing interruptive alerts with passive CDS showed that replacing a burdensome interruptive alert with passive clinical decision support maintained safety outcomes while dramatically reducing clinician frustration
- Embedded suggestions: AI recommendations displayed within existing EHR workflows (e.g., in-context order suggestions) perform better than pop-up interruptions
- Background processing: AI that completes tasks without requiring clinician interaction (e.g., automatic coding suggestions pre-populated in the billing queue) delivers value without adding cognitive load
Principle 3: Graduated Autonomy (Start Passive, Earn Trust, Increase Automation)
Healthcare AI systems should not launch at maximum automation. They should begin passively, demonstrate reliability, and gradually increase their autonomy as trust is established. This mirrors how human trust develops in clinical environments: a new resident is supervised closely, earns autonomy through demonstrated competence, and eventually operates independently.
The five levels of graduated autonomy:
- Passive: AI observes and learns from clinician behavior. No output is visible to the user. The system builds its model silently and establishes a baseline understanding of clinical patterns.
- Suggestive: AI makes information available on demand. The clinician can pull suggestions when they want them, but nothing is pushed. This level tests whether the AI's outputs are valued when the clinician actively seeks them.
- Assistive: AI pre-populates drafts, suggests orders, or prepares documentation. The clinician reviews and edits everything. This is where most ambient AI scribes currently operate, and where the editing burden becomes the key metric.
- Autonomous with oversight: AI handles routine tasks independently. The clinician reviews exceptions and statistical quality metrics rather than individual outputs. Trust at this level requires demonstrated accuracy above 95% over a sustained period.
- Fully autonomous: AI manages defined scope end-to-end. Human oversight is statistical (audit samples) rather than per-case. This level is appropriate only for well-defined, low-risk tasks where error consequences are manageable.
The critical rule: never skip levels. Organizations that deploy AI at level 3 or 4 without establishing trust at levels 1 and 2 will see the same override and abandonment patterns that plagued CDS alerts. Trust cannot be mandated or shortcut. It must be earned through demonstrated competence in the specific clinical environment.
Principle 4: Feedback Loops (Learn From Overrides and Dismissals)
Every override, every edit, every dismissal is a data point. The most important design decision in healthcare AI is whether the system learns from these signals or ignores them.
CDS alert systems were static. When a physician overrode an alert for the 100th time, the system did not adjust. Modern healthcare AI has the opportunity, and the obligation, to do better:
- Override pattern analysis: When a specific AI suggestion is consistently overridden by experienced clinicians, automatically flag it for informaticist review and reduce its frequency
- Edit pattern learning: When clinicians consistently edit AI-generated notes in the same way (removing a section, restructuring a paragraph, changing terminology), the AI should learn these preferences and adjust future outputs
- Contextual override tracking: Track not just what was overridden, but why and in what context. An AI suggestion that is always overridden in the emergency department but accepted in outpatient settings contains valuable information about workflow differences
- Feedback to development: Aggregate override and edit data should flow back to AI development teams as a continuous improvement signal, not sit in a log file that nobody reads
Principle 5: Cognitive Load Measurement (Track Burden, Not Just Accuracy)
Healthcare AI systems obsessively track accuracy metrics: note quality scores, suggestion acceptance rates, diagnostic sensitivity and specificity. These are important but insufficient. The metric that actually predicts adoption and sustainability is cognitive load.
Organizations deploying healthcare AI should measure:
- Task completion time: Not just whether the AI produced a correct output, but whether using the AI made the overall workflow faster or slower
- Interruption frequency: How many times does the AI demand the clinician's attention per hour? Per patient encounter?
- Context-switching cost: How long does it take clinicians to resume their primary task after interacting with an AI system?
- After-hours work: Is AI actually reducing the pajama-time documentation burden, or shifting it from authoring to editing?
- Net cognitive load: Using adapted versions of the NASA Task Load Index (NASA-TLX) to measure the subjective cognitive burden of clinical work with and without AI tools
Case Studies of AI That Avoided Fatigue
Not all healthcare AI is following the alert fatigue path. Some implementations have successfully avoided the fatigue cycle by adhering to the design principles above. Their common thread: they were designed around clinician workflow, not around the AI capability.
Case 1: Passive Clinical Decision Support
Research published in PMC on addressing alert fatigue documented a successful transition from interruptive CDS alerts to passive clinical decision support. The study replaced a burdensome pop-up alert with contextual information displayed within the existing EHR workflow. The result: clinical outcomes were maintained while alert burden was eliminated for that specific use case. The system did not demand attention. It made information available when the clinician looked for it.
Case 2: Workflow-Embedded AI at Scale
Organizations like Microsoft Dragon Copilot, which reports over 100,000 active clinicians, achieved scale not through superior accuracy alone but through deep workflow embedding. The system operates within the EHR interface rather than requiring a separate application. It processes in the background and presents results where the clinician is already working. The 100,000-clinician adoption figure reflects a design philosophy that prioritizes minimal cognitive overhead.
Case 3: Graduated Autonomy in Practice
At St. Luke's Health System, ambient AI implementation followed a graduated approach: initial passive observation, then draft generation with mandatory review, then reduced review for high-confidence outputs. The result: physicians reported a 35% decrease in time spent documenting after hours and a 15% increase in face time with patients. The key: the system earned trust incrementally rather than demanding it at launch.
Case 4: Safety-Focused Agentic AI
Hippocratic AI, with 115 million clinical patient interactions and zero reported safety issues, demonstrates that AI agents can operate at scale in healthcare without creating fatigue patterns. Their approach: narrow scope (specific patient communication tasks), clear boundaries (no clinical decision-making), and continuous safety monitoring. The system does not interrupt clinicians. It handles delegated tasks autonomously within defined guardrails.
A Framework for Measuring AI Adoption vs. AI Fatigue
Most organizations measure AI success through adoption rates and accuracy metrics. These are necessary but insufficient. An 80% adoption rate with a 60% override rate indicates a system heading toward fatigue, not a successful implementation. Organizations need a comprehensive measurement framework that distinguishes healthy adoption from impending fatigue.
The Six Metrics That Matter
1. Active Usage Rate (target: above 70%)
What percentage of licensed clinicians use the AI system daily? This measures basic adoption but does not distinguish between engaged use and obligatory use. Track this alongside other metrics, never in isolation.
2. Override/Edit Rate (target: below 30%)
What percentage of AI outputs are modified, overridden, or dismissed? This is the most direct analog to the CDS alert override rate. If this number exceeds 50%, the system is heading toward the same fatigue pattern that plagued alerts. If it exceeds 80%, fatigue has already set in.
3. Time-to-Override (warning sign: below 2 seconds)
How quickly are clinicians dismissing AI suggestions? Rapid dismissals (under 2-3 seconds) indicate that clinicians have developed automatic override heuristics, exactly the behavior that defined alert fatigue. This is the earliest warning signal available.
4. Cognitive Load Index (target: below 5 on adapted NASA-TLX)
Self-reported cognitive burden using validated instruments. This captures subjective experience that objective metrics miss. A system can have excellent accuracy and acceptable override rates while still feeling burdensome to clinicians.
5. Workflow Disruption Score (target: below 2 on a 5-point scale)
How frequently does the AI system interfere with clinical workflow? This measures the interruption-based design failure directly. Score above 3 indicates the system is operating in technology-centered rather than workflow-centered mode.
6. Net Promoter Score (target: above +30)
Would clinicians recommend this AI tool to peers? NPS captures the aggregate experience in a single metric. A positive NPS suggests the system is adding value that outweighs its burden. A negative NPS indicates the system is perceived as a net negative despite any objective benefits.
The Fatigue Risk Matrix
Plot Active Usage Rate against Override/Edit Rate to identify which quadrant your AI system occupies:
- High Use + Low Override = Healthy Adoption. Clinicians are actively using the system and finding its outputs valuable. This is the goal state. Maintain it by continuing to learn from the remaining overrides and edits.
- High Use + High Override = Alert Fatigue Risk. Clinicians are using the system (possibly because it is mandatory) but routinely dismissing its outputs. This is the CDS alert pattern. Immediate intervention needed: reduce output volume, increase contextual relevance, transition from push to pull architecture.
- Low Use + Low Override = Low Engagement. Clinicians have neither adopted nor rejected the system. They are simply not using it. This may indicate insufficient training, poor workflow integration, or a solution in search of a problem.
- Low Use + High Override = Abandonment Risk. The clinicians who still use the system override most of its outputs. The rest have already stopped using it. This is late-stage fatigue. The system needs fundamental redesign, not incremental improvement.
The Path Forward: Building Healthcare AI for Humans
The history of alert fatigue is a cautionary tale, but it does not have to be a prophecy. Healthcare AI has advantages that CDS alerts never had: the ability to learn from feedback, the ability to adapt to individual users, and the ability to operate in the background without interruption. But these advantages are only realized when the design philosophy prioritizes human factors over technical capability.
The organizations that will succeed with healthcare AI in 2026 and beyond are the ones that ask the right question first. Not "what can our AI do?" but "what does our clinician need, and when, and where, and how?" The observability framework for agentic AI in healthcare must include fatigue metrics alongside performance metrics. The decision about when not to use AI is as important as the decision about when to deploy it.
Alert fatigue cost healthcare billions of dollars and decades of clinician trust. AI fatigue does not have to follow the same trajectory. But only if we remember the lessons that were already paid for, in full, with the previous generation of healthcare technology.
The choice is not between AI and no AI. It is between AI designed for the technology and AI designed for the humans who use it. We already know which approach works. The question is whether healthcare will choose to remember.