Why Healthcare ML Needs a Different CI/CD Pipeline
Standard software CI/CD pipelines test code, build artifacts, and deploy to production. Healthcare ML pipelines must do all of that plus validate data quality, check for distribution drift, verify model accuracy against clinical thresholds, audit for bias across demographic groups, obtain human clinical approval, and orchestrate staged rollouts that can be instantly reverted if patient safety metrics degrade. The cost of deploying a broken healthcare ML model is not a 500 error—it is a missed diagnosis, a wrong treatment recommendation, or a patient safety event.
The FDA's Software as a Medical Device (SaMD) guidance and the EU AI Act both require documented, reproducible processes for developing and deploying clinical AI. A well-designed CI/CD pipeline provides that documentation automatically: every code change is tracked in version control, every model training run is logged with hyperparameters and data versions, every validation result is recorded, and every deployment decision has an audit trail. This guide walks through building a complete healthcare ML CI/CD pipeline using GitHub Actions, with real workflow YAML you can adapt for your organization.
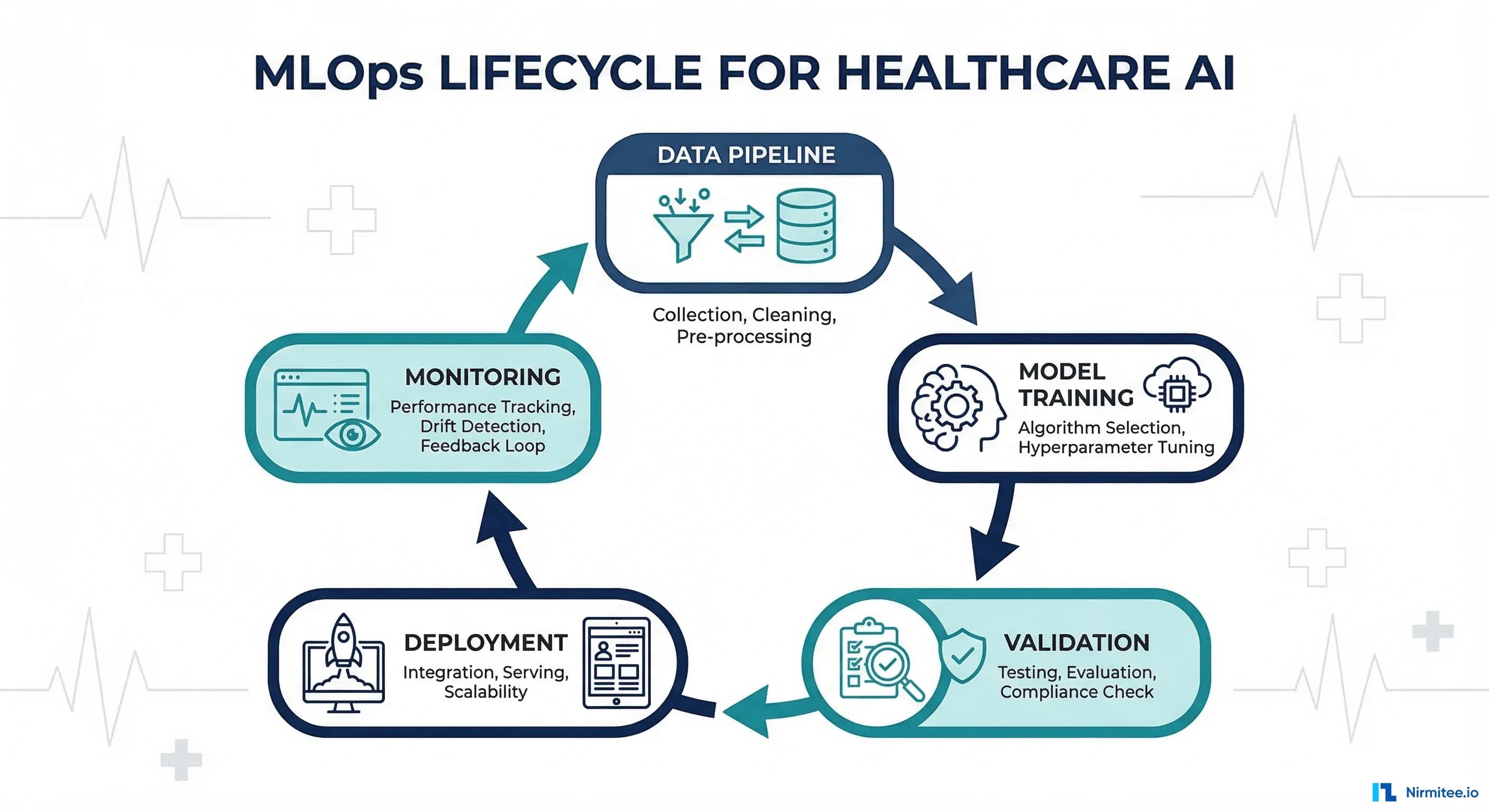
The Nine Stages of Healthcare ML CI/CD
A production healthcare ML pipeline has nine distinct stages, each with specific gates that must pass before proceeding to the next. Unlike standard software deployment where a green test suite means "ship it," healthcare ML requires multiple independent validation layers, including one that requires a human clinician to review and approve.
Stage Overview
| Stage | What Happens | Gate Criteria | Automated? |
|---|---|---|---|
| 1. Code Change | Git push triggers pipeline | PR approved, linting passes | Yes |
| 2. Automated Tests | Unit tests + integration tests | 100% pass rate | Yes |
| 3. Data Validation | Schema check, drift detection | No schema violations, drift below threshold | Yes |
| 4. Model Training | Reproducible training with tracked params | Training completes, metrics logged | Yes |
| 5. Model Validation | Accuracy, bias check, regression test | AUROC above threshold, no bias regression | Yes |
| 6. Clinical Review | Human clinician reviews model outputs | Explicit approval in GitHub | No |
| 7. Shadow Deployment | Run alongside production, compare | Predictions within acceptable divergence | Yes |
| 8. Canary Rollout | 5% traffic to new model | No degradation in live metrics | Yes |
| 9. Full Production | 100% traffic to new model | Canary stable for defined period | Yes |
Stage 1-2: Code Changes and Automated Testing
Every ML pipeline starts with version-controlled code. When a data scientist pushes a change—whether to feature engineering logic, model hyperparameters, training scripts, or serving code—the CI/CD pipeline triggers automatically. The first gate is automated testing, which for healthcare ML includes three categories: unit tests for data transformation functions, integration tests for the full training pipeline, and contract tests for the prediction API.
# tests/test_features.py — Unit tests for feature engineering
import pytest
import pandas as pd
from src.features import extract_age, extract_diagnosis_count, validate_features
def test_extract_age_standard():
"""Age calculation should handle standard cases."""
assert extract_age("1950-06-15", "2026-03-16") == pytest.approx(75.75, abs=0.1)
def test_extract_age_boundary():
"""Age 0 for same-day birth."""
assert extract_age("2026-03-16", "2026-03-16") == pytest.approx(0.0, abs=0.01)
def test_extract_age_missing_returns_none():
"""Missing birth date should return None, not crash."""
assert extract_age(None, "2026-03-16") is None
def test_diagnosis_count_deduplicates():
"""Same diagnosis coded in ICD-10 and SNOMED should count once."""
conditions = [
{"code": "E11.9", "system": "icd10"},
{"code": "44054006", "system": "snomed"}, # Same: Type 2 DM
]
assert extract_diagnosis_count(conditions) == 1
def test_validate_features_rejects_negative_age():
"""Feature validation should catch impossible values."""
features = {"age": -5, "los_days": 3, "dx_count": 2}
with pytest.raises(ValueError, match="age must be non-negative"):
validate_features(features)
def test_validate_features_rejects_zero_los():
"""Length of stay must be at least 1 day."""
features = {"age": 65, "los_days": 0, "dx_count": 2}
with pytest.raises(ValueError, match="los_days must be >= 1"):
validate_features(features)
# tests/test_prediction_api.py — Contract tests for serving
def test_predict_endpoint_returns_valid_schema(client):
response = client.post("/predict", json={
"age": 72, "gender": 1, "dx_count": 5,
"med_count": 8, "prior_admits_12mo": 2,
"los_days": 4, "has_diabetes": 1,
"has_heart_failure": 0, "has_copd": 0,
"abnormal_lab_count": 1
})
assert response.status_code == 200
data = response.json()
assert 0.0 <= data["risk_score"] <= 1.0
assert data["risk_level"] in ["low", "medium", "high"]
assert "model_version" in data
def test_predict_endpoint_rejects_invalid_age(client):
response = client.post("/predict", json={
"age": -10, "gender": 1, "dx_count": 5,
"med_count": 8, "prior_admits_12mo": 2,
"los_days": 4, "has_diabetes": 1,
"has_heart_failure": 0, "has_copd": 0,
"abnormal_lab_count": 1
})
assert response.status_code == 422 # Validation errorStage 3: Data Validation
Data validation is where healthcare ML CI/CD diverges most from standard software pipelines. Before training a model, you must verify that the training data is structurally sound (schema validation), representative of the target population (distribution checks), and has not drifted significantly from previous training datasets (drift detection). A model trained on corrupted or shifted data will produce confident but wrong predictions.
# src/data_validation.py — Data quality gates for healthcare ML
import pandas as pd
import numpy as np
from scipy import stats
from dataclasses import dataclass
@dataclass
class ValidationResult:
passed: bool
checks: dict
errors: list
warnings: list
def validate_training_data(df: pd.DataFrame, reference_df: pd.DataFrame = None) -> ValidationResult:
"""Run all data validation checks before model training."""
errors = []
warnings = []
checks = {}
# 1. Schema validation — required columns present with correct types
required_cols = {
"age": "float64", "gender": "int64", "dx_count": "int64",
"med_count": "int64", "prior_admits_12mo": "int64",
"los_days": "int64", "readmitted_30d": "int64"
}
for col, expected_type in required_cols.items():
if col not in df.columns:
errors.append(f"Missing required column: {col}")
elif not np.issubdtype(df[col].dtype, np.number):
errors.append(f"{col}: expected numeric, got {df[col].dtype}")
checks["schema"] = len(errors) == 0
# 2. Range validation — catch impossible values
range_rules = {
"age": (0, 120), "gender": (0, 1), "dx_count": (0, 100),
"med_count": (0, 50), "los_days": (1, 365),
"prior_admits_12mo": (0, 52)
}
for col, (min_val, max_val) in range_rules.items():
if col in df.columns:
out_of_range = ((df[col] < min_val) | (df[col] > max_val)).sum()
if out_of_range > 0:
pct = out_of_range / len(df) * 100
if pct > 5:
errors.append(f"{col}: {pct:.1f}% values out of range [{min_val}, {max_val}]")
else:
warnings.append(f"{col}: {pct:.1f}% values out of range")
checks["range"] = not any("out of range" in e for e in errors)
# 3. Missing data check
for col in df.columns:
missing_pct = df[col].isna().mean() * 100
if missing_pct > 10:
errors.append(f"{col}: {missing_pct:.1f}% missing (threshold: 10%)")
elif missing_pct > 2:
warnings.append(f"{col}: {missing_pct:.1f}% missing")
checks["completeness"] = not any("missing" in e for e in errors)
# 4. Class balance check
if "readmitted_30d" in df.columns:
positive_rate = df["readmitted_30d"].mean()
if positive_rate < 0.01 or positive_rate > 0.5:
errors.append(f"Unusual readmission rate: {positive_rate:.1%}")
elif positive_rate < 0.05 or positive_rate > 0.3:
warnings.append(f"Readmission rate {positive_rate:.1%} differs from expected 10-20%")
checks["class_balance"] = not any("readmission rate" in e.lower() for e in errors)
# 5. Distribution drift (if reference provided)
if reference_df is not None:
drift_features = ["age", "dx_count", "med_count", "los_days"]
for col in drift_features:
if col in df.columns and col in reference_df.columns:
ks_stat, p_value = stats.ks_2samp(
reference_df[col].dropna(), df[col].dropna()
)
if p_value < 0.001:
errors.append(f"{col}: significant drift detected (KS p={p_value:.4f})")
elif p_value < 0.01:
warnings.append(f"{col}: moderate drift (KS p={p_value:.4f})")
checks["drift"] = not any("drift detected" in e for e in errors)
passed = len(errors) == 0
return ValidationResult(passed=passed, checks=checks, errors=errors, warnings=warnings)Data validation failures should block the pipeline completely. Unlike a flaky integration test that might warrant a retry, a data quality issue indicates a systemic problem—an upstream ETL failure, a change in clinical coding practices, or a data pipeline bug—that will produce a model trained on bad data. The validation script above can be integrated directly into your clinical ML training pipeline as a pre-training gate.
Stage 4-5: Model Training and Validation
Model training in a CI/CD pipeline must be fully reproducible. Every training run should log the exact data version, hyperparameters, random seeds, software versions, and compute environment. MLflow is the most widely adopted open-source tool for experiment tracking in healthcare ML, though Weights and Biases and Neptune are also popular options.
# src/train.py — Reproducible training with MLflow tracking
import mlflow
import mlflow.xgboost
import xgboost as xgb
from sklearn.model_selection import train_test_split
import json
import hashlib
def train_model(data_path: str, config: dict) -> dict:
"""Train model with full reproducibility tracking."""
with mlflow.start_run(run_name=f"readmission_v{config['version']}"):
# Log data version (hash of training data)
import pandas as pd
df = pd.read_csv(data_path)
data_hash = hashlib.sha256(
pd.util.hash_pandas_object(df).values.tobytes()
).hexdigest()[:12]
mlflow.log_param("data_hash", data_hash)
mlflow.log_param("data_rows", len(df))
mlflow.log_param("data_path", data_path)
# Log all hyperparameters
for k, v in config["hyperparameters"].items():
mlflow.log_param(k, v)
# Prepare data
X = df[config["features"]].values
y = df[config["target"]].values
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=config["random_seed"],
stratify=y
)
# Train
model = xgb.XGBClassifier(**config["hyperparameters"])
model.fit(X_train, y_train, eval_set=[(X_val, y_val)], verbose=False)
# Log metrics
from sklearn.metrics import roc_auc_score, average_precision_score
val_probs = model.predict_proba(X_val)[:, 1]
auroc = roc_auc_score(y_val, val_probs)
auprc = average_precision_score(y_val, val_probs)
mlflow.log_metric("auroc", auroc)
mlflow.log_metric("auprc", auprc)
mlflow.log_metric("val_size", len(X_val))
# Log model
mlflow.xgboost.log_model(model, "model")
return {
"run_id": mlflow.active_run().info.run_id,
"auroc": auroc,
"auprc": auprc,
"data_hash": data_hash
}Model Validation with Clinical Thresholds
# src/validate_model.py — Clinical validation gates
import json
import sys
def validate_model(metrics: dict, thresholds: dict) -> dict:
"""Validate model against clinical performance thresholds."""
results = {"passed": True, "checks": []}
# AUROC threshold
if metrics["auroc"] < thresholds["min_auroc"]:
results["passed"] = False
results["checks"].append({
"name": "auroc",
"status": "FAIL",
"actual": metrics["auroc"],
"threshold": thresholds["min_auroc"]
})
else:
results["checks"].append({"name": "auroc", "status": "PASS"})
# Sensitivity at operating threshold
if metrics.get("sensitivity", 0) < thresholds["min_sensitivity"]:
results["passed"] = False
results["checks"].append({
"name": "sensitivity",
"status": "FAIL",
"actual": metrics["sensitivity"],
"threshold": thresholds["min_sensitivity"]
})
else:
results["checks"].append({"name": "sensitivity", "status": "PASS"})
# Regression test — compare with production model
if "production_auroc" in thresholds:
auroc_drop = thresholds["production_auroc"] - metrics["auroc"]
if auroc_drop > thresholds.get("max_auroc_regression", 0.02):
results["passed"] = False
results["checks"].append({
"name": "regression_test",
"status": "FAIL",
"message": f"AUROC dropped {auroc_drop:.3f} from production"
})
# Bias audit — performance across demographic groups
if "demographic_metrics" in metrics:
for group, group_metrics in metrics["demographic_metrics"].items():
auroc_gap = abs(group_metrics["auroc"] - metrics["auroc"])
if auroc_gap > thresholds.get("max_demographic_auroc_gap", 0.05):
results["passed"] = False
results["checks"].append({
"name": f"bias_check_{group}",
"status": "FAIL",
"message": f"{group} AUROC gap: {auroc_gap:.3f}"
})
return results
# Clinical thresholds configuration
THRESHOLDS = {
"min_auroc": 0.75,
"min_sensitivity": 0.80,
"min_specificity": 0.50,
"max_auroc_regression": 0.02,
"max_demographic_auroc_gap": 0.05
}The validation thresholds encode clinical requirements as code. An AUROC below 0.75 means the model lacks sufficient discriminative ability. Sensitivity below 80% means too many high-risk patients are being missed. The regression test ensures a new model never performs significantly worse than the model currently in production. And the bias audit checks that performance does not degrade disproportionately for any demographic group—a critical requirement for equitable healthcare AI that connects to the broader discussion of healthcare ML metrics and clinical utility.
Stage 6: Clinical Review Gate
The clinical review gate is what separates healthcare ML CI/CD from every other industry. Before a model touches patient data in production, a qualified clinician must review the model's predictions on representative cases, examine edge cases and failure modes, verify that the model behaves sensibly for clinical scenarios they encounter daily, and explicitly approve the deployment. This is not a rubber stamp—it is a genuine clinical assessment.
# .github/workflows/clinical-review.yml
# This workflow pauses for human approval before deployment
jobs:
generate-review-report:
runs-on: ubuntu-latest
steps:
- name: Generate Clinical Review Report
run: |
python src/generate_review_report.py \
--model-run-id ${{ needs.validate.outputs.run_id }} \
--output review_report.html
- name: Upload Review Report
uses: actions/upload-artifact@v4
with:
name: clinical-review-report
path: review_report.html
- name: Notify Clinical Reviewer
uses: slackapi/slack-github-action@v1.25.0
with:
channel-id: 'clinical-ai-review'
slack-message: |
New model ready for clinical review.
Model: readmission-prediction v${{ github.run_number }}
AUROC: ${{ needs.validate.outputs.auroc }}
Review report: ${{ github.server_url }}/${{ github.repository }}/actions/runs/${{ github.run_id }}
clinical-approval:
runs-on: ubuntu-latest
needs: generate-review-report
environment: clinical-review # Requires manual approval in GitHub
steps:
- name: Clinical Approval Confirmed
run: echo "Clinical review approved by ${{ github.actor }}"In GitHub, the environment: clinical-review configuration creates a deployment protection rule that requires manual approval from designated reviewers before the workflow proceeds. The clinical reviewer downloads the review report artifact, examines model predictions on edge cases (patients with unusual feature combinations, borderline risk scores, demographically diverse cohorts), and either approves or rejects with comments explaining their clinical concerns.
Stage 7-8: Shadow Deployment and Canary Rollout
After clinical approval, the model enters a two-phase production rollout. Shadow deployment runs the new model alongside the existing production model, logging predictions from both without using the new model's outputs for clinical decisions. This phase validates that the model performs consistently in the production environment with real data volumes, latencies, and edge cases that synthetic testing cannot replicate.
# src/shadow_deployment.py — Shadow mode comparison
import numpy as np
from dataclasses import dataclass
@dataclass
class ShadowComparison:
agreement_rate: float
mean_score_diff: float
max_score_diff: float
risk_level_changes: dict
sample_size: int
def compare_shadow_predictions(
production_scores: list,
shadow_scores: list,
threshold: float = 0.3
) -> ShadowComparison:
"""Compare production vs shadow model predictions."""
prod = np.array(production_scores)
shadow = np.array(shadow_scores)
prod_labels = (prod >= threshold).astype(int)
shadow_labels = (shadow >= threshold).astype(int)
agreement = (prod_labels == shadow_labels).mean()
mean_diff = np.abs(prod - shadow).mean()
max_diff = np.abs(prod - shadow).max()
# Track risk level transitions
transitions = {"low_to_high": 0, "high_to_low": 0, "unchanged": 0}
for p, s in zip(prod_labels, shadow_labels):
if p == 0 and s == 1:
transitions["low_to_high"] += 1
elif p == 1 and s == 0:
transitions["high_to_low"] += 1
else:
transitions["unchanged"] += 1
return ShadowComparison(
agreement_rate=agreement,
mean_score_diff=mean_diff,
max_score_diff=max_diff,
risk_level_changes=transitions,
sample_size=len(prod)
)
# Acceptance criteria for shadow phase
SHADOW_CRITERIA = {
"min_agreement_rate": 0.90, # 90%+ same risk category
"max_mean_score_diff": 0.10, # Average score differs by <0.10
"min_sample_size": 500, # At least 500 predictions compared
"max_high_to_low_rate": 0.05 # <5% of high-risk patients reclassified as low
}After shadow validation passes, the canary rollout begins. Initially 5% of prediction requests are routed to the new model. If all monitoring metrics remain stable for a defined observation window (typically 24-48 hours), traffic increases to 25%, then 50%, then 100%. At each stage, automated checks verify that latency, error rates, prediction distributions, and any available outcome metrics have not degraded. If any metric breaches its threshold, the rollout automatically reverts to the previous model.
Complete GitHub Actions Workflow
Here is the full GitHub Actions workflow YAML that implements all nine stages. This is a production-ready template you can adapt by changing the thresholds, adding your specific test commands, and configuring the deployment targets for your infrastructure.
# .github/workflows/healthcare-ml-cicd.yml
name: Healthcare ML CI/CD Pipeline
on:
push:
branches: [main]
paths:
- 'src/**'
- 'config/**'
- 'data/processed/**'
pull_request:
branches: [main]
env:
MODEL_NAME: readmission-prediction
PYTHON_VERSION: '3.11'
MLFLOW_TRACKING_URI: ${{ secrets.MLFLOW_TRACKING_URI }}
jobs:
# Stage 1-2: Code Quality + Automated Tests
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: ${{ env.PYTHON_VERSION }}
- name: Install dependencies
run: pip install -r requirements.txt -r requirements-dev.txt
- name: Lint
run: |
ruff check src/ tests/
mypy src/ --ignore-missing-imports
- name: Unit Tests
run: pytest tests/unit/ -v --tb=short --junitxml=test-results.xml
- name: Integration Tests
run: pytest tests/integration/ -v --tb=short
- name: Upload test results
uses: actions/upload-artifact@v4
if: always()
with:
name: test-results
path: test-results.xml
# Stage 3: Data Validation
validate-data:
runs-on: ubuntu-latest
needs: test
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: ${{ env.PYTHON_VERSION }}
- name: Install dependencies
run: pip install -r requirements.txt
- name: Pull training data
run: dvc pull data/processed/training_data.csv
- name: Validate data schema and quality
run: python src/data_validation.py --data data/processed/training_data.csv --config config/validation_rules.json
- name: Check for data drift
run: |
python src/drift_detection.py \
--current data/processed/training_data.csv \
--reference data/reference/baseline_distribution.json \
--threshold 0.01
# Stage 4: Model Training
train:
runs-on: ubuntu-latest
needs: validate-data
outputs:
run_id: ${{ steps.train.outputs.run_id }}
auroc: ${{ steps.train.outputs.auroc }}
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: ${{ env.PYTHON_VERSION }}
- name: Install dependencies
run: pip install -r requirements.txt
- name: Pull training data
run: dvc pull data/processed/training_data.csv
- name: Train model
id: train
run: |
RESULT=$(python src/train.py \
--config config/model_config.json \
--data data/processed/training_data.csv)
echo "run_id=$(echo $RESULT | jq -r .run_id)" >> $GITHUB_OUTPUT
echo "auroc=$(echo $RESULT | jq -r .auroc)" >> $GITHUB_OUTPUT
# Stage 5: Model Validation
validate-model:
runs-on: ubuntu-latest
needs: train
outputs:
validation_passed: ${{ steps.validate.outputs.passed }}
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: ${{ env.PYTHON_VERSION }}
- name: Install dependencies
run: pip install -r requirements.txt
- name: Validate model performance
id: validate
run: |
RESULT=$(python src/validate_model.py \
--run-id ${{ needs.train.outputs.run_id }} \
--thresholds config/clinical_thresholds.json)
echo "passed=$(echo $RESULT | jq -r .passed)" >> $GITHUB_OUTPUT
- name: Bias audit
run: |
python src/bias_audit.py \
--run-id ${{ needs.train.outputs.run_id }} \
--protected-attributes age_group,gender,race,insurance
- name: Fail if validation did not pass
if: steps.validate.outputs.passed != 'true'
run: exit 1
# Stage 6: Clinical Review (Manual Approval)
clinical-review:
runs-on: ubuntu-latest
needs: validate-model
if: github.ref == 'refs/heads/main'
environment: clinical-review
steps:
- name: Clinical Review Approved
run: echo "Approved by ${{ github.actor }} at $(date -u)"
# Stage 7: Shadow Deployment
shadow-deploy:
runs-on: ubuntu-latest
needs: clinical-review
steps:
- uses: actions/checkout@v4
- name: Deploy shadow model
run: |
python src/deploy.py \
--run-id ${{ needs.train.outputs.run_id }} \
--mode shadow \
--duration-hours 48
# Stage 8-9: Canary then Full Rollout
canary-deploy:
runs-on: ubuntu-latest
needs: shadow-deploy
steps:
- uses: actions/checkout@v4
- name: Canary rollout (5% traffic)
run: |
python src/deploy.py \
--run-id ${{ needs.train.outputs.run_id }} \
--mode canary \
--traffic-percent 5 \
--observation-hours 24
- name: Promote to full production
run: |
python src/deploy.py \
--run-id ${{ needs.train.outputs.run_id }} \
--mode productionInfrastructure Considerations
| Component | Recommended Tool | Purpose | Alternative |
|---|---|---|---|
| CI/CD | GitHub Actions | Pipeline orchestration | GitLab CI, Jenkins |
| Experiment Tracking | MLflow | Hyperparameters, metrics, artifacts | Weights & Biases, Neptune |
| Data Versioning | DVC | Track data alongside code | LakeFS, Delta Lake |
| Model Registry | MLflow Model Registry | Stage models through lifecycle | SageMaker Model Registry |
| Container Registry | GitHub Container Registry | Store serving Docker images | ECR, GCR |
| Monitoring | Prometheus + Grafana | Prediction monitoring, alerting | Datadog, WhyLabs |
Organizations building healthcare ML CI/CD pipelines should also consider how their data versioning strategy fits into the broader pipeline. Proper data versioning for healthcare ML ensures that every model training run can be traced back to the exact dataset it was trained on—a critical requirement for FDA SaMD submissions and clinical audit trails. The CI/CD pipeline should integrate data version checks as part of the data validation stage, verifying that the training data version matches the expected DVC or LakeFS commit.
Frequently Asked Questions
How long does the clinical review gate typically take?
Clinical review timelines vary by organization and model risk level. Low-risk models (population health analytics, operational predictions) may receive review within 1-2 business days. High-risk models (diagnostic support, treatment recommendations) typically require 1-2 weeks and may involve a committee review. Build the pipeline to accommodate asynchronous approval without blocking other development work.
What happens when the canary rollout detects a problem?
An automated rollback immediately routes 100% of traffic back to the previous production model. The pipeline generates an incident report documenting the detected degradation (which metric, by how much, at what traffic level). The development team investigates the root cause before attempting another deployment. Common causes include data distribution differences between shadow and canary traffic, infrastructure-related latency issues, and edge cases not covered by the validation dataset.
Do I need all nine stages for every model?
The full nine-stage pipeline is appropriate for models that directly influence clinical decisions. For internal analytics models, operational predictions, or research prototypes, you can simplify. At minimum, every healthcare ML deployment should have automated tests (Stage 2), data validation (Stage 3), model validation (Stage 5), and some form of staged rollout (Stages 8-9). Never skip the clinical review gate (Stage 6) for patient-facing models.
How do you handle the 30-day label delay for readmission models?
You cannot measure true model performance until 30 days after each prediction. During the label delay period, monitor input data distribution drift, prediction score distribution, and model latency as proxy indicators. Once 30-day outcomes are available, compute actual performance metrics and compare against the validation baseline. If performance has degraded, the monitoring system triggers an alert for investigation and potential retraining.
Can this pipeline run on cloud ML platforms like SageMaker or Vertex AI?
Yes. GitHub Actions can orchestrate SageMaker training jobs via the AWS CLI, Vertex AI pipelines via gcloud, or Azure ML workspaces via the Azure CLI. The nine-stage structure remains the same—the cloud platform handles compute for training and serving, while GitHub Actions manages the orchestration, gates, and approvals. Many organizations use a hybrid approach: GitHub Actions for CI and gates, cloud ML platforms for training compute and model serving.