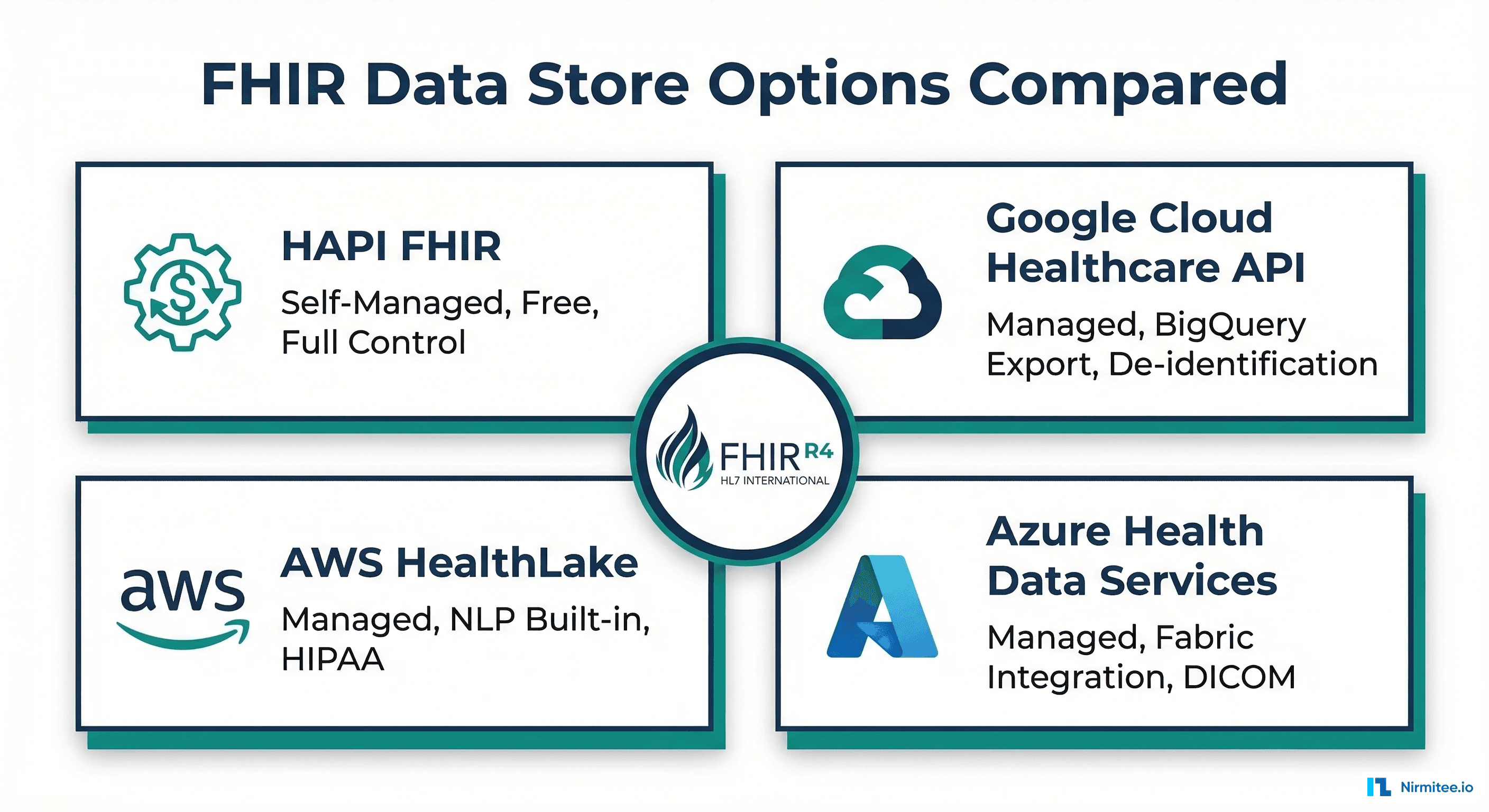
The FHIR Data Store Decision: Build vs. Buy
Every healthcare application that stores clinical data needs a FHIR data store — a system that can persist, index, search, and serve FHIR R4 resources via RESTful APIs. The fundamental decision is whether to self-host an open-source solution or use a managed cloud service.
This decision affects everything downstream: your compliance posture, operational costs, analytics capabilities, scaling ceiling, and vendor lock-in exposure. A 2024 survey by KLAS Research found that 62% of health systems are actively evaluating FHIR data store options as they comply with CMS interoperability mandates and build patient-facing APIs.
This guide provides an honest, detailed comparison of the four dominant options: HAPI FHIR (open source), Google Cloud Healthcare API, AWS HealthLake, and Azure Health Data Services. We cover architecture, cost modeling, search performance, analytics integration, and a decision framework.
Option 1: HAPI FHIR — Open Source, Self-Managed
Architecture
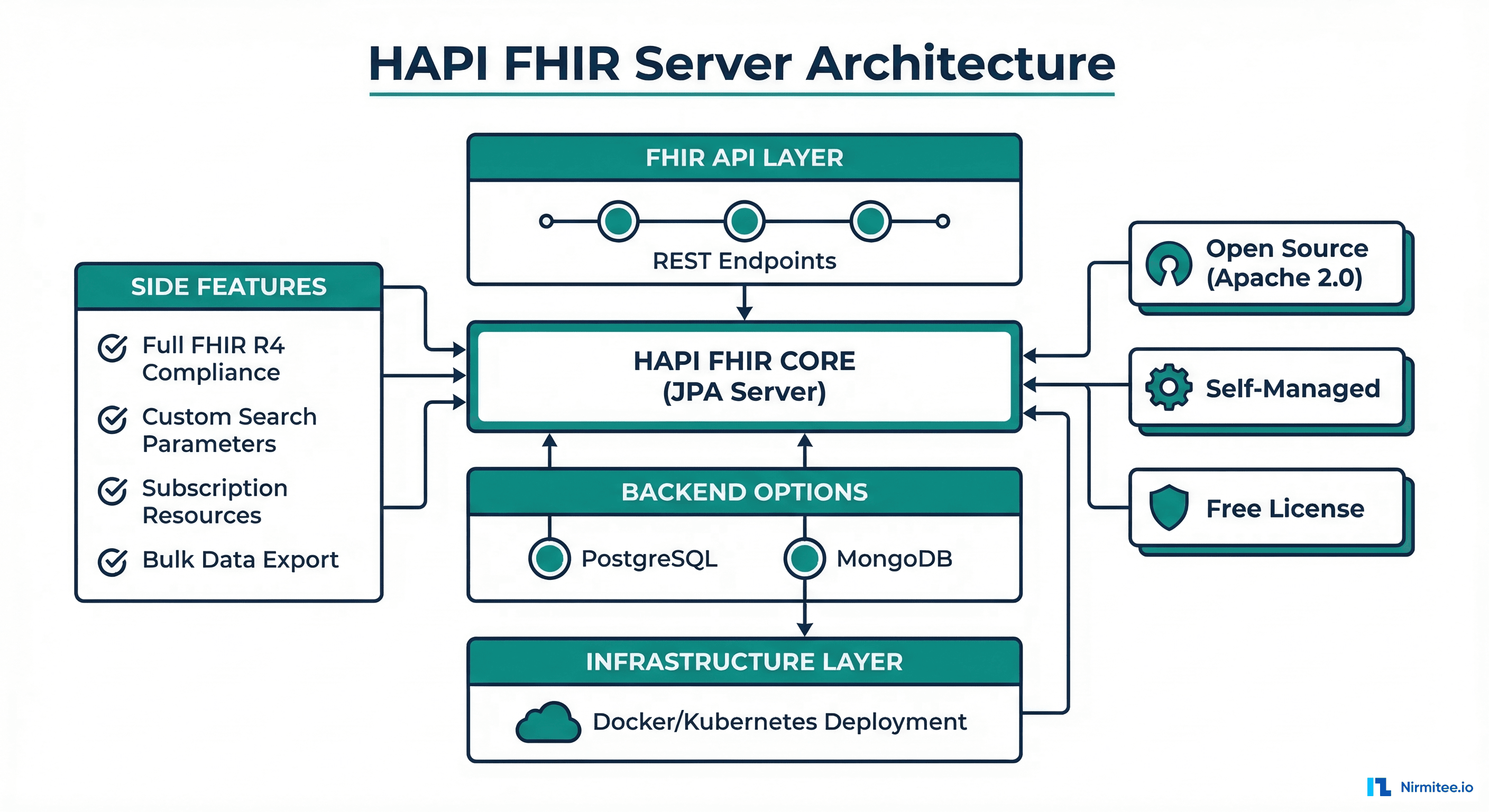
HAPI FHIR is the most widely deployed open-source FHIR server, maintained by Smile CDR (a Canadian health IT company). It is a Java application that runs on any JVM and supports PostgreSQL, MySQL, Oracle, or Microsoft SQL Server as backend databases. A MongoDB backend is also available for document-oriented storage.
Setup: Docker Deployment
# docker-compose.yml for HAPI FHIR with PostgreSQL
version: '3.8'
services:
hapi-fhir:
image: hapiproject/hapi:latest
ports:
- "8080:8080"
environment:
- spring.datasource.url=jdbc:postgresql://db:5432/hapi
- spring.datasource.username=hapi
- spring.datasource.password=changeme
- spring.datasource.driverClassName=org.postgresql.Driver
- spring.jpa.properties.hibernate.dialect=ca.uhn.fhir.jpa.model.dialect.HapiFhirPostgresDialect
- hapi.fhir.fhir_version=R4
- hapi.fhir.bulk_export_enabled=true
- hapi.fhir.allow_multiple_delete=true
- hapi.fhir.reuse_cached_search_results_millis=60000
depends_on:
- db
db:
image: postgres:15
environment:
- POSTGRES_DB=hapi
- POSTGRES_USER=hapi
- POSTGRES_PASSWORD=changeme
volumes:
- hapi-data:/var/lib/postgresql/data
volumes:
hapi-data:# Start HAPI FHIR
docker-compose up -d
# Verify server is running
curl http://localhost:8080/fhir/metadata | jq '.fhirVersion'
# Returns: "4.0.1"
# Create a Patient resource
curl -X POST http://localhost:8080/fhir/Patient \
-H "Content-Type: application/fhir+json" \
-d '{
"resourceType": "Patient",
"name": [{"family": "Smith", "given": ["John"]}],
"birthDate": "1985-03-15",
"gender": "male"
}'
# Search patients
curl "http://localhost:8080/fhir/Patient?name=Smith&birthdate=1985-03-15"Pros
- Free and open source (Apache 2.0 license) — no per-operation or per-GB costs
- Full FHIR R4 compliance — passes the HL7 FHIR conformance test suite, supports all resource types, search parameters, and operations, including
$export - Total control — customize search parameters, interceptors, validation rules, and authorization. You can modify the source code if needed
- No vendor lock-in — runs on any cloud, any Kubernetes cluster, or on-premises. Switch hosting without changing application code
- Active community — 4,000+ GitHub stars, regular releases, extensive documentation, and a responsive Zulip chat community
Cons
- You manage everything — patching, scaling, backup, monitoring, and high availability. Budget $80K-120K/year in DevOps staff time for production deployments
- Search performance degrades at scale — beyond 50M resources, PostgreSQL-backed search requires careful index tuning. Elasticsearch integration helps, but adds operational complexity
- No built-in analytics — you need to build your own pipeline to export data to a data lakehouse or warehouse for analytics
- No built-in de-identification — you need third-party tools or custom code for PHI de-identification
Real-World Scale
HAPI FHIR runs in production at organizations storing 100M+ resources. The Veterans Affairs (VA) Lighthouse API uses HAPI FHIR to serve data for 9 million veterans. Performance tuning includes: partitioned PostgreSQL tables, Elasticsearch for search offloading, connection pooling (HikariCP), and read replicas for high-query workloads.
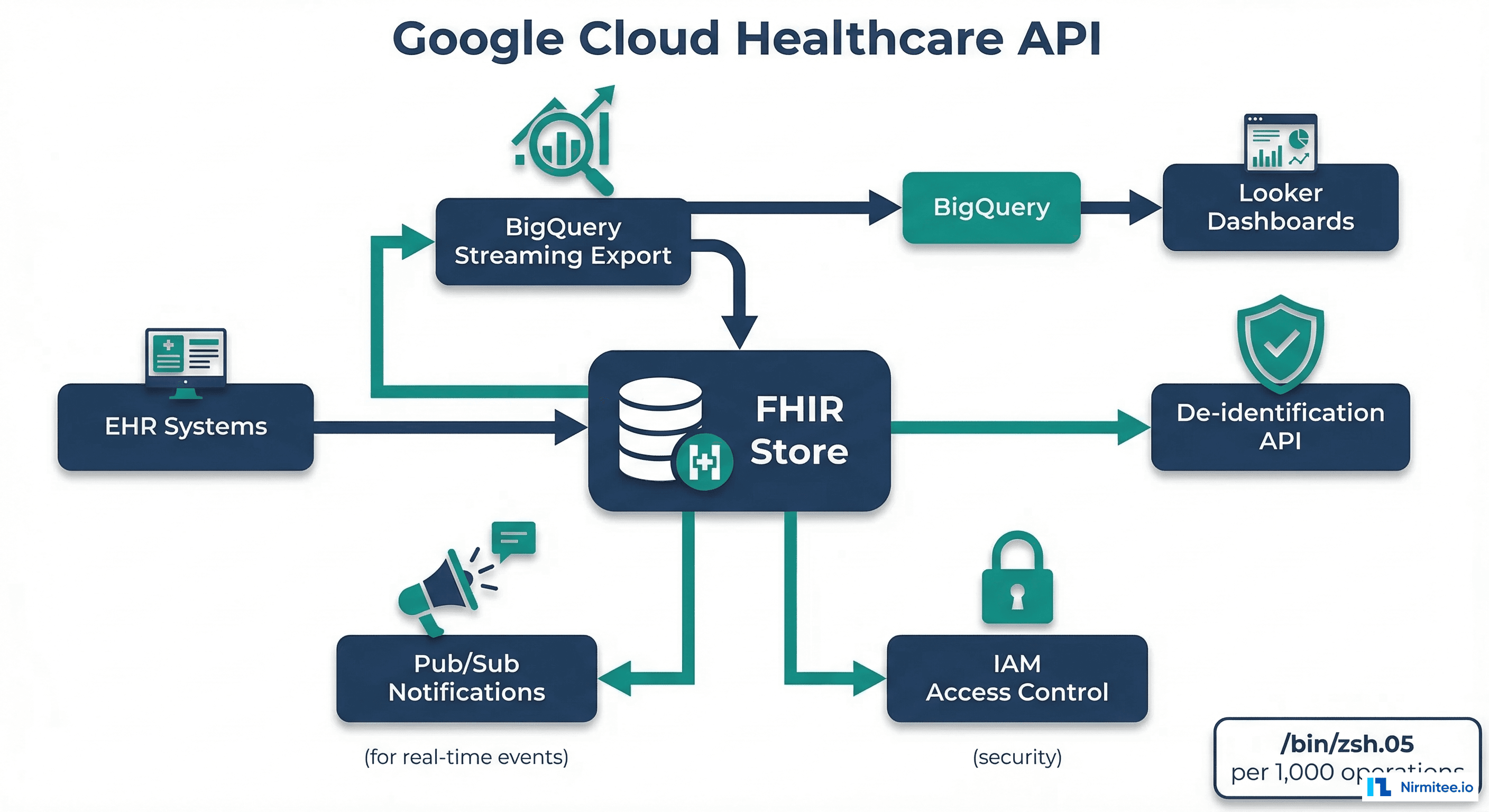
Option 2: Google Cloud Healthcare API
Architecture
Google Cloud Healthcare API provides a fully managed FHIR R4 store as part of the Google Cloud Platform. It stands out for its native BigQuery streaming export — FHIR resources are automatically exported to BigQuery in real-time, enabling SQL analytics without separate ETL pipelines.
Setup
# Create Healthcare dataset and FHIR store
gcloud healthcare datasets create my-health-dataset \
--location=us-central1
gcloud healthcare fhir-stores create my-fhir-store \
--dataset=my-health-dataset \
--location=us-central1 \
--version=R4 \
--enable-update-create \
--disable-referential-integrity
# Enable BigQuery streaming export
gcloud healthcare fhir-stores update my-fhir-store \
--dataset=my-health-dataset \
--location=us-central1 \
--stream-configs=bigquery-destination=bq://my-project.fhir_dataset.fhir_table
# Import FHIR NDJSON from GCS
gcloud healthcare fhir-stores import gcs my-fhir-store \
--dataset=my-health-dataset \
--location=us-central1 \
--gcs-uri=gs://my-bucket/fhir-export/*.ndjson \
--content-structure=RESOURCE
# Query via REST API
curl -X GET \
"https://healthcare.googleapis.com/v1/projects/my-project/locations/us-central1/datasets/my-health-dataset/fhirStores/my-fhir-store/fhir/Patient?name=Smith" \
-H "Authorization: Bearer $(gcloud auth print-access-token)"Pros
- BigQuery streaming export — FHIR resources appear in BigQuery within seconds of creation/update. Run SQL analytics directly on clinical data without building ETL pipelines
- Built-in de-identification — the de-identification API supports HIPAA Safe Harbor and expert determination methods. Strip PHI from FHIR resources automatically before exporting to research datasets
- Fully managed — Google handles scaling, availability, patching, and disaster recovery. SLA: 99.95% availability
- Strong FHIR compliance — passes HL7 FHIR conformance tests, supports SMART on FHIR authorization, Bulk Data Access, and all standard search parameters
- Competitive pricing — $0.05 per 1,000 FHIR operations, $0.04/GB stored. For a moderate workload (10M resources, 1M operations/day), the annual cost is approximately $20K-30K
Cons
- GCP lock-in — deeply integrated with Google Cloud. Migrating to another cloud requires significant refactoring
- Limited customization — you cannot modify search parameters, add custom interceptors, or extend the FHIR server behavior. What Google provides is what you get
- Smaller healthcare ecosystem — GCP has less healthcare-specific tooling compared to AWS or Azure. Fewer healthcare ISVs build on GCP
Best Reference
OneUptime published a detailed guide on using Google Cloud Healthcare API for FHIR data management, covering the streaming BigQuery export pattern. This approach is particularly powerful when combined with Vertex AI for building ML models directly on BigQuery-accessible clinical data.
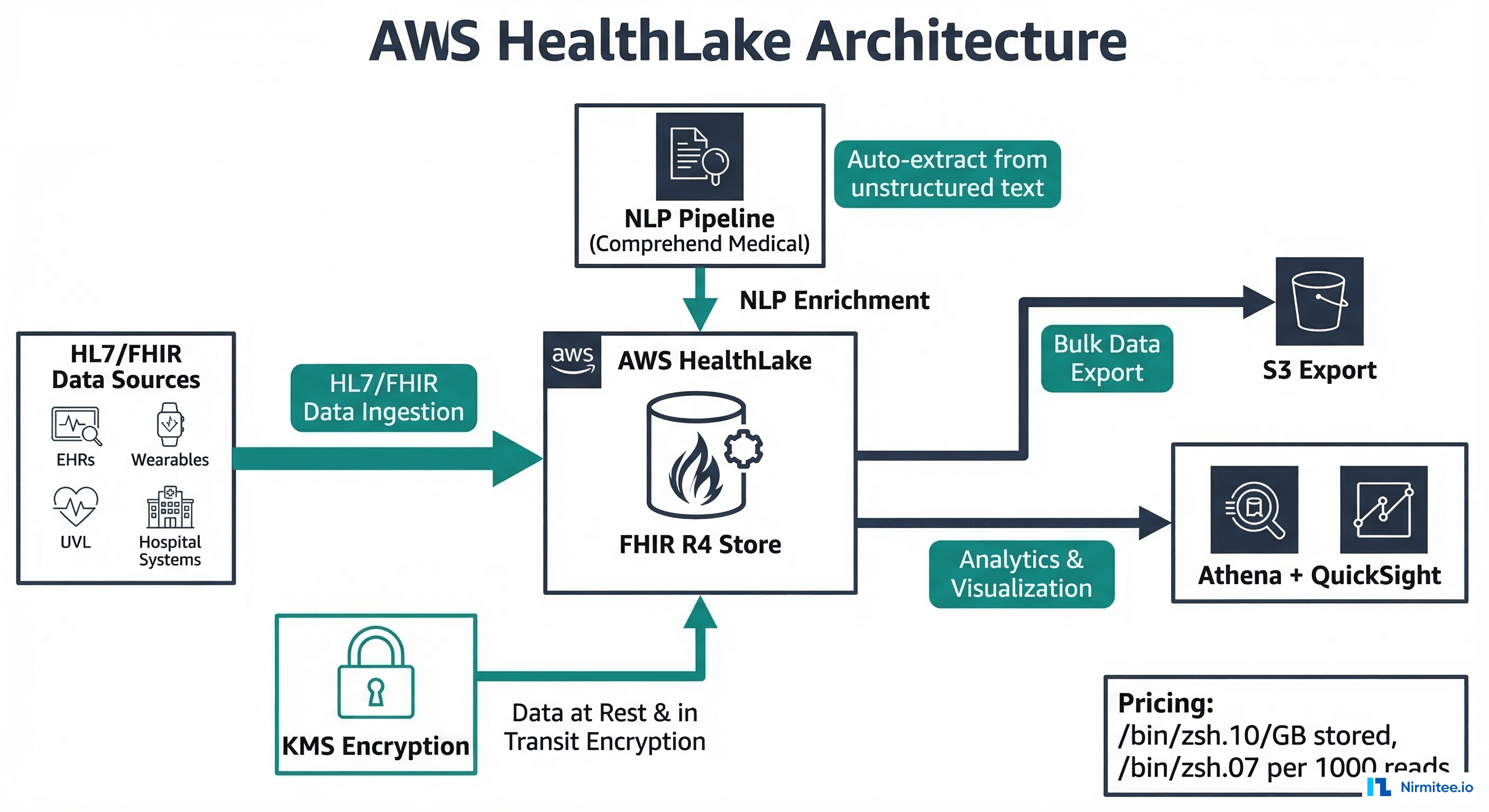
Option 3: AWS HealthLake
Architecture
AWS HealthLake is Amazon's managed FHIR store, differentiated by its built-in NLP pipeline using Amazon Comprehend Medical. When you store FHIR resources in HealthLake, it can automatically extract structured medical entities from unstructured text within those resources and enrich the stored data.
Setup
# Create HealthLake datastore
aws healthlake create-fhir-datastore \
--datastore-name "my-clinical-store" \
--datastore-type-version R4 \
--preload-data-config PreloadDataType=SYNTHEA \
--sse-configuration KmsEncryptionConfig={CmkType=AWS_OWNED_KMS_KEY}
# Wait for datastore to be active
aws healthlake describe-fhir-datastore \
--datastore-id "datastore-id-here" \
--query "DatastoreProperties.DatastoreStatus"
# Create a Patient resource
DATASTORE_ID="your-datastore-id"
ENDPOINT="https://healthlake.us-east-1.amazonaws.com"
aws healthlake create-resource \
--datastore-id $DATASTORE_ID \
--resource-type Patient \
--resource-body '{
"resourceType": "Patient",
"name": [{"family": "Smith", "given": ["John"]}],
"birthDate": "1985-03-15"
}'
# Start FHIR export to S3
aws healthlake start-fhir-export-job \
--datastore-id $DATASTORE_ID \
--output-data-config S3Configuration={S3Uri="s3://my-bucket/exports/",KmsKeyId="key-id"} \
--data-access-role-arn "arn:aws:iam::123456789:role/HealthLakeExportRole"Pros
- Built-in NLP — Amazon Comprehend Medical automatically extracts medical conditions, medications, procedures, and their attributes from unstructured text within FHIR resources. This is unique among managed FHIR stores
- AWS ecosystem integration — native integration with S3, Athena, QuickSight, SageMaker, and Lambda. Most healthcare ISVs build on AWS, so HealthLake integrates naturally with existing infrastructure
- HIPAA-eligible — HealthLake is HIPAA-eligible with BAA support, HITRUST CSF certified, and supports AWS KMS encryption
- Managed scaling — handles ingestion, storage, and query scaling automatically. No capacity planning required
Cons
- Most expensive option — $0.10/GB/month for storage and $0.07 per 1,000 read operations. For 10M resources (approximately 100GB), annual storage alone is $12K — 3x Google's pricing
- Slower search performance — HealthLake's search is notably slower than HAPI FHIR or Google Healthcare API for complex queries. Aggregate searches across large datasets can take 10-30 seconds
- Limited FHIR features — some advanced FHIR capabilities (subscriptions, extended operations) are not fully supported. Bulk export works but is slower than alternatives
- AWS lock-in — deeply tied to the AWS ecosystem. Migrating away requires re-architecting data pipelines
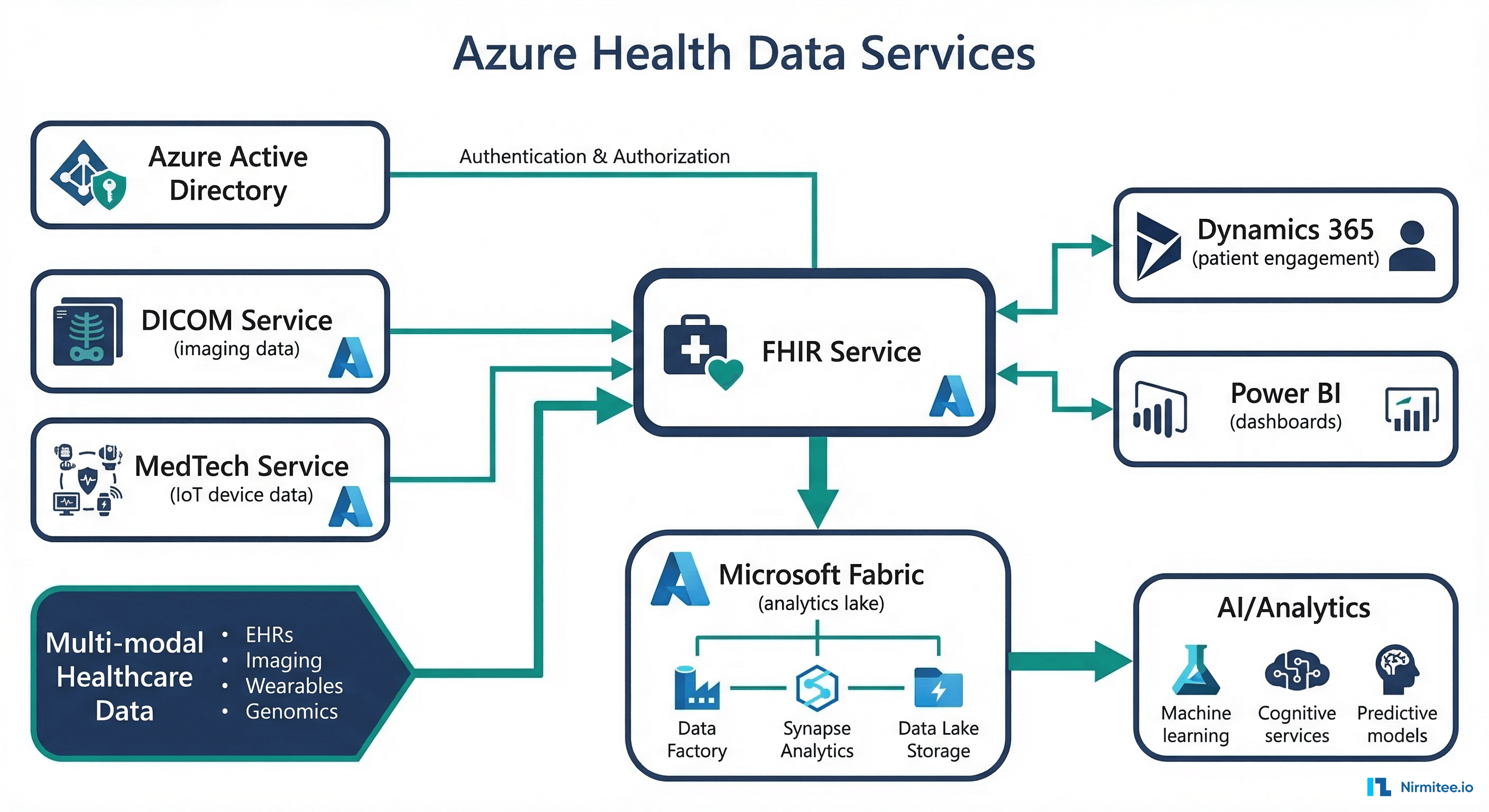
Option 4: Azure Health Data Services
Architecture
Azure Health Data Services is Microsoft's healthcare data platform, offering FHIR, DICOM, and MedTech (IoT) services in a unified namespace. Its differentiator is deep integration with Microsoft Fabric for lakehouse analytics and Dynamics 365 for patient engagement.
Setup
# Create Azure Health Data Services workspace
az healthcareapis workspace create \
--name "my-health-workspace" \
--resource-group "my-rg" \
--location "eastus"
# Create FHIR service
az healthcareapis fhir-service create \
--name "my-fhir" \
--workspace-name "my-health-workspace" \
--resource-group "my-rg" \
--kind "fhir-R4" \
--authentication-authority "https://login.microsoftonline.com/tenant-id" \
--authentication-audience "https://my-health-workspace-my-fhir.fhir.azurehealthcareapis.com"
# Create DICOM service (for imaging alongside FHIR)
az healthcareapis dicom-service create \
--name "my-dicom" \
--workspace-name "my-health-workspace" \
--resource-group "my-rg"
# Query FHIR via REST
FHIR_URL="https://my-health-workspace-my-fhir.fhir.azurehealthcareapis.com"
TOKEN=$(az account get-access-token --resource=$FHIR_URL --query accessToken -o tsv)
curl -X GET "$FHIR_URL/Patient?name=Smith" \
-H "Authorization: Bearer $TOKEN"Pros
- DICOM + FHIR in one platform — unique among managed services. Store imaging data alongside clinical data, linked by patient ID. Critical for radiology, cardiology, and pathology use cases
- Microsoft Fabric integration — export FHIR data to Fabric OneLake for lakehouse analytics. Combines with Power BI for clinical dashboards without a separate ETL
- MedTech/IoT ingestion — ingest device data (vitals monitors, wearables) and convert to FHIR Observation resources automatically
- Dynamics 365 integration — connect clinical data to patient engagement, scheduling, and CRM workflows
- Azure AD authentication — native integration with enterprise identity providers that most health systems already use
Cons
- Complex pricing model — based on throughput units (RU/s) rather than per operation. Capacity planning is confusing, and over-provisioning is expensive
- Microsoft ecosystem dependency — best value when you are fully invested in Azure, Fabric, Dynamics 365, and Teams. Less compelling as a standalone FHIR store
- Newer service — less community knowledge, fewer third-party integrations, and fewer reference architectures compared to HAPI FHIR or Google Healthcare API
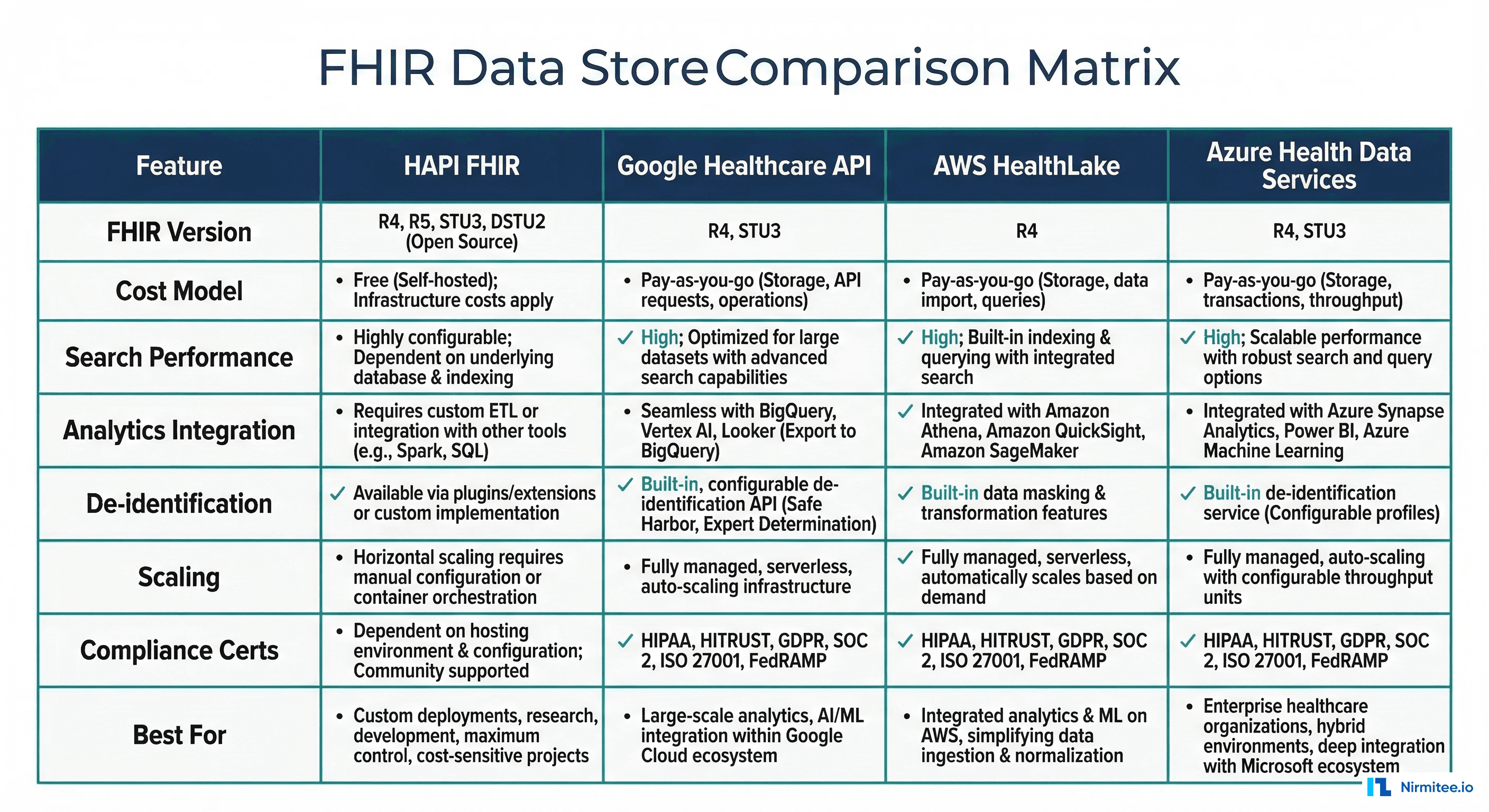
Head-to-Head Comparison
| Feature | HAPI FHIR | Google Healthcare API | AWS HealthLake | Azure Health Data |
|---|---|---|---|---|
| FHIR Version | R4, R5 (preview) | R4 | R4 | R4 |
| License/Cost | Free (Apache 2.0) | $0.05/1K ops | $0.07/1K reads, $0.10/GB | Throughput units |
| Management | Self-managed | Fully managed | Fully managed | Fully managed |
| Search Speed | Fast (tuned PG) | Fast | Moderate | Fast |
| Analytics | Build your own | BigQuery (streaming) | Athena (batch export) | Fabric (streaming) |
| De-identification | Third-party | Built-in (Safe Harbor) | Not built-in | FHIR anonymizer tool |
| NLP | Not included | Not included | Comprehend Medical | Not included |
| DICOM Support | No | Yes (separate store) | No | Yes (same workspace) |
| Bulk Export | Yes ($export) | Yes ($export + GCS) | Yes ($export + S3) | Yes ($export + Blob) |
| SMART on FHIR | Yes (with config) | Yes | Partial | Yes |
| Best For | Full control, multi-cloud | Analytics-heavy, GCP | NLP enrichment, AWS | DICOM+FHIR, Microsoft |
Cost Comparison: 10M Resources Stored
| Cost Category | HAPI FHIR | Google Healthcare API | AWS HealthLake | Azure Health Data |
|---|---|---|---|---|
| Storage (100GB) | $2,400/yr (RDS) | $4,800/yr | $12,000/yr | $6,000/yr |
| Operations (1M/day) | $0 (self-hosted) | $18,250/yr | $25,550/yr | $14,400/yr (RUs) |
| Compute | $14,400/yr (EC2) | $0 (included) | $0 (included) | $0 (included) |
| Analytics add-on | $6,000/yr (self-built) | $3,600/yr (BigQuery) | $4,800/yr (Athena) | $7,200/yr (Fabric) |
| DevOps staff | $80,000/yr (0.5 FTE) | $0 | $0 | $0 |
| Total Annual | $102,800 | $26,650 | $42,350 | $27,600 |
Note: HAPI FHIR has zero licensing cost, but the DevOps overhead is significant. If your organization already has a Kubernetes team managing other services, the incremental cost of running HAPI FHIR drops to ~$23K/year, making it the cheapest option. For organizations without dedicated DevOps, Google Cloud Healthcare API offers the best value.
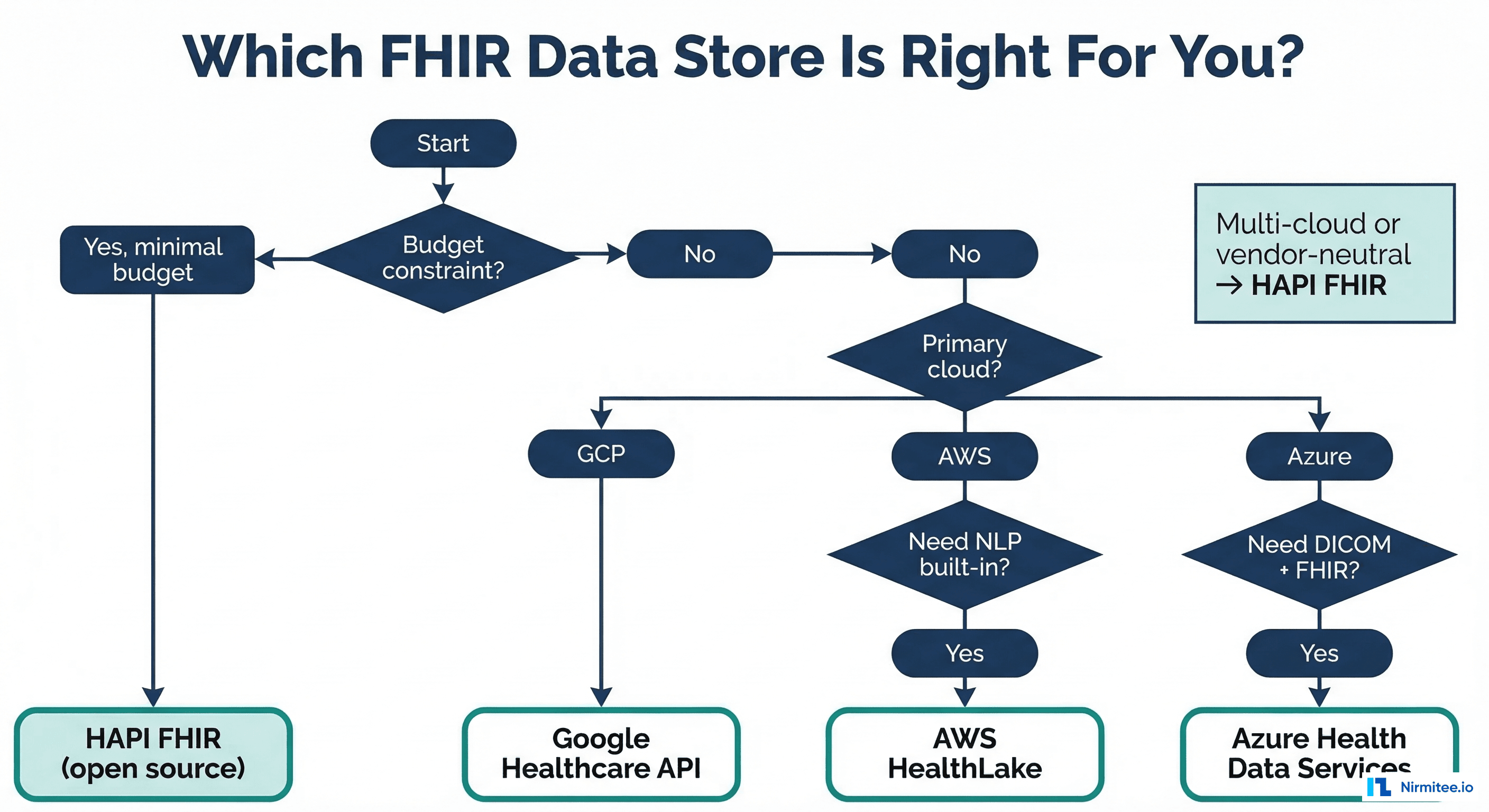
Decision Framework
Choose HAPI FHIR If:
- You need maximum control over FHIR server behavior (custom search parameters, interceptors, validation rules)
- You are multi-cloud or on-premises and cannot commit to a single cloud vendor
- You have an existing DevOps/SRE team that can manage the infrastructure
- Budget is extremely constrained, and you prefer capital-expense (staff) over operational-expense (cloud bills)
- You are building a FHIR server from scratch and want to learn the internals
Choose Google Cloud Healthcare API If:
- Your primary use case is analytics on clinical data — BigQuery streaming export is unmatched
- You need built-in de-identification for research datasets
- You are already invested in GCP (BigQuery, Vertex AI, Looker)
- You want the lowest managed-service cost for moderate workloads
Choose AWS HealthLake If:
- You need NLP enrichment — automatically extract structured data from unstructured text in FHIR resources
- Your organization is all-in on AWS, and you want native integration with S3, SageMaker, and QuickSight
- You work with healthcare ISVs that build on AWS (the largest healthcare cloud ecosystem)
- Read about how NLP enrichment connects to healthcare data liberation strategies
Choose Azure Health Data Services If:
- You need FHIR + DICOM in one platform (radiology, pathology, cardiology imaging)
- Your organization uses Microsoft Fabric for enterprise analytics
- You need IoT/device data ingestion alongside clinical FHIR data
- You are already invested in Azure AD, Dynamics 365, and Teams for your clinical workforce
FAQ: FHIR Data Store Selection
Can I migrate between FHIR data stores?
Yes, because FHIR is a standard format. Export your data as NDJSON using $export, then import into the new store. The challenge is not data format — it is re-configuring search parameters, access controls, subscriptions, and downstream integrations. Budget 2-4 weeks for migration of a production FHIR store with 10M+ resources.
Which option is best for SMART on FHIR apps?
HAPI FHIR provides the most complete SMART on FHIR implementation. Google and Azure support SMART on FHIR through their identity platforms. AWS HealthLake has limited SMART on FHIR support — you may need to implement the authorization server separately using custom SMART auth.
How do these options handle FHIR Subscriptions?
HAPI FHIR supports FHIR Subscriptions natively (websocket, REST hook, email). Google uses Pub/Sub for notifications. Azure supports Event Grid notifications. AWS HealthLake does not support FHIR Subscriptions — use CloudWatch Events or S3 event notifications as alternatives.
What about performance for Bulk Data Export?
For a 10M resource store, expect export times of: HAPI FHIR: 15-30 minutes (depends on PostgreSQL performance), Google: 10-20 minutes (optimized export pipeline), AWS HealthLake: 30-60 minutes (slower), Azure: 15-25 minutes. All produce NDJSON files suitable for ingestion into a medallion architecture.
Do I need a FHIR data store if I already have an EHR?
Usually yes. Your EHR (Epic, Cerner, Meditech) provides a FHIR API for reading data, but it is not designed as a general-purpose data store for your custom applications. A separate FHIR store lets you aggregate data from multiple EHR instances, store data from non-EHR sources (wearables, patient-reported outcomes), and build custom interoperability solutions without impacting EHR performance.
Conclusion: Start with Your Cloud, Graduate to HAPI
For most healthcare startups and mid-size organizations, start with the managed FHIR service on your primary cloud — Google Healthcare API for GCP shops, Azure Health Data Services for Microsoft shops, and AWS HealthLake for AWS shops. Managed services eliminate the operational burden and let your engineering team focus on building clinical applications.
As you scale beyond 50M resources, encounter performance limitations, or need deep customization, graduate to HAPI FHIR running on Kubernetes. The open-source platform gives you unlimited control and eliminates per-operation costs that compound at scale.
At Nirmitee, we have deployed FHIR data stores across all four platforms for healthcare organizations ranging from digital health startups to multi-hospital systems. Contact our team for a free FHIR infrastructure assessment based on your specific requirements and constraints.