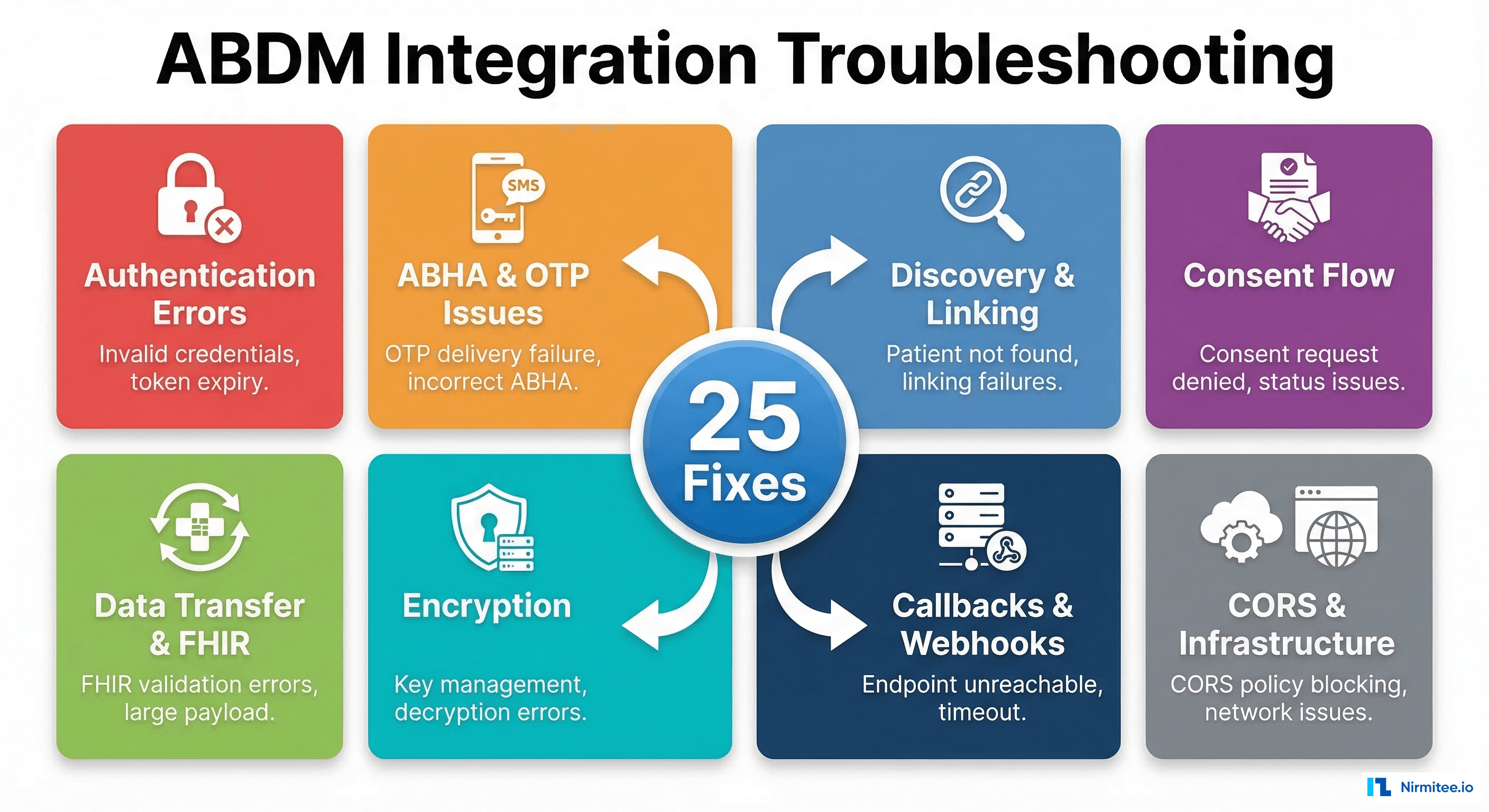
The 80/20 Problem: Most Clinical Data Is Invisible to Analytics
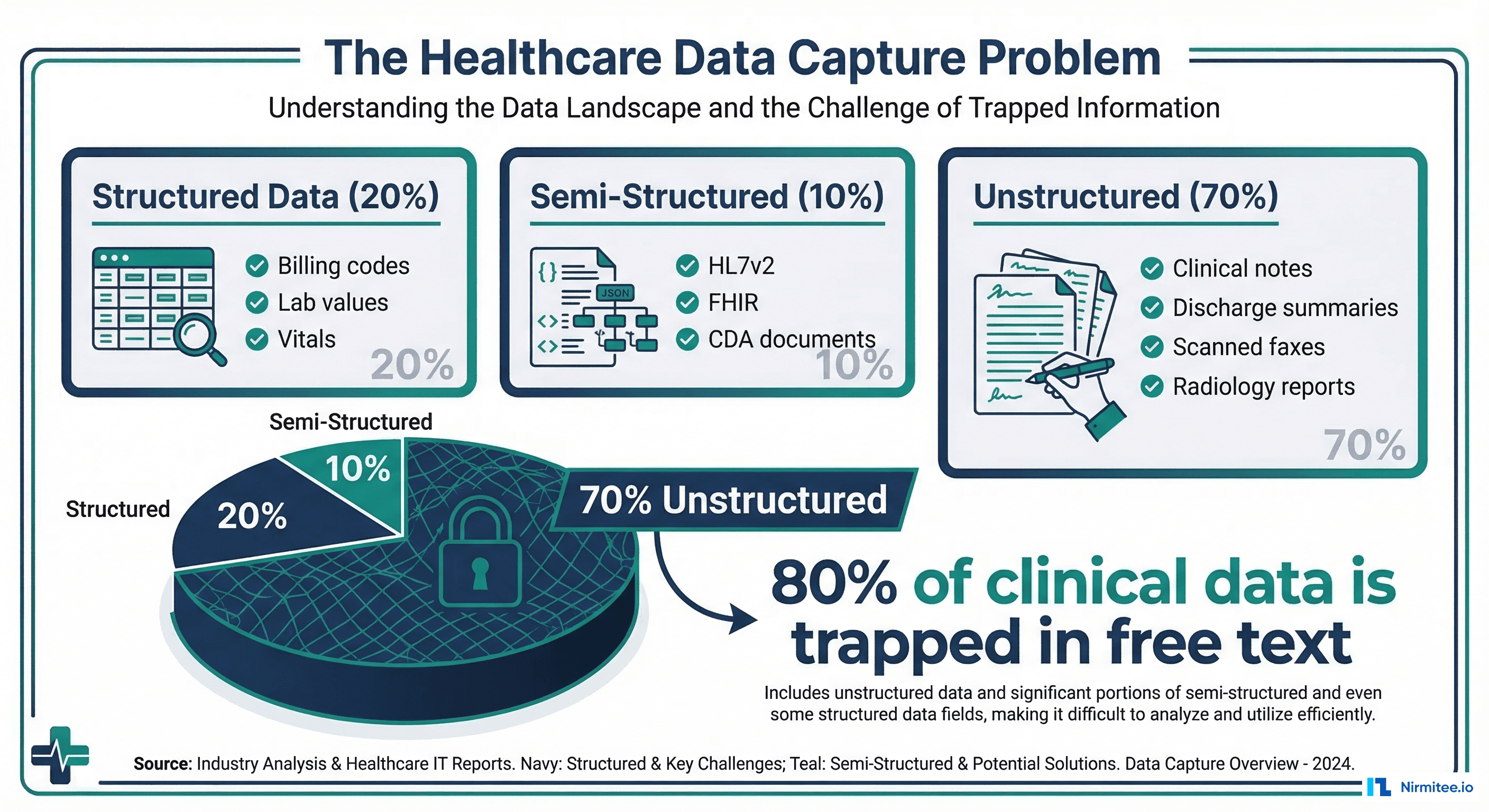
Here is a number that should alarm every health system CIO: 80% of clinical data exists as unstructured free text — physician notes, discharge summaries, radiology reports, pathology results, nursing assessments, and scanned documents. This data contains the richest clinical context — the nuances of patient presentation, clinical reasoning, differential diagnoses, and treatment responses — yet it is effectively invisible to analytics, quality reporting, and AI systems.
A 2024 study in the Journal of the American Medical Informatics Association (JAMIA) found that structured EHR data captures only 20% of the clinical picture. The remaining 80% — trapped in free text — includes critical information like symptom severity, functional status, social determinants of health, and clinical uncertainty that never makes it into coded fields.
This is not just a data problem. It is a care quality problem, a revenue problem, and an AI readiness problem. You cannot train readmission prediction models, calculate accurate quality measures, or enable clinical decision support when four-fifths of the clinical signal is locked in unstructured text.
Why Clinical Data Capture Is Broken
The Documentation Burden Crisis
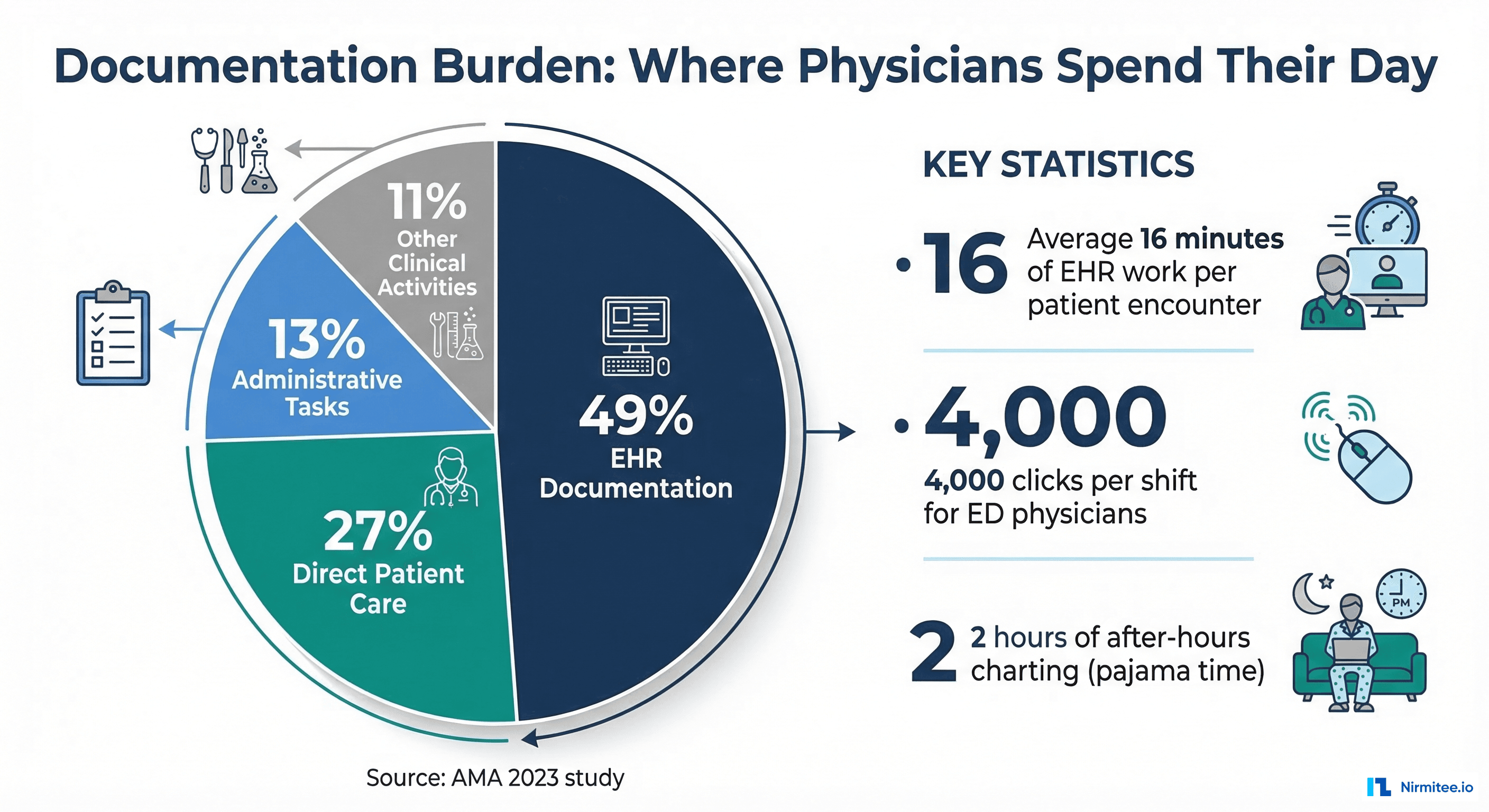
The root cause of the data capture problem is the documentation burden imposed on clinicians. A landmark 2023 AMA study found that physicians spend 49% of their workday on EHR documentation — nearly half their professional time goes to the computer, not the patient.
The numbers are stark:
- 16 minutes of EHR work per patient encounter — for a physician seeing 20 patients/day, that is 5.3 hours of documentation
- 4,000 mouse clicks per shift for emergency department physicians (JAMIA, 2022)
- 1-2 hours of after-hours charting ("pajama time") — completing notes at home after the clinical day ends
- 28% physician burnout rate directly attributed to documentation burden (Medscape 2024 survey)
Despite this enormous time investment, the structured data captured through EHR forms represents only a fraction of the clinical encounter. The physician's mental model — their clinical reasoning, differential diagnosis, assessment of severity, and treatment rationale — gets expressed in free-text notes because structured forms cannot accommodate clinical complexity.
The Three Types of Healthcare Data
Understanding the data capture problem requires distinguishing three categories:
| Category | Percent of Clinical Data | Examples | Capture Method | Analytics Readiness |
|---|---|---|---|---|
| Structured | ~20% | ICD codes, CPT codes, lab values, vitals, medication orders | EHR forms, dropdown menus | Immediately queryable |
| Semi-Structured | ~10% | HL7v2 messages, FHIR resources, CDA documents, XML reports | Interface engines, API integrations | Requires parsing/transformation |
| Unstructured | ~70% | Clinical notes, discharge summaries, radiology reports, faxes, scanned PDFs | Dictation, typing, scanning | Requires NLP/AI extraction |
The semi-structured category (HL7v2, FHIR) is often overlooked. While HL7 and FHIR data has a defined structure, parsing it at scale — handling version differences, local extensions, and edge cases across dozens of sending systems — is a significant integration engineering challenge.
Strategy 1: NLP Extraction from Existing Clinical Text
How It Works
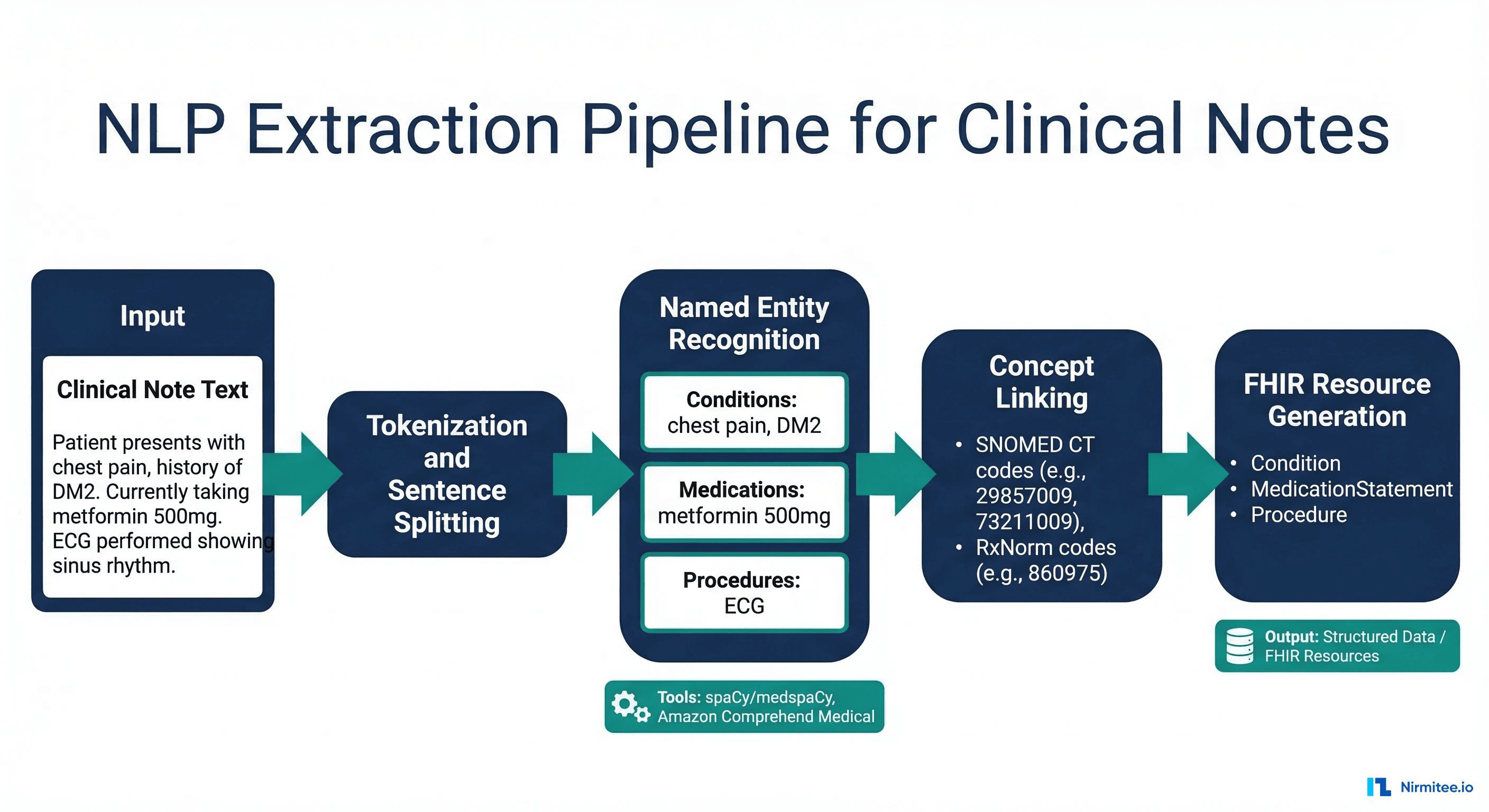
Natural Language Processing (NLP) extracts structured data from existing clinical notes retrospectively. The pipeline reads free-text notes, identifies clinical entities (diagnoses, medications, procedures, lab values), links them to standard terminologies (SNOMED CT, RxNorm, LOINC), and generates structured FHIR resources.
Implementation Architecture
import spacy
import medspacy
from medspacy.ner import TargetRule
from medspacy.context import ConTextRule
# Load clinical NLP pipeline
nlp = medspacy.load(enable=["sentencizer", "target_matcher", "context"])
# Add clinical entity rules
target_rules = [
TargetRule("diabetes", "CONDITION", pattern=[{"LOWER": "diabetes"}]),
TargetRule("diabetes", "CONDITION", pattern=[{"LOWER": "dm2"}]),
TargetRule("hypertension", "CONDITION", pattern=[{"LOWER": "htn"}]),
TargetRule("metformin", "MEDICATION", pattern=[{"LOWER": "metformin"}]),
TargetRule("chest pain", "SYMPTOM",
pattern=[{"LOWER": "chest"}, {"LOWER": "pain"}]),
]
nlp.get_pipe("target_matcher").add(target_rules)
# Context detection (negation, historical, family history)
context_rules = [
ConTextRule("no evidence of", "NEGATED_EXISTENCE", direction="forward"),
ConTextRule("denies", "NEGATED_EXISTENCE", direction="forward"),
ConTextRule("family history of", "FAMILY", direction="forward"),
ConTextRule("history of", "HISTORICAL", direction="forward"),
]
nlp.get_pipe("context").add(context_rules)
def extract_clinical_entities(note_text):
doc = nlp(note_text)
entities = []
for ent in doc.ents:
entities.append({"text": ent.text, "label": ent.label_,
"is_negated": ent._.is_negated,
"is_historical": ent._.is_historical})
return entities
# Example
note = "Patient presents with chest pain. History of DM2 on metformin. Denies SOB."
results = extract_clinical_entities(note)
# Returns: chest pain (SYMPTOM, active), DM2 (CONDITION, historical),
# metformin (MEDICATION, active), SOB (SYMPTOM, negated)Cloud-Based Alternative: Amazon Comprehend Medical
import boto3
comprehend = boto3.client("comprehend-medical", region_name="us-east-1")
def extract_with_comprehend(note_text):
response = comprehend.detect_entities_v2(Text=note_text)
entities = []
for entity in response["Entities"]:
entities.append({
"text": entity["Text"],
"category": entity["Category"],
"type": entity["Type"],
"score": entity["Score"],
"traits": [t["Name"] for t in entity.get("Traits", [])],
})
return entities
# Comprehend Medical automatically detects:
# - Medical conditions with ICD-10 mapping
# - Medications with RxNorm mapping, dosage, frequency
# - Tests/procedures with CPT mapping
# - Negation and temporality
# Cost: $0.01 per 100 charactersStrategy 2: Ambient AI Scribes — Capture at the Point of Care
How It Works
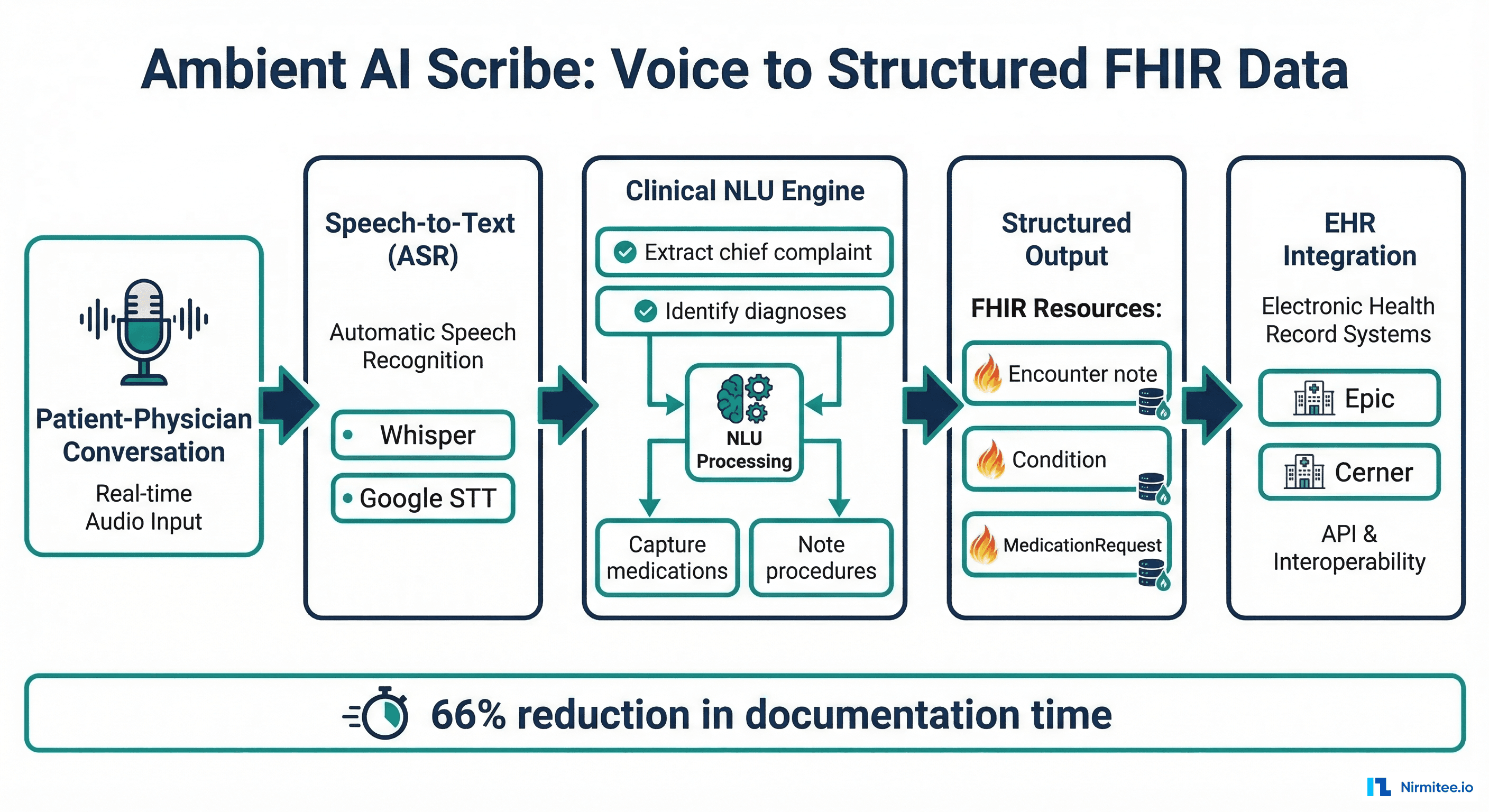
Ambient clinical documentation systems listen to the patient-physician conversation (with consent), transcribe it, extract clinical information, and generate structured documentation in real-time. The physician reviews and signs the note — but the heavy lifting of documentation is automated.
This is the most promising data liberation strategy because it captures data at the source without adding burden. The physician's natural conversation becomes the input, and structured FHIR resources are the output.
Architecture for Voice-to-FHIR
import whisper
# Step 1: Speech-to-text
whisper_model = whisper.load_model("large-v3")
def transcribe_encounter(audio_path):
result = whisper_model.transcribe(audio_path, language="en")
return result["text"], result["segments"]
# Step 2: Clinical NLU - extract structured data
def extract_clinical_data(transcript):
prompt = f"""Extract clinical information from this encounter transcript.
Return JSON with: chief_complaint, diagnoses (with ICD-10),
medications (with dose/frequency), procedures, assessment, plan.
Transcript: {transcript[:2000]}"""
result = clinical_llm.generate(prompt, max_tokens=1000)
return json.loads(result)
# Step 3: Generate FHIR Condition resources
def to_fhir_condition(diagnosis, patient_id, encounter_id):
return {
"resourceType": "Condition",
"subject": {"reference": f"Patient/{patient_id}"},
"encounter": {"reference": f"Encounter/{encounter_id}"},
"code": {
"coding": [{
"system": "http://hl7.org/fhir/sid/icd-10-cm",
"code": diagnosis["icd10_code"],
"display": diagnosis["description"]
}]
},
"clinicalStatus": {"coding": [{"code": "active"}]}
}Leading ambient AI scribe platforms include Nuance DAX Copilot (Microsoft/Epic integration), Suki AI, Abridge, and Nabla. Studies show a 66% reduction in documentation time with ambient clinical documentation.
Strategy 3: Smart Forms — Progressive Disclosure
How It Works
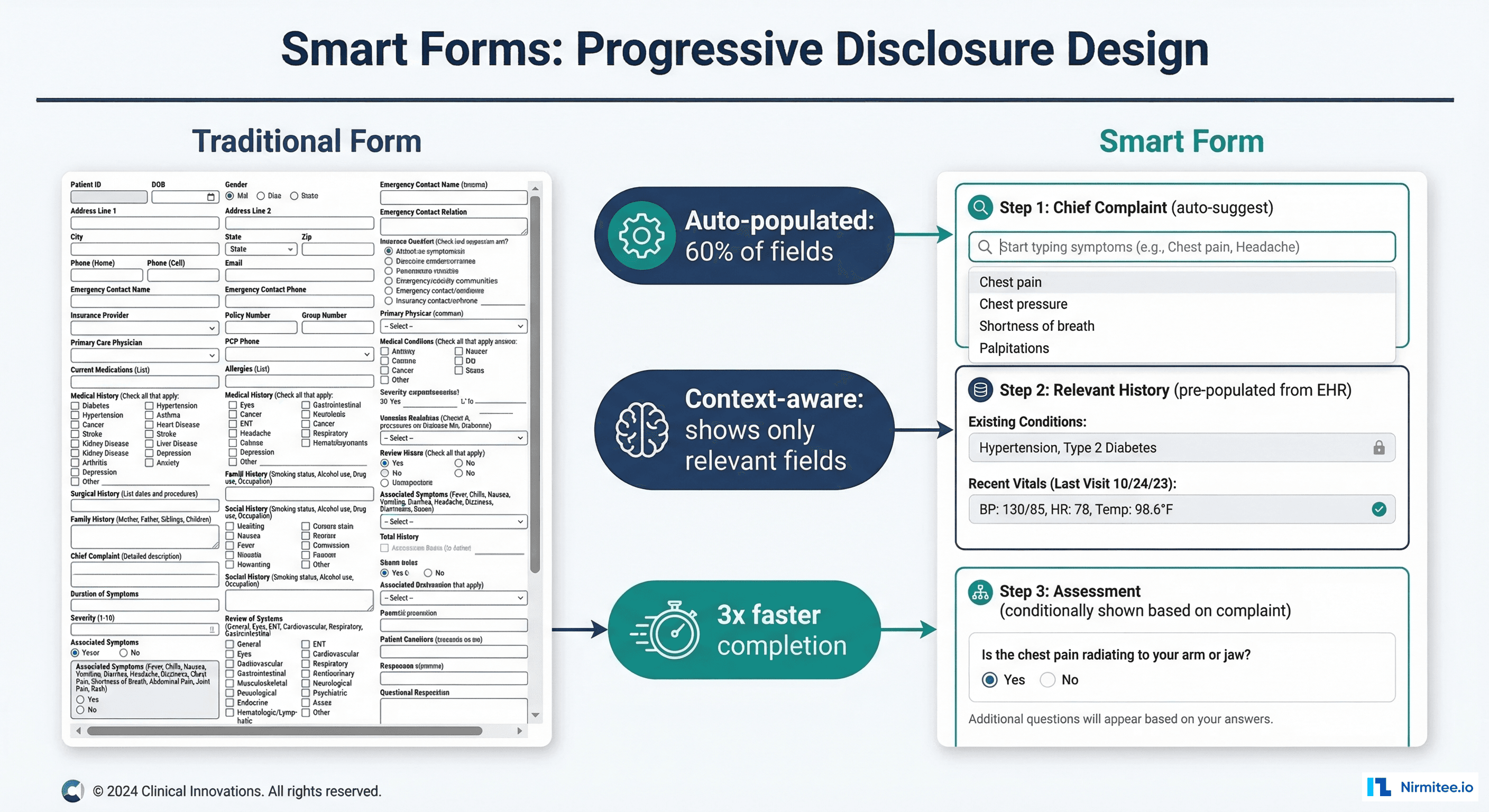
Smart forms capture structured data at the point of care by reducing cognitive load through progressive disclosure. Instead of presenting clinicians with 50-field forms, smart forms show only the fields relevant to the current clinical context, pre-populate known data from the patient record, and use auto-suggest based on partial input.
Design Principles for Clinical Smart Forms
// Smart form engine: progressive disclosure with FHIR pre-population
const SmartFormEngine = {
// Rule: show fields based on chief complaint
fieldRules: {
"chest_pain": {
show: ["onset", "severity", "character", "radiation",
"cardiac_history", "troponin_result"],
hide: ["wound_description", "fracture_location"],
prepopulate: {
"cardiac_history": "GET /Condition?patient=123&code=I25,I21",
"current_meds": "GET /MedicationRequest?patient=123&status=active",
"last_troponin": "GET /Observation?patient=123&code=6598-7&_sort=-date"
}
}
},
// Auto-suggest using FHIR terminology service
autoSuggest: async function(field, input) {
const resp = await fetch(
`https://tx.fhir.org/r4/ValueSet/$expand?filter=${input}&count=10`
);
return resp.json();
}
};Strategy 4: Clinical Documentation Improvement (CDI) Programs
How It Works
CDI programs improve the specificity and accuracy of clinical documentation after the encounter. CDI specialists (typically RNs or HIM professionals) review clinical notes, identify documentation gaps that affect coding accuracy, and query physicians for clarification.
Modern CDI programs use AI to automate query generation:
def generate_cdi_query(note_text, assigned_drg):
prompt = f"""Review this clinical note and current DRG assignment.
Identify documentation opportunities where clarification
could improve coding specificity.
Current DRG: {assigned_drg}
Clinical Note: {note_text[:3000]}
Generate a physician query with:
1. Clinical evidence supporting a more specific diagnosis
2. Specific question for the physician
3. Impact on coding/reimbursement"""
response = clinical_llm.generate(prompt, max_tokens=500)
return response
# Example output:
# "Clinical evidence: BNP 1,250, bilateral rales, CXR pulmonary edema.
# Currently documented as 'heart failure'.
# Query: Can you specify the type (systolic/diastolic) and acuity?
# Impact: DRG 293 -> DRG 291, difference ~$4,200 per case."Choosing the Right Strategy: Decision Framework
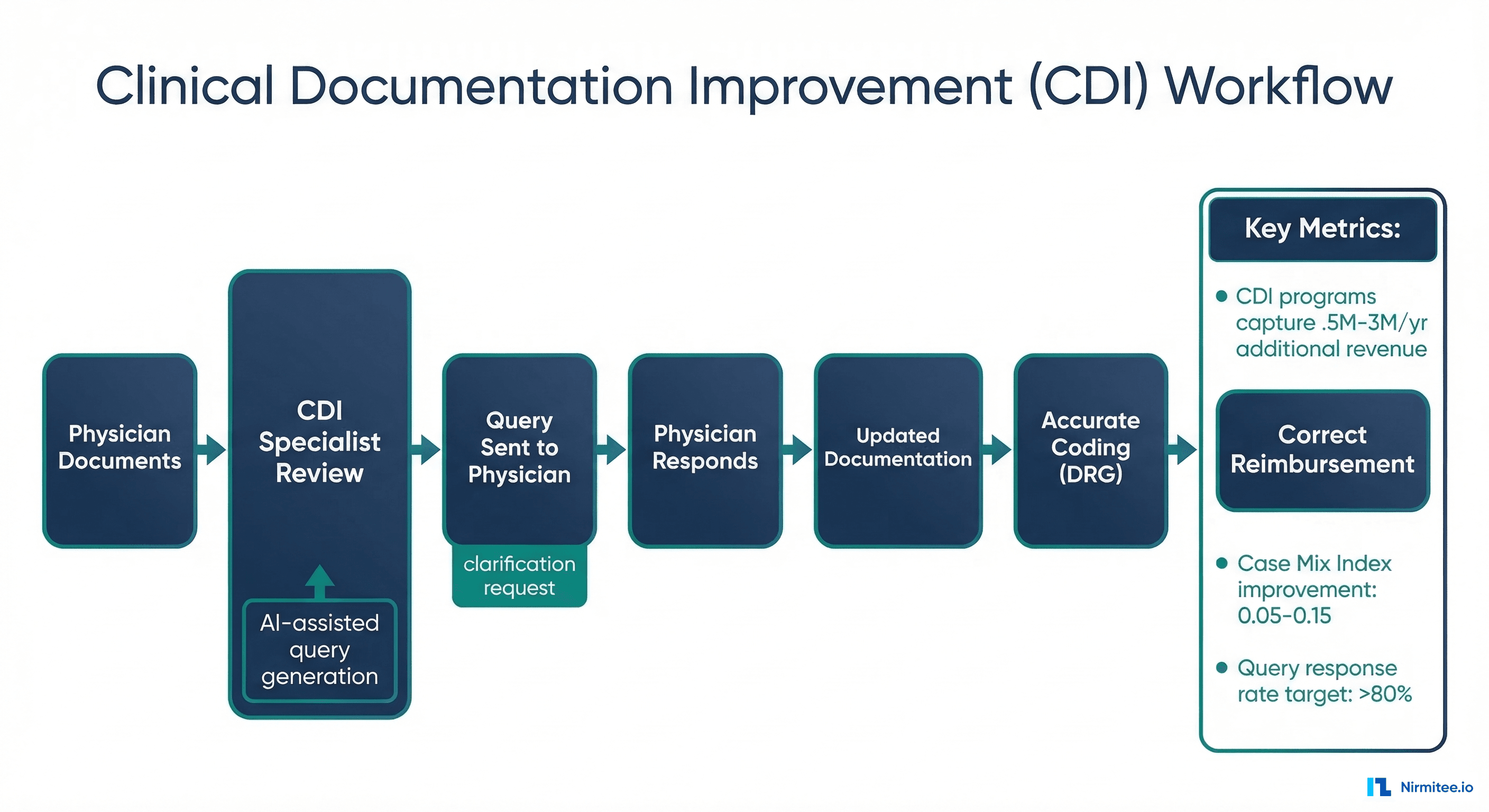
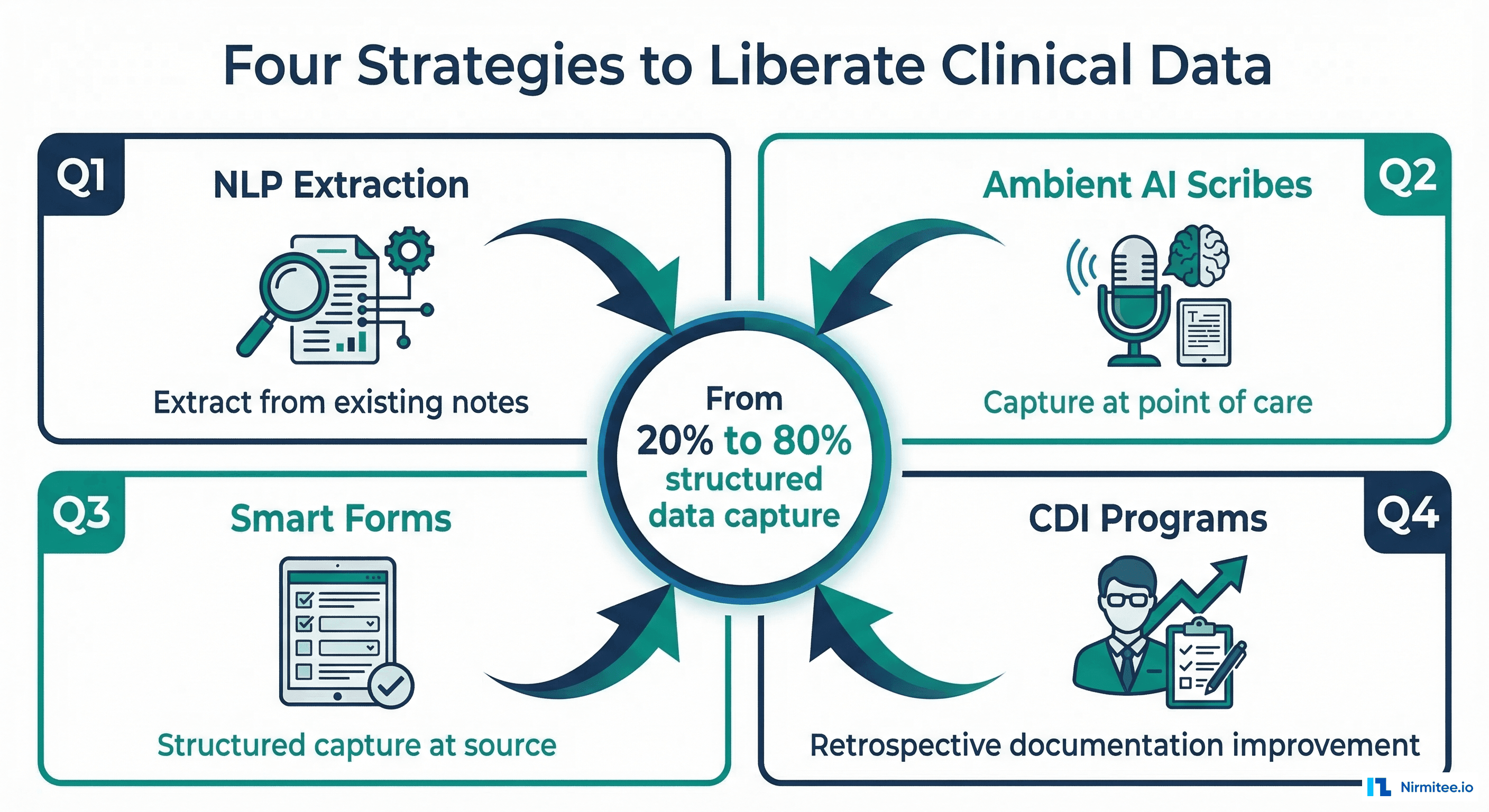
| Dimension | NLP Extraction | Ambient AI Scribe | Smart Forms | CDI Program |
|---|---|---|---|---|
| When captured | Retrospective | Real-time | Real-time | Retrospective |
| Physician workflow change | None | Minimal | Moderate | Minimal |
| Implementation cost | $100K-300K | $200K-500K | $150K-400K | $50K-150K + staff |
| Time to value | 3-6 months | 6-12 months | 3-6 months | 1-3 months |
| Data quality | Medium (85-92%) | High (physician reviewed) | High (structured) | Medium (coding-focused) |
| Annual ROI | $500K-1M | $1M-2M | $800K-1.5M | $1.5M-3M |
| Best for | Research, retrospective | Burnout reduction + data | Specific workflows | Revenue cycle |
Recommended Approach by Organization Type
- Community hospital (under 200 beds): Start with CDI program (fastest ROI) + smart forms for high-volume departments (ED, primary care).
- Mid-size health system (200-500 beds): CDI program + ambient AI scribe pilot in 2-3 departments + NLP extraction for research. Build on your data architecture to store extracted data.
- Large academic medical center (500+ beds): All four strategies simultaneously. NLP for the research data warehouse, ambient AI for clinical departments, smart forms for specialized workflows, and CDI for revenue optimization. Feed everything into a medallion architecture.
FAQ: Healthcare Data Capture
How accurate is clinical NLP extraction?
Modern clinical NLP systems achieve 85-95% F1 scores for named entity recognition on standard benchmarks (i2b2, n2c2). Amazon Comprehend Medical reports 92% accuracy for medication extraction and 89% for condition detection. Accuracy varies by note type — discharge summaries are easier than progress notes. Always validate NLP output with clinician review for clinical decision-making use cases.
Do ambient AI scribes work with EHR systems?
Yes. Nuance DAX Copilot has native Epic integration. Suki integrates with Epic, Cerner, and athenahealth. Abridge has Epic and Cerner connectors. Integration typically works via SMART on FHIR launch or HL7v2 interface. See our guide on EHR integration patterns.
What is the ROI of a CDI program?
ACDIS reports that mature CDI programs generate $1.5M-3M annually in additional revenue for a 300-bed hospital through improved coding specificity. The ROI comes from DRG upgrades, reduced claim denials, and improved case mix index.
How does this relate to AI model training?
Structured data extraction is a prerequisite for training healthcare AI models. You cannot build a readmission prediction model if 80% of the clinical signal is trapped in free text. Each liberation strategy feeds data into your data lakehouse, making it available for ML model training.
Is patient consent required for ambient AI scribes?
Yes. All ambient documentation systems require explicit patient consent before recording. Most implementations use a verbal consent model — the physician informs the patient that the visit will be recorded for documentation purposes. Consent rates are typically 95%+ when physicians frame it as improving the visit experience.
Conclusion: The Data Liberation Imperative
Healthcare organizations that fail to liberate their unstructured data will fall behind in three critical areas: AI-driven care delivery, value-based payment performance, and clinical research capability. The 80% of clinical data trapped in free text is not a technical footnote — it is the difference between analytics that reflect clinical reality and analytics built on 20% of the picture.
The good news: the tooling has matured dramatically. Clinical NLP achieves 90%+ accuracy, ambient AI scribes reduce documentation time by 66%, and CDI programs deliver proven ROI. The question is not whether to invest in data liberation, but which strategy to start with.
At Nirmitee, we help healthcare organizations design and implement data capture strategies that convert unstructured clinical data into actionable, structured FHIR resources. Contact us to discuss your data liberation roadmap.