If you've spent any time in health IT architecture discussions over the past five years, you've almost certainly encountered the "FHIR vs openEHR" debate. The openEHR Discourse thread on this topic alone has surpassed 1,000 replies — a testament to how passionately the community feels about these two standards. But after years of building production healthcare systems, watching the HL7-openEHR collaboration formalize at the June 2025 Amsterdam workshop, and observing NHS England's dual-standard architecture evolve, we're confident in saying: the debate itself is the problem.
FHIR and openEHR don't compete. They solve fundamentally different problems in the healthcare data lifecycle. And the most resilient, future-proof health data architectures use both. This article explains why, shows you how, and gives you a concrete decision framework for your next implementation.
The False Binary: Why "FHIR vs openEHR" Is the Wrong Question
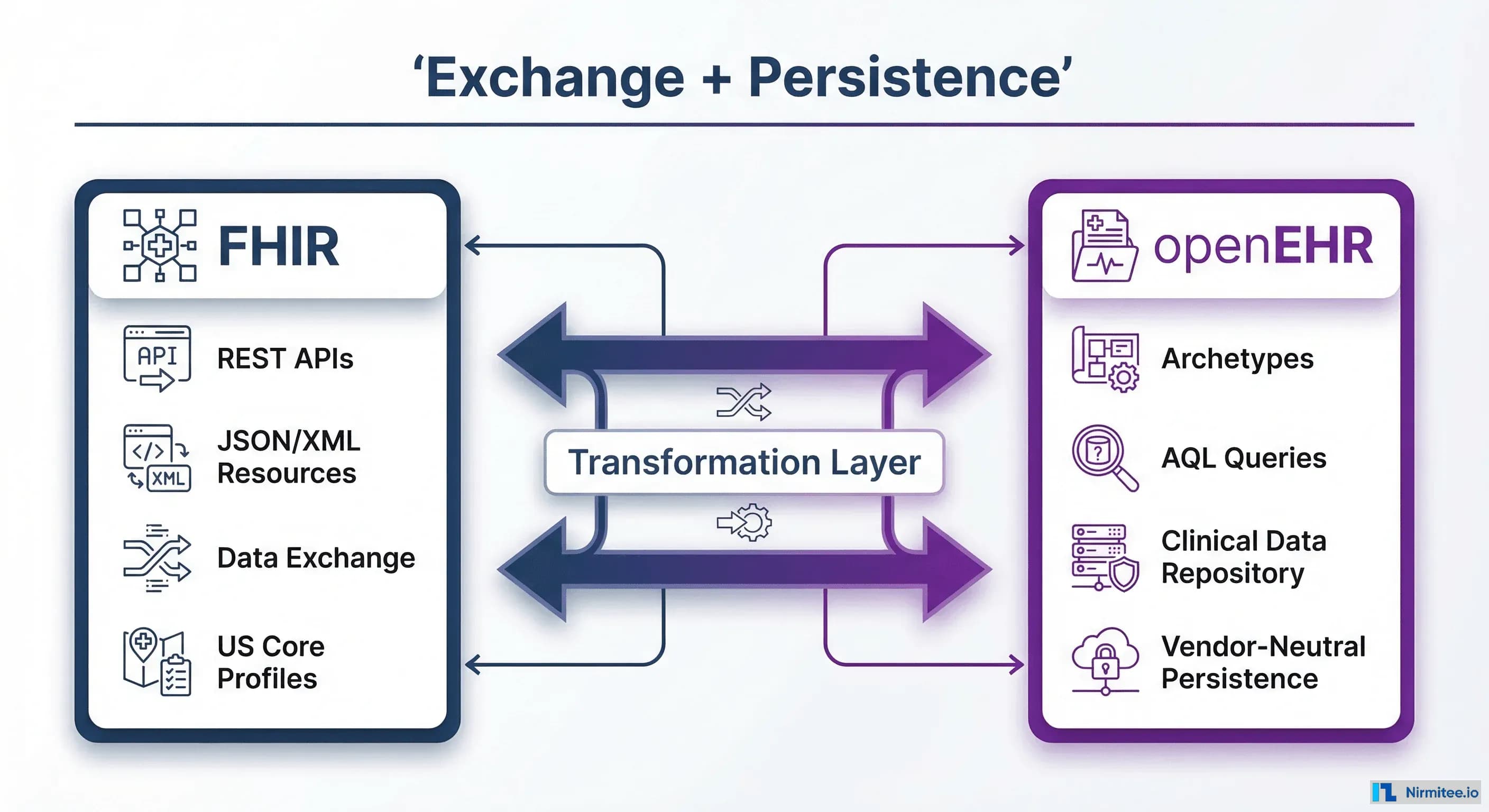
The FHIR vs openEHR debate persists because both standards touch clinical data, and at a surface level, both define how health information should be structured. But the comparison is akin to debating "HTTP vs PostgreSQL." One is a communication protocol; the other is a persistence layer. They operate at different levels of the architecture stack.
FHIR (Fast Healthcare Interoperability Resources) is an exchange standard. It defines how clinical data moves between systems — the wire format, the API contracts, the authorization model (SMART on FHIR), and the search semantics. When CMS mandates FHIR-based Patient Access APIs, they're mandating how data flows out of a system, not how it's stored inside one.
openEHR is a persistence and modeling standard. It defines how clinical data is structured for long-term storage, queried with clinical precision, and evolved over decades without breaking downstream consumers. When a clinician needs to retrieve a patient's complete blood pressure history across 15 years of care — including the exact clinical context, measurement method, and body position — that's an openEHR problem.
In June 2025, this complementary relationship was formally recognized when openEHR International and HL7 International held a landmark two-day workshop in Amsterdam. The joint press release identified five strategic collaboration areas, including aligning clinical content models, standardizing transformation tooling, and identifying clinical domains where dual use delivers the most benefit. As the press release stated, dedicated teams from both organizations are now working on these areas, with progress reviews planned for mid-2026.
The question isn't "which standard should we use?" The question is: "what does each layer of our architecture need?"
What FHIR Does Best (And Where It Falls Short)
FHIR has become the lingua franca of health data exchange, and for good reason. It provides a REST-native API design that any developer with web experience can understand, a resource model (Patient, Observation, Condition, MedicationRequest) that maps intuitively to clinical concepts, an authorization framework (SMART on FHIR) that supports both patient-facing and clinician-facing applications, and a regulatory tailwind — ONC, CMS, and the 21st Century Cures Act have made FHIR adoption effectively mandatory in the US market.
The US regulatory timeline is aggressive and expanding. By January 2026, certified health IT must accommodate USCDI v3 data using FHIR US Core profiles. By July 2026, TEFCA networks must expose data via FHIR APIs aligned with US Core and USCDI v3. The ASTP/ONC's HTI-5 rule released in late 2025 further reoriented the certification program around FHIR-based APIs. For any US health system, FHIR isn't optional — it's table stakes.
FHIR excels at point-in-time data exchange: retrieving a patient's current medications, sharing a discharge summary, supporting a clinical decision support hook, or enabling a patient portal. These are the use cases FHIR was designed for, and it handles them brilliantly.
The Profile Proliferation Problem
But FHIR has a structural limitation that becomes apparent at scale: profile proliferation, or as researchers have coined it, "profiliferation." A comprehensive analysis of the FHIR ecosystem found 1,319 distinct FHIR packages from 602 projects spanning 53 jurisdictions on Simplifier.net. A separate review of nearly 3,000 FHIR profiles from 125 implementation guides found that just two items — Observation and Extension — accounted for half of all profiles.
FHIR's original design philosophy followed an 80/20 rule: the base resources would cover 80% of use cases, with profiling handling the remaining 20%. Research has shown the reality is closer to 65/35, meaning FHIR is significantly more dependent on profiling than its designers intended. Every jurisdiction, every implementation guide, every use case creates its own profiles:
- US Core defines 67+ profiles with Argonaut, Da Vinci (50+ IGs), and CARIN Blue Button layering on top
- UK Core has 98+ profiles with NHS England-specific extensions
- AU Core adds 40+ profiles with ADHA requirements
- Each set is not interoperable with the others by default
The root cause is governance fragmentation. IG authors struggle to find existing profiles that match their needs, hesitate to adopt profiles governed by other organizations, and end up creating new ones — compounding the very problem they're trying to solve. A US Core Patient is not the same as a UK Core Patient, even though both represent the same clinical concept.
This is where openEHR's approach to clinical modeling offers a fundamentally different — and in many ways superior — answer.
What openEHR Does Best (And Where It Falls Short)
openEHR takes a radically different approach to clinical data modeling. Instead of defining resources that approximate clinical concepts (as FHIR does), openEHR separates the reference model (a small, stable set of data types and structures) from archetypes (clinician-authored, maximal models of clinical concepts) and templates (local constraints on archetypes for specific use cases).
This separation of concerns is openEHR's superpower. A blood pressure archetype defines every possible way blood pressure can be recorded across clinical practice — systolic, diastolic, mean arterial, body position, cuff size, measurement method, exertion level, tilt angle. It's authored by clinicians, not engineers, through a formal governance process at the international Clinical Knowledge Manager (CKM). When a hospital needs to record blood pressure, they create a template that constrains the archetype to just the data points their workflow requires — but the underlying structure remains consistent globally.
The practical benefits are significant:
- Query power: openEHR's Archetype Query Language (AQL) is SQL-like and can express complex clinical queries that would require multiple chained FHIR searches. A query like "find all patients with systolic BP > 140 measured in standing position over the last 6 months" is a single AQL expression but a multi-step orchestration in FHIR.
- Versioned compositions: Every clinical document is versioned. You can retrieve any historical state, see what changed, who changed it, and when. This isn't just an audit log — it's a complete temporal data model that supports medicolegal requirements.
- Schema evolution without migration: Because archetypes are additive (new optional fields can be added without breaking existing data), the CDR can evolve its clinical models without the painful database migrations that FHIR-backed systems often require.
- Vendor-neutral persistence: Data stored in an openEHR CDR is not locked to any vendor's proprietary schema. Switch CDR vendors (from EHRbase to Better Platform to Ocean Health Systems), and your data, queries, and templates all transfer.
Where openEHR falls short is equally clear: it has no US regulatory mandate. ONC doesn't require it. CMS doesn't reference it. TEFCA doesn't mention it. For a US health system, openEHR is entirely voluntary — which means adoption requires making a business case rather than checking a compliance box. Additionally, the openEHR developer community, while growing, is significantly smaller than the FHIR ecosystem. Finding engineers with openEHR experience requires either training or working with specialized firms — a gap that companies like Nirmitee are actively addressing by building engineering teams with deep expertise in both standards.
openEHR's API surface is also less standardized than FHIR's. While the openEHR REST API specification exists, implementations vary between CDR vendors, and the tooling ecosystem (client libraries, test harnesses, sandboxes) is less mature than FHIR's.
The Dual-Standard Architecture Pattern
The most architecturally sound approach — and the one gaining traction globally — is what we call the dual-standard pattern: FHIR for the exchange layer, openEHR for the persistence layer, with a transformation layer bridging the two.
This isn't theoretical. NHS England's emerging architecture effectively follows this model, with FHIR UK Core profiles governing external data exchange while exploring openEHR-based clinical data repositories for longitudinal patient records. The vitagroup HIP platform commercially implements this pattern with EHRbase (openEHR CDR) and FHIR APIs. Better Platform's FHIR Connect provides a similar bridge.
The architecture looks like this:
┌─────────────────────────────────────────────────┐
│ External Applications Layer │
│ (Patient Apps, CDS Hooks, Payer Systems, │
│ Research Platforms, Referral Networks) │
└──────────────────────┬──────────────────────────┘
│ FHIR R4 REST APIs
│ SMART on FHIR Auth
│ US Core / UK Core Profiles
┌──────────────────────▼──────────────────────────┐
│ FHIR API Gateway Layer │
│ - Resource validation against profiles │
│ - SMART on FHIR authorization │
│ - Bulk FHIR export ($export) │
│ - Subscription notifications │
└──────────────────────┬──────────────────────────┘
│
┌──────────────────────▼──────────────────────────┐
│ Transformation Layer │
│ - FHIR Resource ↔ openEHR Composition mapping │
│ - FHIRconnect DSL / openFHIR engine │
│ - Archetype-to-Profile alignment │
│ - Terminology normalization (SNOMED, LOINC) │
└──────────────────────┬──────────────────────────┘
│
┌──────────────────────▼──────────────────────────┐
│ openEHR Clinical Data Repository │
│ - Archetype-based data persistence │
│ - AQL query engine │
│ - Versioned compositions │
│ - Template governance │
│ - Vendor-neutral storage │
└─────────────────────────────────────────────────┘The Transformation Layer: Where the Work Lives
The critical engineering challenge in the dual-standard pattern is the transformation layer. This is where FHIR Resources are mapped to openEHR Compositions and vice versa. Until recently, this mapping was bespoke for every project — an expensive, error-prone manual process.
Two significant developments have changed this. FHIRconnect, published in late 2025, introduced a formal Domain-Specific Language (DSL) for openEHR-FHIR transformation. Their research demonstrated that a standardized ETL process is feasible and achieved 65% mapping reuse across projects by leveraging international archetype foundations. The initial release mapped 24 international archetypes to 15 FHIR profiles across seven clinical domains.
The open-source openFHIR engine (from Medblocks) provides a RESTful API where consumers can map bidirectionally — from FHIR Resources to openEHR Compositions and back. This dramatically reduces the engineering effort for organizations adopting the dual-standard pattern.
However, the transformation layer is not a solved problem. Current tooling covers only a subset of archetypes and profiles. Complex mappings — particularly around medication management, care plans, and genomics data — still require custom engineering. This is precisely the kind of deep integration work where having a team that understands both standards at the implementation level is essential. At Nirmitee, our engineering teams work across both FHIR and openEHR stacks precisely because we've seen how many projects stall at the transformation layer when teams only know one side.
Why Not Just Use FHIR for Persistence?
A reasonable objection is: "Why not just use a FHIR server (like HAPI FHIR or Microsoft's FHIR Server) for persistence?" Many organizations do. For simpler use cases — patient portals, claims exchange, lab result delivery — a FHIR server as the system of record works fine.
The dual-standard pattern becomes valuable when you need:
- Deep longitudinal queries: "Show me this patient's HbA1c trend over 10 years, correlated with medication changes and dietary interventions" — this requires the kind of structured clinical data model that openEHR provides and FHIR's search parameters struggle with.
- Multi-jurisdictional data: If your patient population spans regulatory boundaries (US + UK, US + EU), openEHR's international archetypes provide a common clinical model that FHIR's jurisdiction-specific profiles do not.
- Research-grade data repositories: Clinical research requires data structures that are far more granular than what FHIR resources typically capture. openEHR archetypes capture the clinical nuance that researchers need.
- True vendor independence: If you want to switch your CDR vendor without a data migration project, openEHR's vendor-neutral persistence is the only standard that guarantees this.
Implementation Decision Framework
Use this decision tree when evaluating your architecture:
Use FHIR Only When:
- Your primary need is data exchange between existing systems (EHR-to-EHR, EHR-to-payer, EHR-to-patient app)
- You're building SMART on FHIR applications that read from existing EHRs
- You need to meet ONC/CMS certification requirements (Patient Access API, Provider Directory, Prior Auth)
- Your data persistence is handled by a commercial EHR (Epic, Cerner/Oracle Health, MEDITECH) and you don't own the data layer
- Your budget is under $500K and your timeline is under 12 months
Use openEHR Only When:
- You're building a greenfield clinical data repository for a health system or health information exchange
- Your primary consumers are clinicians and researchers, not external applications
- You need longitudinal, version-controlled clinical records spanning decades
- You're in a jurisdiction where openEHR has institutional support (parts of Europe, Australia, Brazil)
- You don't have near-term FHIR API compliance requirements
Use the Dual-Standard Pattern When:
- You need both external interoperability (FHIR) and deep clinical persistence (openEHR)
- You're building a platform that must serve both application developers and clinical users
- You need to support multiple jurisdictions with different FHIR profiles but common clinical models
- You're investing in a long-term data strategy (5+ year horizon) where vendor independence matters
- Your budget supports the transformation layer investment (typically $200K-$500K additional for initial implementation)
- You have access to engineering teams with both FHIR and openEHR expertise
Cost Considerations
The dual-standard pattern is not free. Budget for these line items:
- openEHR CDR licensing or hosting: Open-source (EHRbase) is free but requires operational expertise. Commercial (Better Platform, Ocean Health) ranges from $50K-$200K/year depending on scale.
- Transformation layer development: $200K-$500K for initial build using FHIRconnect/openFHIR as a foundation, plus $50K-$100K/year for maintenance and new mapping development.
- Team training: Budget 2-3 months for FHIR-experienced engineers to become productive with openEHR's archetype model, AQL, and template design.
- Ongoing governance: Someone needs to own the archetype-to-profile alignment as both standards evolve. This is typically a 0.5-1.0 FTE clinical informaticist role.
Real-World Implementation: Lessons From Building With Both
Having built systems that implement both standards, here are the hard-won lessons that documentation and conference talks don't cover:
1. Start With FHIR, Add openEHR for Persistence
Don't try to build both layers simultaneously. Get your FHIR API layer working first — resource validation, SMART on FHIR auth, US Core profile compliance. This gives you immediate value (regulatory compliance, app ecosystem access) while you build the openEHR persistence layer behind it. Your FHIR server can initially be the system of record, with the openEHR CDR introduced as a migration when you need its capabilities.
2. Terminology Normalization Is the Hidden Complexity
The transformation layer isn't just structural mapping — it's terminology reconciliation. FHIR resources and openEHR archetypes both reference SNOMED CT, LOINC, RxNorm, and ICD-10, but they bind to them differently. FHIR uses ValueSets with specific binding strengths (required, extensible, preferred, example). openEHR uses terminology constraints in archetypes with different semantics. Aligning these is where 40-60% of the transformation effort actually lives.
3. AQL Is Incredibly Powerful but Requires Clinical Partnership
AQL lets you express queries that are impossible in FHIR Search. But writing a good AQL query requires understanding the archetype structure, which requires clinical context. The best implementations pair a clinical informaticist (who understands the archetypes) with a software engineer (who understands the query engine). Neither can do it alone effectively.
4. Test With Real Clinical Scenarios, Not Synthetic Data
The transformation layer will pass unit tests with synthetic data and fail spectacularly with real clinical data. Edge cases — missing data elements, local code systems, free-text entries where coded data was expected — are where mappings break. Test with de-identified production data as early as possible.
5. Plan for Profile and Archetype Evolution
Both FHIR profiles and openEHR archetypes evolve. US Core 7.0 changes how conditions are structured. A new archetype version adds data elements. Your transformation layer needs to handle version skew gracefully. Build versioned mappings from day one — it's much harder to retrofit.
6. The Governance Question Is Harder Than the Technical One
Technical implementation of the dual-standard pattern is well-understood. The harder question is organizational: Who owns the archetype selection? Who decides when to update mappings? Who resolves conflicts between FHIR profile requirements and archetype constraints? These governance questions need answers before you write a line of code. At Nirmitee, we've found that establishing a small clinical informatics governance board — typically 3-5 people spanning clinical, technical, and standards expertise — early in the project saves months of rework later.
Looking Ahead: What the HL7-openEHR Collaboration Means for 2026-2027
The June 2025 Amsterdam workshop wasn't just a diplomatic gesture. The five collaborative work areas — content model alignment, terminology standardization, shared governance, reference implementations, and clinical domain prioritization — represent a genuine convergence roadmap. Here's what we expect to see:
- Standardized mapping specifications: The FHIRconnect DSL will likely evolve into a community-maintained mapping library endorsed by both organizations, reducing the cost and risk of the transformation layer.
- Joint clinical domain work: Expect early alignment in high-impact areas like vital signs, medications, and allergies — the clinical domains where both standards already have mature models.
- US market entry for openEHR: As TEFCA matures and organizations look beyond compliance to clinical data strategy, openEHR will gain traction in the US market. The lack of mandate is a barrier, but the clinical query capabilities and vendor independence are increasingly attractive to large health systems tired of data lock-in.
- CDR market growth: Open-source CDRs like EHRbase (backed by vitagroup) and commercial platforms like Better Platform are expanding their FHIR integration capabilities, making the dual-standard pattern more accessible to mid-market health systems.
Conclusion
The "FHIR vs openEHR" debate is a category error. FHIR is the best standard we have for health data exchange — RESTful, widely adopted, regulatory-backed, and developer-friendly. openEHR is the best standard we have for health data persistence — clinically precise, vendor-neutral, query-powerful, and built for longitudinal care.
The dual-standard architecture pattern — FHIR for your API layer, openEHR for your CDR, with a well-engineered transformation layer between them — gives you the best of both worlds: regulatory compliance and ecosystem access through FHIR, deep clinical data capabilities and long-term vendor independence through openEHR.
Not every project needs both. If you're building a patient portal or a SMART on FHIR app, FHIR alone is the right choice. If you're building a research data platform with no external API requirements, openEHR alone might suffice. But if you're building the data infrastructure for a health system that needs to last a decade or more, serve both internal clinical users and external applications, and maintain the flexibility to evolve without vendor lock-in — the dual-standard pattern is the architecture to bet on.
The question isn't "FHIR or openEHR?" It's "how do we make them work together?" And with the HL7-openEHR collaboration now formalized, the transformation tooling maturing, and the CDR market expanding, the answer is becoming clearer every quarter.
Struggling with healthcare data exchange? Our Healthcare Interoperability Solutions practice helps organizations connect clinical systems at scale. We also offer specialized Healthcare Software Product Development services. Talk to our team to get started.