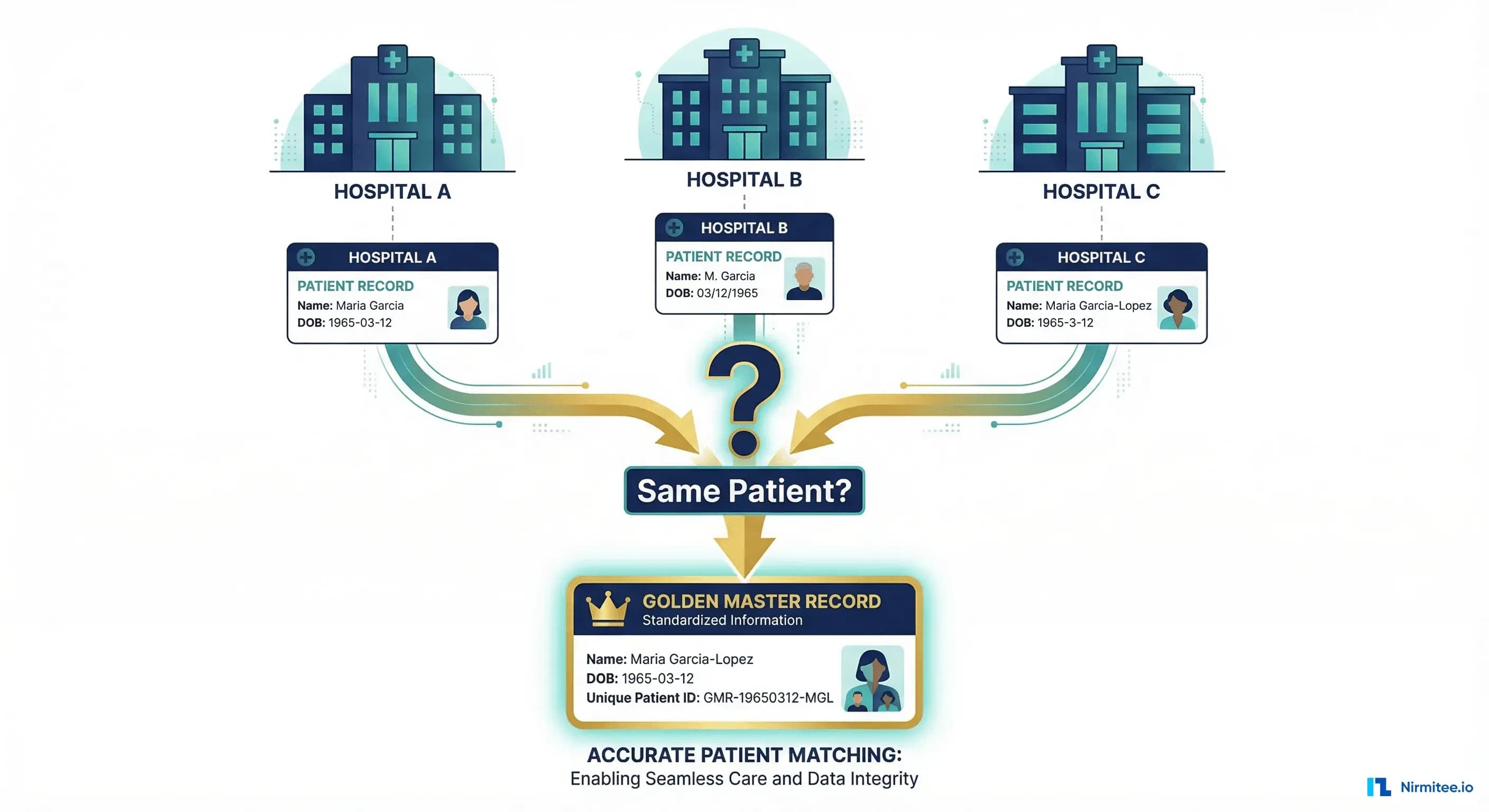

Every healthcare CIO has lived this nightmare: a patient arrives at the ED, the registration clerk searches the system, finds three possible matches, picks the wrong one, and a critical allergy goes unnoticed. Somewhere else in the same health system, another patient's records are split across two medical record numbers, so the radiologist reading their chest CT has no idea about the lung nodule found six months ago at an affiliated clinic.
Patient matching is not a solved problem. Despite decades of investment in Master Patient Indexes (MPIs), the average US hospital still carries a duplicate rate of 8-12%, according to AHIMA research. The Ponemon Institute puts the cost at $1,950 per inpatient stay attributable to duplicate or mismatched records, and that figure only captures direct operational waste. It does not account for the patient safety events: missed drug interactions, redundant imaging, delayed diagnoses, and wrong-site procedures that stem from fragmented identities.
This guide breaks down why demographics-only matching fails, the three algorithmic approaches that actually work, how FHIR $match standardizes the interface, what TEFCA demands for cross-network identity resolution, and the build-versus-buy tradeoffs for an MPI that holds up under real-world conditions. If you are an interoperability architect or health IT leader responsible for data quality, this is the field manual.
The Real Cost of Getting Patient Matching Wrong
Before diving into algorithms, it is worth understanding exactly what is at stake—the financial and clinical consequences of poor patient matching compound across every department in a health system.
- Financial impact: Ponemon Institute's benchmark study found that duplicate records cost hospitals an average of $1,950 per inpatient admission due to redundant tests, claim denials, and manual reconciliation labor. For a 500-bed hospital processing 20,000 admissions per year, that is $39 million annually in avoidable waste.
- Patient safety: The ECRI Institute has ranked patient identification errors among the top 10 patient safety concerns for multiple consecutive years. Split records mean incomplete medication lists, missed allergies, and fragmented problem lists. Overlaid records (two different patients merged into one) can result in wrong-patient blood transfusions and medication errors.
- Regulatory exposure: Under the 21st Century Cures Act, information blocking penalties now apply. If your MPI cannot reliably match patients across systems, you may be unable to fulfill data requests within the required timeframes, creating compliance risk.
- Interoperability failure: TEFCA Qualified Health Information Networks (QHINs) require high-confidence patient matching for cross-network queries. If your organization cannot match reliably, you are functionally locked out of the national health information exchange network.
Why Demographics-Only Matching Fails
Most legacy MPIs rely on exact or near-exact matching of a handful of demographic fields: first name, last name, date of birth, gender, and sometimes Social Security Number. This approach was designed for a world where patients received care at a single institution and registration clerks typed carefully. That world no longer exists.
The Name Problem
Maria Garcia is the most common female name in the US Hispanic population. A single health system in Houston, Dallas, or Los Angeles may have hundreds of patients named Maria Garcia. When you add common Anglo names like James Smith or Jennifer Johnson, demographics alone cannot distinguish between individuals. Then consider:
- Married name changes: Maria Garcia becomes Maria Garcia-Lopez, or drops Garcia entirely
- Legal name changes: Transgender patients updating records, adoptions, and witness protection
- Transliteration variants: Muhammad / Mohammed / Mohammad / Mohamed
- Typos and data entry errors: "Johanson" vs "Johansson" vs "Johnson."
- Nicknames: Bill/William, Bob/Robert, Liz/Elizabeth
The Address Problem
Approximately 580,000 Americans experience homelessness on any given night. These patients have no fixed address. College students move annually. Military families relocate every 2-3 years. Address is one of the least stable demographic fields, yet many MPIs weight it heavily.
The Identifier Problem
The US has no universal patient identifier. Congress has maintained a ban on HHS funding for a national patient ID since 1998 (the Rand Paul amendment). SSN usage is declining due to identity theft concerns, and many patients refuse to provide it. Each facility assigns its own MRN, creating an N-to-N mapping problem across a health system.
The result: demographics-only matching produces both false negatives (failing to link records that belong to the same person) and false positives (incorrectly merging records from different people). Both are dangerous, but in different ways. A false negative means fragmented care; a false positive means treating the wrong patient's data as your own.
Three Approaches to Patient Matching
1. Deterministic Matching
Deterministic matching applies rules-based exact comparisons. If Field A in Record 1 equals Field A in Record 2, it is a match. Typically implemented as a series of pass/fail rules:
Rule 1: IF SSN_match AND DOB_match THEN MATCH
Rule 2: IF MRN_match AND Facility_match THEN MATCH
Rule 3: IF LastName_exact AND FirstName_exact AND DOB_match AND Gender_match THEN MATCH
Rule 4: IF LastName_exact AND FirstName_exact AND Address_exact THEN POSSIBLE_MATCHStrengths: Fast, deterministic (no ambiguity), easy to explain and audit. Works well when you have strong identifiers like SSN or insurance member ID.
Weaknesses: Cannot handle any variation. "Maria Garcia" and "Maria Garcia-Lopez" will never match. A single typo in DOB (1965-03-12 vs 1965-03-21) breaks the chain. Produces high false-negative rates in diverse populations.
2. Probabilistic Matching
Probabilistic matching, formalized by Fellegi and Sunter in their 1969 paper, assigns a weight to each field comparison based on how much it contributes to (or detracts from) the likelihood that two records refer to the same person. The cumulative score determines match confidence.
The core algorithm works as follows:
def probabilistic_match(record_a, record_b, field_configs):
"""
Fellegi-Sunter probabilistic matching implementation.
field_configs: list of dicts with keys:
- name: field name
- weight: importance weight (0.0-1.0)
- comparator: function returning similarity score (0.0-1.0)
- m_probability: P(field agrees | true match)
- u_probability: P(field agrees | non-match)
"""
total_score = 0.0
total_weight = 0.0
field_scores = {}
for config in field_configs:
field_name = config['name']
weight = config['weight']
val_a = record_a.get(field_name, '')
val_b = record_b.get(field_name, '')
# Calculate similarity using field-specific comparator
similarity = config['comparator'](val_a, val_b)
# Fellegi-Sunter log-likelihood ratio
if similarity > 0.0:
m_prob = config['m_probability']
u_prob = config['u_probability']
agreement_weight = math.log2(m_prob / u_prob)
field_score = similarity * agreement_weight * weight
else:
field_score = 0.0
field_scores[field_name] = {
'similarity': similarity,
'weighted_score': field_score
}
total_score += field_score
total_weight += weight
# Normalize to 0.0-1.0 range
normalized_score = total_score / total_weight if total_weight > 0 else 0.0
return {
'score': normalized_score,
'field_scores': field_scores,
'decision': classify_match(normalized_score)
}
def classify_match(score, auto_threshold=0.95, review_threshold=0.85):
if score >= auto_threshold:
return 'AUTO_MATCH'
elif score >= review_threshold:
return 'MANUAL_REVIEW'
else:
return 'NO_MATCH'Key similarity algorithms used in the comparators:
| Algorithm | Best For | How It Works | Example |
|---|---|---|---|
| Jaro-Winkler | Names | Character transposition distance, bonus for common prefix | "Garcia" vs "Garcea" = 0.93 |
| Soundex | Phonetic names | Encodes name to phonetic code (first letter + 3 digits) | "Smith" and "Smyth" both = S530 |
| Double Metaphone | International names | Two phonetic encodings per name for multi-language support | "Schmidt" = XMT/SMT |
| Levenshtein | Addresses, general text | Minimum edit distance (insertions, deletions, substitutions) | "Main St" vs "Main Street" = 4 edits |
| Date fuzzy match | DOB | Component comparison (year, month, day) with transposition detection | 03/12/1965 vs 12/03/1965 = likely swap |
Strengths: Handles real-world data quality issues. Can be tuned per population. Produces a confidence score, enabling tiered workflows (auto-match, manual review, no-match).
Weaknesses: Requires careful tuning of weights and thresholds per deployment. Different patient populations need different configurations. Can produce false positives if thresholds are set too low.
3. Referential Matching
Referential matching augments demographic comparison with lookups against external identity reference databases, such as credit bureau records, state motor vehicle registries, utility connection records, and Social Security death records. Vendors like Verato and LexisNexis Health Care maintain massive referential databases covering 300+ million US identities.
The approach works because these external databases have tracked identity changes over time: name changes after marriage, address history across moves, phone number changes. When your MPI queries "Is Maria Garcia at 123 Main St the same person as Maria Garcia-Lopez at 456 Oak Ave?", a referential database can confirm that Maria Garcia changed her name in 2019 and moved in 2021.
Strengths: Highest accuracy rates (claimed 99%+ by vendors). Handles name changes, address changes, and identity fragmentation that pure algorithmic approaches cannot resolve. Reduces manual review queues by 60-80%.
Weaknesses: Significant ongoing cost (per-transaction pricing). Dependency on external vendor availability. Privacy concerns about sharing PHI with external databases. Not all patients exist in referential databases (undocumented immigrants, minors with no credit history).
FHIR Patient $match Operation
The FHIR Patient $match operation provides a standardized API for patient matching, decoupling the matching algorithm from the client. This is critical for interoperability: any FHIR client can submit a match request without needing to know whether the server uses deterministic, probabilistic, or referential matching internally.
Request Structure
POST /Patient/$match HTTP/1.1
Content-Type: application/fhir+json
{
"resourceType": "Parameters",
"parameter": [
{
"name": "resource",
"resource": {
"resourceType": "Patient",
"name": [
{
"family": "Garcia",
"given": ["Maria"]
}
],
"birthDate": "1965-03-12",
"gender": "female",
"address": [
{
"line": ["123 Main Street"],
"city": "Houston",
"state": "TX",
"postalCode": "77001"
}
],
"telecom": [
{
"system": "phone",
"value": "555-123-4567"
}
],
"identifier": [
{
"system": "http://hospital.example.org/mrn",
"value": "MRN-12345"
}
]
}
},
{
"name": "onlyCertainMatches",
"valueBoolean": false
},
{
"name": "count",
"valueInteger": 5
}
]
}Response Structure
{
"resourceType": "Bundle",
"type": "searchset",
"total": 3,
"entry": [
{
"fullUrl": "http://hospital.example.org/fhir/Patient/pt-67890",
"resource": {
"resourceType": "Patient",
"id": "pt-67890",
"meta": {
"lastUpdated": "2026-01-15T10:30:00Z"
},
"name": [{"family": "Garcia-Lopez", "given": ["Maria"]}],
"birthDate": "1965-03-12",
"gender": "female"
},
"search": {
"mode": "match",
"score": 0.95,
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/match-grade",
"valueCode": "certain"
}
]
}
},
{
"fullUrl": "http://hospital.example.org/fhir/Patient/pt-11111",
"resource": {
"resourceType": "Patient",
"id": "pt-11111",
"name": [{"family": "Garcia", "given": ["Maria", "Elena"]}],
"birthDate": "1965-03-12",
"gender": "female"
},
"search": {
"mode": "match",
"score": 0.72,
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/match-grade",
"valueCode": "probable"
}
]
}
},
{
"fullUrl": "http://hospital.example.org/fhir/Patient/pt-22222",
"resource": {
"resourceType": "Patient",
"id": "pt-22222",
"name": [{"family": "Garcia", "given": ["Marie"]}],
"birthDate": "1965-12-03",
"gender": "female"
},
"search": {
"mode": "match",
"score": 0.45,
"extension": [
{
"url": "http://hl7.org/fhir/StructureDefinition/match-grade",
"valueCode": "possible"
}
]
}
}
]
}The search.score value (0.0 to 1.0) indicates match confidence, and the match-grade extension classifies results as certain, probable, possible, or certainly-not. This standardized interface means your MPI can evolve its internal matching algorithm without breaking any client integrations.
TEFCA Identity Requirements
The Trusted Exchange Framework and Common Agreement (TEFCA) establishes the rules for nationwide health information exchange. For patient matching, TEFCA's Common Agreement specifies several key requirements that your MPI must meet:
- Minimum demographic fields: QHINs must support matching on first name, last name, date of birth, sex, address, and phone number at minimum. Additional fields (SSN last 4, email, insurance ID) are recommended.
- Match confidence thresholds: QHINs must define and publish their match confidence thresholds. Most have adopted a minimum 95% confidence threshold for automated matching.
- No false positive tolerance: TEFCA prioritizes precision over recall. A false positive (returning the wrong patient's records) is treated as a privacy breach. QHINs are expected to err on the side of not matching rather than incorrectly matching.
- Patient demographics query (PDQ): QHINs must support FHIR-based patient demographics queries to resolve identity before document exchange.
- Audit trail: Every match decision, including the fields compared and the confidence score, must be logged for compliance and dispute resolution.
If you are planning to participate in TEFCA as a QHIN Participant or Sub-Participant, your MPI needs to meet these requirements. Most deterministic-only systems will not qualify.
Merge, Unmerge, and Golden Record Management
Matching is only half the problem. Once you determine that two records likely belong to the same person, you need a robust merge/unmerge workflow that does not destroy data or break downstream integrations.
The Golden Record Pattern
A golden record (also called a master record or enterprise record) is the single, authoritative representation of a patient's identity. It is constructed by selecting the best-quality data from each contributing source record:
Source Record A (Hospital Registration):
Name: Maria Garcia
DOB: 1965-03-12
SSN: ***-**-1234
Address: 123 Main St, Houston TX 77001
Phone: (555) 123-4567
Source Record B (Clinic Portal):
Name: Maria Garcia-Lopez
DOB: 03/12/1965
SSN: [not provided]
Address: 456 Oak Avenue, Houston TX 77002
Phone: (555) 123-4567
Golden Record (Merged):
Name: Maria Garcia-Lopez (most recent, legally updated)
Also Known As: Maria Garcia
DOB: 1965-03-12 (standardized ISO format)
SSN: ***-**-1234 (from source with verified SSN)
Address: 456 Oak Avenue, Houston TX 77002 (most recent)
Previous Address: 123 Main St, Houston TX 77001
Phone: (555) 123-4567 (consistent across sources)
Source Records: [Record A, Record B]Critical Merge Considerations
- Survivorship rules: Define which source wins for each field. Typically, most recent verified data wins, but some fields (like SSN) should prefer the source with the highest verification level.
- Downstream notification: Every system that holds a reference to the merged records must be notified. In HL7v2, this is an ADT^A40 merge message. In FHIR, the superseded Patient resource gets a
linkelement pointing to the surviving record withtype: "replaced-by". - Unmerge capability: Incorrect merges happen. Your system must support unmerging without data loss. This means source records are never physically deleted during a merge; they are logically linked. An unmerge restores the original records and sends correction notifications downstream.
- Audit logging: Every merge and unmerge decision must be logged with the operator (or algorithm), timestamp, confidence score, and reason. This is not optional under HIPAA and TEFCA compliance requirements.
Build vs. Buy Decision Matrix
Choosing an MPI strategy involves balancing accuracy requirements, budget, timeline, and long-term flexibility. Here is a realistic assessment:
| Factor | Open Source (OpenMPI, HAPI FHIR) | Commercial (Verato, LexisNexis) | Custom Build |
|---|---|---|---|
| Match Accuracy | 85-92% (probabilistic only, no referential) | 95-99% (referential + probabilistic) | Depends on investment (typically 88-95%) |
| Implementation Time | 3-6 months with tuning | 6-12 weeks (SaaS), 3-6 months (on-prem) | 9-18 months |
| Year 1 Cost | $150K-$300K (engineering time) | $200K-$800K (license + implementation) | $500K-$1.5M (team + infrastructure) |
| Ongoing Annual Cost | $80K-$150K (maintenance + tuning) | $100K-$500K (license + per-transaction) | $200K-$400K (team retention) |
| TEFCA Ready | Requires significant customization | Most vendors are TEFCA-aligned | Must build compliance from scratch |
| Customization | Full control, community support | Limited to vendor configuration | Full control, full responsibility |
| Best For | Tech-forward health systems with strong engineering teams | Health systems prioritizing accuracy and speed to value | Organizations with unique requirements or regulatory constraints |
When to Choose Each Option
- Open source makes sense if you have a strong engineering team, need deep customization (e.g., matching algorithms tuned for specific populations), and can invest time in tuning. HAPI FHIR includes basic
$matchsupport, and OpenMPI provides a probabilistic matching engine. - Commercial is the right choice when accuracy is non-negotiable (e.g., TEFCA participation, multi-state health system), you need fast deployment, and you can justify the ongoing license cost. Referential matching from Verato or LexisNexis is genuinely hard to replicate in-house.
- Custom build is justified only when your use case is genuinely unique (rare disease registries, research cohort matching, international multi-country systems) or when regulatory constraints prevent sharing data with external vendors.
Real-World Gotchas That Architecture Diagrams Miss
After implementing MPI solutions across multiple health systems, here are the problems that consistently surprise teams:
1. The Bootstrap Problem
When you deploy a new MPI against an existing patient database with 2 million records, the initial deduplication run will surface thousands of potential matches for manual review. Plan for a 3-6 month cleanup sprint with dedicated HIM staff. Do not assume the algorithm will auto-resolve everything.
2. Cross-Facility MRN Mapping
In a multi-facility health system, each facility may have assigned its own MRN to the same patient. Your MPI must maintain an enterprise MRN (EMPI) that maps to all facility-level MRNs. This is not just a database table; it is a real-time service that every EMR integration, ADT feed, and order interface must query.
3. Consent and Privacy Segmentation
Matching two records is not the same as merging them. In states with enhanced privacy protections (e.g., 42 CFR Part 2 for substance abuse records, state mental health confidentiality laws), you may be able to identify that two records belong to the same person but be legally prohibited from merging them without explicit patient consent.
4. Newborn and Pediatric Matching
Newborns enter the system as "Baby Boy Smith" or "Infant Girl Johnson" with no SSN, no prior records, and a mother's address that may differ from the birth facility. Pediatric patients change rapidly: names may be updated post-adoption, and guardians change. Your MPI needs special rules for this population.
5. Deceased Patient Records
When a patient dies, their records must be flagged but not purged. MRNs must not be recycled. Cross-referencing with the Social Security Death Index can help identify and flag deceased records, but there is a lag of weeks to months.
6. Real-Time vs. Batch Matching
Registration workflows demand sub-second matching responses. Bulk data loads (acquisitions, migrations, HIE feeds) require batch processing that can handle millions of comparisons. Your architecture must support both modes without the batch process degrading real-time performance.
Practical Implementation Checklist
For healthcare IT architects planning an MPI implementation or upgrade, here is a prioritized checklist:
- Audit your current duplicate rate. Run a probabilistic scan against your production patient database. If your duplicate rate exceeds 10%, budget for a dedicated cleanup project before deploying a new MPI.
- Define your matching tiers. Establish clear thresholds: what score auto-merges, what goes to manual review, and what is rejected. Document these in your governance policy.
- Implement FHIR
$match. Even if your internal MPI uses proprietary algorithms, expose the standardized FHIR interface. This future-proofs your system for TEFCA and third-party integrations. - Build unmerge from day one. Do not treat it as a phase-2 feature. Incorrect merges will happen in the first week. If you cannot unmerge cleanly, you will be manually reconstructing patient records.
- Governance plan. Assign an MPI steward (typically in HIM) who owns match threshold tuning, manual review queue management, and periodic duplicate rate audits.
- Test with your actual data. Synthetic test data is clean. Your production data is not. Test your matching algorithms against a representative sample of real patient records, including the hard cases (common names, incomplete demographics, historical records).
- Monitor continuously. Track your match rate, false positive rate, manual review queue depth, and average review resolution time. Set alerts for anomalies.
FAQ
What is the difference between an MPI and an EMPI?
An MPI (Master Patient Index) typically serves a single facility or system. An EMPI (Enterprise Master Patient Index) spans multiple facilities within a health system or across organizations, maintaining cross-facility identity resolution. In practice, the terms are often used interchangeably, but EMPI implies multi-source matching capability.
Can machine learning replace traditional matching algorithms?
ML models (particularly gradient-boosted trees and neural networks) are being used to improve match scoring, but they supplement rather than replace Fellegi-Sunter probabilistic matching. The challenge is explainability: regulators and HIM staff need to understand why a match decision was made, and black-box ML models struggle with this requirement. Hybrid approaches that use ML for feature extraction and traditional algorithms for scoring are gaining traction.
How does patient matching work across different EHR vendors?
Each EHR vendor (Epic, Oracle Health/Cerner, MEDITECH) has its own internal MPI. Cross-vendor matching typically happens through an external EMPI that ingests ADT feeds from all systems and performs enterprise-level matching. The FHIR $match operation is emerging as the standard interface for this, but adoption varies by vendor.
What accuracy rate should we target for our MPI?
For TEFCA participation, target 95%+ match accuracy with less than 1% false positive rate. For internal operations, 92-95% is acceptable if you have an efficient manual review workflow. Below 90%, you are generating more work for HIM staff than you are saving.
Where Nirmitee Fits
At Nirmitee, we build healthcare data infrastructure that handles the hard problems, including patient matching and identity resolution. Our engineering teams have implemented FHIR-native MPI solutions, probabilistic matching engines, and cross-facility identity resolution for US health systems.
Struggling with healthcare data exchange? Our Healthcare Interoperability Solutions practice helps organizations connect clinical systems at scale. We also offer specialized Healthcare AI Solutions services. Talk to our team to get started.