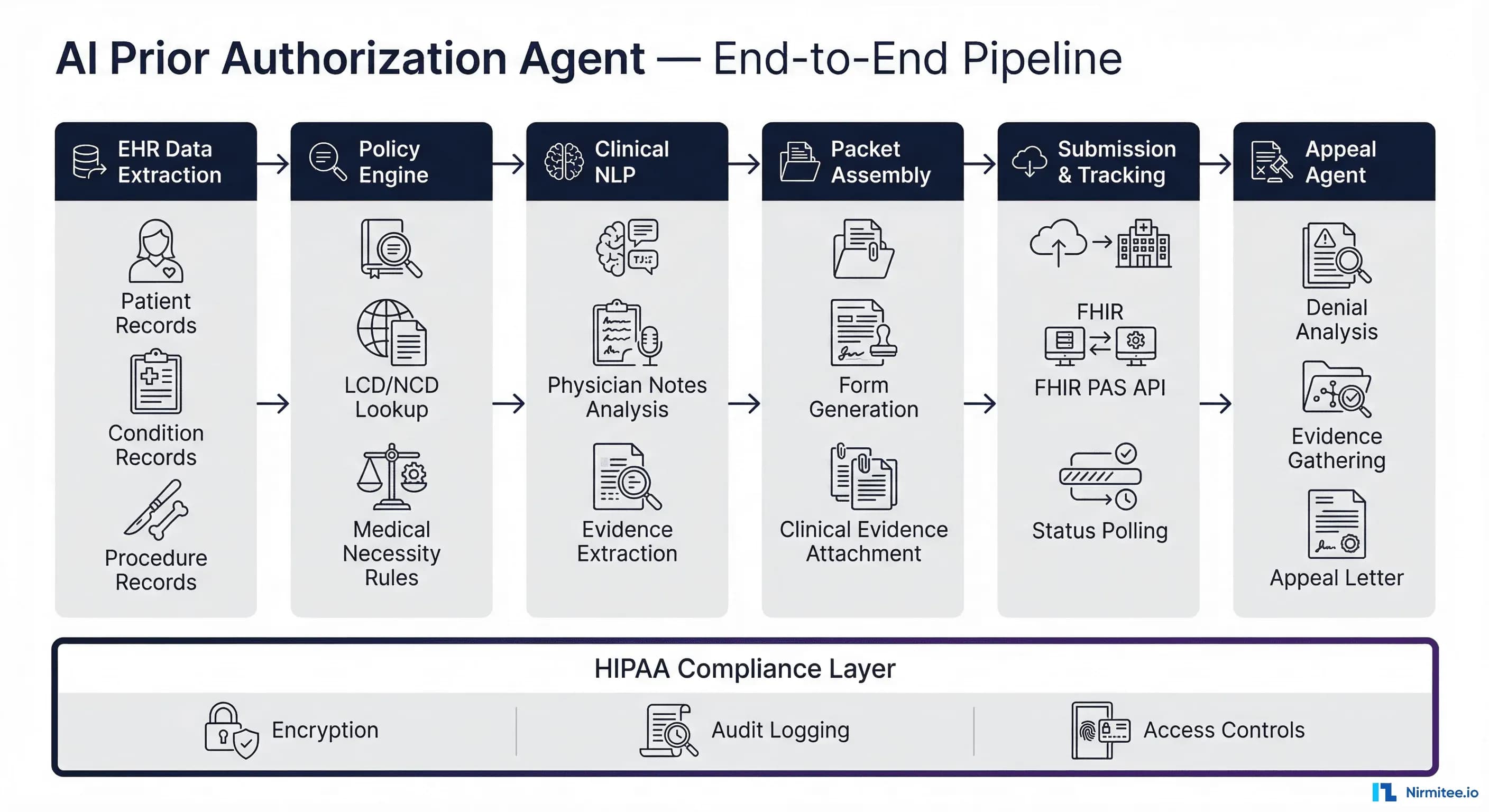
Prior authorization costs the U.S. healthcare system $31 billion annually. Physicians submit nearly 40 prior authorization requests per week, with each one consuming an average of 14 minutes of staff time. In 2024, Medicare Advantage plans alone processed 53 million prior authorization determinations, denying 7.7% of them — yet 81.7% of appealed denials were overturned, proving most denials are administrative failures, not clinical ones.
The tools to solve this exist today. FHIR R4 provides standardized healthcare data access. The Da Vinci PAS Implementation Guide defines the API for electronic prior authorization submission. And large language models like Claude and GPT-4 can extract clinical evidence from physician notes with 86%+ accuracy.
This guide walks you through the complete architecture for building an AI prior authorization agent — from EHR data extraction to automated appeal generation. Unlike product-focused guides that tell you what to buy, this is the technical blueprint for teams that want to build.
If you are new to healthcare AI compliance, start with our HIPAA-Compliant AI Agents Architecture Guide for foundational patterns that apply to every component described below.
System Architecture Overview: The 6-Component Pipeline
A production AI prior authorization agent is not a single model — it is an orchestrated pipeline of six specialized components, each handling a distinct phase of the authorization lifecycle. This separation of concerns is critical for reliability, auditability, and HIPAA compliance.
The pipeline processes a prior authorization request through these stages:
- EHR Data Extraction — Pull structured clinical data via FHIR R4 APIs
- Policy Engine — Match procedures against payer-specific coverage policies
- Clinical NLP — Extract medical necessity evidence from unstructured physician notes
- Packet Assembly — Compile submission forms with attached clinical evidence
- Submission & Tracking — Submit via Da Vinci PAS and monitor status
- Appeal Agent — Analyze denials and generate evidence-backed appeals
A HIPAA compliance layer spans all six components, enforcing encryption, audit logging, access controls, and PHI de-identification at every boundary. Every LLM call, every data access, every decision point is logged to an immutable audit trail.
Let us build each component.
Component 1: EHR Data Extraction via FHIR R4
The first component connects to the EHR system and extracts the structured clinical data needed for a prior authorization request. FHIR R4 is the standard — it provides consistent APIs across Epic, Cerner, Athenahealth, and other EHR vendors that have adopted the US Core Implementation Guide.
Core FHIR Resources for Prior Authorization
Four FHIR resources form the foundation of every prior authorization request:
Patient Resource — Demographics, identifiers, insurance information. The patient resource links to Coverage for payer details.
GET /fhir/Patient/patient-12345
{
"resourceType": "Patient",
"id": "patient-12345",
"identifier": [{
"system": "http://hospital.org/mrn",
"value": "MRN-98765"
}],
"name": [{"family": "Johnson", "given": ["Maria"]}],
"birthDate": "1958-03-14",
"gender": "female",
"address": [{"state": "CA", "postalCode": "90210"}]
}Condition Resource — ICD-10 diagnosis codes, clinical status, onset date, and supporting evidence. This is the clinical justification anchor.
GET /fhir/Condition?patient=patient-12345&clinical-status=active
{
"resourceType": "Condition",
"id": "condition-lumbar-stenosis",
"clinicalStatus": {
"coding": [{"code": "active"}]
},
"code": {
"coding": [{
"system": "http://hl7.org/fhir/sid/icd-10-cm",
"code": "M48.06",
"display": "Spinal stenosis, lumbar region"
}]
},
"onsetDateTime": "2025-08-15",
"subject": {"reference": "Patient/patient-12345"}
}Procedure Resource — CPT codes for the requested procedure, linked to the justifying condition.
// Requested procedure for prior authorization
{
"resourceType": "Procedure",
"code": {
"coding": [{
"system": "http://www.ama-assn.org/go/cpt",
"code": "63047",
"display": "Laminectomy, lumbar"
}]
},
"status": "preparation",
"subject": {"reference": "Patient/patient-12345"},
"reasonReference": [{"reference": "Condition/condition-lumbar-stenosis"}]
}MedicationRequest Resource — For drug prior authorizations, includes medication codes, dosage, and prescriber.
GET /fhir/MedicationRequest?patient=patient-12345&status=active
{
"resourceType": "MedicationRequest",
"medicationCodeableConcept": {
"coding": [{
"system": "http://www.nlm.nih.gov/research/umls/rxnorm",
"code": "1049502",
"display": "Humira 40 MG/0.8 ML Injectable Solution"
}]
},
"dosageInstruction": [{
"text": "40mg subcutaneous every 2 weeks"
}],
"requester": {"reference": "Practitioner/dr-chen"}
}Building the Extraction Layer
The extraction layer should be implemented as a FHIR client service that authenticates via SMART on FHIR (OAuth 2.0), queries the relevant resources, and assembles them into a normalized data structure for downstream processing.
import httpx
from typing import Dict, List
class FHIRExtractor:
"""Extract clinical data from EHR via FHIR R4 API."""
def __init__(self, base_url: str, access_token: str):
self.base_url = base_url.rstrip('/')
self.headers = {
"Authorization": f"Bearer {access_token}",
"Accept": "application/fhir+json"
}
async def extract_prior_auth_data(
self, patient_id: str
) -> Dict:
"""Extract all data needed for prior auth request."""
async with httpx.AsyncClient() as client:
# Parallel fetch of all required resources
patient = await self._get(
client, f"Patient/{patient_id}"
)
conditions = await self._search(
client, "Condition",
{"patient": patient_id, "clinical-status": "active"}
)
procedures = await self._search(
client, "Procedure",
{"patient": patient_id, "status": "preparation"}
)
medications = await self._search(
client, "MedicationRequest",
{"patient": patient_id, "status": "active"}
)
coverage = await self._search(
client, "Coverage",
{"patient": patient_id, "status": "active"}
)
return {
"patient": patient,
"conditions": conditions,
"procedures": procedures,
"medications": medications,
"coverage": coverage
}
async def _get(self, client, path: str) -> Dict:
resp = await client.get(
f"{self.base_url}/{path}",
headers=self.headers
)
resp.raise_for_status()
return resp.json()
async def _search(
self, client, resource: str, params: Dict
) -> List[Dict]:
resp = await client.get(
f"{self.base_url}/{resource}",
params=params,
headers=self.headers
)
resp.raise_for_status()
bundle = resp.json()
return [
e["resource"] for e in bundle.get("entry", [])
]Key design decisions: use async HTTP for parallel resource fetching, implement retry logic with exponential backoff for EHR API rate limits, and cache frequently accessed reference data (Practitioner, Organization) to reduce API calls.
Component 2: Policy Engine — Payer Rules and Medical Necessity
The policy engine determines whether a requested procedure requires prior authorization and, if so, what clinical evidence is needed to justify it. This component replaces the manual process of looking up payer-specific requirements in provider portals and PDF policy documents.
Payer Policy Database Architecture
Payer policies come in three tiers, each with different update frequencies and coverage scopes:
- National Coverage Determinations (NCDs) — CMS-level policies that apply to all Medicare plans. Approximately 300 active NCDs cover common procedures and services. Updated by CMS with public comment periods, typically 2-4 changes per quarter.
- Local Coverage Determinations (LCDs) — Regional Medicare Administrative Contractor (MAC) policies. Over 5,000 active LCDs with jurisdiction-specific rules. A procedure may require prior authorization in one MAC jurisdiction but not another.
- Commercial payer policies — Each commercial insurer (UnitedHealthcare, Anthem, Aetna, Cigna, Humana) maintains proprietary clinical guidelines that often differ significantly from CMS rules. UnitedHealthcare alone publishes over 800 clinical policies covering medical, behavioral health, and pharmacy services.
Store these policies in a vector database for semantic retrieval. When a prior auth request comes in, embed the procedure code combined with diagnosis and retrieve the most relevant policy documents using cosine similarity search.
from pinecone import Pinecone
from openai import OpenAI
class PolicyEngine:
"""Match procedures against payer coverage policies."""
def __init__(self):
self.pc = Pinecone(api_key=PINECONE_API_KEY)
self.index = self.pc.Index("payer-policies")
self.openai = OpenAI()
def check_auth_required(
self, procedure_code: str,
payer_id: str, diagnosis_codes: list
) -> dict:
"""Determine if prior auth is required and
what evidence is needed."""
# Build semantic query
query_text = (
f"Prior authorization requirements for "
f"CPT {procedure_code} with diagnosis "
f"{', '.join(diagnosis_codes)} "
f"payer {payer_id}"
)
# Embed and search policy database
embedding = self.openai.embeddings.create(
model="text-embedding-3-large",
input=query_text
).data[0].embedding
results = self.index.query(
vector=embedding,
top_k=10,
filter={"payer_id": {"$eq": payer_id}},
include_metadata=True
)
# Extract requirements from matching policies
requirements = []
for match in results.matches:
if match.score > 0.82: # High confidence
requirements.append({
"policy_id": match.metadata["policy_id"],
"policy_name": match.metadata["name"],
"auth_required": match.metadata["auth_required"],
"evidence_needed": match.metadata["evidence_checklist"],
"confidence": match.score
})
return {
"auth_required": any(
r["auth_required"] for r in requirements
),
"matching_policies": requirements,
"evidence_checklist": self._merge_checklists(
requirements
)
}Medical Necessity Rules Engine
Beyond simple policy lookup, the engine must evaluate medical necessity criteria against established clinical guidelines. For example, a lumbar laminectomy (CPT 63047) typically requires all of the following to meet medical necessity:
- Documented failure of conservative treatment for 6+ weeks (physical therapy, epidural injections, NSAIDs)
- Imaging evidence (MRI showing stenosis with neural compression)
- Functional limitation documentation (inability to walk more than 200 feet, progressive neurological deficits, bladder/bowel dysfunction)
- Specialist evaluation confirming surgical indication
- BMI within acceptable range for surgical candidacy (some payers require BMI below 40)
These rules are encoded as structured checklists in the policy database. The clinical NLP component (next section) evaluates each checklist item against the patient's clinical record. The checklist structure uses a hierarchical format with AND/OR logic operators connecting criteria groups, mirroring how payer medical directors actually evaluate requests.
Data Pipeline for Policy Document Ingestion
The policy engine requires a continuous ingestion pipeline to keep payer policies current. Payer guidelines change quarterly, and stale policies lead to preventable denials.
- Source monitoring — Scrape CMS.gov for NCD/LCD updates (published quarterly), monitor payer provider portals for policy bulletins, subscribe to payer EDI newsletters for coverage changes.
- Document processing — Parse PDF policy documents into structured sections using document AI (Claude with PDF support or specialized document parsing). Extract coverage criteria, required documentation lists, and medical necessity checklists.
- Embedding and indexing — Chunk policy documents by section (coverage criteria, documentation requirements, exclusions), generate embeddings, and upsert to the vector database with metadata (payer ID, effective date, procedure codes, jurisdiction).
- Validation — After each ingestion cycle, run a test suite of known procedure-payer combinations to verify the policy engine returns correct requirements. Alert on any regressions.
A well-maintained policy database is the foundation of the entire system. Stale or incorrect policy data propagates errors through every downstream component. Budget 10-15% of ongoing engineering time for policy data maintenance and quality assurance.
Component 3: Clinical NLP — Extracting Evidence from Physician Notes
This is where LLMs provide the most significant value in the prior authorization pipeline. Physician notes contain the clinical justification for procedures, but the information is buried in unstructured free-text — progress notes, operative reports, consultation letters, and discharge summaries. The clinical NLP component extracts structured evidence from these documents using large language models.
The Extraction Pipeline
The NLP pipeline follows a three-stage process: extraction, structuring, and evaluation.
Stage 1: Clinical Entity Extraction — The LLM identifies diagnoses, procedures, medications, lab values, imaging findings, and treatment history from raw notes. This goes beyond simple named entity recognition — the model must understand temporal relationships (when was physical therapy attempted?), negation (no evidence of improvement), and clinical significance (stenosis causing radiculopathy vs. incidental finding).
Stage 2: Evidence Structuring — Extracted entities are mapped to standard code systems (ICD-10, CPT, LOINC, RxNorm) and organized by relevance to the prior auth request. The model categorizes findings into the payer's checklist categories: diagnosis confirmation, conservative treatment failure, functional limitation, and imaging evidence.
Stage 3: Checklist Evaluation — Each item on the payer's medical necessity checklist is evaluated against the extracted evidence. Research from the University of Illinois demonstrates this multi-agent approach achieves 95.6% accuracy on overall checklist determinations using GPT-4, with a multi-pass jury voting mechanism that transforms stochastic LLM outputs into statistically reliable predictions.
import anthropic
import json
class ClinicalNLPExtractor:
"""Extract medical necessity evidence using LLMs."""
def __init__(self):
self.client = anthropic.Anthropic()
async def extract_evidence(
self,
physician_notes: str,
evidence_checklist: list
) -> dict:
"""Extract and evaluate clinical evidence against
payer requirements."""
# De-identify PHI before LLM processing
redacted_notes = self.redact_phi(physician_notes)
checklist_str = "\n".join(
f"- {item}" for item in evidence_checklist
)
prompt = f"""You are a clinical documentation specialist
reviewing physician notes for a prior authorization
request.
PHYSICIAN NOTES:
{redacted_notes}
EVIDENCE CHECKLIST (from payer policy):
{checklist_str}
For each checklist item, determine:
1. SUPPORTED - Evidence clearly present in notes
2. PARTIAL - Some evidence exists, may need
supplementation
3. NOT_FOUND - No evidence in current notes
4. CONTRADICTED - Notes contain contradicting evidence
For each item, provide:
- status: one of the above
- evidence_text: exact quote from notes supporting
the determination
- icd10_codes: relevant ICD-10 codes identified
- cpt_codes: relevant CPT codes identified
- confidence: 0.0 to 1.0
Return as JSON array."""
response = self.client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{"role": "user", "content": prompt}]
)
return json.loads(
response.content[0].text
)
def redact_phi(self, text: str) -> str:
"""Remove 18 HIPAA Safe Harbor identifiers
before sending to external LLM API."""
import re
# Names
text = re.sub(
r'\b(Mr|Mrs|Ms|Dr)\.?\s+[A-Z][a-z]+\s+[A-Z][a-z]+',
'[REDACTED_NAME]', text
)
# SSN
text = re.sub(
r'\b\d{3}-\d{2}-\d{4}\b',
'[REDACTED_SSN]', text
)
# MRN / Account numbers
text = re.sub(
r'\bMRN[:\s]*\w+',
'[REDACTED_MRN]', text
)
# Dates of birth
text = re.sub(
r'\bDOB[:\s]*\d{1,2}/\d{1,2}/\d{2,4}',
'[REDACTED_DOB]', text
)
# Phone numbers
text = re.sub(
r'\b\d{3}[-.\s]?\d{3}[-.\s]?\d{4}\b',
'[REDACTED_PHONE]', text
)
return textPrompt Engineering for Medical Necessity
The quality of clinical extraction depends heavily on prompt design. Key patterns that improve accuracy based on published research and production experience:
- Role specification — Instruct the LLM to act as a "clinical documentation specialist" or "utilization review nurse" to activate domain-specific reasoning patterns. This consistently improves extraction quality over generic prompts.
- Structured output — Always request JSON output with predefined fields to ensure consistent downstream processing. Include field-level type hints in the prompt to reduce parsing failures.
- Evidence grounding — Require exact quotes from the source notes for every determination to enable human verification. This also reduces hallucination, as the model must point to specific text rather than synthesize claims.
- Confidence scoring — Include confidence scores so the system can route low-confidence items to human review. Items below 0.85 confidence should always go to the human review queue.
- Chain-of-thought for complex cases — For cases involving multiple comorbidities or unusual treatment paths, use chain-of-thought prompting to improve reasoning accuracy. Research shows this substantially improves smaller model performance, with GPT-3.5 gaining the most benefit from CoT augmentation.
- Multi-pass jury voting — Run the same extraction prompt 5-10 times and use majority voting for the final determination. This ensemble approach increases reliability from approximately 86% to 95%+ accuracy on checklist evaluations, at the cost of proportionally higher latency and API spend.
A critical design principle: never let the LLM make the final authorization decision. The LLM extracts and structures evidence. A deterministic rules engine or a human reviewer makes the final call. This separation is essential for auditability and regulatory compliance.
Multi-Agent Orchestration Pattern
Research from the University of Illinois (2024) demonstrates that a multi-agent LLM architecture significantly outperforms single-model approaches for prior authorization tasks. Their system uses three specialized agents working in concert:
- Classification Agent — Evaluates retrieved clinical documents against each checklist item, categorizing evidence as supporting, contradictory, or irrelevant. Uses semantic similarity filtering with MiniLM-L6-v2 to identify the top-k candidate documents (optimal at k=20-40) before LLM evaluation.
- Jury Agent — Synthesizes verdicts from the Classification Agent across all retrieved documents. Runs multiple evaluation passes (n=10) with majority voting to produce final predictions with confidence scores and evidence citations. This ensemble approach reduces single-pass hallucination risk.
- Propagator Agent — Handles the logical structure of medical necessity checklists, which are hierarchical with AND, OR, and NOT operators connecting criteria groups. The propagator applies deterministic logic rules to child judgments, aggregating verdicts upward through the checklist tree. AND operations use minimum confidence of child nodes; OR operations use maximum confidence.
This architecture achieved 86.2% accuracy on leaf-node checklist predictions and 95.6% on overall checklist determinations using GPT-4. For production deployment, the voting mechanism adds latency (approximately 10x the single-pass time) but the accuracy improvement justifies it for high-stakes medical decisions where incorrect determinations lead to care delays or unnecessary denials.
Component 4: Packet Assembly — Automated Submission Forms
The packet assembly component takes structured clinical data and evidence from the previous components and compiles it into the format required for submission. This includes generating payer-specific forms, attaching clinical documentation, and validating completeness before submission.
Submission Packet Structure
A complete prior authorization packet typically includes:
- PA request form — Payer-specific form with patient demographics, provider information, procedure/diagnosis codes, and service dates
- Letter of medical necessity — Narrative clinical justification linking the diagnosis to the requested procedure, citing specific evidence from the patient record
- Clinical evidence attachments — Lab results, imaging reports, specialist consultations, treatment history documenting conservative therapy failure
- Supporting documentation — Prior treatment records showing failure of conservative therapy, peer-reviewed literature supporting the procedure for the specific diagnosis
class PacketAssembler:
"""Compile prior authorization submission packets."""
def assemble_packet(
self,
patient_data: dict,
clinical_evidence: dict,
policy_requirements: dict,
payer_config: dict
) -> dict:
"""Build complete PA submission packet."""
# Generate letter of medical necessity
necessity_letter = self.generate_necessity_letter(
patient_data, clinical_evidence,
policy_requirements
)
# Map to FHIR Claim resource
claim = self.build_fhir_claim(
patient_data, policy_requirements
)
# Compile evidence attachments
attachments = self.compile_attachments(
clinical_evidence
)
# Build the PAS Request Bundle
bundle = {
"resourceType": "Bundle",
"type": "collection",
"entry": [
{"resource": claim},
{"resource": patient_data["patient"]},
{"resource": patient_data["coverage"][0]},
*[{"resource": att} for att in attachments]
]
}
# Validate completeness against policy
validation = self.validate_packet(
bundle, policy_requirements
)
if not validation["complete"]:
return {
"status": "incomplete",
"missing": validation["missing_items"],
"bundle": bundle
}
return {
"status": "ready",
"bundle": bundle,
"necessity_letter": necessity_letter
}
def build_fhir_claim(self, patient_data, policy) -> dict:
"""Build PAS-compliant Claim resource."""
return {
"resourceType": "Claim",
"status": "active",
"type": {
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/claim-type",
"code": "professional"
}]
},
"use": "preauthorization",
"patient": {
"reference": f"Patient/{patient_data['patient']['id']}"
},
"created": "2026-03-19",
"provider": {
"reference": "Organization/requesting-org"
},
"priority": {
"coding": [{"code": "normal"}]
},
"insurance": [{
"sequence": 1,
"focal": True,
"coverage": {
"reference": f"Coverage/{patient_data['coverage'][0]['id']}"
}
}],
"item": [{
"sequence": 1,
"productOrService": {
"coding": policy["matching_policies"][0]["procedure_coding"]
},
"diagnosisSequence": [1]
}],
"diagnosis": [{
"sequence": 1,
"diagnosisCodeableConcept": {
"coding": policy["matching_policies"][0]["diagnosis_coding"]
}
}]
}Pre-Submission Validation
Before submitting, validate the packet against payer-specific requirements. Common rejection reasons that automated validation catches include:
- Missing or invalid member ID format (each payer has a different format — UHC uses 9-digit numeric, Aetna uses alphanumeric with prefix)
- Incorrect place of service code (outpatient vs. inpatient vs. ambulatory surgical center)
- Diagnosis code not linked to procedure code (ICD-10/CPT pair mismatch per payer bundling rules)
- Missing required attachments (imaging for surgical procedures, lab results for specialty drugs)
- Expired referral or out-of-network provider not pre-approved
- Service date in the past (retrospective auth requires different form and often different endpoint)
- Duplicate request for same service within lookback period
Implementing pre-flight validation reduces rejection rates by 30-40%, saving the resubmission cycle that typically adds 5-10 business days to the authorization timeline. For a 500-case monthly volume, this translates to approximately 150-200 avoided resubmissions per month.
Component 5: Submission and Tracking via Da Vinci PAS
The submission component sends the assembled prior authorization request to the payer using the HL7 Da Vinci Prior Authorization Support (PAS) Implementation Guide. This is the industry-standard FHIR-based approach that replaces manual fax, phone, and portal submissions.
The Da Vinci PAS $submit Operation
PAS defines the $submit operation on the Claim resource. The provider POSTs a PAS Request Bundle to the payer's (or intermediary's) FHIR endpoint. The operation follows the HL7 FHIR R4 specification and is dependent on US Core 3.1, US Core 6.1, and US Core 7.0 profiles.
POST [payer-base-url]/Claim/$submit
Content-Type: application/fhir+json
Authorization: Bearer {oauth2_access_token}
{
"resourceType": "Bundle",
"type": "collection",
"entry": [
{
"resource": {
"resourceType": "Claim",
"status": "active",
"type": {"coding": [{"code": "professional"}]},
"use": "preauthorization",
"patient": {"reference": "Patient/pat-001"},
"insurance": [{
"coverage": {"reference": "Coverage/cov-001"}
}],
"item": [{
"sequence": 1,
"productOrService": {
"coding": [{
"system": "http://www.ama-assn.org/go/cpt",
"code": "63047"
}]
}
}]
}
},
{"resource": {"resourceType": "Patient", "id": "pat-001"}},
{"resource": {"resourceType": "Coverage", "id": "cov-001"}}
]
}Response Handling
The payer returns a PAS Response Bundle containing a ClaimResponse resource with one of three outcomes:
- Approved —
outcome: "complete"with authorization number in thepreAuthReffield. The procedure can proceed. - Pended —
outcome: "queued"with a request for additional information viaprocessNote. The agent should gather the requested documentation and resubmit via the same channel. - Denied —
outcome: "error"with denial reason codes in theerrorarray. This triggers the appeal agent (Component 6).
// ClaimResponse - Approved
{
"resourceType": "ClaimResponse",
"status": "active",
"type": {"coding": [{"code": "professional"}]},
"use": "preauthorization",
"patient": {"reference": "Patient/pat-001"},
"outcome": "complete",
"preAuthRef": "AUTH-2026-78432",
"item": [{
"itemSequence": 1,
"adjudication": [{
"category": {
"coding": [{"code": "benefit"}]
},
"reason": {
"coding": [{"code": "approved"}]
}
}]
}]
}
// ClaimResponse - Pended (additional info needed)
{
"resourceType": "ClaimResponse",
"outcome": "queued",
"processNote": [{
"text": "Please provide MRI report dated within 90 days and physical therapy records showing 6+ weeks of conservative treatment."
}]
}
// ClaimResponse - Denied
{
"resourceType": "ClaimResponse",
"outcome": "error",
"error": [{
"code": {
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/adjudication-error",
"code": "a001",
"display": "Medical necessity not established"
}]
}
}]
}Status Polling and Subscription
For pended requests, implement a polling mechanism or FHIR Subscriptions for real-time status updates. The CMS Interoperability and Prior Authorization Final Rule (CMS-0057-F) mandates that impacted payers respond to urgent requests within 72 hours and standard requests within 7 calendar days, starting in 2026.
class PASStatusTracker:
"""Track prior authorization request status."""
async def poll_status(
self, claim_response_id: str,
payer_base_url: str,
access_token: str
) -> dict:
"""Poll payer for updated status."""
async with httpx.AsyncClient() as client:
resp = await client.get(
f"{payer_base_url}/ClaimResponse/{claim_response_id}",
headers={
"Authorization": f"Bearer {access_token}",
"Accept": "application/fhir+json"
}
)
resp.raise_for_status()
claim_response = resp.json()
outcome = claim_response.get("outcome")
if outcome == "complete":
return {
"status": "approved",
"auth_number": claim_response.get("preAuthRef"),
"details": claim_response
}
elif outcome == "queued":
return {
"status": "pended",
"notes": [
n["text"] for n in
claim_response.get("processNote", [])
],
"details": claim_response
}
elif outcome == "error":
return {
"status": "denied",
"errors": claim_response.get("error", []),
"details": claim_response
}
return {
"status": "unknown",
"details": claim_response
}Building on PAS now positions your system for regulatory compliance as the CMS-0057-F mandate takes effect. Organizations that implement FHIR-based prior authorization before the 2027 deadline gain a competitive advantage through faster authorization turnaround times and reduced manual processing costs.
Component 6: Appeal Agent — Denial Analysis and Evidence-Backed Appeals
The appeal agent is where AI provides the highest ROI in the entire pipeline. According to KFF data, 81.7% of appealed Medicare Advantage prior authorization denials were fully or partially overturned in 2024. But only 11.7% of denials are ever appealed — primarily because the manual appeal process is too time-consuming for already overburdened clinical staff. An AI appeal agent closes this gap by automating the evidence gathering, analysis, and letter drafting process.
Denial Root Cause Analysis
When a prior auth request is denied, the appeal agent first classifies the denial reason into actionable categories:
- Medical necessity not established (42% of denials) — Insufficient clinical evidence in the submission. Most common and most overturnable denial type.
- Missing documentation (23% of denials) — Required attachments were not included or were incomplete. Often a packaging error rather than a clinical issue.
- Coding error (15% of denials) — Incorrect ICD-10/CPT codes, code-pair mismatch, or unlisted procedure code without modifier
- Service not covered (11% of denials) — Procedure excluded under the patient's specific plan. Limited appeal options unless plan interpretation is incorrect.
- Timely filing exceeded (5% of denials) — Request submitted after the payer's deadline (typically 5-15 business days from date of service)
- Out-of-network provider (4% of denials) — Rendering provider not in the payer's network. May be appealable under continuity of care or network adequacy provisions.
Evidence Gathering for Appeals
Based on the denial reason, the agent retrieves additional supporting evidence from the EHR and external sources. For medical necessity denials, this includes retrieving additional clinical notes, lab results, imaging reports, and peer-reviewed literature that supports the clinical decision.
class AppealAgent:
"""Analyze denials and generate appeals."""
def __init__(self):
self.llm = anthropic.Anthropic()
self.fhir_client = FHIRExtractor(...)
self.policy_engine = PolicyEngine()
async def analyze_denial(
self, denial: dict, patient_id: str
) -> dict:
"""Classify denial and determine appeal strategy."""
denial_code = denial["errors"][0]["code"]["coding"][0]["code"]
denial_reason = denial["errors"][0]["code"]["coding"][0]["display"]
# Retrieve additional clinical evidence
additional_evidence = await self.gather_evidence(
patient_id, denial_code
)
# Retrieve peer-reviewed literature
literature = await self.search_literature(
denial["procedure_code"],
denial["diagnosis_code"]
)
# Generate appeal letter
appeal = await self.generate_appeal(
denial, additional_evidence, literature
)
return appeal
async def generate_appeal(
self,
denial: dict,
evidence: dict,
literature: list
) -> dict:
"""Generate evidence-backed appeal letter."""
literature_refs = "\n".join(
f"- {lit['title']} ({lit['journal']}, {lit['year']}): {lit['finding']}"
for lit in literature[:5]
)
prompt = f"""You are a utilization review specialist
drafting a prior authorization appeal letter.
DENIAL DETAILS:
- Denial reason: {denial['reason']}
- Procedure: {denial['procedure_code']}
({denial['procedure_desc']})
- Diagnosis: {denial['diagnosis_code']}
({denial['diagnosis_desc']})
CLINICAL EVIDENCE SUPPORTING THE REQUEST:
{json.dumps(evidence['clinical_findings'], indent=2)}
PEER-REVIEWED LITERATURE:
{literature_refs}
PAYER POLICY REQUIREMENTS:
{json.dumps(evidence['policy_requirements'], indent=2)}
Draft a formal appeal letter that:
1. Clearly states the patient's clinical condition
and functional limitations
2. Addresses each specific denial reason with
evidence citations
3. References the payer's own policy criteria and
shows each criterion is met
4. Cites peer-reviewed literature supporting
medical necessity
5. References relevant CMS NCDs/LCDs if applicable
6. Requests expedited review if clinically urgent
7. Maintains a professional, factual tone
Format as a formal medical letter."""
response = self.llm.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{"role": "user", "content": prompt}]
)
return {
"appeal_letter": response.content[0].text,
"evidence_cited": evidence,
"literature_cited": literature,
"confidence": self.calculate_appeal_confidence(
evidence, literature
)
}The appeal agent should always flag the generated letter for human review before submission. A physician or utilization review specialist must verify the clinical accuracy of the appeal before it is sent to the payer. For more on designing appropriate human oversight, see our guide on bounded autonomy patterns for healthcare AI agents.
Recommended Tech Stack
Intelligence Layer
| Component | Recommendation | Why |
|---|---|---|
| Clinical NLP | Claude API (Sonnet) or GPT-4 | Best accuracy on medical text extraction. Claude offers 200K context window for long clinical notes. |
| Embeddings | text-embedding-3-large (OpenAI) | 1536-dim vectors with strong medical vocabulary coverage |
| Vector Database | Pinecone or Weaviate | Managed service with metadata filtering for payer-specific policy retrieval |
| Appeal letter generation | Claude API (Opus) or GPT-4 | Stronger reasoning for complex clinical argumentation |
Data and Integration Layer
| Component | Recommendation | Why |
|---|---|---|
| FHIR Server | HAPI FHIR R4 | Open-source, Java-based, US Core compliant, production-proven |
| Orchestration API | FastAPI (Python) or Express (Node.js) | Async-first for parallel FHIR queries and LLM calls |
| State Management | PostgreSQL | ACID transactions for audit logs, request tracking, decision history |
| Caching | Redis | Session state, FHIR resource caching, rate limiting |
| Task Queue | Celery + Redis or BullMQ | Async processing for LLM calls, status polling, retries |
Compliance and Operations Layer
| Component | Recommendation | Why |
|---|---|---|
| Cloud Platform | AWS (GovCloud) or GCP with BAA | HIPAA-eligible, SOC 2 certified, BAA available |
| Secrets Management | HashiCorp Vault or AWS Secrets Manager | Rotate API keys, store encryption keys, manage certificates |
| Monitoring | Datadog or Grafana + Prometheus | APM, log aggregation, custom dashboards for PA metrics |
| Deployment | Docker + Kubernetes (EKS/GKE) | Container orchestration with health checks, auto-scaling |
Estimated Infrastructure Costs
For a mid-sized healthcare organization processing 500-1,000 prior authorizations per month:
- LLM API costs: $800-2,000/month (depends on note length and model choice; Claude Sonnet at approximately $0.30 per complex extraction)
- Cloud infrastructure: $1,500-3,000/month (compute, database, storage on HIPAA-eligible tier)
- Vector database: $200-500/month (managed Pinecone or Weaviate with 50K+ policy vectors)
- Monitoring and tools: $300-500/month (Datadog APM, log management, alerting)
- Total: $3,000-6,000/month
Compare this against the manual cost: at 14 minutes per PA request and an average staff cost of $25/hour, 750 PAs per month costs $4,375 in labor alone — before accounting for denials, resubmissions, phone hold times, and appeals. The AMA reports that physicians spend an average of 12 hours per week on prior authorization activities, and 93% report that prior authorization delays access to necessary care. Automation ROI is typically realized within 3-6 months through reduced staff time and faster authorizations.
HIPAA Compliance Architecture
Every component in the pipeline handles Protected Health Information (PHI). Your compliance architecture must address data protection at every boundary, with no exceptions for development or staging environments that contain real patient data.
PHI Protection Layers
- Encryption at rest — AES-256 for all databases, file storage, and backups containing PHI. Use envelope encryption with AWS KMS or GCP Cloud KMS for key management.
- Encryption in transit — TLS 1.3 for all API communication, including internal service-to-service calls within your Kubernetes cluster. Terminate TLS at the service mesh level (Istio/Linkerd), not just at the ingress.
- PHI de-identification for LLM calls — Strip all 18 HIPAA Safe Harbor identifiers before sending clinical text to external LLM APIs. Re-associate after processing using internal reference IDs. This is the most critical control for AI-augmented healthcare systems.
- Business Associate Agreements (BAAs) — Required with every vendor that processes PHI: cloud provider, LLM API provider, vector database, monitoring platform. Both Anthropic and OpenAI offer BAAs for enterprise healthcare customers.
- Role-Based Access Control (RBAC) — Principle of least privilege. The NLP component should never access billing data. The submission component should never access unrelated patient records. Implement at both the application and database level.
- Immutable audit logging — Log every data access, LLM call, and decision with timestamp, user/service identity, and data accessed. Store in append-only storage (S3 with Object Lock or similar). Retain for minimum 6 years per HIPAA requirements.
LLM-Specific Compliance Considerations
When using commercial LLM APIs (Claude, GPT-4) with healthcare data:
- Verify BAA coverage — Anthropic and OpenAI offer BAAs for enterprise customers. Confirm your API agreement includes PHI processing rights. Standard developer accounts typically do not include BAA coverage.
- Use dedicated endpoints — Enterprise LLM plans typically offer isolated endpoints that do not use customer data for model training. Verify this contractually.
- Implement request-level logging — Log every prompt sent to the LLM (after de-identification) and every response received. This is your audit trail for clinical decisions.
- Consider on-premise alternatives — For organizations with strict data residency requirements, consider self-hosted models like Llama 3 with medical fine-tuning. The accuracy trade-off is 5-15% versus frontier models, but PHI never leaves your infrastructure.
- Implement data retention policies — Ensure LLM providers do not retain your prompts or completions beyond the processing window. Configure zero-retention policies where available.
For a comprehensive treatment of HIPAA compliance patterns for AI agents, see our detailed guide: Building HIPAA-Compliant AI Agents: Architecture Guide for Healthcare.
Human-in-the-Loop Design
An AI prior authorization agent should augment, not replace clinical judgment. The human-in-the-loop design determines when the system operates autonomously and when it requires human review. Getting this boundary right is the difference between a helpful tool and a liability.
Autonomy Levels
| Scenario | Autonomy Level | Human Action |
|---|---|---|
| Data extraction from EHR | Full automation | None — deterministic FHIR queries |
| Policy lookup and matching | Full automation | None — rule-based with known policies |
| Clinical NLP (high confidence > 0.9) | Auto with audit | Spot-check 10% of determinations |
| Clinical NLP (low confidence < 0.9) | Human review required | Clinician reviews all flagged items |
| Submission of routine requests | Auto with notification | Staff notified, can intervene within 15 min |
| Appeal letter generation | Human approval required | Physician must review and sign before submission |
| Denial decisions | Never automated | Always requires human clinical review |
Review Queue Design
Build a review dashboard where clinicians can:
- See the AI's evidence extraction side-by-side with the original physician notes for verification
- Approve, modify, or reject each checklist determination with one-click actions
- Add supplementary evidence the AI may have missed from sources not in the FHIR system
- Escalate complex cases to specialist review (peer-to-peer with payer medical director)
- Provide structured feedback that improves future extraction accuracy via prompt refinement
The feedback loop is critical for continuous improvement. Track which extractions clinicians override and use that data to improve prompts, adjust confidence thresholds, and update policy matching rules. Over time, the override rate should decrease from the initial 15-20% to below 5% as the system learns from clinician corrections.
Testing Strategy
Prior authorization involves real patient care decisions. Your testing strategy must validate accuracy, reliability, and safety before production deployment. A single incorrect automated denial can delay critical patient care.
Testing Pyramid
- Unit tests — FHIR resource parsing, code validation, form generation logic, PHI redaction patterns. Target 80%+ coverage on all deterministic components.
- Integration tests — End-to-end pipeline with mock FHIR servers (use HAPI FHIR test server) and recorded LLM responses. Validate Bundle structure, Claim resource compliance with PAS profiles, and ClaimResponse parsing for all three outcome types.
- Accuracy tests — Run the NLP component against a labeled dataset of 500+ physician notes with known medical necessity determinations. Track precision, recall, and F1 score per checklist item category. Minimum threshold: F1 > 0.85 before production deployment.
- Conformance tests — Use the Da Vinci PAS Inferno Test Kit to validate your FHIR implementation against the official PAS profiles. This is the same tool CMS uses for certification.
- Adversarial tests — Submit edge cases: notes with contradictory information, rare procedures without LCD coverage, patients with multiple active coverage plans, notes in multiple languages, incomplete records with missing sections, and cases where the AI should correctly flag "insufficient evidence" rather than force a determination.
- Shadow mode deployment — Run the AI agent in parallel with the manual process for 4-8 weeks. Compare the AI's authorization recommendations against actual human-submitted requests and payer decisions. Track: agreement rate with human decisions, cases where AI would have caught errors humans missed, and cases where AI made incorrect determinations. This is the gold standard validation before going live.
Orchestration Framework Recommendations
For coordinating the multi-agent pipeline in production, evaluate these orchestration options based on your team's expertise and scale requirements:
- LangGraph — Graph-based state machine for complex multi-step agent workflows. Strong support for conditional branching (approved/pended/denied paths), parallel execution (evidence gathering from multiple sources), and persistent state across retries. Best for teams already in the LangChain ecosystem.
- Temporal — Durable execution engine for long-running workflows. Ideal for prior authorization pipelines that may span days (initial submission through pended status through resolution). Built-in retry semantics, timeout handling, and workflow versioning. Best for organizations with complex state management requirements.
- Custom FastAPI + Celery — For teams that need full control over the pipeline. Define the stages as Celery tasks with explicit state transitions stored in PostgreSQL. More engineering effort but zero framework lock-in and complete visibility into every decision point.
Whichever framework you choose, ensure it supports: persistent state across service restarts, configurable retry policies per stage, dead letter queues for failed processing, and observability hooks for monitoring every agent decision with full audit trails.
Deployment and Monitoring
Deployment Architecture
Deploy as containerized microservices on Kubernetes for production reliability, horizontal scaling, and rolling updates:
# docker-compose.yml (development)
services:
orchestrator:
build: ./services/orchestrator
ports: ["8080:8080"]
environment:
- FHIR_SERVER_URL=http://hapi-fhir:8080/fhir
- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY}
- PINECONE_API_KEY=${PINECONE_API_KEY}
- DATABASE_URL=postgresql://user:pass@postgres:5432/pa_agent
- REDIS_URL=redis://redis:6379
depends_on: [postgres, redis, hapi-fhir]
hapi-fhir:
image: hapiproject/hapi:latest
ports: ["8090:8080"]
environment:
- hapi.fhir.allow_multiple_delete=true
- hapi.fhir.us_core_validation=true
postgres:
image: postgres:16
environment:
- POSTGRES_DB=pa_agent
- POSTGRES_USER=user
- POSTGRES_PASSWORD=pass
volumes:
- pgdata:/var/lib/postgresql/data
redis:
image: redis:7-alpine
ports: ["6379:6379"]
volumes:
pgdata:Production Monitoring Metrics
Track these metrics in production to ensure the system operates safely and effectively:
| Metric | Target | Alert Threshold |
|---|---|---|
| PA request processing time (p95) | < 30 seconds | > 60 seconds |
| First-pass approval rate | > 85% | < 75% (7-day rolling) |
| NLP extraction confidence (mean) | > 0.90 | < 0.80 |
| Human override rate | < 10% | > 20% (trend alert) |
| Appeal success rate | > 75% | < 60% |
| FHIR API error rate | < 0.5% | > 2% |
| LLM API latency (p95) | < 5 seconds | > 10 seconds |
| PHI exposure incidents | 0 | Any (immediate page) |
Circuit Breakers and Fallbacks
Implement circuit breakers on all external dependencies to prevent cascading failures:
- LLM API down — Queue requests for retry with exponential backoff. Route to manual review queue if SLA breached (3 retries over 5 minutes).
- FHIR server unreachable — Cache recent patient data with 15-minute TTL. Alert operations team. Degrade gracefully by presenting cached data to human reviewers.
- Payer endpoint unavailable — Queue submissions with exponential backoff. Notify staff for manual submission via payer portal as fallback. Track queue depth for capacity planning.
- Vector DB latency spike — Fall back to cached policy lookups for high-volume procedure codes. Alert on cache staleness exceeding 24 hours.
Getting Started: Implementation Roadmap
Building a production AI prior authorization agent is a 3-6 month effort for a team of 2-4 engineers. Here is a phased approach:
Phase 1 (Weeks 1-4): Foundation
- Set up FHIR server and EHR connectivity (SMART on FHIR OAuth 2.0 flow)
- Build the data extraction layer with the four core FHIR resources
- Establish the policy database with 50-100 high-volume LCD/NCD policies
- Deploy infrastructure (Kubernetes cluster, PostgreSQL, Redis, monitoring)
Phase 2 (Weeks 5-8): Intelligence
- Implement the clinical NLP pipeline with PHI de-identification layer
- Build the policy matching engine with vector search and RAG retrieval
- Develop the packet assembly component with FHIR Claim resource generation
- Create the human review dashboard with one-click approve/reject workflow
Phase 3 (Weeks 9-12): Submission and Appeal
- Integrate the Da Vinci PAS $submit operation with test payer endpoints
- Build the status tracking and notification system with FHIR Subscriptions
- Implement the appeal agent with denial root cause analysis and letter generation
- Run PAS Inferno conformance tests and fix profile compliance issues
Phase 4 (Weeks 13-20): Validation and Launch
- Shadow mode testing (4-6 weeks) comparing AI vs. manual outcomes side-by-side
- Accuracy benchmarking against labeled clinical datasets (minimum F1 > 0.85)
- Security audit, penetration testing, and HIPAA compliance review
- Gradual production rollout starting with high-volume, low-complexity procedure categories
Start with the highest-volume prior authorization categories at your organization — imaging studies, specialty drugs, and surgical procedures typically represent 70%+ of PA volume — to maximize early ROI and build organizational confidence in the system.
For foundational knowledge on building the FHIR integration layer, see our FHIR US Core Implementation Guide. For the complete prior authorization regulatory landscape including CMS-0057-F requirements and compliance timelines, review our Prior Authorization Automation Technical Guide.