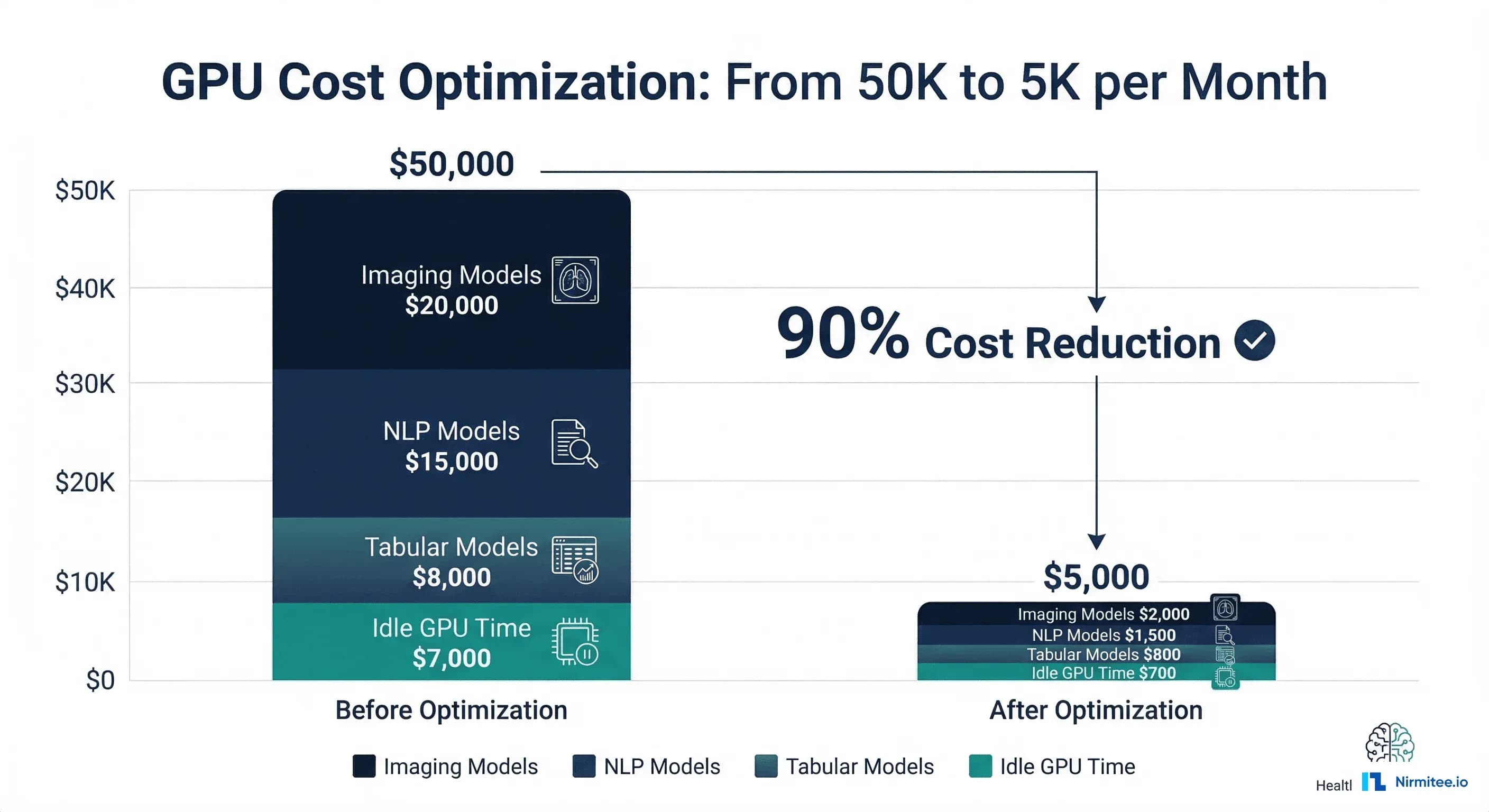
Healthcare organizations deploying multiple AI models face a GPU cost problem that scales faster than their clinical impact. A mid-sized health system running five production models — medical imaging classification, clinical NLP for note extraction, sepsis risk prediction, readmission scoring, and length-of-stay estimation — can easily spend $50,000 per month on GPU infrastructure. That number often exceeds the budget that justified the AI program in the first place.
The root cause is not that GPUs are expensive. The root cause is that most healthcare AI deployments waste 60-80% of their GPU capacity through poor architecture decisions: one model per GPU, always-on instances for models that serve 200 requests per hour, A100 GPUs running tabular models that could run on a CPU, and zero caching for repeated predictions on the same patient.
Strategy 1: Dynamic Batching with Triton Inference Server
The single highest-impact optimization for healthcare inference workloads is dynamic batching. Most healthcare models serve requests one at a time — a prediction request arrives, the GPU processes it, and returns the result. GPUs are designed for parallel processing; running them one request at a time is like using a 48-lane highway for a single car.
NVIDIA Triton Inference Server automatically groups incoming requests into batches and processes them together. A GPU that takes 15ms to process one chest X-ray also takes approximately 18ms to process a batch of 16 chest X-rays — the per-request cost drops by nearly 15x.
# config.pbtxt — Triton Model Configuration with Dynamic Batching
name: "sepsis_risk_model"
platform: "pytorch_libtorch"
max_batch_size: 32
# Dynamic batching configuration
dynamic_batching {
# Maximum time to wait for more requests to form a batch
max_queue_delay_microseconds: 15000 # 15ms — acceptable for clinical
# Preferred batch sizes (Triton will try to fill these)
preferred_batch_size: [8, 16, 32]
# Priority levels for different request types
priority_levels: 2
default_priority_level: 1
# Queue policy
default_queue_policy {
timeout_action: REJECT
default_timeout_microseconds: 30000000 # 30s max wait
allow_timeout_override: true
}
}
# Input specification
input [
{
name: "clinical_features"
data_type: TYPE_FP32
dims: [42] # 42 clinical input features
}
]
# Output specification
output [
{
name: "risk_score"
data_type: TYPE_FP32
dims: [1]
}
]
# Instance configuration
instance_group [
{
count: 2 # 2 model instances on the GPU
kind: KIND_GPU
gpus: [0]
}
]
For a healthcare deployment serving 1,000 predictions per hour across five models, dynamic batching alone can reduce GPU requirements from 5 GPUs (one per model) to 1-2 GPUs — a 60-80% cost reduction with the same latency profile.
Strategy 2: Model-Specific GPU Selection
Not every model needs a $30/hour H100. The most common mistake in healthcare AI infrastructure is using the same GPU type for all models, typically over-provisioning the expensive ones.
| Model Type | Example | Size | Optimal GPU | Monthly Cost |
|---|---|---|---|---|
| Tabular ML | Readmission risk (XGBoost) | 50 MB | CPU (no GPU needed) | $150 |
| Small DNN | Sepsis prediction (PyTorch) | 200 MB | T4 or CPU | $200-400 |
| Medical imaging | Chest X-ray classification | 500 MB - 2 GB | A10G | $730 |
| Clinical NLP | Clinical BERT note extraction | 1-3 GB | T4 or A10G | $380-730 |
| Large NLP/LLM | Clinical summarization (7B+) | 14-70 GB | A100 80GB or H100 | $3,500-5,700 |
A healthcare system running a readmission model on an A100 ($3,500/month) when a CPU instance ($150/month) would deliver identical latency is wasting $3,350 per month on that single model. Multiply by five over-provisioned models and you have the $50K problem.
Strategy 3: Spot and Preemptible Instances
Not every healthcare AI model needs guaranteed uptime. Spot instances (AWS) or preemptible VMs (GCP) offer 60-70% cost savings compared to on-demand pricing, with the trade-off that the instance can be reclaimed with short notice.
The key insight for healthcare is that model criticality is not binary. A sepsis alert model needs sub-second response and cannot tolerate interruption — it runs on-demand. But a readmission risk score calculated at discharge can tolerate a 30-second delay if the spot instance is reclaimed and replaced. And population health scoring that runs nightly can use spot instances exclusively.
# spot_inference_manager.py — Spot Instance Strategy for Healthcare AI
import boto3
import time
from enum import Enum
from dataclasses import dataclass
from typing import Optional
class ModelCriticality(Enum):
CRITICAL = "critical" # On-demand only (sepsis, drug interactions)
IMPORTANT = "important" # Spot with on-demand fallback
BATCH = "batch" # Spot only (population health, reporting)
@dataclass
class ModelDeployment:
model_name: str
criticality: ModelCriticality
gpu_type: str
max_latency_ms: int
fallback_to_cpu: bool = False
# Healthcare model deployment configurations
DEPLOYMENTS = [
ModelDeployment("sepsis_alert", ModelCriticality.CRITICAL,
"g5.xlarge", max_latency_ms=500),
ModelDeployment("drug_interaction", ModelCriticality.CRITICAL,
"g5.xlarge", max_latency_ms=200),
ModelDeployment("readmission_risk", ModelCriticality.IMPORTANT,
"g4dn.xlarge", max_latency_ms=5000,
fallback_to_cpu=True),
ModelDeployment("los_prediction", ModelCriticality.IMPORTANT,
"g4dn.xlarge", max_latency_ms=5000,
fallback_to_cpu=True),
ModelDeployment("population_health", ModelCriticality.BATCH,
"g4dn.xlarge", max_latency_ms=60000),
]
def calculate_monthly_savings(deployments: list) -> dict:
"""Calculate monthly savings from spot instance strategy."""
# AWS GPU pricing (approximate, us-east-1)
pricing = {
"g4dn.xlarge": {"on_demand": 0.526, "spot": 0.158}, # T4
"g5.xlarge": {"on_demand": 1.006, "spot": 0.302}, # A10G
"p4d.24xlarge": {"on_demand": 32.77, "spot": 9.83}, # A100
}
hours_per_month = 730
total_on_demand = 0
total_optimized = 0
for dep in deployments:
gpu = pricing.get(dep.gpu_type, pricing["g4dn.xlarge"])
on_demand_cost = gpu["on_demand"] * hours_per_month
total_on_demand += on_demand_cost
if dep.criticality == ModelCriticality.CRITICAL:
optimized_cost = on_demand_cost # No spot for critical
elif dep.criticality == ModelCriticality.IMPORTANT:
# 80% spot, 20% on-demand fallback
optimized_cost = (
gpu["spot"] * hours_per_month * 0.8 +
gpu["on_demand"] * hours_per_month * 0.2
)
else: # BATCH
optimized_cost = gpu["spot"] * hours_per_month
total_optimized += optimized_cost
return {
"all_on_demand": round(total_on_demand, 2),
"optimized": round(total_optimized, 2),
"monthly_savings": round(total_on_demand - total_optimized, 2),
"savings_pct": round(
(1 - total_optimized / total_on_demand) * 100, 1
),
}
Strategy 4: Multi-Model Serving
A single A10G GPU has 24 GB of VRAM. Most healthcare tabular and small DNN models use 100-500 MB. Running one model per GPU wastes 95%+ of the available memory and compute.
Triton Inference Server natively supports multi-model serving — loading multiple models onto a single GPU and routing requests to the appropriate model. For a typical healthcare deployment with five small-to-medium models totaling 1.5 GB, a single A10G can serve all of them with room to spare.
# triton_model_repository structure for multi-model serving
# model_repository/
# sepsis_risk/
# config.pbtxt
# 1/model.pt
# readmission/
# config.pbtxt
# 1/model.pt
# mortality/
# config.pbtxt
# 1/model.pt
# los_prediction/
# config.pbtxt
# 1/model.pt
# Docker command to launch Triton with all models
# docker run --gpus 1 -p 8000:8000 -p 8001:8001 \
# -v /path/to/model_repository:/models \
# nvcr.io/nvidia/tritonserver:24.01-py3 \
# tritonserver --model-repository=/models \
# --model-control-mode=explicit \
# --load-model=sepsis_risk \
# --load-model=readmission \
# --load-model=mortality \
# --load-model=los_prediction
Strategy 5: Inference Caching
Healthcare workflows create natural caching opportunities. When a physician opens a patient's chart, the system might request the readmission risk score. The same physician reviews the chart again 20 minutes later — the system requests the same score. If the patient's data has not changed, there is no reason to re-run the model.
# inference_cache.py — Redis-based Inference Cache for Healthcare AI
import redis
import hashlib
import json
import time
from typing import Optional, Any
from dataclasses import dataclass
@dataclass
class CacheConfig:
"""Per-model cache configuration."""
model_name: str
ttl_seconds: int # How long predictions remain valid
cache_key_features: list # Which features define cache uniqueness
invalidate_on_new_data: bool = True # Invalidate when patient data changes
# Cache policies per model type
CACHE_POLICIES = {
"readmission_risk": CacheConfig(
model_name="readmission_risk",
ttl_seconds=3600, # 1 hour — risk doesn't change that fast
cache_key_features=["patient_id", "encounter_id"],
invalidate_on_new_data=True,
),
"sepsis_risk": CacheConfig(
model_name="sepsis_risk",
ttl_seconds=300, # 5 minutes — vitals change frequently
cache_key_features=["patient_id", "timestamp_bucket"],
invalidate_on_new_data=True,
),
"mortality_risk": CacheConfig(
model_name="mortality_risk",
ttl_seconds=1800, # 30 minutes
cache_key_features=["patient_id", "encounter_id"],
invalidate_on_new_data=True,
),
}
class InferenceCache:
def __init__(self, redis_url: str = "redis://localhost:6379"):
self.redis = redis.from_url(redis_url)
self.stats = {"hits": 0, "misses": 0}
def _make_key(self, config: CacheConfig, features: dict) -> str:
key_data = {
"model": config.model_name,
**{k: features.get(k) for k in config.cache_key_features}
}
key_hash = hashlib.sha256(
json.dumps(key_data, sort_keys=True).encode()
).hexdigest()[:16]
return f"inference:{config.model_name}:{key_hash}"
def get_prediction(
self, model_name: str, features: dict
) -> Optional[dict]:
config = CACHE_POLICIES.get(model_name)
if not config:
return None
key = self._make_key(config, features)
cached = self.redis.get(key)
if cached:
self.stats["hits"] += 1
return json.loads(cached)
self.stats["misses"] += 1
return None
def store_prediction(
self, model_name: str, features: dict, prediction: dict
):
config = CACHE_POLICIES.get(model_name)
if not config:
return
key = self._make_key(config, features)
self.redis.setex(
key,
config.ttl_seconds,
json.dumps(prediction)
)
@property
def hit_rate(self) -> float:
total = self.stats["hits"] + self.stats["misses"]
return self.stats["hits"] / max(total, 1)
In typical EHR-integrated deployments, inference caching achieves a 25-40% hit rate, directly reducing GPU utilization by the same percentage. The cache must be invalidated when new clinical data arrives for a patient (new lab results, new vitals, new orders).
Strategy 6: Right-Sizing GPU Instances
The final strategy is the simplest but often the most impactful: audit your current GPU utilization and right-size. Most healthcare AI teams provision GPU instances during development (when they needed GPU for training) and never change them for inference, even though inference requires far less compute than training.
Related Reading
For more insights, explore our guides on GPU vs CPU for Healthcare ML Inference and FHIR in Modern Healthcare.
You may also find value in EHR Software Development Guide and Building a Healthtech App.
| Optimization | Implementation Effort | Cost Reduction | Risk |
|---|---|---|---|
| Right-size GPUs | Low (1-2 days) | 30-50% | Minimal (just switch instance type) |
| Spot instances | Low (2-3 days) | 40-60% on eligible models | Low (with fallback configured) |
| Inference caching | Medium (1 week) | 25-40% | Low (cache miss falls through to GPU) |
| Multi-model serving | Medium (1-2 weeks) | 50-75% | Medium (shared resource contention) |
| Dynamic batching | Medium (1-2 weeks) | 60-80% | Low (adds small latency) |
| Model quantization | High (2-4 weeks) | 30-50% | Medium (verify no accuracy loss) |
Cost Calculator Framework
Here is a framework for calculating and tracking GPU inference costs across your healthcare AI portfolio. Use it to identify the highest-impact optimization targets.
# gpu_cost_calculator.py — Healthcare AI GPU Cost Calculator
from dataclasses import dataclass
from typing import List
@dataclass
class ModelProfile:
name: str
model_size_mb: int
avg_requests_per_hour: int
avg_latency_ms: float
current_gpu: str
current_instance_type: str
can_run_on_cpu: bool = False
can_use_spot: bool = False
cacheable: bool = False
cache_hit_rate: float = 0.0
# AWS GPU instance pricing (on-demand, us-east-1, per hour)
INSTANCE_PRICING = {
"cpu_c5.xlarge": 0.170,
"g4dn.xlarge": 0.526, # T4 16GB
"g5.xlarge": 1.006, # A10G 24GB
"g5.2xlarge": 1.212, # A10G 24GB, more CPU
"p4d.24xlarge": 32.77, # 8x A100 40GB
"p5.48xlarge": 98.32, # 8x H100 80GB
}
SPOT_DISCOUNT = 0.70 # 70% discount for spot
HOURS_PER_MONTH = 730
def calculate_current_cost(models: List[ModelProfile]) -> dict:
"""Calculate current monthly GPU spend."""
total = 0
breakdown = []
for m in models:
hourly = INSTANCE_PRICING.get(m.current_instance_type, 1.0)
monthly = hourly * HOURS_PER_MONTH
total += monthly
breakdown.append({
"model": m.name,
"instance": m.current_instance_type,
"monthly_cost": round(monthly, 2),
})
return {"total": round(total, 2), "breakdown": breakdown}
def calculate_optimized_cost(models: List[ModelProfile]) -> dict:
"""Calculate optimized monthly GPU spend."""
total = 0
recommendations = []
for m in models:
rec = {"model": m.name}
# Strategy 1: Right-size (move to CPU if possible)
if m.can_run_on_cpu:
instance = "cpu_c5.xlarge"
rec["change"] = f"Move to CPU ({instance})"
elif m.model_size_mb < 500:
instance = "g4dn.xlarge" # T4 is enough
rec["change"] = f"Downsize to T4 ({instance})"
else:
instance = m.current_instance_type
rec["change"] = "Keep current"
hourly = INSTANCE_PRICING.get(instance, 1.0)
# Strategy 2: Spot instances
if m.can_use_spot:
hourly *= (1 - SPOT_DISCOUNT)
rec["spot"] = True
# Strategy 3: Caching reduces effective requests
effective_utilization = 1.0
if m.cacheable and m.cache_hit_rate > 0:
effective_utilization = 1.0 - m.cache_hit_rate
rec["cache_savings"] = f"{m.cache_hit_rate*100:.0f}%"
monthly = hourly * HOURS_PER_MONTH * effective_utilization
total += monthly
rec["monthly_cost"] = round(monthly, 2)
recommendations.append(rec)
return {"total": round(total, 2), "recommendations": recommendations}
# Example healthcare deployment
healthcare_models = [
ModelProfile("chest_xray_classifier", 1200, 500, 45.0,
"A10G", "g5.xlarge"),
ModelProfile("clinical_bert_ner", 1500, 300, 35.0,
"A10G", "g5.xlarge", cacheable=True,
cache_hit_rate=0.30),
ModelProfile("readmission_risk", 50, 800, 5.0,
"A10G", "g5.xlarge", can_run_on_cpu=True,
can_use_spot=True, cacheable=True,
cache_hit_rate=0.35),
ModelProfile("sepsis_predictor", 200, 1200, 8.0,
"A10G", "g5.xlarge"),
ModelProfile("los_estimator", 80, 600, 4.0,
"A10G", "g5.xlarge", can_run_on_cpu=True,
can_use_spot=True, cacheable=True,
cache_hit_rate=0.40),
]
current = calculate_current_cost(healthcare_models)
optimized = calculate_optimized_cost(healthcare_models)
print(f"Current monthly cost: ${current['total']:,.2f}")
print(f"Optimized monthly cost: ${optimized['total']:,.2f}")
print(f"Monthly savings: ${current['total'] - optimized['total']:,.2f}")
Implementation Roadmap
The recommended implementation order, based on effort-to-impact ratio:
- Week 1: Audit and right-size. Inventory all GPU instances, measure actual utilization, and switch tabular/small models to T4 or CPU. Expected savings: 30-50%.
- Week 2: Enable spot instances. Classify models by criticality. Move batch and non-critical models to spot instances with on-demand fallback. Expected additional savings: 20-30%.
- Week 3-4: Deploy inference caching. Add Redis-based caching for models with predictable cache-hit patterns (readmission, mortality, LOS)—expected additional savings: 10-15%.
- Month 2: Migrate to Triton. Deploy Triton Inference Server with dynamic batching and multi-model serving. Consolidate multiple models onto fewer GPUs. Expected additional savings: 20-30%.
For monitoring the performance of your optimized models, see our guide on AI model monitoring and drift detection in healthcare. For containerization best practices, see Docker and Kubernetes for healthcare ML.
Conclusion
GPU inference costs in healthcare AI are a solvable problem. The 90% cost reduction from $50K to $5K per month is not theoretical — it comes from six practical strategies that any engineering team can implement incrementally: right-sizing GPUs, using spot instances for non-critical models, caching redundant predictions, serving multiple models per GPU, enabling dynamic batching, and quantizing models where clinically safe.
The key insight is that most healthcare GPU costs are driven by over-provisioning and architectural inefficiency, not by the inherent cost of GPU compute. A readmission risk model running on an A100 is not more accurate than the same model running on a CPU — it is just 20x more expensive. Start with the audit, implement the quick wins (right-sizing and spot), then invest in the architectural changes (Triton, caching) that deliver sustained savings as your model portfolio grows.


