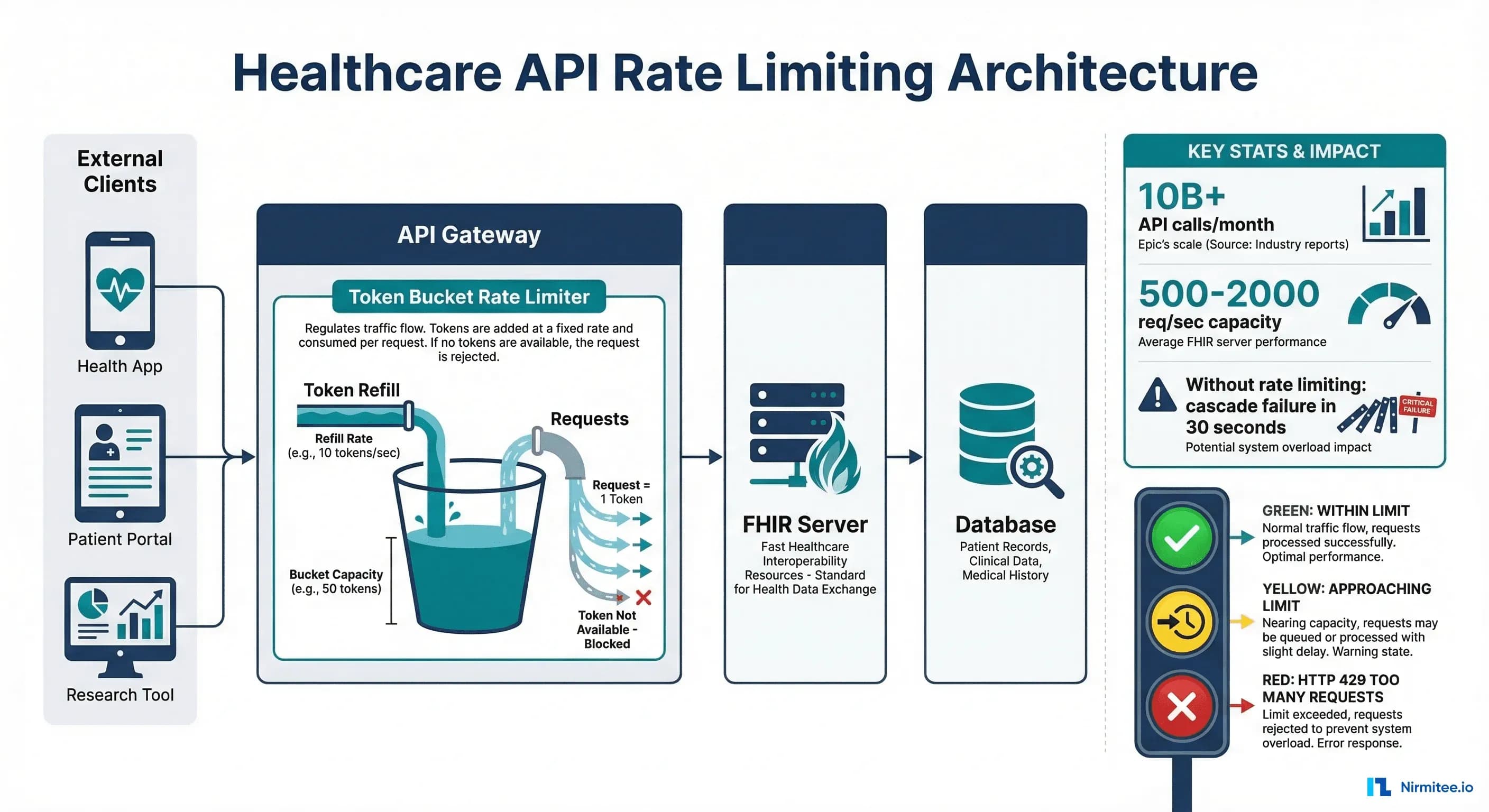
Epic processes over 10 billion FHIR API calls per month. Cerner handles billions more. When CMS mandated Patient Access APIs in 2021, every major EHR vendor suddenly became an API platform — and discovered that healthcare systems built for controlled interface traffic couldn't handle the chaotic request patterns of a public API ecosystem.
Rate limiting isn't optional for healthcare APIs. It's infrastructure-critical. Without it, a single misbehaving client can cascade-fail your entire FHIR server, taking down not just that client's access but every integration partner, patient portal, and clinical application that depends on your API. This has happened in production at real health systems — and the incident reports aren't pretty.
This guide covers everything you need to implement production-grade rate limiting for healthcare FHIR APIs: algorithm selection, multi-dimensional limiting strategies, SMART scope-based throttling, proper HTTP 429 responses, circuit breakers for downstream protection, SLA design, and implementation approaches with Kong, NGINX, and custom middleware.
Why Healthcare APIs Need Rate Limiting More Than Most
Healthcare APIs have characteristics that make them uniquely vulnerable to traffic spikes:
- Expensive queries: A FHIR search like
GET /Observation?patient=123&category=laboratory&date=ge2020-01-01can hit millions of database rows. Unlike a social media API where each request touches a single cache key, healthcare queries often involve complex joins across clinical data tables. - Bursty traffic patterns: Healthcare traffic follows clinical workflows. Monday mornings see 3-5x normal traffic as providers catch up from the weekend. End-of-month billing runs trigger bulk data exports. Flu season creates admission surges that cascade to API traffic.
- Downstream fragility: Many FHIR servers sit in front of legacy systems — HL7v2 interfaces, legacy databases, third-party clinical systems — that were never designed for high-concurrency API traffic. A FHIR facade amplifies this risk.
- Regulatory requirements: CMS interoperability rules require that APIs be available to third-party apps. You can't just block traffic — you must serve it reliably while protecting backend systems.
- Patient safety implications: When a FHIR server goes down, clinical decision support stops, patient portals go dark, and downstream integrations lose access to real-time clinical data. This isn't an e-commerce site returning HTTP 503 for a product page — it's a clinical system going offline.
Rate Limiting Algorithms: Token Bucket vs. Sliding Window
Two algorithms dominate production rate limiting. Each has trade-offs that matter for healthcare API traffic patterns.
Token Bucket
The token bucket algorithm maintains a "bucket" of tokens for each client. Tokens are added at a fixed rate (the sustained rate). Each request consumes one token. If the bucket is empty, the request is rejected. The bucket has a maximum capacity (the burst limit), allowing clients to briefly exceed the sustained rate.
// Token bucket implementation in Go
type TokenBucket struct {
mu sync.Mutex
tokens float64
maxTokens float64
refillRate float64 // tokens per second
lastRefill time.Time
}
func (tb *TokenBucket) Allow() bool {
tb.mu.Lock()
defer tb.mu.Unlock()
// Refill tokens based on elapsed time
now := time.Now()
elapsed := now.Sub(tb.lastRefill).Seconds()
tb.tokens = math.Min(tb.maxTokens, tb.tokens+elapsed*tb.refillRate)
tb.lastRefill = now
// Consume a token if available
if tb.tokens >= 1 {
tb.tokens--
return true
}
return false
}Why it works for healthcare: Clinical workflows are inherently bursty. A provider opens a patient chart and the app fires 15 FHIR requests in 2 seconds (Patient, Conditions, Medications, Allergies, recent Observations, etc.), then goes quiet for minutes. Token bucket accommodates this burst while enforcing a sustainable average rate.
Sliding Window Log
The sliding window algorithm maintains a log of request timestamps. For each new request, it counts how many requests occurred in the past N seconds. If the count exceeds the limit, the request is rejected.
// Sliding window with Redis sorted sets
func (sw *SlidingWindow) Allow(clientID string) bool {
ctx := context.Background()
now := time.Now().UnixMilli()
windowStart := now - int64(sw.windowSize.Milliseconds())
key := fmt.Sprintf("ratelimit:%s", clientID)
pipe := sw.redis.Pipeline()
// Remove entries outside the window
pipe.ZRemRangeByScore(ctx, key, "0", strconv.FormatInt(windowStart, 10))
// Count entries in the window
countCmd := pipe.ZCard(ctx, key)
pipe.Exec(ctx)
if countCmd.Val() >= int64(sw.maxRequests) {
return false
}
// Add current request
sw.redis.ZAdd(ctx, key, redis.Z{Score: float64(now), Member: now})
sw.redis.Expire(ctx, key, sw.windowSize)
return true
}When to use it: Sliding window is better when you need strict rate enforcement without bursts — for example, limiting bulk data export requests or write operations that modify clinical data. It's also more predictable for SLA documentation because the limit is exact: "100 requests per 60 seconds" means exactly that.
Our Recommendation
Use token bucket for read operations (FHIR GET) and sliding window for write operations (FHIR POST/PUT/DELETE) and expensive operations (Bulk Data $export, $everything). This hybrid approach matches healthcare traffic patterns: bursty reads during chart reviews, controlled writes during clinical documentation.
Multi-Dimensional Rate Limiting
A single rate limit per client isn't enough for healthcare APIs. You need multiple dimensions of limiting to protect both the API and downstream systems.
Per-Client Limits
Every SMART on FHIR client gets a rate limit based on its registration tier. This is the outermost layer — it caps total traffic from any single consumer regardless of what they're requesting.
| Client Tier | Sustained Rate | Burst Limit | Example |
|---|---|---|---|
| Standard | 60 req/min | 20 req burst | Patient-facing mobile apps |
| Provider | 300 req/min | 50 req burst | EHR-integrated clinical apps |
| Enterprise | 1000 req/min | 200 req burst | Backend analytics, population health |
| Bulk Data | 10 req/min | 2 req burst | $export, batch operations |
Per-Patient Limits
Cap the total number of requests for any single patient across all clients. This prevents a compromised or malicious client from scraping a patient's entire medical history through rapid sequential queries. A typical per-patient limit is 100 requests per minute — enough for any legitimate clinical workflow but insufficient for bulk extraction.
Per-Resource Limits
Different FHIR resources have different backend costs. Searching Observations (often the largest clinical table) is orders of magnitude more expensive than reading a single Patient by ID. Apply resource-specific limits:
- Patient (by ID): 300 req/min — cheap, heavily cached
- Observation (search): 30 req/min — expensive, hits large tables
- $everything: 5 req/min — assembles entire patient record
- Bulk $export: 2 req/hour — generates large datasets
Global Backend Limits
A hard ceiling on total requests reaching the database or downstream systems, regardless of how many clients are active. If your PostgreSQL instance handles 2,000 queries/second comfortably, set the global limit at 1,500/second to maintain headroom for administrative queries, batch jobs, and monitoring. This is the last line of defense — if all per-client limits are correctly set, this limit should rarely trigger.
SMART Scope-Based Throttling
One of the most effective healthcare-specific rate limiting strategies is throttling based on SMART on FHIR scopes. The scopes in an access token tell you what the client is authorized to do, and different scopes have different infrastructure costs.
The principle: write scopes get lower rate limits than read scopes. System-level scopes get different limits than patient-level scopes. Bulk operations get the most restrictive limits.
// SMART scope-based rate limit configuration
var scopeLimits = map[string]RateLimit{
"patient/*.read": {Rate: 120, Burst: 20, Window: time.Minute},
"patient/*.write": {Rate: 30, Burst: 5, Window: time.Minute},
"user/*.read": {Rate: 300, Burst: 50, Window: time.Minute},
"user/*.write": {Rate: 60, Burst: 10, Window: time.Minute},
"system/*.read": {Rate: 1000, Burst: 200, Window: time.Minute},
"system/*.write": {Rate: 100, Burst: 20, Window: time.Minute},
"system/Patient.$export": {Rate: 2, Burst: 1, Window: time.Hour},
}
func getRateLimitForRequest(token *SMARTToken, resourceType, operation string) RateLimit {
// Find the most specific matching scope
scope := fmt.Sprintf("%s/%s.%s", token.Context, resourceType, operation)
if limit, ok := scopeLimits[scope]; ok {
return limit
}
// Fall back to wildcard scope
wildcardScope := fmt.Sprintf("%s/*.%s", token.Context, operation)
if limit, ok := scopeLimits[wildcardScope]; ok {
return limit
}
// Default: restrictive
return RateLimit{Rate: 30, Burst: 5, Window: time.Minute}
}HTTP 429 Responses: Doing It Right
When a client exceeds its rate limit, your API must return a clear, actionable HTTP 429 response. Too many healthcare APIs return a generic 429 with no guidance — forcing clients to guess when they can retry.
A proper healthcare API 429 response includes:
HTTP/1.1 429 Too Many Requests
Retry-After: 30
X-RateLimit-Limit: 100
X-RateLimit-Remaining: 0
X-RateLimit-Reset: 1710432000
Content-Type: application/fhir+json
{
"resourceType": "OperationOutcome",
"issue": [{
"severity": "error",
"code": "throttled",
"diagnostics": "Rate limit exceeded for client 'patient-portal-app'. Limit: 100 requests per minute. Current usage: 100/100. Retry after 30 seconds.",
"details": {
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/operation-outcome",
"code": "throttled"
}]
}
}]
}Key elements:
- Retry-After header: Tells the client exactly how many seconds to wait. Well-behaved clients (and SMART app frameworks) will respect this automatically.
- X-RateLimit-* headers: Standard rate limit headers showing the limit, remaining capacity, and reset timestamp. These help client developers tune their request patterns.
- FHIR OperationOutcome: The response body must be a valid FHIR resource, not a generic error page. FHIR clients expect JSON responses at FHIR endpoints.
- Diagnostic detail: Include which limit was hit, the client identifier, and the reset timing. This makes debugging straightforward for client developers.
Circuit Breakers for Downstream Protection
Rate limiting controls inbound traffic. Circuit breakers protect downstream systems when they're struggling. These are complementary patterns — you need both.
A circuit breaker monitors the health of each downstream dependency (database, HL7v2 interfaces, external FHIR servers, terminology services) and has three states:
- Closed (normal): Requests flow through. Failures are counted. If failures exceed a threshold within a time window (e.g., 5 failures in 30 seconds), the circuit opens.
- Open (failing): All requests are immediately rejected with HTTP 503 and a FHIR OperationOutcome indicating the downstream system is unavailable. No requests reach the downstream system, giving it time to recover.
- Half-open (testing): After a configured timeout (e.g., 60 seconds), a single test request is allowed through. If it succeeds, the circuit closes. If it fails, the circuit reopens for another timeout period.
In healthcare, circuit breakers are essential because downstream systems often fail gradually rather than completely. A database under load might respond to 80% of queries but timeout on the other 20%. Without a circuit breaker, the FHIR server keeps sending requests, accumulating blocked threads, and eventually becomes unresponsive itself — a classic cascade failure antipattern.
SLA Design for Healthcare APIs
Rate limits must be documented in your API SLA (Service Level Agreement). Healthcare API consumers — app developers, integration partners, third-party vendors — need to know your limits before they build against your API. Discovering rate limits at runtime through 429 responses is a terrible developer experience.
A healthcare API SLA should cover:
Availability Guarantees
- 99.9% uptime = 8.7 hours of downtime per year (industry standard for healthcare APIs)
- 99.99% uptime = 52.6 minutes per year (target for Tier 1 clinical APIs)
- Planned maintenance windows: scheduled, communicated 72 hours in advance
- Unplanned downtime escalation: page on-call within 5 minutes, status page update within 15 minutes
Performance Guarantees
- p50 latency: under 100ms for reads, under 500ms for writes
- p95 latency: under 500ms for reads, under 2000ms for writes
- p99 latency: under 2000ms for reads, under 5000ms for writes
- Error rate: under 0.1% of requests return 5xx errors (excluding 429s)
Rate Limit Documentation
Publish rate limits in three places: (1) your FHIR CapabilityStatement using extension elements, (2) your developer portal documentation, and (3) response headers on every API call. Include examples of how to handle 429 responses with exponential backoff. Provide a sandbox environment where developers can test against rate limits before going to production.
Implementation: Kong, NGINX, and Custom Middleware
Kong API Gateway
Kong's rate-limiting plugin supports token bucket and sliding window algorithms out of the box. For healthcare APIs, use the Redis-backed rate limiting plugin for distributed deployments:
# Kong rate limiting configuration for FHIR API
_format_version: "3.0"
services:
- name: fhir-server
url: http://fhir-backend:8080
routes:
- name: fhir-api
paths:
- /fhir
plugins:
- name: rate-limiting-advanced
config:
strategy: redis
redis:
host: redis-cluster
port: 6379
limits:
- key: consumer # Per SMART client
window_size: 60
limit: 100
- key: header # Per patient (from X-Patient-ID)
header_name: X-Patient-ID
window_size: 60
limit: 100
error_code: 429
error_message: "Rate limit exceeded"NGINX
NGINX's limit_req module implements a leaky bucket algorithm. For healthcare APIs, combine zone-based limiting with geo and header-based differentiation:
# NGINX rate limiting for FHIR endpoints
http {
# Define rate limit zones
limit_req_zone $http_authorization zone=per_client:10m rate=100r/m;
limit_req_zone $uri zone=per_resource:10m rate=50r/m;
server {
# FHIR read endpoints - allow bursts
location ~ ^/fhir/(Patient|Encounter|Condition) {
limit_req zone=per_client burst=20 nodelay;
proxy_pass http://fhir_backend;
}
# Expensive search endpoints - strict limiting
location ~ ^/fhir/Observation {
limit_req zone=per_resource burst=5;
proxy_pass http://fhir_backend;
}
# Bulk export - very restrictive
location /fhir/$export {
limit_req zone=per_client burst=1;
proxy_pass http://fhir_backend;
}
# Custom 429 response with FHIR OperationOutcome
error_page 429 = @rate_limited;
location @rate_limited {
default_type application/fhir+json;
return 429 '{"resourceType":"OperationOutcome","issue":[{"severity":"error","code":"throttled"}]}';
}
}
}Custom Middleware (Go)
For maximum control — especially scope-based throttling — implement rate limiting as middleware in your FHIR server:
func RateLimitMiddleware(limiterStore *LimiterStore) echo.MiddlewareFunc {
return func(next echo.HandlerFunc) echo.HandlerFunc {
return func(c echo.Context) error {
// Extract client ID from SMART token
token := extractSMARTToken(c)
clientID := token.ClientID
// Get applicable rate limit based on scope + resource
resourceType := extractResourceType(c.Path())
operation := mapHTTPMethodToOp(c.Request().Method)
limit := getRateLimitForRequest(token, resourceType, operation)
// Check rate limit
limiter := limiterStore.GetLimiter(clientID, limit)
if !limiter.Allow() {
retryAfter := limiter.RetryAfter()
c.Response().Header().Set("Retry-After", strconv.Itoa(retryAfter))
c.Response().Header().Set("X-RateLimit-Limit", strconv.Itoa(limit.Rate))
c.Response().Header().Set("X-RateLimit-Remaining", "0")
return c.JSON(429, fhir.OperationOutcome{
Issue: []fhir.Issue{{
Severity: "error",
Code: "throttled",
Diagnostics: fmt.Sprintf("Rate limit exceeded. Retry after %d seconds.", retryAfter),
}},
})
}
return next(c)
}
}
}Monitoring and Alerting
Rate limiting generates critical operational data. Monitor these signals:
- 429 rate by client: If a specific client consistently hits limits, they may need a higher tier or guidance on optimizing their request patterns
- Global rate limit triggers: If the backend protection limit triggers, your infrastructure needs scaling — not your rate limits
- Circuit breaker state changes: Every open/close transition should trigger an alert. Frequent transitions indicate an unstable downstream system
- Latency percentile drift: If p95 latency is climbing, rate limits may need tightening before the system degrades
- Per-patient hotspots: Unusual per-patient request rates may indicate a data breach attempt or a malfunctioning client
Build a monitoring dashboard that shows real-time request rates, 429 frequency, circuit breaker status, and backend latency. The integration and DevOps teams should be able to see at a glance whether the API is healthy, stressed, or degrading.
Looking to build a robust healthcare platform? Our Healthcare Software Product Development team turns complex requirements into production-ready systems. We also offer specialized Healthcare Interoperability Solutions services. Talk to our team to get started.
Frequently Asked QuestionsHow do rate limits interact with CMS interoperability requirements?
CMS requires that Patient Access APIs be available to third-party apps. You're allowed to implement rate limiting — CMS explicitly acknowledges this in the 2024 Final Rule. However, rate limits must be "reasonable" and not used as a mechanism to discourage or block access. Document your limits publicly, offer a tiered approach, and provide a process for clients to request higher limits.
What rate limits do Epic and Cerner use?
Epic's FHIR API enforces approximately 100 requests per minute per client for patient-context operations, with higher limits for backend system access. Oracle Health (Cerner) uses similar limits but varies by deployment. Both return standard HTTP 429 with Retry-After headers. Use their published rate limits as benchmarks for your own implementation.
Should rate limits be the same in sandbox and production?
No. Sandbox environments should have more generous rate limits (or no limits at all) to allow developers to test freely. However, publish your production rate limits in your sandbox documentation so developers can build their retry logic before going live. Some organizations implement "rate limit preview" mode in sandbox — the response includes X-RateLimit headers showing what would have happened in production, without actually blocking.
How do we handle legitimate high-volume use cases like population health analytics?
Create an Enterprise or Bulk Data tier with higher sustained rates and lower burst limits (since analytics workloads should be steady, not bursty). Require these clients to use system-level SMART scopes and FHIR Bulk Data Access for large extractions instead of per-patient queries. Bulk Data $export is specifically designed for this — rate limit individual FHIR queries aggressively while providing a dedicated bulk extraction pathway.
Conclusion
Rate limiting for healthcare APIs isn't a nice-to-have — it's the difference between a stable clinical platform and an outage that affects patient care. The investment in proper rate limiting infrastructure pays back on the first day a runaway client would have taken down your FHIR server.
Start with token bucket per-client limiting (it handles bursty clinical workflows well), add per-patient and per-resource dimensions, implement SMART scope-based throttling for fine-grained control, and protect downstream systems with circuit breakers. Document everything in your SLA and developer portal. And monitor relentlessly — rate limiting without observability is flying blind.
Need help designing rate limiting for your healthcare API? At Nirmitee, we build production FHIR servers with enterprise-grade rate limiting, auth, and observability. We can audit your current API infrastructure and implement the right limiting strategy for your traffic patterns. Get in touch.