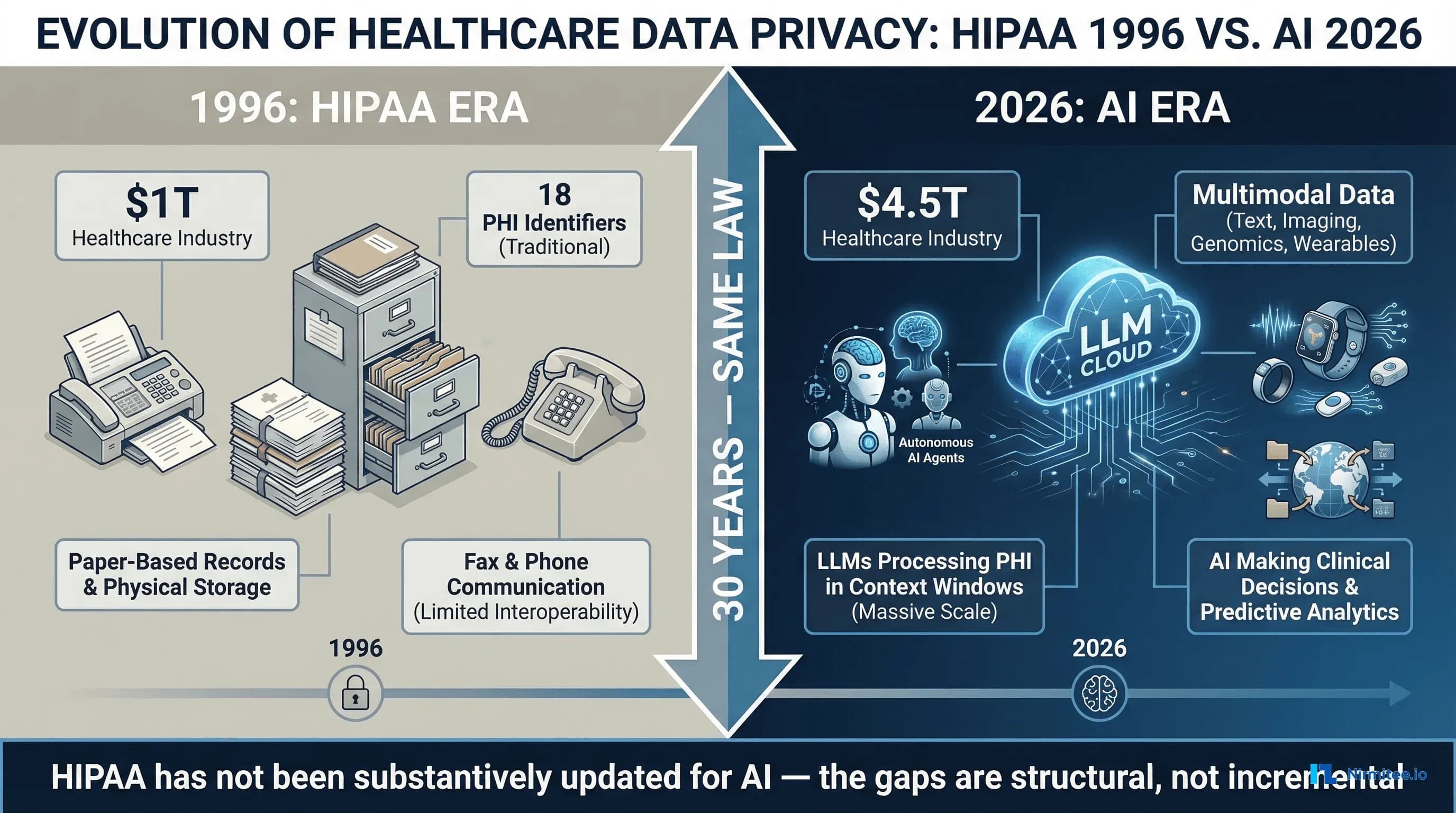
The Health Insurance Portability and Accountability Act was signed into law on August 21, 1996. Bill Clinton was president. Google did not exist. The internet had 36 million users worldwide. Healthcare records were paper. Communication between providers and payers happened by fax, phone, and mail. The law was designed to protect health information in that world — a world of filing cabinets, physical access controls, and human-readable documents that moved at the speed of postal delivery.
Three decades later, the US healthcare industry generates $4.5 trillion in annual revenue. Large language models process clinical notes in milliseconds. AI agents make triage recommendations, draft clinical documentation, flag billing anomalies, and predict patient deterioration. Wearable devices stream continuous biometric data from hundreds of millions of consumers. Cloud-based AI services process healthcare data across jurisdictions, time zones, and national borders. And HIPAA — the same law, substantively unchanged in its core privacy and security framework — is expected to govern all of it.
It cannot. Not because HIPAA was poorly written, but because it was written for a fundamentally different technological reality. The gaps between what HIPAA covers and what healthcare AI requires are not edge cases or theoretical concerns. They are structural deficiencies that create real compliance risk for every health system, payer, and technology vendor deploying AI in clinical settings today.
Closing these gaps operationally is possible — see our case study on automating HIPAA compliance with SOC 2 continuous monitoring.
This analysis identifies and examines seven specific gaps where HIPAA fails to adequately address healthcare AI, surveys the state laws attempting to fill those gaps, maps the NIST AI Risk Management Framework to healthcare, and provides a practical compliance architecture for organizations that cannot wait for federal legislation to catch up.
HIPAA in 1996 vs. Healthcare in 2026
To understand why HIPAA is inadequate for AI, you need to understand what it was designed to address. The HIPAA Privacy Rule (finalized in 2000, effective 2003) established national standards for the protection of individually identifiable health information. The Security Rule (finalized in 2003, effective 2005) set standards for protecting electronic protected health information (ePHI). The Breach Notification Rule (2009, via HITECH) required reporting of unauthorized PHI disclosures.
These rules assume a specific technology model: data exists in identifiable systems (databases, EHRs, claims platforms), controlled by identifiable entities (covered entities and business associates), accessed by identifiable people (workforce members with role-based access), for identifiable purposes (treatment, payment, healthcare operations). Every HIPAA safeguard — administrative, physical, and technical — maps to this model.
Healthcare AI breaks every one of these assumptions. Data does not stay in identifiable systems — it flows into LLM context windows, embedding spaces, and model weights. The entities processing data include AI models that are not clearly "business associates" under current definitions. Access is not by identifiable people — it is by algorithms that operate at scale without human-by-human authorization. And the purposes of data use expand beyond treatment, payment, and operations to include model training, inference, evaluation, and continuous learning.
The healthcare industry that HIPAA was designed to protect was worth approximately $1 trillion in 1996. Today it is $4.5 trillion. The data volumes are incomparable. A single academic medical center generates petabytes of clinical, imaging, genomic, and operational data annually. The attack surface has expanded from physical building access and fax interception to cloud infrastructure, API endpoints, model extraction attacks, and prompt injection. And yet the core regulatory framework has not undergone a fundamental revision to account for any of this.
Gap 1: PHI in LLM Context Windows
When a clinician asks an AI system to summarize a patient's medical history, the patient's protected health information enters the LLM's context window. This is the fundamental interaction pattern of healthcare AI, and HIPAA does not clearly address it.
HIPAA defines specific categories of PHI handling: use (sharing within a covered entity), disclosure (sharing with an external party), storage (maintaining in a system), and transmission (sending between systems). When PHI enters an LLM context window, which of these is occurring?
If the LLM is hosted by a cloud vendor under a Business Associate Agreement, sending PHI to the model API is arguably a disclosure to a business associate — which is permitted under HIPAA for treatment, payment, and healthcare operations purposes. But what happens inside the context window is not a disclosure in any traditional sense. The model processes the information through billions of parameters, generating outputs that may contain derivatives of the PHI without containing the original identifiers. Is the model's internal processing a "use"? Is the generated output a new "disclosure"? If the model temporarily holds PHI in GPU memory during inference, is that "storage" subject to the Security Rule?
The Minimum Necessary Standard adds further complexity. HIPAA requires that covered entities limit PHI disclosures to the minimum necessary for the intended purpose. But LLMs do not process information selectively — they process the entire context window. If a clinician's prompt includes a full patient chart to ask a specific clinical question, the model "sees" every piece of PHI in that chart, even though only a subset is relevant to the question. Does this violate the Minimum Necessary Standard? There is no regulatory guidance that answers this question.
The HHS Office for Civil Rights (OCR) December 2023 letter to Congress acknowledged that "the use of AI and other advanced technologies in healthcare raises questions about how the HIPAA Rules apply," but stopped short of providing definitive guidance. The letter noted that OCR is "considering whether additional rulemaking or guidance may be necessary" — a statement that, as of March 2026, has not resulted in new rules specifically addressing AI.
For compliance officers, the practical implication is clear: every time PHI enters an LLM prompt, you are operating in a regulatory gray zone where the rules were not written with this use case in mind. The safest interpretation is to treat every LLM interaction containing PHI as both a use and a potential disclosure, apply the Minimum Necessary Standard to prompt construction, and log every interaction for audit purposes. But this interpretation is not mandated by law — it is a best practice born from the absence of specific guidance.
Gap 2: De-Identification Is Broken for AI
HIPAA provides two methods for de-identifying health information so that it is no longer considered PHI: the Safe Harbor method (removing 18 specific identifiers) and the Expert Determination method (a qualified expert certifies that re-identification risk is "very small"). De-identified data is exempt from HIPAA entirely. This framework was adequate when de-identified data consisted of structured database fields. It is fundamentally inadequate for multimodal AI data.
The Safe Harbor method's 18 identifiers were defined in the era of structured data: names, dates, phone numbers, Social Security numbers, medical record numbers, geographic subdivisions smaller than a state, and so forth. These identifiers map cleanly to database columns. Remove the columns, and the data is de-identified.
But healthcare AI processes unstructured data: clinical notes ("the patient's daughter, who lives on Elm Street, mentioned that..."), radiology images (which can contain burned-in patient information and facial features in CT/MRI scans), voice recordings (which contain biometric voiceprints), genomic sequences (which are inherently unique identifiers), and wearable data streams (which contain gait patterns, heart rhythm signatures, and sleep patterns that are individually identifiable).
Research from Nature Communications has demonstrated that individuals can be uniquely re-identified from as few as 15 demographic attributes with 99.98% accuracy, even in "anonymized" datasets. A 2022 study published on arXiv showed that large language models can memorize and reproduce training data, including potentially sensitive information, through targeted prompting techniques. The Harvard Privacy Tools Project has documented numerous cases where supposedly de-identified health datasets were re-identified using auxiliary information.
For AI systems specifically, the re-identification risk is amplified by several factors. LLMs can correlate patterns across seemingly unrelated data points to infer identities. Multimodal models that process both text and images can link de-identified clinical notes to identifiable imaging data. And the training data itself may contain memorized associations that surface during inference — a phenomenon researchers call training data extraction.
The Expert Determination method, while more flexible than Safe Harbor, requires statistical proof that re-identification risk is "very small." But there is no established methodology for calculating re-identification risk from LLM inference outputs or from data that has been processed through neural network layers. The expert determination framework assumes that de-identification is a static property of a dataset — remove certain fields, and the data is de-identified. In reality, re-identification risk is contextual and dynamic: the same data may be identifiable or not depending on what other data an adversary has access to and what computational tools they can apply.
The practical consequence is that organizations using AI in healthcare cannot rely on HIPAA's de-identification standards as a safe harbor. Data that passes the Safe Harbor test may still be identifiable when processed by AI systems, and there is no regulatory framework for assessing or mitigating that risk.
Gap 3: BAA Ambiguity for AI Vendors
The Business Associate Agreement is HIPAA's primary mechanism for extending privacy and security obligations to third parties that handle PHI on behalf of covered entities. When a health system uses an AI vendor to process clinical data, the vendor must sign a BAA. But the BAA framework was designed for clearly defined services — claims processing, billing, data hosting — not for AI systems whose data handling is opaque by nature.
The major AI providers now offer BAAs for their API services. OpenAI offers a BAA for its API (Enterprise tier), committing to zero data retention and no training on customer data. Anthropic provides a BAA for its Claude API with similar commitments: zero retention by default and no training on PHI. Microsoft Azure OpenAI provides BAA coverage under the broader Azure BAA, with customer-controlled data retention and HITRUST certification. Self-hosted open-source models (Llama, Mistral, etc.) eliminate the BAA question entirely — if you host the model, you control the data — but shift the entire compliance burden to your organization.
However, signing a BAA does not equal HIPAA compliance. A BAA establishes the vendor's obligations regarding PHI they receive. It does not address how PHI is used in prompts you construct, whether your prompt engineering inadvertently creates minimum necessary violations, how AI-generated outputs containing PHI derivatives are stored and shared, whether the model's behavior (hallucination, confabulation) constitutes an unauthorized disclosure, or what happens when a model generates clinically inaccurate information that includes real PHI.
The BAA framework assumes the business associate performs a defined service with defined data inputs and outputs. AI is fundamentally different: the outputs are probabilistic, not deterministic. A billing service processes a claim and returns a result. An LLM processes a prompt and returns a generated response that may include PHI, derivatives of PHI, hallucinated information, or combinations of all three. The BAA does not — and was not designed to — address the compliance implications of probabilistic outputs.
Furthermore, the distinction between "API" and "consumer product" creates confusion. OpenAI offers a BAA for its API but not for ChatGPT. A clinician who copies patient information into ChatGPT (rather than a BAA-covered API integration) has created a HIPAA violation that no BAA can retroactively cure. The proliferation of AI tools that look consumer-simple but handle enterprise-sensitive data creates a shadow AI problem that HIPAA's BAA framework cannot address.
Gap 4: Algorithmic Decisions and the Right to Explanation
HIPAA contains no provision requiring covered entities or business associates to explain how AI systems make decisions that affect patient care, coverage, or access. This is a critical gap as AI increasingly influences clinical and administrative decisions in healthcare.
The European Union's AI Act (effective August 2024, with obligations phasing in through 2027) classifies healthcare AI as "high-risk" and requires transparency, human oversight, and documentation of AI decision-making processes. The EU's GDPR Article 22 grants individuals the right not to be subject to decisions based solely on automated processing and the right to obtain "meaningful information about the logic involved." HIPAA has no equivalent.
In practice, AI is already making consequential decisions in US healthcare. Utilization management AI determines whether prior authorization requests are approved or denied. Clinical decision support AI influences treatment recommendations. Risk stratification AI determines which patients receive proactive outreach and which do not. Predictive models determine staffing levels, bed assignments, and resource allocation.
A 2023 U.S. Senate investigation found that Medicare Advantage insurers were using AI-driven utilization management tools to deny care at increasing rates, with UnitedHealthcare's post-acute care denial rate jumping from 10.9% to 22.7% between 2020 and 2022. Patients denied care by these algorithms had no regulatory right to understand how the AI reached its denial decision. HIPAA's individual rights (access, amendment, accounting of disclosures) do not extend to algorithmic transparency.
The absence of a right to explanation means patients cannot challenge AI-made decisions on algorithmic grounds, clinicians cannot audit the reasoning behind AI recommendations, health systems cannot verify that AI decisions comply with clinical practice guidelines, and regulators cannot assess whether AI-driven utilization management constitutes a systematic denial of necessary care. This gap creates both patient safety risks and legal liability exposure that HIPAA does not address.
Gap 5: Training Data Provenance
When a health system deploys an AI model for clinical use, a fundamental question arises: what data was the model trained on? If the model was trained on protected health information — even inadvertently — the health system may be deploying a model that contains memorized PHI in its weights, creating a potential HIPAA violation every time the model generates output.
HIPAA's framework addresses data at rest, in transit, and in use. It does not address data that has been absorbed into model parameters through training. The distinction matters because PHI that exists in a database can be deleted, access-controlled, and audited. PHI that has been encoded into the weights of a neural network through gradient descent cannot be selectively removed without retraining the entire model — a process called machine unlearning that remains an active area of research with no production-ready solutions for large language models.
The landmark Carlini et al. (2021) paper "Extracting Training Data from Large Language Models" demonstrated that GPT-2 could be prompted to reproduce verbatim text from its training data, including personally identifiable information. Subsequent research has shown that larger models are more susceptible to training data extraction, not less. A model trained on clinical notes containing PHI could, under the right prompting conditions, reproduce fragments of those notes — names, diagnoses, treatment plans — in its outputs.
For health systems, the training data provenance problem creates several compliance challenges. Commercial AI models (GPT-4, Claude, Gemini) do not fully disclose their training data composition. Vendors state that their models were not trained on PHI, but independent verification is impossible. If a model was trained on publicly scraped data that included improperly de-identified health records (a known issue with Common Crawl and similar datasets), the health system deploying that model has no way to detect or mitigate the exposure.
Fine-tuned models create additional risk. When a health system fine-tunes a base model on its own clinical data, the fine-tuned model demonstrably contains information derived from that PHI. If the fine-tuned model is later shared, stolen, or accessed by unauthorized parties, is the model itself a "disclosure" of PHI? HIPAA has no answer because the concept of PHI encoded in model weights did not exist when the law was written.
The October 2023 Executive Order on AI Safety directed federal agencies to develop guidelines for AI data provenance, but as of March 2026, no binding regulations specifically require healthcare AI vendors to certify that their training data is free of PHI. The gap between what is technically needed and what is legally required remains vast.
Gap 6: Wearable and Consumer Health Data Outside HIPAA
Hundreds of millions of Americans generate continuous health data through consumer devices: Apple Watch (heart rate, ECG, blood oxygen, fall detection), Fitbit (activity, sleep, heart rate variability), Oura Ring (sleep staging, temperature, HRV), continuous glucose monitors (Dexcom, Libre), and a rapidly expanding ecosystem of consumer health wearables. This data is often more granular, more continuous, and more clinically valuable than data collected in traditional clinical settings.
None of it is covered by HIPAA.
HIPAA applies to covered entities (healthcare providers, health plans, healthcare clearinghouses) and their business associates. Apple, Google, Fitbit, Oura, Garmin, and other consumer health device manufacturers are not covered entities. The health data they collect — even when it is identical in content to data that would be PHI if collected by a provider — is not protected health information under HIPAA. It is governed, if at all, by the FTC Health Breach Notification Rule and state consumer privacy laws, which provide significantly weaker protections.
The AI implications are profound. Consumer health data is increasingly used to train AI models for clinical applications. Research models trained on Apple Watch ECG data, Fitbit activity data, and CGM glucose patterns are being developed for clinical deployment. When these models enter clinical settings, they carry training data that was never subject to HIPAA protections — creating a backdoor through which unprotected health data enters the regulated healthcare ecosystem.
Furthermore, the boundary between consumer and clinical health data is dissolving. Apple's Health Records feature allows users to import clinical data from EHRs into the Apple Health app, where it is mixed with consumer-generated data and governed by Apple's privacy policy rather than HIPAA. When an AI model processes this combined dataset — clinical diagnoses alongside consumer wearable data — which regulatory framework applies?
The 21st Century Cures Act and ONC's information blocking rules promote patient access to health data, including through consumer-facing APIs. But they do not extend HIPAA protections to consumer platforms that receive and process this data. The regulatory gap means that the most comprehensive health data picture for any individual American — combining clinical records, wearable data, genomic information, and behavioral data — exists entirely outside HIPAA's protective framework.
Gap 7: Cross-Border Data Flows
Cloud-based AI services process data in data centers distributed across geographic regions. When a US health system sends PHI to an AI API, where is that data physically processed? HIPAA requires safeguards for PHI but does not explicitly restrict where PHI can be processed geographically, as long as appropriate safeguards are in place. This creates complex compliance scenarios when AI vendors process healthcare data in multiple jurisdictions.
The practical challenges are significant. Major cloud providers operate data centers in the US, EU, Asia-Pacific, and other regions. AI inference may be routed to different data centers based on latency, load balancing, or capacity. A health system's BAA may specify US-only data processing, but verifying that commitment requires understanding the vendor's infrastructure architecture — which is typically proprietary.
The EU's General Data Protection Regulation (GDPR) imposes strict requirements on transferring personal data (including health data) outside the EU. If a US health system treats EU citizens (medical tourism, telehealth, international clinical trials) and processes their data through an AI system, both HIPAA and GDPR may apply — and their requirements may conflict. GDPR's data minimization principle is more restrictive than HIPAA's minimum necessary standard. GDPR's right to erasure has no HIPAA equivalent. And GDPR's restrictions on automated decision-making create obligations that HIPAA does not.
For organizations operating AI in healthcare, cross-border data flow creates jurisdictional uncertainty. Which law applies when data crosses borders during processing? How do you comply with data localization requirements when using globally distributed AI services? What are the breach notification obligations when a data incident involves PHI processed in multiple jurisdictions? HIPAA provides no framework for answering these questions, because when it was written, data processing was local.
State Laws Filling the Gaps
In the absence of federal AI legislation, state legislatures are moving aggressively to regulate AI in healthcare. The result is a patchwork of state laws that create additional compliance obligations beyond HIPAA — and, in some cases, conflict with each other.
Texas HB 1709: AI Transparency in Insurance Decisions
Effective September 2025, Texas HB 1709 requires insurance companies to disclose when artificial intelligence is used in claim processing and coverage decisions. The law mandates that insurers provide notice to consumers when AI has been used in a decision that adversely affects them and establish a process for consumers to request human review of AI-made decisions. For health insurers operating in Texas, this creates transparency obligations that HIPAA does not require.
The practical impact extends beyond Texas-domiciled insurers. National payers operating in Texas must implement AI transparency mechanisms for their Texas members, which often leads to system-wide implementation for operational efficiency. The law effectively creates a de facto national standard for AI transparency in insurance decisions.
Colorado SB 24-205: Comprehensive AI Governance for Insurance
Colorado's Senate Bill 24-205, effective in 2026, is the most comprehensive state-level AI governance law affecting healthcare. It requires insurers to conduct algorithmic impact assessments for AI systems that make or substantially assist in making coverage, claims, or underwriting decisions. The law mandates bias testing across protected characteristics (race, gender, age, disability status), documentation of AI system design and training data, annual reporting to the Colorado Division of Insurance, and a consumer right to contest AI-made decisions.
Colorado's law goes further than any federal requirement in mandating that insurers demonstrate their AI systems do not produce discriminatory outcomes. For health systems and payers using AI for utilization management, clinical decision support, or population health management, Colorado's requirements create a compliance framework that is significantly more demanding than HIPAA's technology-neutral approach.
California AB 331: Automated Decision Systems in Healthcare
California's Assembly Bill 331, advancing through the legislature in 2026, targets automated decision systems (ADS) used in healthcare and other high-stakes domains. The bill requires deployers of ADS to conduct impact assessments before deployment, provide consumers with notice that ADS is being used, enable consumers to opt out of ADS-based decisions where feasible, and maintain documentation of ADS performance and accuracy. California's approach is notable for its focus on the deployer (the health system or payer using the AI) rather than the developer (the AI vendor), creating obligations for organizations that implement AI systems even if they did not build them.
Maryland SB 601: AI in Utilization Review
Maryland's Senate Bill 601, effective in 2025, specifically targets AI in health insurance utilization review — the process by which payers determine whether to authorize or deny healthcare services. The law requires that AI-driven utilization review decisions be supervised by licensed physicians, prohibits fully automated denials of care without human clinical review, and mandates that AI systems used in utilization review be regularly validated against clinical practice guidelines. This law directly addresses the concerns raised by the Senate investigation into Medicare Advantage AI-driven denials, creating a state-level requirement for human oversight of AI in coverage decisions.
The Compliance Complexity
For national healthcare organizations, the emerging state AI law landscape creates significant compliance complexity. A health system operating in multiple states must comply with Texas's AI transparency requirements, Colorado's algorithmic impact assessment mandates, California's consumer opt-out provisions, and Maryland's physician supervision requirements — all while maintaining HIPAA compliance as the baseline. These state laws are not harmonized, and their requirements sometimes conflict, creating a compliance environment that is more complex and costly than a single updated federal framework would be.
NIST AI Risk Management Framework Applied to Healthcare
In the absence of updated federal regulation, the NIST AI Risk Management Framework (AI RMF 1.0), published in January 2023, provides the most comprehensive voluntary framework for managing AI risk. While not legally binding, the AI RMF is increasingly referenced by state regulators, included in procurement requirements, and cited in legal proceedings as a standard of reasonable care. For healthcare organizations, mapping the AI RMF to existing HIPAA compliance programs provides a structured approach to addressing the gaps identified above.
Govern: Organizational AI Governance
The Govern function establishes organizational structures and policies for AI risk management. In healthcare, this means establishing an AI governance committee with representation from clinical, legal, compliance, IT, and privacy leadership. It requires developing AI-specific policies that extend HIPAA compliance programs to cover LLM use, prompt engineering standards, and output review procedures. Organizations must define risk tolerance for AI applications in clinical versus administrative versus research contexts and create an AI system inventory that catalogs every AI tool, its data inputs, its decision outputs, and its HIPAA compliance status.
Map: Understanding AI Context and Risk
The Map function requires organizations to understand the context in which AI systems operate and the risks they create. For healthcare AI, mapping includes cataloging all data flows where PHI enters AI systems (prompts, fine-tuning data, evaluation datasets), identifying where AI decisions affect patient care, coverage, or access, assessing re-identification risk for data processed by AI systems (beyond HIPAA's Safe Harbor checklist), and documenting the training data provenance for every deployed AI model to the extent possible.
Measure: Quantifying AI Risk
The Measure function requires quantitative assessment of AI risks. In healthcare, this means measuring AI model accuracy, fairness, and reliability across patient demographics, quantifying the rate of PHI exposure in AI outputs (hallucination of real patient data), testing de-identification effectiveness against AI-powered re-identification attacks, and benchmarking AI decision quality against clinical practice guidelines and human clinician decisions.
Manage: Mitigating AI Risk
The Manage function requires organizations to implement controls that mitigate identified AI risks. For healthcare, management controls include prompt sanitization gateways that enforce minimum necessary before PHI enters AI systems, output filtering that detects and redacts unintended PHI in AI-generated content, human-in-the-loop requirements for clinical decisions that affect patient care, incident response playbooks specific to AI failures (hallucination of PHI, discriminatory outputs, model drift), and continuous monitoring of AI system behavior for performance degradation or emergent risks.
What a Modern "HIPAA for AI" Would Look Like
If Congress were to update HIPAA to address AI — or pass a new federal healthcare AI law — what would it need to include? Based on the gaps identified in this analysis, a modern regulatory framework would require at minimum the following provisions.
1. Explicit AI Data Processing Definitions
The law would need to define how HIPAA's existing categories (use, disclosure, storage, transmission) apply to AI processing. Specifically: is PHI in a prompt a disclosure? Is model inference a use? Is PHI encoded in model weights a form of storage? Without these definitions, compliance remains interpretive.
2. AI-Specific De-Identification Standards
Safe Harbor's 18 identifiers are insufficient for multimodal AI data. A modern standard would need to address re-identification risk from unstructured text, imaging, voice, genomic, and wearable data — and require dynamic risk assessment rather than static checklist compliance.
3. AI Vendor Accountability Beyond BAAs
BAAs should be supplemented with AI-specific obligations: training data certifications, model behavior warranties, memorization risk assessments, and incident notification requirements specific to AI failures (not just data breaches).
4. Algorithmic Transparency and Right to Explanation
Patients should have the right to know when AI influenced decisions affecting their care or coverage and to receive meaningful explanations of how the AI reached its conclusions. This aligns with the EU AI Act's approach and would address the utilization management AI concerns identified by the Senate investigation.
5. Training Data Provenance Requirements
AI vendors serving healthcare should be required to certify the provenance of their training data, attest that no HIPAA-protected information was used without authorization, and implement machine unlearning capabilities for data that was used improperly.
6. Extended Coverage for Consumer Health Data
Health data generated by consumer devices should receive baseline privacy protections when it is used for clinical purposes or when it is combined with clinical data — regardless of whether the entity collecting it is a covered entity under current definitions.
7. Cross-Border Data Processing Standards
The law should establish clear requirements for AI processing of PHI across jurisdictions, including data localization options, jurisdictional conflict resolution, and breach notification harmonization.
8. Preemption of State AI Laws
To avoid the compliance complexity of 50 different state AI healthcare laws, a federal framework should preempt state laws on AI in healthcare while setting a floor that states can exceed for consumer protection. Without preemption, the current trajectory leads to an unworkable patchwork of conflicting requirements.
Practical Compliance Architecture for Today
Federal legislation takes years. Healthcare organizations deploying AI cannot wait. Here is a practical compliance architecture that addresses the seven HIPAA-AI gaps using available tools, frameworks, and contractual mechanisms.
Layer 1: Data Governance
PHI Classification Engine: Implement automated PHI detection and classification for all data entering AI systems. Use NLP-based entity recognition to identify PHI in unstructured text before it is sent to AI models. Tag data with sensitivity levels and apply access controls based on classification. This addresses Gap 1 (PHI in context windows) by ensuring you know exactly what PHI enters which AI system.
De-Identification Pipeline: Go beyond Safe Harbor. Implement Expert Determination with k-anonymity and differential privacy for data used in AI systems. For unstructured data, use purpose-built de-identification models (such as Microsoft Presidio or similar tools) that address the limitations identified in Gap 2. Regularly test de-identification effectiveness against re-identification attacks using adversarial testing.
Consent Management: Implement granular consent mechanisms that allow patients to control whether their data is used in AI processing, fine-tuning, or research — beyond HIPAA's current minimum requirements. This future-proofs against state laws (Colorado, California) that are requiring AI-specific consent provisions. For guidance on building consent-driven architectures aligned with CMS and ONC interoperability regulations, see our regulatory compliance analysis.
Data Provenance Registry: Maintain a registry that tracks the origin, transformation, and destination of all data used in AI systems. For fine-tuned models, record exactly which datasets were used for training, when, and under what authorization. This addresses Gap 5 (training data provenance) by creating an auditable chain of custody.
Layer 2: AI Processing Controls
Prompt Sanitization Gateway: Deploy a middleware layer between clinical systems and AI APIs that enforces the Minimum Necessary Standard on prompts. The gateway strips PHI that is not required for the specific AI task, replaces identifiers with tokens where possible, and logs the original and sanitized prompts for audit. For a technical blueprint of how to build these safeguards, see our guide on building HIPAA-compliant AI agents.
BAA-Covered or Self-Hosted Inference: Every AI model processing PHI must operate under a BAA (for cloud-hosted models) or within your own HIPAA-compliant infrastructure (for self-hosted models). No exceptions. Maintain a registry of which models are BAA-covered and which are not. Block access to non-BAA models from systems that handle PHI.
Output Filtering: Implement automated PHI detection on AI model outputs before they are returned to users or stored in clinical systems. Flag outputs that contain PHI not present in the input (potential memorization/hallucination of training data). Redact, log, and investigate flagged outputs.
Audit Trail: Log every AI interaction: input, output, model version, timestamp, user, purpose, and PHI classification. Retain logs for the HIPAA-required minimum of six years. Design logs to support both HIPAA accounting of disclosures and the algorithmic audit requirements emerging in state laws.
Layer 3: Monitoring and Compliance
NIST AI RMF Implementation: Map your AI governance program to the four NIST AI RMF functions (Govern, Map, Measure, Manage). Use the AI RMF profiles and playbooks to structure your risk assessment and mitigation activities. This provides defensible documentation of reasonable care in the absence of specific federal AI regulation.
Algorithmic Impact Assessment: Conduct impact assessments for all AI systems that affect patient care or coverage decisions, following Colorado's SB 24-205 as the most comprehensive template. Assess for bias, accuracy, reliability, and clinical validity. Repeat assessments quarterly or when models are updated.
State Law Compliance Matrix: Maintain a matrix mapping your AI deployments to applicable state laws. For each state where you operate, document which AI transparency, consent, bias testing, and human oversight requirements apply and how you comply. Update quarterly as new state laws take effect.
Incident Response Playbook: Develop AI-specific incident response procedures that address scenarios HIPAA's breach notification rule does not contemplate: AI hallucination of real patient PHI, discriminatory AI outputs, model drift leading to clinical safety concerns, and training data contamination. Include notification triggers, investigation procedures, and remediation steps. For a comprehensive checklist approach to maintaining compliance across all dimensions, refer to the essential HIPAA compliance checklist for developers.
The Path Forward
HIPAA was not built for AI. This is not a criticism of the law — it is a recognition that technology has outpaced regulation by three decades. The seven gaps identified in this analysis are not theoretical. They create real compliance risk, real patient safety concerns, and real legal liability for every healthcare organization deploying AI today.
The regulatory landscape is evolving. HHS OCR is considering AI-specific guidance. State legislatures are passing AI healthcare laws. The NIST AI RMF provides a voluntary framework. The EU AI Act offers a model for comprehensive regulation. But none of these, individually or collectively, provide the clarity that healthcare organizations need right now.
The practical answer is layered defense: treat HIPAA as the compliance floor, implement the NIST AI RMF as your risk management framework, build the technical architecture described above, and monitor state laws as they evolve. Document everything. Err on the side of more protection, not less. And recognize that in a regulatory gray zone, your organization's policies and practices become the de facto standard by which you will be judged.
The healthcare industry spent 30 years building HIPAA compliance programs for a world of paper records and fax machines. It does not have 30 years to build compliance programs for AI. The organizations that act now — building robust, defensible AI compliance architectures before regulators mandate them — will have a significant competitive advantage when the regulatory landscape inevitably catches up.
Frequently Asked Questions
Does HIPAA apply to AI systems that process protected health information?
Yes, HIPAA applies to AI systems that process PHI — but with significant gaps. If a covered entity or business associate uses an AI system to process PHI, HIPAA's Privacy and Security Rules apply to that processing. However, HIPAA does not specifically define how its concepts (use, disclosure, minimum necessary, de-identification) apply to AI operations like LLM inference, model training, or probabilistic output generation. The law's protections apply, but their practical application to AI is ambiguous and lacks regulatory guidance from HHS OCR. Organizations should treat all AI processing of PHI as subject to HIPAA while implementing additional safeguards beyond what HIPAA explicitly requires.
Can healthcare organizations use ChatGPT or other consumer AI tools with patient data?
No. Consumer AI products like ChatGPT, Google Gemini (consumer version), and other free or consumer-tier AI tools are not covered by Business Associate Agreements and cannot be used to process PHI. Using these tools with patient data constitutes a HIPAA violation regardless of the user's intent. Healthcare organizations must use enterprise or API versions of AI tools that are covered by BAAs — such as OpenAI's Enterprise API, Anthropic's API, or Azure OpenAI — and must implement technical controls to prevent workforce members from using consumer AI tools with PHI. Shadow AI (unauthorized use of consumer AI tools) is one of the most significant HIPAA compliance risks in healthcare today.
Is AI-generated clinical content considered protected health information under HIPAA?
This is one of the unresolved questions in healthcare AI compliance. If an AI system generates clinical content (a note summary, a treatment recommendation, a risk assessment) based on a specific patient's PHI, the output likely constitutes PHI because it relates to an identifiable individual's health condition. However, if the AI generates general clinical guidance not tied to a specific patient, or if the output is sufficiently abstracted from the input PHI, it may not constitute PHI. The safest approach is to treat all AI-generated content that was derived from PHI as PHI for compliance purposes, subject to the same access controls, audit logging, and retention requirements as the source data.
What should be included in a BAA with an AI vendor?
A BAA with an AI vendor should include all standard HIPAA BAA provisions plus AI-specific clauses: a commitment that PHI will not be used for model training without explicit authorization, zero or defined-period data retention for prompts and outputs, geographic restrictions on where PHI is processed, incident notification requirements that cover AI-specific failures (memorization, hallucination of PHI, model compromise), model versioning and change notification requirements, the right to audit the vendor's AI-specific security controls, and subprocessor transparency (disclosure of any third-party services involved in AI processing). Standard BAA templates are insufficient for AI vendors — the unique risks of AI processing require tailored contractual protections.
How do state AI healthcare laws interact with HIPAA?
State AI healthcare laws operate alongside HIPAA, not in place of it. HIPAA establishes a federal floor for health information privacy, and states can impose additional requirements that exceed HIPAA's protections. State AI laws like Colorado SB 24-205, Texas HB 1709, California AB 331, and Maryland SB 601 create obligations (algorithmic impact assessments, AI transparency, bias testing, human oversight) that HIPAA does not address. Healthcare organizations must comply with both HIPAA and all applicable state laws, which creates significant compliance complexity for organizations operating across multiple states. There is currently no federal preemption of state AI healthcare laws, meaning the compliance burden will continue to increase as more states pass AI legislation.