The Problem Nobody Talks About Until Production
You have deployed an openEHR-based clinical data repository. Templates are uploaded, compositions are flowing in, AQL queries are working, and clinicians are using the system daily. Then someone says: "We need to add a field to the blood pressure archetype."
What happens next is the part of openEHR that most tutorials skip entirely. Archetype versioning in production is where clinical modeling theory meets operational reality. Change a live archetype incorrectly and you break queries, corrupt historical data, or silently lose clinical context.
This guide covers what actually happens when you change a live clinical model, how to version archetypes safely, and how to build a CI/CD pipeline for clinical models that prevents production incidents.
Semantic Versioning for Clinical Models
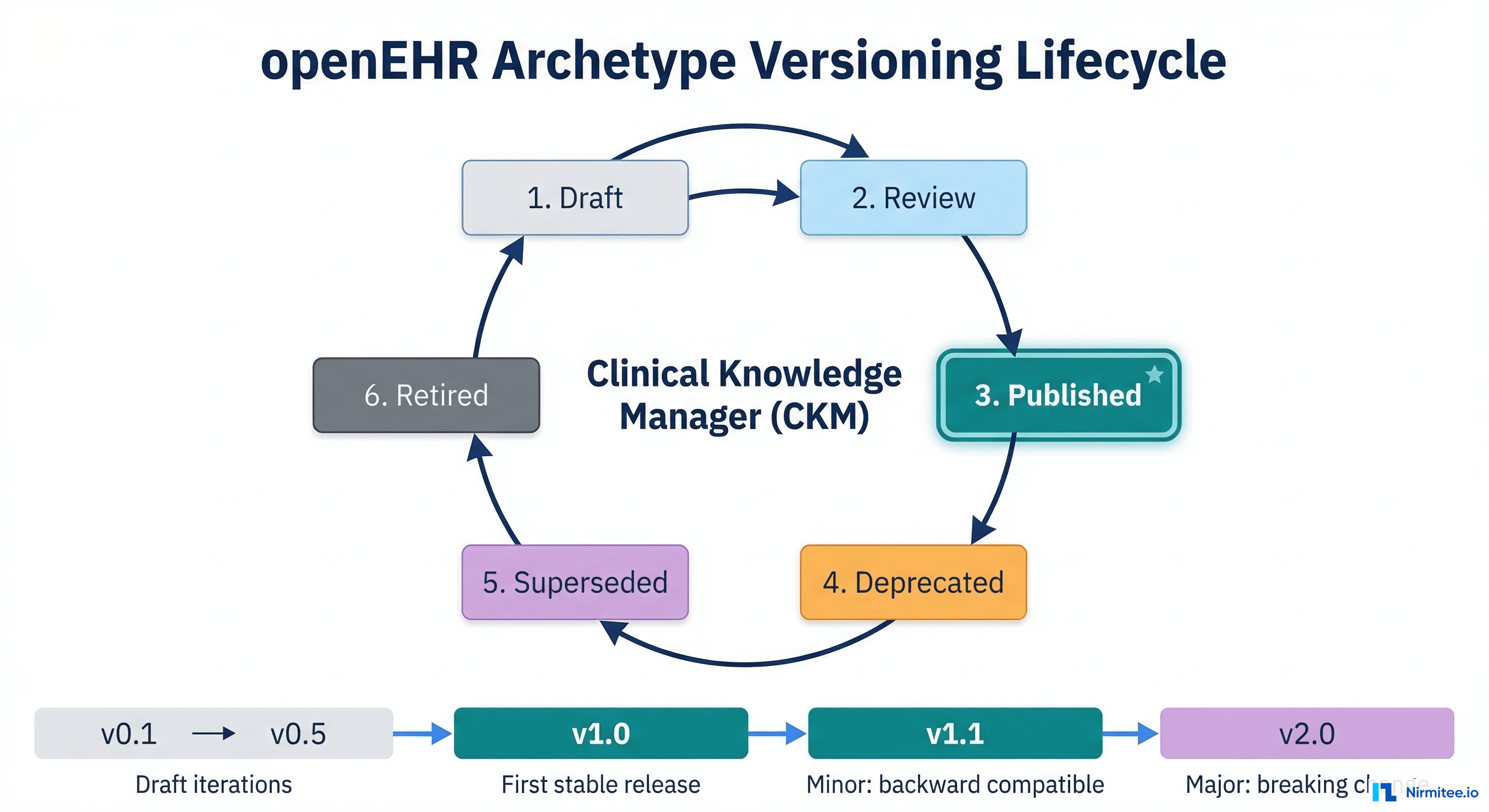
The openEHR Versioning Scheme
openEHR uses semantic versioning with a twist. An archetype version follows the major.minor.patch pattern, but the rules for what constitutes each type of change are defined by clinical impact, not just API compatibility.
- Major version (v1.0.0 to v2.0.0) — Breaking change to the archetype structure. Existing compositions may not validate against the new version. Examples: removing an element, changing a data type, tightening cardinality from optional to mandatory.
- Minor version (v1.0.0 to v1.1.0) — Backward-compatible addition. Existing compositions remain valid. Examples: adding an optional element, widening a value range, adding a new terminology binding.
- Patch version (v1.0.0 to v1.0.1) — Metadata-only change. No structural impact. Examples: fixing a description, adding a translation, correcting a comment.
In ADL 2, the version is encoded directly in the archetype identifier. The archetype org.openehr::openEHR-EHR-OBSERVATION.blood_pressure.v1.0.3 tells you exactly which version you are working with. In ADL 1.4 (still widely used), the version is simpler: openEHR-EHR-OBSERVATION.blood_pressure.v1 with only the major version in the ID and minor/patch tracked in the archetype header metadata.
Why This Matters More Than Software Versioning
In software, a breaking API change means clients need to update their integration code. In clinical data, a breaking archetype change means historical patient records may no longer be interpretable. A blood pressure recording from 2023 stored against archetype v1 must remain queryable and clinically meaningful even after archetype v2 is deployed in 2026. This is a regulatory requirement in most jurisdictions, not just a nice-to-have.
Breaking vs. Non-Breaking Changes
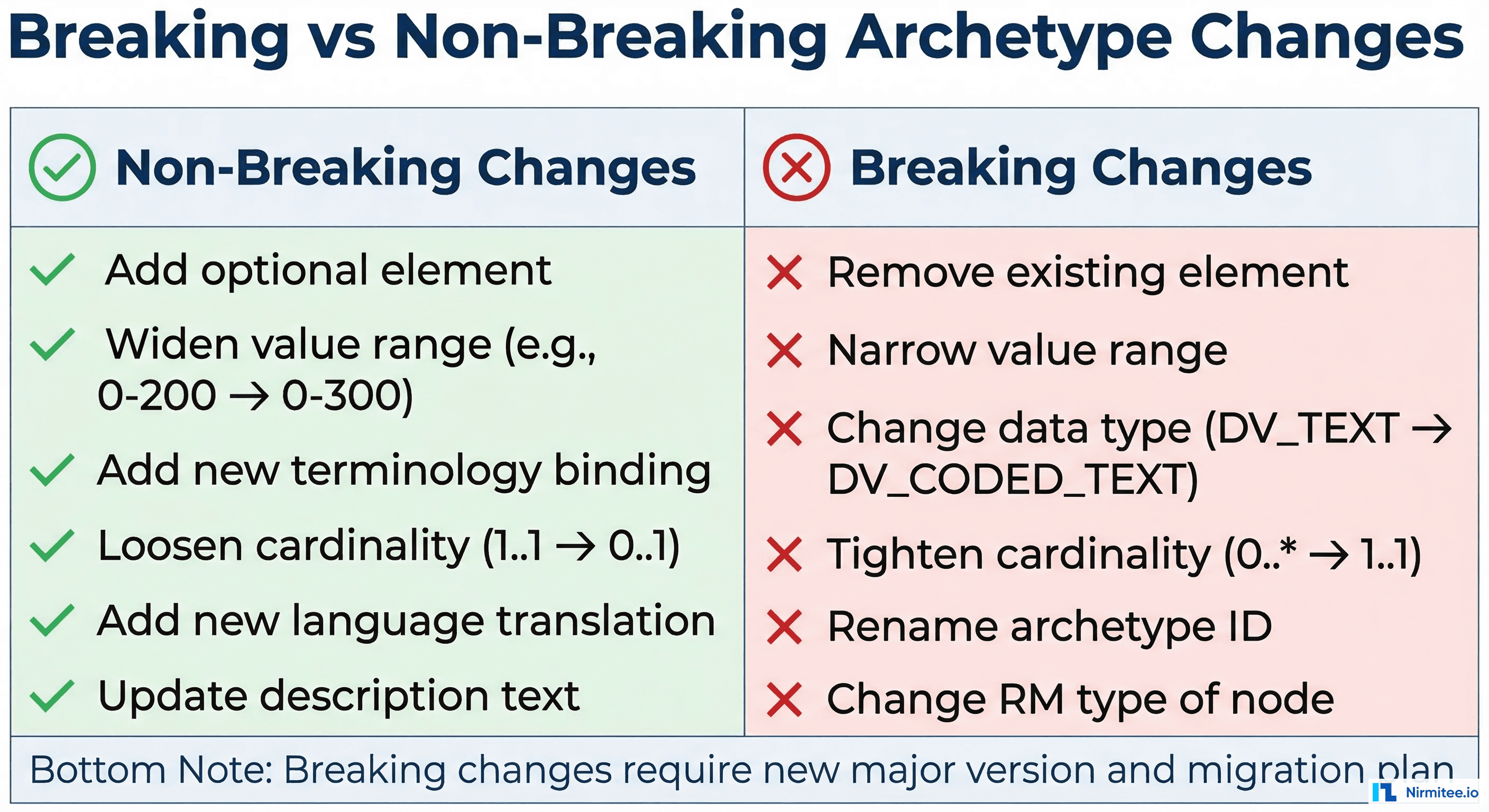
Non-Breaking Changes (Minor Version Bump)
These changes are safe to deploy without migrating existing data:
- Adding an optional element — Adding a new optional field like
measurement_methodto a blood pressure archetype. Existing compositions simply will not have this field; queries against it return NULL for historical records. - Widening a value range — Changing systolic blood pressure valid range from 0-300 mmHg to 0-400 mmHg. All existing values remain valid.
- Adding a terminology binding — Adding LOINC codes alongside existing SNOMED CT bindings. Existing SNOMED-coded data is unaffected.
- Loosening cardinality — Changing from
1..1(exactly one) to0..1(zero or one). Existing data with one value is still valid. - Adding language translations — Adding a Spanish translation to an English archetype. No structural impact.
Breaking Changes (Major Version Bump)
These changes invalidate existing compositions and require a migration strategy:
- Removing an element — Deleting the
body_positionfield from blood pressure. Existing compositions that contain this field are no longer valid against the new archetype version. - Changing a data type — Converting
DV_TEXT(free text) toDV_CODED_TEXT(coded value only). Existing free-text values cannot satisfy the new constraint. - Tightening cardinality — Changing from
0..*(zero or more) to1..1(exactly one). Existing compositions with zero or multiple values are now invalid. - Narrowing a value range — Reducing valid temperature from -50 to 100 Celsius down to 30 to 45 Celsius. Existing values outside the new range are invalid.
- Renaming or restructuring nodes — Changing the archetype path structure. All AQL queries referencing the old paths will break.
The Decision Framework
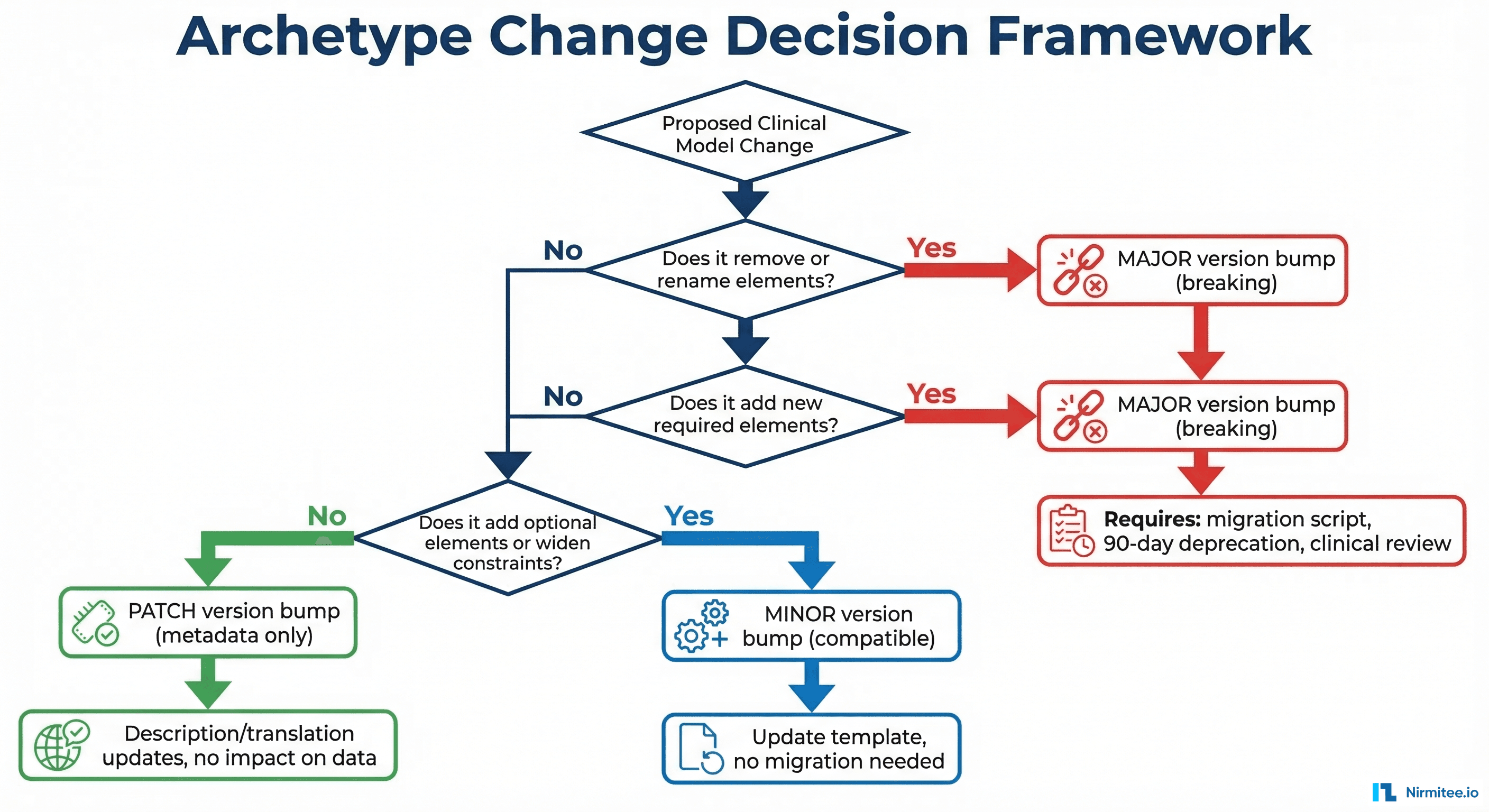
Before making any change, run through this decision tree:
- Does the change remove or rename any existing element? If yes, it is a major version change.
- Does the change add a new mandatory element? If yes, it is a major version change (existing compositions lack the required field).
- Does the change narrow constraints (tighter cardinality, smaller value ranges, more restrictive data types)? If yes, it is a major version change.
- Does the change add optional elements or widen constraints? If yes, it is a minor version change.
- Is it only a description, translation, or comment update? If yes, it is a patch version change.
ADL 1.4 to ADL 2 Migration
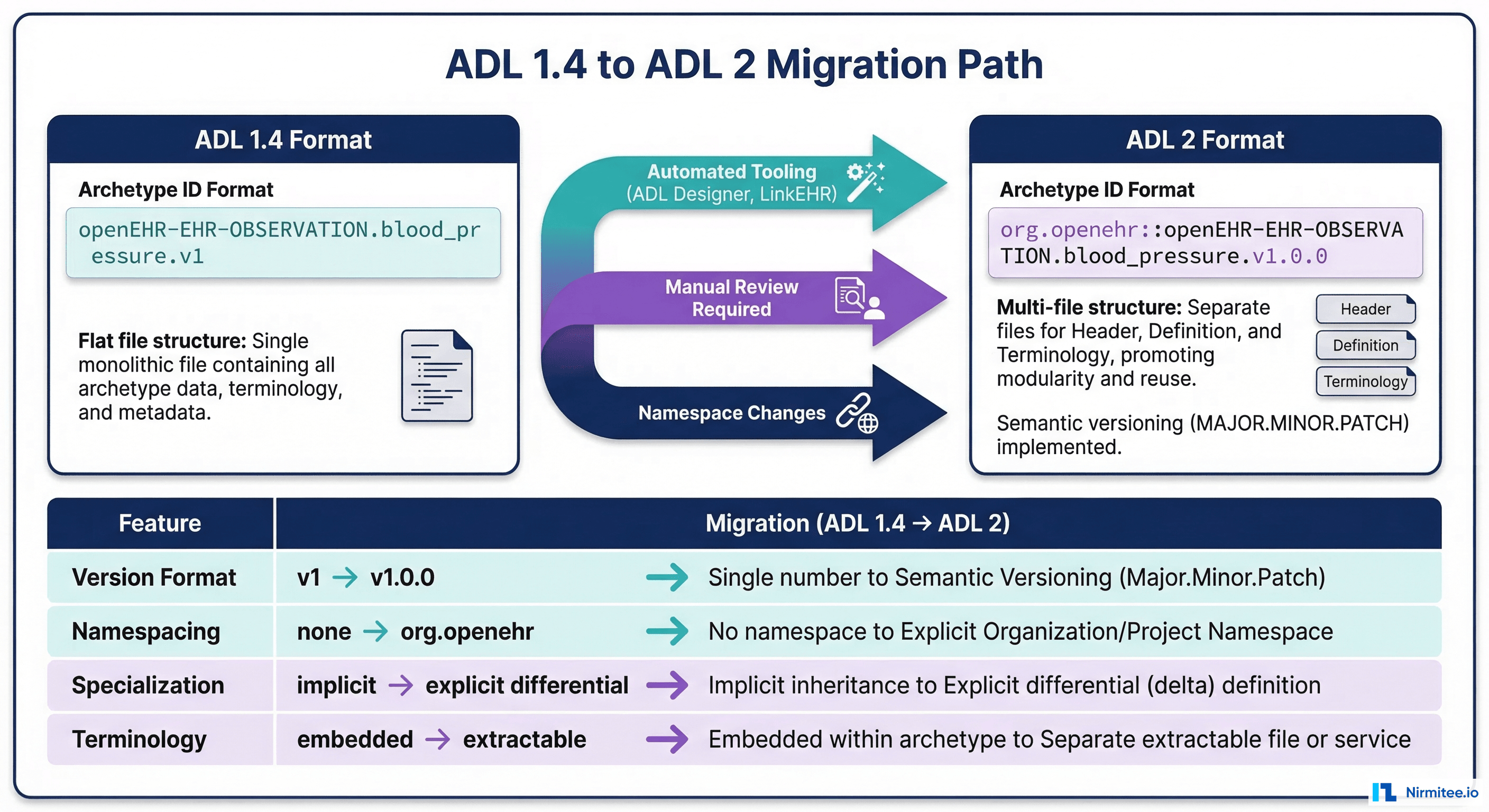
What Changed Between ADL Versions
ADL (Archetype Definition Language) 2 is a significant evolution from ADL 1.4. Most production openEHR systems today still run ADL 1.4 archetypes, but the ecosystem is moving toward ADL 2. Understanding the differences is critical for version management.
| Aspect | ADL 1.4 | ADL 2 |
|---|---|---|
| Version in ID | archetype.v1 (major only) | archetype.v1.0.3 (full semver) |
| Namespacing | None | org.openehr:: prefix |
| Specialization | Full copy with modifications | Differential format (only changes) |
| Terminology | Embedded in archetype | Extractable, referenceable |
| Validation | Loose, implementation-dependent | Strict, formally specified |
| Tooling | ADL Designer, Ocean tools | ADL Designer 2, Archie library |
Migration Strategy
Migrating from ADL 1.4 to ADL 2 is not a simple format conversion. The semantic versioning model changes, and specialized archetypes switch from full-copy to differential format. Here is the practical approach:
- Inventory your archetypes — Catalog all archetypes in use, noting which are international (from CKM) and which are local customizations.
- Use automated tooling — The ADL 1.4-to-2 converter in the Archie library handles most syntactic conversions. Run it on your entire archetype repository.
- Manual review required — Automated conversion handles syntax but not semantics. Have a clinical informaticist review each converted archetype to ensure clinical meaning is preserved.
- Update templates — OPTs (Operational Templates) need regeneration from the ADL 2 archetypes. This is a mechanical step but must be verified against your CDR.
- Test query compatibility — AQL queries should work the same against both ADL versions, but verify this explicitly for your critical queries.
What Happens to Existing Compositions
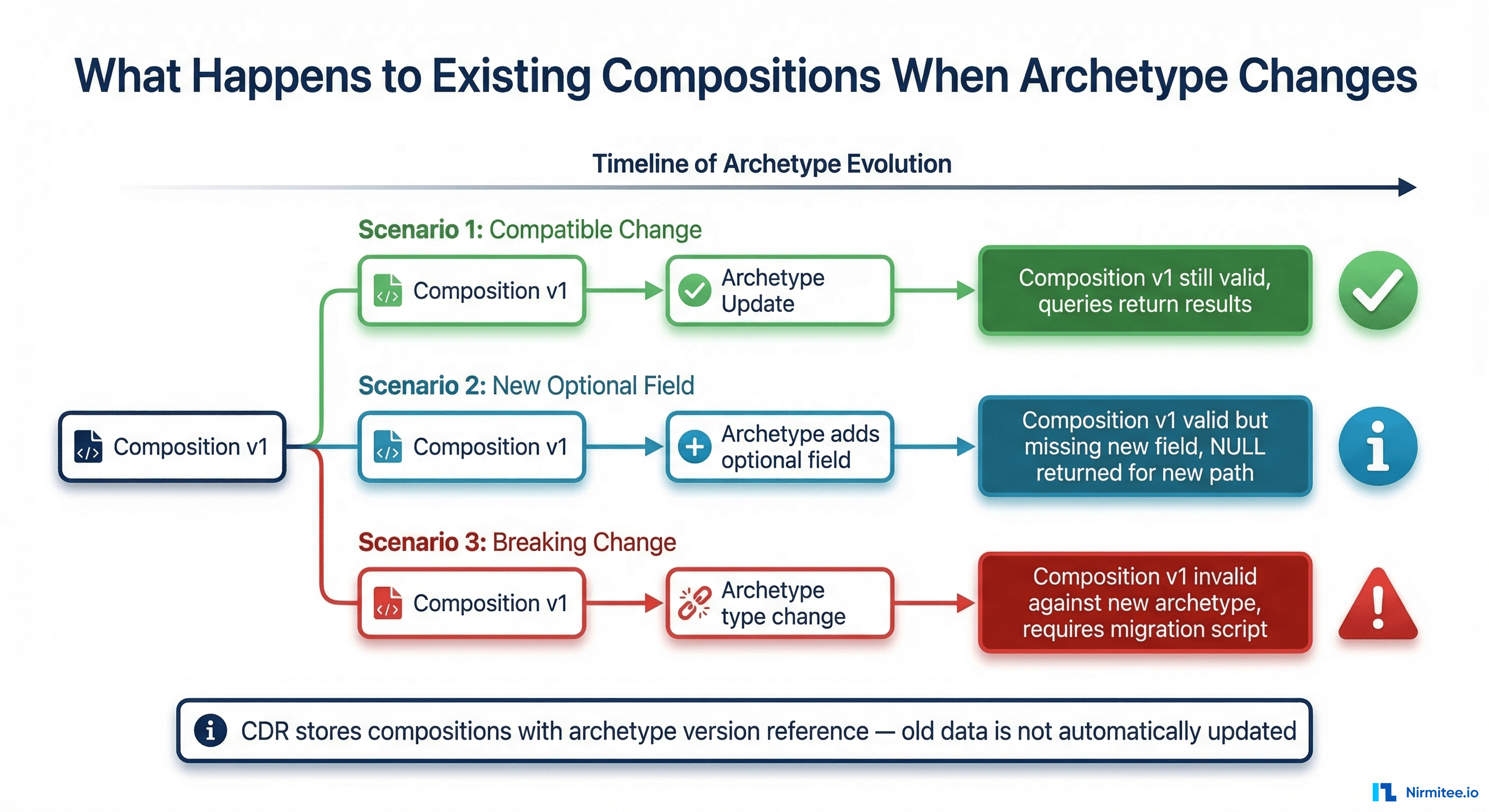
The Core Question
When you upload a new version of an archetype to your CDR, what happens to the compositions already stored against the previous version? The answer depends on your CDR implementation, but the general principles are consistent.
Scenario 1: Minor Version Change
You add an optional measurement_device field to the blood pressure archetype (v1.0.0 to v1.1.0). Existing compositions stored against v1.0.0:
- Remain valid — They satisfy all the constraints of v1.1.0 because the new field is optional.
- Return NULL for new field — AQL queries asking for
measurement_devicereturn NULL for historical records. - Do not need migration — No action required on existing data.
- New compositions use v1.1.0 — Going forward, the template includes the new field.
Scenario 2: Major Version Change
You change the blood pressure archetype to require body_position (was optional, now mandatory) and change clinical_interpretation from DV_TEXT to DV_CODED_TEXT. This is v1.x to v2.0.0.
- Existing compositions are invalid against v2.0.0 — They may lack the now-required
body_positionand have free-text values where coded values are now required. - CDR behavior varies:
- EHRbase — Stores compositions with a reference to the template version. Old compositions remain queryable via AQL using the v1 template. New compositions use v2. You can query across both versions.
- Better Platform — Supports template versioning with automatic version resolution. Queries can target specific versions or span all versions.
- Migration is optional but recommended — You can leave old data as-is (queryable via v1 paths) or run a migration script to upgrade old compositions to v2 format.
Writing a Composition Migration Script
When migration is required, here is the pattern:
# Composition migration script: v1 to v2 blood pressure
import requests
CDR_URL = "https://ehrbase.example.com/ehrbase/rest/openehr/v1"
# Step 1: Query all compositions using the old template
aql = """
SELECT c/uid/value as uid, e/ehr_id/value as ehr_id
FROM EHR e CONTAINS COMPOSITION c[openEHR-EHR-COMPOSITION.encounter.v1]
WHERE c/name/value = 'Blood Pressure Recording'
AND NOT EXISTS c/content[openEHR-EHR-OBSERVATION.blood_pressure.v2]
"""
# Step 2: For each composition, GET, transform, PUT
for uid, ehr_id in query_results:
# Get the full composition
comp = requests.get(f"{CDR_URL}/ehr/{ehr_id}/composition/{uid}").json()
# Transform: add default body_position, convert text to coded
bp_section = comp['content'][0] # blood pressure observation
bp_section['data']['events'][0]['data']['items'].append({
'_type': 'ELEMENT',
'name': {'value': 'Body position'},
'value': {
'_type': 'DV_CODED_TEXT',
'value': 'Sitting',
'defining_code': {'code_string': 'at1001', 'terminology_id': {'value': 'local'}}
}
})
# Update the composition (creates new version, preserves history)
requests.put(
f"{CDR_URL}/ehr/{ehr_id}/composition/{uid}",
json=comp,
headers={"If-Match": uid}
)CDR Version Management Strategies
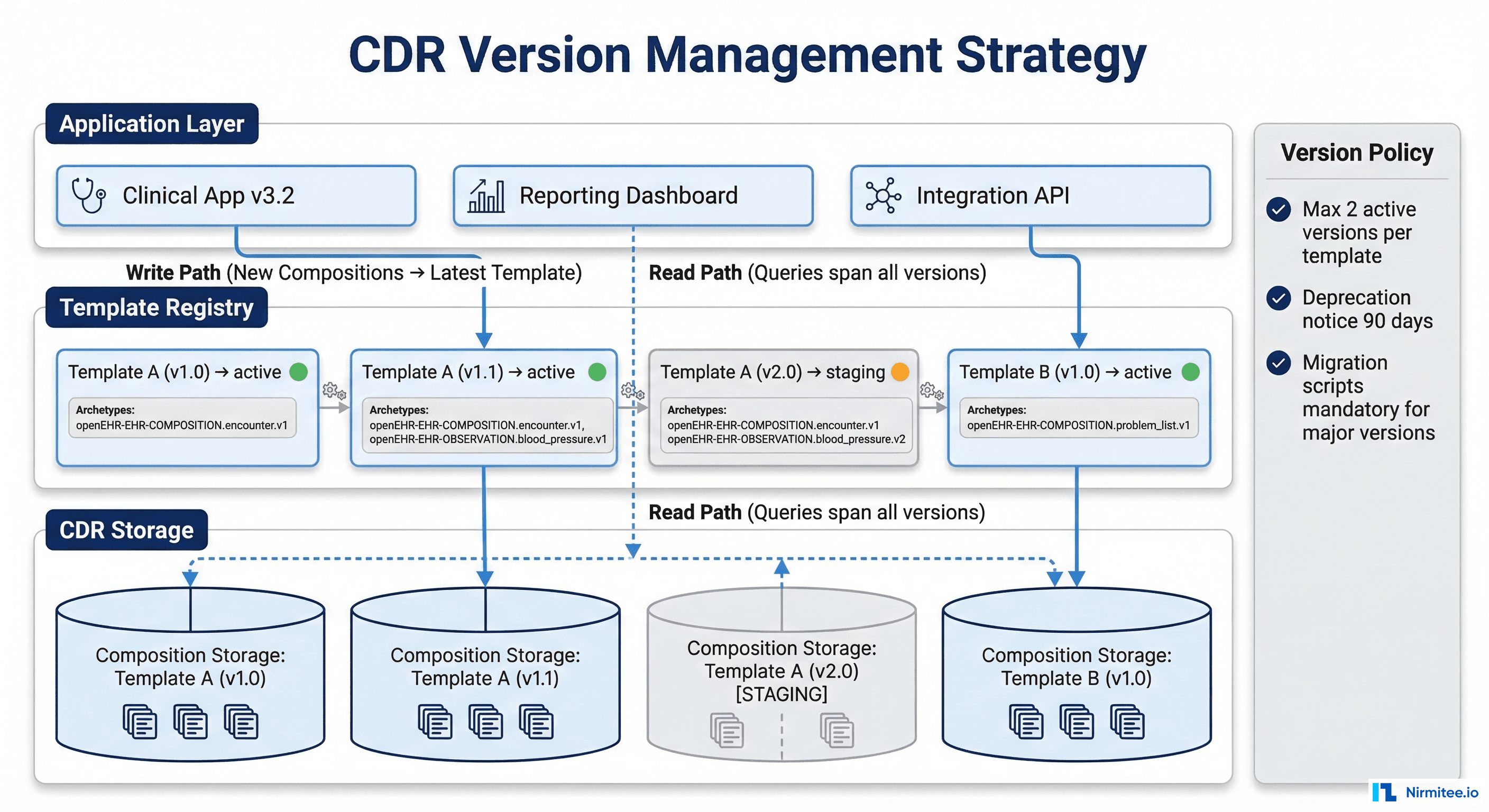
Template Registry Pattern
The most robust approach to managing archetype versions in production is a template registry — a controlled catalog of which template versions are active, staging, or deprecated.
-- Template version registry schema
CREATE TABLE template_registry (
id SERIAL PRIMARY KEY,
template_id VARCHAR(255) NOT NULL,
version VARCHAR(20) NOT NULL,
status VARCHAR(20) NOT NULL DEFAULT 'staging',
-- staging, active, deprecated, retired
uploaded_at TIMESTAMP DEFAULT NOW(),
activated_at TIMESTAMP,
deprecated_at TIMESTAMP,
deprecation_reason TEXT,
migration_script_path TEXT,
UNIQUE(template_id, version),
CHECK (status IN ('staging', 'active', 'deprecated', 'retired'))
);
-- Policy: max 2 active versions per template
-- Enforced by application logic, not constraintVersion Lifecycle Policy
Establish clear policies before you need them:
- Maximum active versions — Allow at most 2 active versions of any template at the same time. This limits the query complexity and maintenance burden.
- Deprecation notice period — When deprecating a template version, give consuming applications 90 days notice. Document the migration path.
- Mandatory migration scripts — Every major version bump must include a tested migration script. No exceptions. The script should be idempotent and resumable.
- Composition version tracking — Track which template version each composition was created with. This enables targeted queries and migration planning.
Cross-Version AQL Queries
One of the practical challenges with multiple archetype versions is writing AQL queries that work across versions. Here are two approaches:
-- Approach 1: Query each version separately and UNION
-- (Not standard AQL, but supported by some CDRs as extension)
SELECT e/ehr_id/value, bp/data/events/event/data/items[at0004]/value/magnitude as systolic
FROM EHR e CONTAINS COMPOSITION c
CONTAINS OBSERVATION bp[openEHR-EHR-OBSERVATION.blood_pressure.v1]
-- Plus query for v2
SELECT e/ehr_id/value, bp/data/events/event/data/items[at0004]/value/magnitude as systolic
FROM EHR e CONTAINS COMPOSITION c
CONTAINS OBSERVATION bp[openEHR-EHR-OBSERVATION.blood_pressure.v2]
-- Approach 2: Version-agnostic query (if paths are unchanged)
-- Some CDRs resolve the archetype regardless of version
SELECT e/ehr_id/value, bp/data/events/event/data/items[at0004]/value/magnitude as systolic
FROM EHR e CONTAINS COMPOSITION c
CONTAINS OBSERVATION bp[openEHR-EHR-OBSERVATION.blood_pressure]
-- Omitting version matches all versions (CDR-dependent)CI/CD for Clinical Models
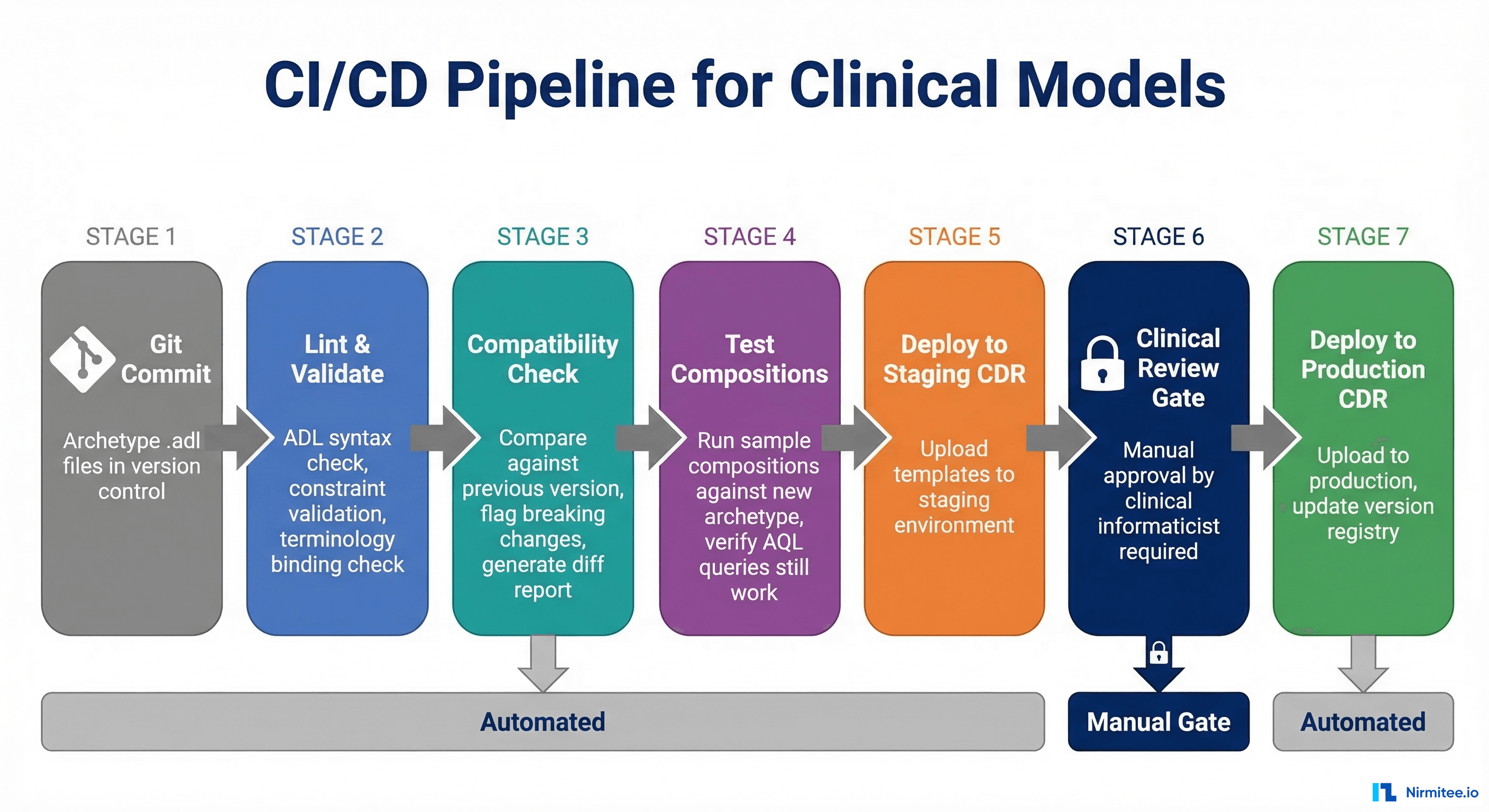
Version Control for Archetypes
Archetypes and templates should be stored in Git, just like application code. The repository structure:
clinical-models/
archetypes/
openEHR-EHR-OBSERVATION.blood_pressure.v1.adl
openEHR-EHR-OBSERVATION.blood_pressure.v2.adl
openEHR-EHR-EVALUATION.adverse_reaction_risk.v1.adl
templates/
encounter.v1.opt
encounter.v2.opt
discharge_summary.v1.opt
migrations/
blood_pressure_v1_to_v2.py
encounter_template_v1_to_v2.py
tests/
test_blood_pressure_compositions.json
test_encounter_compositions.json
.github/
workflows/
clinical-model-ci.ymlPipeline Stages
Stage 1: Lint and Validate — Check ADL syntax using the Archie library. Validate constraint consistency, terminology bindings, and ontology references.
# GitHub Actions: clinical model CI
name: Clinical Model CI
on:
push:
paths: ['archetypes/**', 'templates/**']
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Validate ADL files
run: |
java -jar archie-validator.jar \
--archetype-dir archetypes/ \
--report-format json \
--output validation-report.json
- name: Check for breaking changes
run: |
python3 scripts/breaking-change-detector.py \
--old-version main \
--new-version HEAD \
--archetype-dir archetypes/
- name: Run test compositions
run: |
python3 scripts/test-compositions.py \
--template-dir templates/ \
--test-data-dir tests/ \
--cdr-url $CDR_STAGING_URLStage 2: Compatibility Check — Compare the changed archetype against its previous version. Generate a diff report highlighting all structural changes and classifying them as breaking or non-breaking.
Stage 3: Test Compositions — POST sample compositions against the new template in a staging CDR. Verify that all existing AQL queries still return expected results.
Stage 4: Clinical Review Gate — This is a manual gate. No archetype change reaches production without explicit approval from a clinical informaticist. This is non-negotiable. Automated tests catch structural issues; clinical review catches semantic issues like "this field name is clinically misleading."
Stage 5: Deploy to Production CDR — Upload the new template to the production CDR. Update the template registry. If it is a major version, execute the migration script with monitoring.
Rollback Strategy
What happens when a deployed archetype change causes issues in production?
- Minor version rollback — Revert the template in the CDR to the previous minor version. New compositions go back to the old format. No data migration needed since the change was backward-compatible.
- Major version rollback — More complex. If compositions have already been created against the new version, they need to be migrated back. This is why migration scripts must be bidirectional (v1-to-v2 AND v2-to-v1).
- Emergency procedure — Disable the template entirely in the CDR (if supported), reverting to the previous active version. Alert all consuming applications. This is the clinical equivalent of a hotfix rollback.
Production Incident Patterns
The "Ghost Field" Problem
A common incident: a minor version adds an optional field, and application developers start using it in queries and UI. Six months later, someone realizes that historical data (pre-field) returns NULL, and clinical reports that filter on this field silently exclude all historical records. The report looks correct — it just has fewer patients than expected.
Prevention: For any new field added via minor version, implement a backfill strategy. Either migrate historical compositions to include a default value, or ensure all queries that use the new field handle NULL explicitly.
The "Terminology Drift" Problem
An archetype binds to SNOMED CT for diagnosis coding. Over time, SNOMED releases new versions. Codes used in older compositions may be deprecated or reclassified in newer SNOMED editions. The archetype has not changed, but the terminology underneath it has.
Prevention: Version-lock terminology bindings in archetypes. Reference specific SNOMED editions. Run terminology health checks that compare stored codes against the current edition and flag deprecated codes for review.
Frequently Asked Questions
Can I delete an archetype version from the CDR?
No. If any composition references that archetype version, deleting it makes the composition uninterpretable. Archetype versions should be deprecated and eventually retired, but never deleted. The CDR should retain all archetype versions indefinitely for data provenance.
How do I handle archetype changes from the international CKM?
When the international openEHR community releases a new version of an archetype you use, treat it like any other version upgrade. Review the changelog, classify the changes as breaking or non-breaking, test against your existing data, and plan migration if needed. Do not auto-update international archetypes in production.
Should every CDR environment use the same archetype versions?
Development and staging environments should run the latest versions for testing. Production should only run versions that have passed the full CI/CD pipeline including clinical review. Maintain a version manifest that documents exactly which versions are deployed in each environment.
What about archetype specializations?
Specialized archetypes (e.g., a pediatric blood pressure specializing the general blood pressure archetype) have their own version track, but they depend on the parent archetype version. A major version change in the parent may break the specialization. Test specialization compatibility in your CI pipeline.
Conclusion
Archetype versioning in production is governance engineering, not just technical configuration. The key takeaways:
- Classify every change using the semantic versioning decision framework before implementing it.
- Never deploy breaking changes without a migration script. The script must be tested, idempotent, and bidirectional.
- Implement a CI/CD pipeline with automated validation and a manual clinical review gate.
- Maintain a template registry that tracks version lifecycle across all environments.
- Plan for cross-version queries from day one. Your data will span multiple archetype versions within the first year of production use.
The organizations that handle archetype versioning well are the ones that treat clinical models as first-class engineering artifacts — version-controlled, tested, reviewed, and deployed with the same rigor as application code. If you need help establishing a clinical model governance process, our team can help.