We build AI agents for healthcare. We've shipped agents that summarize clinical notes, extract prior authorization data from faxes, and identify care gaps across patient panels. We believe in the technology.
Which is exactly why we need to tell you: most of the AI agent projects you're evaluating right now will fail.
Gartner predicts a 40% cancellation rate for agentic AI projects by 2027. McKinsey reports that 80% of AI projects never make it to production. And from what we see in the field, a significant portion of those failures share the same root cause: teams used an AI agent where a simpler, deterministic tool would have been faster, cheaper, and more reliable.
This isn't a failure of AI. It's a failure of tool selection.
If you're a healthcare CTO evaluating where to deploy AI agents, the highest-value skill you can develop is knowing when not to use one. Here are seven cases where a rules engine, a direct API call, or a simple cron job will outperform any LLM-based agent — and we'll show you where agents genuinely add value as a complement.
The 7 Cases Where Simpler Technology Wins
1. Deterministic Eligibility Checks
The workflow: A patient presents at registration. Your system sends an X12 270 eligibility inquiry to a payer and receives a 271 response. You need to parse the response, check coverage status, extract copay/deductible amounts, and display the result.
Why a rules engine wins: The X12 270/271 transaction set is a deterministic standard. Loop 2110C, segment EB, element EB01 — these are fixed positions with enumerated values. "1" means active coverage. "6" means inactive. There is no ambiguity. A rules engine parses this in under 10ms with 100% accuracy.
An LLM attempting the same task delivers roughly 95% accuracy (it occasionally misreads segment boundaries), takes 1.5-2 seconds per transaction, and costs $0.01-0.03 per call. At 50,000 eligibility checks per day, that's $500-$1,500/day in API costs for worse accuracy.
Where an agent complements: When a 271 response contains free-text remarks in the MSG segment — things like "coverage pending employer verification, contact plan administrator" — an agent can interpret the ambiguous language, draft a patient-friendly explanation, and suggest next steps for the front desk. The rules engine handles the structured data; the agent handles the unstructured edge cases.
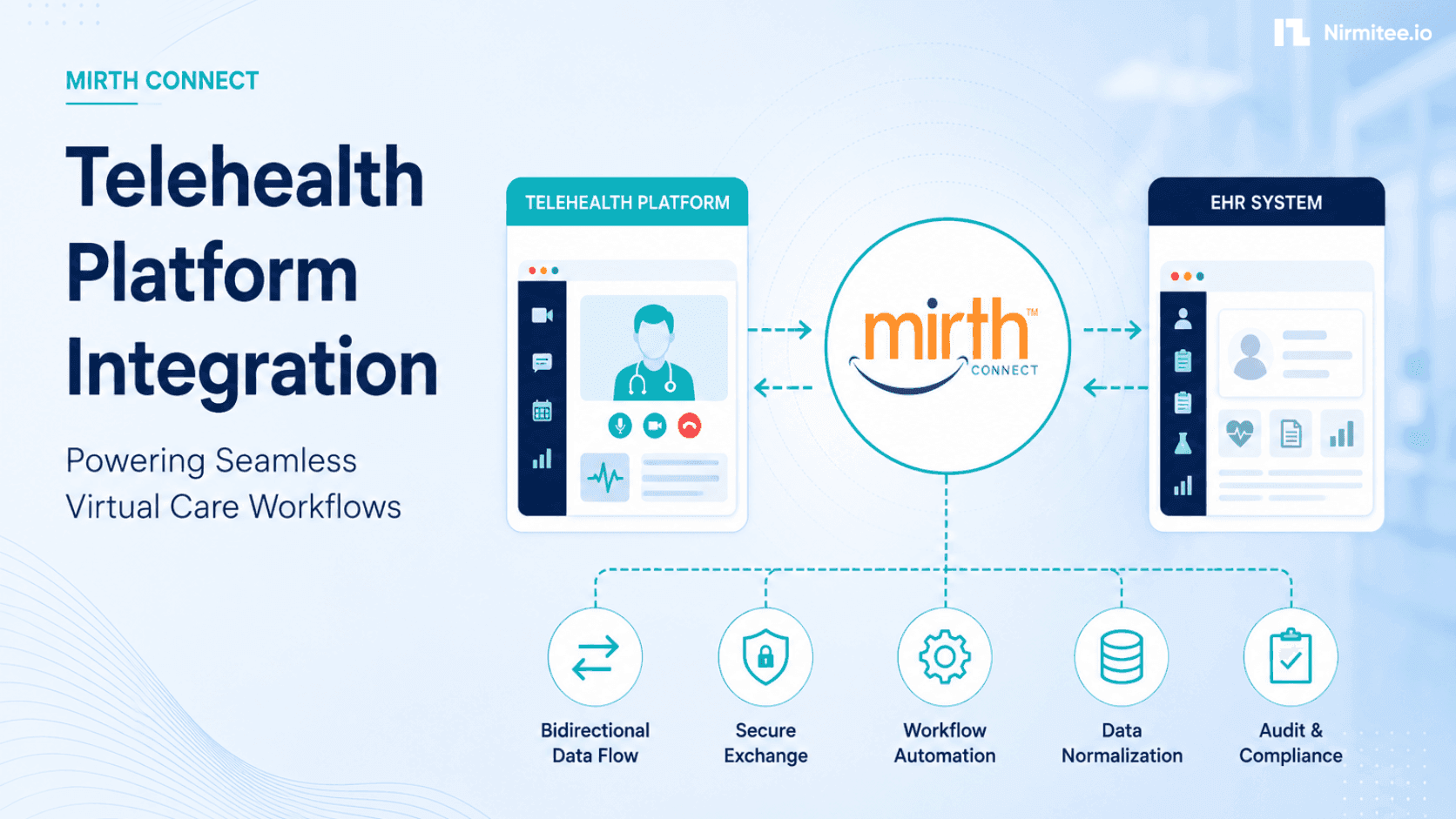
2. Simple Data Transformation (HL7v2 to FHIR)
The workflow: Your lab system sends HL7v2 ORU messages. Your FHIR-based clinical data repository needs DiagnosticReport resources. You need to transform the data.
Why an integration engine wins: HL7v2 to FHIR mapping is structural, not semantic. OBX-3 maps to Observation.code. OBX-5 maps to Observation.value. PID-3 maps to Patient.identifier. These are fixed, documented mappings defined in the HL7 FHIR v2-to-FHIR Implementation Guide.
Tools like Mirth Connect, Rhapsody, or Iguana handle this transformation at thousands of messages per second with deterministic, auditable output. Every transformation is reproducible. Every edge case is explicitly handled in the channel configuration.
An LLM might produce a plausible-looking FHIR resource, but it will occasionally hallucinate field values, invent extensions, or silently drop segments it doesn't recognize. In a clinical data pipeline processing millions of lab results per month, even a 0.1% error rate means thousands of corrupted records.
Where an agent complements: When you encounter non-standard HL7v2 messages from a new trading partner — messages with custom Z-segments, unusual encoding, or missing required fields — an agent can analyze the message structure, suggest mapping rules, and flag anomalies for a human integration engineer to review. It accelerates the configuration of the rules engine, not the runtime transformation.
3. Appointment Reminders
The workflow: For each appointment tomorrow, send the patient an SMS or email reminder 24 hours in advance. Include the provider name, time, location, and preparation instructions.
Why a cron job + API wins: This is a scheduled batch operation with zero ambiguity. Query the scheduling system for tomorrow's appointments. For each result, populate a message template. Call the Twilio/SendGrid API. Log the result. Done.
A cron job does this in minutes for thousands of appointments. Total infrastructure cost: a $20/month VM and per-message SMS fees. The logic fits in 50 lines of code. It's been running reliably at health systems since 2010.
Running this through an AI agent means you're paying for LLM inference on every message, adding 1-3 seconds of latency per reminder, introducing non-determinism (the agent might phrase the reminder differently each time, creating patient confusion), and creating an unnecessary failure mode.
Where an agent complements: When a patient replies to the reminder with a free-text message — "Can I reschedule to Thursday afternoon?" or "Do I need to fast before this?" — a conversational agent can interpret the intent, check scheduling availability, and handle the interaction. The cron job sends; the agent responds.
4. Reimbursement Rate Calculations
The workflow: Calculate the expected reimbursement for a procedure. Apply the CMS Physician Fee Schedule, adjust for geographic locality (GPCI), apply any sequestration reduction, and factor in the patient's contract-specific rates.
Why a formula engine wins: CMS publishes the Physician Fee Schedule as a downloadable dataset with exact formulas. The payment calculation is:
Payment = [(Work RVU × Work GPCI) + (PE RVU × PE GPCI) + (MP RVU × MP GPCI)] × Conversion Factor × (1 - Sequestration Rate)
This is arithmetic. A database lookup plus a formula produces the exact, auditable result in milliseconds. Every payer contract has similar deterministic rate tables.
An LLM asked to calculate reimbursement might hallucinate a conversion factor, apply last year's GPCI adjustments, or simply get the arithmetic wrong. For revenue cycle operations processing $50M+ in annual claims, even a 0.5% calculation error means $250,000 in lost or incorrect reimbursements.
Where an agent complements: When a denial comes back with an ambiguous remark code and you need to determine the appeal strategy — "Was this denied because of bundling, medical necessity, or a missing modifier?" — an agent can read the denial letter, cross-reference the clinical documentation, and suggest the highest-probability appeal path. Deterministic math for calculation; judgment for appeal strategy.
5. Real-Time Drug Interaction Checks (Under 100ms)
The workflow: A physician selects a medication in the CPOE. Before the order is signed, the system must check for interactions with the patient's current medications and display alerts for any clinically significant conflicts.
Why a direct API wins: Drug interaction checking at the point of prescribing is a real-time clinical safety function. The physician is actively making a decision. Response time must be under 100ms to avoid disrupting clinical workflow — anything slower, and clinicians start ignoring or overriding the alerts.
The NLM's RxNorm API returns interaction data in 10-25ms. FDB (First Databank) and Medi-Span provide interaction databases that can be queried locally in under 5ms. A rules engine with cached interaction tables responds in 2-10ms.
An LLM-based agent, even the fastest models, introduces 800ms-2,200ms of latency. That's 20-200x too slow for a real-time clinical safety check. And unlike a deterministic lookup, the LLM might miss a known interaction or hallucinate one that doesn't exist — both dangerous in a clinical context.
Where an agent complements: After the interaction alert fires, an agent can provide contextual clinical decision support — "This interaction is severe in patients with renal impairment. This patient's last eGFR was 35. Consider dose adjustment per the renal dosing protocol." The rules engine catches the interaction; the agent contextualizes it.
6. Controlled Substance Audit Trails (DEA Compliance)
The workflow: Every prescribing, dispensing, and administration event for a Schedule II-V controlled substance must be logged with an immutable audit trail. This trail must be deterministic, reproducible, and available for DEA inspection.
Why deterministic rules win: The DEA's Electronic Prescriptions for Controlled Substances (EPCS) regulation (21 CFR Part 1311) requires that audit records be tamper-evident and exactly reproducible. If an auditor re-runs the same inputs, they must get the same outputs.
LLMs are non-deterministic by design. Even with the temperature set to 0, the same prompt can produce different outputs across API calls due to model updates, batching, and floating-point non-determinism. This fundamentally violates the reproducibility requirement for controlled substance tracking.
A rules engine with cryptographic hashing produces identical outputs every time. The audit trail is mathematically verifiable. There is no probability involved — just deterministic state transitions logged with SHA-256 hashes.
Where an agent complements: An agent can analyze patterns across audit data — identifying potential diversion by flagging unusual prescribing patterns, detecting doctor-shopping across PDMP data, or surfacing statistical anomalies that a rules engine wouldn't catch. The rules engine maintains the trail; the agent performs surveillance.
7. High-Volume, Low-Complexity Claims Processing
The workflow: Process 10 million professional claims per month. Apply payer-specific business rules, validate coding combinations, check for duplicate claims, and route to adjudication.
Why a batch processor wins: The economics are devastating for LLM-based processing at this scale:
| Metric | Rules Engine | AI Agent (LLM) |
|---|---|---|
| Cost per claim | $0.00005 | $0.03 |
| Monthly cost (10M claims) | $500 | $300,000 |
| Processing time per claim | 10ms | 2,000ms |
| Monthly throughput time | 28 hours (parallelized) | 5,500+ hours (serial) |
| Accuracy | 100% (deterministic) | 95-98% (probabilistic) |
| Cost multiplier | 1x (baseline) | 600x |
That's a 600x cost difference for worse accuracy and slower processing. For a large payer processing 100M+ claims annually, the LLM approach would cost $3.6 million per year in API fees alone — for a task that existing rules engines handle for under $10,000/year.
Where an agent complements: When claims are denied and require human-like reasoning to resolve — reading clinical notes to extract medical necessity justification, interpreting ambiguous coding scenarios, or drafting appeal letters — an agent provides genuine value. The rules engine processes the 95% of claims that follow patterns; the agent handles the 5% that require judgment.
The Decision Framework
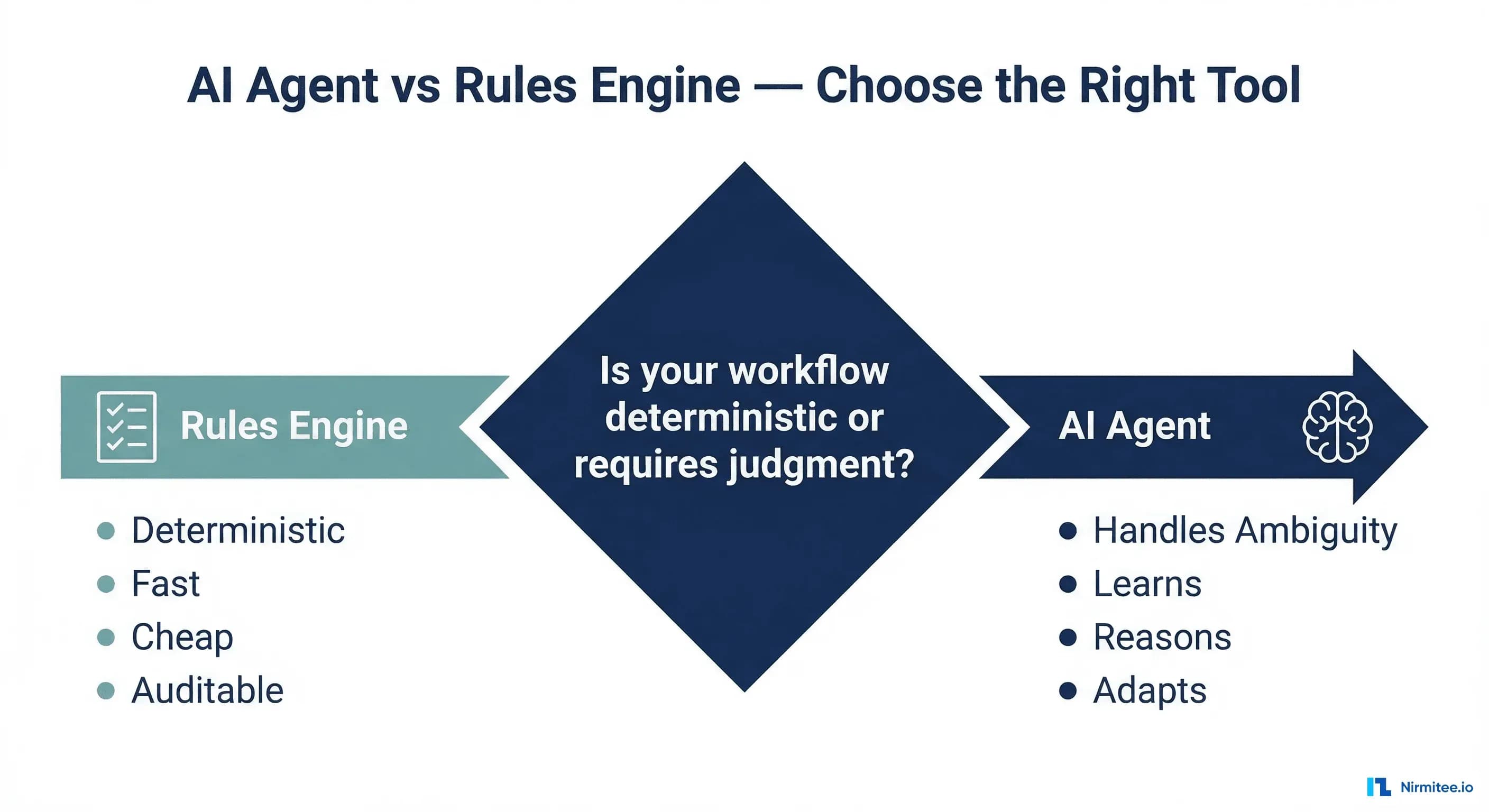
Before deploying an AI agent, run your workflow through these three questions:
Question 1: Is the workflow deterministic?
If the same input always produces the same output (eligibility parsing, fee calculations, data transformation), use a rules engine. Full stop.
Question 2: Does it require natural language understanding?
If the input is structured data (X12, HL7v2, CSV, database queries), you don't need an LLM. Use integration engines, ETL pipelines, or direct API calls. If the input involves free text, clinical notes, or ambiguous language, an agent may be appropriate.
Question 3: Does it need a real-time response (<100ms)?
If yes, even NLU tasks should use pre-computed results or cached models. LLM latency (500-5,000ms) is incompatible with real-time clinical workflows.
Rules Engine vs AI Agent: The Complete Comparison
| Dimension | Rules Engine | AI Agent | Winner For Healthcare |
|---|---|---|---|
| Accuracy | 100% deterministic | 90-98% probabilistic | Rules Engine (when applicable) |
| Latency | 1-50ms | 500-5,000ms | Rules Engine |
| Cost/Transaction | $0.0001 | $0.01-0.05 | Rules Engine (100-500x cheaper) |
| Auditability | Fully reproducible | Non-deterministic outputs | Rules Engine (regulatory compliance) |
| Handles Ambiguity | No — fails on edge cases | Yes — reasons through uncertainty | AI Agent |
| Scales to Volume | Excellent — linear cost | Expensive at scale — per-call pricing | Rules Engine |
| Regulatory Compliance | Built-in determinism | Requires guardrails, monitoring | Rules Engine |
| Learning / Adaptation | Manual rule updates | Continuous improvement possible | AI Agent |
The Hybrid Architecture: Where Both Win Together
The most effective healthcare architectures we see aren't choosing between rules engines and AI agents — they're using both, each where they excel:
- Claims processing: The rules engine adjudicates 95% of claims automatically. The agent handles the 5% that require clinical judgment for denial resolution.
- Clinical decision support: Rules engine fires drug interaction alerts in real-time. The agent provides contextual reasoning for complex clinical scenarios.
- Coding and documentation: Agent extracts information from unstructured clinical notes. The rules engine validates the extracted codes against CCI edits and LCD policies.
- Patient communication: Rules engine triggers reminders and standard notifications. The agent handles conversational follow-ups and complex patient questions.
- Prior authorization: Rules engine checks deterministic criteria (is this service in the PA-required list?). The agent compiles clinical evidence and drafts the authorization request narrative.
This hybrid model delivers the reliability of deterministic systems where you need it and the reasoning capability of AI where ambiguity demands it.
The Bottom Line
The healthcare organizations getting the most value from AI agents aren't the ones deploying agents everywhere. They're the ones deploying agents only where agents are the right tool — and using proven, cheaper, faster technology for everything else.
Before your next AI agent initiative, ask: "Could a rules engine do this?" If the answer is yes, you'll save months of development, hundreds of thousands in operating costs, and avoid the testing and safety challenges that come with non-deterministic systems in clinical environments.
From prior auth to clinical documentation, our Agentic AI for Healthcare practice builds agents that automate real healthcare workflows. We also offer specialized Healthcare Interoperability Solutions services. Talk to our team to get started.