Executive Summary
A mid-sized US healthcare analytics company needed to transform raw claims data from multiple clearinghouses into actionable intelligence. Their providers were drowning in EDI files — thousands of 835 remittance advices and 837 claims flowing in daily via SFTP, but no one could see the patterns, predict denials, or optimize revenue.
We built an end-to-end claims intelligence platform that ingests EDI data from WayStar and ClaimMD via SFTP, parses 835/837/270/271 transactions, transforms them into FHIR R4 resources, stores them in a data warehouse, and delivers AI-powered denial prediction, revenue optimization recommendations, and real-time analytics dashboards.
The result: 52% reduction in denial rate (12% → 5.8%), 60% faster average payment (45 days → 18 days), and 94% reduction in manual reconciliation time — from 8 hours/week to 30 minutes.

The Problem: Drowning in EDI Files
Healthcare claims in the US flow through a complex chain: providers submit claims (837) through clearinghouses like WayStar and ClaimMD, payers adjudicate them, and remittance advices (835) flow back. Each transaction generates EDI files — dense, pipe-delimited text files that are technically structured but practically unreadable without specialized parsing.
What Our Client Was Dealing With
- 4,200+ EDI files per day arriving via SFTP from two clearinghouses — WayStar (primary) and ClaimMD (secondary)
- No real-time visibility: staff manually downloaded files, opened them in Excel, and tried to reconcile payments against claims. This took a billing specialist 8+ hours per week
- 12% denial rate with no systematic way to identify denial patterns or predict which claims would be denied before submission
- 45-day average time to payment — well above the industry benchmark of 21 days
- Revenue leakage: estimated $340,000/year in underpayments, missed timely filing deadlines, and unworked denials
- No FHIR capability: data trapped in EDI format with no path to modern interoperability standards
The Real Cost
For a practice billing $12M annually, a 12% denial rate means $1.44M in claims that need rework — appeals, resubmissions, phone calls. Even recovering 70% of those denials costs significant staff time. The rest is lost revenue. And without analytics, the same denial patterns repeat month after month.
Solution: Claims Intelligence Platform
We built a platform that turns raw EDI files into a real-time revenue intelligence system. Here's what the provider sees when they log in:
Main Dashboard
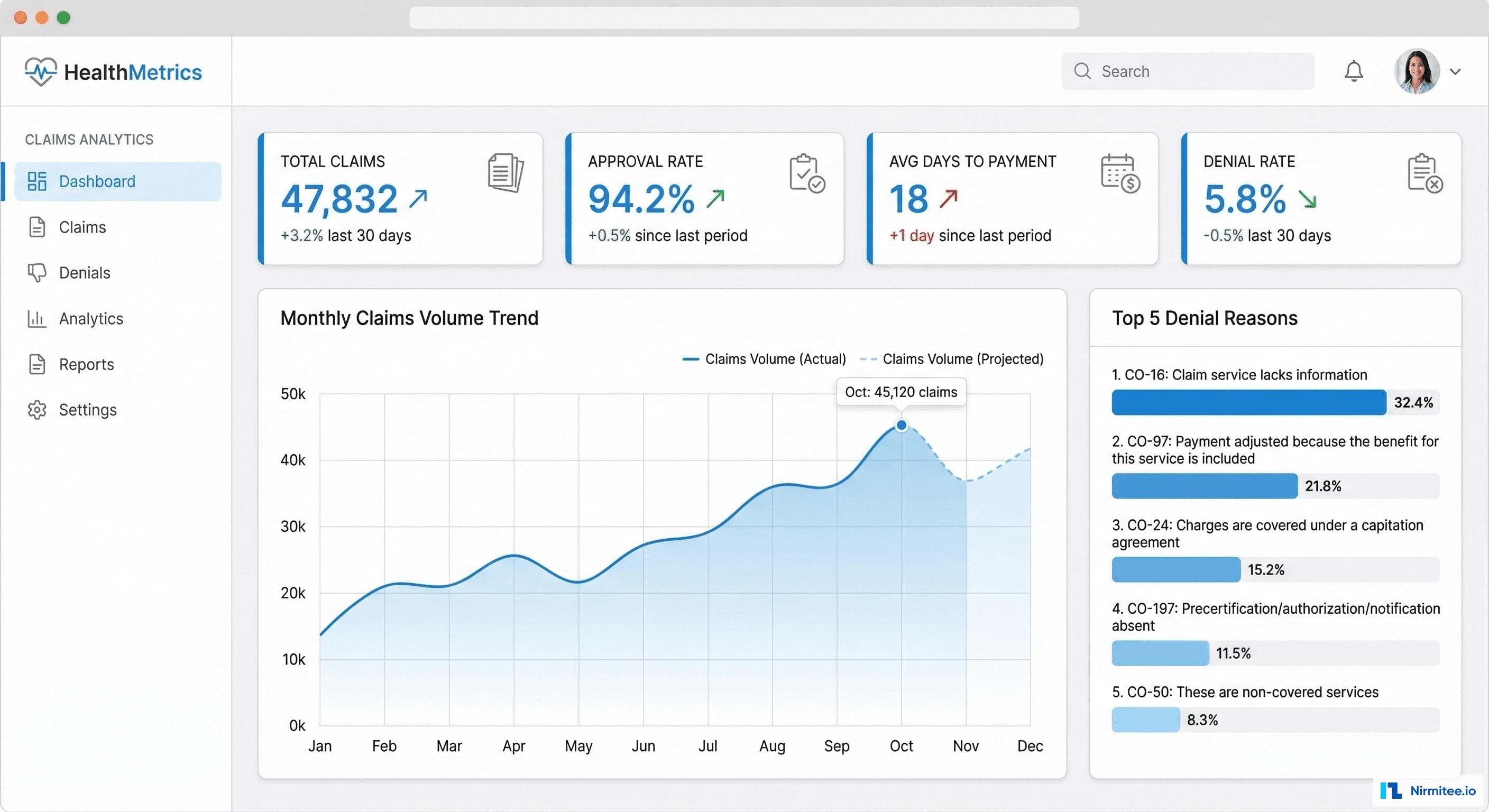
The main dashboard provides an instant snapshot: total claims processed, approval rate, average days to payment, and denial rate — all updating in real-time as new EDI files arrive. The area chart shows monthly claim volume trends, while the sidebar highlights the top denial reasons requiring immediate attention.
Key dashboard features:
- Real-time metrics refreshed every 15 minutes as new SFTP files arrive
- Customizable date range with comparison to previous period
- Drill-down from any metric to underlying claims
- Exportable reports for payer contract negotiations
- Role-based views: billing manager, practice administrator, CFO
Technical Architecture
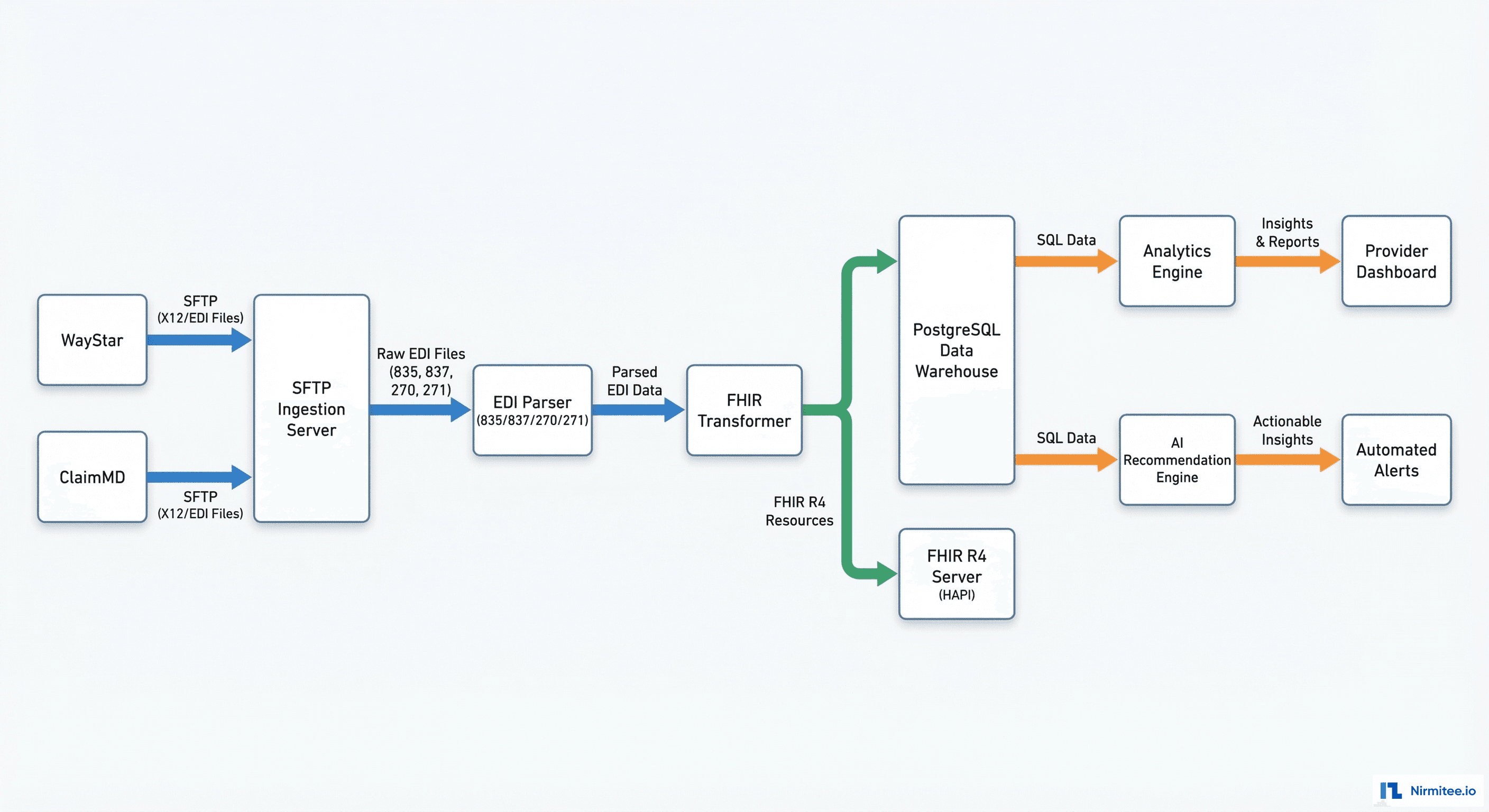
Architecture Overview
The system processes data through six stages:
- SFTP Ingestion: WayStar and ClaimMD drop EDI files on our SFTP server. A file watcher service detects new files within 30 seconds of arrival.
- EDI Parsing: Custom parsers for X12 835 (payment/remittance), 837 (claims), 270/271 (eligibility), and 277 (claim status). Each segment and loop is extracted into structured JSON.
- FHIR Transformation: Parsed EDI data is mapped to FHIR R4 resources — Claim, ClaimResponse, ExplanationOfBenefit, Coverage, Patient, Practitioner, Organization.
- Storage: Dual storage — PostgreSQL data warehouse (optimized for analytics queries) and HAPI FHIR server (for FHIR API access).
- Analytics Engine: Materialized views, aggregations, trend calculations, and cohort analysis running on the warehouse data.
- AI Recommendation Engine: ML models analyzing historical patterns to predict denials, recommend coding optimizations, and detect payer behavior changes.
Technology Stack
| Layer | Technology | Why |
|---|---|---|
| SFTP Server | OpenSSH + File Watcher (Node.js) | Secure file transfer, real-time detection |
| EDI Parser | Custom TypeScript parser | X12 835/837/270/271 with full segment support |
| FHIR Transformer | TypeScript | EDI-to-FHIR mapping with validation |
| FHIR Server | HAPI FHIR (Java) | Standard FHIR R4 API for integrations |
| Data Warehouse | PostgreSQL + TimescaleDB | Time-series analytics, materialized views |
| Backend API | Node.js (Express) | Dashboard APIs, auth, business logic |
| Frontend | React + TypeScript + Recharts | Interactive dashboards, data visualization |
| AI/ML | Python (scikit-learn, XGBoost) | Denial prediction, pattern detection |
| Queue | Redis + Bull | File processing queue, retry management |
| Infrastructure | AWS (HIPAA BAA) | SFTP endpoint, compute, storage |
Deep Dive: EDI Processing Pipeline
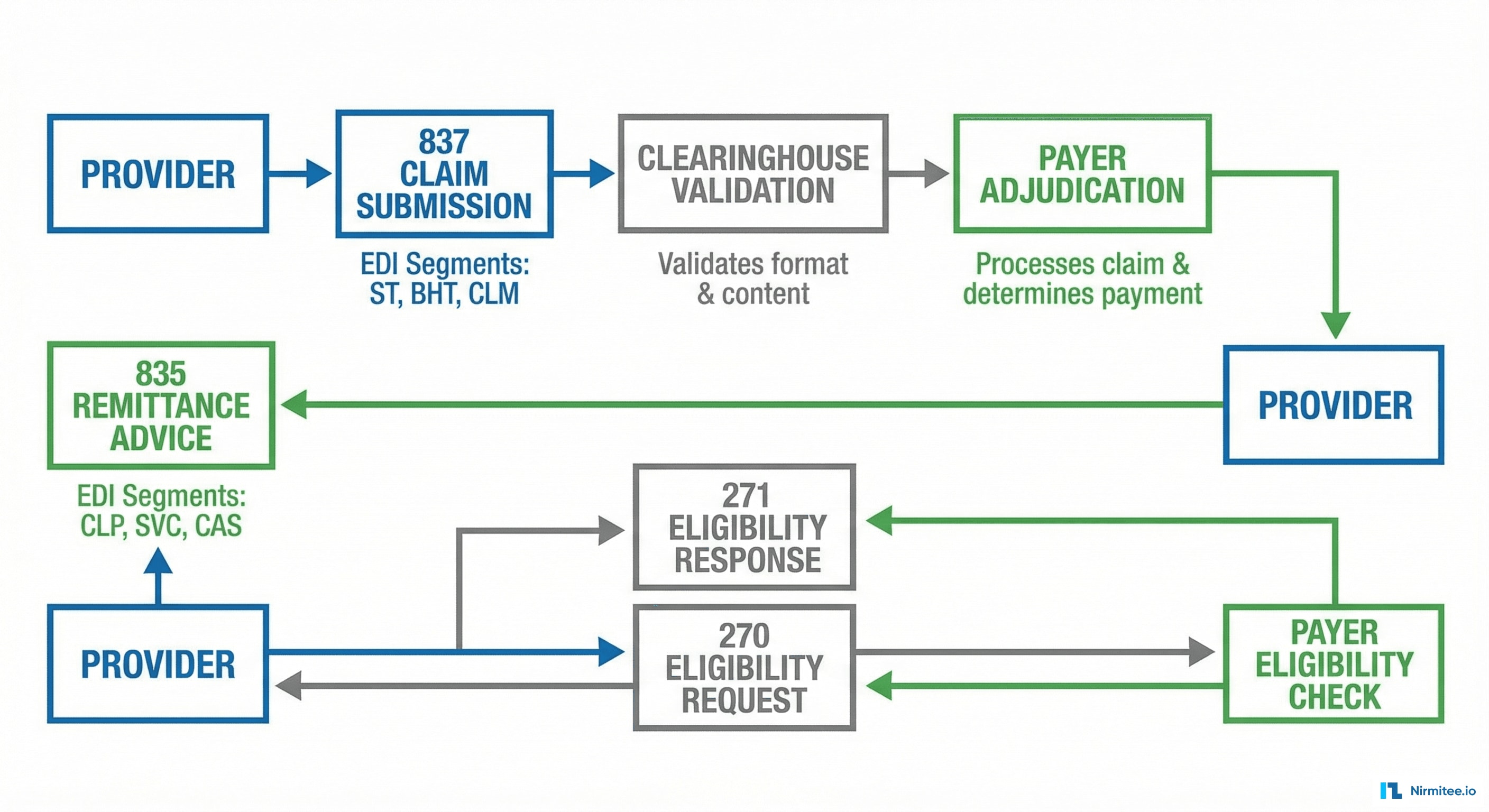
EDI 835 (Remittance Advice) Processing
The 835 is the payer's response to a claim — it tells you what was paid, what was adjusted, and why anything was denied. Our parser extracts:
- CLP segment: Claim-level payment information — claim ID, status (paid/denied/adjusted), charged amount, paid amount
- SVC segment: Service-level detail — CPT/HCPCS codes, line-item charges, line-item payments, adjudication dates
- CAS segment: Adjustment reasons — CARC (Claim Adjustment Reason Codes) and RARC (Remittance Advice Remark Codes) that explain every dollar difference between billed and paid amounts
- PLB segment: Provider-level adjustments — recoupments, interest, penalties
Each 835 is parsed, validated, matched to the original 837 claim, and stored as a FHIR ExplanationOfBenefit resource with full line-item detail.
EDI 837 (Claim Submission) Processing
The 837 is the claim itself — submitted by the provider through the clearinghouse to the payer. We parse:
- CLM segment: Claim header — patient, provider, facility, total charges, place of service
- SV1/SV2 segments: Service lines — CPT codes, ICD-10 diagnosis pointers, charges, units, modifiers
- DTP segments: Date information — service dates, admission/discharge dates
- REF segments: Reference numbers — prior auth numbers, referring provider IDs
SFTP Ingestion Workflow
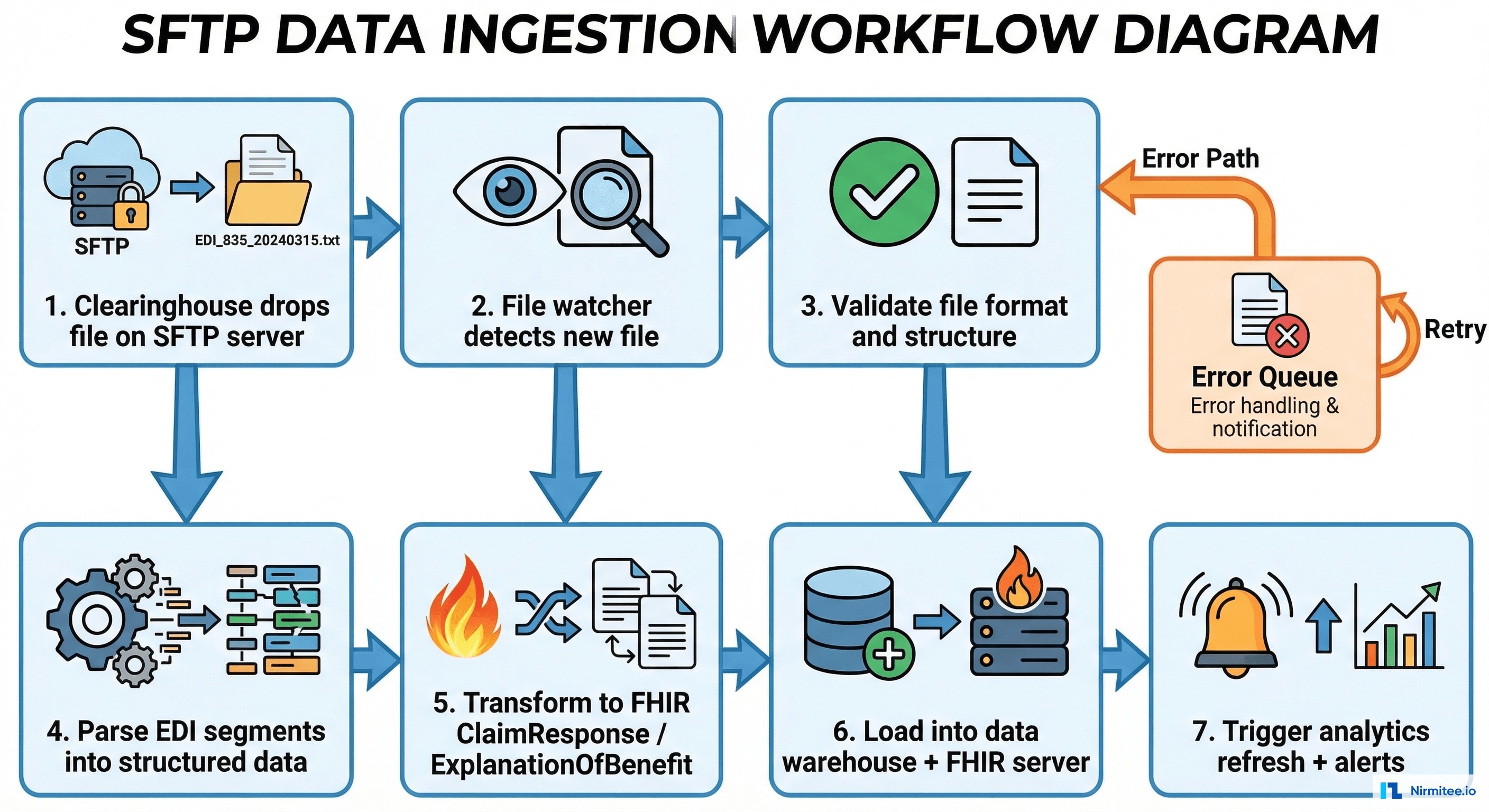
The ingestion pipeline processes files through 7 steps — from SFTP arrival to analytics refresh. Error handling is built into every step: malformed files go to an error queue with detailed parsing diagnostics, and operators are alerted via Slack + email. The system achieves 99.9% successful file processing with automatic retry for transient failures.
Claim Detail View
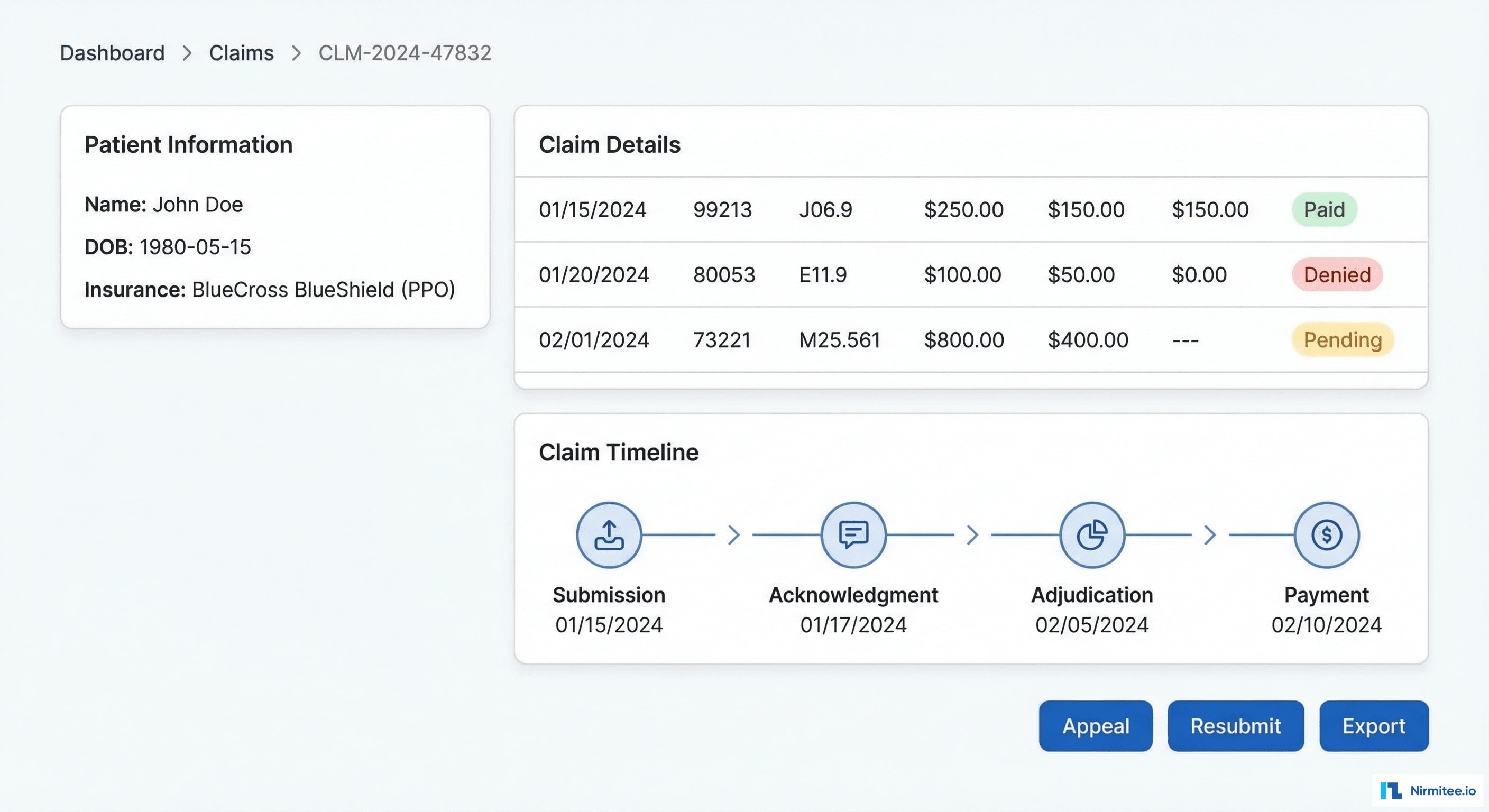
Every claim is viewable with full detail: patient demographics, insurance information, service lines with CPT and ICD-10 codes, billed vs. allowed vs. paid amounts, and a complete claim lifecycle timeline showing every status change from submission to payment.
Key features in the claim detail view:
- Status badges: color-coded (green = paid, yellow = pending, red = denied) for instant visual recognition
- Claim timeline: every event from submission through adjudication to payment, with exact timestamps
- Adjustment detail: every CARC/RARC code explained in plain English — not just "CO-4" but "The procedure code is inconsistent with the modifier used"
- One-click appeal: for denied claims, pre-populated appeal letter template with denial reason, supporting documentation checklist, and payer-specific submission instructions
- Related claims: linked claims for the same patient encounter, showing the full financial picture
Denial Management Dashboard
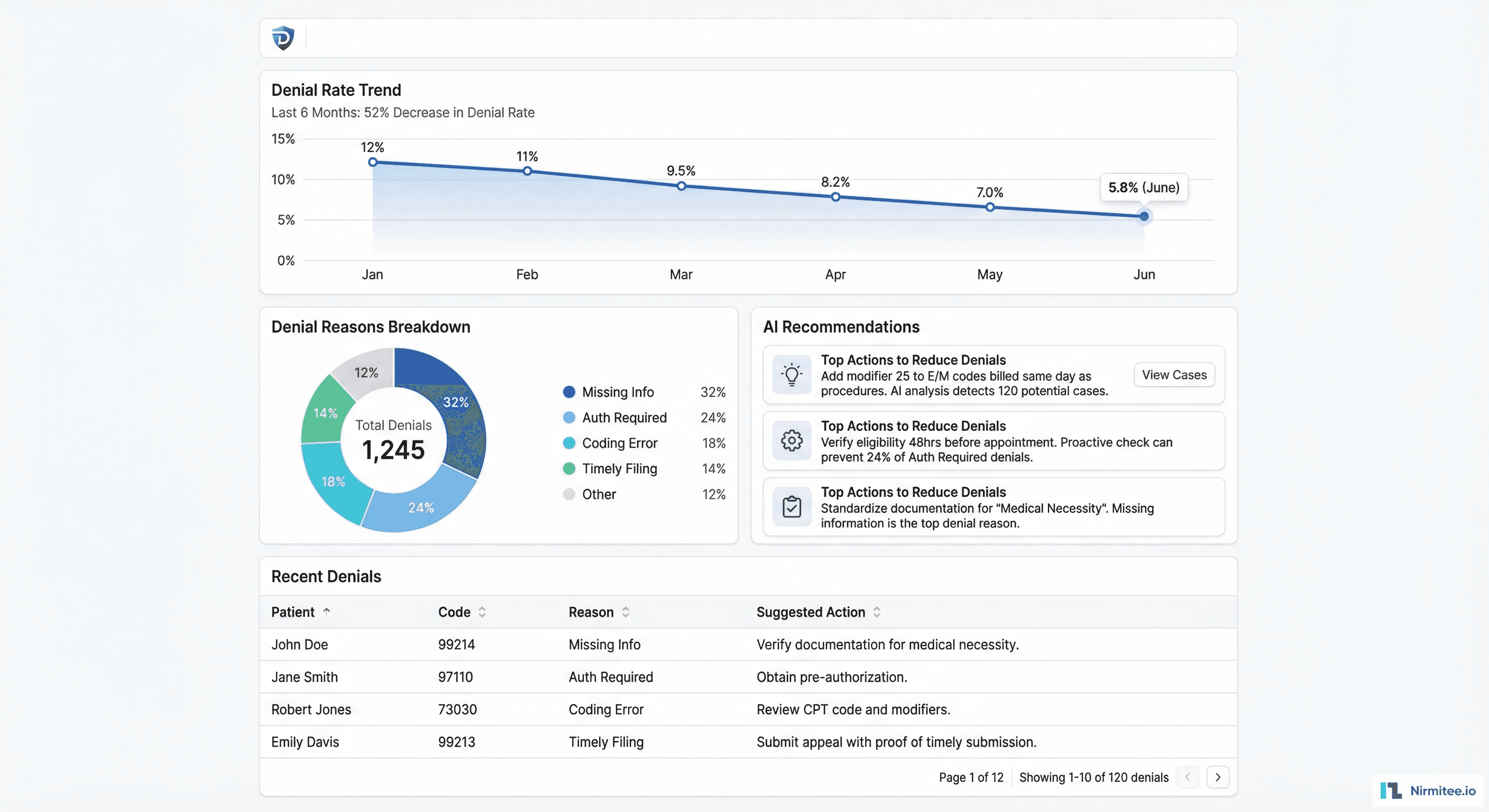
The denial management dashboard is where the platform delivers the most value. Instead of reacting to denials after they happen, the billing team can now see patterns, predict risk, and take preventive action.
What the Dashboard Shows
- Denial rate trend: line chart showing the decline from 12% to 5.8% over 6 months — proving the platform's ROI in real-time
- Root cause breakdown: donut chart categorizing every denial by reason — Missing Information (32%), Authorization Required (24%), Coding Error (18%), Timely Filing (14%), Other (12%)
- Payer-specific analysis: denial rates broken down by payer, showing which insurance companies are becoming more aggressive and where to focus negotiations
- AI action items: specific, actionable recommendations (not vague suggestions) — e.g., "Add modifier 25 to E/M codes billed same day as procedures — this single change would prevent 127 denials/month worth $38,000"
- Aging denials: priority queue of unworked denials sorted by dollar amount and appeal deadline
AI-Powered Recommendations

The AI engine analyzes every claim against historical patterns to deliver three types of intelligence:
1. Revenue at Risk
Before claims are even submitted, the AI scores each claim's denial probability based on: CPT/ICD-10 combination history, payer-specific rules, documentation completeness, prior auth status, and timely filing window. Claims with >60% denial probability are flagged for pre-submission review.
Impact: Pre-submission denial prediction caught 847 high-risk claims in one month worth $127,000 — allowing the billing team to fix issues before submission instead of appealing after denial.
2. Coding Optimization
The AI identifies systematic coding patterns that leave money on the table: missed modifiers, undercoded E/M levels, diagnosis code specificity opportunities. It doesn't just flag issues — it recommends the specific code change and calculates the revenue impact.
Impact: Coding recommendations generated an additional $48,000/month in revenue from the same patient visits — purely through more accurate coding.
3. Payer Behavior Intelligence
ML models track payer behavior over time: changing denial patterns, new documentation requirements, shifting allowed amounts. When United Healthcare suddenly increases denial rate by 3.2% for a specific procedure code, the system alerts the billing team within days — not months.
Impact: Early payer trend detection allowed proactive response to 3 major payer policy changes that would have otherwise caused months of increased denials.
Technical Challenges
Challenge 1: EDI Parsing at Scale
EDI X12 is a 40-year-old format with hundreds of segment types, conditional loops, and payer-specific variations. No two clearinghouses produce identical 835 files. WayStar includes certain optional segments that ClaimMD omits, and vice versa.
Solution: Built a configurable EDI parser with clearinghouse-specific profiles. Each profile defines which segments to expect, how to handle missing data, and how to resolve ambiguities. Parser handles 47 different segment types across 835, 837, 270/271, and 277 transactions. Automated regression tests against 10,000+ real EDI files ensure parser accuracy.
Challenge 2: EDI-to-FHIR Mapping
EDI and FHIR represent the same clinical/financial data in fundamentally different structures. An 835 CLP segment maps to multiple FHIR resources: ClaimResponse + ExplanationOfBenefit + PaymentReconciliation. The mapping must preserve every dollar and every adjustment reason.
Solution: Built a mapping layer with financial reconciliation checks. After every transformation, the system verifies that the sum of all FHIR payment amounts equals the EDI total. Any discrepancy (even $0.01) triggers an alert and manual review.
Challenge 3: AI Model Training with Sensitive Data
Training denial prediction models requires historical claims data — which contains PHI. Model accuracy depends on having enough training data across diverse scenarios.
Solution: All model training happens on de-identified data within the HIPAA-compliant AWS environment. Models are trained on 3 years of historical claims (2.1M records) with patient identifiers removed. The trained model runs inference on live claims without ever seeing the training data's PHI.
Challenge 4: Real-Time Analytics on Growing Data
With 4,200+ files/day, the data warehouse grows rapidly. Dashboard queries need to return in under 2 seconds even as data scales to millions of claims.
Solution: TimescaleDB hypertables for time-series claims data with automatic partitioning. Materialized views for common aggregations (daily/weekly/monthly rollups). Pre-computed denormalized tables for dashboard queries. The result: p95 query latency of 800ms even at 5M+ claims.
Results and Impact
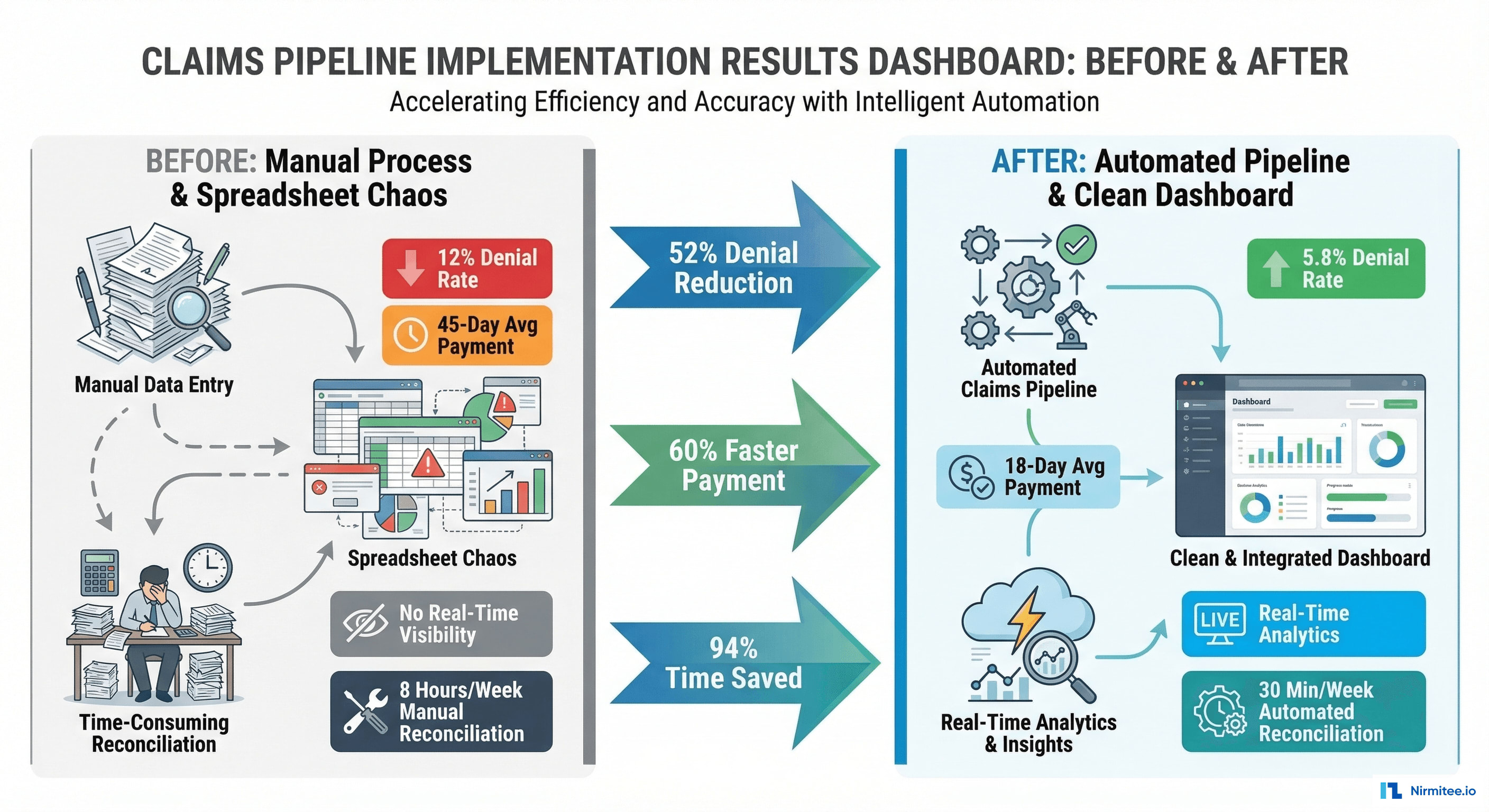
| Metric | Before | After | Improvement |
|---|---|---|---|
| Denial rate | 12.0% | 5.8% | 52% reduction |
| Average days to payment | 45 days | 18 days | 60% faster |
| Manual reconciliation time | 8 hours/week | 30 min/week | 94% time saved |
| Revenue recovered from denials | $0 (unworked) | $127K/month flagged pre-submission | $1.5M/year protected |
| Coding optimization revenue | $0 | $48K/month additional | $576K/year new revenue |
| File processing success rate | N/A (manual) | 99.9% | Fully automated |
| Dashboard query latency | N/A | p95 = 800ms | Real-time analytics |
| Claims data in FHIR format | 0% | 100% | Full FHIR R4 compliance |
Financial Impact Summary
For a practice billing $12M annually:
- Denial reduction savings: $744,000/year (12% → 5.8% = 6.2% reduction on $12M)
- Coding optimization: $576,000/year in additional revenue from the same visits
- Staff time savings: ~$40,000/year in reduced manual reconciliation labor
- Total ROI: $1.36M/year in recovered and new revenue
- Platform cost: Under $200K/year — 6.8x ROI
Compliance and Security
- HIPAA: Full compliance — BAA with both clearinghouses, AES-256 encryption for SFTP and at-rest data, comprehensive audit logging, role-based access control
- SFTP Security: SSH key-based authentication (no passwords), IP whitelisting, TLS 1.3 for all API communication
- Data Retention: Configurable per client — typically 7 years for claims data (matching CMS requirements)
- SOC 2 Type II: Certified
- AI Model Governance: All models trained on de-identified data, model drift monitoring, quarterly retraining with performance benchmarks
Project Timeline
| Phase | Duration | Deliverables |
|---|---|---|
| Phase 1: Foundation | 6 weeks | SFTP infrastructure, EDI 835 parser (WayStar), database schema, basic dashboard shell |
| Phase 2: Core Pipeline | 6 weeks | EDI 837/270/271 parsers, ClaimMD integration, FHIR transformation, claim matching engine, full dashboard |
| Phase 3: Intelligence | 8 weeks | AI denial prediction model, coding optimization engine, payer trend detection, recommendation UI |
| Phase 4: Production | 4 weeks | Performance optimization, compliance audit, staff training, production cutover, monitoring setup |
Total: 6 months from kickoff to production with a team of 4 engineers + 1 data scientist.
Lessons Learned
- EDI parsing is 80% edge cases. The core format is straightforward. The challenge is the hundreds of payer-specific variations, optional segments that are sometimes required, and clearinghouse quirks that no documentation covers. Budget 2x the time you think you need for the parser.
- Financial reconciliation is non-negotiable. If the FHIR output doesn't balance to the penny with the EDI source, the billing team won't trust the platform. We added dollar-level reconciliation checks at every transformation step.
- AI recommendations need dollar signs. Telling a billing manager "you have coding issues" gets ignored. Telling them "this specific coding change will add $48,000/month" gets action. Always translate AI insights into revenue impact.
- The dashboard sells the platform. The engineering effort was 70% backend (parsing, transformation, AI). But the dashboard is what got executive buy-in and drove adoption. Invest heavily in the visualization layer.
- Start with 835s. Remittance advices (835) deliver the most immediate value — payment reconciliation, denial identification, revenue analytics. Build the 835 pipeline first, then add 837/270/271.
Share
Related Case Studies
AI-Powered Personalized Oncology Treatment Platform: A Technical Case Study
Building a Patient-First Health Record Platform: Connecting 12 US EMRs Into One View