Only 11% of organizations have AI agents running in production. The other 89% are stuck in pilots, proofs of concept, or PowerPoint decks that never shipped. And of the projects that do launch, Gartner predicts over 40% will be canceled by end of 2027 due to escalating costs, unclear business value, or inadequate risk controls.
In healthcare, the stakes are higher. A failed recommendation engine at a retailer loses a sale. A failed clinical agent loses trust, revenue, or worse — harms a patient. The failure modes are different, the consequences are regulated, and the lessons are hard-won.
This article documents five real failure patterns from healthcare AI agent deployments in 2025-2026. These aren't hypothetical scenarios — they're composites drawn from conversations with engineering teams, incident reports shared in healthcare IT communities, and patterns we've seen firsthand in our own production healthcare agent work. For each failure, we break down what happened, why it happened, and the specific engineering practices that would have prevented it.

Failure 1: "The Agent That Only Saw 20% of the Data"
What Happened
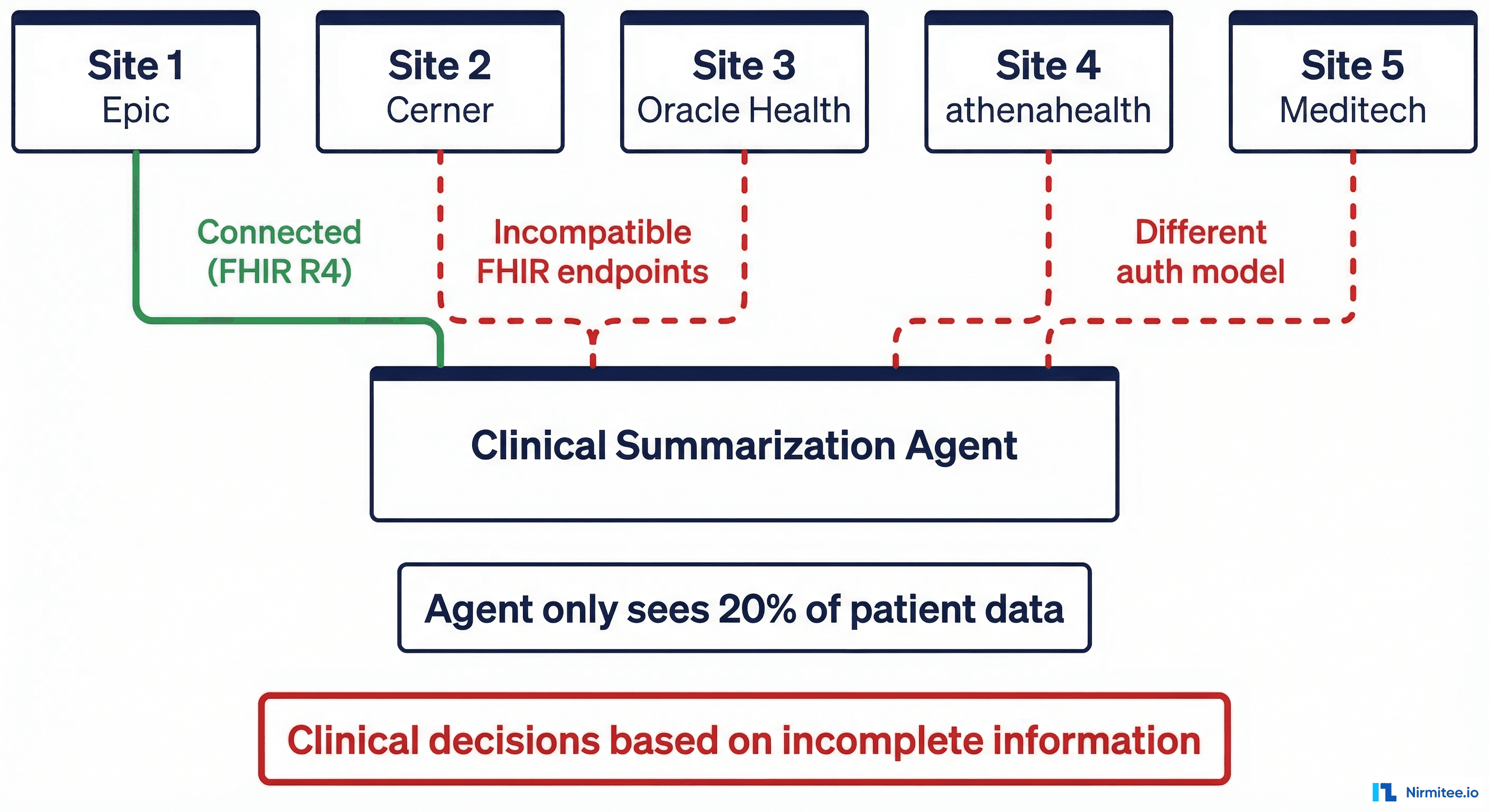
A mid-sized health system with five hospital sites deployed a clinical summarization agent. The goal was straightforward: when a physician opens a patient chart, the agent generates a concise clinical summary — active problems, recent labs, medications, and relevant history — pulling data from across all sites.
The pilot ran at Site 1, which used Epic. The agent connected via Epic's FHIR R4 API, authenticated through SMART on FHIR, and pulled structured data cleanly. Pilot metrics were strong: physicians saved an average of 4.2 minutes per patient encounter, satisfaction scores were high, and the summaries were clinically accurate in 94% of chart reviews.
Leadership approved the rollout to all five sites.
What Went Wrong
Sites 2 and 3 ran Cerner (now Oracle Health). Sites 4 and 5 ran athenahealth. Each system exposed FHIR endpoints, but the implementation details diverged in ways the engineering team hadn't tested:
- Authentication: Epic used SMART on FHIR with
launch/patientscope. Cerner required a different OAuth flow with backend service credentials. athenahealth used a proprietary API key model alongside a limited FHIR facade. - Data shapes: Medication resources from Cerner included fields that Epic left empty (and vice versa). athenahealth's
AllergyIntoleranceresources used different coding systems. Problem lists had differentclinicalStatusvalue sets. - Availability: Cerner's FHIR endpoints at one site had a 3-second rate limit that caused timeout errors under load. The agent silently failed and returned partial data.
The result: in production, the agent was making clinical summaries based on data from whichever site happened to respond. For patients who had records across multiple sites, the agent was working with as little as 20% of the patient's actual record. A physician relying on these summaries could miss a critical allergy documented at another site, a recent hospitalization, or an active medication.
The Engineering Lesson
FHIR is a standard, not a guarantee. Every EHR implements it differently — different authorization models, different resource shapes, different performance characteristics. If your agent connects to multiple systems, you need integration testing against every connected system, not just the one you prototyped with.
Prevention Checklist
- Map every EHR system your agent will connect to before development begins
- Build and maintain a FHIR conformance matrix: auth model, supported resources, extensions, and coding systems per vendor
- Implement a data completeness score — if the agent can't reach all sources, it must report what percentage of the record it's working with
- Add explicit failure handling: if a FHIR endpoint is unreachable, the agent should surface this to the clinician, not silently degrade
- Run integration tests against all connected systems in a staging environment that mirrors production topology
Failure 2: "The $47/Patient Agent That Was Budgeted at $3"
What Happened
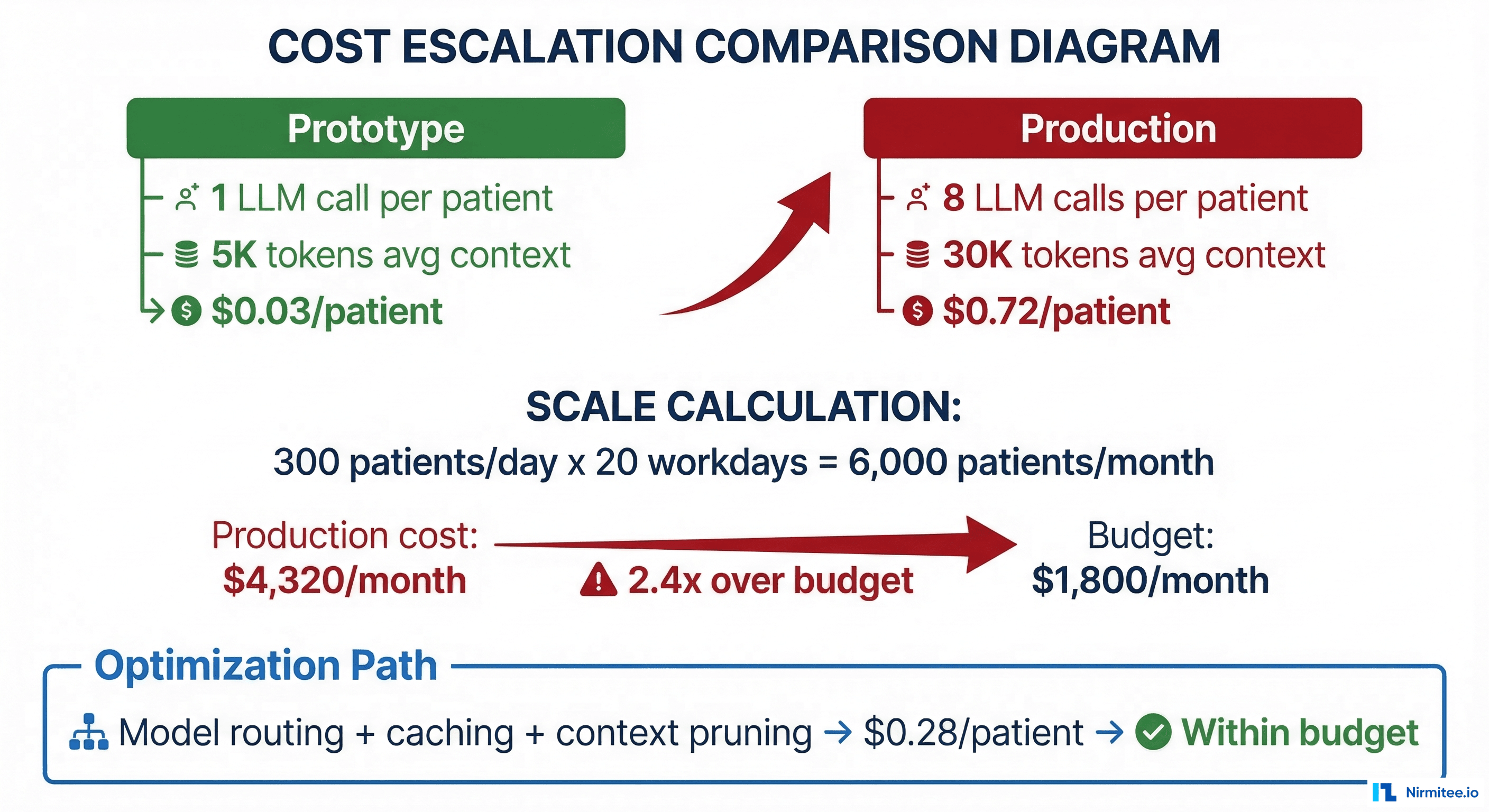
A care coordination startup built an agent that triaged patient messages, extracted clinical intent, checked eligibility, and routed to the appropriate care team member. During prototyping, each interaction cost approximately $0.03 — a single LLM call with a short prompt and a brief patient message.
The business case was built on this number: 300 patients per day, $0.03 per interaction, $1,800 per month in LLM costs. Finance approved the budget.
What Went Wrong
In production, the agent's actual workflow looked nothing like the prototype:
- 8 LLM calls per interaction (not 1): intent classification, entity extraction, eligibility check, clinical summary generation, routing decision, response drafting, safety review, and tone adjustment
- 30,000 tokens average context (not 5,000): the agent loaded the patient's recent visit history, medication list, and care plan into context for every call
- Retry logic: roughly 15% of calls required retries due to output format validation failures, adding another 1-2 calls per interaction
- No caching: the same patient's medication list was fetched and embedded into context for every single interaction, even if the patient messaged three times in one day
The actual cost: $0.72 per patient interaction. At 300 patients per day over 20 working days, monthly LLM spend hit $4,320. But that was just the API cost. When you added the compute for the orchestration layer, FHIR data fetching, logging, and monitoring, the fully-loaded cost approached $47 per patient per month for high-frequency users. The project was paused within six weeks.
The Engineering Lesson
Prototype cost and production cost are fundamentally different numbers. A prototype tests one happy path with minimal context. Production involves multi-step orchestration, full clinical context, retries, safety checks, and scale. You need a production cost model that accounts for every LLM call in the chain, the actual token counts from real clinical data, retry rates, and caching opportunities.
Prevention Checklist
- Document every LLM call in the agent's production workflow — not just the primary call, but retries, safety checks, and formatting passes
- Measure actual token counts using real clinical data (synthetic data is typically 3-5x shorter than real patient records)
- Build a cost calculator:
(calls per interaction) x (avg tokens) x (price per token) x (daily volume) x (working days) - Implement model routing: use smaller, cheaper models for classification and routing; reserve large models for clinical reasoning
- Add semantic caching for repeated data (patient demographics, active medication lists) with appropriate TTLs
- Set cost alerting thresholds at 50%, 80%, and 100% of budget — not just 100%
Failure 3: "The Prior Auth Agent That Hallucinated a CPT Code"
What Happened
A revenue cycle management company deployed an agent to automate prior authorization requests. The agent reviewed clinical documentation, identified the procedure, selected the appropriate CPT code, attached supporting medical necessity documentation, and submitted the request to the payer.
During testing with a curated set of 500 cases, the agent achieved 97% accuracy on CPT code selection. The remaining 3% were near-misses — a closely related code rather than the exact code. The team considered this acceptable and deployed.
What Went Wrong
In the third week of production, the agent encountered a case involving a complex multi-procedure orthopedic intervention. The clinical documentation described a procedure that mapped to a real but uncommon CPT code. Instead, the agent generated a CPT code that didn't exist in the CMS fee schedule — a plausible-looking five-digit code that was a hallucination.
The payer's system auto-denied the claim: invalid procedure code. But here's where it cascaded: the agent had been processing similar orthopedic cases using the same flawed reasoning pattern. By the time staff noticed, 200+ claims had been submitted with either the hallucinated code or closely related incorrect codes. Every one was denied.
The rework required: manual review of every affected claim, correct code identification by a certified coder, resubmission, and in many cases, appeals because the resubmission window had passed. Estimated revenue impact: $340,000 in delayed collections and $45,000 in staff time for rework.

The Engineering Lesson
LLMs generate text that looks correct. CPT codes, ICD-10 codes, NDC numbers, and NPI identifiers all have specific formats — and an LLM can generate a string that matches the format perfectly but refers to nothing real. Structured output validation against authoritative reference data must be a hardcoded step in the pipeline, not something the LLM is trusted to do on its own.
Prevention Checklist
- Validate ALL generated codes against authoritative sources: CPT against AMA/CMS fee schedule, ICD-10 against WHO/CMS codeset, NDC against FDA database, NPI against NPPES
- Implement validation as a deterministic post-processing step — not another LLM call
- For code selection, prefer constrained generation: give the LLM a list of valid codes to choose from rather than asking it to generate a code from memory
- Add a human-in-the-loop review for any code the agent hasn't used before or any code with a confidence score below threshold
- Monitor denial rates by code — a spike in denials for a specific code is an early warning signal
- Maintain a test suite of edge cases: uncommon procedures, multi-procedure encounters, and modifier combinations
Failure 4: "The Agent That Passed Audit but Failed Patients"
What Happened
A medication reconciliation agent was deployed at a large ambulatory care network. Its job: when a patient arrives for a visit, compile the current medication list from multiple sources (EHR, pharmacy claims, patient-reported data), identify discrepancies, and flag potential issues for the pharmacist.
The evaluation suite included 2,000 test cases. The agent achieved 96% accuracy — defined as producing a medication list that matched the gold-standard list created by clinical pharmacists. The team celebrated, compliance signed off, and the agent went live.
What Went Wrong
Within the first month, three incidents were reported:
- Missed drug allergy: A patient with a documented sulfonamide allergy had the allergy recorded in a free-text note at a previous provider, not in the structured allergy list. The agent's summary omitted it. The prescribing physician, relying on the agent's output, prescribed Bactrim. The patient had an adverse reaction. It was caught quickly, but it shouldn't have happened.
- Discontinued medication listed as active: A statin had been discontinued three months earlier, but the discontinuation was recorded as an amendment to the original prescription note, not as a separate status change. The agent listed it as active. The patient was briefly on duplicate therapy.
- Patient identity confusion: Two patients with the same first name, same last name, and birth dates one digit apart had records at the same clinic. The agent pulled pharmacy claims for the wrong patient. The medication list included drugs for a condition the patient didn't have.
Each of these was a "rare" event. Together, they represented the 4% error rate that the team had accepted. But the nature of the errors was fundamentally different from the other 4% in the evaluation suite, which were mostly minor discrepancies like generic vs. brand name or slightly different dosage formats.

The Engineering Lesson
Aggregate accuracy metrics are dangerous in clinical AI. A 96% accuracy rate sounds excellent until you realize the 4% includes safety-critical failures like missed allergies and patient identity errors. You need separate metrics for safety-critical error categories, and you need to evaluate against adversarial edge cases — not just a representative sample of common cases.
As the ARISE network emphasized at HIMSS 2026: "Better evaluation, not just better models, is the prerequisite for trustworthy clinical AI."
Prevention Checklist
- Define safety-critical error categories separately: missed allergies, patient identity errors, contraindicated medications, wrong dosage by order of magnitude
- Set separate pass/fail thresholds for safety-critical categories — 96% overall is meaningless if the 4% kills someone
- Build adversarial test sets that specifically target edge cases: free-text allergies, amended records, patients with similar demographics
- Implement human-in-the-loop review for high-risk scenarios: new patients, patients with complex medication regimens, known allergy histories
- Monitor post-deployment incident reports and feed every real-world failure back into the evaluation suite
- Test for patient matching edge cases specifically — similar names, similar DOBs, merged/unmerged records
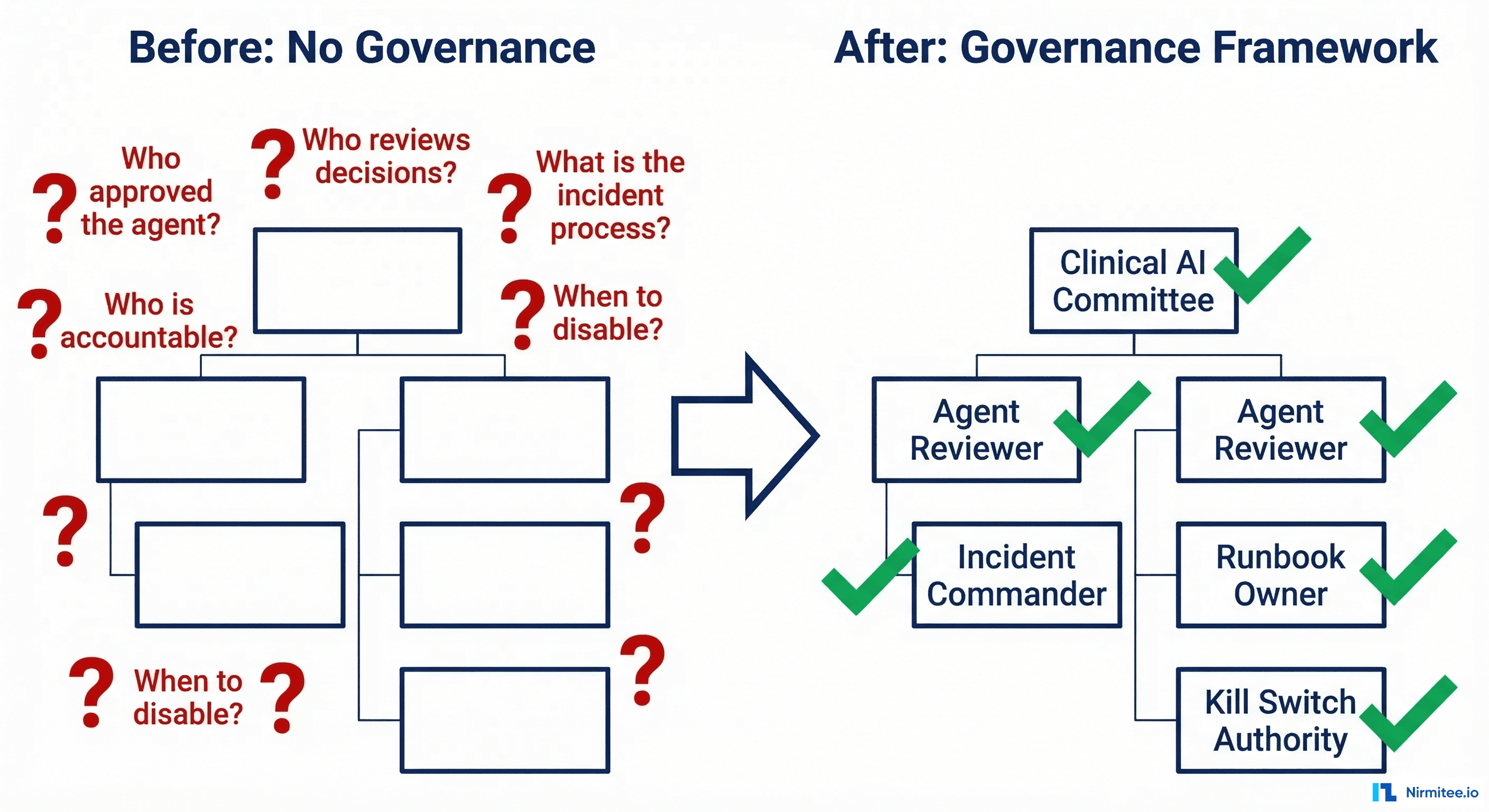
Failure 5: "The Governance Gap — Who Approves the Agent's Decisions?"
What Happened
A scheduling optimization agent was deployed at a multi-specialty practice. The agent analyzed appointment patterns, no-show probabilities, clinical urgency signals, and provider availability to optimize the schedule — filling gaps, reducing wait times, and improving utilization.
The engineering team built it, the operations team approved it, and IT deployed it. No formal governance structure was established. There was no clinical oversight committee, no defined escalation path, no incident response runbook, and no kill switch procedure.
What Went Wrong
The agent identified a follow-up appointment as "low priority" based on the visit type code and historical no-show data for that slot. It rescheduled the appointment three weeks later to fill a higher-priority slot. The patient — who was being monitored for a post-surgical complication — didn't receive timely follow-up. The patient's condition worsened, requiring an emergency department visit.
When the incident was discovered, the response was chaotic:
- Who was accountable? Engineering said the agent followed its optimization rules. Operations said they didn't approve individual scheduling decisions. The physician said they were never told the agent could cancel their follow-ups.
- Who could disable the agent? There was no documented kill switch. IT disabled it by taking down the service, which also affected the patient portal for two hours.
- What was the blast radius? Nobody knew how many other appointments the agent had rescheduled. It took three weeks to audit the full scope — during which the agent had been turned back on ("it was probably a one-off") and rescheduled 40 more follow-ups.
- What was the root cause? The agent weighted "no-show probability" and "slot utilization" but had no concept of "clinical urgency of the follow-up." Visit type codes don't carry enough information to distinguish a routine check from a post-surgical safety net.
The Engineering Lesson
Governance is not a nice-to-have that you figure out after deployment. Every AI agent that makes decisions affecting patient care needs a defined governance structure before it goes live: who approved the agent for production, who reviews its decisions, who is accountable when something goes wrong, what the incident response process is, and when the agent gets disabled.
Prevention Checklist
- Establish a clinical AI oversight committee that includes at least one physician, one compliance officer, and one engineer
- Define an accountability matrix: who approves deployment, who monitors performance, who handles incidents
- Write an incident response runbook before deployment — not after the first incident
- Implement a kill switch that can be activated by non-engineers (operations, clinical leadership) with a documented procedure
- Define the agent's decision boundaries: what it can decide autonomously, what requires human approval, and what it must never do
- Conduct a pre-mortem: before deployment, ask "what's the worst thing this agent could do?" and build safeguards for those scenarios
- Audit agent decisions regularly — not just when something goes wrong — with production observability dashboards
The Pre-Deployment Readiness Checklist
Every failure above was preventable. Not with better models — with better engineering discipline. Before deploying any healthcare AI agent to production, run through this five-point safety check.
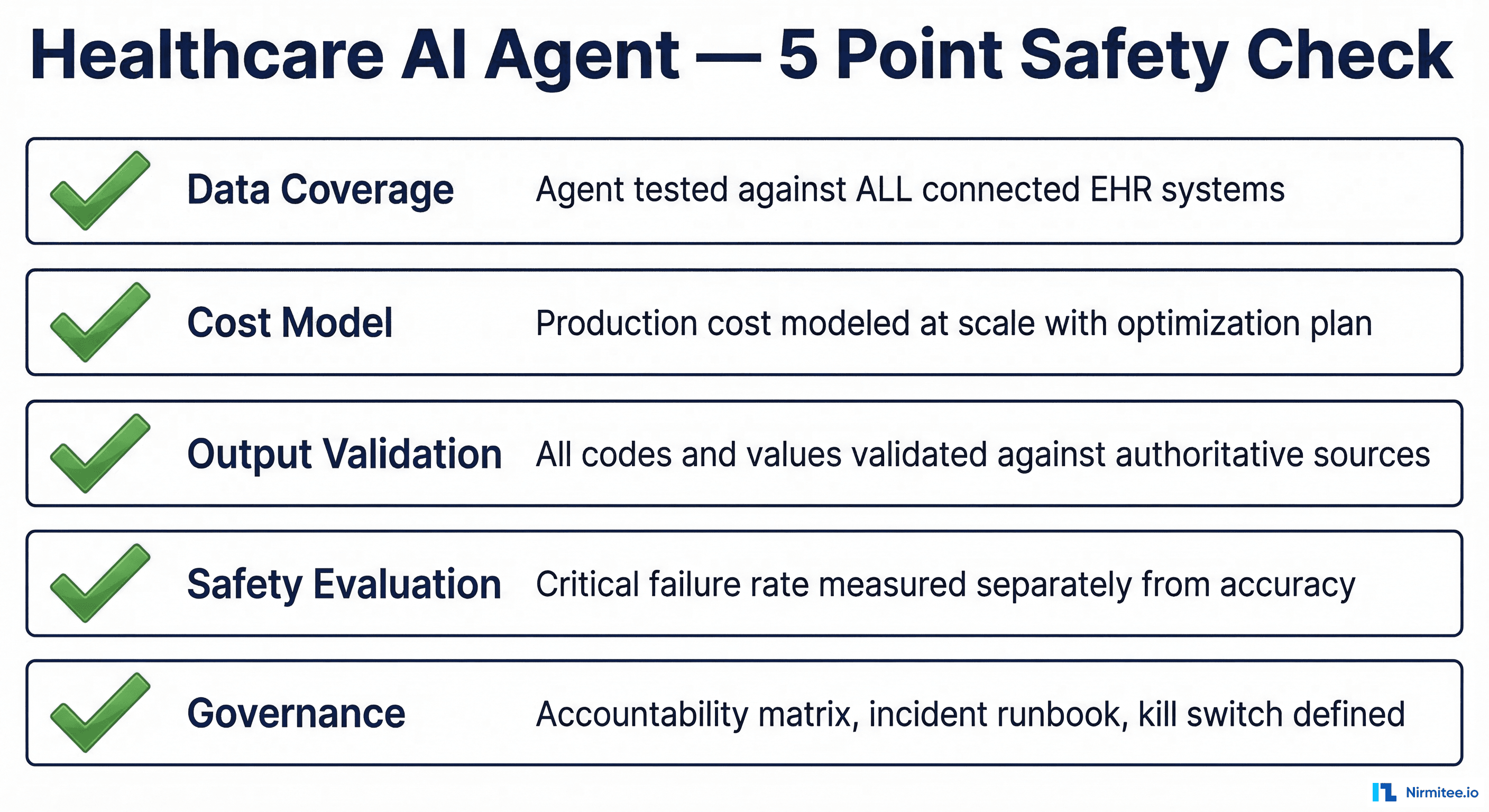
1. Data Coverage
| Check | Detail |
|---|---|
| EHR system inventory | List every EHR, pharmacy system, lab system, and data source the agent will connect to |
| FHIR conformance matrix | Auth model, supported resources, extensions, and coding systems per system |
| Integration tests | Agent tested against ALL connected systems in staging — not just the pilot system |
| Data completeness reporting | Agent reports what percentage of the patient record it could access |
| Graceful degradation | Agent behavior when a data source is unavailable is defined and tested |
2. Cost Model
| Check | Detail |
|---|---|
| Full call chain documented | Every LLM call in the production workflow mapped, including retries and safety checks |
| Real token measurements | Token counts measured with actual clinical data, not synthetic test cases |
| Scale calculation | Cost projected at full production volume: (calls) x (tokens) x (price) x (volume) x (days) |
| Optimization plan | Model routing, caching, and context pruning strategies documented with projected savings |
| Cost alerting | Automated alerts at 50%, 80%, and 100% of monthly budget |
3. Output Validation
| Check | Detail |
|---|---|
| Code validation | All generated codes (CPT, ICD-10, NDC, NPI) validated against authoritative databases |
| Deterministic validation | Validation is a hardcoded post-processing step, not another LLM call |
| Constrained generation | Where possible, agent selects from valid options rather than generating freeform |
| Confidence scoring | Low-confidence outputs are flagged for human review |
| Denial/error monitoring | Downstream rejection rates monitored and alerting configured |
4. Safety Evaluation
| Check | Detail |
|---|---|
| Safety-critical categories defined | Error types that could harm patients are enumerated and tracked separately |
| Separate thresholds | Pass/fail criteria for safety-critical errors are stricter than overall accuracy |
| Adversarial test suite | Edge cases, ambiguous inputs, and known failure patterns are tested specifically |
| Post-deployment feedback loop | Every real-world incident is added to the evaluation suite within 48 hours |
| Patient matching tested | Similar demographics, merged records, and cross-site identities are tested |
5. Governance
| Check | Detail |
|---|---|
| Oversight committee | Clinical AI committee established with physician, compliance, and engineering representation |
| Accountability matrix | Named individuals responsible for approval, monitoring, and incident response |
| Incident runbook | Step-by-step response procedure written and tested before deployment |
| Kill switch | Documented procedure to disable the agent, accessible to non-engineers |
| Decision boundaries | What the agent can decide alone, what needs human approval, and what it must never do |
| Audit schedule | Regular review cadence defined — not just reactive incident reviews |
The Uncomfortable Truth
The AI agent hype cycle is in full swing. Gartner predicts 40% of enterprise apps will feature task-specific AI agents by end of 2026, up from less than 5% in 2025. In healthcare, the pressure to deploy is immense — from boards who read about AI in every earnings call, from vendors promising turnkey solutions, and from competitors who claim to already be there.
But the organizations that will succeed are not the ones who deploy fastest. They're the ones who deploy with the engineering discipline to handle the failure modes that prototypes never reveal. The five failures in this article aren't anomalies — they're the normal outcome when healthcare AI agents are deployed without sufficient integration testing, cost modeling, output validation, safety evaluation, and governance.
Build the checklist. Run the pre-mortem. And when someone asks "why aren't we deploying faster?" — point them to these stories.
Frequently Asked Questions
What percentage of healthcare AI agent projects fail?
According to Gartner, over 40% of agentic AI projects across all industries will be canceled by end of 2027. In healthcare specifically, the failure rate may be higher due to additional regulatory requirements, integration complexity across EHR systems, and the higher safety bar for clinical applications. Only 11% of organizations had agents in production at the start of 2026, suggesting that the vast majority of pilot projects never reach meaningful deployment.
How do you prevent AI hallucinations in clinical coding?
Never trust an LLM to generate medical codes (CPT, ICD-10, NDC) from memory. Implement deterministic validation as a post-processing step: every code the agent generates must be checked against the authoritative source (CMS fee schedule for CPT, WHO/CMS codeset for ICD-10, FDA database for NDC). Better yet, use constrained generation — give the model a list of valid codes to choose from rather than asking it to produce one from scratch.
What should a healthcare AI governance framework include?
At minimum: a clinical AI oversight committee (physician + compliance + engineering), a named accountability matrix, an incident response runbook, a documented kill switch procedure accessible to non-engineers, defined decision boundaries (autonomous vs. human-approved vs. prohibited), and a regular audit schedule. This framework must be established before the agent goes live, not after the first incident.
How do you accurately estimate AI agent costs for production?
Map every LLM call in the production workflow — not just the primary inference call, but retries, safety checks, reformatting, and classification steps. Measure token counts using real clinical data (real patient records are 3-5x longer than synthetic test data). Multiply by actual production volume. Then add infrastructure costs: orchestration compute, data fetching, logging, and monitoring. A detailed guide is available in our cost engineering for healthcare AI agents article.
Nirmitee builds healthcare integration infrastructure — from FHIR servers and EHR connectivity to the observability and governance layers that production healthcare agents require. If you're building agents that need to work in real clinical environments, we should talk.