In February 2026, Microsoft and the Health Management Academy published a joint research report that should be on every healthcare CIO's desk. The finding that stopped the industry in its tracks: 61% of health system leaders surveyed are already building agentic AI capabilities — autonomous systems that can reason, plan, and take action across clinical and operational workflows without constant human prompting.
But here's the uncomfortable follow-up: fewer than 5% of those organizations have a structured framework for evaluating whether their infrastructure, data, governance, people, and priorities are actually ready for agents that make decisions on their own.
That gap — between enthusiasm and readiness — is where the real risk lives. Not in whether agentic AI works (it does), but in whether your health system can deploy it safely, scale it responsibly, and measure its impact rigorously.
This article breaks down a 5-dimension readiness assessment framework derived from the Microsoft/HMA research, adapted with practical scoring criteria you can apply to your own organization today. We'll walk through each dimension, provide a self-assessment scorecard, define four maturity levels, and give you a 90-day action plan to close the gaps.
Why Readiness Matters More Than Technology Selection
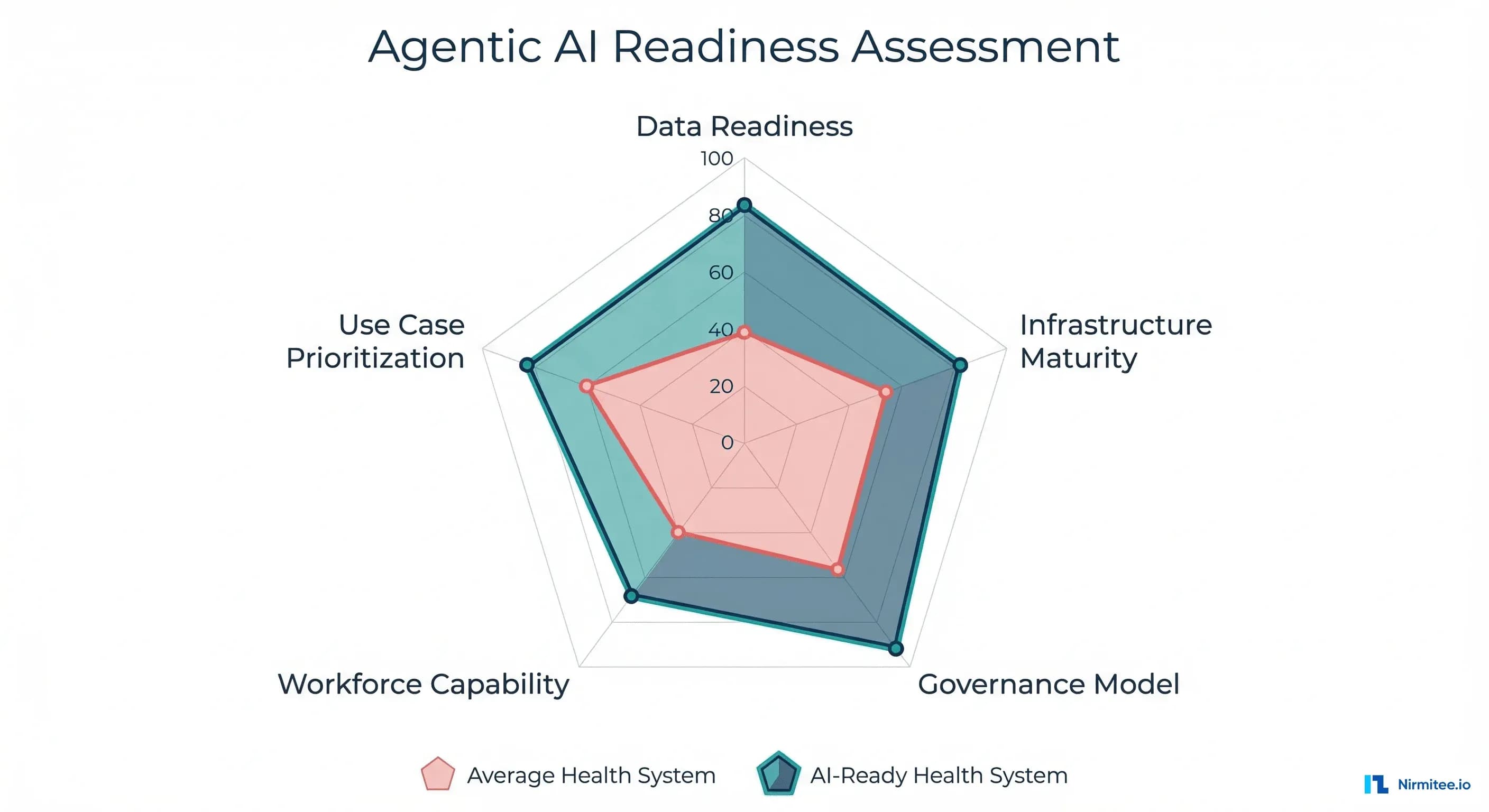
The agentic AI conversation in healthcare has largely focused on which technology to deploy: LangChain vs. CrewAI vs. AutoGen, GPT-4o vs. Claude vs. Gemini, fine-tuned models vs. RAG pipelines. But the Microsoft/HMA research reveals that technology selection accounts for less than 20% of deployment success. The other 80% comes from organizational readiness across five interconnected dimensions.
This mirrors what we've seen across agent framework evaluations — the framework matters far less than the data infrastructure, governance model, and clinical validation processes surrounding it.
Consider a concrete example. A 400-bed academic medical center deploys an agentic AI system for prior authorization. The agent can query payer portals, pull clinical documentation from the EHR, compile medical necessity arguments, and submit authorization requests autonomously. Technically, it works. But without structured data pipelines (Dimension 1), the agent pulls inconsistent medication lists from three different systems. Without a governance model (Dimension 3), nobody knows who's accountable when the agent submits an authorization with incorrect clinical data. Without workforce capability (Dimension 4), the IT team can't debug why the agent started hallucinating CPT codes at 2 AM.
Readiness isn't optional. It's the difference between a successful pilot and a HIPAA incident.
Dimension 1: Data Readiness
Is your clinical data structured, accessible, and clean enough for autonomous agents?
Data readiness is the foundation. Agentic AI systems don't just read data — they act on it. When an agent retrieves a patient's medication list to check for drug interactions before recommending a treatment adjustment, the consequences of incomplete or inconsistent data become clinical, not just analytical.
What Data Readiness Actually Requires
FHIR coverage and maturity. The minimum threshold is FHIR R4 APIs exposing USCDI v1 data classes. But for agents, you need more: real-time Observation resources, up-to-date MedicationRequest records, and Condition resources with proper SNOMED CT coding. According to ONC's 2025 interoperability report, only 38% of hospitals expose all USCDI v3 data classes via production FHIR APIs. The rest have gaps that will cause agent failures at runtime.
Data normalization and terminology services. Agents need consistent clinical terminology. If your EHR stores diagnoses as free-text problem list entries in one module and ICD-10 codes in another, an agent performing clinical summarization will produce inconsistent outputs. Implementing a terminology service (SNOMED CT, RxNorm, LOINC mapping) is non-negotiable for agent-scale operations. For deep technical guidance on building these pipelines, see our coverage of FHIR for AI/ML data pipelines.
Real-time data access. Batch ETL pipelines that refresh nightly won't work for agents making real-time clinical decisions. You need event-driven architectures — FHIR Subscriptions (R5), Change Data Capture from your data warehouse, or streaming pipelines that give agents access to data within seconds of creation, not hours.
RAG-indexed clinical data. For agents that need to reference clinical guidelines, institutional protocols, or prior patient records, you need vector-indexed document stores with proper chunking strategies. A RAG pipeline for clinical data is fundamentally different from general-purpose RAG — it requires section-aware chunking (separating HPI from Assessment from Plan), metadata preservation (encounter date, authoring clinician, document type), and citation tracking for auditability.
Data Readiness Maturity Levels
| Level | Description | Key Indicators |
|---|---|---|
| 1 — Siloed | Data trapped in individual systems | No FHIR APIs, manual data exports, inconsistent formats across departments |
| 2 — Connected | Basic interoperability in place | FHIR R4 APIs for some resources, but inconsistent data quality, no terminology normalization |
| 3 — Standardized | Enterprise data governance | USCDI v3 compliance, normalized terminology (SNOMED/LOINC/RxNorm), master data management |
| 4 — AI-Ready | Optimized for autonomous consumption | Real-time FHIR access, clean data pipelines, RAG-indexed clinical documents, data quality monitoring |
Dimension 2: Infrastructure Maturity
Can your infrastructure handle the computational, networking, and security demands of autonomous agents?
Agentic AI is infrastructure-intensive in ways that traditional analytics and even basic ML models are not. Agents make multiple LLM calls per task, maintain persistent state, orchestrate tool calls to external systems, and need to operate within strict latency requirements for clinical workflows.
Critical Infrastructure Components
GPU capacity and inference infrastructure. If you're running models on-premises (increasingly common for PHI-sensitive workloads), you need dedicated GPU clusters. A single clinical summarization agent processing 200 patient encounters per hour requires approximately 4x NVIDIA A100 GPUs for acceptable latency. Most health systems dramatically underestimate this requirement. Cloud-based inference (Azure OpenAI, AWS Bedrock, Google Vertex AI) shifts this to an OpEx model, but introduces data residency and BAA considerations that your procurement team needs to understand. The cost engineering reality is detailed in our analysis of healthcare AI agent production economics.
API gateway and rate management. Agents generate orders of magnitude more API calls than human users. A single prior authorization agent might make 15-20 FHIR API calls, 3-5 payer portal API calls, and 2-3 LLM inference calls per authorization request. At 500 authorizations per day, that's 10,000+ API calls — from one agent. Your API gateway needs to handle this volume with proper rate limiting, circuit breaking, and priority queuing so agent traffic doesn't degrade clinician-facing applications.
Identity and access management at agent scale. Every agent needs a service identity with precisely scoped permissions. This is not the same as a service account shared across applications. Each agent should have its own OAuth 2.0 client credentials grant, with FHIR SMART scopes that limit it to exactly the resources and operations it needs. A prior authorization agent needs Patient.read, Condition.read, MedicationRequest.read — but should never have Patient.write or MedicationAdministration.write. This level of granular RBAC for non-human actors is new territory for most health system IAM teams. See our technical deep-dive on connecting AI agents to the EHR via FHIR and SMART.
Observability and monitoring. You cannot run autonomous agents without comprehensive observability. Every agent action needs to be logged, traced, and auditable. This means distributed tracing (OpenTelemetry), structured logging of every LLM call (prompt, response, latency, token count), and real-time dashboards that surface anomalies before they become incidents. Our guide to healthcare AI agent observability covers the specific dashboard your compliance officer needs before go-live.
Dimension 3: Governance Model
Who approves agent deployment? Who's accountable when something goes wrong?
Governance is the dimension where most health systems are weakest — and where the consequences of gaps are most severe. The Microsoft/HMA survey found that only 12% of organizations building agentic AI have a formal governance framework that covers agent-specific risks like autonomous decision-making, model drift, and cascading failures across multi-agent systems.
Essential Governance Components
AI Governance Board. A cross-functional body that includes the CIO, CMIO, CISO, General Counsel, and at minimum one practicing clinician. This board approves agent deployment to production, sets acceptable risk thresholds, and makes decommissioning decisions. It should meet bi-weekly during active agent deployment phases and monthly during steady-state operations.
Clinical Validation Committee. Separate from the governance board, this committee focuses specifically on clinical accuracy and safety. It reviews agent outputs against gold-standard clinical judgments, defines accuracy thresholds per use case (e.g., drug interaction detection must be >99.5% sensitivity), and conducts periodic retrospective reviews of agent decisions. This is the healthcare-specific governance layer that generic AI governance frameworks miss entirely.
Incident response protocol. When (not if) an agent makes a clinically significant error, you need a documented response protocol: immediate containment (disable the agent), root cause analysis, impact assessment (which patients were affected), notification procedures (internal and potentially regulatory), and remediation timeline. This protocol should be tested via tabletop exercises quarterly, just like your cybersecurity incident response plan.
Model versioning and rollback policies. Every agent deployment must be versioned, with the ability to roll back to a previous version within minutes. This includes not just the model weights, but the prompt templates, tool configurations, guardrail rules, and FHIR scope definitions. The governance board should approve every version promotion to production. For multi-agent architectures, this complexity multiplies — see our analysis of multi-agent orchestration patterns.
Compliance documentation. Every agent needs a living compliance document that maps to HIPAA compliance surfaces specific to AI agents, including data access patterns, decision audit trails, and the new attack surfaces that autonomous agents create.
Dimension 4: Workforce Capability
Do you have the people who can build, deploy, and oversee autonomous healthcare AI?
The workforce dimension is the most constrained. The Microsoft/HMA research found that 78% of health systems cite talent as their primary barrier to agentic AI adoption — ahead of budget, technology, and regulatory concerns.
The challenge isn't just hiring ML engineers. It's finding (or developing) people who understand both the technical stack and the clinical context. An ML engineer who builds excellent RAG pipelines but doesn't understand why medication reconciliation matters clinically will build agents that are technically sophisticated and clinically dangerous.
The Four Roles You Need
Clinical Informaticist. The bridge between clinical workflows and AI capabilities. This person understands SNOMED CT hierarchies, FHIR resource relationships, clinical documentation patterns, and can translate clinician needs into technical requirements. They review agent outputs for clinical plausibility and design evaluation criteria that reflect real clinical value.
ML/AI Engineer with Healthcare Context. Beyond standard ML skills, this role requires an understanding of PHI handling, HIPAA technical safeguards, clinical NLP challenges (negation detection, temporal reasoning, abbreviation expansion), and the specific failure modes of LLMs in clinical contexts. They build the clinical safety guardrails that prevent agents from causing harm.
Integration Engineer. Healthcare agents don't operate in isolation — they connect to EHRs, payer systems, lab information systems, pharmacy networks, and imaging archives. This role requires deep knowledge of HL7v2, FHIR, DICOM, NCPDP SCRIPT, and the practical realities of healthcare system integration. Our six layers of production healthcare agents detail why this integration expertise is non-negotiable.
AI Operations (AIOps) Specialist. Responsible for monitoring agent performance in production, managing model drift, scaling infrastructure, and coordinating incident response. This is a new role that didn't exist two years ago, and most health systems haven't yet created it.
Building vs. Buying Talent
The realistic path for most health systems is a hybrid: upskill existing clinical informatics staff on AI/ML fundamentals (3-6 month investment), partner with specialized firms for initial deployments, and selectively recruit for the most critical gaps. Pure in-house build is unrealistic given market competition for AI talent; pure outsource is dangerous given the clinical context requirements.
Dimension 5: Use Case Prioritization
Which workflows should you automate first for maximum ROI with minimum risk?
Not every workflow benefits from agentic AI, and deploying agents in the wrong order creates organizational fatigue, governance overhead without returns, and (worst case) clinical risk without clinical benefit. The prioritization framework is deceptively simple: target workflows that are high volume, low clinical complexity, and high cost.
The Prioritization Matrix
Plot your candidate workflows on two axes: business impact (cost savings, revenue recovery, clinician time savings) and implementation complexity (data availability, clinical risk, regulatory requirements, integration difficulty).
Quadrant 1 — Start Here (High Impact, Low Complexity):
- Prior authorization: $31 average cost per manual PA, 34 PAs per physician per week (AMA 2025 survey). Agent-assisted PA can reduce processing time by 75% and denial rates by 15-20%.
- Eligibility verification: High volume, structured data, clear success/failure criteria. An agent can verify insurance eligibility in seconds rather than the 8-12 minutes staff spend per verification.
- Appointment reminders and scheduling optimization: Patient-facing, low clinical risk, measurable impact on no-show rates (typically 5-8% reduction).
- Clinical documentation coding assistance: Suggesting ICD-10 and CPT codes from clinical notes. Low direct clinical risk, significant revenue impact ($1.2M average annual recovery per 500-bed facility from improved coding accuracy).
Quadrant 2 — Phase 2 (High Impact, High Complexity):
- Clinical summarization: Enormous time savings potential (estimated 2.5 hours per physician per day), but requires high accuracy thresholds, clinician trust, and robust evaluation suites that account for the stakes involved.
- Care coordination: Complex multi-system integration, requires understanding of care plans, social determinants, and longitudinal patient context. High value but requires a mature data infrastructure (Dimension 1 at Level 3+).
- Discharge planning: Reduces readmissions (30-day readmission rate improvement of 8-12% in early studies), but requires integration with post-acute care networks and real-time bed management systems.
Quadrant 3 — Automate with Rules, Not Agents: Simple, low-variability tasks like appointment confirmation texts, lab result notification routing, and basic eligibility checks are better served by deterministic automation (rules engines, simple APIs) than by agents. Don't use a $0.15/call LLM for a task that a $0.001 API call handles perfectly.
Quadrant 4 — Deprioritize: High-complexity, low-impact workflows like rare disease differential diagnosis or complex multi-comorbidity treatment planning. Important clinically, but the ROI doesn't justify the governance and validation overhead in early deployment phases.
The Self-Assessment Scorecard
Rate your organization 1-5 on each dimension using the criteria below. Be honest — inflated scores lead to deployment failures.
| Dimension | Score 1 | Score 3 | Score 5 | Your Score |
|---|---|---|---|---|
| Data Readiness | No FHIR APIs; data in silos; no terminology standards | FHIR R4 for core resources; some terminology mapping; batch data access | Real-time FHIR; full USCDI v3; RAG-indexed clinical data; data quality monitoring | ___ |
| Infrastructure | No GPU capacity; shared service accounts; no API gateway | Cloud-based inference; basic API management; some agent-specific service identities | Dedicated inference infra; granular SMART scopes per agent; full observability stack | ___ |
| Governance | No AI governance body; no agent-specific policies | Governance board exists; basic approval process; ad-hoc incident response | Full governance framework; clinical validation committee; tested incident response; model versioning | ___ |
| Workforce | No AI/ML staff; no clinical informatics capability | Some ML engineers; clinical informaticist on staff; training programs in development | Full AI team with clinical context; AIOps role; continuous upskilling; retention strategy | ___ |
| Use Cases | No prioritization framework; ad-hoc experimentation | Prioritization matrix defined; 1-2 pilots selected; ROI model drafted | Portfolio of agents in production; measured ROI; systematic pipeline for new use cases | ___ |
Interpreting Your Total Score
| Total Score | Maturity Level | What It Means |
|---|---|---|
| 5-9 | Exploring | You're researching agentic AI but lack the foundation for safe deployment. Focus on Dimensions 1 and 2 before anything else. |
| 10-15 | Piloting | You have enough infrastructure for controlled pilots. Select one Quadrant 1 use case and build governance around it. |
| 16-20 | Scaling | Your foundation supports multiple agents. Focus on Dimension 3 (governance) and Dimension 4 (workforce) to scale safely. |
| 21-25 | Optimizing | You're operating at the frontier. Focus on multi-agent orchestration, autonomous improvement loops, and measurable clinical outcomes. |
Maturity Level Distribution: Where the Industry Stands
Based on the Microsoft/HMA survey data and supplementary industry analysis from CHIME and HIMSS 2026 reports, here's where U.S. health systems currently fall:
- Exploring (approximately 49%): Nearly half of health systems are still in research mode. They're attending conferences, reading whitepapers, and running internal discussions, but haven't stood up infrastructure or governance for agentic AI. Many are stuck here because Dimension 1 (data readiness) scores below 2.
- Piloting (approximately 35%): The largest active cohort. These organizations have 1-2 agent use cases running in sandboxed environments, typically in revenue cycle or administrative workflows. Their primary constraint is Dimension 3 — governance frameworks haven't caught up to deployment velocity.
- Scaling (approximately 15%): A smaller group that has multiple agents in production with formal governance oversight. These are typically large academic medical centers or integrated delivery networks with existing AI/ML teams. Their challenge is Dimension 4 — scaling the workforce to support a growing agent portfolio.
- Optimizing (approximately 1%): A handful of organizations (Mayo Clinic, Kaiser Permanente, Mass General Brigham are frequently cited) that are operating networks of agents with autonomous coordination, continuous performance optimization, and measured clinical outcome improvements.
Your 90-Day Agentic AI Readiness Plan
Regardless of your current maturity level, the next 90 days should follow this structure:
Month 1: Assess (Days 1-30)
- Complete the self-assessment scorecard with your leadership team. Include CIO, CMIO, CISO, VP of Revenue Cycle, and CNO. Honest scoring requires cross-functional perspectives.
- Audit your FHIR API coverage. Run the ONC FHIR Certification Test Suite against your production APIs. Document which USCDI v3 data classes are missing or incomplete.
- Inventory your integration points. Map every system an agent might need to touch: EHR, revenue cycle, pharmacy, lab, imaging, and payer portals. For each, document the API availability, authentication method, and data format.
- Benchmark infrastructure capacity. If considering on-premises inference, run load tests. If cloud-based, get BAA-covered pricing from your cloud provider for inference workloads.
Month 2: Plan (Days 31-60)
- Select your first use case from Quadrant 1. Use the prioritization matrix. Don't pick the most exciting use case — pick the one where data readiness and governance requirements align with your current scores.
- Draft your governance framework. Define the governance board composition, approval workflow for agent deployment, incident response protocol, and model versioning policy. It doesn't need to be perfect — it needs to exist before the first agent hits production.
- Address workforce gaps. Enroll clinical informatics staff in AI/ML foundations courses (Coursera's AI in Healthcare specialization, Stanford's Clinical AI certificate). For immediate capability gaps, engage a specialized healthcare AI partner who can provide implementation support while your team upskills.
- Define success metrics. For your selected use case, establish quantitative success criteria: processing time reduction, cost savings, accuracy thresholds, clinician satisfaction scores, and patient safety metrics.
Month 3: Pilot (Days 61-90)
- Deploy your first agent in a controlled environment. Start with a shadow deployment where the agent processes real data, but a human reviews every action before it takes effect. Measure agent accuracy against human performance.
- Activate governance processes. Run the governance board approval workflow for your pilot. Document every decision and exception. This dry run will expose gaps in your framework before you scale.
- Measure and iterate. Collect performance data against your predefined success metrics. Conduct weekly reviews with the clinical validation committee. Adjust agent behavior, guardrails, and prompts based on real-world performance.
- Plan Phase 2. Based on pilot results, update your readiness scorecard and select the next use case. Each deployment should improve your scores across all five dimensions.
Where Nirmitee Fits
At Nirmitee, we build the data infrastructure and integration layers that make agentic AI possible in healthcare. From FHIR API development and clinical data pipeline engineering to EHR integration and interoperability consulting, we help health systems move from Dimension 1 scores of 1-2 to the Level 3-4 data readiness that autonomous agents require. If your self-assessment reveals data and infrastructure gaps, that's where we start.
Ready to deploy AI agents in your healthcare workflows? Explore our Agentic AI for Healthcare services to see what autonomous automation can do. We also offer specialized Healthcare AI Solutions services. Talk to our team to get started.
Frequently Asked Questions
What is the difference between agentic AI and traditional AI in healthcare?
Traditional AI in healthcare operates on a request-response model: a clinician asks a question, and the model provides an answer. Agentic AI systems operate autonomously — they can plan multi-step workflows, call external tools (FHIR APIs, payer portals, formulary databases), make intermediate decisions, and take actions without requiring a human prompt at every step.
An AI chatbot that answers patient questions is traditional AI. An agent that independently verifies insurance eligibility, checks formulary coverage, identifies a cheaper therapeutic equivalent, and submits a prior authorization is agentic AI.
How long does it take a health system to move from Exploring to Piloting?
Based on industry data, the median timeline from Exploring to a credible pilot is 6-9 months. The primary bottleneck is almost always Dimension 1 (data readiness) — standing up FHIR APIs with sufficient data quality takes 3-6 months for organizations starting from a low base. Organizations with existing FHIR infrastructure can move to pilot in 2-3 months.
Should we build agentic AI capabilities in-house or buy from a vendor?
Neither extreme works well. Pure vendor solutions lack the clinical context specificity your workflows require. A pure in-house build is prohibitively expensive given the talent shortage (Dimension 4).
The most successful model is partnering with a healthcare integration and data infrastructure specialist for the foundational layers (FHIR APIs, data pipelines, integration) while building use-case-specific agent logic in-house, where your clinical domain expertise lives.
What are the biggest risks of deploying agentic AI without a governance framework?
Three categories of risk: clinical safety (agent makes a decision that leads to patient harm, with no audit trail or accountability chain), regulatory (HIPAA violations from uncontrolled PHI access, OIG scrutiny for agent-generated billing submissions), and operational (cascading failures in multi-agent systems that disrupt clinical workflows at scale). Governance isn't bureaucracy — it's the structure that makes the difference between an agent and an incident.
Related reading
For more insights, explore our guides on AI agents in healthcare and FHIR in Modern Healthcare.
You may also find value in EHR Software Development Guide and Building a Healthtech App.


