Part of our complete guide to HIPAA Compliance Checklist for Healthcare Software Developers: Code-Level Requirements for 2026.
Every week, a new healthcare AI startup announces a product that reads clinical notes, triages patients, generates prior authorization letters, or summarizes discharge instructions. The underlying models are extraordinarily capable.
GPT-4o can pass medical licensing exams. Claude can extract structured data from unstructured clinical narratives with near-human accuracy. Gemini can process multimodal inputs combining imaging, lab results, and physician notes.
But capability is not the same as compliance. And in US healthcare, compliance is not optional — it is existential.
For teams that want this handled as a service, see our healthcare compliance software offering.
The moment your AI agent reads a patient's name alongside their diagnosis, you are processing Protected Health Information (PHI) under HIPAA. The moment that PHI enters an LLM's context window, you have created a data flow that must satisfy the HIPAA Security Rule, the Privacy Rule, and potentially the Breach Notification Rule.
If your AI agent operates autonomously — making decisions without a human reviewing each one — you have introduced a new category of compliance risk that most healthcare organizations have never encountered.
This guide is the architecture reference we wished existed when we started building AI systems for healthcare. It covers every layer of the compliance stack: what counts as PHI in an AI context. This guide covers which vendors will sign a Business Associate Agreement and how to architect your data flows so PHI is protected at every step. It also shows how to build audit trails for autonomous AI decisions — and how to navigate the fast-changing regulatory landscape around healthcare AI.
Related Reading
For more insights, explore our guides on Healthcare Cybersecurity Architecture After Change Healthcare and FHIR in Modern Healthcare.
You may also find value in EHR Software Development Guide and Building a Healthtech App.
This is not a legal document. It is an engineering guide written for the development teams building healthcare AI products in 2026. Every pattern described here has been deployed in production. Every vendor assessment reflects current BAA availability. Every code example is drawn from real implementations.
Understanding PHI in the Age of LLMs
The foundation of HIPAA compliance for AI systems begins with a precise understanding of what constitutes Protected Health Information — and how that definition maps to the data structures AI systems consume.
The 18 HIPAA Identifiers and LLM Context Windows
HIPAA defines PHI as any individually identifiable health information held or transmitted by a covered entity or its business associate. The HIPAA Privacy Rule specifies 18 categories of identifiers that, when combined with health information, create PHI.
Understanding these categories is critical because they define the boundary between data you can freely send to an AI model and data that requires the full weight of HIPAA compliance infrastructure.
The 18 identifiers are: names, geographic data smaller than a state, dates (except year) related to an individual, phone numbers, fax numbers, email addresses, Social Security numbers, medical record numbers, and health plan beneficiary numbers. The list continues with account numbers, certificate/license numbers, vehicle identifiers and serial numbers, device identifiers and serial numbers, web URLs, IP addresses, biometric identifiers, full-face photographs, and any other unique identifying number or code.
Here is the critical insight for AI engineers: PHI is created by combination, not by isolation. A diagnosis code alone (E11.65 — Type 2 diabetes with hyperglycemia) is not PHI. A patient's name alone is not PHI. But the combination of a name with a diagnosis code creates PHI.
When your AI agent processes a clinical note that contains both a patient identifier and clinical information, the entire content of that context window becomes PHI-laden data subject to HIPAA protections.
De-identification Strategies for AI Processing
HIPAA provides two methods for de-identifying health information, and both are directly applicable to preparing data for AI processing.
Safe Harbor Method (45 CFR §164.514(b)(2)): Remove all 18 identifiers and have no actual knowledge that the remaining information could identify an individual. This is the most common approach for healthcare AI because it provides a clear, auditable standard.
If you strip all 18 identifiers from a clinical note before sending it to an LLM, the resulting text is no longer PHI, and HIPAA no longer applies to that specific data transmission.
Expert Determination Method (45 CFR §164.514(b)(1)): A qualified statistical expert determines that the risk of identifying an individual from the data is very small. This method is more nuanced and allows you to retain some data elements (like partial dates or geographic regions) that the Safe Harbor method would require you to remove.
For AI training data, Expert Determination can be valuable because it preserves more clinical context while still achieving de-identification.
In practice, most production healthcare AI systems use a hybrid approach:
# De-identification pipeline for LLM processing
import re
from typing import Dict, List, Tuple
class PHIDeidentifier:
"""HIPAA Safe Harbor de-identification for LLM context preparation."""
def __init__(self):
self.token_map: Dict[str, str] = {} # Maps tokens back to PHI
self.counter = 0
def deidentify(self, clinical_text: str) -> Tuple[str, Dict]:
"""Strip PHI and return tokenized text + mapping."""
text = clinical_text
# Names (NER-based detection recommended for production)
text = self._replace_pattern(
text,
r'\b(?:Mr|Mrs|Ms|Dr)\.?\s+[A-Z][a-z]+(?:\s+[A-Z][a-z]+)+',
'PATIENT_NAME'
)
# SSN
text = self._replace_pattern(
text, r'\b\d{3}-\d{2}-\d{4}\b', 'SSN'
)
# MRN (common formats)
text = self._replace_pattern(
text, r'\bMRN[:\s]*\d{6,10}\b', 'MRN'
)
# Dates (preserve year for clinical context)
text = self._replace_pattern(
text, r'\b\d{1,2}/\d{1,2}/\d{4}\b', 'DATE'
)
# Phone numbers
text = self._replace_pattern(
text, r'\b\(?\d{3}\)?[-.\s]?\d{3}[-.\s]?\d{4}\b', 'PHONE'
)
# Email
text = self._replace_pattern(
text, r'\b[\w.-]+@[\w.-]+\.\w+\b', 'EMAIL'
)
return text, self.token_map
def _replace_pattern(self, text: str, pattern: str, token_type: str) -> str:
def replacer(match):
self.counter += 1
token = f"[{token_type}_{self.counter}]"
self.token_map[token] = match.group()
return token
return re.sub(pattern, replacer, text)
def reidentify(self, ai_response: str) -> str:
"""Re-identify AI output by replacing tokens with original PHI."""
result = ai_response
for token, original in self.token_map.items():
result = result.replace(token, original)
return resultThis pattern allows your AI agent to process clinical content with full semantic understanding while ensuring that raw PHI never enters the LLM's context window. The token mapping is stored in your own infrastructure — never sent to the AI vendor — and is used to re-identify the AI's response when it needs to reference specific patients.
For production systems, replace the regex-based approach with a trained NER (Named Entity Recognition) model specifically tuned for clinical text. Microsoft's Presidio, Amazon Comprehend Medical, and John Snow Labs' Spark NLP for Healthcare all provide clinical NER models that greatly outperform regex for PHI detection in unstructured clinical narratives.
Business Associate Agreements: The Vendor Landscape in 2026
A Business Associate Agreement is a legal contract required by HIPAA whenever a covered entity (hospital, health plan, provider) shares PHI with a third party (business associate) who will create, receive, maintain, or transmit PHI on its behalf.
If your AI system sends PHI to a cloud AI provider, that provider must sign a BAA with you — or you must ensure PHI never reaches them.
The BAA landscape for AI vendors has evolved rapidly since 2024. Here is the current state as of March 2026:
OpenAI
OpenAI offers BAAs for its API and Enterprise tiers. The API BAA covers GPT-4o, GPT-4, o1, o3, Whisper, and DALL-E when accessed through the API with zero data retention enabled. ChatGPT consumer plus accounts are not covered.
The Enterprise tier includes additional controls: SSO integration, data isolation, dedicated compute options, and a more complete BAA that covers both API and web interface usage. Key condition: you must enable zero-retention mode (the API default since 2025) to ensure prompts and completions are not stored by OpenAI after processing.
Anthropic
Anthropic provides BAAs for Claude API access through direct sales agreements. Coverage includes Claude 3.5 Sonnet, Claude 3.5 Haiku, and Claude 4 Opus models. The BAA is available for organizations with committed usage agreements — contact their sales team directly.
Anthropic's Constitutional AI approach provides an additional safety layer, but the BAA is the legal requirement. Claude does not retain prompt data by default on the API tier, which aligns well with HIPAA's minimum necessary standard.
Google Cloud (Vertex AI)
Google Cloud has the broadest BAA coverage in the AI space. Their BAA covers all Vertex AI services, including Gemini models, AutoML, Document AI, Cloud Healthcare API, Speech-to-Text, and the full generative AI platform.
The BAA is part of the standard Google Cloud agreement — no premium pricing or special tier required. This is a significant advantage for organizations already on GCP. One critical caveat: do not include PHI in Dialogflow agent definitions, training phrases, or entity configurations, as these may be captured in system logs outside the BAA scope.
AWS Bedrock
Amazon Bedrock is covered under the AWS BAA addendum. This includes access to Claude (Anthropic), Titan (Amazon), Llama (Meta), and other models available through Bedrock. The AWS BAA is complete, covering over 150 services.
Bedrock-specific protections include VPC endpoints, private model deployment, and integration with AWS HealthLake for FHIR-native healthcare data. For organizations with existing AWS Healthcare workloads, Bedrock provides the path of least resistance.
Azure OpenAI
Microsoft Azure OpenAI Service is covered under the Azure BAA, which is one of the most mature in the industry. Coverage includes GPT-4o, GPT-4, DALL-E, Whisper, and all models available through the Azure OpenAI endpoint.
Azure provides data residency guarantees (data stays in your selected region), private endpoints via Azure Private Link, and integration with Azure Health Data Services. Content filtering and abuse monitoring can be customized for healthcare use cases.
Self-Hosted Models (Llama, Mistral, Mixtral)
When you self-host an open-source model, there is no external vendor to sign a BAA — you are the data processor. PHI never leaves your infrastructure, which eliminates the vendor BAA requirement entirely.
However, you assume full responsibility for all HIPAA technical safeguards: encryption at rest, encryption in transit, access controls, audit logging, and physical security of the infrastructure. Self-hosting is the right choice for organizations processing the most sensitive categories of PHI (42 CFR Part 2 substance abuse records, genomic data, behavioral health records) or those with existing on-premises GPU infrastructure.
Related reading: Sovereign AI in Healthcare: On-Prem LLM Guide.
Three Architecture Patterns for HIPAA-Compliant AI
A Business Associate Agreement is a legal contract required by HIPAA. It applies whenever a covered entity (hospital, health plan, provider) shares PHI with a third party — a business associate — who will create, receive, maintain, or transmit PHI on its behalf.
Pattern A: PHI Never Leaves Your Infrastructure
In this pattern, you self-host the AI model on your own infrastructure (on-premises GPU cluster or a dedicated cloud VPC). PHI is processed entirely within your security boundary. No external AI API calls are made with any data — identified or de-identified.
How it works:
- Clinical data originates in your EHR system
- Data is routed to your on-premises or VPC-hosted AI inference service
- A self-hosted model (Llama 3.1 405B, Mistral Large, or fine-tuned smaller models) processes the data
- Results are returned to your application layer
- All processing occurs within your HIPAA-compliant network boundary
# Kubernetes deployment for self-hosted healthcare LLM
apiVersion: apps/v1
kind: Deployment
metadata:
name: healthcare-llm-inference
namespace: hipaa-ai
labels:
compliance: hipaa
data-classification: phi-processing
spec:
replicas: 2
selector:
matchLabels:
app: llm-inference
template:
metadata:
labels:
app: llm-inference
phi-boundary: internal-only
spec:
nodeSelector:
gpu: "true"
hipaa-zone: "restricted"
containers:
- name: vllm-server
image: vllm/vllm-openai:latest
args:
- "--model"
- "meta-llama/Llama-3.1-70B-Instruct"
- "--tensor-parallel-size"
- "4"
- "--max-model-len"
- "32768"
resources:
limits:
nvidia.com/gpu: 4
memory: "160Gi"
volumeMounts:
- name: model-cache
mountPath: /root/.cache/huggingface
- name: audit-logs
mountPath: /var/log/inference
volumes:
- name: model-cache
persistentVolumeClaim:
claimName: llm-model-cache
- name: audit-logs
persistentVolumeClaim:
claimName: inference-audit-logs
---
# Network policy: no egress to public internet
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: llm-no-egress
namespace: hipaa-ai
spec:
podSelector:
matchLabels:
app: llm-inference
policyTypes:
- Egress
egress:
- to:
- namespaceSelector:
matchLabels:
zone: hipaa-internalBest for: Organizations processing the highest-sensitivity PHI categories (substance abuse records under 42 CFR Part 2, reproductive health data, behavioral health records, genomic information). Also appropriate for organizations with existing GPU infrastructure or those with regulatory requirements that prohibit any external data transmission.
Cost consideration: Running Llama 3.1 70B on 4x A100 GPUs costs about $12,000-$18,000/month on cloud GPU instances, or $150,000-$250,000 in capital expenditure for on-premises hardware. Compare this with the API cost for equivalent throughput at cloud providers ($5,000-$15,000/month depending on volume).
Pattern B: Cloud AI with BAA + De-identification (Hybrid)
This is the most common pattern in production healthcare AI systems today. PHI is de-identified before it reaches the cloud AI provider. The AI processes de-identified data, and re-identification happens in your infrastructure.
How it works:
- Clinical data originates in your EHR system
- Your de-identification engine strips the 18 HIPAA identifiers, replacing them with tokens
- The de-identified text is sent to a cloud AI API (OpenAI, Anthropic, Google — all under BAA)
- The AI processes the clinical content without access to identifying information
- Your application layer re-identifies the response using the token mapping
- Complete audit trail logs every step
This pattern provides defense in depth: even if the BAA relationship with your AI vendor were somehow compromised, the data they received was already de-identified. The BAA serves as a second layer of legal protection over the technical protection of de-identification.
Best for: The majority of healthcare AI use cases — clinical documentation assistance, AI-powered clinical decision support, medical coding suggestions, patient engagement chatbots, and care gap identification. This pattern balances strong privacy protection with the full capability of frontier AI models.
Pattern C: Full Cloud AI with BAA (Direct PHI)
In this pattern, PHI is sent directly to the cloud AI provider under the protection of a BAA. No de-identification is performed. The AI model has full access to the patient's identified information.
How it works:
- Clinical data originates in your EHR system
- Data passes through your API gateway with TLS 1.3 encryption, authentication, and rate limiting
- The full clinical content — including patient identifiers — is sent to the cloud AI API
- The AI processes the content with full context
- The response is returned and logged
This pattern is simpler to implement but requires absolute trust in your BAA and the vendor's compliance posture. With the PHI classification and vendor landscape established, the core architectural question becomes: where does PHI live in your AI data flow? There are three proven patterns. Each has a different security, cost, and complexity profile.
Best for: Administrative AI (scheduling optimization, billing inquiries, insurance verification), patient-facing chatbots where the patient has consented to AI-assisted communication, and internal workflow automation where the AI needs access to patient identity for routing or coordination purposes.
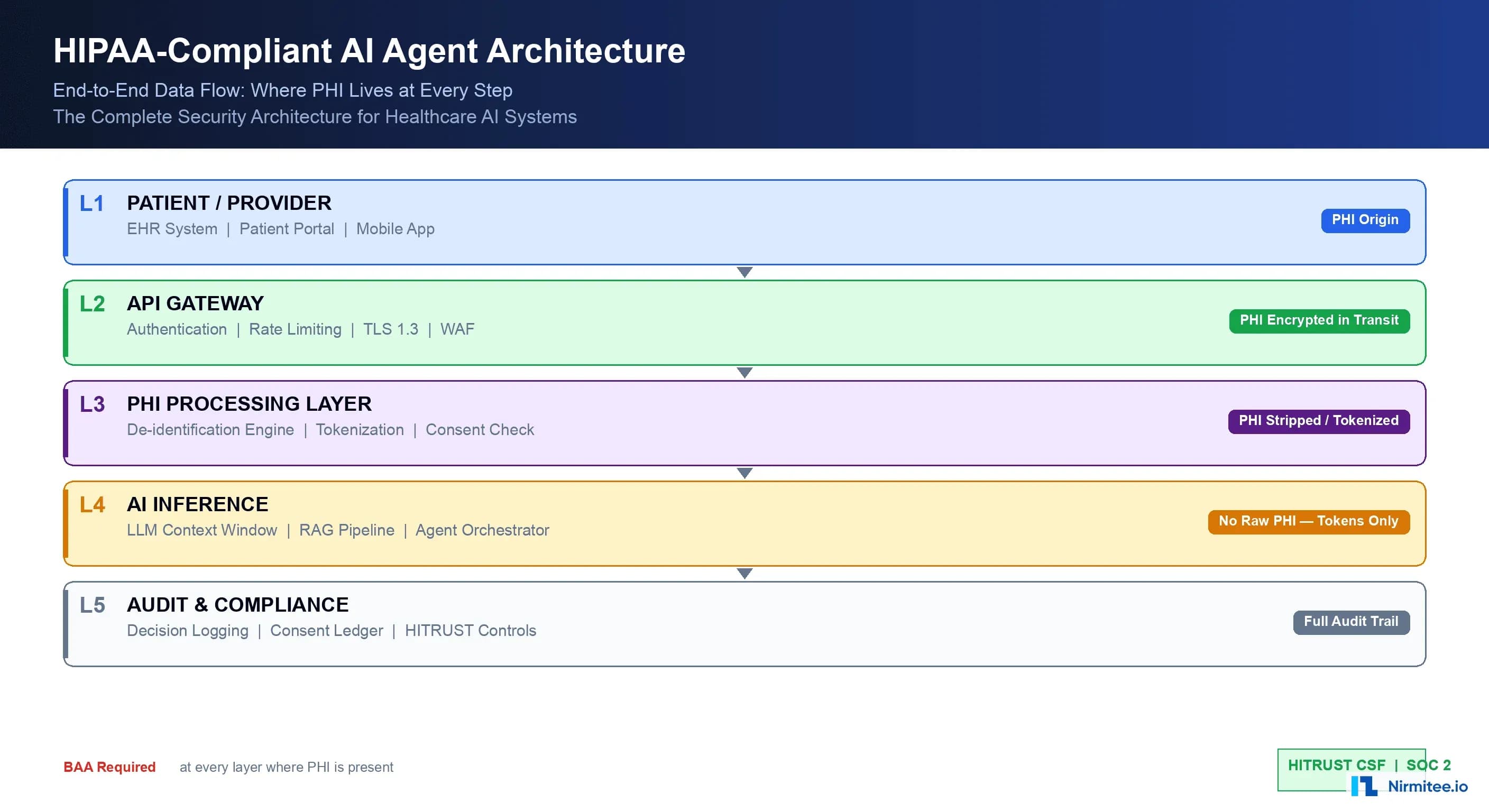
Data Flow Security: Protecting PHI at Every Step
Regardless of which architecture pattern you choose, HIPAA requires specific technical safeguards at every point where PHI is created, received, maintained, or transmitted. Here is the security implementation for a complete AI data flow:
Encryption Requirements
In Transit: TLS 1.3 is the minimum standard for all PHI transmissions. This includes API calls to AI vendors, internal service-to-service communication, and data replication. Certificate pinning is recommended for connections to AI vendor endpoints to prevent man-in-the-middle attacks.
At Rest: AES-256 encryption for all stored PHI, including audit logs, token mappings, and any cached AI responses that contain PHI. Use envelope encryption with a KMS (AWS KMS, Azure Key Vault, GCP Cloud KMS, or HashiCorp Vault) so that encryption keys are managed separately from the encrypted data.
# Encryption envelope for PHI token mappings
import boto3
from cryptography.fernet import Fernet
import json
import base64
class PHITokenStore:
"""Encrypted storage for PHI de-identification token mappings."""
def __init__(self, kms_key_id: str, region: str = 'us-east-1'):
self.kms = boto3.client('kms', region_name=region)
self.kms_key_id = kms_key_id
def encrypt_mapping(self, token_map: dict) -> bytes:
"""Encrypt token mapping with KMS-managed key."""
# Generate a data encryption key via KMS
response = self.kms.generate_data_key(
KeyId=self.kms_key_id,
KeySpec='AES_256'
)
plaintext_key = response['Plaintext']
encrypted_key = response['CiphertextBlob']
# Encrypt the token mapping with the data key
fernet_key = base64.urlsafe_b64encode(plaintext_key[:32])
fernet = Fernet(fernet_key)
encrypted_data = fernet.encrypt(
json.dumps(token_map).encode()
)
# Return encrypted key + encrypted data as a single blob
return json.dumps({
'encrypted_key': base64.b64encode(encrypted_key).decode(),
'encrypted_data': encrypted_data.decode()
}).encode()
def decrypt_mapping(self, blob: bytes) -> dict:
"""Decrypt token mapping using KMS."""
package = json.loads(blob)
# Decrypt the data key via KMS
response = self.kms.decrypt(
CiphertextBlob=base64.b64decode(package['encrypted_key'])
)
plaintext_key = response['Plaintext']
# Decrypt the token mapping
fernet_key = base64.urlsafe_b64encode(plaintext_key[:32])
fernet = Fernet(fernet_key)
decrypted = fernet.decrypt(
package['encrypted_data'].encode()
)
return json.loads(decrypted)Access Controls
HIPAA's minimum necessary standard (45 CFR §164.502(b)) requires that access to PHI be limited to the minimum amount necessary to accomplish the intended purpose. For AI systems, this translates to:
- Prompt-level access controls: Your AI agent should only receive the specific clinical data elements needed for its current task. A coding AI does not need the patient's phone number. A scheduling AI does not need the patient's lab results.
- Role-based access to AI outputs: Different user roles should see different levels of AI-generated content. A billing specialist sees the AI's coding suggestions. A clinician sees the AI's clinical summary. Neither sees the other's output unless their role requires it.
- Service account isolation: Each AI agent or microservice should have its own service account with narrowly scoped permissions. Never share a single database connection or API key across multiple AI services.
Audit Logging for Autonomous AI Decisions
When an AI agent makes a decision autonomously — suggesting a diagnosis code, generating a prior authorization letter, or flagging a care gap — that decision must be auditable. HIPAA's audit control requirements (§164.312(b)) mandate that covered entities implement mechanisms to record and examine activity in information systems that contain or use PHI.
For AI systems, this goes beyond traditional application logging. Every AI decision that touches PHI must capture:
The Audit Record Structure
{
"decision_id": "ai-dec-7f3a9b2c-4e1d-4a8b-9c3f-2d1e0f9a8b7c",
"timestamp": "2026-03-19T14:23:01.847Z",
"agent": {
"type": "clinical_documentation_assistant",
"model": "claude-3.5-sonnet-20260101",
"version": "1.4.2",
"deployment_id": "prod-cda-us-east-1"
},
"context": {
"encounter_id": "enc-abc123",
"phi_in_context": false,
"deidentification_method": "safe_harbor",
"input_token_count": 2847,
"input_hash": "sha256:9f86d081884c7d659a2feaa0c55ad015..."
},
"decision": {
"type": "icd10_code_suggestion",
"output": "E11.65 — Type 2 diabetes mellitus with hyperglycemia",
"confidence": 0.94,
"alternatives": [
{"code": "E11.9", "confidence": 0.82},
{"code": "E13.65", "confidence": 0.71}
]
},
"human_review": {
"required": true,
"reviewer": "dr.smith@hospital.org",
"review_timestamp": "2026-03-19T14:25:33.102Z",
"status": "approved",
"modifications": null
},
"compliance": {
"hipaa_safeguard": "audit_control_164.312b",
"retention_days": 2190,
"immutable": true,
"storage": "s3://hipaa-audit-logs/2026/03/19/"
}
}Retention requirements: HIPAA requires covered entities to retain documentation for six years from the date of creation or the date when it was last in effect. For AI decision logs, this means every autonomous AI decision must be stored in immutable, tamper-proof storage for a minimum of 2,190 days.
Use write-once storage (S3 Object Lock, Azure Immutable Blob Storage, or GCS Bucket Lock) to prevent modification or deletion during the retention period.
It is appropriate for lower-sensitivity use cases where the clinical context benefits greatly from having patient identity available. One example: AI systems that need to correlate a patient's current visit with their longitudinal health record. These alerts should trigger immediate human review.
Consent Management for AI-Assisted Care
HIPAA's Privacy Rule provides a framework for when PHI can be used and disclosed. But AI introduces new consent considerations that go beyond traditional clinical data sharing.
Treatment, Payment, and Health Care Operations (TPO)
Under HIPAA, covered entities can use and disclose PHI for treatment, payment, and health care operations without patient authorization.
This is the legal basis for most clinical AI use cases. An AI agent that helps a physician document a clinical encounter, suggests diagnosis codes for billing, or identifies care gaps for quality improvement falls under TPO.
However, there are important nuances:
- AI-generated clinical notes: If an AI generates or substantially modifies a clinical note, the patient has the right to know. The CMS Interoperability and Patient Access Final Rule requires that patients can access their health records, including AI-generated content. Consider adding metadata to AI-assisted notes indicating they were generated with AI assistance.
AI in research vs. operations: If your AI system is learning from patient data to improve its models (even locally), this may cross from operations into research. This requires IRB approval and potentially explicit patient consent.
The line between "quality improvement" and "research" is a compliance minefield — consult your IRB and compliance officer.
- Psychotherapy notes: These receive heightened protection under HIPAA. AI systems should never process psychotherapy notes without explicit, separate patient authorization — even for TPO purposes.
State-Specific Consent Requirements
Several states have enacted AI-specific consent laws that go beyond HIPAA's baseline:
California (CCPA/CPRA + AB 331): Requires disclosure when automated decision-making technology is used in decisions that greatly affect consumers.
Healthcare AI decisions about treatment recommendations or insurance coverage likely trigger this requirement. Patients have the right to opt out of automated decision-making.
- Colorado (SB 24-205): Enacted one of the first complete AI governance laws. Deployers of high-risk AI systems (including healthcare) must conduct algorithmic impact assessments, disclose AI use to consumers, and provide opt-out mechanisms. Effective February 2026.
- New York (SHIELD Act + proposed AI Accountability Act): The SHIELD Act already requires reasonable data security safeguards. Proposed AI legislation would require bias audits for AI systems used in significant decisions affecting New Yorkers, including healthcare decisions.
- Illinois (BIPA implications): If your AI processes biometric identifiers (voice recognition, facial recognition for patient identification), the Biometric Information Privacy Act requires explicit consent and specific data handling procedures.
- Washington (My Health My Data Act): Applies to consumer health data processed outside of HIPAA-covered entities. If your AI product processes health data from non-covered entities (health apps, wellness platforms), this law requires consent and provides a private right of action.
The Human-in-the-Loop Requirement
Not all AI decisions in healthcare can be fully autonomous. The concept of "human-in-the-loop" (HITL) is both a regulatory expectation and a clinical safety requirement. But the level of human involvement should be calibrated to the risk level of the AI's decision.
Risk-Based Human Oversight Framework
The FDA's guidance on AI/ML-based Software as a Medical Device (SaMD) and the NIST AI Risk Management Framework both support a risk-based approach to human oversight. Here is how to implement it:
Tier 1 — Autonomous Operation (Low Risk): AI operates independently with periodic batch review. Appropriate for administrative tasks with low clinical impact and high reversibility. Examples: appointment scheduling suggestions, insurance eligibility pre-checks, medical record summarization for chart prep, patient FAQ responses, facility wayfinding. Human review: weekly quality audit of a statistical sample (5-10% of decisions).
Tier 2 — Human-on-the-Loop (Moderate Risk): AI makes recommendations that a human must acknowledge before they take effect. The human does not need to independently arrive at the same conclusion — they review the AI's recommendation and approve, modify, or reject it. Examples: ICD-10 code assignment, prior authorization letter generation, care gap identification, medication interaction alerts, clinical documentation drafts. Human review: every decision, but streamlined (one-click approve or modify).
Tier 3 — Human-in-the-Loop (High Risk): AI provides information and analysis, but the human makes the final decision independently. The AI serves as a decision support tool, not a decision maker. Examples: diagnosis suggestions, treatment plan modifications, medication dosage adjustments, surgical risk assessments, mental health crisis triage. Human review: full independent clinical judgment required. The AI's output is one input among many.
# Human-in-the-loop decision router
from enum import Enum
from dataclasses import dataclass
from typing import Optional
import datetime
class RiskTier(Enum):
AUTONOMOUS = 1 # Low risk, batch review
HUMAN_ON_LOOP = 2 # Moderate risk, acknowledge before effect
HUMAN_IN_LOOP = 3 # High risk, independent human decision
@dataclass
class AIDecision:
decision_id: str
decision_type: str
risk_tier: RiskTier
ai_recommendation: str
confidence: float
requires_review: bool
reviewer: Optional[str] = None
review_status: Optional[str] = None
reviewed_at: Optional[datetime.datetime] = None
class HITLRouter:
"""Route AI decisions through appropriate human oversight."""
RISK_MAP = {
'scheduling_suggestion': RiskTier.AUTONOMOUS,
'eligibility_check': RiskTier.AUTONOMOUS,
'chart_summary': RiskTier.AUTONOMOUS,
'icd10_suggestion': RiskTier.HUMAN_ON_LOOP,
'prior_auth_letter': RiskTier.HUMAN_ON_LOOP,
'care_gap_alert': RiskTier.HUMAN_ON_LOOP,
'documentation_draft': RiskTier.HUMAN_ON_LOOP,
'diagnosis_suggestion': RiskTier.HUMAN_IN_LOOP,
'treatment_modification': RiskTier.HUMAN_IN_LOOP,
'dosage_adjustment': RiskTier.HUMAN_IN_LOOP,
'crisis_triage': RiskTier.HUMAN_IN_LOOP,
}
def route(self, decision: AIDecision) -> dict:
tier = self.RISK_MAP.get(
decision.decision_type,
RiskTier.HUMAN_IN_LOOP # Default to highest oversight
)
decision.risk_tier = tier
if tier == RiskTier.AUTONOMOUS:
decision.requires_review = False
return {
'action': 'execute',
'review': 'batch_audit',
'sample_rate': 0.10 # 10% spot check
}
elif tier == RiskTier.HUMAN_ON_LOOP:
decision.requires_review = True
return {
'action': 'queue_for_review',
'review': 'acknowledge_before_effect',
'timeout_minutes': 60,
'escalation': 'supervisor_if_unreviewed'
}
else: # HUMAN_IN_LOOP
decision.requires_review = True
return {
'action': 'present_as_reference',
'review': 'independent_clinical_judgment',
'timeout_minutes': None, # No auto-execute
'escalation': 'none' # Human decides independently
}The NIST AI Risk Management Framework for Healthcare
The NIST AI Risk Management Framework (AI RMF 1.0), published in January 2023 and supplemented with healthcare-specific guidance through the NIST AI RMF Playbook, provides the most complete government framework for managing AI risks.
While not legally binding, it is rapidly becoming the de facto standard that regulators, auditors, and enterprise customers reference when evaluating healthcare AI products.
The Four Core Functions
GOVERN: Establish policies, roles, and accountability structures for AI oversight. For healthcare organizations, this means forming an AI Governance Committee with representation from clinical leadership, legal/compliance, information security, and engineering.
This committee should maintain a registry of all AI systems processing PHI, approve new AI deployments, and conduct quarterly risk reviews.
MAP: Identify, characterize, and prioritize AI risks within context. Best for: Administrative AI (scheduling optimization, billing inquiries, insurance verification) and patient-facing chatbots where the patient has consented to AI-assisted communication. Also a fit for internal workflow automation where the AI needs patient identity for routing or coordination.
MEASURE: Quantify AI risks using healthcare-specific metrics. Key metrics include: accuracy by demographic group (age, race, sex, socioeconomic status), false positive and false negative rates for clinical AI recommendations, PHI exposure incidents (how often is PHI detected in what should be de-identified data?), and human override rates (how often do clinicians reject AI recommendations, and are there patterns?).
MANAGE: Implement controls to treat, transfer, or accept identified risks. This is where your technical controls live: guardrails that prevent AI from operating outside its trained domain, human-in-the-loop checkpoints for high-risk decisions, circuit breakers that disable AI features when error rates exceed thresholds, and rollback mechanisms that can revert to human-only workflows instantly.
NIST AI RMF and HIPAA Alignment
The NIST AI RMF is not a replacement for HIPAA — it is a complementary framework. HIPAA tells you what you must protect (PHI) and the categories of safeguards required (administrative, physical, technical).
The NIST AI RMF tells you how to manage the risks introduced by AI systems that process that PHI. Together, they provide a complete compliance posture.
| HIPAA Requirement | NIST AI RMF Function | Implementation |
|---|---|---|
| Risk Analysis (§164.308(a)(1)) | MAP | AI-specific risk assessment covering model bias, PHI exposure, clinical safety |
| Access Controls (§164.312(a)) | MANAGE | Role-based access to AI inputs and outputs, minimum necessary enforcement |
| Audit Controls (§164.312(b)) | MEASURE | Complete decision logging, anomaly detection, quality metrics |
| Transmission Security (§164.312(e)) | MANAGE | TLS 1.3, certificate pinning, VPC endpoints for AI API calls |
| Integrity Controls (§164.312(c)) | GOVERN + MANAGE | Model versioning, output validation, tamper-proof audit logs |
| Workforce Training (§164.308(a)(5)) | GOVERN | AI-specific HIPAA training for developers, clinicians, and administrators |
State AI Regulations Impacting Healthcare
While HIPAA provides the federal baseline, state regulations are increasingly adding AI-specific requirements that healthcare organizations must navigate. This is an actively evolving area — here is the landscape as of March 2026:
Colorado SB 24-205 (Effective February 2026)
Colorado's AI Act is the most complete state AI law affecting healthcare. Real-time alerting: Configure alerts for anomalous AI behavior patterns. Watch for sudden changes in confidence distributions, unexpected PHI exposure (PHI detected in what should be de-identified data), or AI decisions that deviate greatly from historical patterns. Healthcare AI systems that influence treatment decisions, insurance coverage, or access to care are explicitly classified as high-risk.
California AB 331 + CCPA/CPRA
California's framework combines its existing complete privacy law (CCPA/CPRA) with emerging AI-specific legislation. Key requirements: consumers must be notified when automated decision-making technology is used, opt-out rights for automated profiling, mandatory bias audits for AI systems making significant decisions, and expanded breach notification requirements when AI systems are involved in data incidents.
EU AI Act Extraterritorial Impact
For healthcare AI, mapping means documenting every PHI touchpoint in your AI data flow. It also means characterizing the clinical impact of AI errors (what happens if the AI suggests the wrong diagnosis code?), identifying bias vectors (does the AI perform equally well across demographic groups?), and assessing the safety implications of each AI decision type. US healthcare companies serving international populations must architect their AI systems to satisfy both HIPAA and the EU AI Act's requirements.
Implementation Roadmap: From Zero to HIPAA-Compliant AI
Here is a practical, phased roadmap for organizations building their first HIPAA-compliant AI system:
Phase 1: Foundation (Weeks 1-4)
- Conduct an AI-specific risk assessment covering PHI data flows, vendor relationships, and clinical impact
- Establish your AI Governance Committee with clinical, legal, security, and engineering representation
- Select your architecture pattern (A, B, or C) based on your PHI sensitivity and infrastructure maturity
- Execute BAAs with all AI vendors in your data flow
- Deploy encryption at rest and in transit for all AI-related infrastructure
Phase 2: Core Infrastructure (Weeks 5-10)
- Implement your de-identification pipeline (if using Pattern B)
- Deploy your AI inference infrastructure (self-hosted or cloud)
- Build the audit logging framework with immutable storage
- Implement role-based access controls for AI inputs and outputs
- Deploy the human-in-the-loop decision routing system
- Conduct initial security penetration testing on the AI infrastructure
Phase 3: Validation and Compliance (Weeks 11-16)
- Run shadow mode: AI processes data in parallel with human workflows but does not affect patient care
- Conduct bias testing across demographic groups
- Complete your NIST AI RMF documentation (GOVERN, MAP, MEASURE, MANAGE)
- Perform a tabletop exercise simulating an AI-related PHI breach
- Engage a third-party auditor for a pre-deployment compliance review
- Train all users (developers, clinicians, administrators) on AI-specific HIPAA policies
Phase 4: Production Deployment (Weeks 17-20)
- Deploy to production with full audit logging and monitoring
- Begin with Tier 2 (human-on-the-loop) for all decisions, regardless of risk classification
- Monitor AI decision quality, human override rates, and system performance
- Gradually move appropriate decision types to Tier 1 (autonomous) as confidence data accumulates
- Establish quarterly compliance review cadence
Key Takeaways for Healthcare AI Builders
Building HIPAA-compliant AI is not a checkbox exercise — it is an architectural discipline. The organizations that get it right will build systems that are not just compliant but trustworthy, auditable, and clinically valuable. Here are the principles that matter most:
- PHI classification is the foundation. Before writing a single line of AI code, map every data element in your system and classify it against the 18 HIPAA identifiers. Build your de-identification pipeline before your inference pipeline.
- BAAs are table stakes, not the finish line. A signed BAA does not make you compliant — it makes your vendor accountable. You still need the full technical safeguard stack: encryption, access controls, audit logging, and incident response.
- Defense in depth is the only safe approach. Use Pattern B (de-identification + BAA) as your default. If PHI must enter the AI context window, ensure you have BAA coverage, encryption in transit, audit logging, and access controls — multiple layers, not a single point of protection.
- Every AI decision is an auditable event. Implement complete decision logging from day one, not as an afterthought. Six years of immutable, tamper-proof audit records is the HIPAA minimum. Build for it.
- Human oversight scales with clinical risk. Not everything needs a human in the loop. But everything involving a clinical judgment that could affect patient outcomes does. Build a risk-based framework and enforce it architecturally, not just procedurally.
- State laws are the wild card. HIPAA is the floor, not the ceiling. Colorado, California, Illinois, and others are adding AI-specific requirements that will affect your product. Build flexibility into your compliance architecture to absorb new requirements without major re-architecture.
Building AI agents for healthcare? Nirmitee specializes in HIPAA-compliant, FHIR-integrated AI systems built on the architecture patterns described in this guide. From clinical decision support to autonomous revenue cycle agents, we help US health systems deploy AI that is both powerful and compliant. Talk to our healthcare AI team →
Looking to build a robust healthcare platform? Our Healthcare Software Product Development team turns complex requirements into production-ready systems. We also offer specialized Agentic AI for Healthcare services. Talk to our team to get started.