Why Healthcare Data Teams Are Drowning — and How Data Mesh Fixes It
The typical multi-hospital health system runs a centralized data warehouse managed by a small analytics team. Every department — cardiology, laboratory, pharmacy, billing — submits requests to this team for new datasets, reports, and pipelines. The result is predictable: a 6-12 week backlog, stale data, and frustrated clinicians who resort to building shadow spreadsheets.
Data mesh, a paradigm introduced by Zhamak Dehghani at ThoughtWorks in 2019, offers an alternative. Instead of funneling all data through a central team, data mesh distributes ownership to the clinical domains that understand the data best. Each domain publishes data products — curated, documented, quality-monitored datasets with defined SLAs — that other teams can discover and consume independently.
This is not just an engineering pattern. For healthcare organizations managing data across multiple hospitals, clinics, and specialties, data mesh addresses fundamental problems: data ownership ambiguity, cross-departmental trust, regulatory compliance at scale, and the chronic bottleneck of centralized data teams. This guide covers how to implement data mesh principles in a healthcare setting, with concrete examples from clinical domains.

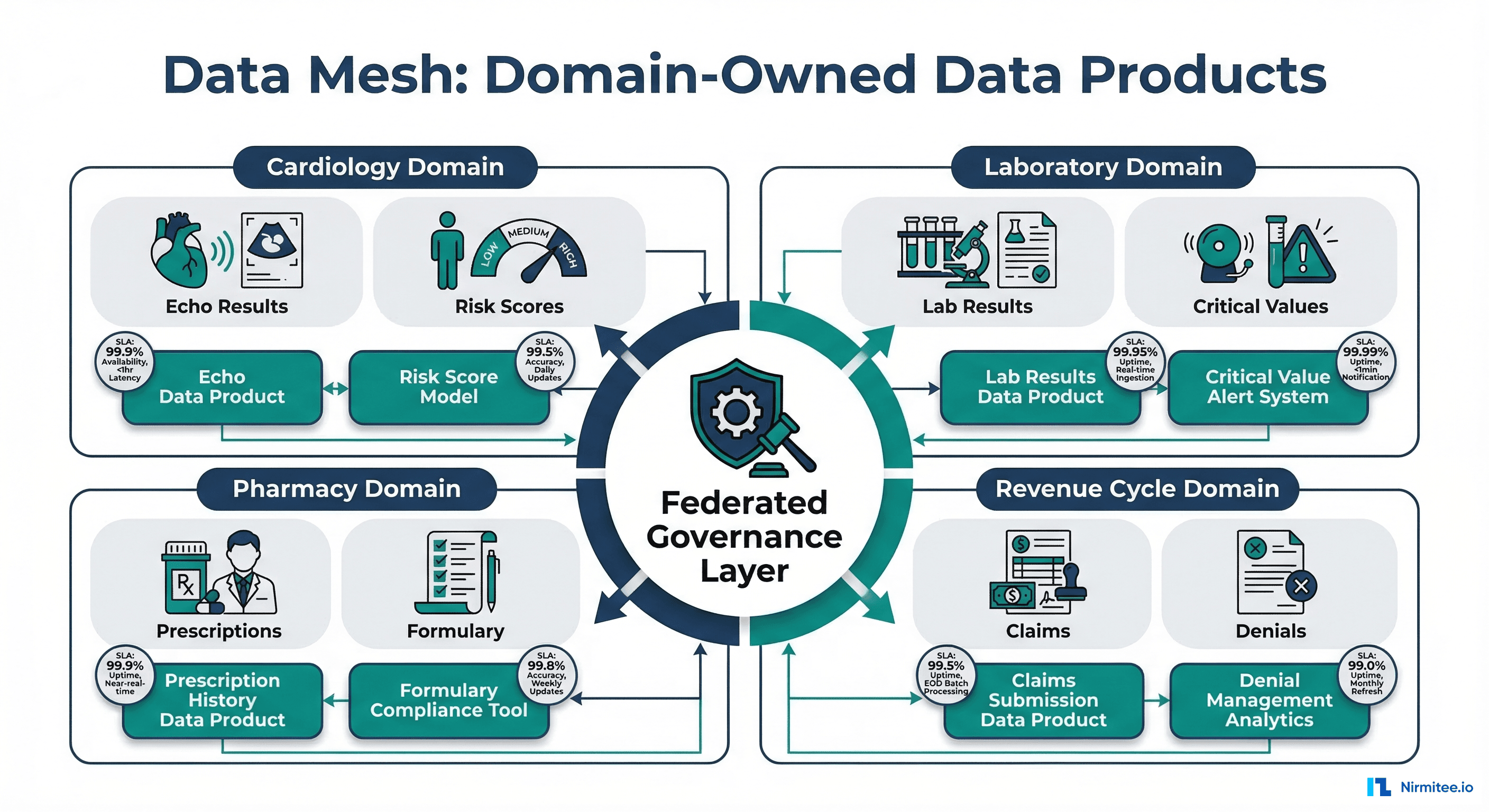
The Four Principles of Data Mesh Applied to Healthcare
1. Domain Ownership
In a data mesh, the team closest to the data owns it end-to-end. In healthcare, this maps directly to clinical departments:
- Cardiology owns cardiac data: echocardiogram results, cath lab reports, cardiac device data (pacemakers, ICDs), and risk scores (ASCVD, CHA2DS2-VASc)
- Laboratory owns lab data: chemistry panels, microbiology cultures, pathology results, critical value alerts, and reference range management
- Pharmacy owns medication data: prescribing patterns, formulary compliance, drug interaction alerts, dispensing records, and controlled substance tracking
- Revenue Cycle owns financial data: claims lifecycle, denial analytics, charge capture completeness, payment posting, and revenue leakage analysis
Each domain team includes data engineers who build and maintain pipelines, analysts who understand the clinical context, and a domain data product owner who defines priorities and SLAs.
2. Data as a Product
A data product is not just a table in a database. It is a curated, documented, quality-monitored dataset designed for consumption by other teams. Every healthcare data product must include:
- Schema definition: Clear structure, often aligned with FHIR or OMOP standards
- Quality SLAs: Freshness guarantees (e.g., lab results within 15 minutes of validation), completeness thresholds (99.5% coded with LOINC), accuracy metrics
- Documentation: Auto-generated schema docs, data dictionary, example queries, known limitations
- Access controls: Role-based access with PHI-appropriate masking (clinicians see full data, researchers see de-identified)
- Discoverability: Listed in a shared data catalog where any team can find and evaluate it

3. Self-Serve Data Infrastructure Platform
Domain teams should not each build their own infrastructure from scratch. The platform team provides shared, standardized tools that reduce the cognitive load of publishing data products:
| Platform Service | Purpose | Healthcare-Specific Requirements |
|---|---|---|
| Data Catalog | Discover and understand available data products | PHI classification tags, HIPAA sensitivity labels, data lineage tracking |
| Quality Framework | Automated data quality checks and monitoring | Clinical validation rules (lab ranges, vital sign bounds), data quality dashboards |
| Access Control | Role-based and attribute-based access management | Break-the-glass emergency access, minimum necessary standard, audit trails for PHI access |
| Pipeline Templates | Standardized ETL/ELT patterns for domain teams | FHIR ingestion templates, HL7v2 parsing, bulk export handlers |
| Schema Registry | Central repository of approved data schemas | FHIR profiles, OMOP CDM table schemas, US Core conformance |
| Observability | Monitoring pipeline health and data freshness | SLA breach alerts, OpenTelemetry traces for data lineage |
4. Federated Computational Governance
Healthcare cannot have ungoverned data — HIPAA, state privacy laws, and accreditation requirements demand enterprise-wide controls. Data mesh solves this with federated governance: enterprise standards that all domains must follow, combined with domain-level autonomy for implementation details.
# federated-governance-policy.yaml
# Enterprise-wide standards (mandatory for all domains)
enterprise_standards:
data_format:
clinical: "FHIR R4 or OMOP CDM v5.4"
financial: "X12 EDI or custom with documented schema"
interoperability: "All data products must expose FHIR-compatible APIs"
phi_classification:
levels:
- restricted: "Direct identifiers (name, SSN, MRN)"
- sensitive: "Quasi-identifiers (DOB, ZIP, dates of service)"
- de-identified: "Safe harbor or expert determination applied"
default: "restricted" # assume PHI until classified
retention:
minimum: "6 years (HIPAA)"
medical_records: "10 years (state-dependent, check local law)"
minors: "until age 21 + retention period"
automated_purging: true
access_control:
authentication: "SSO via enterprise IdP (SAML/OIDC)"
authorization: "RBAC + ABAC (attribute-based for PHI)"
audit: "all PHI access logged, 6-year retention"
break_the_glass: "emergency override with mandatory justification"
quality:
minimum_completeness: 0.95
freshness_sla_required: true
validation_on_publish: true
# Domain-specific policies (autonomy within guardrails)
domain_policies:
cardiology:
device_data_handling: "FDA 21 CFR Part 11 compliance"
imaging_format: "DICOM with FHIR ImagingStudy wrapper"
laboratory:
critical_values: "immediate notification pipeline required"
reference_ranges: "age/sex stratified, updated quarterly"
pharmacy:
controlled_substances: "DEA Schedule II-V tracking"
formulary: "updated within 24h of P&T committee decisions"
revenue_cycle:
payer_rules: "payer-specific validation before submission"
coding_standards: "ICD-10-CM/PCS current year, CPT updated annually"
Healthcare Domain Examples: What Data Products Look Like
Cardiology Domain Data Products
The cardiology data team publishes four core data products that downstream consumers (population health, quality reporting, research) depend on:
# cardiology_data_products.py
# Domain: Cardiology | Owner: Cardiac Data Engineering Team
CARDIOLOGY_DATA_PRODUCTS = {
"echo_results": {
"name": "Echocardiogram Results",
"description": "Structured echo findings including LVEF, "
"wall motion, valve assessments, and measurements",
"schema": "FHIR DiagnosticReport + Observation components",
"freshness_sla": "within 2 hours of final read",
"quality_metrics": {
"completeness": 0.98, # 98% of echo reports have structured LVEF
"coding": "LOINC for all measurement types",
"validation": "LVEF 10-80%, chamber dimensions within physiologic range"
},
"access": {
"clinician": "full",
"researcher": "de-identified, IRB approval required",
"quality_team": "aggregate metrics only"
},
"consumers": [
"Heart Failure Registry",
"Quality Reporting (CMS Star Ratings)",
"Population Health Dashboard",
"Surgical Planning Team"
],
"update_frequency": "streaming (real-time from echo PACS)",
"storage": "Delta Lake bronze -> silver -> gold"
},
"cardiac_risk_scores": {
"name": "Cardiac Risk Score Calculations",
"description": "Pre-computed risk scores: ASCVD 10-year risk, "
"CHA2DS2-VASc (stroke risk in AF), HEART score (ACS)",
"schema": "FHIR RiskAssessment resources",
"freshness_sla": "recalculated daily at 02:00 UTC",
"quality_metrics": {
"completeness": 0.92, # 92% of eligible patients have current scores
"validation": "scores within published ranges, input completeness check"
},
"consumers": [
"CDS Hooks (real-time alerts)",
"Population Health Stratification",
"Value-Based Care Risk Adjustment"
]
},
"cath_lab_reports": {
"name": "Catheterization Lab Procedure Reports",
"description": "Structured cath lab data: coronary anatomy, "
"interventions, hemodynamics, complications",
"schema": "FHIR Procedure + Observation",
"freshness_sla": "within 4 hours of procedure completion",
"quality_metrics": {
"completeness": 0.99,
"coding": "CPT for procedures, SNOMED for findings"
}
},
"device_telemetry": {
"name": "Cardiac Device Remote Monitoring",
"description": "Pacemaker and ICD remote monitoring data: "
"device checks, arrhythmia episodes, lead measurements",
"schema": "FHIR DeviceMetric + Observation",
"freshness_sla": "daily batch from device vendor APIs",
"regulatory": "FDA 21 CFR Part 11 compliant storage"
}
}Laboratory Domain Data Products
# laboratory_data_products.py
# Domain: Laboratory | Owner: Lab Informatics Team
LABORATORY_DATA_PRODUCTS = {
"lab_results": {
"name": "Validated Lab Results",
"description": "All validated lab results with LOINC coding, "
"reference ranges, and interpretive flags",
"schema": "FHIR Observation (laboratory category)",
"freshness_sla": "within 15 minutes of LIS validation",
"quality_metrics": {
"loinc_coverage": 0.995, # 99.5% LOINC coded
"completeness": 0.99, # 99% have reference ranges
"units_standardized": True # UCUM units throughout
},
"critical_value_pipeline": {
"enabled": True,
"notification_sla": "< 5 minutes from result to alert",
"channels": ["EHR inbox", "pager", "SMS"],
"escalation": "if unacknowledged in 30 min, page supervisor"
},
"consumers": [
"Clinical Decision Support",
"Population Health Analytics",
"Quality Measures (HEDIS)",
"Research Data Warehouse (OMOP measurement table)"
]
},
"trending_analytics": {
"name": "Lab Result Trends and Analytics",
"description": "Pre-computed trends: 90-day moving averages, "
"rate of change, predicted next value for chronic patients",
"schema": "Custom analytics schema with FHIR Observation references",
"freshness_sla": "recalculated within 1 hour of new result",
"consumers": [
"Chronic Disease Management Dashboard",
"Physician mobile app trend views"
]
}
}
Data Product Contract Template
Every data product must be published with a machine-readable contract. This contract serves as the interface between the producing domain and its consumers:
# data-product-contract.yaml
# Template for healthcare data product registration
apiVersion: datamesh.healthcare.io/v1
kind: DataProduct
metadata:
name: lab-results-validated
domain: laboratory
owner: lab-informatics-team
version: "2.3.0"
last_updated: "2026-03-16"
spec:
description: >
Validated laboratory results from all hospital lab instruments.
LOINC-coded with UCUM units and age/sex-stratified reference ranges.
schema:
format: "FHIR R4 Observation"
profile: "http://hl7.org/fhir/us/core/StructureDefinition/us-core-observation-lab"
storage: "Delta Lake (gold layer)"
location: "s3://health-data-lake/gold/lab/results/"
quality:
freshness:
sla: "15 minutes from LIS validation"
measurement: "max(current_time - observation.effectiveDateTime)"
alert_threshold: "30 minutes"
completeness:
target: 0.995
critical_fields:
- "code.coding[0].code" # LOINC code
- "valueQuantity.value" # result value
- "valueQuantity.unit" # UCUM unit
- "referenceRange" # normal range
accuracy:
validation_rules:
- "valueQuantity.value within 5 SD of population mean"
- "effectiveDateTime not in future"
- "status in (final, amended, corrected)"
access:
classification: "PHI - Restricted"
roles:
treating_clinician:
access: "full"
filter: "patient in care_team"
researcher:
access: "de-identified"
requires: "IRB approval + DUA"
quality_analyst:
access: "aggregate"
minimum_cell_size: 11
billing:
access: "CPT + diagnosis codes only"
sla:
availability: "99.9%"
latency_p99: "< 200ms for single patient query"
throughput: "10,000 records/second for bulk export"
dependencies:
upstream:
- "lis-raw-results (bronze layer)"
- "omop-vocabulary (concept mapping)"
downstream:
- "population-health-dashboard"
- "clinical-decision-support"
- "research-data-warehouse"
compliance:
hipaa: true
retention: "10 years (state requirement)"
audit_logging: true
encryption: "AES-256 at rest, TLS 1.3 in transit"
Technical Implementation: Self-Serve Data Platform
Platform Architecture
# platform-infrastructure.yaml
# Self-serve data platform for healthcare data mesh
# Deployed via Terraform + Kubernetes
platform_services:
data_catalog:
tool: "DataHub (open-source) or Unity Catalog"
features:
- schema_discovery: "auto-crawl Delta Lake, FHIR server"
- lineage_tracking: "end-to-end from source EHR to dashboard"
- phi_tagging: "automated PII/PHI detection and classification"
- search: "natural language search across all data products"
- quality_scores: "data product health scores visible to consumers"
quality_framework:
tool: "Great Expectations + custom healthcare validators"
checks:
standard:
- "schema conformance (FHIR profile validation)"
- "completeness (critical field null rates)"
- "freshness (time since last update vs SLA)"
- "volume anomaly (sudden drops/spikes in record count)"
clinical:
- "vital signs within physiologic range"
- "lab values within instrument reportable range"
- "medication doses within FDA-approved range"
- "age at event consistent with demographics"
access_control:
tool: "Apache Ranger or Immuta"
policies:
- type: "RBAC"
description: "role-based access by job function"
- type: "ABAC"
description: "attribute-based for PHI (department, care team)"
- type: "dynamic_masking"
description: "SSN, DOB, name masked for non-clinical users"
- type: "row_level_security"
description: "researchers see only consented patients"
pipeline_templates:
available:
- "fhir-ingestion"
- "hl7v2-to-fhir"
- "edi-claims-processing"
- "device-telemetry-streaming"
- "bulk-fhir-export"
standard_stages:
- "bronze: raw ingestion (immutable)"
- "silver: cleaned, validated, PHI-tagged"
- "gold: business-ready data products"
Implementing Data Product Discovery
# data_product_registry.py
# Central registry for data mesh data products
# Consumed by the data catalog UI
from dataclasses import dataclass, field
from typing import Optional
from datetime import datetime
import json
@dataclass
class QualitySLA:
freshness_minutes: int
completeness_target: float
last_measured: Optional[datetime] = None
current_freshness_minutes: Optional[float] = None
current_completeness: Optional[float] = None
@property
def freshness_healthy(self) -> bool:
if self.current_freshness_minutes is None:
return False
return self.current_freshness_minutes <= self.freshness_minutes
@property
def completeness_healthy(self) -> bool:
if self.current_completeness is None:
return False
return self.current_completeness >= self.completeness_target
@dataclass
class DataProduct:
name: str
domain: str
owner_team: str
description: str
schema_format: str
storage_location: str
quality_sla: QualitySLA
phi_classification: str # restricted, sensitive, de-identified
consumer_count: int = 0
version: str = "1.0.0"
tags: list = field(default_factory=list)
@property
def health_score(self) -> float:
"""Calculate overall health score (0-100)."""
score = 0
if self.quality_sla.freshness_healthy:
score += 40
if self.quality_sla.completeness_healthy:
score += 40
if self.consumer_count > 0:
score += 10
if self.version != "1.0.0":
score += 10 # mature product
return score
# Example: Register lab results data product
lab_results = DataProduct(
name="lab-results-validated",
domain="laboratory",
owner_team="Lab Informatics",
description="Validated lab results with LOINC coding and reference ranges",
schema_format="FHIR R4 Observation (US Core Lab Profile)",
storage_location="s3://data-lake/gold/lab/results/",
quality_sla=QualitySLA(
freshness_minutes=15,
completeness_target=0.995,
current_freshness_minutes=8.2,
current_completeness=0.997,
last_measured=datetime(2026, 3, 16, 10, 0)
),
phi_classification="restricted",
consumer_count=12,
version="2.3.0",
tags=["clinical", "lab", "loinc", "fhir"]
)
print(f"Health Score: {lab_results.health_score}/100")
# Output: Health Score: 100/100
Organizational Change: The Hardest Part
Team Structure
Data mesh requires organizational change, not just technology. Each domain needs a small, embedded data team:
| Role | Responsibility | Reports To |
|---|---|---|
| Domain Data Product Owner | Defines data product roadmap, SLAs, and priorities | Domain clinical/operational leader |
| Domain Data Engineer (1-2) | Builds and maintains domain pipelines on shared platform | Domain Data Product Owner |
| Domain Analyst | Understands clinical context, validates data quality | Domain Data Product Owner |
| Platform Engineer (shared) | Maintains shared infrastructure, tools, templates | Platform team lead (centralized) |
The platform team remains centralized but serves domains rather than controlling them. Their success metric is domain team productivity, not the number of pipelines they build themselves. This is a critical mindset shift from traditional centralized data architectures.
Common Resistance and How to Address It
| Objection | Reality | Mitigation |
|---|---|---|
| "We do not have data engineers in clinical departments" | You are already managing data — just informally and poorly | Embed 1-2 platform-trained engineers in each domain; they learn clinical context on the job |
| "HIPAA requires centralized control" | HIPAA requires accountability and safeguards, not centralization | Federated governance enforces HIPAA uniformly; each domain has a designated privacy officer |
| "Our EHR vendor handles data" | EHR data extracts are raw materials, not data products | Domain teams add clinical context, quality SLAs, and documentation that vendors cannot |
| "Too expensive for our size" | Start with 1-2 domains, prove value, then expand | Pilot with the domain that has the most data requests (usually lab or revenue cycle) |
Implementation Roadmap

Phase 1: Foundation (Months 1-3)
- Identify 4-6 clinical domains and their data assets
- Establish federated governance council (CIO, CISO, CMIO, domain leaders)
- Select and deploy self-serve platform (data catalog, quality framework)
- Define enterprise standards: data formats, PHI classification, retention
- Choose pilot domain (recommendation: Laboratory — highest data volume, clearest ownership)
Phase 2: Pilot Domain (Months 4-6)
- Embed 2 data engineers in pilot domain
- Publish first 2-3 data products (e.g., Lab Results, Critical Values, Trending)
- Register in data catalog with full contracts
- Onboard 3-5 initial consumers (population health, quality reporting, research)
- Measure: time-to-data-access before vs. after
Phase 3: Scale (Months 7-12)
- Expand to 3-4 domains (add Cardiology, Pharmacy, Revenue Cycle)
- Deploy shared quality monitoring and SLA dashboards
- Implement cross-domain data products (e.g., patient journey combining lab + cardiology + pharmacy)
- Establish data product lifecycle management (versioning, deprecation, migration)
Phase 4: Maturity (Year 2+)
- All major domains publishing data products
- Self-serve consumption: new data requests fulfilled in days, not months
- Cross-domain analytics: population health, value-based care, research
- Data marketplace: internal teams can browse, evaluate, and subscribe to data products
- Automated compliance: PHI masking, retention, and audit applied by platform
Data Mesh vs. Other Architectures for Healthcare
| Architecture | Best For | Weakness in Healthcare |
|---|---|---|
| Centralized Data Warehouse | Small health systems, single-hospital | Bottleneck at scale; central team lacks clinical domain expertise |
| Data Lake | Raw data storage, ML experimentation | Becomes a "data swamp" without governance; no ownership accountability |
| Data Lakehouse | Unified batch + streaming analytics | Still centrally managed; does not solve ownership problem |
| Data Mesh | Multi-hospital systems, complex organizations | Requires organizational change; overkill for small practices |
| Hybrid (Lakehouse + Mesh) | Best of both: shared infrastructure + domain ownership | Most complex to implement; requires mature platform team |
For most multi-hospital health systems, we recommend a hybrid approach: build a data lakehouse as the shared infrastructure platform, then overlay data mesh principles for domain ownership and governance.
Frequently Asked Questions
Is data mesh appropriate for a single hospital?
Probably not in full form. Data mesh shines in multi-hospital systems with distinct clinical departments that each generate significant data volumes. A single community hospital with 200 beds likely benefits more from a well-managed centralized lakehouse. However, even single hospitals can adopt the "data as a product" mindset — publishing documented, quality-monitored datasets from each department — without the full organizational restructuring.
How does data mesh handle cross-domain queries?
Cross-domain analytics are enabled through shared infrastructure. When a population health analyst needs data from cardiology, lab, and pharmacy simultaneously, they query each domain's published data products through the shared data catalog. The platform handles federation — joining data across domains while respecting each domain's access controls. Some organizations create explicit "cross-domain data products" owned by the analytics team that combine upstream domain products.
Does data mesh conflict with HIPAA?
No. HIPAA requires safeguards, accountability, and minimum necessary access — data mesh actually improves all three. Domain ownership creates clear accountability (the lab team is responsible for lab PHI). Federated governance enforces uniform HIPAA policies. Data product contracts with explicit access controls implement minimum necessary. The key is that the federated governance layer must enforce enterprise-wide HIPAA standards that no domain can override.
What is the minimum team size to start data mesh?
You need at least: 2-3 platform engineers (to build shared infrastructure), 1-2 data engineers per pilot domain, and executive sponsorship from the CIO or CMIO. Total: approximately 6-8 people for a pilot with one domain. This is not significantly more than what most health systems already have in their analytics team — the difference is organizational placement and accountability, not headcount.
How do we handle real-time vs. batch data products?
Data products can be either streaming (real-time) or batch — the contract makes the freshness SLA explicit. Lab critical values might have a 5-minute SLA (streaming via Kafka or FHIR Subscriptions), while cardiac risk scores might recalculate daily (batch). The self-serve platform should support both patterns through pipeline templates, so domain teams choose the right approach for each product without building infrastructure from scratch.