If you have ever tried to read the openEHR specification, you probably closed the tab within 10 minutes. The official docs are written for standards committees, not developers. This guide strips away the jargon and explains openEHR the way you would explain it to a senior engineer joining your team on day one.
By the end of this post, you will understand exactly what openEHR is, why it exists, how its architecture works, and when to use it instead of (or alongside) FHIR.
What Is openEHR and Why Should You Care?
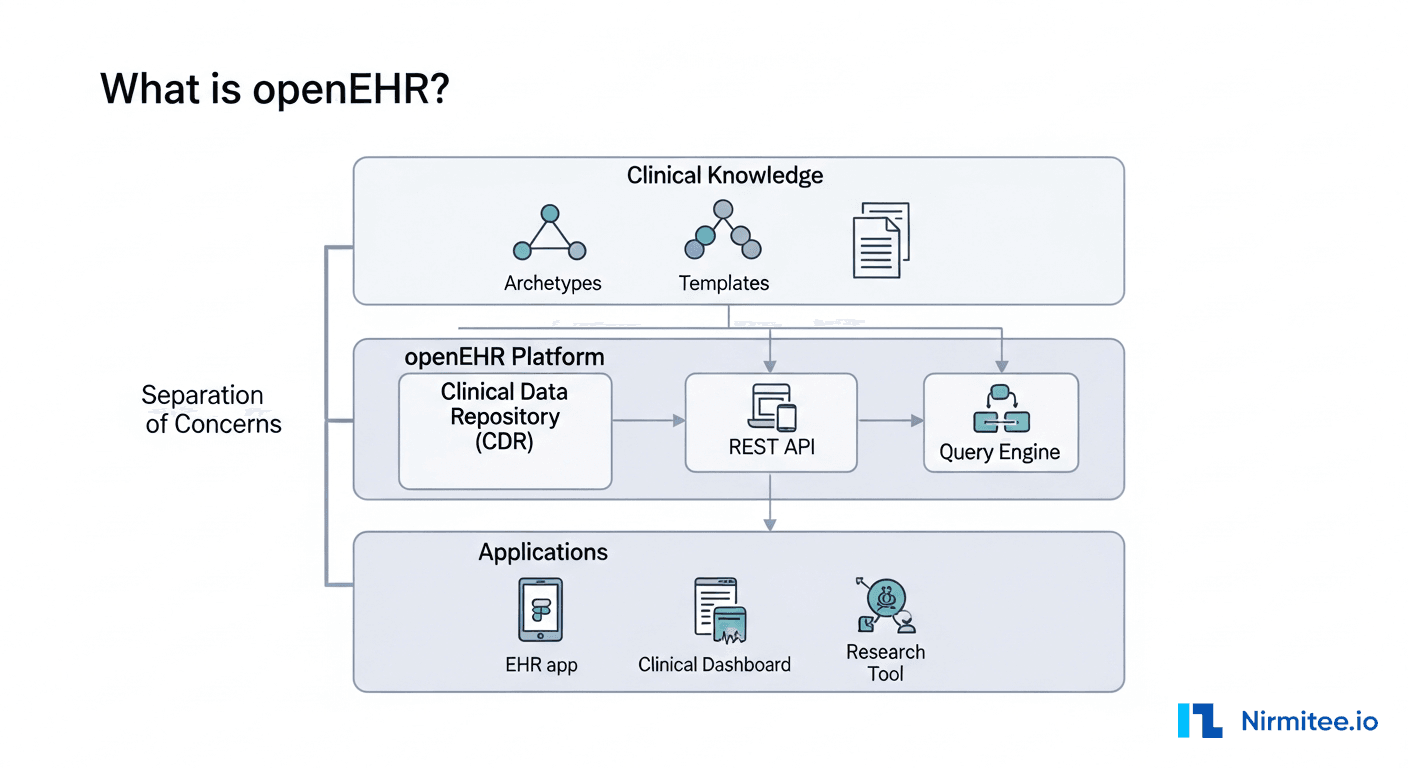
openEHR is an open standard for building clinical data repositories (CDRs) that store health records in a way that survives software changes. The core idea is radical: separate the clinical knowledge from the software that stores it.
In a traditional EHR, if a hospital wants to add a new field like "patient-reported pain score," a developer has to modify the database schema, update the API, change the frontend, test everything, and deploy. In an openEHR system, a clinical informaticist adds a new archetype (a reusable clinical model), updates the template, and the CDR accepts the new data structure without any code changes. The platform adapts to clinical requirements, not the other way around.
This matters because healthcare data models change constantly. New lab tests, new clinical guidelines, new regulatory requirements, new research protocols. If your system requires a code deployment every time the clinical model changes, you are building technical debt faster than you can ship features.
The Big Idea: Two-Level Modelling
Everything in openEHR flows from one architectural decision: two-level modelling. This is the single concept you must understand. Everything else follows from it.
- Level 1 — Reference Model (RM): A small, stable set of data structures that your software is built against. Think of it as the "physics engine" of your system. It defines generic containers like Composition, Section, Entry, Element, and DataValue. Developers build software against this level. It almost never changes.
- Level 2 — Archetypes and Templates: Clinical knowledge definitions that constrain the Reference Model into specific clinical concepts. A "Blood Pressure" archetype says: "An Entry must have a systolic value (mmHg), a diastolic value (mmHg), a patient position, and a device used." Clinicians and informaticists manage this level. It changes frequently and that is fine — no code deployment needed.
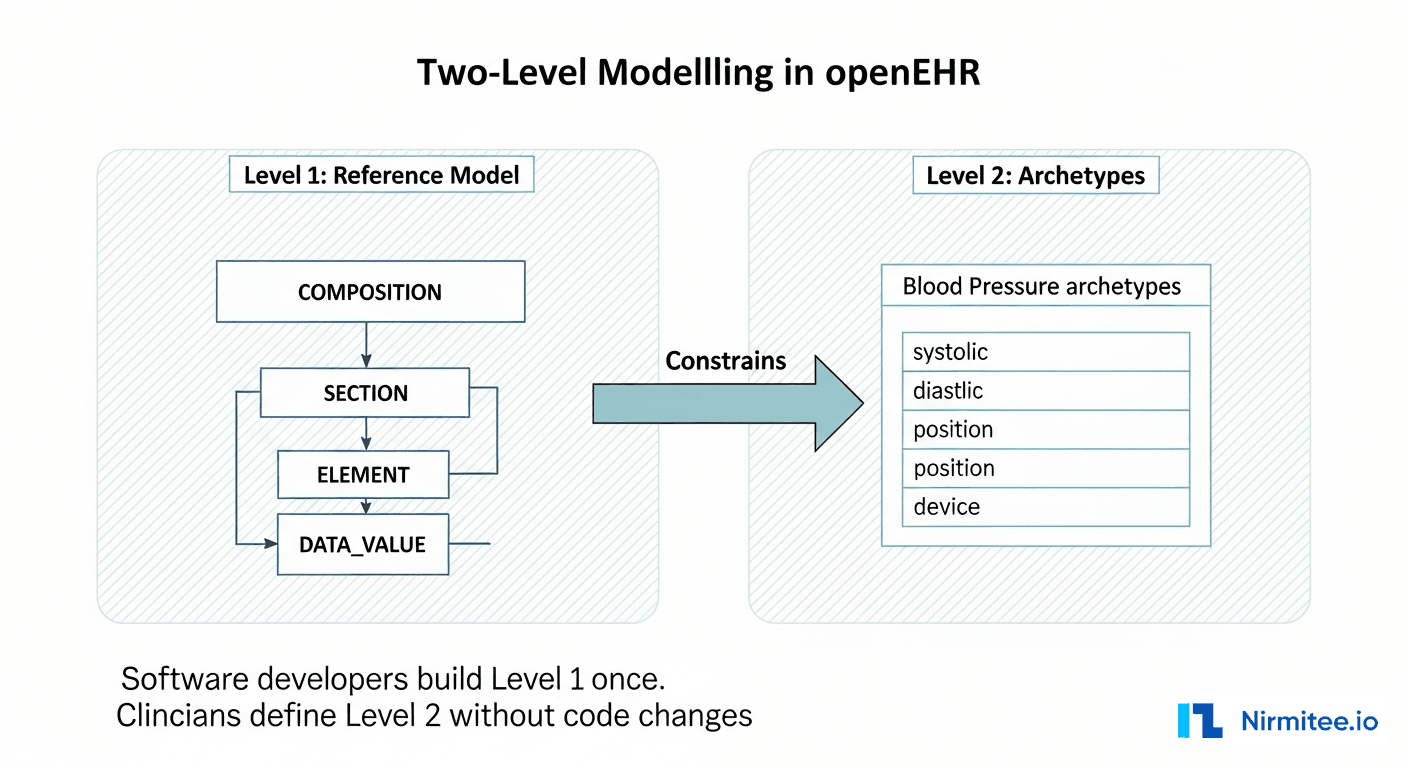
This separation is why openEHR systems can adapt to new clinical requirements without rebuilding the application. The software only knows about Level 1. The clinical models at Level 2 are loaded at runtime.
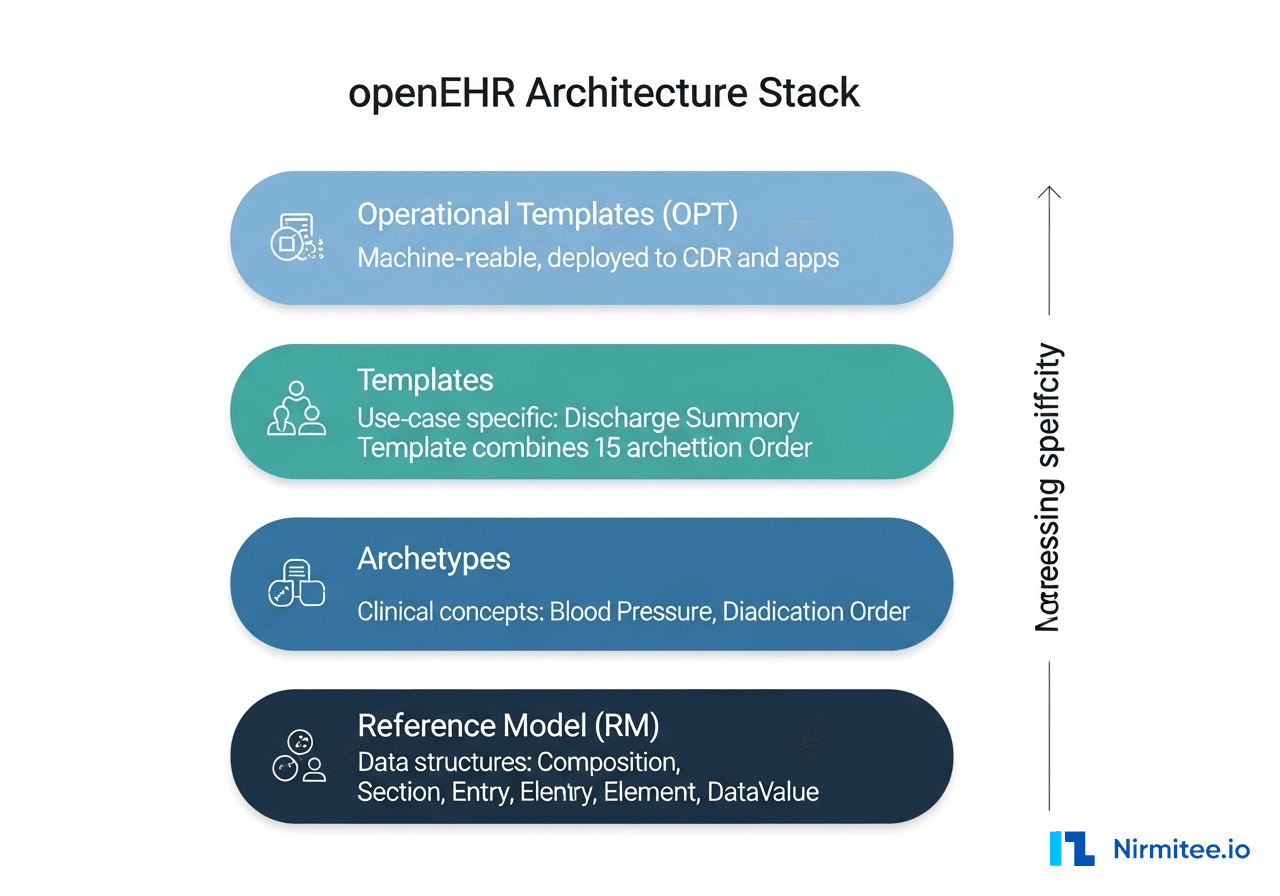
The Architecture Stack: RM, Archetypes, Templates, OPT
The openEHR architecture has four layers. Each layer builds on the one below it, adding more clinical specificity:
- Reference Model (RM) — The foundation. Defines generic data structures: Composition (a clinical document), Section (a grouping), Entry (a clinical statement — Observation, Evaluation, Instruction, Action), Element (a single data point), and DataValue (the actual value — quantity, text, coded term, date). Your software is compiled against the RM. It is stable across openEHR versions.
- Archetypes — Reusable clinical concept definitions written in ADL (Archetype Definition Language). Each archetype constrains the RM for one clinical concept. Examples:
openEHR-EHR-OBSERVATION.blood_pressure.v2,openEHR-EHR-EVALUATION.problem_diagnosis.v1. Published on the international Clinical Knowledge Manager (CKM) atckm.openehr.org. Over 600 peer-reviewed archetypes are available. - Templates — Use-case specific combinations of archetypes. A "Discharge Summary" template might combine 15 archetypes: diagnoses, medications, procedures, vital signs, care plan. Templates are what you actually deploy. They define exactly which archetypes, which fields, and which terminology bindings apply for a specific clinical form or document.
- Operational Templates (OPT) — The machine-readable, flattened version of a template. When you deploy a template to your CDR, it gets compiled into an OPT. The CDR uses the OPT to validate incoming data, generate forms, and build query paths.
How Clinical Data Actually Flows Through an openEHR System
Here is the concrete sequence of what happens when a nurse records a blood pressure reading:
- Clinician enters data via a form generated from the template. The form knows which fields are required, what units are valid, and what coded terms are acceptable.
- Template validates the input against archetype constraints. Systolic must be a quantity in mmHg, between 0 and 1000. Position must be one of: sitting, standing, lying, reclining.
- A Composition is created — a structured RM instance containing the validated data. This is the canonical storage format. It is a tree structure: Composition, Section, Observation, Element, DataValue.
- The CDR stores the Composition with full versioning. Every change creates a new version. The previous version is never deleted. The audit trail records who changed what, when, and why.
- Any application can query the data using AQL (Archetype Query Language). The query uses archetype paths, not table or column names. This means you can query "all blood pressure readings where systolic > 140" across every application that ever stored blood pressure data, regardless of which template or form was used.
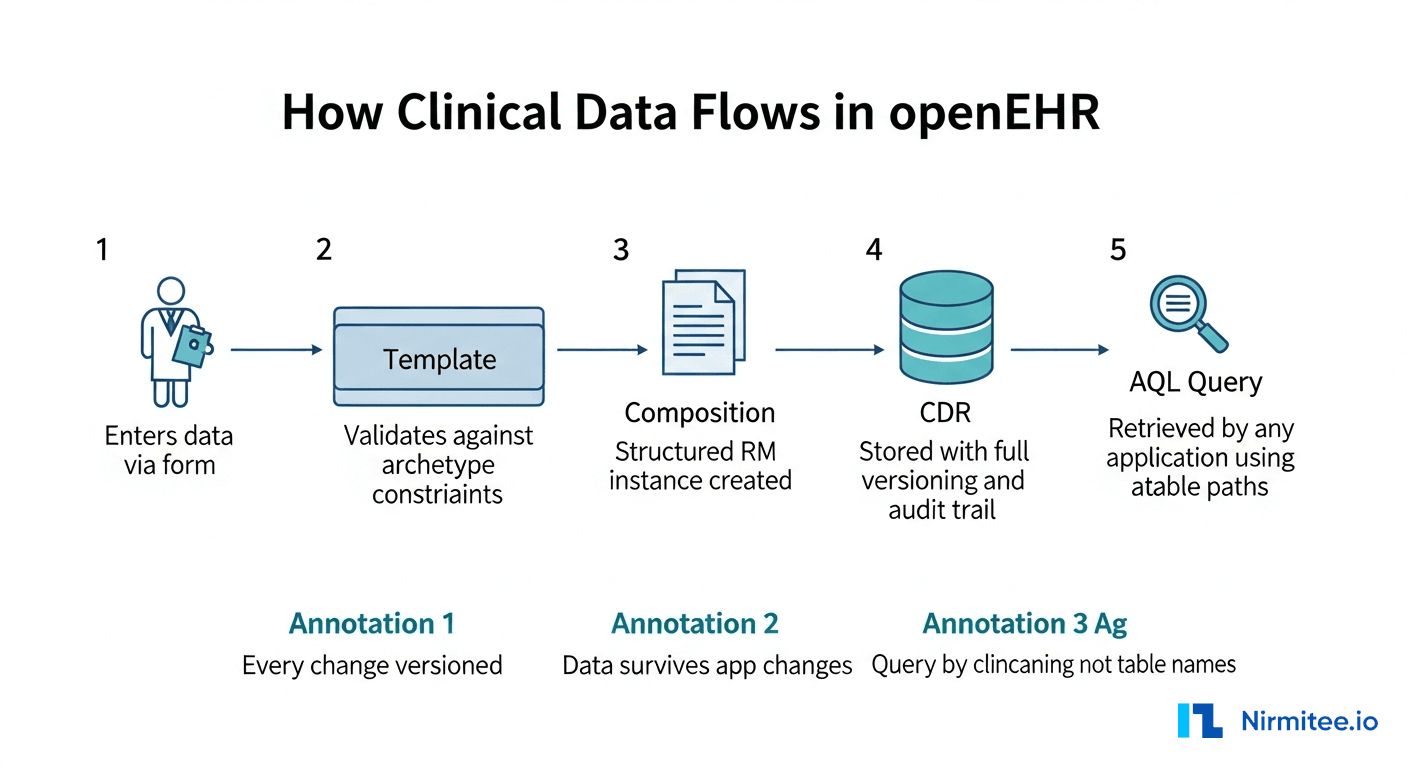
The critical insight: the data outlives the application. If you replace your frontend, rebuild your forms, or switch your entire application stack, every piece of clinical data ever stored remains queryable because it conforms to the Reference Model and is indexed by archetype paths.
openEHR vs FHIR: They Solve Different Problems
This is the question every healthcare developer asks. The answer is simple once you understand what each standard optimizes for:
- openEHR is optimized for storing clinical data. It gives you a maximal, highly detailed data model with full versioning, provenance, and clinical query capability. It is the system of record.
- FHIR is optimized for exchanging clinical data. It gives you a minimal, 80%-coverage data model with a REST API and a massive ecosystem of apps and tools. It is the integration layer.
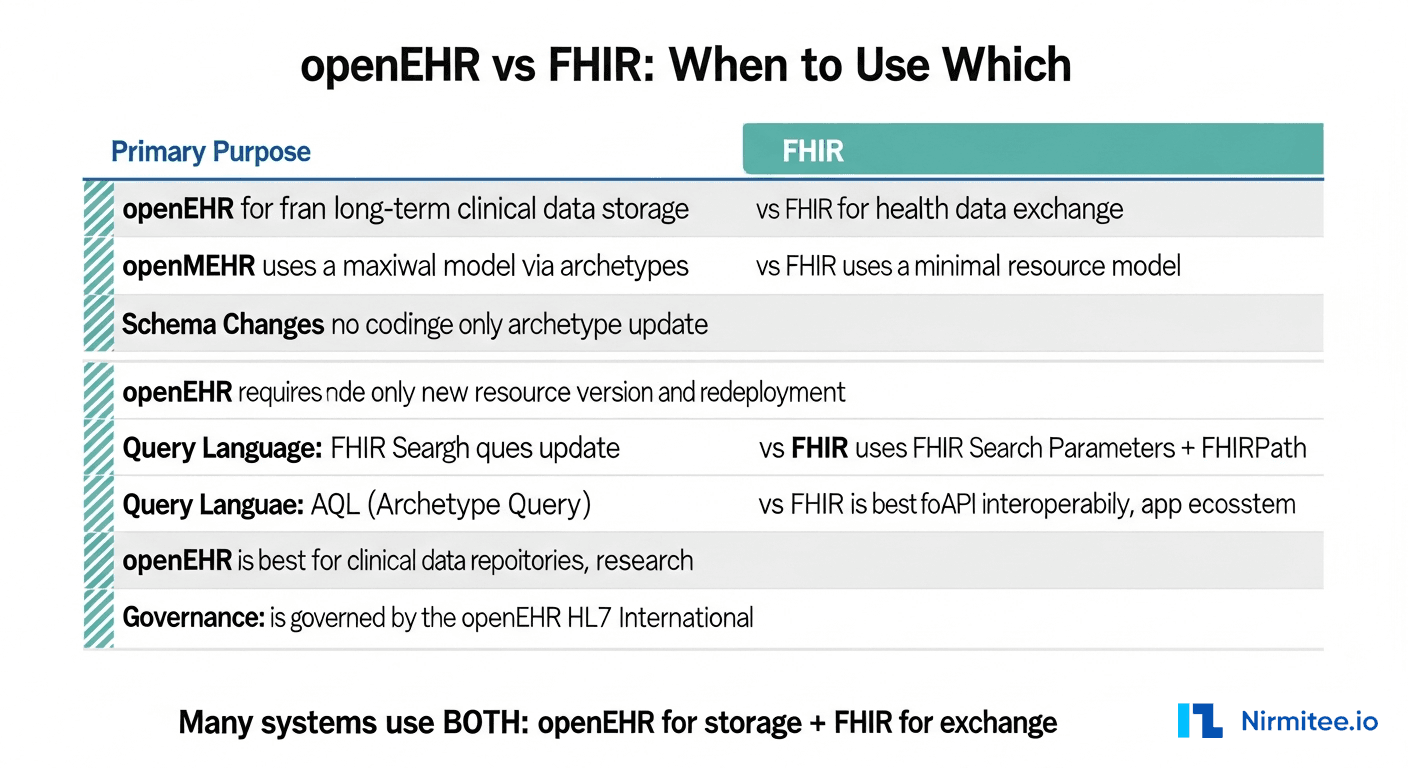
In practice, many production systems use both. The openEHR CDR is the clinical data repository where data lives permanently. FHIR APIs expose that data to external systems, patient apps, and third-party integrations. The CDR stores data in openEHR format and serves it out as FHIR resources on request.
Key differences in practice:
- Schema evolution: openEHR handles new clinical concepts without code changes. FHIR requires new resource profiles and often new API endpoints.
- Query power: AQL can query across all clinical data by archetype path. FHIR Search is limited to predefined search parameters per resource type.
- Versioning: openEHR versions every composition change with full audit trail. FHIR versioning is optional and implementation-dependent.
- Ecosystem: FHIR has a much larger app ecosystem, more developer tools, and wider adoption in the US market. openEHR dominates in Europe, Australia, and government-backed national health programs.
When to Choose openEHR
Use openEHR when your primary requirement is one or more of:
- Long-term clinical data storage — patient records that must remain queryable for 50+ years across multiple system generations.
- Rapidly changing clinical models — research institutions, clinical trials, or health systems that frequently add new data types.
- Clinical query requirements — population health analytics, clinical decision support, or research that needs to query across all stored clinical data by meaning, not by table structure.
- Regulatory environments that mandate structured, auditable clinical records — EU, Australia, Norway, Brazil, India (ABDM is evaluating openEHR components).
- Multi-vendor environments where clinical data must be shared across different EHR systems without lock-in to a single vendor data model.
Getting Started: The Practical Path
If you want to build with openEHR today, here is the concrete path:
- Pick a CDR: EHRbase (open source, Java), Better Platform (commercial, enterprise), or Ocean Health Systems (commercial, mature).
- Browse existing archetypes on the Clinical Knowledge Manager. Do not create new archetypes if one already exists.
- Build a template using the Archetype Designer tool at
tools.openehr.org. Combine the archetypes you need for your use case. - Upload the OPT to your CDR and start posting Compositions via the openEHR REST API.
- Query with AQL. Example:
SELECT o/data[at0001]/events[at0006]/data[at0003]/items[at0004]/value FROM EHR e CONTAINS OBSERVATION o[openEHR-EHR-OBSERVATION.blood_pressure.v2] WHERE o/data[at0001]/events[at0006]/data[at0003]/items[at0004]/value/magnitude > 140
The learning curve is real — openEHR has more concepts to internalize than FHIR. But once you understand the architecture, you gain a system that adapts to clinical change without engineering bottlenecks. For healthcare organizations building systems meant to last decades, that trade-off is worth it.