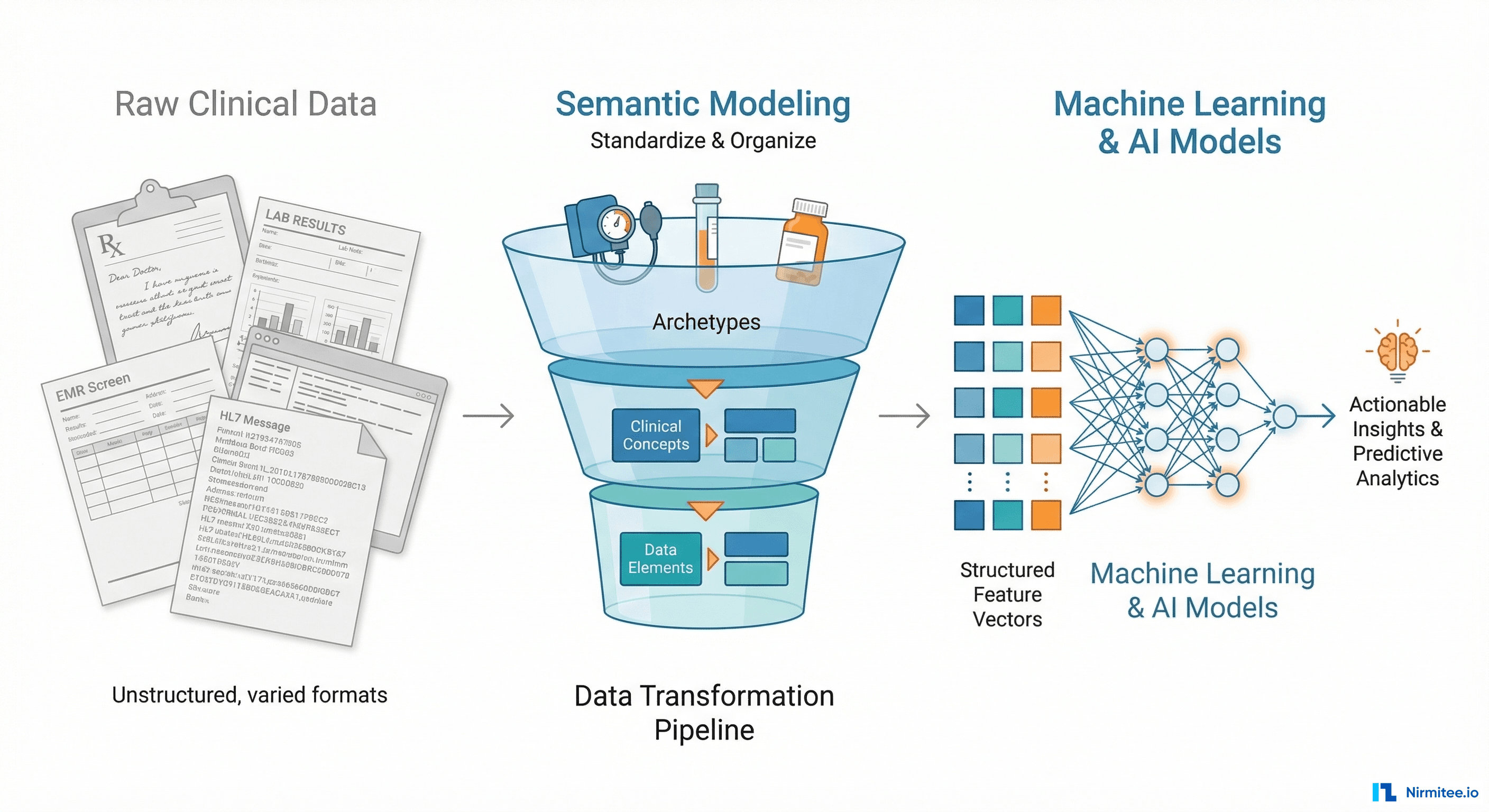
Every week, another headline announces an AI agent that can diagnose diseases, triage patients, or automate clinical documentation. The models are impressive. GPT-4, Med-PaLM, and specialized clinical LLMs score higher than many physicians on medical exams. The technology works.
And yet, the vast majority of hospitals that attempt to deploy AI agents fail — not because the AI is wrong, but because it cannot reach the data it needs or push its outputs where they matter.
This is not an AI problem. It is an integration problem.
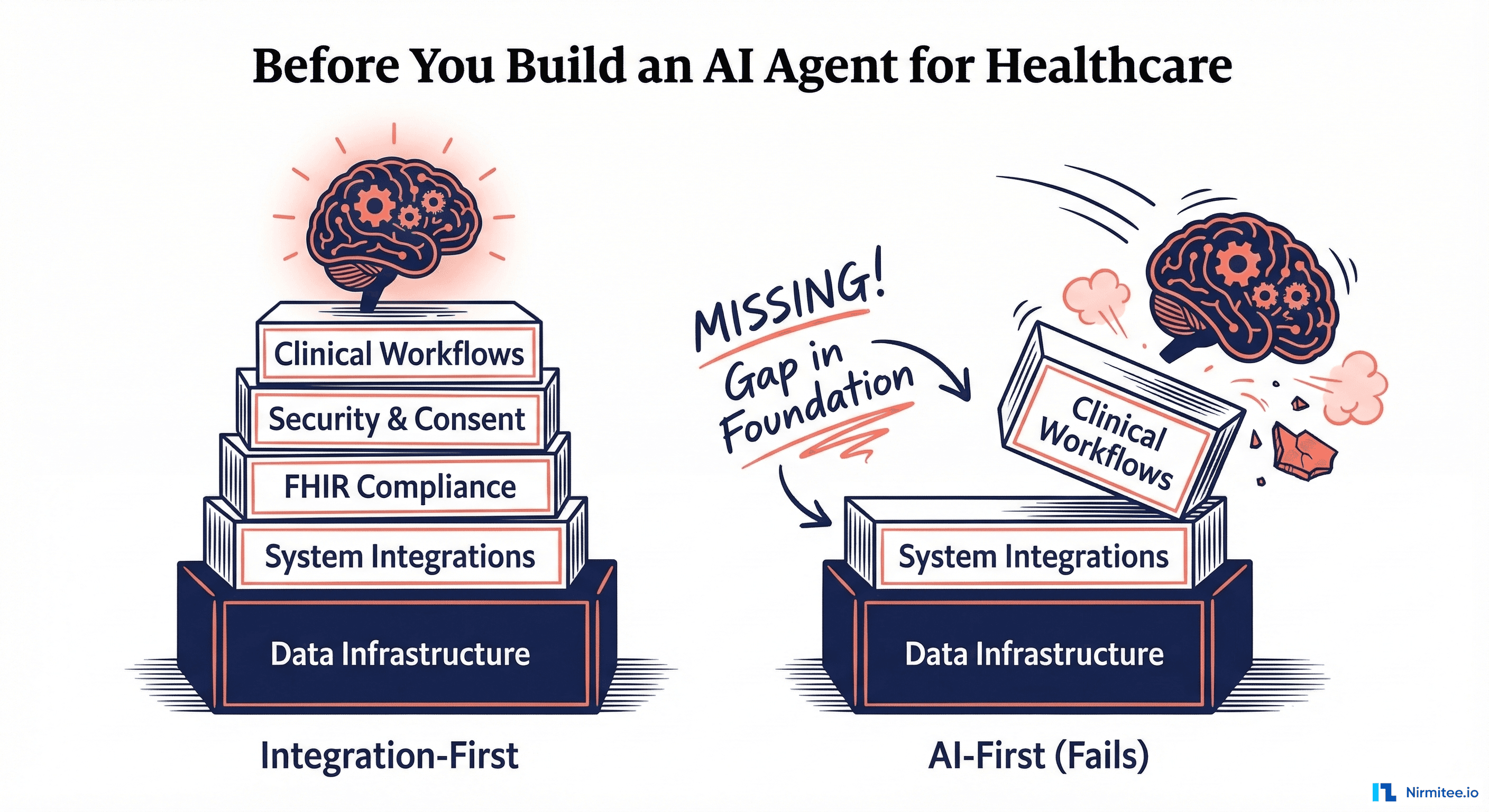
Before writing a single prompt or fine-tuning a single model, there are foundational prerequisites that determine whether an AI agent will be a production system or a demo that never leaves the conference stage. This guide lays them out — specifically, practically, and without the hype.
The Uncomfortable Truth: AI Without Integration Is a Toy
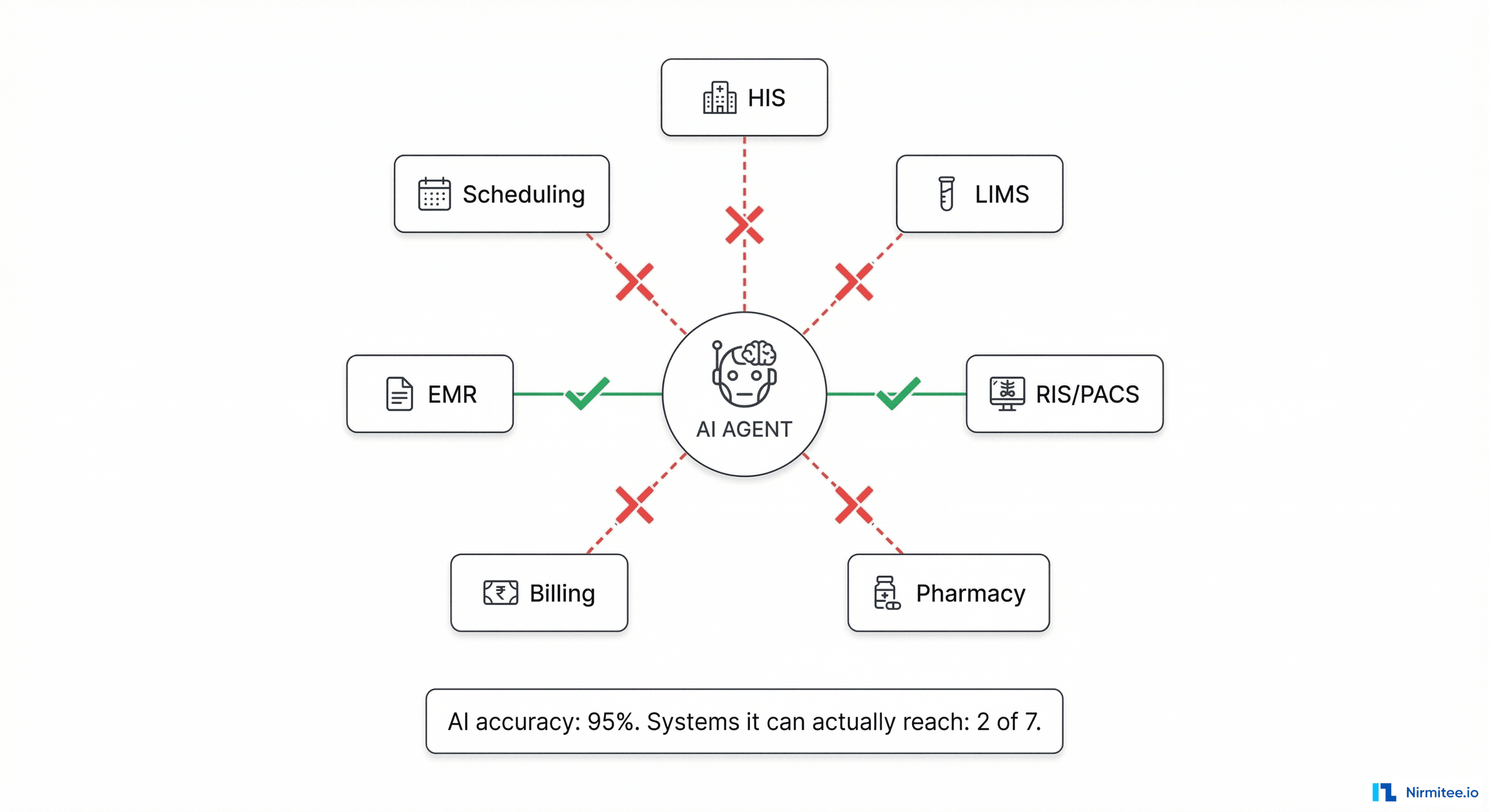
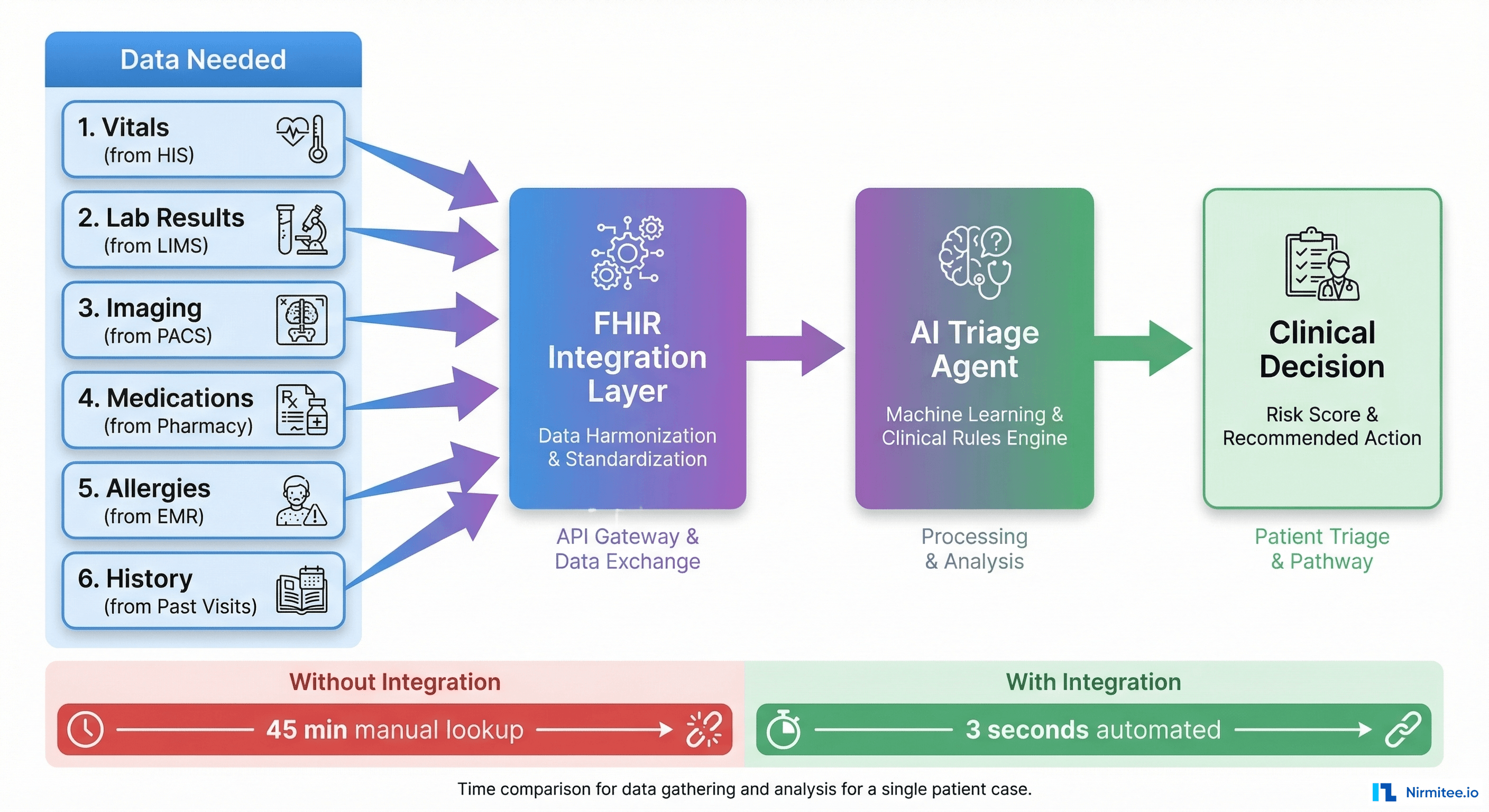
Consider a concrete scenario. You build an AI triage agent for an emergency department. It needs to:
- Read the patient's vitals (from the HIS)
- Check their medication history (from the Pharmacy system)
- Review recent lab results (from the LIMS)
- Look at a recent chest X-ray (from PACS)
- Check allergy records (from the EMR)
- Write the triage decision back into the patient chart (into the HIS)
That is six different systems, each built by a different vendor, each with its own database schema, its own API (or no API at all), its own authentication, and its own data format. Your AI model might have 95% clinical accuracy — but if it can only connect to 2 of those 6 systems, its effective accuracy is zero for the cases where it is missing critical data.
Integration is not a nice-to-have. It is the prerequisite that makes AI useful.
The Prerequisites — Bottom Up, Not Top Down
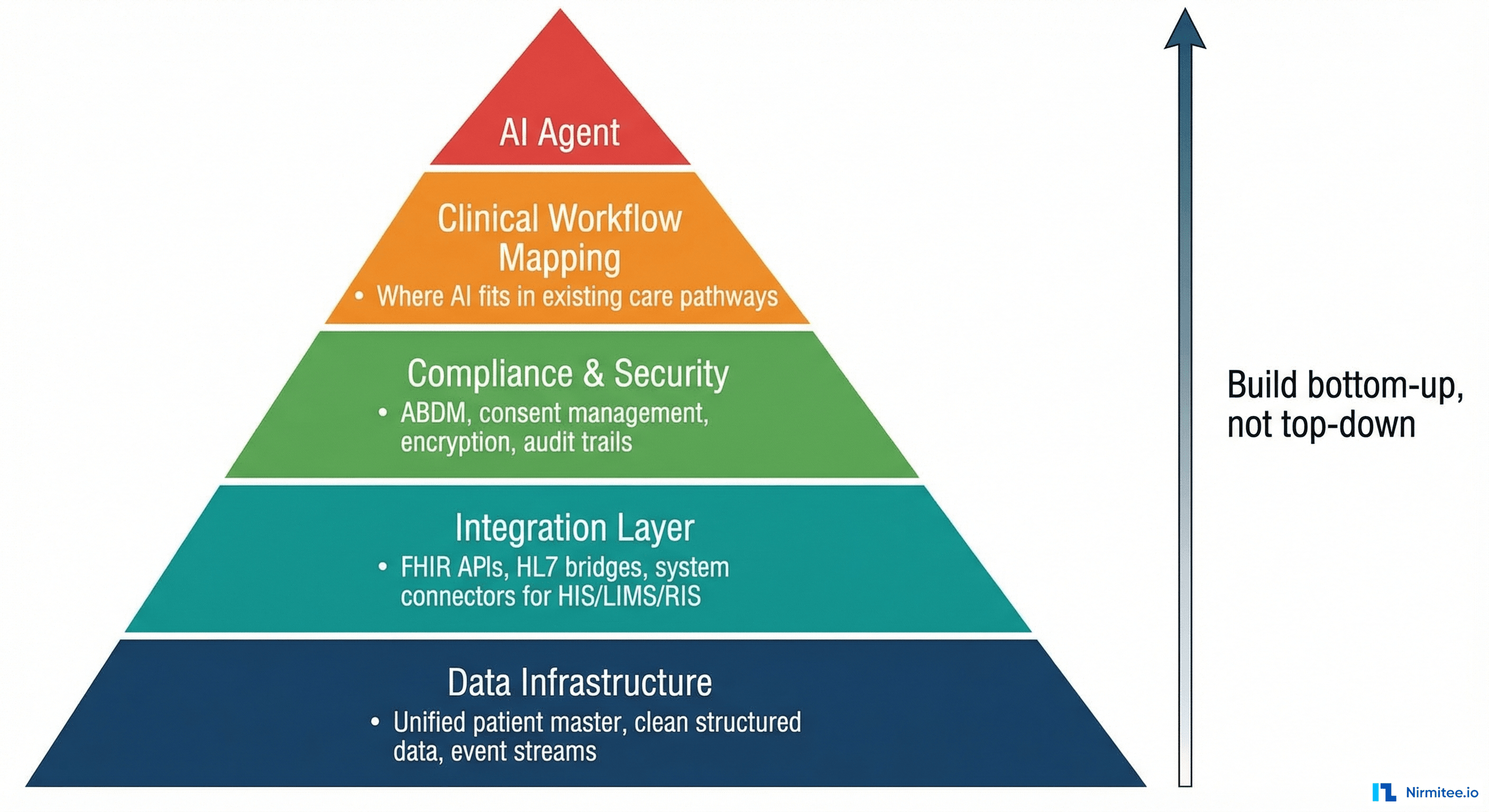
Healthcare AI projects fail when they start at the top (the model) and work down. They succeed when they start at the bottom (the infrastructure) and work up. Here are the layers, in order:
Layer 1: Data Infrastructure — The Foundation
Before any AI can function, you need clean, accessible, structured data. In most hospitals, this does not exist out of the box.
What you need:
| Requirement | Why It Matters | Common Reality |
|---|---|---|
| Unified Patient Master Index | AI must correlate data across systems for the same patient | Patient is MRN-123 in HIS, LAB-456 in LIMS, RAD-789 in RIS — no linking |
| Structured clinical data | AI needs coded diagnoses (ICD-10), coded procedures (CPT/SNOMED), coded medications — not free-text scanned PDFs | 70%+ of hospital data is unstructured notes, scanned documents, handwritten prescriptions |
| Event streams | AI agents must react to events in real-time (new lab result, new admission, vitals breach) | Most HIS systems have no event/webhook mechanism — data sits in batch reports |
| Historical data depth | Clinical AI needs longitudinal patient history, not just today's visit | Systems are replaced every 5-7 years — historical data is often lost or archived in incompatible formats |
The hard truth: If your hospital cannot tell you "give me all lab results for patient X across all departments for the last 3 years in a structured format" within seconds, you are not ready for AI. Fix your data infrastructure first.
Layer 2: Integration Layer — The Connective Tissue
This is the layer where most AI healthcare projects die. Your AI agent needs to read from and write to every clinical system in the hospital. Each of those systems speaks a different language.
The reality of hospital system interfaces:
| System | Typical Interface | Data Format | Integration Difficulty |
|---|---|---|---|
| HIS (Hospital Information System) | Proprietary API or direct DB | Custom SQL schema | High — vendor-locked |
| LIMS (Lab Information System) | HL7v2 messages or CSV exports | HL7 ORU/ORM messages | Medium — standard exists but implementations vary wildly |
| RIS/PACS (Radiology) | DICOM + HL7v2 | DICOM for images, HL7 for reports | High — binary image data + text reports |
| Pharmacy | Proprietary or HL7v2 | Custom or HL7 RDE messages | Medium |
| EMR | REST API (if modern) or none | FHIR (if lucky) or proprietary JSON/XML | Varies — from easy to impossible |
| Billing | Flat files or SOAP | CSV, XML, proprietary | Low clinical relevance but high operational |
| Scheduling | Proprietary | Custom | Usually locked down |
An AI agent cannot navigate this heterogeneity directly. You need an integration middleware — a layer that normalizes all these interfaces into a single, consistent API that the AI can consume.
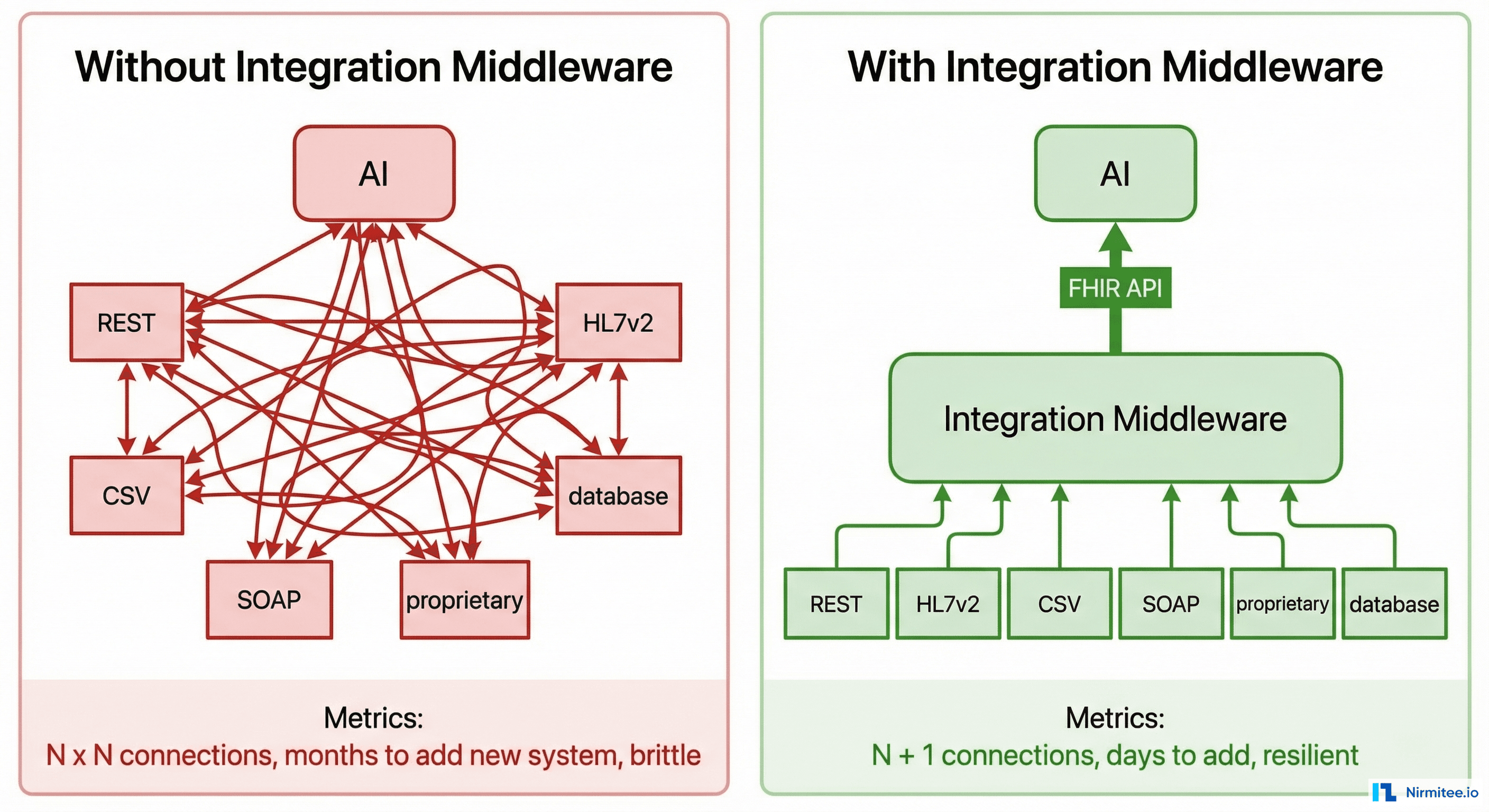
Why FHIR Is the Answer (and Why It Is Not Enough)
HL7 FHIR (Fast Healthcare Interoperability Resources) is the industry standard for healthcare data exchange. It gives you standardized resource types — Patient, Observation, DiagnosticReport, MedicationRequest, ImagingStudy — with consistent JSON structures.
FHIR solves the "lingua franca" problem: Your AI agent speaks FHIR. Your middleware translates each hospital system into FHIR. The AI never needs to know whether the data came from a 20-year-old HL7v2 LIMS or a modern REST-based EMR.
But FHIR alone is not enough because:
- Most hospital systems do not natively speak FHIR. Someone must build the translation layer per system. This is where 80% of the integration work lives
- FHIR profiles vary. India uses NRCeS profiles (National Resource Centre for EHR Standards). The US uses US Core. The data shape differs. Your AI must be trained on the right profile
- FHIR does not solve the write-back problem. Reading data via FHIR is well-defined. Writing AI decisions back into the originating system (posting a triage note back into HIS, updating a medication order) often requires system-specific APIs that FHIR does not cover
Layer 3: Compliance, Security, and Consent
Healthcare data is the most regulated category of personal data. An AI agent that processes patient records must comply with:
| Requirement | What It Means for AI |
|---|---|
| ABDM Compliance (India) | If your AI reads or writes patient health records, those records must flow through ABDM-compliant consent mechanisms. V3 APIs, linking tokens, Fidelius encryption — all apply. The AI does not get a shortcut |
| Patient Consent | An AI agent cannot access a patient's lab results without consent. In ABDM, this means consent artefacts with expiry, purpose, and scope. Your AI must check consent validity before every data access |
| Audit Trails | Every data access by the AI must be logged: what data, which patient, what time, what decision was made. Regulatory audits will ask for this |
| Data Residency | Patient data cannot leave the country (or sometimes the state). If your AI model runs on a US-based cloud API, you have a compliance problem |
| Encryption in Transit and at Rest | All patient data the AI touches must be encrypted. ABDM mandates Fidelius (ECDH) for data exchange. Your local storage must use AES-256 or equivalent |
| De-identification for Training | If you want to fine-tune the AI on hospital data, that data must be de-identified per HIPAA Safe Harbor or Expert Determination methods. Using raw patient data for model training is a legal and ethical violation |
The integration implication: Your middleware is not just a data pipe — it is an enforcement layer. It must check consent before forwarding data to the AI, encrypt all data in transit, log every access, and block requests that violate scope or expiry.
Layer 4: Clinical Workflow Mapping
This is the most underestimated prerequisite. An AI agent does not operate in a vacuum — it must fit into existing clinical workflows used by doctors, nurses, and staff every day.
Critical questions you must answer before building:
- Where in the workflow does the AI act? — Does it provide suggestions before the doctor sees the patient? During the consultation? After, as a second opinion? The answer determines what data is available and what the output format must be
- Who sees the AI output? — A doctor expects a concise clinical summary. A nurse expects actionable alerts. A receptionist expects scheduling recommendations. Same AI, different output rendering
- What happens when the AI is wrong? — Healthcare requires human-in-the-loop. The AI must present its reasoning, allow override, and log the override with the clinician's rationale. This is not optional — it is a medicolegal requirement
- What happens when the AI is unavailable? — If your AI agent goes down, the hospital must continue operating. The clinical workflow must have a non-AI fallback path. AI must be additive, not a single point of failure
The integration implication: Your AI output must be delivered inside the tools clinicians already use — as a panel in the HIS, as an alert in the nursing station, as a flag in the lab system. If the doctor has to open a separate AI dashboard, adoption will be near zero.
The Integration Challenges That Persist Even When AI Works
Let us assume your AI model is perfect. It makes the right clinical decision every time. Here are the integration challenges that will still block you:
Challenge 1: The Last Mile Problem
Getting data into the AI is only half the battle. The AI's output must flow back into the clinical systems where clinicians work.
Examples:
- AI generates a discharge summary → it must be written as a structured document into the HIS, tagged to the correct encounter, and visible in the patient chart
- AI flags a critical lab result → the alert must appear in the HIS nursing dashboard within seconds, not in a separate AI portal that nobody checks
- AI recommends a medication change → it must create a draft order in the pharmacy system that the doctor can review and approve with one click
Each of these write-back paths requires a different integration with a different system, using a different API, with different validation rules. The AI's clinical accuracy is irrelevant if its output never reaches the clinician.
Challenge 2: Real-Time vs. Batch
Most hospital systems were designed for batch processing — generate a report at end of day, export a CSV overnight. AI agents need real-time data:
- A sepsis detection agent needs vitals every 5 minutes
- A triage agent needs new admission data within seconds
- A drug interaction checker needs the medication order before it is finalized
The solution: Your integration layer must implement event-driven architecture — database change data capture (CDC), HL7v2 message listeners, webhook triggers — to convert batch-oriented systems into real-time data streams. This is engineering work that has nothing to do with AI but everything to do with making AI useful.
Challenge 3: Multi-Vendor, Multi-Version Chaos
A typical Indian hospital runs:
- HIS from Vendor A (version 4.2, installed 2019)
- LIMS from Vendor B (version 7.1, installed 2022)
- PACS from Vendor C (version 3.0, installed 2017, no longer supported)
- Pharmacy from Vendor A (different product line, version 2.8)
- Billing from an in-house team (custom PHP application)
Each vendor has different API contracts, different authentication mechanisms, different data models, different uptime guarantees. Some systems have no API at all — the only way to extract data is direct database queries or screen scraping.
Your integration middleware must handle all of this. It needs pluggable connectors — one per system type and version — that abstract the chaos into a clean, unified interface for the AI.
Challenge 4: Patient Identity Across Systems
The same patient is:
MRN-10234in HISLAB-78901in LIMSPAT-5566in PACS12-3456-7890-1234(ABHA number) in ABDM
If your AI agent queries the LIMS for "MRN-10234", it will find nothing. You need a Patient Master Index (PMI) that maps all these identifiers to a single canonical patient ID. Without it, the AI literally cannot correlate a patient's lab results with their radiology images with their medication history.
Building and maintaining this PMI is an integration problem. ABHA (ABDM's unique health identifier) helps — but only if all systems have been linked to ABHA, which loops back to M1 milestone compliance.
Challenge 5: Consent-Gated Data Access
Under ABDM, an AI agent cannot simply query all patient data. The flow must be:
- AI determines it needs patient X's lab results
- Middleware checks: is there a valid consent artefact for this purpose?
- If yes: fetch data, decrypt (Fidelius), pass to AI
- If no: AI must operate without that data or trigger a consent request
- Every access is logged with timestamp, purpose, and consent artefact ID
This consent-checking layer sits between the AI and the data. It cannot be bypassed. It adds latency. It adds complexity. And it is mandatory.
Challenge 6: The Write-Back Authorization Problem
Reading patient data is complex enough. Writing AI decisions back into clinical systems is harder:
- Who is the author? — When AI writes a note into the patient chart, whose name goes on it? Regulatory frameworks require a responsible clinician. The AI cannot be the author of record
- Validation rules differ per system: — The HIS might require specific fields (encounter ID, department code, ICD-10 diagnosis code) that the AI must include. The pharmacy system might require a prescriber ID and DEA number. Each write-back has its own validation contract
- Approval workflows: — AI output should enter as a "draft" or "pending review" state, not as a finalized order. The integration must support staging AI outputs for human approval
How to Solve the Integration Problem
The answer is not "buy an integration platform" or "wait for all vendors to support FHIR." The answer is a pragmatic, layered approach:
1. Build the Middleware First, Add AI Second
Before touching any AI model, build the integration middleware that connects to your hospital systems. Validate that you can:
- Retrieve a patient's complete clinical picture from all systems in under 5 seconds
- Receive real-time events when new data is created (lab result finalized, new admission, vitals recorded)
- Write structured data back into the HIS, pharmacy, and other systems
- Enforce consent checking and audit logging on every data access
Once this works, plugging in AI is straightforward — the AI consumes FHIR from the middleware and writes back through the middleware. Without this layer, every AI project becomes a bespoke integration nightmare.
2. Use FHIR as the Internal Contract
Even if your hospital systems do not speak FHIR, make FHIR the internal contract between your middleware and your AI agent. This gives you:
- Vendor independence: Replace LIMS Vendor A with Vendor B? Just update the connector. The AI layer does not change
- Model portability: Train or fine-tune the AI on FHIR-structured data. Switch from GPT-4 to a clinical LLM? The data format stays the same
- ABDM readiness: ABDM already mandates FHIR R4 with NRCeS profiles for data exchange. Your middleware is doing double duty
3. Implement Event-Driven Architecture
AI agents are reactive — they respond to clinical events. Your middleware must convert hospital systems into event sources:
// Event-driven AI agent architecture
EventBus:
HIS → [new_admission, vitals_recorded, discharge_initiated]
LIMS → [lab_result_finalized, critical_value_detected]
RIS → [imaging_study_completed, report_signed]
Pharmacy → [medication_ordered, interaction_flagged]
AI Agent subscribes to relevant events:
sepsis_detector.subscribe([vitals_recorded, lab_result_finalized])
triage_agent.subscribe([new_admission])
drug_checker.subscribe([medication_ordered])
On event:
1. Fetch full patient context via FHIR middleware
2. Check consent validity
3. Run AI inference
4. Write output back via middleware (as draft/pending review)
5. Log everything4. Design for Human-in-the-Loop from Day One
Every AI output in healthcare must be reviewable, overridable, and auditable. Your integration must support:
- Staging: AI outputs enter as drafts, not finalized records
- Approval workflows: A clinician reviews, approves, or modifies the AI output before it becomes part of the medical record
- Override logging: When a doctor disagrees with the AI, the system logs both the AI recommendation and the doctor's actual decision — this is gold for future model improvement
- Explainability metadata: The AI's reasoning (which data points influenced the decision, confidence scores) must be stored alongside the output for medicolegal protection
5. Start with One Use Case, Prove the Integration
Do not try to build a hospital-wide AI platform on day one. Pick one high-value use case — clinical documentation, lab result interpretation, medication interaction checking — and build the full vertical:
- Integrate with the 2-3 systems that use case requires
- Build the FHIR conversion for those specific data types
- Implement consent checking for that data flow
- Deploy the AI with human-in-the-loop review
- Measure: clinician adoption, time saved, error rates
- Then expand to the next use case, reusing the integration infrastructure
Each new use case gets cheaper because the middleware, connectors, and consent infrastructure already exist. The first use case costs 10x — every subsequent one costs 2x.
The Checklist: Are You Ready for Healthcare AI?
Before engaging any AI vendor or starting any AI development, answer these questions honestly:
| Question | If No, Fix This First |
|---|---|
| Can you retrieve a patient's complete clinical record from all systems in under 10 seconds? | Build integration middleware + Patient Master Index |
| Do your systems emit real-time events (new results, new admissions)? | Implement event-driven connectors (CDC, HL7 listeners, webhooks) |
| Is your clinical data coded (ICD-10, SNOMED, LOINC) or mostly free text? | Invest in data structuring and NLP for legacy records |
| Do you have ABDM M2 compliance (HIP — sharing records on consent)? | Complete ABDM milestone integration first — it builds the exact infrastructure AI needs |
| Can you write data back into the HIS and pharmacy system programmatically? | Build write-back APIs with staging/approval workflows |
| Do you have patient consent management that checks scope, purpose, and expiry? | Implement consent artefact management per ABDM V3 specifications |
| Do you have audit logging for every data access? | Add centralized audit trail before processing any patient data with AI |
| Have you mapped the clinical workflow where the AI will operate? | Shadow clinicians, document the workflow, identify the exact insertion point for AI |
If you answered "no" to more than two of these, you are not ready for AI. You are ready for integration. And that is not a consolation prize — the integration work IS the AI readiness work. Every connector you build, every FHIR mapping you create, every consent flow you implement makes your eventual AI deployment faster, cheaper, and more impactful.
How Nirmitee Approaches This
At Nirmitee, we have seen hospitals spend months on AI pilots that fail at integration. Our approach flips the sequence:
- Integration-first architecture: We build the middleware layer that connects HIS, LIMS, RIS, PACS, and pharmacy systems with FHIR-normalized APIs — this works whether you add AI or not
- ABDM compliance as a foundation: M1, M2, M3 milestone integration gives you patient identity (ABHA), consent management, and FHIR data exchange — exactly the infrastructure AI agents need
- Event-driven connectors: Real-time data streams from hospital systems, not batch exports
- AI-ready data layer: Once the integration layer is live, adding AI use cases becomes a matter of subscribing to events and consuming FHIR — not re-integrating with every hospital system from scratch
- Human-in-the-loop by design: Every AI output flows through staging, approval, and audit logging built into the middleware
The boring truth is that the prerequisite work — integration, data quality, compliance, workflow mapping — is where healthcare AI projects are won or lost. The model is the easy part. Talk to us about building the foundation that makes AI actually work in your hospital.
Share
Related Posts
NABH Asset Management Compliance: A Complete Guide for Indian Hospitals
The Complete FHIR-to-openEHR Resource Mapping Matrix (2026 Reference)