In January 2024, a major health system's AI-powered medication assistant recommended a drug combination that would have caused severe bleeding in an elderly patient on warfarin. The system flagged it as "moderate interaction" when pharmacological databases classify warfarin plus high-dose aspirin as a critical contraindication in patients over 75 with renal impairment. A pharmacist caught it. But what if they hadn't?
This is why clinical safety guardrails aren't optional features — they're the difference between a helpful AI agent and a dangerous one.
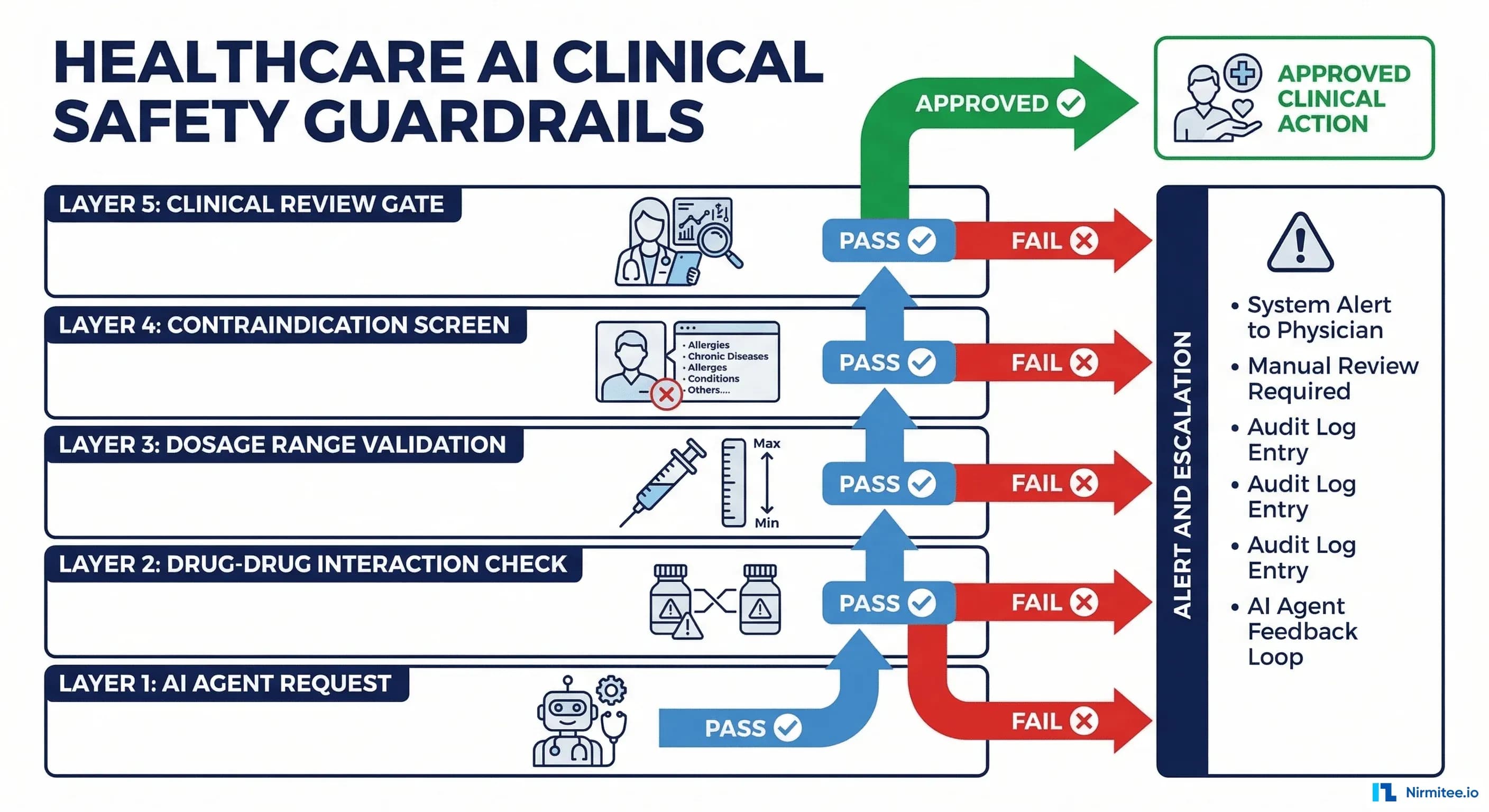
The Five-Layer Safety Architecture
Clinical safety for AI agents isn't a single check — it's a defense-in-depth strategy with five independent layers. Each layer catches different failure modes, and a failure at one layer is caught by the next.
Layer 1: Drug-Drug Interaction Screening
Before any medication recommendation reaches a clinician, the AI agent must check it against the patient's complete active medication list. This requires querying FHIR MedicationRequest resources with status=active and cross-referencing against a drug interaction database.
import requests
# Drug interaction severity levels
SEVERITY_LEVELS = {
"contraindicated": {"action": "BLOCK", "requires_override": "attending_physician"},
"major": {"action": "BLOCK", "requires_override": "prescriber"},
"moderate": {"action": "WARN", "requires_override": None},
"minor": {"action": "INFORM", "requires_override": None},
}
def check_drug_interactions(new_med_rxnorm: str, active_meds: list, patient_context: dict) -> list:
"""Check a new medication against all active meds using RxNorm + FDB."""
interactions = []
for active_med in active_meds:
# Query NLM RxNorm Interaction API
resp = requests.get(
"https://rxnav.nlm.nih.gov/REST/interaction/list.json",
params={"rxcuis": f"{new_med_rxnorm}+{active_med['rxnorm_code']}"}
)
if resp.status_code == 200:
data = resp.json()
for group in data.get("fullInteractionTypeGroup", []):
for interaction in group.get("fullInteractionType", []):
severity = classify_severity(interaction, patient_context)
interactions.append({
"drug_pair": (new_med_rxnorm, active_med["rxnorm_code"]),
"severity": severity,
"description": interaction.get("comment", ""),
"action": SEVERITY_LEVELS[severity]["action"],
"evidence_source": "NLM_RxNorm_Interaction_API"
})
return interactionsReal-world example: Warfarin (RxCUI: 11289) + Fluconazole (RxCUI: 4083) is a critical interaction — fluconazole inhibits CYP2C9, dramatically increasing warfarin levels and bleeding risk. Your guardrail must classify this as "contraindicated" regardless of what the AI agent recommends.
Layer 2: Dosage Range Validation
AI agents generating medication dosages must validate against weight-based, age-based, and renal-function-adjusted limits:
def validate_dosage(medication: dict, patient: dict) -> dict:
"""Validate medication dosage against clinical limits."""
drug_info = get_drug_reference(medication["rxnorm_code"])
issues = []
# Weight-based check (especially critical for pediatrics)
if patient.get("weight_kg"):
mg_per_kg = medication["dose_mg"] / patient["weight_kg"]
if mg_per_kg > drug_info["max_mg_per_kg"]:
issues.append({"type": "OVERDOSE", "severity": "critical",
"detail": f"{mg_per_kg:.1f} mg/kg exceeds max {drug_info['max_mg_per_kg']} mg/kg"})
# Renal adjustment (GFR-based)
if patient.get("gfr") and patient["gfr"] < 30:
renal_max = drug_info.get("renal_impairment_max_dose")
if renal_max and medication["dose_mg"] > renal_max:
issues.append({"type": "RENAL_OVERDOSE", "severity": "major",
"detail": f"GFR {patient['gfr']}: max dose is {renal_max}mg"})
# Age-based (geriatric/pediatric)
if patient.get("age") and patient["age"] >= 65:
if medication["rxnorm_code"] in BEERS_CRITERIA_DRUGS:
issues.append({"type": "BEERS_CRITERIA", "severity": "major",
"detail": "Listed in AGS Beers Criteria for older adults"})
return {"valid": len(issues) == 0, "issues": issues}Layer 3: Contraindication Screening
Beyond drug-drug interactions, the agent must check for drug-condition, drug-allergy, and drug-pregnancy contraindications. This requires querying FHIR AllergyIntolerance, Condition, and patient demographic resources:
- Drug-allergy: Check
AllergyIntoleranceresources for the medication and its drug class (e.g., patient allergic to sulfa → block all sulfonamide antibiotics) - Drug-condition: Metformin + eGFR <30 (lactic acidosis risk), NSAIDs + active GI bleeding, beta-blockers + severe asthma
- Drug-pregnancy: FDA pregnancy categories, especially Category X medications (e.g., isotretinoin, methotrexate, warfarin)
Layer 4: Clinical Appropriateness Check
Is the medication even appropriate for the documented condition? An AI agent recommending amoxicillin for a viral upper respiratory infection isn't dangerous per se, but it violates antibiotic stewardship guidelines and wastes resources. This layer uses condition-medication mappings from clinical practice guidelines:
- Check that the prescribed medication has an evidence-based indication for the documented diagnosis
- Flag first-line vs. second-line therapy deviations
- Check formulary compliance (insurance coverage, prior auth requirements)
Layer 5: Human-in-the-Loop Gate
Critical and major safety findings must NEVER be overridable by the AI agent itself. Only a licensed clinician can override with documented justification. This is the bounded autonomy pattern — the AI agent operates freely within safe boundaries but escalates anything that crosses safety thresholds:
def process_medication_request(agent_request: dict, patient: dict) -> dict:
"""Multi-layer safety check pipeline."""
# Layer 1: Drug interactions
interactions = check_drug_interactions(
agent_request["rxnorm_code"],
get_active_medications(patient["id"]),
patient
)
critical = [i for i in interactions if i["severity"] in ("contraindicated", "major")]
if critical:
return {"action": "BLOCK", "reason": critical, "requires": "physician_override"}
# Layer 2: Dosage validation
dosage_result = validate_dosage(agent_request, patient)
if not dosage_result["valid"]:
critical_dose = [i for i in dosage_result["issues"] if i["severity"] == "critical"]
if critical_dose:
return {"action": "BLOCK", "reason": critical_dose, "requires": "physician_override"}
# Layer 3: Contraindications
contras = check_contraindications(agent_request, patient)
if contras:
return {"action": "BLOCK", "reason": contras, "requires": "physician_override"}
# All checks passed
return {"action": "APPROVE", "warnings": interactions + dosage_result["issues"]}Integrating with CDS Hooks
Safety guardrails should surface through the EHR's native clinical decision support. CDS Hooks fires at clinical decision points — specifically, the medication-prescribe hook — and returns cards that display directly in the clinician's workflow:
// CDS Hook response for a critical drug interaction
{
"cards": [{
"uuid": "interaction-warfarin-fluconazole",
"summary": "CRITICAL: Warfarin + Fluconazole interaction",
"detail": "Fluconazole inhibits CYP2C9, increasing warfarin levels 2-3x. High risk of serious bleeding. Consider voriconazole or adjust warfarin dose with INR monitoring q2-3 days.",
"indicator": "critical",
"source": {"label": "First Databank Drug Interactions"},
"suggestions": [{
"label": "Switch to voriconazole 200mg BID",
"actions": [{"type": "create", "description": "Alternative antifungal",
"resource": {"resourceType": "MedicationRequest", "medicationCodeableConcept": {"coding": [{"system": "http://www.nlm.nih.gov/research/umls/rxnorm", "code": "121243", "display": "voriconazole"}]}}}]
}]
}]
}Testing Your Guardrails
Clinical safety guardrails must be tested with known dangerous combinations. Build a test suite that includes:
- Known critical interactions: Warfarin+NSAIDs, methotrexate+trimethoprim, lithium+ACE inhibitors, MAOIs+SSRIs
- Dosage edge cases: Pediatric weight-based calculations, geriatric Beers Criteria drugs, renal dose adjustments
- Allergy cross-reactivity: Penicillin allergy → cephalosporin cross-reactivity assessment
- False positive rate: Ensure moderate interactions don't block legitimate prescribing
For the complete HIPAA compliance architecture, see our HIPAA-compliant AI agent guide.
Building clinical AI agents at Nirmitee, we've implemented these safety layers across multiple health system deployments. If you need help getting your clinical safety architecture right, reach out.


