
Open any healthcare startup's landing page. Count how many say "AI-powered." Now ask yourself: what does that actually mean? In most cases, it means they call an LLM API somewhere in their stack. Maybe they auto-generate a summary. Maybe they have a chatbot that answers FAQs. Maybe — and this is more common than anyone admits — they have a rules engine with an if-statement that someone decided to call AI.
We have built over 20 healthcare applications. We have evaluated dozens more for potential clients. The gap between what companies claim about their AI and what actually runs in production is staggering. And enterprise buyers are getting smarter about asking the right questions.
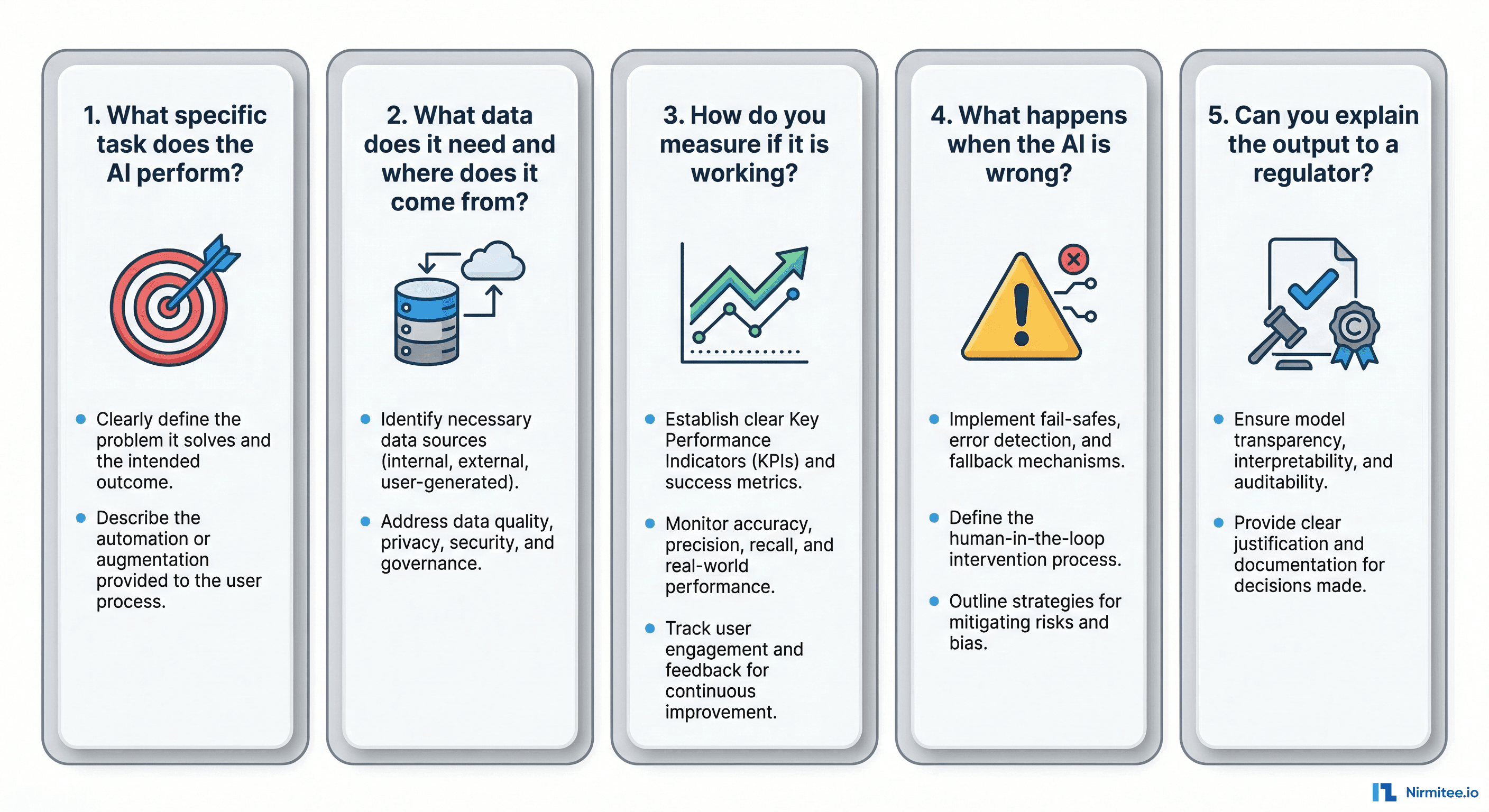
Here are the five questions that separate real agentic AI from marketing copy.
Question 1 — What Goal Does Your Agent Pursue Autonomously?
This is the question that eliminates 80% of "AI-powered" products in one shot.
An agent has a goal. Not a prompt. Not an input field. A goal. "Verify this patient's insurance eligibility and resolve any discrepancies" is a goal. "Summarize this text" is a task. The difference matters enormously.
A goal implies persistence. The agent does not give you an answer and disappear. It pursues the goal across multiple steps, over time, handling obstacles as they arise. If the payer API returns an error, the agent retries. If the patient's name does not match, the agent checks alternative identifiers. If the coverage is termed, the agent checks for replacement plans. It keeps going until the goal is achieved or it determines that human intervention is needed.
Most "AI-powered" healthcare products have tasks, not goals. They take an input, produce an output, and stop. That is a tool, not an agent. Tools are useful. But calling a tool "AI-powered" is like calling a calculator "AI-powered" because it does math faster than a human.
If you cannot articulate a specific goal your AI pursues autonomously — with multiple steps, error recovery, and a definition of "done" — you do not have an agent. You have a feature that uses an API.
Question 2 — What Tools and APIs Does It Use to Act?
An agent acts on the world. It does not just think — it does things. What things, specifically?
Real agentic AI in healthcare has a toolkit: FHIR APIs to read and write clinical data, X12 transaction sets to communicate with payers, scheduling APIs to book appointments, notification systems to alert staff, and document APIs to generate and file paperwork. The agent selects the right tool for each step, calls it with the right parameters, interprets the response, and decides what to do next.
Ask any vendor: "What APIs does your AI call, and what actions does it take?" If the answer is "it calls OpenAI's API," that is one tool — the thinking tool. Where are the doing tools? An agent that can only think but cannot act is a chatbot with extra steps.
The tool question also reveals the depth of integration. Shallow AI sits on top of your existing system and offers suggestions. Deep agentic AI is wired into your system's APIs and can execute actions directly — with appropriate permissions and oversight. The difference is between a consultant who writes a memo and an employee who does the work.
Question 3 — How Does It Handle Failures Gracefully?
This question separates demo AI from production AI, and it is the one that makes most vendors uncomfortable.

In a demo, everything works. The data is clean, the APIs respond instantly, and the patient's name is spelled correctly in every system. In production, nothing works like the demo. API calls time out. Patient records have conflicting information. Insurance cards are expired. Fax machines — yes, fax machines — send illegible documents. The lab results come back in a format nobody has seen before.
A real agent handles all of this. Not by crashing. Not by silently producing wrong results. By reasoning about the failure and choosing an appropriate response.
The payer API timed out? Retry with exponential backoff, then try the backup clearinghouse, then queue for manual follow-up with full context. The patient's date of birth does not match? Check if it is a formatting difference (MM/DD/YYYY vs DD/MM/YYYY), check if a transposition error is likely, flag for human verification if ambiguous. The OCR on the insurance card cannot read the group number? Try multiple OCR passes, cross-reference with known group number formats for that payer, escalate with the partial information and the original image attached.
Ask the vendor: "What happens when your AI encounters data it does not understand?" If they say "it asks the user," that is a chatbot. If they say "it never happens," that is a lie. If they walk you through a specific failure cascade with concrete fallback strategies, you might be looking at real agentic AI.
Question 4 — How Does It Improve Over Time?
Static AI is a snapshot. Agentic AI is a learning system.
Every time a human overrides an agent's decision, that is a training signal. The agent suggested "coverage active" but the billing specialist corrected it to "coverage termed" — why? Was it a data staleness issue? A payer-specific rule the agent did not know? A genuinely ambiguous case where the human had additional context?
Real agentic systems capture these corrections, analyze them for patterns, and improve. Not through expensive model retraining, but through updated rules, refined confidence thresholds, and expanded knowledge bases. The agent that handles 85% of cases autonomously in month one handles 92% in month three — not because the underlying LLM got smarter, but because the agent's domain knowledge grew from real-world feedback.
Ask the vendor: "How has your AI's accuracy changed over the last six months? What specifically caused it to improve?" If they cannot answer with data — specific metrics, specific improvements, specific feedback loops — their AI is static. It is the same today as it was when they shipped it, and it will be the same six months from now.
Question 5 — When Does It Escalate to Humans?
Here we see the maturity question. Immature AI systems try to do everything. Mature agentic systems know their limits.
A well-designed healthcare agent has explicit escalation criteria. Not "escalate when confused" — that is too vague. Concrete criteria: escalate when confidence drops below a defined threshold for a specific decision type, escalate when the dollar amount exceeds a specific limit, escalate when the patient has a specific flag (VIP, complex case, active complaint), escalate when the agent has attempted more than a defined number of resolution steps without success.
The escalation is not just a notification. A handoff. The agent provides the human with everything they need: what was attempted, what data was gathered, what the agent's best guess is and why, and what specific information or decision the human needs to provide. The human does not start from scratch — they pick up where the agent left off.
Notably, ask "Show me an escalation. What does the human see?Notably, " human sees a generic alert that says "AI needs help," that is not escalation — that is abdication. If the human sees a structured briefing with context, attempted actions, and a specific ask, you are looking at a real human-in-the-loop system.
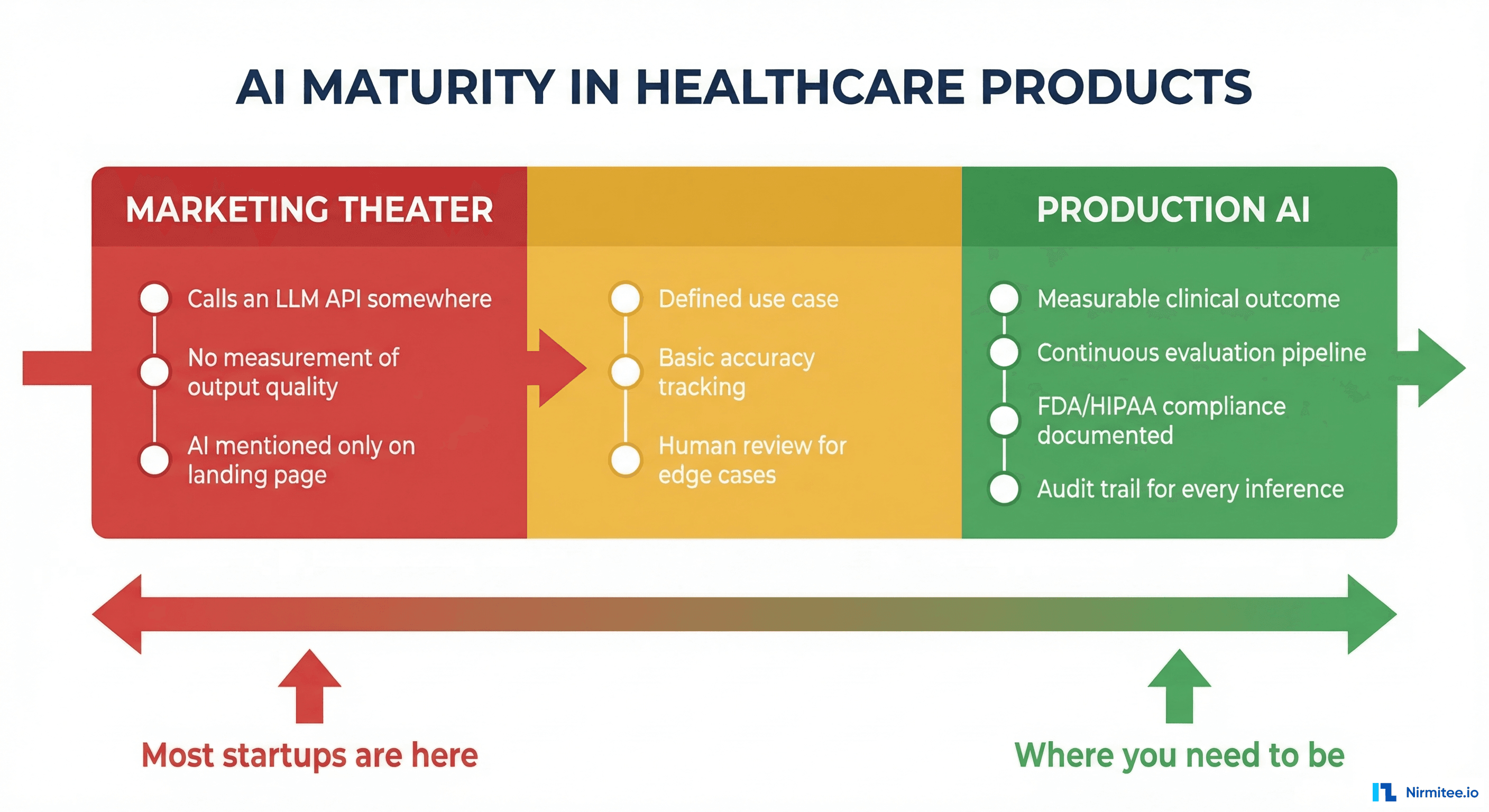
The AI Maturity Spectrum
Not all AI is equal, and not all AI that is less than fully agentic is worthless. The problem is not that companies use AI at different maturity levels — the problem is that they all use the same label. Here is what the spectrum actually looks like.
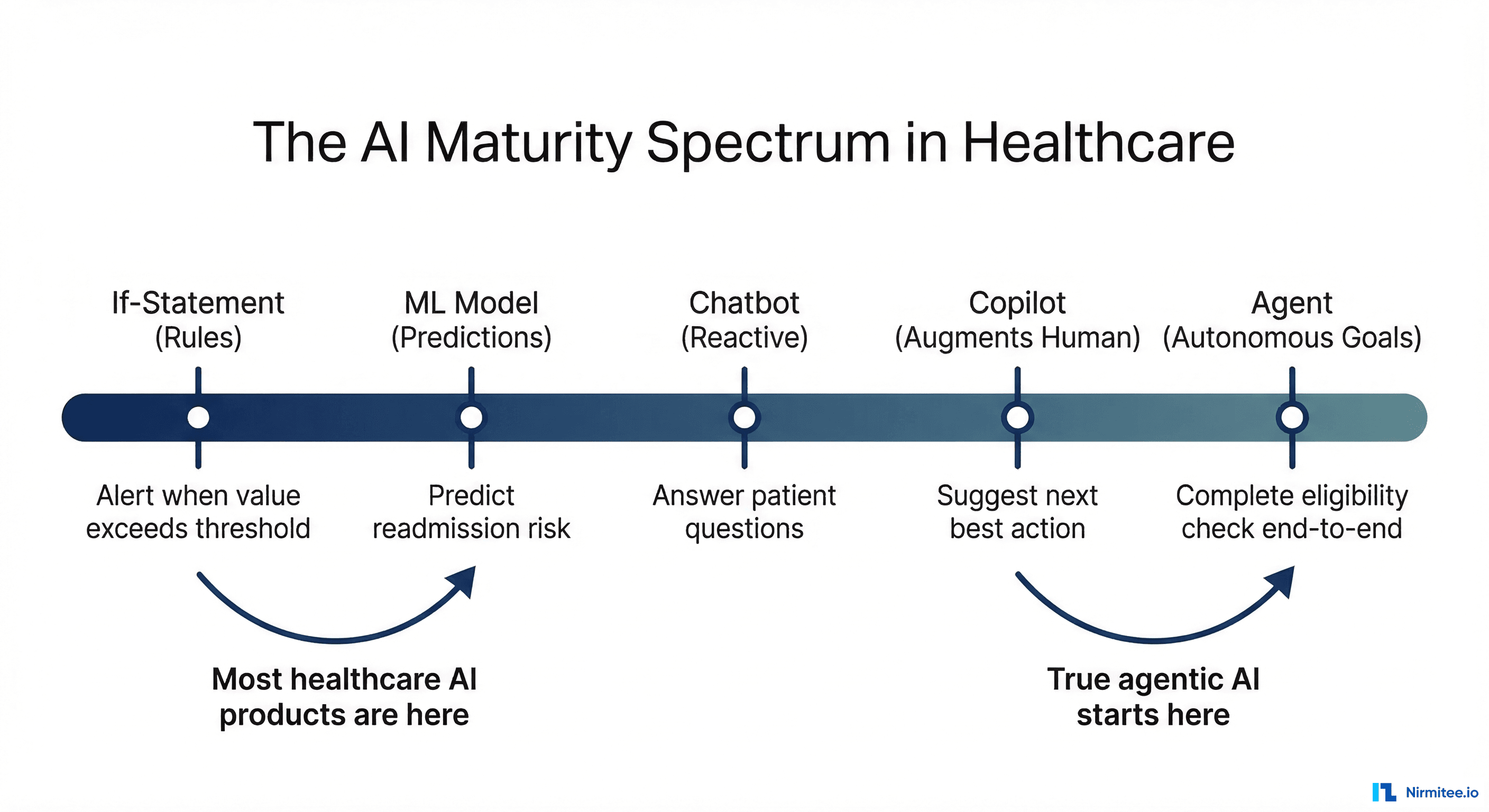
Level 1: Rules engines. If-then-else logic, decision trees, lookup tables. Not AI by any reasonable definition, but many products label it as such. "Our AI determines eligibility" might mean "we check if the plan code is in a list of active plans."
Level 2: ML models. Trained models that classify, predict, or extract data. OCR that reads insurance cards, NLP that extracts diagnoses from clinical notes, predictive models that flag high-risk patients. Genuinely useful, but not agentic. The model produces an output and stops.
Level 3: Chatbots and assistants. LLM-powered conversational interfaces that answer questions, summarize information, or help users navigate complex systems. Useful for patient engagement and clinician support. Still not agentic — they respond to prompts, they do not pursue goals.
Level 4: Copilots. AI that works alongside humans in real-time, suggesting actions and drafting outputs that the human reviews and approves. Clinical documentation copilots, coding assistance, prior auth draft generation. Genuinely valuable and increasingly common. Getting close to agentic, but the human is still the driver.
Level 5: Agents. AI that pursues goals autonomously, uses tools to act, handles failures, improves over time, and knows when to escalate. The human sets the goal and handles escalations — the agent does everything in between.
There is nothing wrong with being at Level 2 or Level 3. There is everything wrong with being at Level 2 and claiming to be at Level 5. Your customers will figure it out, and when they do, your credibility is gone.
What Enterprise Buyers Are Learning to Ask
The healthcare enterprise buying cycle is long and thorough. Procurement teams, clinical informatics, IT security, compliance — they all get a vote. And they are getting educated about AI fast.
Here is what sophisticated buyers are asking in 2026:
- "Show us a production audit log, not a demo." They want to see real agent decisions with real data (de-identified). The reasoning chain, the confidence score, the outcome. Consider: impossible to fake because it requires an actual running agent making actual decisions.
- "What is your escalation rate, and how has it changed?" A high escalation rate means the agent is not useful. A declining escalation rate means it is learning. A static escalation rate means nobody is closing the feedback loop.
- "What happens when we change payers or add new workflows?" Can the agent adapt, or does it need to be reprogrammed? Notice how the brittleness test — the same question that killed RPA.
- "How do you handle PHI in your AI pipeline?" Does patient data go to a third-party LLM? Is it logged? Is it used for training? Is there a BAA in place? These are compliance deal-breakers, and vague answers kill deals.
- "What is the total cost of ownership, including the humans in the loop?" If the agent escalates 40% of cases to humans, it is not saving 100% of the labor — it is saving 60%. Honest vendors present this math. Dishonest vendors only show the automation rate in their cherry-picked demo scenarios.
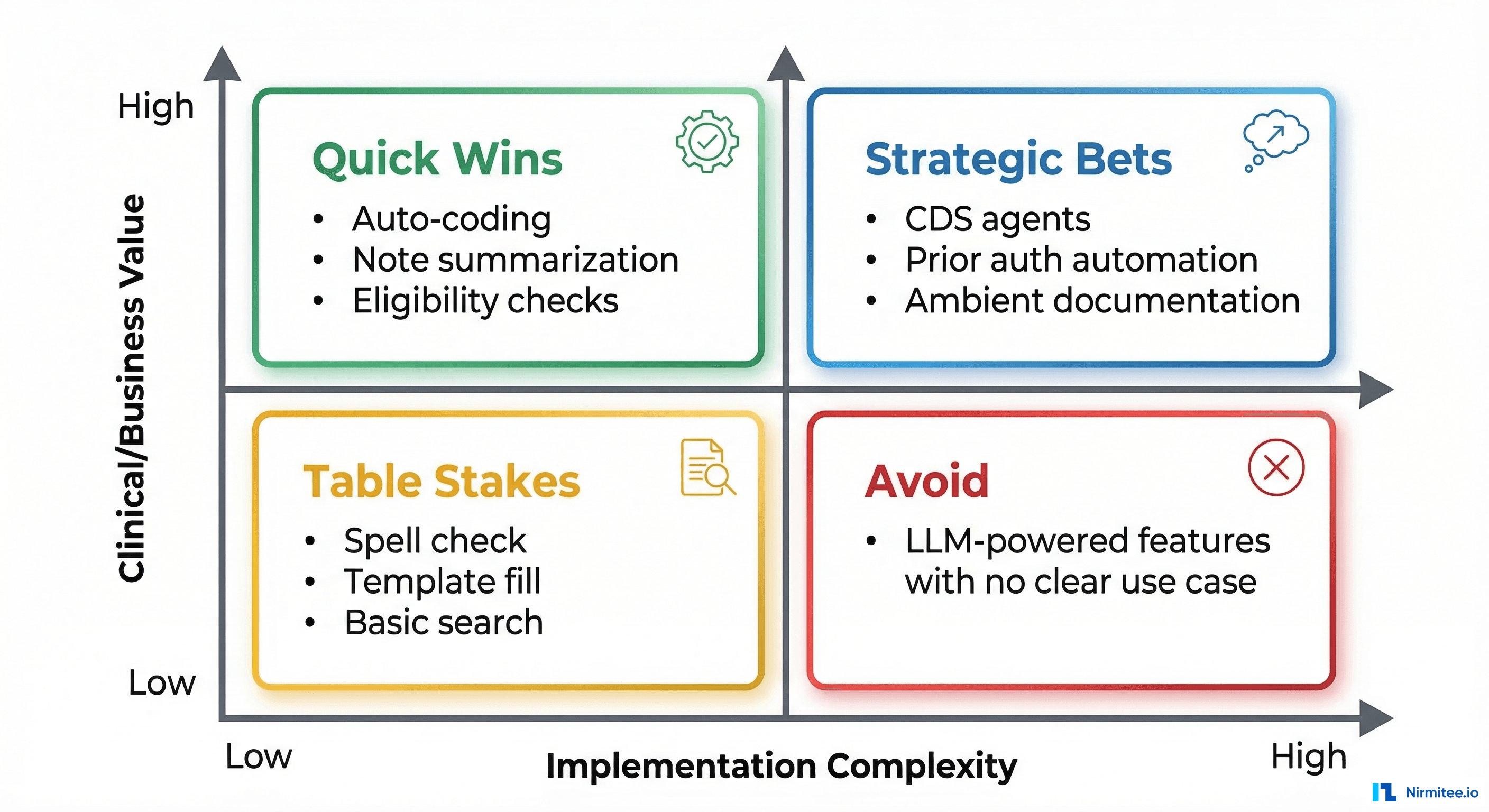
How to Actually Earn the "AI-Powered" Label
If you are building a healthcare product and you want to honestly claim AI capabilities, here is the bar you need to clear.
Be specific about what your AI does. Not "AI-powered eligibility verification." Instead: "Our agent autonomously verifies patient eligibility across 1,200 payers, resolves 87% of discrepancies without human intervention, and provides a structured handoff for the remaining 13%." Specific claims are credible. Vague claims are marketing.
Publish your metrics. Accuracy rate, autonomy rate, escalation rate, average resolution time, improvement trajectory. If you are proud of your AI, show the numbers. If you are not willing to show the numbers, ask yourself why.
Show the failure modes. Every AI system fails. The question is how. If you show a prospect how your agent handles a case it cannot resolve — gracefully, with context-rich escalation — you build more trust than any successful demo ever could. Buyers know that demos are curated. Showing failure handling is proof that you have thought about production realities.
Differentiate your levels. If some features are Level 2 (ML models) and one feature is Level 5 (agentic), say so. "Our clinical note summarization uses NLP extraction (Level 2), and our eligibility verification is fully agentic (Level 5)." This honesty is more impressive than claiming everything is advanced AI.
Invite technical due diligence. Let the prospect's engineering team look under the hood. If your AI is real, technical scrutiny only makes you look better. When teams nervous about technical due diligence, your AI is probably not what you are claiming.
The Bottom Line
"AI-powered" has become the "cloud-based" of 2026 — a label so overused that it communicates nothing. Every healthcare product claims it. Few can back it up.
The five questions in this article are not theoretical. They are the questions that enterprise buyers, investors, and technical evaluators are learning to ask. If you cannot answer them with specifics — concrete goals, named tools, documented failure handling, measurable improvement, and structured escalation — then your AI is not what you think it is.
That does not mean you should not ship it. Rules engines, ML models, chatbots, and copilots all create real value in healthcare. But call them what they are. Save "AI-powered" for when you have built something that actually earns the label — an agent that pursues goals, uses tools, handles failures, learns from feedback, and knows when to ask for help.
The market will reward honesty. (For a deeper look at healthcare interoperability standards, see our HL7v2-to-FHIR migration guide and FHIR vs openEHR architecture comparison.) The buyers who matter — the ones with real budgets and real problems — are tired of demos that do not match production. Give them something real, tell them exactly what it is, and let the product speak for itself.
Share
Related Posts
Designing AI-Driven Clinical Decision Support Systems: The Complete Engineering Guide
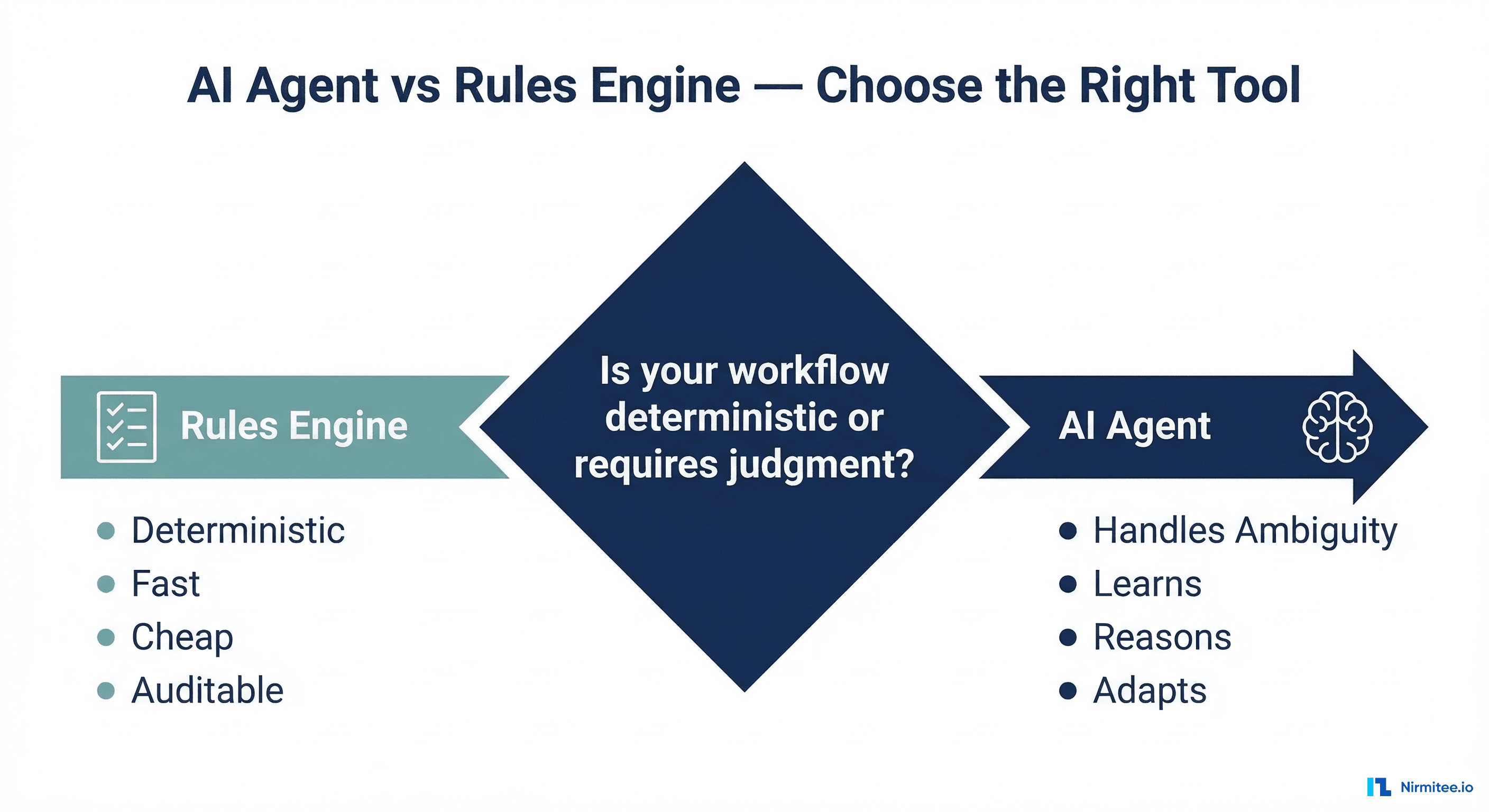
When NOT to Use an AI Agent in Healthcare: 7 Cases Where a Rules Engine Wins
