Why Healthcare AI Has a Data Problem
Healthcare AI has a paradox at its core: the models that could save the most lives need the most data, but the data that could train them is locked behind the strictest privacy regulations on earth. HIPAA in the United States, GDPR in Europe, and dozens of national privacy frameworks worldwide all agree on one thing — patient data should not leave the institution that collected it.
This creates a fragmentation problem. A single hospital might have 50,000 patient records for a specific condition. Across a network of 20 hospitals, that number could be 1 million. The difference in model performance between 50K and 1M training samples is not incremental — it is often the difference between a model that is clinically useful and one that is not. A 2023 study published in Nature Medicine found that multi-institutional models outperformed single-institution models by 6-17% AUC across six different clinical prediction tasks.
Traditional approaches to this problem — data sharing agreements, de-identification, centralized data lakes — all have significant limitations. Data sharing agreements take 12-18 months to negotiate. De-identification is imperfect (re-identification attacks succeed 87% of the time on supposedly de-identified datasets, according to a 2022 study by Rocher et al.). Centralized data lakes concentrate risk and create single points of failure.
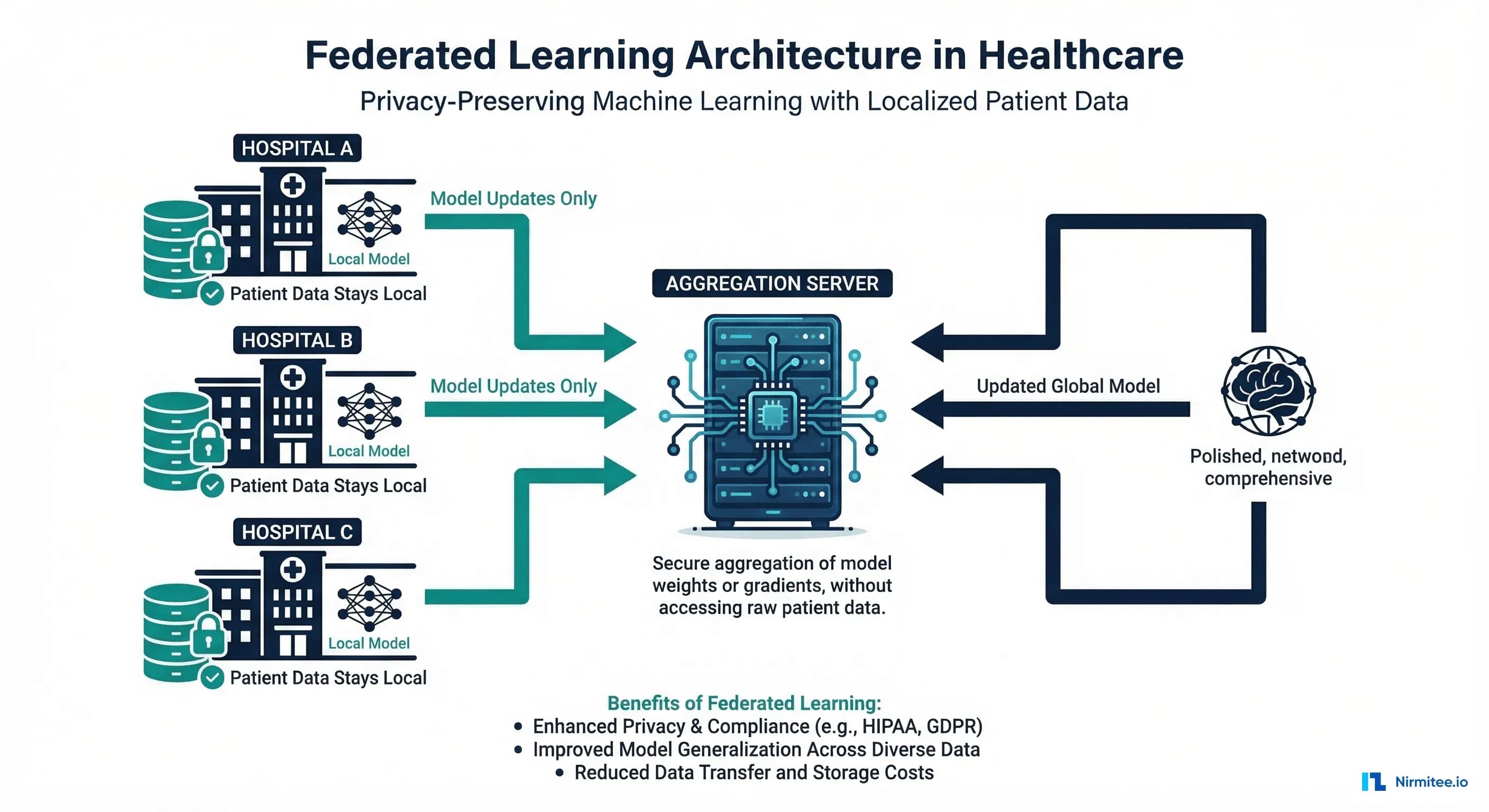
Federated learning offers a fundamentally different approach: instead of bringing data to the model, bring the model to the data.
What Is Federated Learning?
Federated learning (FL) is a machine learning paradigm where a model is trained across multiple decentralized data sources without exchanging raw data. Originally proposed by Google in 2016 for improving mobile keyboard predictions, FL has found its most compelling application in healthcare — where the privacy constraints are not just regulatory preferences but legal requirements with criminal penalties.
The core mechanism is straightforward:
- A coordinator distributes a global model to all participating institutions
- Each institution trains the model locally on its own patient data
- Only the model updates (gradients or weight deltas) are sent back to the coordinator — never the raw data
- The coordinator aggregates updates using algorithms like Federated Averaging (FedAvg) to produce an improved global model
- The cycle repeats until the model converges
What leaves each hospital is a set of numerical tensors — gradient values that describe how the model should change, not the patient records that produced those changes. A gradient tensor for a chest X-ray classification model might be 25 million floating-point numbers. Reconstructing a specific patient's chest X-ray from those gradients is computationally infeasible, especially when combined with differential privacy (which we will cover later).
FL Architectures: Centralized, Decentralized, and Hierarchical
Not all federated learning deployments look the same. The architecture you choose depends on your network topology, trust model, and regulatory environment.
Centralized Federated Learning
The most common architecture. A single coordinator server (often operated by a research consortium or cloud provider) manages the training process. Hospitals communicate only with the coordinator, never with each other.
Best for: Research consortia with a trusted central organizer (e.g., the TriNetX network, OHDSI collaborations). The coordinator can be a neutral third party like an academic medical center or a cloud provider with a BAA.
Limitation: Single point of failure. If the coordinator is compromised or goes offline, training stops.
Decentralized (Peer-to-Peer) Federated Learning
No central coordinator exists. Hospitals exchange model updates directly with each other using gossip protocols or blockchain-based consensus. Each node aggregates updates from its peers.
Best for: Networks where no single entity is trusted to coordinate, or where regulatory requirements prohibit any centralization. Some European health data spaces are exploring this model under GDPR's data sovereignty requirements.
Limitation: Higher communication overhead (O(n squared) vs O(n) for centralized). Convergence is slower and harder to guarantee.
Hierarchical Federated Learning
A tiered approach: individual hospitals aggregate within their health system first, then health systems aggregate at a regional or national level. This matches the actual organizational structure of healthcare delivery.
Best for: Large integrated delivery networks (IDNs) like Kaiser Permanente, HCA Healthcare, or national health services (NHS). A hospital within Kaiser first aggregates with its regional Kaiser peers, then the Kaiser regional model participates in a broader multi-system federation.
Limitation: More complex orchestration. Requires clear governance at each tier.
| Architecture | Communication | Trust Model | Convergence | Best Healthcare Use Case |
|---|---|---|---|---|
| Centralized | O(n) per round | Trust coordinator | Fast (10-50 rounds) | Research consortia, multi-site trials |
| Decentralized | O(n squared) per round | No single trust | Slower (50-200 rounds) | Cross-border EU health data spaces |
| Hierarchical | O(n) within tier | Tiered trust | Moderate (20-100 rounds) | Integrated delivery networks, national systems |
Federated Learning Frameworks for Healthcare
Several open-source frameworks have emerged for implementing FL in healthcare settings. Each has different strengths.
NVIDIA FLARE (Federated Learning Application Runtime Environment)
Purpose-built for healthcare FL, NVIDIA FLARE emerged from the NVIDIA Clara project and has been used in some of the largest healthcare FL studies to date, including the EXAM study — a 20-hospital federated learning project for COVID-19 severity prediction that achieved an average AUC of 0.92.
Key features: Built-in privacy mechanisms (differential privacy, secure aggregation), healthcare-specific workflows, integration with NVIDIA Clara for medical imaging, and enterprise-grade security.
Flower (flwr)
The most flexible and framework-agnostic FL library. Flower works with PyTorch, TensorFlow, JAX, and even scikit-learn. Its simplicity makes it the best choice for teams that want to get started quickly.
Key features: Minimal boilerplate, strategy pattern for custom aggregation algorithms, simulation mode for local development, and strong community.
PySyft (OpenMined)
Focused on privacy-preserving computation, PySyft combines FL with secure multi-party computation (SMPC) and differential privacy. It provides the strongest privacy guarantees but has more complexity.
Key features: Remote execution on encrypted data, integration with PyTorch, privacy budgeting, and audit trails.
TensorFlow Federated (TFF)
Google's official FL framework, tightly integrated with the TensorFlow ecosystem. Best for teams already invested in TensorFlow.
Key features: TensorFlow integration, eager and graph mode execution, simulation runtime for local experimentation.
Building a Clinical FL Training Loop with Flower
Let us build a practical federated learning system for a clinical readmission prediction model using the Flower framework. This example demonstrates how three hospitals can collaboratively train a model without sharing any patient data.
Server Configuration
The FL server orchestrates training rounds and aggregates model updates:
# fl_server.py — Federated Learning Server for Clinical Readmission Model
import flwr as fl
from flwr.server.strategy import FedAvg
from typing import List, Tuple, Optional, Dict
import numpy as np
class ClinicalFedAvg(FedAvg):
"""Custom FedAvg with healthcare-specific enhancements."""
def __init__(self, min_hospitals: int = 3, **kwargs):
super().__init__(
min_fit_clients=min_hospitals,
min_evaluate_clients=min_hospitals,
min_available_clients=min_hospitals,
**kwargs
)
self.round_metrics: List[Dict] = []
def aggregate_fit(
self,
server_round: int,
results: List[Tuple[fl.server.client_proxy.ClientProxy, fl.common.FitRes]],
failures: List,
):
"""Aggregate with weighted averaging based on dataset size."""
if not results:
return None, {}
# Log per-hospital metrics for audit trail (regulatory requirement)
for client, fit_res in results:
self.round_metrics.append({
"round": server_round,
"hospital_id": client.cid,
"num_samples": fit_res.num_examples,
"loss": fit_res.metrics.get("train_loss", 0.0),
})
print(f" Round {server_round} | Hospital {client.cid}: "
f"{fit_res.num_examples} samples, "
f"loss={fit_res.metrics.get('train_loss', 0.0):.4f}")
# Use parent FedAvg aggregation (weighted by num_examples)
return super().aggregate_fit(server_round, results, failures)
def aggregate_evaluate(
self,
server_round: int,
results: List[Tuple[fl.server.client_proxy.ClientProxy, fl.common.EvaluateRes]],
failures: List,
):
"""Track validation metrics across hospitals."""
if not results:
return None, {}
# Weighted average of AUC across hospitals
total_samples = sum(r.num_examples for _, r in results)
weighted_auc = sum(
r.metrics.get("auc", 0.0) * r.num_examples
for _, r in results
) / total_samples
print(f"\n Round {server_round} Global AUC: {weighted_auc:.4f}\n")
return super().aggregate_evaluate(server_round, results, failures)
def start_fl_server(num_rounds: int = 20, min_hospitals: int = 3):
"""Launch the federated learning server."""
strategy = ClinicalFedAvg(
min_hospitals=min_hospitals,
fraction_fit=1.0, # All hospitals participate each round
fraction_evaluate=1.0, # All hospitals evaluate each round
)
fl.server.start_server(
server_address="0.0.0.0:8080",
config=fl.server.ServerConfig(num_rounds=num_rounds),
strategy=strategy,
)
if __name__ == "__main__":
start_fl_server(num_rounds=20, min_hospitals=3)
Hospital Client
Each hospital runs a Flower client that trains on its local data:
# fl_hospital_client.py — Hospital-side FL Client
import flwr as fl
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.metrics import roc_auc_score
import numpy as np
from collections import OrderedDict
class ReadmissionModel(nn.Module):
"""Clinical readmission prediction model.
Input features: 42 clinical variables including:
- Demographics (age, gender)
- Vitals (BP, HR, SpO2, temp)
- Lab results (CBC, BMP, HbA1c)
- Diagnoses (ICD-10 encoded)
- Prior utilization (ED visits, admissions in 12 months)
"""
def __init__(self, input_dim: int = 42):
super().__init__()
self.network = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.BatchNorm1d(128),
nn.Dropout(0.3),
nn.Linear(128, 64),
nn.ReLU(),
nn.BatchNorm1d(64),
nn.Dropout(0.2),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid(),
)
def forward(self, x):
return self.network(x)
class HospitalFLClient(fl.client.NumPyClient):
"""Flower client for a single hospital."""
def __init__(self, hospital_id: str, train_data, val_data,
epochs_per_round: int = 3, batch_size: int = 64):
self.hospital_id = hospital_id
self.model = ReadmissionModel()
self.criterion = nn.BCELoss()
self.epochs = epochs_per_round
self.batch_size = batch_size
# Create data loaders from hospital's local data
self.train_loader = DataLoader(
train_data, batch_size=batch_size, shuffle=True
)
self.val_loader = DataLoader(
val_data, batch_size=batch_size, shuffle=False
)
def get_parameters(self, config):
"""Return model parameters as numpy arrays."""
return [val.cpu().numpy() for _, val in
self.model.state_dict().items()]
def set_parameters(self, parameters):
"""Set model parameters from numpy arrays."""
params_dict = zip(self.model.state_dict().keys(), parameters)
state_dict = OrderedDict(
{k: torch.tensor(v) for k, v in params_dict}
)
self.model.load_state_dict(state_dict, strict=True)
def fit(self, parameters, config):
"""Train model on local hospital data."""
self.set_parameters(parameters)
optimizer = torch.optim.Adam(self.model.parameters(), lr=1e-3)
self.model.train()
total_loss = 0.0
num_batches = 0
for epoch in range(self.epochs):
for X_batch, y_batch in self.train_loader:
optimizer.zero_grad()
predictions = self.model(X_batch).squeeze()
loss = self.criterion(predictions, y_batch)
loss.backward()
optimizer.step()
total_loss += loss.item()
num_batches += 1
avg_loss = total_loss / max(num_batches, 1)
num_samples = len(self.train_loader.dataset)
return (
self.get_parameters(config={}),
num_samples,
{"train_loss": avg_loss, "hospital_id": self.hospital_id},
)
def evaluate(self, parameters, config):
"""Evaluate model on local validation data."""
self.set_parameters(parameters)
self.model.eval()
all_preds, all_labels = [], []
total_loss = 0.0
with torch.no_grad():
for X_batch, y_batch in self.val_loader:
predictions = self.model(X_batch).squeeze()
loss = self.criterion(predictions, y_batch)
total_loss += loss.item()
all_preds.extend(predictions.numpy())
all_labels.extend(y_batch.numpy())
auc = roc_auc_score(all_labels, all_preds)
num_samples = len(self.val_loader.dataset)
return (
total_loss / len(self.val_loader),
num_samples,
{"auc": auc, "hospital_id": self.hospital_id},
)
def start_hospital_client(hospital_id: str, server_address: str):
"""Load local data and connect to FL server."""
# In production, load from hospital's data warehouse
# Each hospital has different data distributions (non-IID)
train_data, val_data = load_hospital_data(hospital_id)
client = HospitalFLClient(
hospital_id=hospital_id,
train_data=train_data,
val_data=val_data,
)
fl.client.start_numpy_client(
server_address=server_address,
client=client,
)
The Non-IID Data Challenge
The most significant technical challenge in healthcare FL is non-IID (non-independent and identically distributed) data. Unlike federated learning for mobile keyboards — where each user's data is roughly similar — hospitals serve fundamentally different patient populations.
Consider three hospitals in a federated sepsis prediction study:
- Hospital A (urban academic medical center): 60% complex multi-organ cases, younger trauma patients, diverse demographics
- Hospital B (rural community hospital): 80% elderly patients, higher proportion of COPD and heart failure comorbidities
- Hospital C (pediatric specialty hospital): 95% patients under 18, different vital sign ranges, different sepsis presentations
Standard FedAvg assumes all participants have roughly similar data distributions. When that assumption breaks down, the global model can oscillate — each round, it gets pulled in different directions by hospitals with very different patient populations.
Solutions for Non-IID Healthcare Data
| Strategy | How It Works | When to Use |
|---|---|---|
| FedProx | Adds a proximal term to local training that penalizes deviation from the global model | Moderate non-IID; hospital populations overlap somewhat |
| SCAFFOLD | Uses control variates to correct for client drift during local updates | Severe non-IID with many training rounds |
| Per-FedAvg | Trains a global model that is designed to be fine-tuned locally (meta-learning approach) | Hospitals need personalized models (e.g., different disease mixes) |
| Clustered FL | Groups hospitals with similar data distributions and trains separate models per cluster | Distinct hospital types (academic vs. community vs. specialty) |
| Data Sharing | Each hospital shares a small amount of non-sensitive synthetic data to create a shared anchor | When hospitals agree to share summary statistics |
Differential Privacy Integration
Federated learning alone does not guarantee privacy. Research has shown that model updates (gradients) can leak information about training data through gradient inversion attacks. To provide provable privacy guarantees, FL must be combined with differential privacy (DP). For more on healthcare data privacy requirements, see our guide on HIPAA compliance for healthcare AI.
In DP-FL, each hospital adds carefully calibrated noise to its model updates before sending them to the coordinator. The noise is large enough to obscure any individual patient's contribution but small enough that the aggregated model still converges.
The key parameter is epsilon — the privacy budget:
- Epsilon = 0.1: Very strong privacy. Model accuracy degrades significantly. Suitable for highly sensitive psychiatric or HIV data.
- Epsilon = 1.0: Strong privacy with moderate accuracy impact. The sweet spot for most clinical models.
- Epsilon = 10.0: Weak privacy but near-baseline accuracy. Acceptable when data is already low-sensitivity (e.g., anonymized population health statistics).
A practical approach for healthcare is local differential privacy, where each hospital clips gradients and adds Gaussian noise before transmission:
# dp_fl_client.py — Differential Privacy for FL Hospital Client
import torch
import numpy as np
from typing import List
def clip_and_noise_gradients(
parameters: List[np.ndarray],
clip_norm: float = 1.0,
noise_multiplier: float = 1.1, # Controls epsilon
num_samples: int = 1000,
) -> List[np.ndarray]:
"""Apply DP-SGD style clipping and noise to model updates.
Args:
parameters: Model parameter arrays after local training
clip_norm: Maximum L2 norm for gradient clipping
noise_multiplier: Ratio of noise std to clip_norm
num_samples: Number of training samples (for sensitivity calibration)
Returns:
Noised parameters with differential privacy guarantee
"""
noised_params = []
for param in parameters:
# Step 1: Clip the parameter update to bound sensitivity
param_norm = np.linalg.norm(param)
clip_factor = min(1.0, clip_norm / (param_norm + 1e-8))
clipped = param * clip_factor
# Step 2: Add calibrated Gaussian noise
noise_std = clip_norm * noise_multiplier / num_samples
noise = np.random.normal(0, noise_std, size=param.shape)
noised_params.append(clipped + noise)
return noised_params
def compute_privacy_budget(
noise_multiplier: float,
num_rounds: int,
sample_rate: float, # fraction of data used per round
delta: float = 1e-5, # probability of privacy breach
) -> float:
"""Estimate total epsilon using RDP accountant.
Uses Renyi Differential Privacy for tighter epsilon bounds.
In production, use Google's dp-accounting library.
"""
# Simplified RDP composition (use opacus or dp-accounting for exact)
# epsilon grows as O(sqrt(num_rounds)) with subsampling
rdp_epsilon = (
sample_rate ** 2 * num_rounds / (2 * noise_multiplier ** 2)
)
# Convert RDP to (epsilon, delta)-DP
epsilon = rdp_epsilon + np.log(1 / delta) / (noise_multiplier - 1)
return epsilon
Communication Overhead and Optimization
Transmitting full model updates from each hospital every round creates significant bandwidth requirements. A ResNet-50 model used for medical imaging has approximately 25 million parameters. At 32-bit precision, that is 100 MB per update, per hospital, per round. Over 50 rounds with 20 hospitals, you are looking at 100 GB of data transfer.
In healthcare, where many hospitals still operate on limited network infrastructure, this is a real barrier. Several techniques address this:
- Gradient Compression: Only transmit the top-k% of gradient values (typically top 1-10%). Studies show 90-99% compression with less than 1% accuracy loss.
- Quantization: Reduce gradient precision from 32-bit to 8-bit or even 1-bit (sign-SGD). Reduces bandwidth 4-32x.
- Asynchronous FL: Hospitals submit updates when ready instead of waiting for all hospitals to complete a round. Eliminates the straggler problem.
- Local SGD: Run more local training epochs per round (e.g., 10 instead of 1) to reduce the number of communication rounds needed.
The Free-Rider Problem in Healthcare FL
In any collaborative system, there is a risk that some participants contribute less than others. In healthcare FL, a free-rider hospital might:
- Submit random noise instead of genuine model updates (to benefit from the global model without contributing real training)
- Contribute minimal data (e.g., 100 records) while benefiting from the aggregated knowledge of hospitals with 100,000+ records
- Submit stale updates from a previous round to reduce their compute costs
Detection and mitigation strategies include:
- Contribution scoring: Track each hospital's impact on global model improvement. Hospitals whose updates consistently do not improve (or degrade) global validation performance are flagged.
- Minimum data requirements: Governance agreements require a minimum dataset size for participation.
- Reputation systems: Blockchain-based reputation tracking where hospitals earn credits proportional to their contribution quality.
For guidance on monitoring model performance in production, including detecting when federated models drift, see our article on AI model monitoring and drift detection.
Real-World Healthcare FL Deployments
Federated learning is not theoretical in healthcare — several large-scale deployments have published results:
- EXAM Study (2022): 20 hospitals across 5 continents used NVIDIA FLARE to predict COVID-19 patient oxygen needs. The federated model achieved AUC 0.92, outperforming 16 of 20 single-institution models. Published in Nature Medicine.
- Intel/UPenn Brain Tumor Study (2022): 71 institutions across 6 continents trained a federated model for glioblastoma boundary detection. The FL model improved tumor detection by 33% compared to single-institution models. Published in Nature Communications.
- HealthChain (EU, 2023): A European Commission-funded project using FL across hospitals in France, Luxembourg, and Spain for breast cancer treatment response prediction.
- Owkin (Commercial): A Paris-based startup running FL across cancer centers in the US and Europe, with partnerships with 15+ academic medical centers.
Implementation Roadmap for Healthcare Organizations
| Phase | Timeline | Activities | Deliverables |
|---|---|---|---|
| 1. Infrastructure | Months 1-2 | Deploy FL server, set up secure communication channels (mTLS), configure hospital compute nodes | Working FL infrastructure, network connectivity tested |
| 2. Pilot | Months 3-4 | 2-3 hospitals run FL on a simple model (e.g., readmission prediction), validate convergence | Pilot results report, model performance benchmarks |
| 3. Compliance | Month 5 | Privacy audit (DP parameters), HIPAA compliance review, IRB approval if research, BAAs signed | Compliance certification, privacy budget documentation |
| 4. Production | Months 6-8 | Deploy production model, add monitoring and alerting, establish model governance | Production FL pipeline, monitoring dashboards |
| 5. Scale | Months 9-12 | Onboard additional hospitals, add new models, optimize communication | Scaled network, multiple FL models in production |
Challenges and Limitations
FL is not a silver bullet. Healthcare teams should be aware of these limitations:
- Model convergence: With highly non-IID data across hospitals, FL models may converge to suboptimal solutions compared to centralized training on pooled data. The accuracy gap is typically 2-5% AUC.
- Debugging difficulty: When a FL model underperforms, it is hard to diagnose whether the issue is bad data at one hospital, a communication error, or an algorithm problem — because you cannot inspect the data at other sites.
- Governance complexity: Who owns the federated model? Who is liable when it makes an error? How are hospitals compensated for their computational contributions? These governance questions do not have standard answers yet.
- Regulatory uncertainty: The FDA has not issued specific guidance on FL-trained models for SaMD. Current FDA AI guidance assumes centralized training data that can be fully audited.
Frequently Asked Questions
Is federated learning HIPAA-compliant?
FL itself does not automatically make you HIPAA-compliant, but it significantly reduces risk by keeping PHI at the source institution. You still need BAAs with any FL server operators, encryption in transit for model updates, and proper access controls. The key benefit is that raw patient data never leaves the covered entity's control.
How does federated learning compare to simply de-identifying data and sharing it?
De-identification is imperfect — studies show 87% of supposedly de-identified records can be re-identified using external data. FL avoids this risk entirely because raw data never leaves the institution. However, FL models may be slightly less accurate than models trained on perfectly pooled data (typically 2-5% AUC gap).
What is the minimum number of hospitals needed for effective FL?
Research suggests 5-10 hospitals provide the best cost-benefit ratio. Fewer than 3 hospitals offer minimal advantage over single-institution training. Beyond 20 hospitals, returns diminish and communication overhead increases. The EXAM study showed that 20 hospitals achieved near-optimal performance, with most gains realized by the first 8-10 participants.
Can federated learning work with medical imaging models?
Yes, and imaging is one of FL's strongest healthcare applications. The Intel/UPenn brain tumor study demonstrated FL across 71 institutions for MRI segmentation. The main consideration is that imaging models are large (50-200M parameters), so communication optimization techniques like gradient compression become essential.
How do you handle hospitals joining or leaving the federation mid-training?
Asynchronous FL protocols handle dynamic participation. When a new hospital joins, it receives the current global model and begins contributing from the next round. When a hospital leaves, the aggregation simply uses fewer participants. The Flower framework handles this natively through its client management system.
Conclusion
Federated learning represents the most practical path to multi-institutional healthcare AI today. It solves the fundamental tension between data-hungry models and privacy regulations by keeping patient data where it belongs — at the institution that collected it — while still enabling collaborative model training that benefits every participant.
The technology is maturing rapidly. NVIDIA FLARE and Flower have made implementation accessible to any health system with basic ML infrastructure. The EXAM and Intel/UPenn studies have demonstrated clinical-grade performance at scale. And the privacy framework — combining FL with differential privacy and secure aggregation — provides defense-in-depth that satisfies even the most conservative compliance teams.
The organizations building FL capabilities now will have a significant advantage as healthcare AI moves from single-institution pilots to network-scale deployments. The question is not whether your hospital will participate in federated learning, but whether you will be ready when the invitation comes.