Healthcare IT doesn't get nights off. When a hospital runs 24/7/365, the technology that supports it must too. But the engineers who maintain that technology are human. They need sleep, they need weekends, and they burn out when on-call practices are designed around the system's needs without considering theirs.
This guide covers on-call rotation design, escalation policies, compensation models, and burnout prevention strategies specifically for healthcare IT teams. The goal: reliable 24/7 coverage that doesn't destroy the humans providing it.
Why Healthcare On-Call Is Different
Most SRE on-call guides assume you can deprioritize after business hours. E-commerce slows at midnight. SaaS products have maintenance windows. Healthcare has neither. Emergency departments are busiest at night. Lab systems process overnight batch runs. Clinical staff access the EHR at all hours.
Healthcare on-call differs in three key ways:
- No true off-peak. While patient volume ebbs overnight, critical systems must remain available. A lab result delay at 3 AM affects a patient in the ICU just as much as one at 3 PM.
- Clinical knowledge requirements. The on-call engineer needs to understand not just the technology but the clinical workflow impact. Knowing the FHIR server is slow is insufficient; knowing that slow FHIR queries delay medication reconciliation in the ED is essential.
- Regulatory consequences. EHR downtime isn't just a service disruption; it triggers HIPAA assessment requirements if PHI access is affected and may require regulatory reporting if the downtime exceeds certain thresholds.
Rotation Design That Works
The Primary + Secondary Model
Every on-call rotation needs at minimum two layers: a primary responder and a secondary (backup) responder. For healthcare, add a third layer: the engineering manager as escalation backstop.
| Role | Responsibility | Response SLA | Escalation Trigger |
|---|---|---|---|
| Primary On-Call | First responder for all pages. Triages, investigates, resolves or escalates. | Acknowledge within 5 min | Auto-escalate to secondary if no ACK in 5 min |
| Secondary On-Call | Backup responder. Available if primary doesn't acknowledge or needs help. | Acknowledge within 10 min | Auto-escalate to manager if no ACK in 15 min total |
| Manager Escalation | Ensures someone is engaged. Coordinates cross-team if needed. Doesn't debug — manages. | Acknowledge within 15 min | CIO notification if P1 unresolved after 30 min |
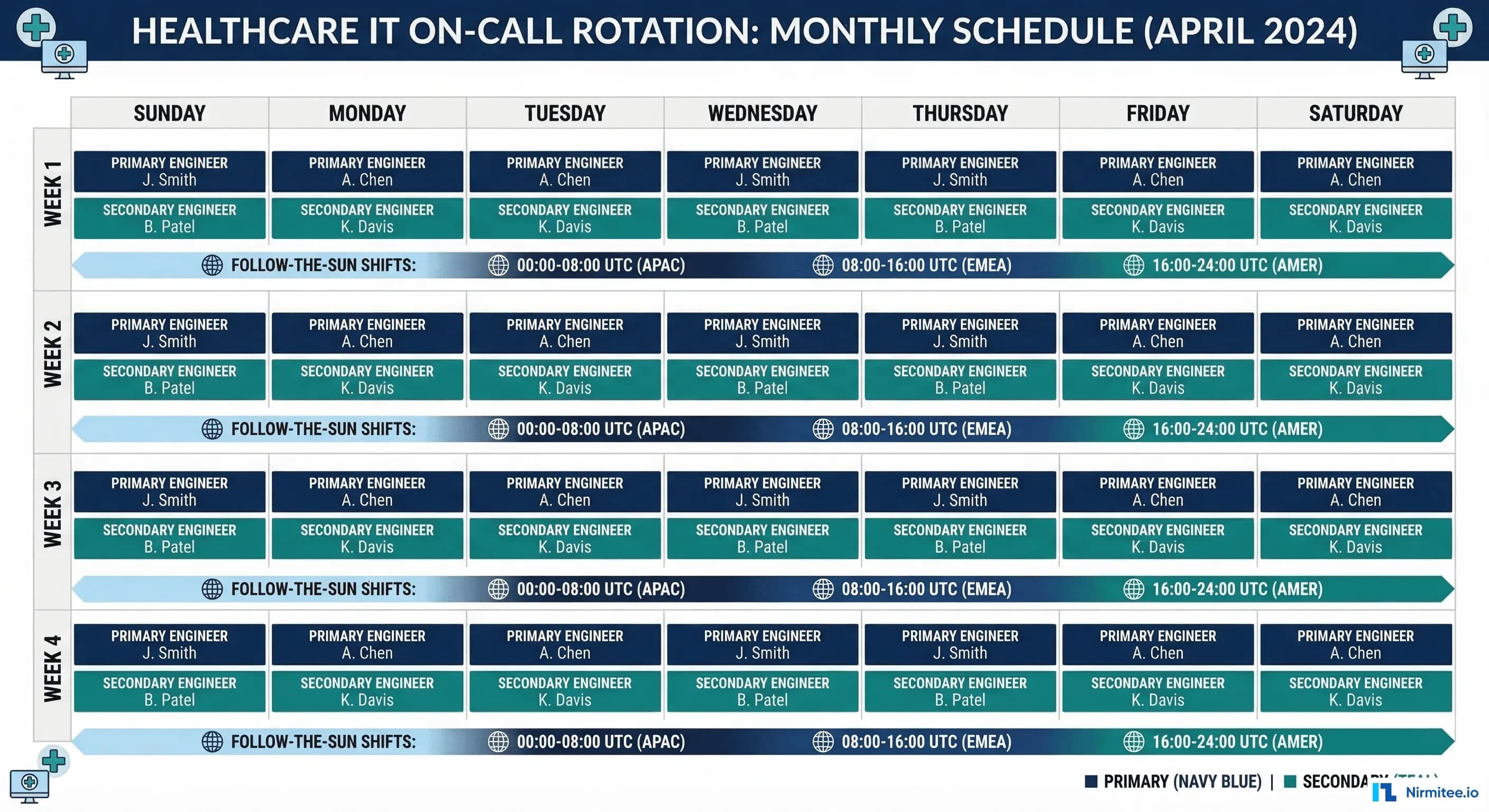
Weekly Rotations, Not Daily
Daily rotations create context-switching overhead. The engineer who was on-call last night doesn't carry the context to the next on-call engineer about the flaky Mirth channel they nursed through the evening. Weekly rotations provide continuity:
- Monday 9 AM to Monday 9 AM — clean handoff during business hours when both engineers are awake and available for context transfer.
- 30-minute handoff meeting — outgoing on-call briefs incoming on-call: open incidents, systems under watch, known risks for the coming week (scheduled deployments, certificate expirations, vendor maintenance windows).
- Handoff document — standardized template covering: current incidents, systems on watch, upcoming changes, vendor contacts needed.
# PagerDuty on-call rotation (Terraform)
resource "pagerduty_schedule" "clinical_platform" {
name = "Clinical Platform On-Call"
time_zone = "America/New_York"
layer {
name = "Primary"
start = "2026-01-06T09:00:00-05:00"
rotation_virtual_start = "2026-01-06T09:00:00-05:00"
rotation_turn_length_seconds = 604800 # 7 days
users = [
pagerduty_user.engineer_a.id,
pagerduty_user.engineer_b.id,
pagerduty_user.engineer_c.id,
pagerduty_user.engineer_d.id,
]
}
layer {
name = "Secondary"
start = "2026-01-06T09:00:00-05:00"
rotation_virtual_start = "2026-01-13T09:00:00-05:00" # Offset by 1 week
rotation_turn_length_seconds = 604800
users = [
pagerduty_user.engineer_b.id,
pagerduty_user.engineer_c.id,
pagerduty_user.engineer_d.id,
pagerduty_user.engineer_a.id,
]
}
}
# Escalation policy
resource "pagerduty_escalation_policy" "clinical_platform" {
name = "Clinical Platform Escalation"
num_loops = 2
rule {
escalation_delay_in_minutes = 5
target {
type = "schedule_reference"
id = pagerduty_schedule.clinical_platform.id # Primary layer
}
}
rule {
escalation_delay_in_minutes = 10
target {
type = "schedule_reference"
id = pagerduty_schedule.clinical_platform.id # Secondary layer
}
}
rule {
escalation_delay_in_minutes = 15
target {
type = "user_reference"
id = pagerduty_user.eng_manager.id
}
}
}Follow-the-Sun for Multi-Timezone Organizations
For health systems with teams across multiple timezones (or healthcare technology companies with distributed engineering), follow-the-sun eliminates overnight pages entirely:
| Timezone | Coverage Hours | Team | Handoff |
|---|---|---|---|
| US East (ET) | 7 AM - 3 PM ET | Boston/NYC team | 3 PM ET handoff to US West |
| US West (PT) | 12 PM - 8 PM PT (3-11 PM ET) | Seattle/SF team | 8 PM PT handoff to APAC |
| Asia Pacific (IST/SGT) | 8 AM - 4 PM IST (10:30 PM - 6:30 AM ET) | India/Singapore team | 4 PM IST handoff to US East |
The key requirement for follow-the-sun: each team must have the same access, runbooks, and authority. If the APAC team can't restart a Mirth channel or roll back a deployment, follow-the-sun creates a secondary problem: the night team pages the day team anyway.
Escalation Policies by Severity
Different severities need different escalation behaviors. A P4 cosmetic issue should never wake anyone up. A P1 patient-safety incident should reach the incident commander within minutes.
# Escalation policy YAML (for documentation/configuration)
# Adapt to your PagerDuty/OpsGenie configuration
escalation_policies:
P1_critical:
description: "Patient safety impact — core clinical systems down"
steps:
- action: page_immediately
target: primary_on_call
channels: [sms, phone_call, push_notification]
- wait: 5_minutes
if_no_ack: page_secondary
channels: [sms, phone_call, push_notification]
- wait: 10_minutes
if_no_ack: page_manager
channels: [phone_call]
- wait: 15_minutes
if_no_ack: page_cio
channels: [phone_call]
parallel_actions:
- create_slack_channel: "inc-{date}-{short_desc}"
- notify_clinical_it_lead: true
- update_help_desk_script: true
auto_bridge: true # Auto-open conference bridge
P2_high:
description: "Clinical workflow disruption — workaround available"
steps:
- action: page_primary
channels: [push_notification, sms]
- wait: 15_minutes
if_no_ack: page_secondary
channels: [sms, phone_call]
- wait: 30_minutes
if_no_ack: page_manager
channels: [phone_call]
parallel_actions:
- notify_slack: "#clinical-platform-alerts"
P3_medium:
description: "Degraded performance — no direct patient impact"
steps:
- action: notify_slack
channel: "#clinical-platform-alerts"
- wait: 2_hours
if_no_ack: page_primary
channels: [push_notification]
business_hours_only: false # Still notify 24/7, but don't page
P4_low:
description: "Minor/cosmetic — no workflow impact"
steps:
- action: create_ticket
queue: "clinical-platform-backlog"
- action: notify_slack
channel: "#clinical-platform-general"
business_hours_only: true # Batch for morning reviewCompensation: Paying for the Burden
On-call without compensation breeds resentment. Engineers who feel they're giving free labor to the hospital will leave for companies that don't require on-call. Healthcare IT already faces talent retention challenges; underpaying on-call makes it worse.
Compensation Models
| Model | How It Works | Pros | Cons |
|---|---|---|---|
| Flat weekly stipend | $500-1,500/week for carrying the pager | Predictable cost; simple to administer | Doesn't differentiate quiet weeks from nightmare weeks |
| Per-incident bonus | $100-300 per incident handled outside business hours | Compensates proportionally to disruption | Creates perverse incentive to not fix underlying issues |
| Comp time | 1 day off for each week on-call; additional day if paged > 3 times at night | Promotes recovery; prevents cumulative fatigue | Team must be large enough to absorb the absence |
| Hybrid | $500/week base + $150/night incident + 1 comp day | Balances predictability with proportionality | More complex to administer |
The hybrid model is the recommendation for healthcare IT teams. The base stipend recognizes the burden of carrying the pager (even quiet weeks restrict your freedom). The per-incident bonus compensates for actual sleep disruption. The comp day enforces recovery.
Burnout Prevention: The Numbers That Matter
On-call burnout isn't caused by a single bad night. It's caused by accumulated sleep debt, lack of recovery time, and the feeling that the pager burden is unfair or unmanageable. Track these metrics to detect burnout before it causes attrition:
Key Burnout Indicators
| Metric | Healthy | Warning | Critical |
|---|---|---|---|
| Pages per on-call night | 0-2 | 3-5 | > 5 (fix underlying issues) |
| On-call frequency | 1 week in 4+ | 1 week in 3 | 1 week in 2 (hire or restructure) |
| Sleep interruptions per week | 0-1 | 2-3 | > 3 (alert fatigue or system instability) |
| Mean time between pages (overnight) | > 4 hours | 2-4 hours | < 2 hours (clustering indicates single root cause) |
| On-call NPS (team survey) | > +20 | 0 to +20 | < 0 (morale problem — act immediately) |
The 1-in-4 Rule
No engineer should be on-call more than one week in four. This means your on-call pool needs at minimum 4 qualified engineers. With a team of 6-8, you achieve 1-in-6 or 1-in-8 rotation, which is sustainable long-term.
If your team has only 3 engineers, you cannot run a healthy on-call rotation. Options:
- Hire a 4th engineer — the cost of the hire is less than the cost of the attrition that 1-in-3 rotation causes.
- Share on-call across teams — combine clinical platform and integration team into a single on-call pool with shared runbooks.
- Use a managed service — outsource first-level triage to a NOC that follows your runbooks and escalates to your team only when engineering judgment is needed.
Toil Budgets
Google's SRE model caps toil at 50% of engineering time. For on-call, this translates to: if more than half of on-call pages require repetitive manual actions (restart channel, clear queue, rotate certificate), those actions must be automated.
# Toil tracking template (Python/Pandas)
import pandas as pd
from datetime import datetime
# Monthly toil report
toil_data = [
{"date": "2026-03-01", "incident": "Mirth ADT channel stopped", "action": "Restart channel", "toil": True, "minutes": 15, "automatable": True},
{"date": "2026-03-03", "incident": "FHIR server OOM", "action": "Scale pods + investigate", "toil": False, "minutes": 45, "automatable": False},
{"date": "2026-03-05", "incident": "Certificate expiry warning", "action": "Rotate cert manually", "toil": True, "minutes": 30, "automatable": True},
{"date": "2026-03-07", "incident": "Mirth ADT channel stopped", "action": "Restart channel", "toil": True, "minutes": 15, "automatable": True},
{"date": "2026-03-10", "incident": "DB connection pool full", "action": "Kill idle connections", "toil": True, "minutes": 20, "automatable": True},
{"date": "2026-03-12", "incident": "New integration mapping issue", "action": "Debug + fix mapping", "toil": False, "minutes": 90, "automatable": False},
]
df = pd.DataFrame(toil_data)
toil_pct = df[df['toil']]['minutes'].sum() / df['minutes'].sum() * 100
automatable_minutes = df[df['automatable']]['minutes'].sum()
print(f"Toil percentage: {toil_pct:.0f}%")
print(f"Automatable toil: {automatable_minutes} minutes/month")
print(f"Top toil sources:")
for incident, group in df[df['toil']].groupby('incident'):
print(f" {incident}: {len(group)} occurrences, {group['minutes'].sum()} min total")Clinical IT vs Infrastructure On-Call
Larger health systems split on-call into two tracks. Understanding the boundary prevents misrouted pages:
| Domain | Clinical IT On-Call | Infrastructure On-Call |
|---|---|---|
| Scope | EHR application issues, clinical workflows, interface mappings, user access | Servers, networks, databases, Kubernetes, cloud platform, security |
| Common pages | Mirth channel stopped, FHIR query errors, clinical report failures, interface mapping issues | Node unhealthy, disk full, database replica lag, certificate expiry, network partition |
| Required knowledge | HL7v2/FHIR standards, clinical workflows, EHR configuration, Mirth Connect | Linux, Kubernetes, PostgreSQL, networking, cloud services, security |
| Vendor escalation | Epic/Oracle Health support, interface vendor support | Cloud provider support, hardware vendor support |
The critical handoff point: when a Mirth channel stops because the downstream server is unreachable, clinical IT identifies the symptom (Mirth error) and infrastructure on-call investigates the cause (network issue, server down). Establish clear escalation paths between the two tracks.
EHR Vendor Support Escalation
Your on-call engineer will sometimes need vendor support. Pre-negotiate and document these escalation paths before the 3 AM incident.
Epic Support Tiers
| Tier | Access Method | Response SLA | When to Use |
|---|---|---|---|
| Tier 1 — Support Web | Epic UserWeb ticket | Next business day | Configuration questions, non-urgent bugs |
| Tier 2 — Priority | Phone: 608-271-9000 | 4 hours | Production issue affecting clinical workflows |
| Tier 3 — Emergency | Emergency hotline (per contract) | 1 hour | System-wide outage, patient safety impact |
Oracle Health (Cerner) Support Tiers
| Tier | Access Method | Response SLA | When to Use |
|---|---|---|---|
| Standard | uCern portal ticket | Next business day | Configuration, non-urgent issues |
| High | Phone: 888-274-3672 | 4 hours | Production workflow disruption |
| Critical | Critical escalation line (per contract) | 1 hour | System-wide outage, data integrity risk |
Store these contact details in your runbook repository. During a P1 incident, your on-call engineer should open a vendor case within 5 minutes, not spend 15 minutes searching for a phone number.
On-Call Health Scorecard
Track on-call health monthly and share results with engineering leadership. This scorecard makes on-call burden visible and creates accountability for improvement.
# On-call health scorecard generator
import json
from datetime import datetime
def generate_scorecard(month_data: dict) -> dict:
"""
Generate monthly on-call health scorecard.
month_data keys:
- total_pages: int
- overnight_pages: int (10 PM - 7 AM)
- p1_incidents: int
- mtta_minutes: float (mean time to acknowledge)
- mttr_minutes: float (mean time to resolve)
- toil_percentage: float
- engineer_nps: int (-100 to 100)
- rotation_frequency: str (e.g., "1 in 4")
- pages_per_night: float (average)
"""
scorecard = {
"month": month_data.get("month", datetime.now().strftime("%Y-%m")),
"metrics": {
"pages_per_night": {
"value": month_data["pages_per_night"],
"target": "< 2",
"status": "green" if month_data["pages_per_night"] < 2
else "yellow" if month_data["pages_per_night"] < 5
else "red"
},
"mtta": {
"value": f"{month_data['mtta_minutes']:.1f} min",
"target": "< 5 min",
"status": "green" if month_data["mtta_minutes"] < 5
else "yellow" if month_data["mtta_minutes"] < 15
else "red"
},
"engineer_nps": {
"value": month_data["engineer_nps"],
"target": "> +20",
"status": "green" if month_data["engineer_nps"] > 20
else "yellow" if month_data["engineer_nps"] > 0
else "red"
},
"toil_percentage": {
"value": f"{month_data['toil_percentage']:.0f}%",
"target": "< 50%",
"status": "green" if month_data["toil_percentage"] < 30
else "yellow" if month_data["toil_percentage"] < 50
else "red"
}
},
"action_items": []
}
# Auto-generate action items from red/yellow metrics
for metric_name, metric in scorecard["metrics"].items():
if metric["status"] == "red":
scorecard["action_items"].append(
f"URGENT: {metric_name} is {metric['value']} (target: {metric['target']})"
)
elif metric["status"] == "yellow":
scorecard["action_items"].append(
f"WATCH: {metric_name} is {metric['value']} (target: {metric['target']})"
)
return scorecard
# Example usage
result = generate_scorecard({
"month": "2026-03",
"total_pages": 87,
"overnight_pages": 23,
"p1_incidents": 1,
"mtta_minutes": 3.2,
"mttr_minutes": 28.0,
"toil_percentage": 42,
"engineer_nps": 35,
"rotation_frequency": "1 in 5",
"pages_per_night": 1.1
})
print(json.dumps(result, indent=2))Frequently Asked Questions
What's the minimum team size for sustainable healthcare on-call?
Four engineers minimum for a 1-in-4 rotation. With three engineers, you're at 1-in-3, which research shows leads to burnout within 6-12 months. If you can't hire a fourth, combine on-call pools across related teams or engage a managed NOC for first-level triage. Your alert fatigue reduction efforts directly impact how many engineers you need — fewer alerts means less on-call burden per rotation.
Should on-call engineers also do sprint work during their on-call week?
Yes, but reduce their sprint commitment by 50%. On-call engineers should work on low-priority, interruptible tasks: documentation updates, runbook maintenance, tech debt cleanup, alert tuning. Never assign them to critical-path sprint stories that block other team members if interrupted. Some teams use the on-call week for "improvement work" — fixing the issues that cause on-call pages, which creates a virtuous cycle.
How do we handle on-call during holidays?
Holiday on-call requires premium compensation (2-3x the normal on-call stipend is standard). Allow engineers to volunteer for holiday coverage first; many are willing if the compensation is right. If no volunteers, rotate holidays fairly across the team year-over-year. Track holiday on-call assignments to ensure no one is consistently stuck with the same holidays. Some teams offer "holiday swap" — work Christmas this year, guaranteed Thanksgiving off next year.
What do we do when the on-call engineer is out sick?
The secondary on-call automatically becomes primary. The engineering manager takes secondary until someone from the pool can volunteer. This is another reason the 1-in-4 minimum matters: with 4 people, one being sick still leaves 3 to cover. Have a documented "emergency coverage" process that doesn't require the sick engineer to find their own replacement.
How should we handle cross-team incidents that span clinical IT and infrastructure?
Establish a "bridge" protocol: both on-call engineers join a shared incident channel. Designate one as incident commander based on where the root cause appears to be. If unclear, the infrastructure on-call takes command (most cross-team incidents have an infrastructure root cause). For building the incident management framework that coordinates these cross-team responses, see our Healthcare Incident Management guide, and for testing your cross-team resilience, our Chaos Engineering for Healthcare guide covers game day exercises.
Conclusion
On-call is a necessary part of running healthcare IT systems. But it doesn't have to be a sentence. Well-designed rotations, clear escalation policies, fair compensation, and vigilant burnout monitoring transform on-call from a dreaded burden into a manageable aspect of the job. The engineers who built and maintain your clinical systems are your most valuable asset. Protect them from the pager, and they'll protect the systems that protect patients.
Start by measuring where you are today: pages per night, rotation frequency, engineer NPS. Then work systematically through the improvements in this guide. Within a quarter, your on-call will be demonstrably healthier, and your retention will reflect it. For the post-incident learning process that closes the loop on every on-call incident, see our guide on Post-Incident Reviews for Healthcare Systems.