The question comes up in every health IT architecture review: Should we use openEHR or FHIR? It is the wrong question. The right question is: how do we run both together?
For a concrete application of these patterns in a specific clinical domain, see how we approached building a mental health platform on openEHR.
openEHR and FHIR solve different problems. FHIR is an interoperability standard — it defines how systems exchange health data through REST APIs. OpenEHR is a clinical data modeling standard — it defines how health data is structured, stored, and queried for long-term clinical use. Choosing between them is like choosing between TCP/IP and a database schema. You need both, and the architecture for connecting them determines whether your platform succeeds or collapses under its own complexity.
This article documents four architecture patterns for running openEHR and FHIR together — drawn from published implementations across hospital networks, digital health platforms, and national health exchanges. For each pattern, it covers when it works, when it fails, and how to choose between them.
This is one of the few detailed side-by-side comparisons of these patterns available today.
Why You Need Both (Not Either/Or)
Before diving into patterns, it is critical to understand what each standard actually does well — and where it falls short:
What FHIR Does Well
- Interoperability — FHIR is the lingua franca for exchanging health data between systems. Epic, Cerner, Oracle Health, and every major EHR vendor expose FHIR APIs.
- Developer experience — REST APIs, JSON, OAuth 2.0, well-documented resources. A JavaScript developer can build a FHIR app in a day.
- Ecosystem — SMART on FHIR, CDS Hooks, Bulk FHIR, US Core Implementation Guides, Da Vinci IGs. The tooling is mature and growing.
- Regulatory backing — US ONC mandates, ABDM in India, EHDS in Europe all reference FHIR.
Where FHIR Falls Short
- Clinical data modeling — FHIR resources are generic by design. An
Observationcan hold a blood pressure, a survey answer, or a genetic variant. There is no built-in clinical structure beyond the base resource. - Longitudinal storage — FHIR was designed for exchange, not storage. Using a FHIR server as your primary clinical data repository works for simple cases but struggles with complex clinical documents, temporal queries, and archetype-level governance.
- Clinical modeling governance — FHIR profiles and Implementation Guides provide some structure, but there is no equivalent of openEHR's Clinical Knowledge Manager for community-governed, reusable clinical models.
What openEHR Does Well
- Two-level modeling — the reference model (technical structure) and archetypes (clinical knowledge) are separated. Clinicians define what data means; engineers define how it is stored. This separation is powerful.
- Longitudinal clinical data — openEHR was designed to be a lifelong, vendor-neutral clinical data repository. Compositions, versioned entries, and AQL make it excellent for longitudinal patient records.
- Clinical Knowledge Manager — a global, peer-reviewed library of reusable clinical models (archetypes). Over 600 archetypes covering vital signs, diagnoses, medications, procedures, and more.
- AQL (Archetype Query Language) — a query language designed specifically for clinical data. It understands archetypes, compositions, and clinical hierarchies natively.
Where openEHR Falls Short
- Interoperability — openEHR has no widely adopted API standard for cross-system exchange. The REST API spec exists but is not supported by Epic, Cerner, or any major US EHR vendor.
- Developer ecosystem — the developer tooling is improving (EHRbase, Better, Medblocks), but is still small compared to FHIR's ecosystem. Finding openEHR developers is harder than finding FHIR developers.
- Regulatory adoption — outside of Europe, Australia, and parts of Asia, openEHR has limited regulatory backing compared to FHIR.
The conclusion is clear: FHIR for interoperability, openEHR for clinical data modeling and storage. The question becomes: how do you connect them?
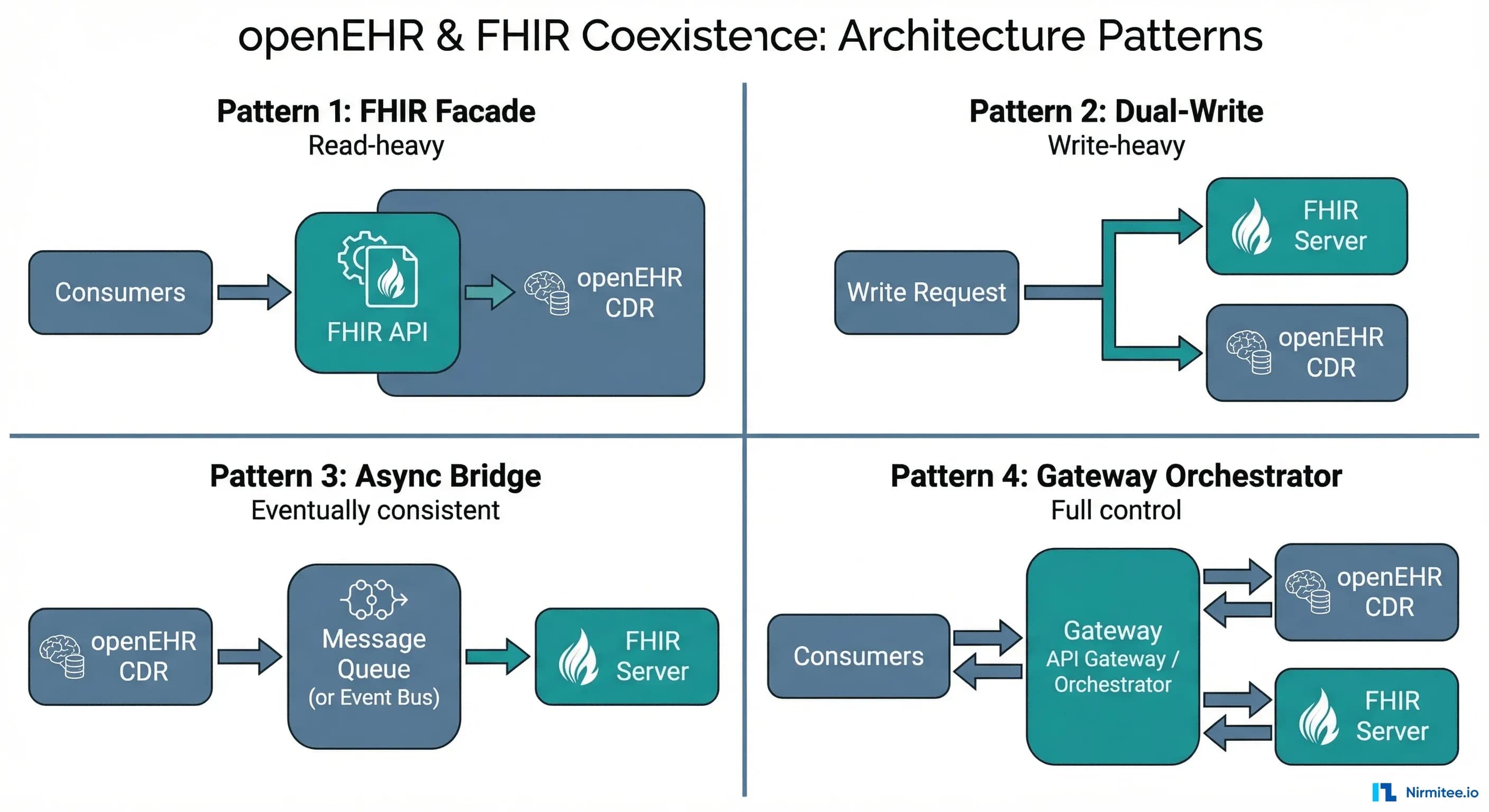
Pattern 1 — FHIR Facade over openEHR CDR
How It Works
openEHR is the single source of truth. All clinical data is stored as openEHR Compositions in the CDR (Clinical Data Repository). A facade layer sits in front and exposes standard FHIR R4 REST endpoints. When a consumer sends GET /Observation?patient=123&code=85354-9, the facade:
- Translates the FHIR query into an AQL query against the openEHR CDR
- Executes the AQL query and retrieves matching Compositions
- Maps the openEHR data (paths, archetypes, coded values) into FHIR resources
- Returns standard FHIR JSON to the consumer
For write operations, the process reverses: incoming FHIR resources are mapped to openEHR Compositions and committed to the CDR.
Implementation Details
The mapping layer is the core engineering challenge. Each FHIR resource type needs a bidirectional mapper to one or more openEHR templates:
- FHIR Patient maps to openEHR
EHRobject + demographic Composition - FHIR Observation maps to Compositions using archetypes like
openEHR-EHR-OBSERVATION.blood_pressure.v2 - FHIR MedicationRequest maps to
openEHR-EHR-INSTRUCTION.medication_order.v3 - FHIR Condition maps to
openEHR-EHR-EVALUATION.problem_diagnosis.v1
The EHRbase FHIR Bridge project (open source) implements exactly this pattern. It provides pre-built mappers for common FHIR resources to openEHR archetypes. However, in production, you will inevitably need custom mappers for your specific templates.
When to Use
- openEHR is already your primary CDR, and you need to expose FHIR APIs for external consumption
- You want a single data store (openEHR) with FHIR as the interoperability layer
- Read-heavy workloads — consumers mostly query via FHIR, writes happen through internal clinical apps
When to Avoid
- Write-heavy FHIR workloads — the translation overhead on every write adds latency
- You need full FHIR server capabilities (Subscriptions, Bulk Export, US Core compliance) — facades often implement a subset
- Your team does not have openEHR expertise to maintain the mapping layer
Production Gotchas
- Pagination: FHIR pagination (Bundle with
nextlinks) and AQL pagination (LIMIT/OFFSET) have different semantics. Your facade must translate cleanly. - Search parameters: FHIR defines ~50 search parameters per resource. You will not map all of them. Document which ones are supported and return
OperationOutcomefor unsupported parameters. - References: FHIR uses resource references (
Patient/123). OpenEHR uses EHR IDs and composition UIDs. The facade must maintain a reference mapping table. - Terminology mapping: openEHR may store codes in SNOMED while FHIR consumers expect LOINC. The facade may need to include terminology translation — do not underestimate this.
Pattern 2 — Dual-Write to FHIR Server and openEHR CDR
How It Works
Both a FHIR server (HAPI FHIR, Azure Health Data Services, Google Cloud Healthcare API) and an openEHR CDR (EHRbase, Better) run in production. When clinical data is captured, a write orchestrator sends it to both systems simultaneously.
Each system stores the data in its native format. The FHIR server holds FHIR resources optimized for interoperability, SMART app queries, and regulatory compliance. The openEHR CDR holds Compositions optimized for longitudinal clinical analysis, AQL queries, and clinical modeling governance.
Implementation Details
The write orchestrator is the critical component. It must:
- Accept clinical data from the source application (could be in either format or a neutral format)
- Transform to FHIR resources and commit to the FHIR server
- Transform to openEHR Compositions and commit to the CDR
- Handle partial failures — what if the FHIR write succeeds but openEHR fails?
- Maintain correlation IDs linking the FHIR resource to its openEHR Composition counterpart
The consistency problem: dual-write without distributed transactions means eventual consistency at best. If the FHIR write succeeds and the openEHR write fails (or vice versa), you have data drift. You need a reconciliation process:
- A nightly comparison job that queries both stores and flags discrepancies
- An idempotent retry queue for failed writes
- A decision on which store is authoritative when conflicts arise
When to Use
- You need the full capabilities of both — complete FHIR server features (Subscriptions, Bulk Export, SMART launch) AND full openEHR features (AQL, versioned compositions, archetype governance)
- Different teams consume different stores — the interoperability team uses FHIR, the clinical analytics team uses openEHR
- You are migrating from FHIR-only to openEHR and need both to run during the transition
When to Avoid
- Small teams — maintaining two data stores, two sets of mappings, and a consistency monitor is operationally expensive
- Strong consistency requirements — if you cannot tolerate any window of inconsistency, dual-write without distributed transactions is risky
- Cost-sensitive environments — you are paying for two data stores, two sets of infrastructure, and the orchestration layer
Production Gotchas
- ID correlation: You need a mapping table linking FHIR resource IDs to openEHR composition UIDs and EHR IDs. This table becomes critical infrastructure — lose it, and you cannot correlate across stores.
- Schema evolution: When an openEHR template changes, both the openEHR and FHIR mappings need to update simultaneously. Coordinate releases carefully.
- Storage cost: You are storing the same clinical data twice. For large health systems, this adds up. Run cost projections before committing.
Pattern 3 — Asynchronous Bridge via Event Bus
How It Works
One system is primary (usually openEHR), and changes are propagated to the other (FHIR) asynchronously via an event bus (Kafka, RabbitMQ, AWS SNS/SQS, Google Pub/Sub).
When a Composition is committed to the openEHR CDR, a Change Data Capture (CDC) mechanism emits an event. A bridge consumer reads the event, maps the Composition to one or more FHIR resources, validates them, and writes to the FHIR server. The propagation happens asynchronously — typically 2-30 seconds after the openEHR write.
Implementation Details
The CDC mechanism depends on your CDR:
- EHRbase: Use database-level CDC (Debezium on PostgreSQL) or application-level hooks to capture composition changes
- Better Platform: Use the webhook/notification mechanism to trigger on composition commits
- Custom CDR: Implement a change log table or event outbox pattern
The bridge consumer is the mapping engine. For each incoming composition event:
- Retrieve the full Composition from the openEHR CDR
- Identify the template and extract structured data using the flat/structured format
- Map to FHIR resources using template-specific mappers
- Validate against the target FHIR profile (US Core, IPS, etc.)
- POST/PUT to the FHIR server
- Record the mapping in the correlation table
The reverse direction (FHIR to openEHR) is also possible but less common. You would subscribe to FHIR Subscriptions or poll the FHIR server for changes.
When to Use
- openEHR is the primary CDR, and you need FHIR representations for downstream consumers (patient portals, mobile apps, partner integrations)
- You can tolerate eventual consistency (2-30 second delay) between stores
- You want decoupled systems — the openEHR CDR does not need to know about FHIR, and vice versa
- You need robust error handling — event buses give you dead letter queues, retry policies, and replayability for free
When to Avoid
- Real-time FHIR queries — if a consumer needs the FHIR resource immediately after the openEHR write, async adds unacceptable latency
- Bidirectional sync with high write volume on both sides — circular event loops become a nightmare to debug
Production Gotchas
- Ordering guarantees: Events for the same patient must be processed in order. Use patient ID as the partition key in Kafka to ensure per-patient ordering.
- Idempotency: The bridge consumer must be idempotent. If an event is replayed (which Kafka allows), the FHIR server should not create duplicate resources. Use conditional creates (
If-None-Exist) or PUT with deterministic IDs. - Schema evolution: When the openEHR template changes, the bridge consumer mapping must update. Deploy the new consumer before committing compositions with the new template version.
- Monitoring: Monitor the lag between the openEHR write timestamp and the FHIR resource creation timestamp. Alert if lag exceeds your SLA (typically 30-60 seconds max).
Pattern 4 — Unified Gateway Orchestrator
How It Works
A unified API gateway sits in front of both the openEHR CDR and FHIR server. Consumers interact with a single API surface that abstracts the underlying dual-backend complexity. The gateway decides which backend to route each request to — or routes to both.
This is the most architecturally complex pattern, but the most powerful. The gateway provides:
- Unified query API — consumers query one endpoint; the gateway routes to the optimal backend (AQL for complex clinical queries, FHIR Search for standard interoperability queries)
- Transactional dual-write — the gateway orchestrates writes to both backends within a saga pattern, with compensating transactions on failure
- Unified auth — a single SMART on FHIR authorization layer that works for both backends
- Format negotiation — consumers can request data in FHIR JSON, openEHR flat format, or a custom clinical format via content negotiation
Implementation Details
The gateway has four internal layers:
- API Layer: Exposes REST endpoints that look like FHIR but with extensions for openEHR-native queries. Example:
GET /Observation?patient=123routes to FHIR, whilePOST /aqlroutes to openEHR. - Query Router: Analyzes the incoming request and determines the optimal backend. Simple FHIR searches go to the FHIR server. Complex analytical queries (time-series analysis, cross-composition joins) go to openEHR via AQL.
- Write Orchestrator: Implements the saga pattern for dual-writes. Step 1: Write to primary (openEHR). Step 2: map and write to secondary (FHIR). If step 2 fails: queue for async retry (do not roll back step 1).
- Auth and Consent: A unified SMART on FHIR authorization server that issues tokens valid for both backends. Consent policies are evaluated once at the gateway level.
Notably, when
- You are building a health data platform that must serve multiple consumer types: clinical apps (need openEHR depth), patient-facing apps (need FHIR simplicity), analytics (need AQL), and external partners (need standard FHIR)
- You want to shield consumers from backend complexity — they should not need to know whether data comes from openEHR or FHIR
- You have the engineering team size (5-8 developers) and organizational commitment to maintain a custom platform layer
When to Avoid
- MVPs and startups — this pattern is over-engineered for early-stage products. Start with Pattern 1 or 3 and evolve.
- Teams under 4 developers — the operational burden of maintaining a gateway, two backends, saga orchestration, and monitoring is significant
- When only one standard is actually needed — if your consumers only need FHIR, do not build a gateway just to have openEHR behind it
Production Gotchas
- Gateway as single point of failure: The gateway must be deployed as a horizontally scalable, highly available service. If it goes down, all access to both backends is lost.
- Saga complexity: Distributed sagas with compensating transactions are notoriously hard to debug. Invest heavily in distributed tracing (OpenTelemetry) from day one.
- Version coupling: The gateway couples the release cycles of both backends. A breaking change in EHRbase or HAPI FHIR requires coordinated gateway updates.
How a Blood Pressure Reading Flows Through Each Pattern
The best way to understand the practical differences is to trace the same data point — a patient's blood pressure reading (systolic 120, diastolic 80 mmHg) — through each pattern:
Pattern 1 (Facade)
Doctor records BP → Clinical app commits a Composition using archetype openEHR-EHR-OBSERVATION.blood_pressure.v2 → Data stored in openEHR CDR → Patient portal sends GET /Observation?code=85354-9 → Facade translates to AQL → AQL returns data → Facade maps to FHIR Observation with two components (systolic, diastolic) → Returns JSON to portal. Latency: real-time. Storage: single (openEHR).
Pattern 2 (Dual-Write)
Doctor records BP → Write orchestrator maps to both formats → Commits Composition to openEHR CDR AND POSTs Observation to FHIR server → Both stores have the data in their native format → Consumers query whichever store suits their need. Latency: real-time. Storage: dual. Risk: write failure in one store.
Pattern 3 (Async Bridge)
Doctor records BP → Clinical app commits Composition to openEHR CDR → CDC captures the commit → Event emitted to Kafka topic composition.created → Bridge consumer picks up event → Maps blood pressure archetype to FHIR Observation → POSTs to FHIR server → Available for FHIR queries. Latency: 2-30 seconds. Storage: dual (eventual). Most resilient to failures.
Pattern 4 (Gateway)
Doctor records BP → Clinical app sends to gateway API → Gateway writes to openEHR CDR (primary) → Gateway maps and writes to FHIR server (secondary) → If FHIR write fails, queued for retry → Consumer queries gateway → Gateway routes to optimal backend based on query type. Latency: real-time. Storage: dual (strongly consistent for reads). Most flexible.
How to Choose — The Decision Flowchart
Run through these questions in order:
- Do you actually need both openEHR and FHIR? If your use case is pure interoperability (patient apps, data exchange), FHIR alone is sufficient. If your use case is pure clinical data modeling (internal CDR, research), openEHR alone may suffice. Only proceed if you genuinely need both.
- Is openEHR your primary CDR? If yes, the data lives in openEHR, and you are exposing FHIR for interoperability. Choose between Pattern 1 (real-time) and Pattern 3 (async).
- Do both systems need write access? If yes, you are in dual-write territory. Choose between Pattern 2 (simpler, eventual consistency) and Pattern 4 (complex, strong consistency).
- Can you tolerate eventual consistency? If yes, Pattern 2 or 3. If no, Pattern 1 or 4.
Pattern Comparison Matrix
For quick reference, here is how the four patterns compare across the dimensions that matter most in production:
- Complexity: Pattern 1 is the simplest (one data store, one mapping layer). Pattern 4 is most complex (saga orchestration, dual backends, unified auth).
- Data consistency: Patterns 1 and 4 offer strong consistency. Patterns 2 and 3 are eventually consistent.
- Team size: Pattern 1 can be maintained by 2-3 developers. Pattern 4 realistically needs 5-8 dedicated platform engineers.
- Production maturity: Patterns 1 and 3 are the most common in documented production deployments. Pattern 4 is rare — most organizations that need it build it custom. Pattern 2 is emerging, often as a migration strategy.
Practical Lessons from openEHR + FHIR Integrations
After deploying these patterns across multiple health systems, here are the lessons that do not fit neatly into any single pattern:
- Start with Pattern 1, evolve to Pattern 3. Most teams should start with a FHIR Facade. It is the simplest, keeps openEHR as the single source of truth, and meets most interoperability requirements. When you need more FHIR server features (Subscriptions, Bulk Export), add an async bridge to a dedicated FHIR server alongside the facade.
- The mapping layer is the product. Regardless of pattern, the mapper between openEHR templates and FHIR resources is where 60% of the engineering effort goes. Invest in a mapping framework with configuration-driven mappers, not hardcoded translation logic. The EHRbase FHIR Bridge is a good starting point, but you will need to extend it.
- Test with real clinical data. Lab data from a synthetic generator will not catch the edge cases that real-world clinical data produces. Malformed archetype paths, unexpected null values, coded entries using retired SNOMED codes — these are the things that break mappers in production.
- Version your mappers independently. The openEHR template will change (new version of the blood pressure archetype). The FHIR profile will change (new US Core version). Your mapper must handle both independently. Use a mapper version registry that tracks which template version maps to which FHIR profile version.
- Monitor the semantic gap. Track how much clinical information is lost in translation. OpenEHR archetypes often capture more granular data than FHIR resources support. Document what is lost, flag it in your mapping documentation, and raise it with your clinical governance team.
- Do not build Pattern 4 on day one. Teams sometimes architect a unified gateway before they have a single production integration. It is over-engineering at its worst. Build Pattern 1, run it for 6 months, understand your real access patterns, then decide whether you need the gateway.
Build on Both Standards with Confidence
The openEHR and FHIR ecosystems are converging, not competing. The IHE community is defining integration profiles that bridge both. Azure Health Data Services now supports openEHR alongside FHIR. EHRbase ships with a FHIR Bridge out of the box. The question is no longer whether to use both — it is how to architect the connection.
Each pattern has trade-offs that only become clear during implementation. Organizations have built FHIR facades over EHRbase for hospital networks, async bridges for national health exchanges, and dual-write architectures for digital health platforms migrating from FHIR-only to openEHR-backed storage. The key is understanding both standards at the archetype and resource level — not just the marketing level.
Architecting an openEHR + FHIR system? Talk to our interoperability engineering team. We will help you choose the right pattern, build the mapping layer, and get to production without the six-month detour most teams take.
Struggling with healthcare data exchange? Our Healthcare Interoperability Solutions practice helps organizations connect clinical systems at scale. We also offer specialized Healthcare Software Product Development services. Talk to our team to get started.