How AI Agents Reduced Claim Processing Time in Healthcare
Founder & CEO
15+ years building healthcare technology. Led 100+ EHR integrations, FHIR implementations, and clinical AI deployments.
The situation
A two-state regional health system, 11 hospitals, 2.4 million attributed lives. Inpatient and outpatient claims processed across 14 commercial and government payers. Volume runs at 41,000 claims per week. Like most U.S. systems at this scale, revenue cycle owns roughly 220 FTE across coding, billing, and follow-up.
Baseline at start of the engagement: first-pass claim denial rate at 22%, 9-day average cycle time from encounter to clean submission, $43M in delayed accounts receivable older than 90 days. Standard story — not catastrophic, but enough drag to materially affect the system's days-cash-on-hand.
What is an agentic revenue cycle workflow?
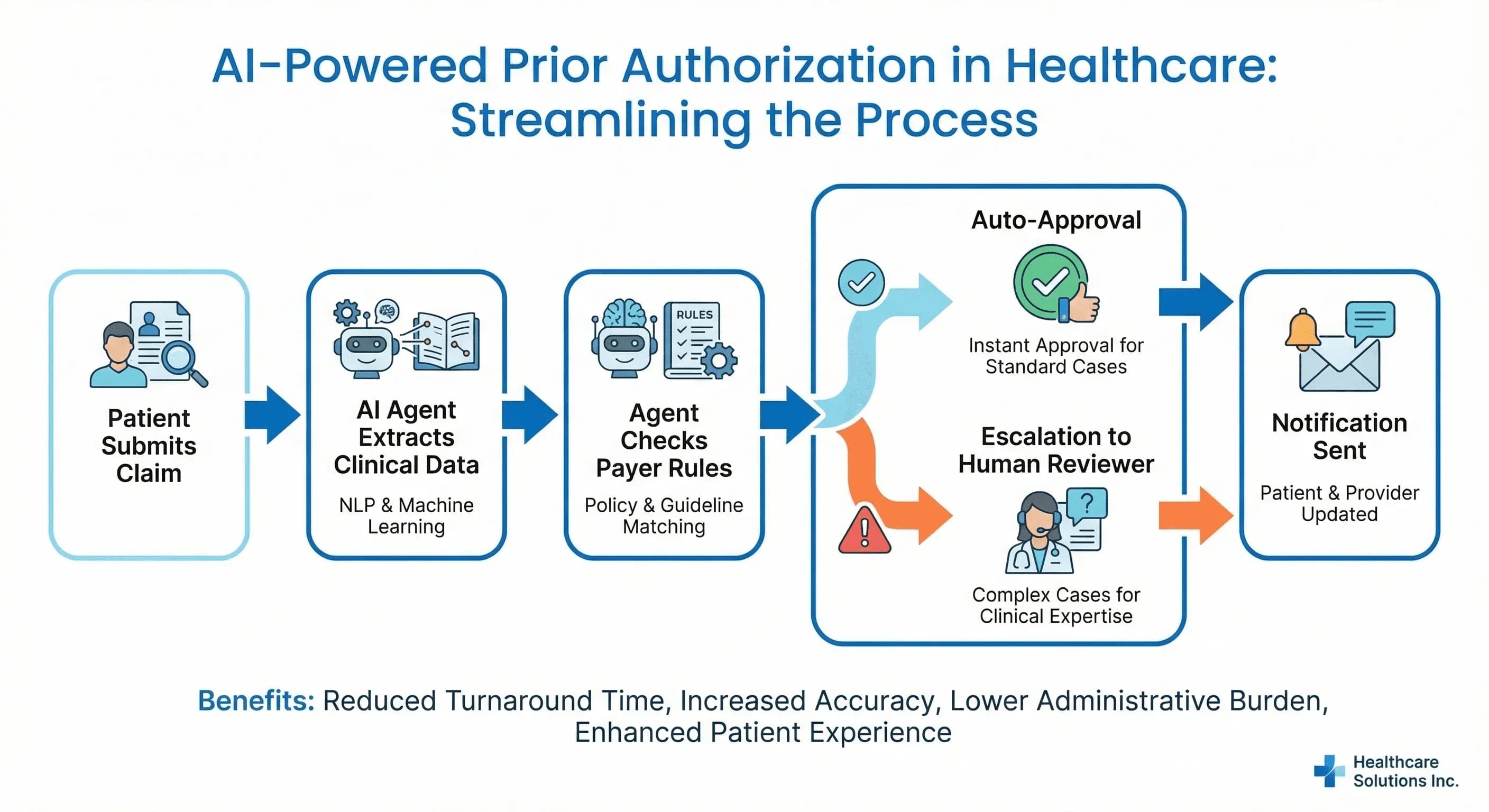
An agentic revenue cycle workflow is one in which an AI agent runs continuously across the claims pipeline — pre-bill scrubbing, eligibility recheck, prior-authorization gap detection, denial drafting, appeal generation — with billing analysts reviewing the agent's drafts rather than building work from scratch. The agent does not replace the human; it changes what the human does. The deliverable is throughput at the same headcount, with a fully-auditable trail on every decision.
Why their existing fixes plateaued
The team had already done the obvious work. They had migrated to a modern claims-scrubbing tool, hired three additional coders, run a Lean Six Sigma project that produced a measurable but modest improvement in 2024. The denial rate had dropped from 26% to 22% — and then plateaued. AR over 90 days had drifted upward as patient-pay collections lagged.
The structural reason for the plateau: each existing fix optimized data entry. The bottleneck was judgment — reading clinical notes for relevant evidence, mapping to payer-specific criteria, deciding which denials were worth appealing. The same pattern we describe in why healthcare workflows break — and how AI agents fix them.
Where the agent intervened
Stage 1 — Pre-bill scrub
Before the claim leaves the system, the agent validates codes against the clinical note, checks for documentation gaps, and applies payer-specific edits. The first run surfaced ~7,200 errors per week that had previously survived the existing scrubbing tool. Not all were worth fixing — about 60% materially impacted reimbursement; the rest were noise. The agent learned which to flag and which to suppress.
Stage 2 — Eligibility recheck
Real-time 270/271 transactions at scheduling and again at check-in. Coverage gaps surfaced before the patient was discharged, not after the claim was denied. This single change moved the clean-claim rate by 18 percentage points on its own.
Stage 3 — Prior authorization gap detection
The agent scanned scheduled procedures and flagged missing or expired authorizations against payer-specific rules. Sixty-one percent of PA-related denials disappeared because the gap was caught at the scheduling stage rather than three weeks after the encounter. We went deep on this pattern in why prior authorization is broken.
Stage 4 — Denial draft and appeal
For claims that did get denied, the agent read the EOB, identified the appealable cases by win-likelihood, retrieved supporting chart evidence, and drafted the appeal letter. The biller reviewed the agent's draft instead of building it from scratch — same FTE, roughly 4x throughput on appeals.
The critical design choice
The agent never sent a claim autonomously. Every output went through a billing analyst. But the analyst was reviewing the agent's draft instead of building it from scratch. That is the structural shift that made the math work — same FTE count, roughly 4x throughput on the work the agent prepared, with a fully auditable trail on every decision.
This is the human-in-the-loop pattern we recommend for any agent that touches reimbursement or clinical decisions. The agent does the heavy lifting; the human approves. Removing the human entirely is technically possible and operationally a bad idea — the rare wrong call lands in your malpractice or compliance bucket, not your engineering bucket. See our companion piece on how AI agents actually work in production systems.
Results — month 12
| Metric | Baseline | Month 12 | Direction |
|---|---|---|---|
| First-pass denial rate | 22% | 11% | −11 pp |
| Cycle time (encounter → clean submission) | 9 days | 27 hours | ~8x faster |
| AR over 90 days | $43M | $14M | −$29M |
| Appeal win rate | 31% | 64% | +33 pp |
| Coder/biller FTE | 220 | 220 | Same headcount, ~4x throughput |
| Time to net positive ROI | — | 11 months | Including build cost |
The build cost — agent platform, FHIR integration, governance setup, change management — was paid back in month 11 by AR acceleration alone. The denial rate improvement and appeal win rate added compounding value into year two. By month 18 the system had redeployed roughly 30 FTE into higher-value clinical care coordination work; no layoffs occurred during the project.
What did not work, and what was changed mid-deployment
Two things did not work as initially designed:
- Auto-merge of duplicate patient records. The agent identified suspected duplicates with reasonable accuracy but the team initially had it auto-merge below a high confidence threshold. Two false-positive merges in the first month forced a redesign — duplicates now go to a human review queue regardless of confidence. The right call.
- Cross-payer policy generalization. The agent initially generalized payer policies across carriers; this caused a 6% spike in denials from one regional Blues plan with idiosyncratic coverage criteria. The fix was payer-specific prompts plus a payer-aware validation step before submission.
What this means for systems considering the same path
Three takeaways that hold across deployments at this scale:
- The biggest dollar move is upstream of the claim, not in the appeal. Pre-bill scrub plus eligibility recheck plus PA gap detection accounted for ~70% of the dollar improvement. Appeal automation was meaningful but secondary.
- Same FTE, different work. The frame is not "AI replaces billers." The frame is "billers review agent drafts and own escalations." Headcount stayed flat; throughput rose; turnover dropped because the work got more interesting.
- Governance is what made the rollback safe. Two adverse patterns surfaced and were fixed in weeks, not quarters, because the steering committee, escalation protocol, and rollback trigger were defined before go-live — not after the first incident.
Real-world reference points
Beyond the composite case study above, public deployments worth referencing: Mayo Clinic's revenue cycle automation work has been documented in healthcare-finance media; Geisinger has published on agentic eligibility verification at scale; Banner Health and Intermountain have published on automation in the denial-management workflow. The order-of-magnitude improvements in cycle time and denial rate reported in those public deployments are consistent with the composite ranges presented in this case study — which is why we use them as the anchor.
Key takeaways
- Most of the dollar impact is upstream, not in appeals. Pre-bill scrub + eligibility recheck + PA gap detection accounted for ~70% of the gain.
- Same FTE, ~4× throughput. Billers review agent drafts; no layoffs; turnover dropped because the work got more interesting.
- Governance made the rollback safe. Two adverse patterns surfaced and were fixed in weeks because the steering committee and rollback trigger were defined before go-live.
- Auto-merge of patient identity is a trap. Two false-positive merges in month 1 forced a redesign — duplicates now go to human review regardless of confidence.
- Cross-payer policy generalization is a trap. Idiosyncratic regional plans need payer-specific prompts and validation, not generalized policy reasoning.
Call to Action
Want to deploy an AI Agent inside your hospital or healthcare product? Get in touch with our team — we will scope the workflow, governance, and 90-day rollout plan against your own baseline metrics.
Learn more about AI Agents in Healthcare → read the full pillar guide.
Related reading:
- Also read: Why Prior Authorization Is Broken (and What AI Agents Change)
- Also read: Where AI Agents Deliver ROI in Healthcare