The $0.03 Illusion: What Nobody Tells You About Healthcare AI Costs
Every healthcare AI demo starts the same way. You fire up an API call to GPT-4o, feed it a clinical note, and get a beautifully structured response. Cost: $0.03. You multiply that by your expected patient volume, add a comfortable margin, and pitch your board on a product that "practically prints money."
Then you go to production.
The $0.03 prototype call becomes $2-5 per patient interaction. Your monthly API bill lands between $12,000 and $30,000 — and that is before infrastructure, compliance, and engineering costs. According to a 2025 study published in npj Digital Medicine, large healthcare systems running generative AI in production report operational costs of $3,200-$13,000 per month in LLM API spend alone.
This is not a cautionary tale. This is an engineering problem with quantifiable solutions. This guide breaks down the real token economics of healthcare AI agents, gives you five proven strategies to reduce costs by 60-80%, and shows you the exact math for when self-hosting beats API calls.
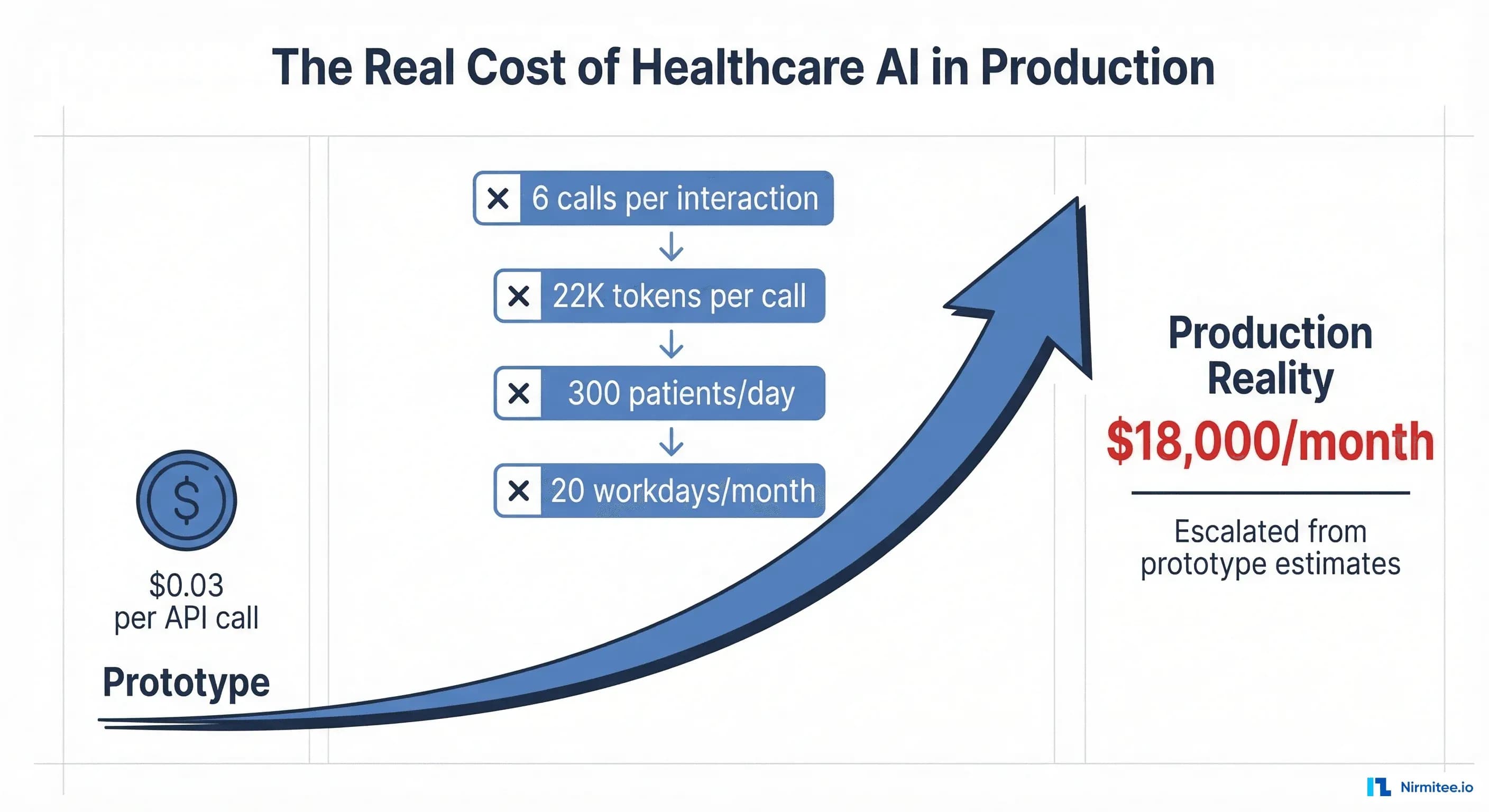
Why Healthcare AI Costs 50-100x More Than Your Prototype Suggested
The gap between prototype and production costs comes from three compounding factors that nobody accounts for during the demo phase.
Factor 1: Multi-Call Agent Architectures
A production healthcare AI agent does not make one LLM call per patient interaction. It makes 5-8 calls in a chain:
- Call 1: RAG retrieval query — reformulate the patient question into an embedding search query
- Call 2: Context assembly — summarize retrieved documents into a coherent clinical context
- Call 3: Clinical reasoning — the actual diagnostic or decision-support inference
- Call 4: Tool calls — query FHIR APIs, check drug interactions, pull lab reference ranges
- Call 5: Output structuring — format the response into structured clinical data (ICD codes, SNOMED terms)
- Call 6: Safety guardrails — check for hallucinations, verify clinical accuracy against guidelines
- Calls 7-8: Refinement and patient-facing summary generation
Each call carries its own token cost. Each call includes system prompts, few-shot examples, and context windows that multiply the effective cost per interaction.
Factor 2: Clinical Context Is Token-Dense
Healthcare data is not a chatbot conversation. A single patient interaction requires loading substantial clinical context into the LLM's context window. Here is the real token breakdown:
| Clinical Data Component | Tokens | What It Contains |
|---|---|---|
| FHIR Patient Bundle | 2,000 | Demographics, identifiers, insurance, contacts, care team references |
| Lab Results (recent) | 5,000 | CBC, BMP, lipid panel, HbA1c — structured FHIR Observation resources |
| Medication List | 3,000 | Active prescriptions, dosages, RxNorm codes, interaction flags |
| Encounter Notes | 10,000 | Last 3-5 clinical notes, assessment/plan sections, provider observations |
| System Prompt + Guardrails | 2,000 | Clinical guidelines, output format rules, safety constraints, few-shot examples |
| Total Per Call | 22,000 | Loaded into context for each LLM call in the chain |
With 6 calls per interaction and 22,000 input tokens per call, each patient interaction consumes approximately 132,000 input tokens and generates roughly 8,000 output tokens across all calls combined.
Factor 3: The Volume Multiplier
A mid-size clinic sees 300 patients per day. Over 20 workdays per month, that is 6,000 patient interactions. Multiply by the per-interaction token consumption, and the numbers become sobering.
The Real Cost: Model-by-Model Comparison
Using the 22K input tokens per call, 6 calls per interaction, and 6,000 monthly interactions baseline, here is what each major model actually costs in a healthcare production environment (as of March 2026 pricing):
| Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Cost Per Interaction | Monthly Cost (6K interactions) |
|---|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | $0.41 | $2,460 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $0.52 | $3,120 |
| Gemini 3.1 Pro | $2.00 | $12.00 | $0.36 | $2,160 |
| Claude Opus 4.6 | $5.00 | $25.00 | $0.86 | $5,160 |
| GPT-4o-mini | $0.15 | $0.60 | $0.02 | $120 |
| Claude Haiku 4.5 | $1.00 | $5.00 | $0.17 | $1,020 |
| Gemini Flash | $0.075 | $0.30 | $0.01 | $60 |
The critical insight: using a single premium model for every call in the chain puts you at $2,000-5,000/month for a single clinic. Scale to a health system with 50 clinics and you are looking at $100,000-250,000/month in API costs alone. This is why cost optimization is not optional — it is an architectural requirement.
Five Cost Reduction Strategies That Actually Work
Strategy 1: Intelligent Model Routing (Save 40-60%)
Not every call in the agent chain requires GPT-4o or Claude Opus. The most impactful cost reduction is routing each task to the cheapest model that can handle it reliably:
| Task Type | Recommended Model | Cost Per Call | Why |
|---|---|---|---|
| Clinical reasoning / differential diagnosis | Claude Opus or GPT-4o | $0.08-0.14 | Requires deep medical knowledge, nuanced judgment |
| Data extraction / parsing FHIR resources | GPT-4o-mini or Haiku | $0.002-0.03 | Structured extraction — accuracy is high even on small models |
| Output formatting / code generation | Fine-tuned small model | $0.0005 | Repetitive, pattern-based — perfect for specialized models |
| Simple lookups (drug names, ICD codes) | No LLM — direct FHIR/DB query | $0.00 | Deterministic lookups should never hit an LLM |
| Safety / hallucination checks | Claude Sonnet or GPT-4o | $0.05-0.09 | Needs strong reasoning but with a focused, shorter prompt |
With intelligent routing, a 6-call chain that cost $0.52 with Claude Sonnet everywhere drops to approximately $0.15-0.20 — a 60% reduction. For your 6,000 monthly interactions, that takes you from $3,120 to $900-1,200/month. This approach aligns with how leading health systems are building AI-driven clinical decision support — using the right tool for each specific task.
Strategy 2: Semantic Caching and FHIR Data Reuse (Save 20-30%)
Healthcare queries are repetitive. When 15 patients ask about metformin side effects in the same week, you should not re-embed and re-retrieve the same clinical guidelines 15 times. Implement two levels of caching:
- Semantic cache: Hash the embedding vector of incoming queries. If a query is within cosine similarity >0.95 of a cached query, return the cached response. Tools like GPTCache or custom Redis-based solutions work well here.
- Session-level FHIR cache: When a patient session starts, pull their FHIR bundle once and cache it for the session duration (typically 15-30 minutes). Every subsequent LLM call in that session reuses the cached context instead of re-fetching from the EHR.
- Prompt caching: Both Anthropic and OpenAI now offer prompt caching discounts (up to 90% off cached input tokens). Structure your system prompts and clinical guidelines as cacheable prefixes.
Combined, these caching strategies reduce redundant token consumption by 20-30% across your patient population. For a system processing 6,000 interactions/month, that is $600-900 in monthly savings at Sonnet-tier pricing.
Strategy 3: Context Pruning — Send What Matters (Save 25-35%)
The 22,000-token context window per call is a worst case. In practice, most clinical queries do not need the full patient record. Context pruning uses a lightweight classifier (or simple rules) to determine which clinical data components are relevant:
- Medication-related query? Send medication list + recent labs. Skip encounter notes. Context drops from 22K to 10K tokens.
- Lab result interpretation? Send labs + relevant encounter notes. Skip the medication list and full FHIR bundle. Context drops to 17K tokens.
- Appointment scheduling or administrative? Skip all clinical data. Context drops to 2K tokens (system prompt only).
A well-implemented context pruner reduces average tokens per call from 22,000 to 12,000-15,000 — a 30% reduction that compounds across all 6 calls in the chain. This is where understanding healthcare interoperability standards like FHIR becomes critical — structured data formats make selective context assembly possible.
Strategy 4: Prompt Engineering for Cost (Save 10-20%)
Most healthcare AI system prompts are bloated. They include lengthy preambles, excessive few-shot examples, and redundant safety instructions. Aggressive prompt optimization can reduce system prompt tokens from 2,000 to 800 without degrading output quality:
- Compress few-shot examples: Replace 5 verbose examples with 2 concise ones. Use structured formats (JSON templates) instead of natural language examples.
- Externalize guidelines: Instead of embedding full clinical guidelines in the prompt, reference them via RAG retrieval only when relevant.
- Version and A/B test prompts: Track cost-per-quality metrics. Often a 40% shorter prompt produces identical clinical accuracy.
Strategy 5: Fine-Tuning for Repetitive Tasks (Save 60-80% at Scale)
Certain healthcare AI tasks are high-volume and pattern-predictable — making them ideal candidates for fine-tuned small models that replace expensive API calls entirely:
- ICD-10/SNOMED coding: Given a clinical note, assign diagnosis codes. A fine-tuned 7B parameter model matches GPT-4o accuracy after training on 50,000 labeled examples.
- Note summarization: Condense encounter notes into structured SOAP summaries. Highly repetitive format — perfect for specialization.
- Prior authorization extraction: Pull required data elements from clinical records for CMS prior authorization compliance. Structured input/output makes fine-tuning straightforward.
- Medication reconciliation: Compare medication lists across care settings. Rules-based with clear patterns.
Fine-tuning costs $500-5,000 upfront (depending on dataset size and model). After approximately 50,000 calls, a fine-tuned self-hosted model is cheaper than any API. For high-volume tasks, the payback period is measured in weeks, not months.
The Break-Even Math: API vs. Self-Hosted
At what patient volume does self-hosting beat API calls? Here is the math, using a single A100 80GB GPU (available at $1.49/hour from cloud providers as of March 2026):
| Cost Component | API-Based (GPT-4o) | Self-Hosted (Fine-tuned 7B on A100) |
|---|---|---|
| Fixed monthly cost | $0 | $1,073 (A100 at $1.49/hr x 720 hrs) |
| Fine-tuning (amortized over 12 months) | $0 | $250/month |
| Engineering/DevOps overhead | $500 | $2,000 |
| Cost per interaction | $0.41 | $0.008 |
| Cost at 10K interactions/month | $4,600 | $3,403 |
| Cost at 25K interactions/month | $10,750 | $3,523 |
| Cost at 50K interactions/month | $21,000 | $3,723 |
| Cost at 100K interactions/month | $41,500 | $4,123 |
The crossover point is approximately 8,000-10,000 interactions per month for a fine-tuned 7B model handling extraction and formatting tasks. For the full agent pipeline (which still needs a premium model for clinical reasoning), the hybrid approach — self-hosted for extraction, API for reasoning — crosses over at roughly 25,000-30,000 interactions/month.
Key considerations for self-hosting in healthcare:
- HIPAA compliance: Self-hosted models eliminate data transmission to third-party APIs — a significant compliance advantage. No BAA negotiations with OpenAI or Anthropic needed for those workloads.
- Latency: Self-hosted inference on A100 delivers 50-100 tokens/second for a 7B model — faster than most API endpoints under load.
- Operational burden: You need MLOps expertise for model serving, monitoring, and updates. Budget $150-200K/year for a dedicated ML engineer.
Revenue Offset: How to Price Your AI-Powered Feature
Cost engineering is only half the equation. The other half is pricing your AI feature to capture the value it creates. The standard model for healthcare AI is Per Patient Per Month (PPPM) pricing.
The Value Calculation
According to Morgan Stanley research, AI in US healthcare could save trillions by 2050. At the individual provider level, the math is concrete:
- Average physician hourly rate: $250/hour ($4.17/minute)
- AI agent saves 15 minutes per patient interaction (documentation, coding, order entry)
- Value created per patient: $62.50
- Additional value from reduced errors, faster throughput, improved coding accuracy: $15-30/patient
- Total value created: $77-93 per patient interaction
The Pricing Sweet Spot
| Metric | Conservative | Mid-Range | Premium |
|---|---|---|---|
| PPPM price | $5 | $10 | $15 |
| Agent cost (optimized) | $1.50 | $3.00 | $3.00 |
| Gross margin per patient | $3.50 (70%) | $7.00 (70%) | $12.00 (80%) |
| Revenue at 1,000 patients | $5,000/mo | $10,000/mo | $15,000/mo |
| Revenue at 10,000 patients | $50,000/mo | $100,000/mo | $150,000/mo |
| Revenue at 50,000 patients | $250,000/mo | $500,000/mo | $750,000/mo |
At the mid-range $10 PPPM price point with optimized costs of $3 PPPM, you generate $7 PPPM in gross margin at 70% margins. That is a healthy SaaS business. The key is that cost engineering directly expands your margin — every dollar saved on API costs drops straight to the bottom line.
Cost Calculator Framework: Build Your Own Model
Use this framework to model your specific healthcare AI agent economics. Plug in your numbers for each variable:
| Variable | Your Value | Example |
|---|---|---|
| Daily patient volume | ___ | 300 |
| Working days per month | ___ | 20 |
| LLM calls per interaction | ___ | 6 |
| Avg input tokens per call | ___ | 22,000 |
| Avg output tokens per call | ___ | 1,300 |
| Primary model input cost (per 1M) | ___ | $2.50 |
| Primary model output cost (per 1M) | ___ | $10.00 |
| % calls routed to cheap model | ___ | 60% |
| Cheap model input cost (per 1M) | ___ | $0.15 |
| Cheap model output cost (per 1M) | ___ | $0.60 |
| Cache hit rate | ___ | 25% |
| Context pruning reduction | ___ | 30% |
Monthly cost formula:
monthly_interactions = daily_patients × working_days
tokens_per_interaction = calls × avg_input_tokens × (1 - cache_rate) × (1 - pruning_rate)
premium_cost = tokens_per_interaction × (1 - cheap_route_pct) × premium_rate
budget_cost = tokens_per_interaction × cheap_route_pct × budget_rate
output_cost = calls × avg_output_tokens × blended_output_rate
total_monthly = monthly_interactions × (premium_cost + budget_cost + output_cost)For our example: 6,000 interactions x (132K tokens x 0.75 x 0.70) per interaction, split 40/60 between premium and budget models = approximately $1,100/month — down from $3,120 with zero optimization. That is a 65% reduction.
The Bottom Line: Cost Engineering Is a Competitive Moat
Healthcare AI companies that treat LLM costs as a fixed line item will get squeezed out by competitors who engineer their costs down. The playbook is straightforward:
- Measure first: Instrument every LLM call with cost tracking. You cannot optimize what you do not measure. Log tokens consumed, model used, latency, and output quality per call.
- Route intelligently: Use expensive models only where clinical accuracy demands it. Route everything else to budget models or fine-tuned alternatives.
- Cache aggressively: Semantic caching, FHIR session caching, and prompt caching combined can eliminate 25-30% of redundant computation.
- Prune context: Send only the clinical data the query actually needs. Build a lightweight relevance classifier that costs fractions of a cent.
- Fine-tune at scale: Once a task exceeds 50K monthly calls, the ROI on fine-tuning is unambiguous. Start with your highest-volume, most repetitive tasks.
The companies winning in healthcare AI are not the ones with the best models. They are the ones with the best cost-per-insight. At Nirmitee, we engineer healthcare AI systems with production economics built in from day one — because a brilliant clinical AI agent that bankrupts your margins is not a product, it is a research project.
Looking to build a robust healthcare platform? Our Healthcare Software Product Development team turns complex requirements into production-ready systems. We also offer specialized Agentic AI for Healthcare services. Talk to our team to get started.
Frequently Asked Questions
What is a realistic monthly LLM API cost for a healthcare AI agent in production?
For a mid-size clinic processing 6,000 patient interactions per month, expect $1,000-3,000/month in optimized API costs, or $2,500-5,000/month without optimization. Large health systems with 50+ clinics can see $50,000-250,000/month before cost engineering interventions.
When should I consider self-hosting an LLM instead of using APIs?
Self-hosting becomes cost-effective at approximately 8,000-10,000 monthly interactions for fine-tuned extraction tasks, or 25,000-30,000 interactions for a hybrid pipeline. It also provides HIPAA compliance advantages by keeping patient data on-premises.
How do I calculate the ROI of a healthcare AI agent?
Measure the physician time saved per patient interaction (typically 10-20 minutes), multiply by the physician's effective hourly rate ($200-350/hour), and compare against your all-in cost per interaction ($0.15-0.50 with optimization). Most healthcare AI agents deliver 10-20x ROI when properly cost-engineered.
Which LLM is most cost-effective for healthcare applications?
There is no single answer — the most cost-effective approach is model routing. Use GPT-4o or Claude Opus for clinical reasoning tasks requiring deep medical knowledge, GPT-4o-mini or Gemini Flash for data extraction and formatting, and fine-tuned small models for high-volume repetitive tasks like ICD coding.
How does prompt caching reduce healthcare AI costs?
Both Anthropic and OpenAI offer prompt caching that reduces input token costs by up to 90% for repeated system prompts and clinical guidelines. Since healthcare AI agents use the same system prompt and guideline context across thousands of interactions, caching these prefixes can save 15-25% of total input token costs.