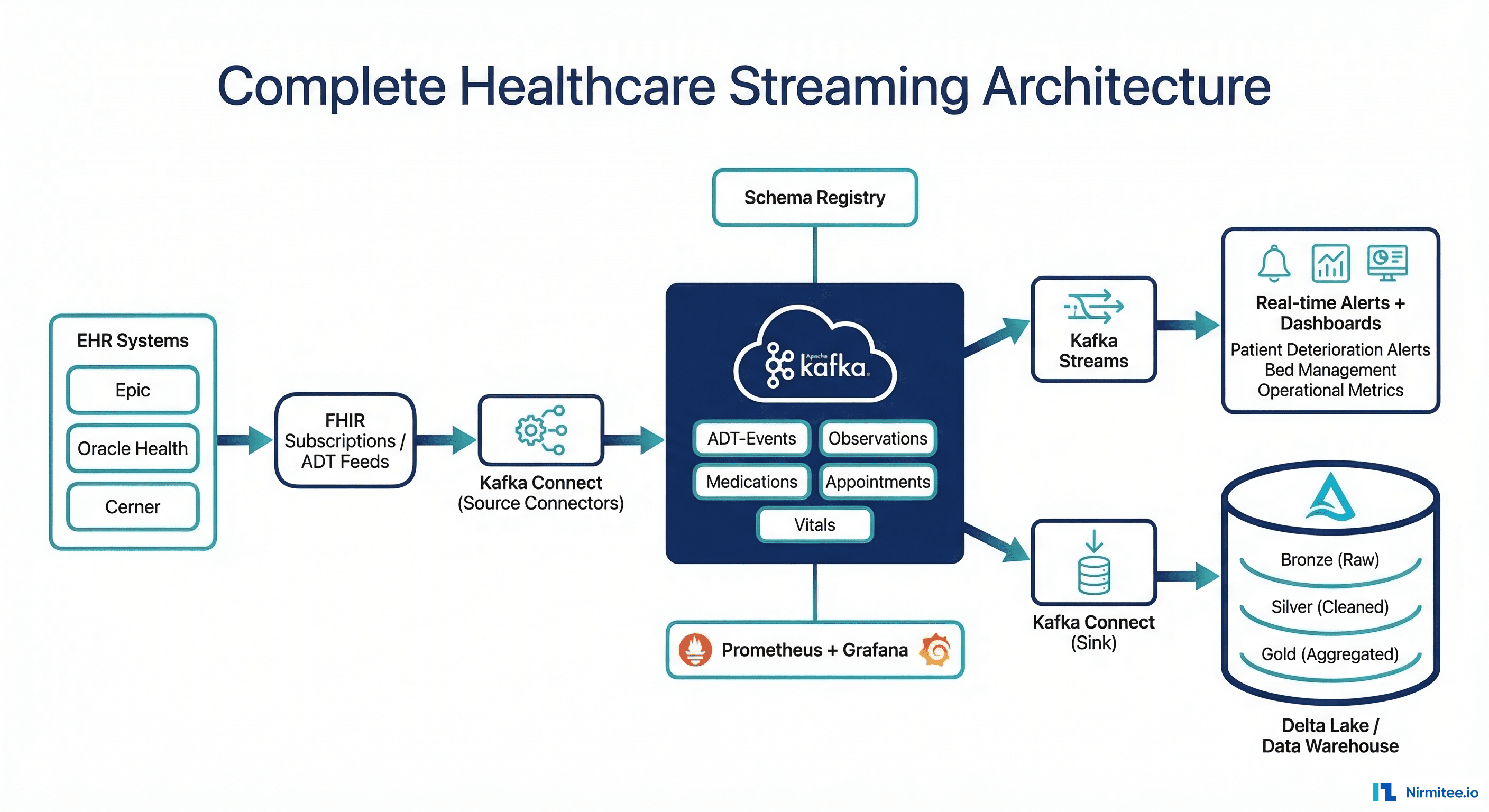
Every hospital generates thousands of clinical events per minute: patient admissions, lab results, medication administrations, vital sign readings, and discharge notifications. Traditional batch processing handles these events with hourly or daily ETL jobs, meaning a critical lab result might sit in a queue for hours before triggering an alert. In an industry where delayed responses cost lives, this latency is unacceptable.
Apache Kafka provides the event streaming backbone that healthcare organizations need: real-time delivery of clinical events with exactly-once guarantees, millisecond latency, and the ability to replay events for debugging or reprocessing. Combined with FHIR as the data standard, Kafka enables a unified streaming architecture where every system, from the EHR to the clinical dashboard to the AI agent, speaks the same language in real time.
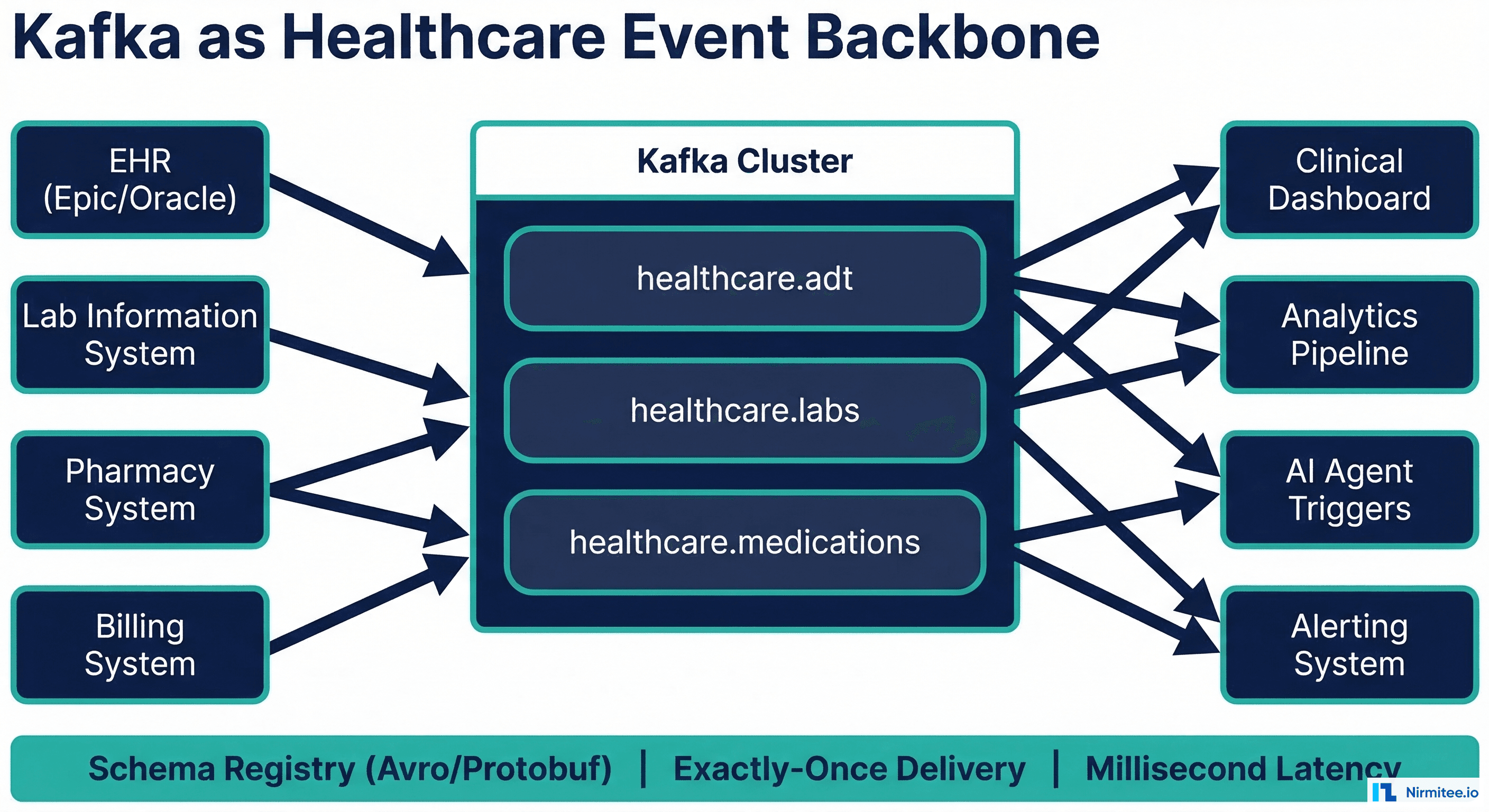
Why Kafka for Healthcare Event Streaming
Healthcare integration has traditionally relied on point-to-point HL7v2 interfaces. A 500-bed hospital typically maintains 200-400 individual interfaces, each a brittle connection between two systems. When one system changes, every connected interface must be updated. According to HIMSS research, hospitals spend 30-40% of their IT budget maintaining these interfaces.
Kafka replaces this point-to-point spaghetti with a centralized event bus. Producers publish events to topics, consumers subscribe to the topics they need, and neither side needs to know about the other. Adding a new consumer (a clinical dashboard, an analytics pipeline, an AI agent) requires zero changes to existing systems.
Kafka vs Traditional Healthcare Messaging
| Capability | HL7v2 Point-to-Point | Mirth Connect Hub | Apache Kafka |
|---|---|---|---|
| Delivery guarantee | Best-effort TCP | At-least-once (with DLQ) | Exactly-once semantics |
| Latency | ~100ms | ~500ms (transform overhead) | <10ms (producer to consumer) |
| Replay capability | None | Channel history (limited) | Full replay from any offset |
| Throughput | ~1K msgs/sec per interface | ~10K msgs/sec | ~1M msgs/sec per cluster |
| Adding new consumer | New interface required | New channel + destination | New consumer group (zero changes) |
| Schema enforcement | HL7v2 spec (loosely followed) | Custom validation filters | Schema Registry (strict) |
For organizations already using Mirth Connect for HL7v2 integration, Kafka complements rather than replaces it. Mirth handles protocol translation (HL7v2 to FHIR), Kafka handles event distribution. See our guide on building a FHIR facade over legacy HL7v2 systems for the pattern.
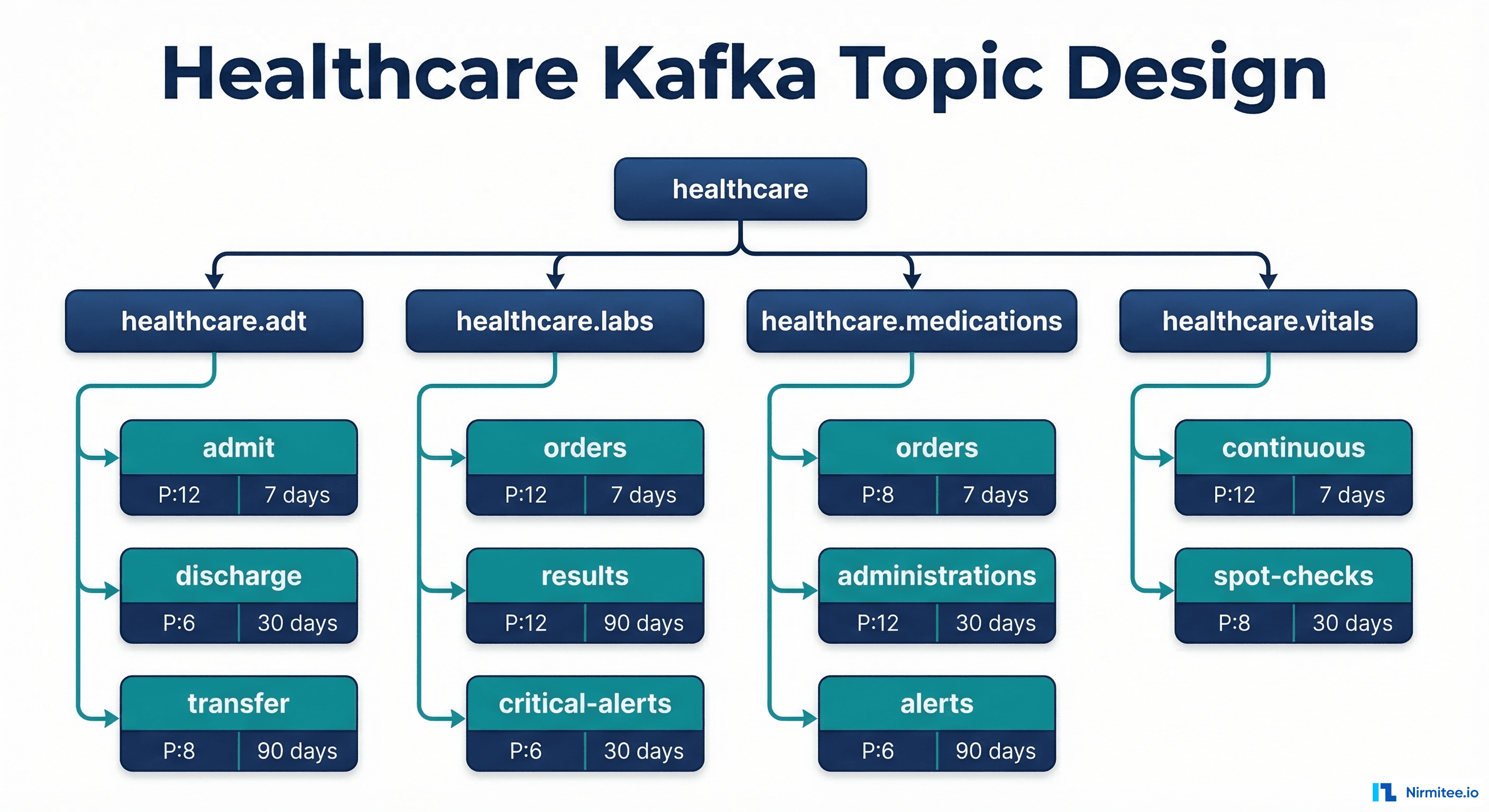
Topic Design for Healthcare Events
Topic design is the most consequential architectural decision in a healthcare Kafka deployment. Get it wrong, and you end up with ordering problems, consumer bottlenecks, and compliance headaches. The key principles: partition by patient ID for ordering guarantees, separate topics by event domain for independent scaling, and set retention based on regulatory requirements.
Recommended Topic Structure
# Create healthcare topics with appropriate configurations
# ADT events: high volume, patient-ordered, 30-day retention
kafka-topics.sh --create \
--topic healthcare.adt.events \
--partitions 12 \
--replication-factor 3 \
--config retention.ms=2592000000 \
--config cleanup.policy=delete \
--config min.insync.replicas=2 \
--config message.timestamp.type=CreateTime
# Lab results: medium volume, patient-ordered, 90-day retention
kafka-topics.sh --create \
--topic healthcare.labs.results \
--partitions 8 \
--replication-factor 3 \
--config retention.ms=7776000000 \
--config cleanup.policy=delete \
--config min.insync.replicas=2
# Critical alerts: low volume, high priority, compacted
kafka-topics.sh --create \
--topic healthcare.alerts.critical \
--partitions 6 \
--replication-factor 3 \
--config cleanup.policy=compact \
--config min.insync.replicas=2 \
--config max.compaction.lag.ms=3600000
# Medication orders: exactly-once required
kafka-topics.sh --create \
--topic healthcare.medications.orders \
--partitions 8 \
--replication-factor 3 \
--config retention.ms=7776000000 \
--config min.insync.replicas=2Partitioning Strategy: Why Patient ID
In healthcare, event ordering matters at the patient level. An admit event must be processed before a discharge event for the same patient. A lab order must be processed before its result. By using patient_id as the partition key, Kafka guarantees that all events for a single patient are processed in order by the same consumer instance.
from confluent_kafka import Producer
import json
import hashlib
def create_healthcare_producer():
"""Create Kafka producer with healthcare-grade settings."""
return Producer({
"bootstrap.servers": "kafka-1:9092,kafka-2:9092,kafka-3:9092",
# Exactly-once delivery
"enable.idempotence": True,
"acks": "all",
"max.in.flight.requests.per.connection": 5,
# Transactional producer for exactly-once
"transactional.id": "clinical-producer-001",
# Compression for FHIR JSON payloads
"compression.type": "lz4",
# Retry settings
"retries": 2147483647,
"retry.backoff.ms": 100,
"delivery.timeout.ms": 120000,
})
def publish_fhir_event(producer, resource_type, resource, event_type="create"):
"""Publish a FHIR resource event to the appropriate topic."""
topic_map = {
"Patient": "healthcare.adt.events",
"Encounter": "healthcare.adt.events",
"Observation": "healthcare.labs.results",
"MedicationRequest": "healthcare.medications.orders",
"DiagnosticReport": "healthcare.labs.results",
}
topic = topic_map.get(resource_type, "healthcare.fhir.other")
patient_id = extract_patient_id(resource)
event = {
"event_type": event_type,
"resource_type": resource_type,
"resource_id": resource.get("id"),
"patient_id": patient_id,
"timestamp": resource.get("meta", {}).get("lastUpdated"),
"fhir_resource": resource
}
# Partition by patient_id for per-patient ordering
producer.produce(
topic=topic,
key=patient_id.encode("utf-8") if patient_id else None,
value=json.dumps(event).encode("utf-8"),
callback=delivery_callback
)
producer.flush()
def extract_patient_id(resource):
"""Extract patient reference from any FHIR resource."""
if resource.get("resourceType") == "Patient":
return resource.get("id")
subject = resource.get("subject", {})
ref = subject.get("reference", "")
if ref.startswith("Patient/"):
return ref.replace("Patient/", "")
return None
def delivery_callback(err, msg):
if err:
print(f"DELIVERY FAILED: {err}")
# In production: alert + retry queue
else:
print(f"Delivered to {msg.topic()}[{msg.partition()}] @ {msg.offset()}")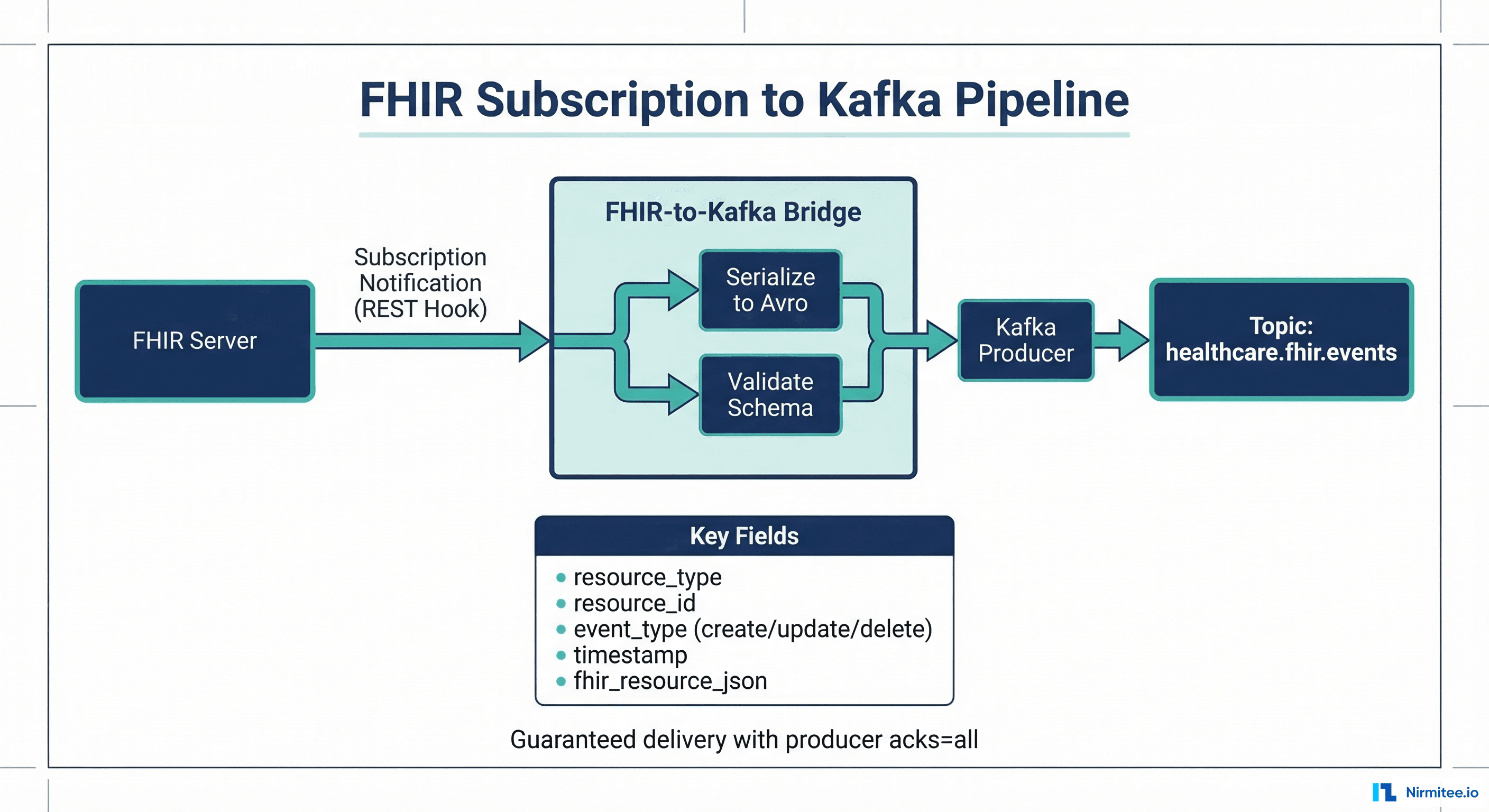
FHIR Subscriptions as Kafka Event Sources
FHIR R4 Subscriptions provide a standard mechanism for EHR systems to notify external consumers when resources change. By connecting FHIR Subscriptions to Kafka producers, you get a standards-based CDC pipeline that works with any FHIR-compliant EHR. For deep coverage of FHIR Subscription architecture, see our guide on moving from polling to real-time with FHIR Subscriptions.
FHIR Subscription to Kafka Bridge
from flask import Flask, request, jsonify
from confluent_kafka import Producer
import json
import logging
app = Flask(__name__)
logger = logging.getLogger("fhir-kafka-bridge")
producer = create_healthcare_producer()
@app.route("/fhir-webhook", methods=["POST"])
def handle_fhir_subscription():
"""Receive FHIR Subscription notification, forward to Kafka."""
bundle = request.get_json()
if bundle.get("resourceType") != "Bundle":
return jsonify({"error": "Expected Bundle"}), 400
entries = bundle.get("entry", [])
published = 0
for entry in entries:
resource = entry.get("resource", {})
resource_type = resource.get("resourceType")
if not resource_type:
continue
# Determine event type from Bundle.entry.request
req = entry.get("request", {})
method = req.get("method", "PUT")
event_type = {
"POST": "create",
"PUT": "update",
"DELETE": "delete"
}.get(method, "update")
publish_fhir_event(
producer, resource_type, resource, event_type
)
published += 1
logger.info(
f"Published {published} events from "
f"FHIR Subscription notification"
)
return jsonify({"published": published}), 200
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)Kafka Connect FHIR Source Connector
For systems that do not support FHIR Subscriptions, Kafka Connect can poll FHIR APIs at scheduled intervals. This is less efficient than push-based subscriptions but works with any FHIR server:
{
"name": "fhir-source-connector",
"config": {
"connector.class": "io.confluent.connect.http.HttpSourceConnector",
"tasks.max": "3",
"http.api.url": "https://ehr.hospital.org/fhir",
"http.request.method": "GET",
"http.request.headers": "Authorization: Bearer ${FHIR_TOKEN}",
"http.topic.name.pattern": "healthcare.fhir.${resource_type}",
"poll.interval.ms": "30000",
"http.response.json.path": "$.entry[*].resource",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"transforms": "extractPatientId",
"transforms.extractPatientId.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractPatientId.field": "id"
}
}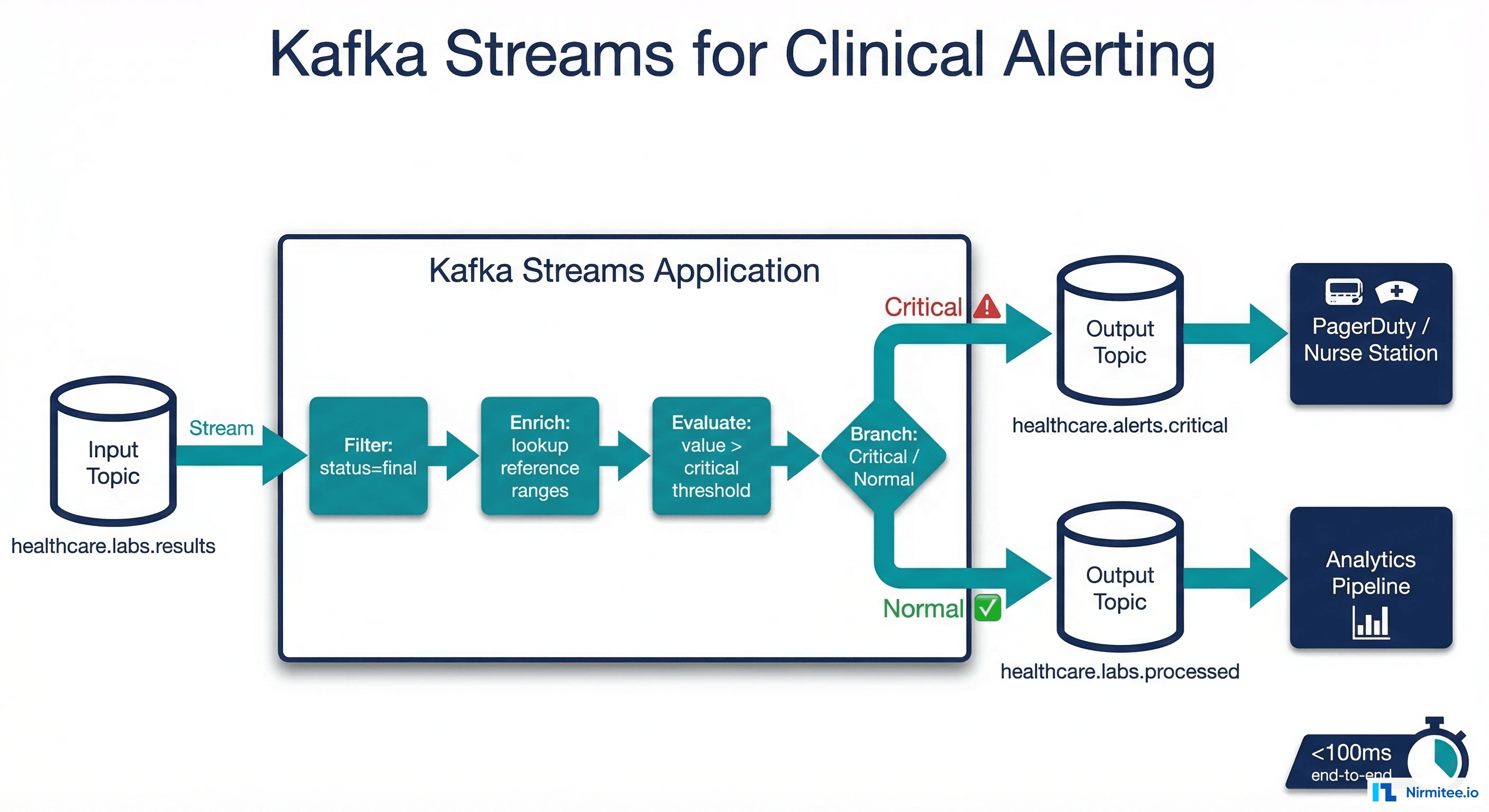
Kafka Streams for Real-Time Clinical Logic
Kafka Streams enables you to process clinical events in real time with exactly-once semantics, no separate cluster required. The most compelling healthcare use case: real-time alerting on critical lab values.
Critical Lab Value Alert Pipeline
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.kstream.*;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
public class CriticalLabAlertProcessor {
// Critical value thresholds (LOINC code -> range)
private static final Map<String, double[]> CRITICAL_RANGES = Map.of(
"2345-7", new double[]{40, 500}, // Glucose mg/dL
"2160-0", new double[]{0.5, 10.0}, // Creatinine mg/dL
"6298-4", new double[]{3.5, 5.5}, // Potassium mEq/L
"2951-2", new double[]{136, 145}, // Sodium mEq/L
"718-7", new double[]{7.0, 18.0} // Hemoglobin g/dL
);
public static void main(String[] args) {
StreamsBuilder builder = new StreamsBuilder();
ObjectMapper mapper = new ObjectMapper();
KStream<String, String> labResults =
builder.stream("healthcare.labs.results");
// Branch into critical and normal streams
KStream<String, String>[] branches = labResults
.filter((key, value) -> {
JsonNode event = mapper.readTree(value);
return "final".equals(
event.at("/fhir_resource/status").asText()
);
})
.branch(
(key, value) -> isCriticalValue(
mapper.readTree(value)
),
(key, value) -> true // default: normal
);
// Critical path: enrich and alert
branches[0]
.mapValues(value -> enrichWithPatientContext(
mapper.readTree(value)
))
.to("healthcare.alerts.critical");
// Normal path: send to processed topic
branches[1].to("healthcare.labs.processed");
KafkaStreams streams = new KafkaStreams(
builder.build(), getStreamsConfig()
);
streams.start();
}
private static boolean isCriticalValue(JsonNode event) {
String loincCode = event
.at("/fhir_resource/code/coding/0/code")
.asText();
double value = event
.at("/fhir_resource/valueQuantity/value")
.asDouble();
double[] range = CRITICAL_RANGES.get(loincCode);
if (range == null) return false;
return value < range[0] || value > range[1];
}
}This pipeline processes every lab result in under 100 milliseconds. A critical potassium level triggers an alert on the nurse station dashboard before the physician has finished reviewing the order in the EHR. For organizations building clinical AI agents on top of these streams, see our guide on building healthcare AI agent data pipelines.
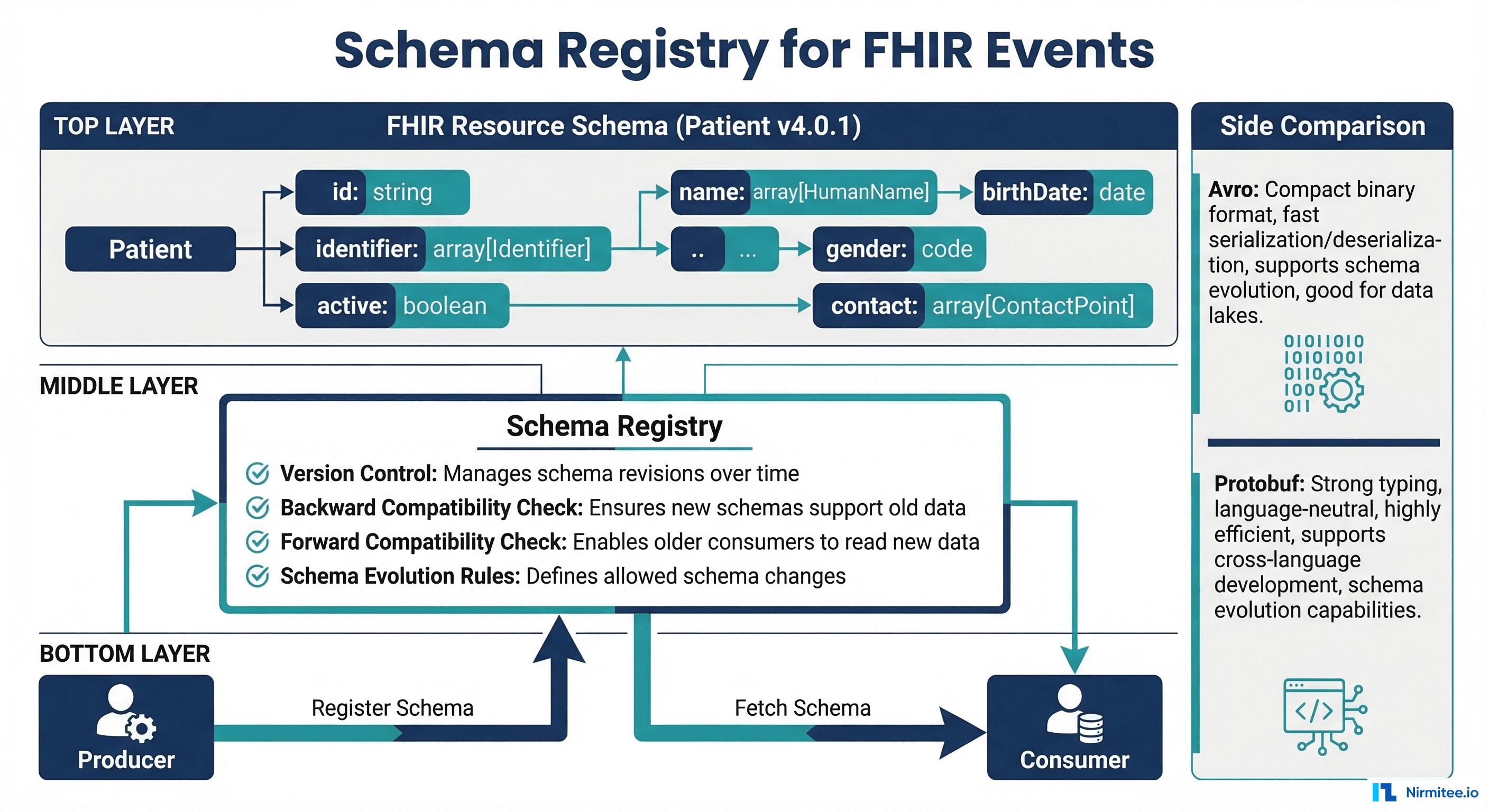
Schema Registry for FHIR Event Schemas
Without schema enforcement, producers can send malformed events that break consumers. The Confluent Schema Registry enforces contracts between producers and consumers using Avro, Protobuf, or JSON Schema. For healthcare, this means a producer cannot send a lab result without a patient reference, a LOINC code, and a value, because the schema rejects it at write time.
Avro Schema for FHIR Observation Events
{
"type": "record",
"name": "FhirObservationEvent",
"namespace": "io.nirmitee.healthcare.events",
"fields": [
{"name": "event_id", "type": "string"},
{"name": "event_type", "type": {
"type": "enum",
"name": "EventType",
"symbols": ["CREATE", "UPDATE", "DELETE"]
}},
{"name": "timestamp", "type": "long",
"logicalType": "timestamp-millis"},
{"name": "patient_id", "type": "string"},
{"name": "encounter_id", "type": ["null", "string"],
"default": null},
{"name": "observation", "type": {
"type": "record",
"name": "Observation",
"fields": [
{"name": "id", "type": "string"},
{"name": "status", "type": "string"},
{"name": "code_system", "type": "string"},
{"name": "code", "type": "string"},
{"name": "code_display", "type": "string"},
{"name": "value", "type": ["null", "double"],
"default": null},
{"name": "value_string", "type": ["null", "string"],
"default": null},
{"name": "unit", "type": ["null", "string"],
"default": null},
{"name": "effective_datetime", "type": "string"},
{"name": "reference_range_low",
"type": ["null", "double"], "default": null},
{"name": "reference_range_high",
"type": ["null", "double"], "default": null}
]
}}
]
}Schema Compatibility Rules for Healthcare
| Compatibility | Allowed Changes | Healthcare Use Case |
|---|---|---|
| BACKWARD | Add optional fields, remove fields with defaults | Adding new FHIR extensions (safe for existing consumers) |
| FORWARD | Remove optional fields, add fields with defaults | Deprecated fields (safe for existing producers) |
| FULL | Add/remove optional fields with defaults only | Recommended for clinical events (maximum safety) |
| NONE | Any change | Development only (never for production clinical data) |
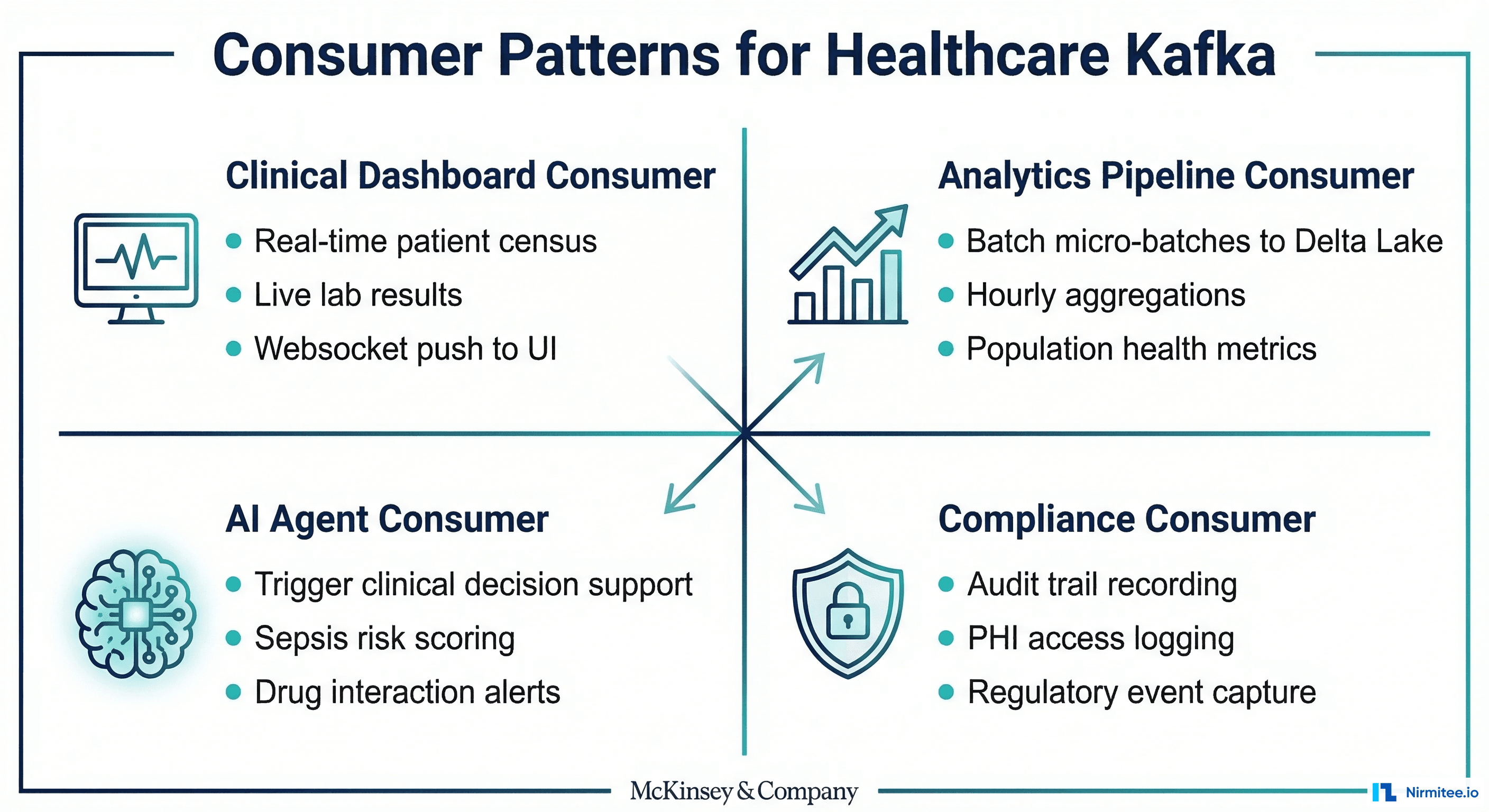
Consumer Patterns for Healthcare Data
Different consumers have different requirements. A clinical dashboard needs sub-second latency. An analytics pipeline can tolerate a lag of minutes. An AI agent needs an enriched context. A compliance system needs guaranteed delivery. Kafka consumer groups handle all of these patterns simultaneously.
Clinical Dashboard Consumer (Real-Time)
from confluent_kafka import Consumer
import json
import asyncio
import websockets
class ClinicalDashboardConsumer:
def __init__(self):
self.consumer = Consumer({
"bootstrap.servers": "kafka:9092",
"group.id": "clinical-dashboard-v1",
"auto.offset.reset": "latest",
"enable.auto.commit": False,
"max.poll.interval.ms": 30000,
"fetch.min.bytes": 1,
"fetch.wait.max.ms": 100,
})
self.consumer.subscribe([
"healthcare.adt.events",
"healthcare.labs.results",
"healthcare.alerts.critical"
])
self.websocket_clients = set()
async def stream_to_dashboard(self):
"""Stream clinical events to dashboard via WebSocket."""
while True:
msg = self.consumer.poll(timeout=0.1)
if msg is None:
continue
if msg.error():
continue
event = json.loads(msg.value())
dashboard_event = self.transform_for_dashboard(event)
# Push to all connected dashboard clients
if self.websocket_clients:
await asyncio.gather(*[
ws.send(json.dumps(dashboard_event))
for ws in self.websocket_clients
])
self.consumer.commit(asynchronous=False)
def transform_for_dashboard(self, event):
"""Transform FHIR event to dashboard-friendly format."""
return {
"type": event["event_type"],
"resource": event["resource_type"],
"patient_id": event["patient_id"],
"timestamp": event["timestamp"],
"summary": self.build_summary(event),
"priority": "critical"
if event.get("is_critical") else "normal"
}Analytics Pipeline Consumer (Micro-Batch)
class AnalyticsPipelineConsumer:
"""Micro-batch consumer that writes to Delta Lake."""
def __init__(self, batch_size=1000, flush_interval_sec=60):
self.consumer = Consumer({
"bootstrap.servers": "kafka:9092",
"group.id": "analytics-pipeline-v1",
"auto.offset.reset": "earliest",
"enable.auto.commit": False,
"max.poll.records": batch_size,
"isolation.level": "read_committed",
})
self.consumer.subscribe([
"healthcare.adt.events",
"healthcare.labs.results",
"healthcare.medications.orders"
])
self.buffer = []
self.batch_size = batch_size
def consume_and_load(self):
"""Consume events in micro-batches, load to Delta Lake."""
while True:
msg = self.consumer.poll(timeout=1.0)
if msg and not msg.error():
self.buffer.append(
json.loads(msg.value())
)
if len(self.buffer) >= self.batch_size:
self.flush_to_delta_lake()
def flush_to_delta_lake(self):
"""Write buffered events to Delta Lake bronze layer."""
if not self.buffer:
return
df = spark.createDataFrame(self.buffer)
df.write.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.save("/data/healthcare/bronze/kafka_events")
self.consumer.commit(asynchronous=False)
self.buffer.clear()For the Delta Lake side of this pipeline, see our detailed guide on Delta Lake for healthcare with ACID transactions and time travel.
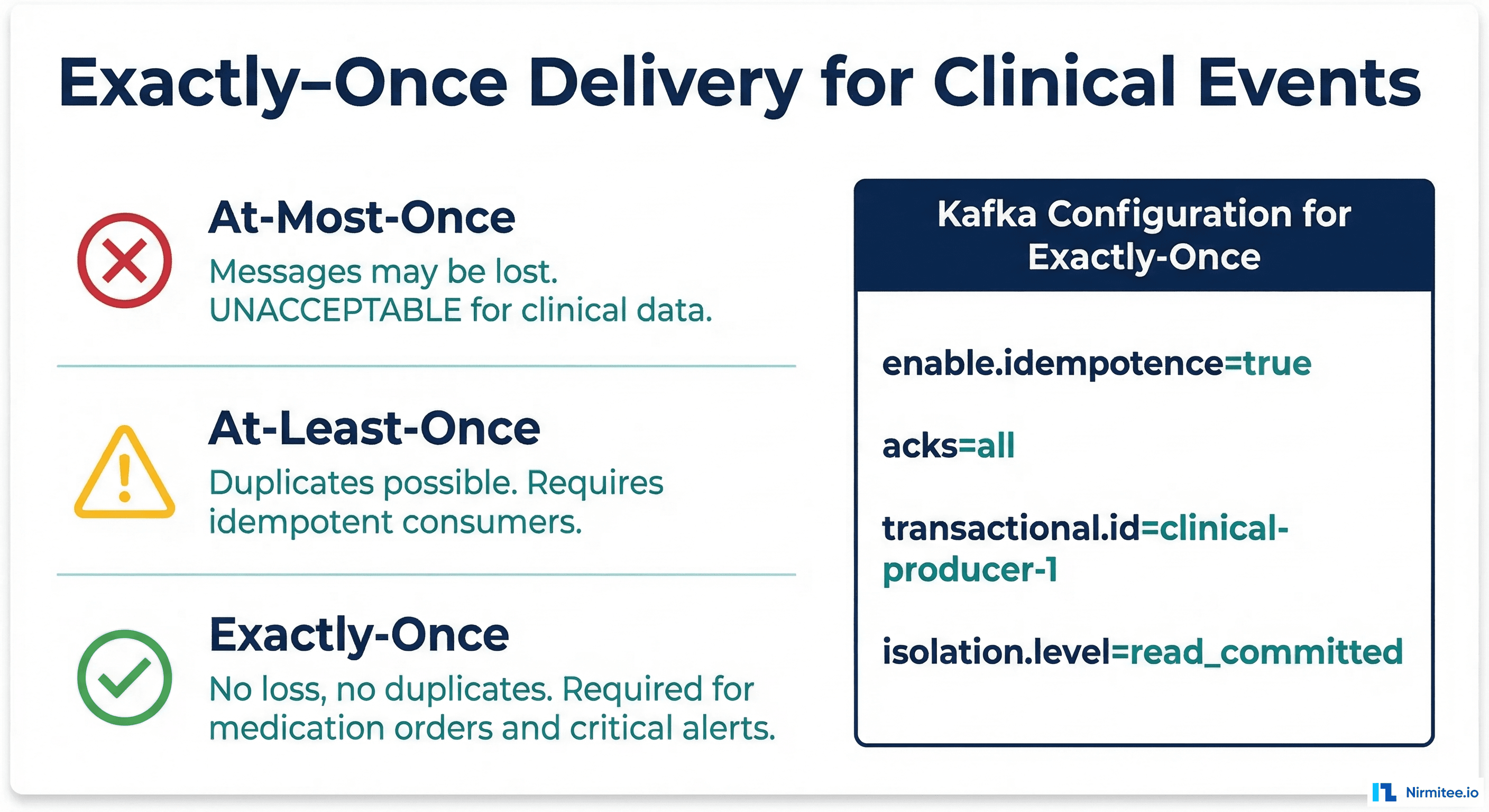
Exactly-Once Delivery for Clinical Events
For clinical data, "at-least-once" delivery means a medication order might be recorded twice. "At-most-once" means it might be lost entirely. Neither is acceptable. Kafka exactly-once semantics (EOS) guarantee that each clinical event is processed exactly one time, even in the face of producer retries, consumer crashes, or broker failures.
Configuring Exactly-Once End-to-End
# Producer: transactional exactly-once
producer_config = {
"bootstrap.servers": "kafka:9092",
"enable.idempotence": True,
"acks": "all",
"transactional.id": "clinical-ehr-producer-001",
"max.in.flight.requests.per.connection": 5,
}
producer = Producer(producer_config)
producer.init_transactions()
# Wrap clinical writes in a transaction
try:
producer.begin_transaction()
# Publish patient admission and associated resources
# atomically — all succeed or all fail
producer.produce("healthcare.adt.events",
key=patient_id, value=admit_event)
producer.produce("healthcare.adt.events",
key=patient_id, value=encounter_event)
producer.produce("healthcare.medications.orders",
key=patient_id, value=med_order_event)
producer.commit_transaction()
except Exception as e:
producer.abort_transaction()
raise
# Consumer: read_committed isolation
consumer_config = {
"bootstrap.servers": "kafka:9092",
"group.id": "clinical-consumer-v1",
"isolation.level": "read_committed",
"enable.auto.commit": False,
}Exactly-Once Checklist for Healthcare Kafka
| Component | Setting | Why It Matters |
|---|---|---|
| Producer | enable.idempotence=true | Prevents duplicate messages from retries |
| Producer | acks=all | Ensures all replicas acknowledge before confirming |
| Producer | transactional.id set | Enables atomic multi-topic writes |
| Broker | min.insync.replicas=2 | Prevents data loss if one broker fails |
| Consumer | isolation.level=read_committed | Only reads committed transaction results |
| Consumer | enable.auto.commit=false | Manual commit after processing confirmed |
Production Deployment Considerations
Monitoring Healthcare Kafka Clusters
# Prometheus alerting rules for healthcare Kafka
groups:
- name: healthcare-kafka-alerts
rules:
# Alert if consumer lag exceeds 5 minutes
- alert: ClinicalConsumerLagHigh
expr: |
kafka_consumer_group_lag_sum{
group=~"clinical-.*"
} > 30000
for: 5m
labels:
severity: critical
annotations:
summary: "Clinical consumer lag > 5 min"
description: "Consumer group {{ $labels.group }}
has {{ $value }} messages lag"
# Alert if under-replicated partitions
- alert: HealthcareUnderReplicated
expr: |
kafka_server_replica_manager_under_replicated_partitions > 0
for: 2m
labels:
severity: critical
annotations:
summary: "Under-replicated partitions detected"
# Alert if producer error rate spikes
- alert: ClinicalProducerErrors
expr: |
rate(kafka_producer_record_error_total{
client_id=~"clinical-.*"
}[5m]) > 0.01
for: 3m
labels:
severity: warningFor comprehensive monitoring strategies, see our guide on 7 metrics every healthcare integration team should track and our article on alerting for healthcare systems with PagerDuty runbooks.
Frequently Asked Questions
How does Kafka compare to a healthcare integration engine like Mirth Connect?
They serve different purposes and work well together. Mirth Connect excels at protocol translation (HL7v2 to FHIR, CSV to HL7v2) and message transformation. Kafka excels at high-throughput event distribution, replay, and stream processing. The recommended architecture: Mirth Connect as the protocol translator on the edges, Kafka as the central event backbone. Mirth produces to Kafka topics after translating messages; downstream consumers read from Kafka.
What Kafka cluster size do I need for a hospital?
A 500-bed hospital generating ~5,000 events per minute needs a 3-broker cluster minimum (for replication factor 3). Each broker should have 32GB RAM, 8+ cores, and NVMe SSDs. For health systems with multiple hospitals, scale to 5-7 brokers. The primary bottleneck is usually disk I/O for retention, not CPU or network. Budget $15-25K/year for a self-managed cluster or $30-50K/year for Confluent Cloud.
Is Kafka HIPAA-compliant?
Kafka itself is infrastructure software, so HIPAA compliance depends on your deployment. Requirements: encrypt data in transit (TLS), encrypt data at rest (disk encryption), implement ACLs for topic access, enable audit logging, and sign a BAA with your infrastructure provider. Confluent Cloud offers HIPAA-eligible deployments. Self-managed deployments must configure encryption, authentication (SASL/SCRAM or mTLS), and authorization (Kafka ACLs) manually.
How do I handle message ordering across multiple topics?
Kafka guarantees ordering within a partition, not across topics. If you need a patient admission to be processed before their medication order, and they are on different topics, use Kafka Streams with a windowed join: buffer events from both topics in a time window, then process them in the correct order. Alternatively, use a single topic with event type headers and partition by patient ID.
What happens if Kafka goes down?
With replication factor 3 and min.insync.replicas=2, Kafka tolerates one broker failure with zero data loss. Producers fail over to available brokers automatically. Consumers rebalance and resume from committed offsets. For multi-datacenter resilience, use Kafka MirrorMaker 2 to replicate across data centers. The key metric: monitor under-replicated partitions and alert immediately when any appear.
Should I use Avro or Protobuf for healthcare event schemas?
Both work well. Avro has better Schema Registry integration and is the Confluent ecosystem default. Protobuf has stronger cross-language support and more explicit typing. For healthcare teams primarily using Java/Python with the Confluent platform, choose Avro. For teams with Go/Rust services or gRPC APIs, choose Protobuf. The critical point is to use a schema at all; untyped JSON events are the source of most healthcare integration failures.