Your Mirth Connect implementation is failing. Maybe the channels are down more than they are up. Maybe nobody can explain what half the channels do. Maybe you are the third team assigned to "fix the integration layer" and the previous two teams quit, got reassigned, or were let go. The good news: it is almost certainly not Mirth's fault. The bad news: the real problems are harder to fix than a software bug.
According to industry research, 70% of healthcare integration failures are governance and process issues, not technical problems. The integration engine works fine. What fails is the people, processes, and organizational structures around it. Failed integration projects waste an average of $200,000 to $500,000 before organizations restart with a different approach (HIMSS, 2024). That money buys a lot of governance framework.
This article is for the frustrated integration teams, the CIOs planning their second attempt, and the consultants called in to rescue a burning platform. We will walk through the five most common failure patterns, the warning signs that your implementation is dying, and a concrete rescue playbook that has worked for organizations ranging from 50-bed community hospitals to 2,000-bed academic medical centers.
It Is Probably Not Mirth's Fault
Let us address this directly. Mirth Connect has been processing billions of healthcare messages since 2006. It powers integration at thousands of healthcare organizations worldwide. When an implementation fails, blaming the tool is the easiest explanation and almost always the wrong one.
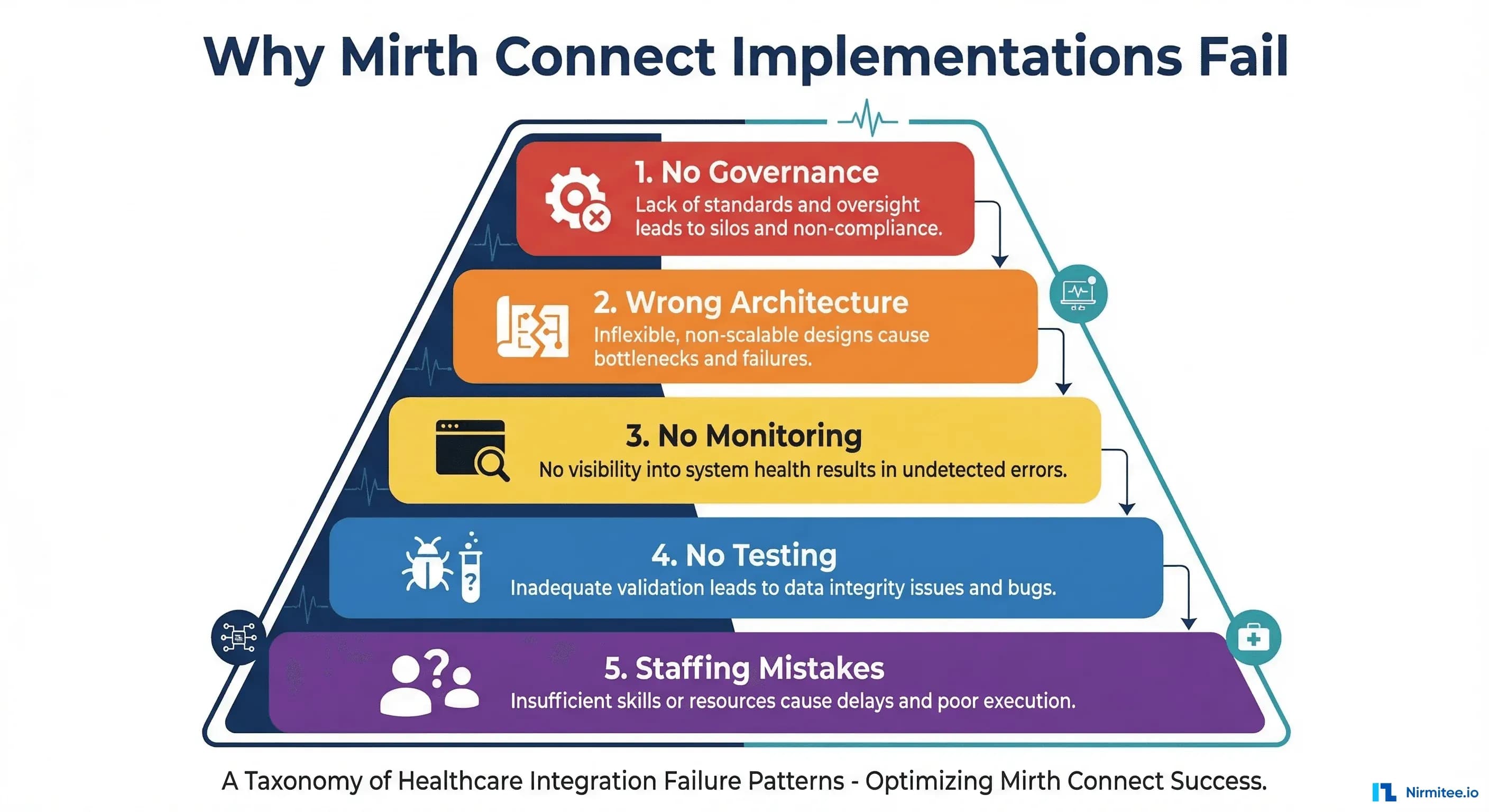
Here is what actually fails:
- Governance: No standards, no documentation, no review process. Channels are created ad hoc by whoever needs one, with no coordination.
- Architecture: Monolithic channels doing too much, no error handling, no separation of concerns.
- Monitoring: Nobody knows when channels fail until clinicians complain that data is missing.
- Testing: Changes are tested manually (or not at all), and regressions accumulate.
- Staffing: One person knows everything, and when they leave, the implementation dies with their tribal knowledge.
The pattern is consistent across organizations. A Gartner analysis of healthcare IT project failures found that technical platform limitations account for fewer than 15% of failures. The remaining 85% are process, governance, and organizational issues. With 60-80% of US hospitals still running HL7v2 interfaces, the integration engine is mission-critical infrastructure that demands the same operational rigor as the EHR itself.
Failure Pattern 1: No Governance
This is the most common failure pattern and the hardest to see from inside the organization. It starts innocently: a developer needs to send ADT messages to a new system. They create a channel. It works. Another developer needs lab results flowing to a different system. They create another channel. It works too. Fast forward two years, and you have 150 channels with no naming convention, no documentation, no change management process, and no single person who understands all of them.
What No-Governance Looks Like
- Naming chaos: Channels named "ADT_Feed," "ADT Feed 2," "ADT_Feed_COPY," "test_adt_do_not_delete," and "Johns_channel." Nobody knows which is production.
- No documentation: The only documentation is the channel configuration itself, and even that is cryptic because transformer code has no comments.
- Tribal knowledge: Ask who built channel X and the answer is "Dave, but he left in 2023." Ask what it does and the answer is "we think it sends lab orders, but we are not sure to where."
- No change management: Changes are made directly in production because there is no staging environment and no deployment process.
- Shadow channels: Developers create channels for "temporary" needs that become permanent. Nobody tracks them. Some have been running for years with nobody knowing they exist.
The cost of no governance compounds over time. Each new channel added without standards makes the existing mess harder to untangle. Organizations that let this pattern run for 3-5 years typically face a complete rebuild because the cost of documenting and standardizing the existing channels exceeds the cost of starting over. For strategies on proper channel organization, see our guide on Mirth Connect channel design patterns.
Failure Pattern 2: Wrong Architecture
The second pattern is architectural. Channels are designed as monolithic processing pipelines that do too much in a single channel. A single channel receives HL7 messages, transforms them, validates them, routes them to three different destinations, handles errors for each destination differently, and logs everything to a database. When one destination is down, the entire channel backs up. When the transformer logic needs to change for one destination, the risk of breaking the other two is high.
Architectural Anti-Patterns
- The God Channel: One channel that handles ADT, ORM, ORU, and MDM messages with a 500-line JavaScript transformer that branches on message type. Untestable, unmaintainable, and guaranteed to break when anyone changes anything.
- No error handling: Messages that fail transformation are silently dropped. No dead letter queue, no alerting, no way to reprocess failed messages.
- Direct database writes: Channels that write directly to application databases instead of using APIs. When the database schema changes, channels break in ways that are difficult to diagnose.
- No message queuing: Destinations are connected synchronously. When a destination system is slow or down, the entire channel stops processing, creating a cascade of failures across the integration layer.
- Hardcoded configuration: IP addresses, ports, credentials, and business rules embedded directly in channel configurations instead of externalized in configuration maps.
The right architecture separates concerns: one channel per message type per destination, with shared code template libraries for common transformations. Error handling channels catch and queue failed messages for reprocessing. Configuration is externalized so the same channel definition works across development, staging, and production environments. Learn more about building resilient architectures in our article on building a robust HL7 interface engine.
Failure Pattern 3: No Monitoring
Channels fail silently. This is the default behavior of most integration engines, and Mirth Connect is no exception. A channel stops processing messages because a destination system changed its IP address. The channel error counter increments. Nobody is watching the error counter. Two days later, a clinician notices that lab results have not been arriving for 48 hours. The help desk gets involved. The integration team investigates. The fix takes 30 seconds. The two days of missing lab results take two weeks to reconcile.
Monitoring Gaps That Kill Implementations
- No alerting on channel errors: Errors accumulate in the Mirth dashboard, but nobody checks the dashboard proactively.
- No message volume monitoring: A channel that normally processes 500 messages per hour drops to zero. Nobody notices because there is no baseline and no anomaly detection.
- No queue depth monitoring: Destination queues grow to 10,000 messages before anyone notices. By then, the system is so backed up that clearing the queue causes its own problems.
- No latency tracking: Messages take 30 seconds to process instead of the normal 200 milliseconds. The system is technically working but degraded enough to cause clinical workflow issues.
- No dashboard: The only way to check channel health is to log into the Mirth Administrator and manually inspect each channel. With 100+ channels, this is a full-time job that nobody does.
Production monitoring is not optional for healthcare integration. For a comprehensive approach to solving this, see our deep dive on what reliable Mirth Connect monitoring looks like in production.
Failure Pattern 4: No Testing
Manual testing is the norm in most Mirth Connect implementations. A developer makes a change, opens the Mirth Administrator, sends a sample message through the channel, and checks whether it arrived at the destination. If it did, the change is deployed to production. This process has three fatal flaws: it does not cover edge cases, it does not catch regressions, and it does not scale.
The Real Cost of No Testing
- Regression cascades: A fix to one channel's transformer breaks three other channels that depend on the same code template. Nobody knows until production data is corrupted.
- Fear of change: The integration team becomes paralyzed. They know that any change might break something, so they avoid changes. Technical debt accumulates. The system becomes increasingly fragile.
- Production-as-test: Without a test environment, every deployment is tested in production. Some organizations create a "test" channel group in their production Mirth instance, which is production with extra steps.
- No confidence in deployments: Every deployment is a white-knuckle affair. The team deploys on Friday afternoon (bad idea), watches the channels for an hour, declares victory, and goes home. The problem appears Monday morning when the full message volume hits.
Automated testing transforms the integration team from reactive firefighters to proactive engineers. Our guide on automated testing for Mirth Connect shows exactly how to build a CI/CD pipeline with unit tests, integration tests, and Docker-based test environments.
Failure Pattern 5: Staffing Mistakes
The most dangerous failure pattern is organizational. One person — let us call them the "Mirth guru" — builds the entire integration layer. They know every channel, every transformer, every quirk. They are the only person who can troubleshoot production issues. They work nights and weekends because they are the only person who can. Then they leave.
The Bus Factor Problem
The "bus factor" is the number of people who would need to be hit by a bus (or, more charitably, win the lottery and quit) before the project collapses. For most Mirth Connect implementations, the bus factor is one. This is not a technology problem. It is a management problem.
- No cross-training: Only one person understands the integration layer. Knowledge transfer never happens because the guru is too busy keeping the system running.
- No documentation: The guru does not document because they do not need documentation — they remember everything. When they leave, the documentation leaves with them.
- Wrong hiring profile: Organizations hire Java developers for a role that requires healthcare domain knowledge, integration architecture expertise, and operational experience. The developer can write code but does not understand HL7, clinical workflows, or production operations.
- Understaffing: One person managing 100+ channels is unsustainable. The standard ratio in mature integration teams is one engineer per 30-50 active channels, with a minimum team size of three for 24/7 coverage.
Warning Signs Your Implementation Is Dying
If you see three or more of these signs, your implementation is in trouble:
- Nobody can explain what all the channels do. If your team cannot produce a complete inventory of channels, their purposes, and their data flows within 24 hours, your documentation has failed.
- Changes require "the one person who knows." If any operational task requires a specific individual, you have a single point of failure.
- Clinicians report data gaps before the integration team. If your first notification of a channel failure comes from a clinician complaint, your monitoring has failed.
- The team is afraid to make changes. If the integration team avoids touching channels because "it might break something," your testing and architecture have failed.
- You have channels with names like "test," "copy," or someone's name. This is the hallmark of ad-hoc development without governance.
- Your staging environment does not exist or does not match production. If changes go directly from development to production, you are testing in production.
- Error queues have thousands of messages that nobody investigates. This means errors are so routine that the team has normalized failure.
- You cannot rebuild the environment from scratch. If your Mirth server died today, could you rebuild it? If the answer involves "we would need to pull the configuration from the database backup," your version control has failed.
The Rescue Playbook
Rescuing a failed Mirth Connect implementation is a structured process. It takes 12-16 weeks for a mid-size organization (50-200 channels) and requires dedicated resources. Here is the playbook:
Phase 1: Assessment (Weeks 1-2)
Before you fix anything, you need to understand what you have. This phase produces a complete picture of the current state.
- Channel inventory: Export every channel definition. Catalog name, purpose, source, destination(s), message type, daily volume, and last modification date.
- Dependency mapping: Identify which channels feed which systems. Map the data flow from source systems through the integration layer to destination systems.
- Health assessment: Which channels are working? Which have error queues? Which have not processed a message in months? Which are duplicates?
- Stakeholder interviews: Talk to the clinical users. Which interfaces are critical? Which cause the most complaints? Where are the data gaps?
- Risk classification: Classify every channel as critical (patient safety impact), important (workflow impact), or low (convenience only).
Phase 2: Documentation (Weeks 3-5)
Document what exists, starting with the critical channels identified in Phase 1.
- Channel documentation template: Create a standard template covering purpose, source system, destination system, message types handled, transformation logic, error handling, and escalation procedures.
- Data flow diagrams: Create visual diagrams showing how data flows through the integration layer. These diagrams become the primary communication tool for the rest of the rescue.
- Runbook: Document operational procedures: how to restart channels, how to reprocess failed messages, how to deploy changes, how to handle common error scenarios.
Phase 3: Standardization (Weeks 6-9)
Implement the governance framework that should have existed from the beginning.
- Naming convention: Adopt a standard naming convention (e.g.,
SOURCE_MSGTYPE_DESTINATION) and rename all existing channels. - Channel groups: Organize channels into logical groups by clinical domain (ADT, Lab, Radiology, Pharmacy) or by source/destination system.
- Code template libraries: Extract common transformation logic into shared libraries. Eliminate duplicate code across channels.
- Configuration externalization: Move all environment-specific values (hostnames, ports, credentials) to Mirth's Configuration Map.
- Version control: Set up MirthSync or equivalent to store all channel definitions in Git.
Phase 4: Testing (Weeks 10-12)
Build the test infrastructure that will prevent future regressions.
- Test environment: Deploy a dedicated Mirth instance (Docker-based for easy teardown/rebuild) with test databases and mock endpoints.
- Unit tests: Write tests for all code template library functions.
- Integration tests: Write tests for all critical channels. Send test messages and verify correct output.
- CI pipeline: Set up automated testing that runs on every change before deployment.
Phase 5: Monitoring (Weeks 13-14)
Implement production monitoring and alerting.
- Channel health dashboard: Build a dashboard showing the status of all channels, message volumes, error rates, and queue depths.
- Alerting: Configure alerts for channel failures, volume anomalies, queue growth, and latency spikes.
- Escalation procedures: Define who gets paged for what, with clear escalation paths and response time targets.
- Regular reviews: Schedule weekly operational reviews to catch emerging issues before they become crises.
When to Rescue vs. When to Rebuild
Not every failed implementation can be rescued. Sometimes the technical debt is so deep that starting over is cheaper and faster. Here is how to decide:
Rescue When:
- The majority of channels (>60%) are functional and correctly processing messages.
- The core architecture is sound but the governance layer is missing.
- The team has domain knowledge but lacks process discipline.
- Budget constraints prevent a full rebuild.
- Clinical operations cannot tolerate the downtime of a migration to a new platform.
Rebuild When:
- Fewer than 40% of channels are functional.
- The architecture has fundamental flaws (e.g., everything runs in a single channel group with shared global state).
- The Mirth version is so old that upgrading is itself a rebuild.
- Nobody on the current team understands the existing implementation.
- The organization is also migrating EHR systems, which changes all interfaces anyway.
A HealthIT.gov study found that organizations that attempted to rescue deeply broken implementations (>60% of channels non-functional) spent 40% more over two years than organizations that rebuilt from scratch. The rescue kept them running in the short term but never fully resolved the underlying architectural issues. If you are considering a rebuild, our article on setting up Mirth Connect for high availability provides the architectural foundation for getting it right the second time.
Prevention: Governance Framework from Day One
The best rescue is the one you never need. If you are starting a new Mirth Connect implementation or migrating from the open-source version, build the governance framework from day one.
The Minimum Viable Governance Framework
- Naming convention:
SOURCE_MSGTYPE_DESTINATION(e.g.,EPIC_ADT_LABCORP,CERNER_ORM_PAX). Enforced from the first channel. - Documentation requirement: Every channel must have a description field completed with purpose, message types, and contact person. No exceptions.
- Change management: All changes go through version control. PRs are reviewed by at least one other team member. No direct production changes.
- Testing requirement: Every channel must have at least one integration test before deployment to production. Critical channels require edge case testing.
- Monitoring from day one: Channel health dashboards and alerting configured before the first channel goes live.
- Cross-training: No single person owns a channel. At least two people must understand every critical channel.
- Regular reviews: Monthly architecture reviews to catch drift from standards before it becomes technical debt.
Governance Metrics to Track
Metric Target Frequency
Channel documentation coverage 100% Monthly
Channels with automated tests 90%+ Monthly
Mean time to detect failure (MTTD) <5 min Weekly
Mean time to resolve (MTTR) <30 min Weekly
Change failure rate <5% Monthly
Bus factor per channel ≥2 Quarterly
Channels per engineer ≤50 Quarterly
Error queue depth <100 DailyWhat This Costs
Let us talk real numbers. These are based on market rates for healthcare integration engineers in 2025-2026:
- Rescue (50-200 channels): $150,000-$350,000 over 14-16 weeks. Includes assessment, documentation, standardization, testing, and monitoring setup. Requires 2-3 dedicated engineers.
- Rebuild (50-200 channels): $300,000-$700,000 over 6-12 months. Full rebuild from scratch with proper architecture, governance, and testing from day one. Requires 3-4 engineers plus project management.
- Prevention (governance from day one): $20,000-$50,000 additional per year in process overhead. This is 5-10% of the rescue cost, which is why prevention is the obvious answer.
- Doing nothing: $200,000-$500,000 per failed attempt, plus the clinical risk of unreliable integration. Most organizations that do nothing eventually face a regulatory finding or a patient safety event that forces action at a much higher cost.
Building interoperable healthcare systems is complex. Our Healthcare Interoperability Solutions team has deep experience shipping production integrations. We also offer specialized Healthcare Software Product Development services. Talk to our team to get started.
Frequently Asked QuestionsCan we rescue our Mirth implementation while keeping production running?
Yes, and you must. The rescue playbook is designed to run alongside production operations. Phase 1 (assessment) and Phase 2 (documentation) require no changes to the running system. Phase 3 (standardization) makes changes incrementally, one channel group at a time, with rollback plans for each change. The key is never taking on more change at once than you can safely roll back. See our article on top integration failures for more on managing risk during changes.
We are considering switching from Mirth Connect to a different integration engine. Will that fix the problem?
No. If the failure patterns described here — no governance, wrong architecture, no monitoring, no testing, staffing mistakes — are the root cause, switching integration engines will just recreate the same problems on a different platform. Fix the process first. The tool is rarely the problem. Some organizations find that the discipline of a rescue project makes them far more effective on the same platform than a migration to a new one.
How do we convince executive leadership to invest in a rescue when the current system "mostly works"?
Frame it in terms of risk and cost. Calculate the cost of the last three major integration incidents: engineer overtime, clinical workarounds, data reconciliation, regulatory reporting. Multiply by the frequency. Compare that annualized cost to the one-time rescue investment. Most organizations find the rescue pays for itself within 12-18 months in avoided incident costs alone, not counting the reduced risk of a patient safety event.
What is the minimum team size for a sustainable Mirth Connect operation?
Three engineers minimum for 24/7 coverage of a production integration layer. This provides vacation coverage, sick day coverage, and ensures no single point of failure. For organizations with more than 100 channels, plan for one engineer per 30-50 active channels. Include at least one senior engineer who can handle architecture decisions and complex troubleshooting.
Should we hire Mirth specialists or train existing staff?
Both. For the rescue itself, bring in at least one experienced Mirth consultant who has done this before. They will identify issues faster and avoid common pitfalls. Simultaneously, cross-train your existing team. The goal is to end the rescue with an internal team that can sustain the implementation independently. The consultant should be building capability, not creating another single point of failure.
The Bottom Line
Your Mirth Connect implementation did not fail because of Mirth Connect. It failed because of missing governance, wrong architecture, absent monitoring, no testing, or staffing mistakes. Probably a combination of several. The rescue playbook is straightforward: assess what you have, document it, standardize it, test it, and monitor it. It takes 14-16 weeks of dedicated effort for a mid-size organization.
The harder question is whether your organization has the will to invest in the process discipline that prevents the next failure. The governance framework is not complicated. The naming conventions, documentation requirements, testing protocols, and monitoring standards are all well-established practices. The challenge is maintaining them when deadlines are tight, budgets are squeezed, and the integration team is asked to "just get it done" without the overhead of proper process.
Every shortcut taken today becomes technical debt that compounds tomorrow. Every undocumented channel, every untested change, every unmonitored interface adds to the fragility of your integration layer. And in healthcare, where integration failures mean delayed clinical data, broken workflows, and potential patient harm, that fragility is not an acceptable risk.