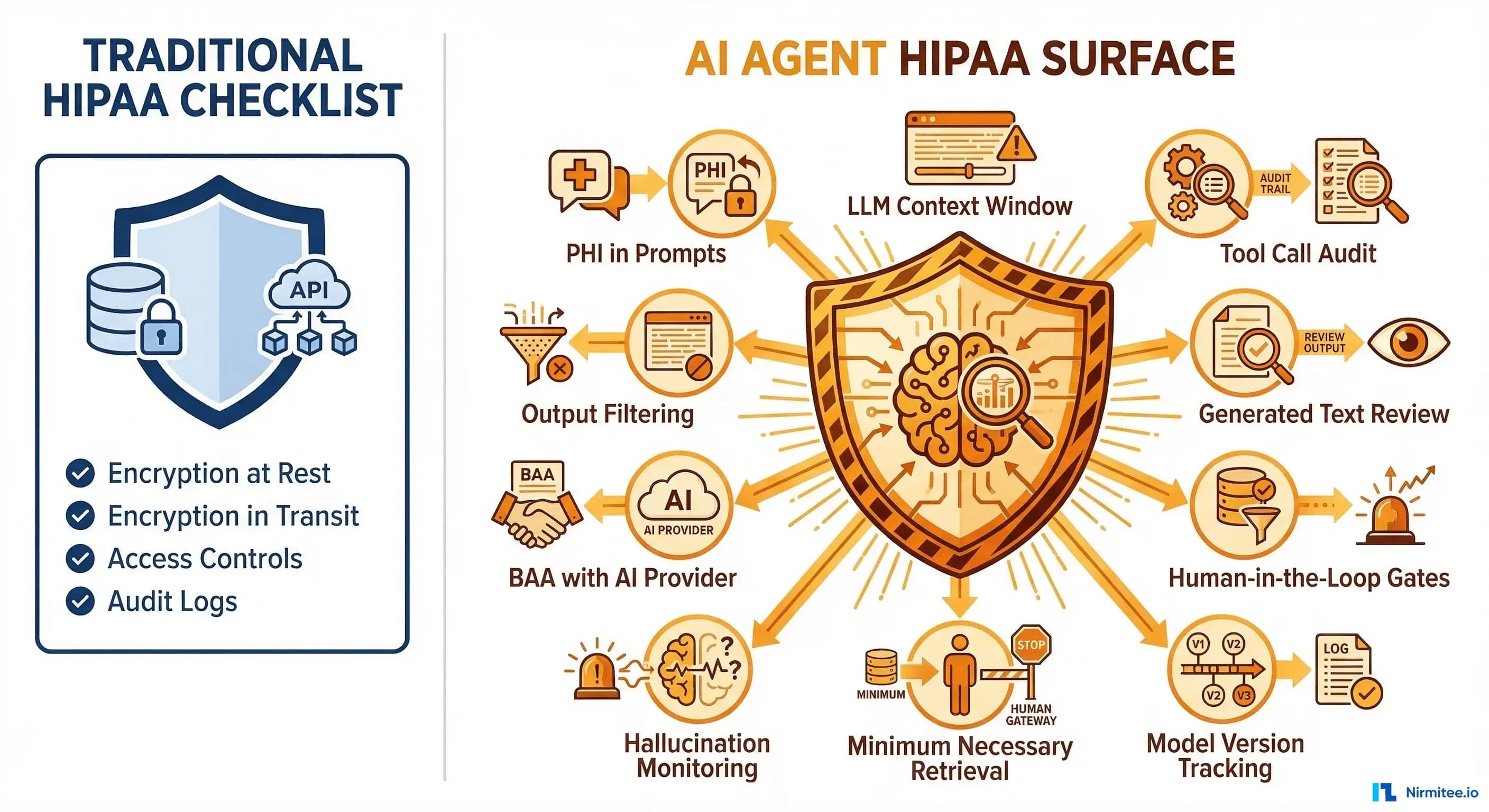
I shipped my first HIPAA-compliant AI agent in late 2024. We had the checklist. Encryption at rest, encryption in transit, access controls, audit logs, BAA signed. The compliance officer signed off. We deployed.
Within a week, our security review flagged something the checklist never mentioned: the agent was pulling entire patient records into its context window to answer simple medication questions. Every inference was an implicit disclosure event. Every tool call was an unlogged PHI access. And the generated output? It occasionally surfaced lab values from patients the clinician hadn't even asked about.
The standard HIPAA checklist was designed for a world of databases and REST APIs — systems where data flows are deterministic and auditable by design. AI agents break every assumption that checklist was built on. They reason over PHI. They make autonomous decisions about what data to access. They generate text that might contain information they were never explicitly given. And every single one of these behaviors creates a compliance surface that your existing controls don't cover.
This is not a theoretical concern. According to a 2025 scoping review of 464 studies on LLMs and patient health information, 38.4% failed to report whether they implemented effective measures to protect PHI. The gap between what teams think they're covering and what they're actually exposed to is enormous.
The Four Compliance Surfaces Your Checklist Misses
Traditional HIPAA compliance assumes a request-response model: a user authenticates, queries a database, receives specific records. An AI agent obliterates this model. Here are the four surfaces that emerge the moment you put an LLM between a clinician and a FHIR server.
1. PHI in the LLM Context Window — Yes, the Prompt Itself Is PHI
When your agent constructs a prompt that includes "Patient John Smith, DOB 03/15/1982, current medications: Metformin 500mg, Lisinopril 10mg," that prompt is electronic protected health information. It's being transmitted to a compute environment, stored in memory (however briefly), and processed by a model. Under 45 CFR 164.312, this transmission requires encryption, access controls, and audit logging — the same as any other PHI transmission.
Most teams encrypt the API call (TLS covers transmission) but completely miss that the prompt contents are now sitting in GPU memory on the inference provider's infrastructure. If you're using a cloud-hosted model, that memory is managed by the provider. If your BAA with them doesn't explicitly cover inference-time data handling, you have a gap.
Practical implication: your prompt construction logic is now a PHI handling system. It needs the same controls as your database layer.
2. Agent Decisions as "Use" of PHI
HIPAA defines "use" as the sharing, employment, application, utilization, examination, or analysis of PHI within a covered entity. When your agent reads a patient's lab results and decides to flag an abnormal creatinine level, that inference is a "use" of PHI. When it decides NOT to flag something, that's also a use — it examined the data and made a determination.
This matters because every use of PHI must be for an authorized purpose under the minimum necessary standard. If your agent is making inferences beyond what the clinician asked for — summarizing unrelated conditions, correlating across visits, identifying patterns the user didn't request — each of those is an additional "use" that needs justification.
3. Generated Text May Contain PHI from Training Data
This is the surface that keeps compliance officers up at night. LLMs can memorize training data. If a model was trained on (or fine-tuned with) clinical text, it can reproduce fragments of that text in its outputs — including patient identifiers, diagnoses, and treatment details that belong to entirely different patients.
Research from PMC's multi-model assurance analysis found that hallucination rates in clinical contexts range from 50% to 82% across models and prompting methods. While not all hallucinations involve PHI leakage, the risk of generating clinically plausible but factually incorrect information — potentially including memorized patient data — is nonzero and largely unmeasured.
A 2025 study on medical LLM vulnerabilities demonstrated that replacing just 0.001% of training tokens with medical misinformation produces models that propagate medical errors. The memorization risk runs in both directions.
4. Tool Calls — Every FHIR Read Is an Access Event
When your agent calls a FHIR API to read Patient/123, MedicationRequest?patient=123, and Observation?patient=123&category=laboratory, that's three PHI access events. Under HIPAA's audit control requirements (45 CFR 164.312(b)), each one must be logged with enough detail to reconstruct who accessed what, when, and why.
The "why" is where agents break traditional audit models. A human user accessing a patient record has an implicit "why" — they're the treating clinician, they clicked the chart. An agent accessing records has a chain of reasoning: the user asked a question, the agent decided it needed lab results, it formulated a FHIR query, it received the response. Your audit trail needs to capture this entire chain, not just the API call.
The BAA Question: Who Is Your Business Associate?
If your agent sends PHI to an external LLM provider — OpenAI, Anthropic, Google, anyone — that provider is a business associate under HIPAA. You need a BAA with them. No exceptions, no workarounds, no "but we de-identify first" (unless you've actually implemented Safe Harbor or Expert Determination de-identification, which most teams haven't).
The good news: the major providers now offer BAAs. The bad news: the coverage varies significantly, and the "shared responsibility model" means a signed BAA doesn't automatically make your implementation compliant.
Here's the current landscape as of early 2026:
Azure OpenAI: BAA available as part of Microsoft's standard HIPAA/HITRUST compliance. GPT-4 and GPT-4o are HIPAA-eligible services when deployed in Azure with proper configuration. Your data is not used for training. This is currently the most straightforward path for teams already in the Microsoft ecosystem.
AWS Bedrock: BAA available under the AWS BAA framework. Claude (Anthropic), Titan, and Llama models are accessible through Bedrock with HIPAA eligibility. Anthropic's Claude is notably available through all three major cloud providers with HIPAA-compliant infrastructure — a unique position among foundation models.
Google Cloud Vertex AI: BAA available under Google Cloud's HIPAA compliance framework. Gemini models are HIPAA-eligible services. Same shared responsibility model applies.
Anthropic API (Direct): BAA available for API customers upon request. Claude models are covered. Anthropic has expanded its healthcare focus with Claude for Healthcare launched in 2025.
OpenAI API (Direct): BAA available for Enterprise and API tier customers. ChatGPT Free, Plus, and Team tiers are explicitly NOT covered under any BAA and must not be used with PHI.
Critical nuance: a signed BAA covers the provider's infrastructure. It does not cover how you use that infrastructure. If you send unencrypted PHI in prompt metadata, store conversation histories with PHI in an uncovered logging service, or fail to implement access controls on your end, the BAA doesn't protect you. The shared responsibility model means you own your application layer's compliance.
Minimum Necessary: The Principle That Should Reshape Your Architecture
The Minimum Necessary Standard requires that covered entities limit PHI access to the minimum amount needed for the intended purpose. For traditional systems, this means role-based access controls and scoped queries. For AI agents, this principle should fundamentally reshape how you build your retrieval layer.
The wrong approach — and I've seen this in production systems — is to dump the entire patient record into the context window and let the LLM figure out what's relevant. A typical patient record might run 50,000+ tokens. You're paying roughly $0.75 per inference call, and you're exposing every piece of PHI the patient has to the model, regardless of the question being asked.
The correct approach is to treat RAG (Retrieval-Augmented Generation) not just as a performance pattern, but as a compliance pattern. When a clinician asks "What are this patient's current medications and any recent interactions?", your retrieval layer should pull only MedicationRequest and MedicationAdministration resources — not the full chart. The result: 3,000 tokens, $0.04 per call, and a dramatically smaller compliance surface.
This is one of the rare cases where compliance requirements and cost optimization point in exactly the same direction. Building a targeted retrieval layer makes your agent cheaper, faster, and more compliant simultaneously.
Implementation checklist for minimum necessary retrieval:
- Map each agent capability to the specific FHIR resource types it needs
- Implement query-time resource filtering — the agent should never have access to resource types outside its scope
- Log which resources were retrieved vs. which were available (the "what I accessed" vs. "what I could have accessed" gap)
- Set token budgets per agent action as a hard ceiling on context size
- Review and audit the retrieval patterns quarterly — are agents accessing resources they don't need?
Audit Trail Requirements: What Your Logs Actually Need to Capture
Under 45 CFR 164.312(b), you must implement mechanisms that "record and examine activity in information systems that contain or use electronic protected health information." For AI agents, this means logging far more than API calls.
Your agent audit log needs to capture the full reasoning chain. Here's the schema we use in production:
{
"timestamp": "2026-03-16T14:23:01.847Z",
"session_id": "sess_a1b2c3d4",
"patient_id_hash": "sha256:e3b0c44298fc...",
"agent_action": "tool_call",
"action_detail": "FHIR read: MedicationRequest?patient=patient-123",
"fhir_resources_accessed": [
"MedicationRequest/med-001",
"MedicationRequest/med-002"
],
"phi_fields_in_context": [
"patient.name",
"medication.code",
"medication.dosage"
],
"llm_provider": "anthropic",
"model_version": "claude-sonnet-4-20250514",
"tokens_in": 2847,
"tokens_out": 412,
"output_reviewed_by": null,
"review_decision": "auto_approved",
"review_policy": "low_impact_summary",
"latency_ms": 1243,
"request_context": {
"user_id": "dr-smith-001",
"user_role": "treating_physician",
"original_query": "What medications is this patient currently taking?",
"purpose": "treatment"
}
}Key design decisions in this schema:
- patient_id_hash: Never log raw patient identifiers in your audit system. Hash them. Your audit log itself is a system containing PHI metadata — keep it minimal.
- phi_fields_in_context: Track which specific PHI fields were included in the prompt, not the values themselves. This lets you audit minimum necessary compliance without creating another PHI store.
- request_context: Capture the "why" — who asked, what role, what was the original question. This is what makes the audit trail actually useful during a compliance review.
- review_decision + review_policy: Track whether a human reviewed the output and which policy determined the review requirement. Critical for demonstrating your clinical decision support governance.
Here's a practical implementation — a HIPAA-compliant audit logger that wraps LangChain agent tool calls:
import hashlib
import json
import time
import logging
from datetime import datetime, timezone
from typing import Any
from langchain.callbacks.base import BaseCallbackHandler
logger = logging.getLogger("hipaa_audit")
class HIPAAAuditLogger(BaseCallbackHandler):
"""
LangChain callback handler that logs every tool call,
LLM invocation, and agent output for HIPAA compliance.
Designed for 45 CFR 164.312(b) audit control requirements.
"""
def __init__(self, audit_sink: str = "structured_log"):
self.audit_sink = audit_sink
self.session_start = time.monotonic()
def _hash_patient_id(self, patient_id: str) -> str:
"""One-way hash patient IDs — never store raw identifiers in logs."""
salt = "your-org-specific-salt-from-env" # Load from env in production
return f"sha256:{hashlib.sha256(f'{salt}:{patient_id}'.encode()).hexdigest()[:16]}"
def _extract_fhir_resources(self, tool_input: dict) -> list[str]:
"""Extract FHIR resource references from tool call inputs."""
resources = []
url = tool_input.get("url", "")
if "/fhir/" in url:
# Parse resource type and ID from FHIR URL
parts = url.split("/fhir/")[-1].split("?")[0]
resources.append(parts)
return resources
def _build_audit_entry(self, **kwargs) -> dict:
return {
"timestamp": datetime.now(timezone.utc).isoformat(),
"latency_ms": int((time.monotonic() - self.session_start) * 1000),
**kwargs
}
def on_tool_start(self, serialized: dict, input_str: str, **kwargs):
tool_name = serialized.get("name", "unknown")
tool_input = kwargs.get("inputs", {})
entry = self._build_audit_entry(
agent_action="tool_call",
action_detail=f"{tool_name}: {input_str[:200]}",
fhir_resources_accessed=self._extract_fhir_resources(
tool_input if isinstance(tool_input, dict) else {}
),
)
logger.info(json.dumps(entry))
def on_llm_start(self, serialized: dict, prompts: list[str], **kwargs):
# Log the LLM call WITHOUT logging prompt contents (PHI)
entry = self._build_audit_entry(
agent_action="inference",
llm_provider=serialized.get("id", ["unknown"])[-1],
model_version=kwargs.get("invocation_params", {}).get("model", "unknown"),
tokens_in=sum(len(p.split()) for p in prompts), # Approximate
phi_fields_in_context=self._detect_phi_fields(prompts),
)
logger.info(json.dumps(entry))
def on_llm_end(self, response, **kwargs):
entry = self._build_audit_entry(
agent_action="inference_complete",
tokens_out=sum(
len(g.text.split())
for g in response.generations[0]
) if response.generations else 0,
)
logger.info(json.dumps(entry))
def _detect_phi_fields(self, prompts: list[str]) -> list[str]:
"""
Detect which categories of PHI are present in prompts.
Returns field categories, NOT the actual values.
"""
phi_indicators = {
"patient.name": ["patient name", "mr.", "mrs.", "dr."],
"patient.dob": ["date of birth", "dob", "born on"],
"medication.code": ["medication", "prescription", "mg", "tablet"],
"observation.lab": ["lab result", "blood test", "creatinine", "a1c"],
"condition.diagnosis": ["diagnosed with", "icd-10", "diagnosis"],
}
detected = []
prompt_text = " ".join(prompts).lower()
for field, indicators in phi_indicators.items():
if any(ind in prompt_text for ind in indicators):
detected.append(field)
return detected
# Usage with LangChain agent
# agent = initialize_agent(
# tools=tools,
# llm=llm,
# callbacks=[HIPAAAuditLogger()],
# )This logger captures the what, when, and why of every agent action without storing the actual PHI values in the audit trail — a critical design decision. Your audit log itself becomes a PHI-adjacent system if it contains raw patient data, creating a recursive compliance problem.
Agent Output Review: When to Auto-Approve vs. Require Human-in-the-Loop
Not every agent output needs a human reviewer. Requiring human review for every interaction defeats the purpose of building an agent in the first place. But some outputs absolutely must have a human in the loop before reaching a clinician — and getting this boundary wrong has both compliance and patient safety implications.
The decision framework comes down to two axes: clinical impact and output confidence.
High confidence + Low clinical impact → Auto-approve with audit. Appointment scheduling suggestions, patient record summaries for context, administrative task completion. Log everything, but don't gate it.
High confidence + High clinical impact → Human review required. Diagnostic suggestions, treatment recommendations, medication interaction alerts. Even when the agent is confident, a human must validate before these reach a clinician as actionable information. This is where clinical decision support system design intersects directly with HIPAA compliance.
Low confidence + Low clinical impact → Auto-approve with flag. Data entry assistance, form pre-filling, non-clinical communications. Flag it for later review if needed, but don't block the workflow.
Low confidence + High clinical impact → Block output entirely. If the agent isn't confident and the output could affect clinical decisions, don't show it. Escalate to the treating clinician directly. This is your safety valve.
Implementing this requires your agent to output a confidence score alongside every response — not the LLM's token-level probability, but a calibrated assessment of whether the output is supported by the retrieved evidence. We use a simple rubric: did the retrieved FHIR resources contain the information the agent cited? If yes, high confidence. If the agent extrapolated beyond the evidence, low confidence.
Incident Response: "The Agent Said WHAT?"
Your incident response plan needs a new chapter for AI agents. Traditional HIPAA breach scenarios involve unauthorized access or data exfiltration. Agent-specific incidents are different — and often harder to detect.
Scenario 1: Cross-patient data leakage. The agent includes information from Patient A's record in a response about Patient B. This can happen through context window contamination (residual data from a previous query in the same session), RAG retrieval errors (the vector search returned documents from the wrong patient), or LLM hallucination drawing on memorized training data. This is a breach. It triggers the HIPAA Breach Notification Rule. You have 60 days.
Scenario 2: Hallucinated clinical recommendation. The agent generates a medication dosage or diagnostic suggestion that isn't grounded in the patient's actual data. This isn't a HIPAA breach per se, but it's a patient safety event that your compliance framework should capture. If the hallucinated information includes PHI-like data (realistic-seeming patient identifiers, lab values, etc.), it could be a breach even if the data is fabricated — because determining whether generated data matches a real patient's data requires investigation.
Scenario 3: Excessive PHI access. Your audit logs reveal the agent is accessing 10x more FHIR resources than necessary for the queries it's handling. This isn't a breach, but it's a minimum necessary violation that needs remediation before it becomes one. Set up automated alerts: if an agent session accesses more than N resources or M distinct resource types, flag it for review.
For each scenario, your incident response should include: immediate containment (disable the agent or switch to human-only mode), root cause analysis using your audit trail, affected patient notification assessment, remediation and testing before re-enabling the agent, and a post-incident compliance review.
Building This Right from Day One
If you're building a healthcare AI agent today, here's the non-negotiable starting point:
- Sign a BAA with your LLM provider before writing a single line of agent code. Azure OpenAI, AWS Bedrock, Google Vertex AI, Anthropic API, or OpenAI Enterprise. Pick one that offers a BAA. No BAA, no PHI.
- Implement minimum necessary retrieval at the architecture level. Use RAG with FHIR resource-type scoping. Map each agent capability to the specific resources it needs. Set token budgets.
- Build your audit logger before your agent logic. Use the schema and callback pattern above. Every tool call, every inference, every output — logged with context but without raw PHI.
- Define your human-in-the-loop policy. Use the confidence x impact matrix. Implement it as a middleware layer between the agent output and the user interface.
- Plan for incidents. Write the "agent said something wrong" playbook now, not after the first incident. Include cross-patient data leakage, hallucinated clinical content, and excessive PHI access scenarios.
- Test your compliance surfaces, not just your features. Red-team your agent: try to get it to output PHI from other patients, access resources outside its scope, generate clinical recommendations without evidence. Make these tests part of your CI/CD pipeline.
The teams that treat compliance as an architectural concern — not a post-deployment checkbox — are the ones shipping agents that actually survive contact with production healthcare environments. At Nirmitee, we build healthcare software systems where compliance is part of the architecture from day one, not bolted on after the fact. If you're navigating these challenges, we've likely already solved them. Whether it's FHIR-based interoperability, AI-driven clinical decision support, or choosing the right technology stack for healthcare — we ship production systems that pass compliance reviews.
The HIPAA checklist got you to 2020. Your AI agent needs a 2026 compliance framework. Start building it now.
From prior auth to clinical documentation, our Agentic AI for Healthcare practice builds agents that automate real healthcare workflows. We also offer specialized Healthcare AI Solutions services. Talk to our team to get started.