An engineering lead at a digital health company told me her team spent six weeks evaluating agent frameworks before building anything. They prototyped in CrewAI (fast to start, but hit walls on state management), tried LangGraph (powerful but the learning curve ate two sprints), considered Temporal (overkill for their first use case), and finally shipped a custom Python implementation—which they are now re-architecting because it cannot handle the complexity of their second use case.
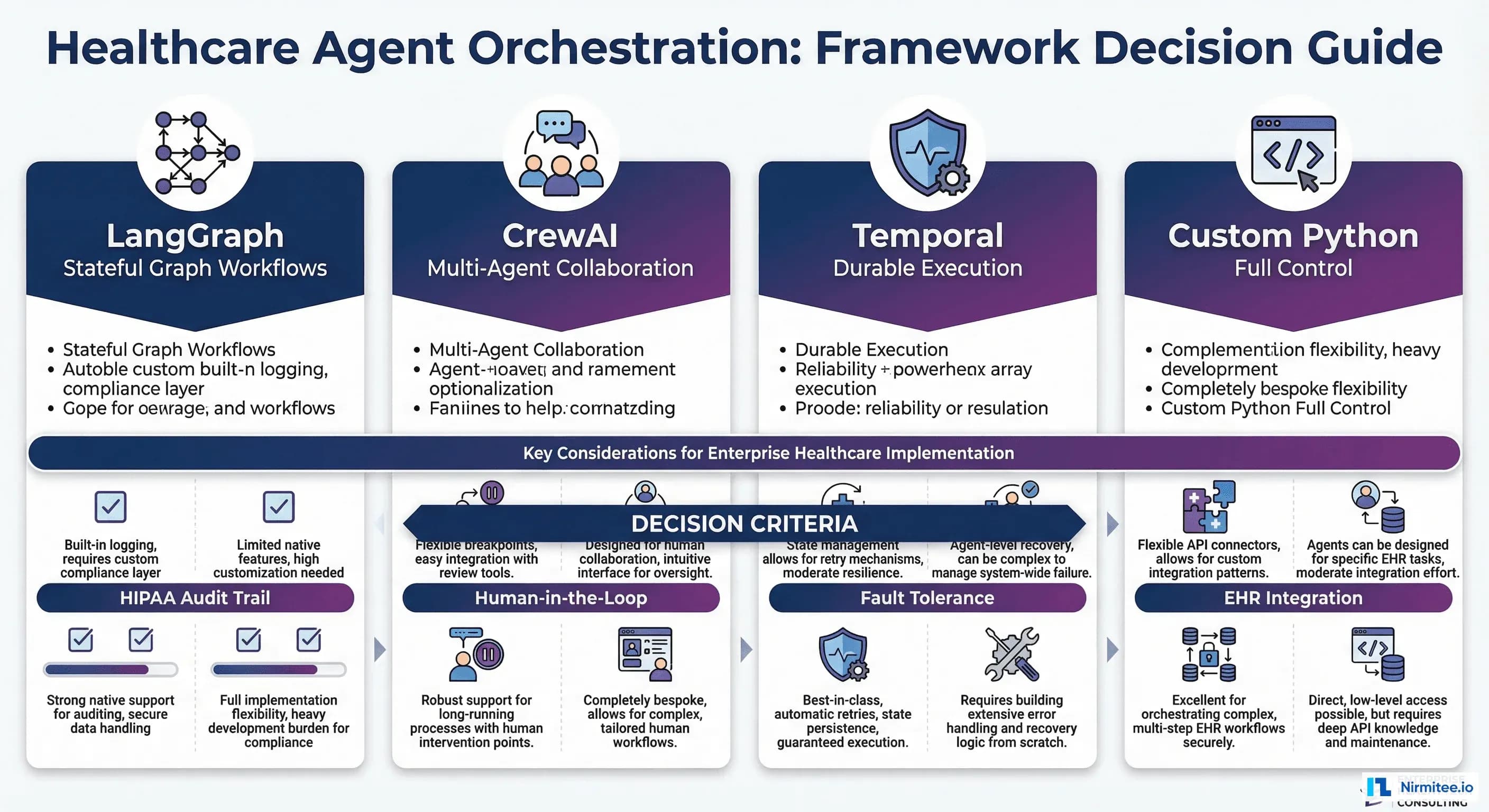
Framework fatigue is real. The agent orchestration landscape has more options than healthcare teams have time to evaluate. LangGraph reached 1.0 in late 2025 and became the default runtime for LangChain agents. CrewAI's multi-agent collaboration model appeals to teams building role-based agent systems. Temporal raised $300M at a $5B valuation and is the gold standard for durable execution. And custom Python remains the most common approach in healthcare, where teams want maximum control over HIPAA-sensitive workflows.
This guide provides the decision framework. Not "which framework is best"—that question has no universal answer—but which framework fits your specific healthcare use case, team, and regulatory requirements.
The Four Options at a Glance
| Framework | Architecture | Best For | Healthcare Fit |
|---|---|---|---|
| LangGraph | Directed graph with stateful nodes | Complex branching workflows with conditional logic | Strong: built-in checkpointing, human-in-the-loop |
| CrewAI | Role-based agent collaboration | Multi-agent teams with defined roles and tasks | Moderate: fast prototyping, weaker audit trails |
| Temporal | Durable execution engine | Long-running, failure-resistant cross-system workflows | Strongest: guaranteed completion, full audit log |
| Custom Python | Whatever you build | Simple workflows or maximum EHR integration control | Depends entirely on engineering investment |
LangGraph: Stateful Agent Workflows
LangGraph models agent workflows as directed graphs where each node represents a processing step, edges define the flow between steps, and state persists across the entire execution. It reached version 1.0 in October 2025 and is now the default runtime for all LangChain agents.
Why LangGraph Works for Healthcare
- State persistence with checkpointing: Every step in the workflow saves state. If a node fails—API timeout from the EHR, LLM rate limit, network partition—the workflow resumes from the last checkpoint, not from the beginning. In healthcare, this means a prior authorization workflow that takes 72 hours does not lose context when a payer API goes down at hour 40
- Built-in human-in-the-loop: LangGraph's interrupt mechanism pauses workflow execution at designated nodes, waits for human input, and resumes. For clinical workflows requiring physician approval or nurse review, this is not an afterthought—it is a first-class feature
- Conditional branching: Clinical workflows are inherently branching. A patient triage agent needs to route differently based on acuity score, insurance type, and available resources. LangGraph's graph model handles this naturally
- Memory management: Both short-term working memory (conversation context) and long-term persistent memory (patient history, prior interactions) are supported natively
LangGraph in Practice: Clinical Documentation Pipeline
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.sqlite import SqliteSaver
from typing import TypedDict, Annotated
import operator
class ClinicalDocState(TypedDict):
patient_id: str
encounter_id: str
transcript: str
clinical_entities: list[dict]
draft_note: str
physician_approved: bool
final_note: str
audit_trail: Annotated[list[str], operator.add]
def extract_clinical_entities(state: ClinicalDocState) -> dict:
"""Extract diagnoses, medications, procedures from transcript."""
entities = clinical_nlp_extract(state["transcript"])
return {
"clinical_entities": entities,
"audit_trail": [f"Extracted {len(entities)} entities"]
}
def generate_draft_note(state: ClinicalDocState) -> dict:
"""Generate SOAP note from extracted entities."""
note = llm_generate_note(
entities=state["clinical_entities"],
patient_id=state["patient_id"]
)
return {"draft_note": note, "audit_trail": ["Draft note generated"]}
def physician_review(state: ClinicalDocState) -> dict:
"""Human-in-the-loop: physician reviews and approves."""
# LangGraph pauses here until physician provides input
return {"audit_trail": ["Awaiting physician review"]}
def should_route_to_review(state: ClinicalDocState) -> str:
"""Route based on confidence score."""
confidence = calculate_confidence(state["clinical_entities"])
if confidence < 0.85:
return "physician_review" # Low confidence: human review
return "auto_approve" # High confidence: auto-approve
# Build the graph
workflow = StateGraph(ClinicalDocState)
workflow.add_node("extract", extract_clinical_entities)
workflow.add_node("generate", generate_draft_note)
workflow.add_node("physician_review", physician_review)
workflow.add_node("write_to_ehr", write_note_to_ehr)
workflow.set_entry_point("extract")
workflow.add_edge("extract", "generate")
workflow.add_conditional_edges("generate", should_route_to_review)
workflow.add_edge("physician_review", "write_to_ehr")
workflow.add_edge("auto_approve", "write_to_ehr")
workflow.add_edge("write_to_ehr", END)
# Persist state for HIPAA audit trail
checkpointer = SqliteSaver.from_conn_string("clinical_docs.db")
app = workflow.compile(checkpointer=checkpointer)LangGraph Limitations in Healthcare
- Learning curve: The graph-based mental model is not intuitive for teams used to sequential code. Multiple sources report that teams need 2-4 weeks to become productive, which is significant for health tech teams with delivery pressure
- Infrastructure requirements: Running LangGraph in production requires careful planning for state synchronization across distributed nodes. Scaling horizontally can create bottlenecks during workload surges
- No native MCP/A2A support: As of early 2026, LangGraph does not natively support Model Context Protocol or Agent-to-Agent Protocol, though community integrations exist
- Overkill for simple workflows: If your agent has a linear pipeline (ingest, process, output), LangGraph's graph model adds complexity without benefit
CrewAI: Multi-Agent Collaboration
CrewAI takes a different approach: instead of defining a graph, you define agents with roles, assign them tasks, and let the framework handle the collaboration. It is the highest-abstraction option, which makes it the fastest to prototype and the most limited when you need fine-grained control.
Why CrewAI Appeals for Healthcare
- Intuitive mental model: Healthcare is inherently team-based. A "crew" of agents mirrors how clinical teams work—a triage nurse agent, a documentation agent, a coding agent, a billing agent. The role-based model maps naturally to clinical workflows
- Fastest time to prototype: CrewAI can have a multi-agent system running in hours, not days. For health tech teams that need to demonstrate feasibility quickly, this speed matters
- Sequential and parallel execution: Tasks can run in sequence (assess, then document, then code) or in parallel (coding and documentation simultaneously)
CrewAI in Practice: Care Team Agent Crew
from crewai import Agent, Task, Crew, Process
# Define agents with healthcare roles
triage_agent = Agent(
role="Clinical Triage Specialist",
goal="Assess patient acuity and route to appropriate care pathway",
backstory="Experienced ER triage nurse with 15 years of experience",
tools=[ehr_query_tool, vitals_assessment_tool],
verbose=True
)
documentation_agent = Agent(
role="Clinical Documentation Specialist",
goal="Generate accurate, complete clinical notes from encounter data",
backstory="Certified medical coder with documentation expertise",
tools=[note_generator_tool, icd10_lookup_tool]
)
coding_agent = Agent(
role="Medical Coding Specialist",
goal="Assign accurate ICD-10 and CPT codes to maximize clean claim rate",
backstory="CPC-certified coder specializing in E/M leveling",
tools=[coding_engine_tool, payer_rules_tool]
)
# Define tasks
triage_task = Task(
description="Assess patient {patient_id} using vitals and chief complaint. "
"Determine acuity level (1-5) and recommended care pathway.",
agent=triage_agent,
expected_output="Acuity assessment with routing recommendation"
)
documentation_task = Task(
description="Generate SOAP note for encounter based on triage assessment "
"and clinical observations.",
agent=documentation_agent,
context=[triage_task], # Receives triage output
expected_output="Complete SOAP note ready for physician review"
)
coding_task = Task(
description="Assign ICD-10 and CPT codes based on the clinical documentation. "
"Verify against payer-specific rules for clean claim submission.",
agent=coding_agent,
context=[documentation_task], # Receives documentation output
expected_output="Coded encounter with confidence scores"
)
# Assemble the crew
care_crew = Crew(
agents=[triage_agent, documentation_agent, coding_agent],
tasks=[triage_task, documentation_task, coding_task],
process=Process.sequential,
verbose=True
)
result = care_crew.kickoff(inputs={"patient_id": "P-12345"})CrewAI Limitations in Healthcare
- Weak audit trails: CrewAI's production readiness is rated "medium" by IBM's framework comparison. For HIPAA-regulated workflows, the lack of built-in state persistence and comprehensive audit logging is a significant gap
- Limited state management: Unlike LangGraph's checkpoint-based state or Temporal's durable execution, CrewAI's state handling is simpler. Long-running clinical workflows that span hours or days need external state management
- Less control over execution: The abstraction that makes CrewAI fast to start also means less control over error handling, retry logic, and conditional branching. In healthcare, where edge cases are clinical safety issues, this matters
- LLM dependency: CrewAI agents rely heavily on LLM reasoning for task execution. In healthcare, you often need deterministic logic (rule-based payer requirements, coding guidelines) mixed with LLM-powered analysis. CrewAI makes the deterministic parts harder to implement
Temporal: Durable Execution for Long-Running Workflows
Temporal is not an AI agent framework—it is a durable execution engine. Workflows written in Python, Go, Java, or TypeScript survive server crashes, network partitions, and week-long delays, continuing exactly where they left off. Temporal raised $300M at a $5B valuation, and it is the infrastructure choice for organizations that cannot afford workflow failures.
Why Temporal Dominates for Healthcare Infrastructure
- Guaranteed completion: A Temporal workflow will complete or explicitly fail with a recorded reason. It will never silently drop a claim submission, lose a prior authorization in progress, or skip a step in a clinical trial enrollment. For revenue cycle agent pipelines, this guarantee is non-negotiable
- Complete audit trail: Every workflow execution, every activity invocation, every retry, every timer, every signal is recorded in Temporal's event history. This is the most comprehensive audit trail of any framework—critical for HIPAA compliance and regulatory audits
- Language-agnostic: Temporal supports Python, Go, Java, TypeScript, and .NET. Healthcare engineering teams that run Go services for FHIR processing and Python services for ML inference can orchestrate both from the same workflow
- Battle-tested at scale: Netflix, Uber, and Stripe run Temporal at massive scale. Healthcare organizations benefit from this battle-testing without having to prove the infrastructure themselves
Temporal in Practice: Prior Authorization Workflow
from temporalio import workflow, activity
from datetime import timedelta
@activity.defn
async def check_pa_requirement(order: dict) -> dict:
"""Check if prior auth is required for this order."""
# Query payer rules database
rules = await payer_rules_db.query(
payer_id=order["payer_id"],
cpt_code=order["cpt_code"]
)
return {"required": rules.pa_required, "criteria": rules.criteria}
@activity.defn
async def submit_pas_request(bundle: dict) -> dict:
"""Submit Da Vinci PAS request to payer."""
response = await fhir_client.post(
f"{bundle['payer_endpoint']}/$submit",
json=bundle["fhir_bundle"]
)
return {"status": response["outcome"], "auth_number": response.get("id")}
@activity.defn
async def gather_clinical_documentation(patient_id: str, criteria: dict) -> dict:
"""Extract required clinical docs from EHR."""
docs = await ehr_client.search_documents(
patient_id=patient_id,
criteria=criteria
)
return {"documents": docs, "completeness_score": calculate_completeness(docs)}
@workflow.defn
class PriorAuthWorkflow:
"""Long-running PA workflow with durable execution."""
@workflow.run
async def run(self, order: dict) -> dict:
# Step 1: Check if PA is required (retries automatically on failure)
pa_check = await workflow.execute_activity(
check_pa_requirement, order,
start_to_close_timeout=timedelta(seconds=30),
retry_policy=RetryPolicy(maximum_attempts=3)
)
if not pa_check["required"]:
return {"status": "NOT_REQUIRED", "proceed": True}
# Step 2: Gather clinical documentation
docs = await workflow.execute_activity(
gather_clinical_documentation,
args=[order["patient_id"], pa_check["criteria"]],
start_to_close_timeout=timedelta(minutes=5)
)
# Step 3: If documentation incomplete, wait for human (up to 48 hours)
if docs["completeness_score"] < 0.9:
await workflow.wait_condition(
lambda: self.documentation_complete,
timeout=timedelta(hours=48)
)
# Step 4: Submit PA request
result = await workflow.execute_activity(
submit_pas_request,
build_pas_bundle(order, docs),
start_to_close_timeout=timedelta(minutes=2)
)
# Step 5: If pended, poll for decision (up to 7 days per CMS rule)
if result["status"] == "pended":
result = await self.poll_for_decision(
result["auth_number"],
timeout=timedelta(days=7)
)
return resultTemporal Limitations in Healthcare
- Not an AI framework: Temporal orchestrates workflows. It does not provide LLM integration, prompt management, or agent abstraction. You build AI logic in activities, Temporal ensures they execute reliably. This means more code for AI-specific patterns
- Steep learning curve: Temporal's programming model (workflows, activities, signals, queries, child workflows) takes weeks to learn properly. The deterministic workflow constraint—no random calls, no direct I/O in workflow code—catches teams off guard
- Infrastructure overhead: Temporal requires running the Temporal Server (or paying for Temporal Cloud). For small teams building their first agent, this is significant overhead. Temporal Cloud starts at $200/month but scales with execution volume
- Overkill for simple agents: A single-purpose chatbot or a document summarization agent does not need durable execution. Temporal's value scales with workflow complexity and duration
Custom Python: When Frameworks Add More Than They Remove
The uncomfortable truth: for many healthcare AI use cases, a well-structured Python application with asyncio, a task queue (Celery/RQ), and a database is sufficient. Frameworks add value when complexity exceeds what custom code can manage cleanly—but they also add dependencies, learning curves, and abstraction leakage.
When Custom Wins
- Single-purpose agents: An agent that reads FHIR resources, applies rules, and writes results does not need a graph or a crew. A Python function with retry logic handles this cleanly
- Maximum EHR integration control: When you need byte-level control over HL7v2 message parsing or custom FHIR search optimization, frameworks can get in the way
- Regulatory constraints on dependencies: Some healthcare organizations have strict policies about third-party dependencies in clinical systems. A custom implementation with minimal dependencies may be the only option that passes security review
- Team expertise: If your team knows Python deeply but has no LangGraph or Temporal experience, the 4-6 weeks of learning curve may not be justified for the first use case
When Custom Breaks Down
- State management complexity: Once your workflow has more than 5 steps with branching, custom state management becomes error-prone. This is where LangGraph or Temporal earns its keep
- Multi-agent coordination: Coordinating multiple agents with shared state and sequential dependencies is where frameworks shine. Custom implementations of this pattern tend to become unmaintainable
- Failure recovery: Building retry logic, dead letter queues, and checkpoint recovery from scratch is engineering effort that Temporal and LangGraph provide out of the box
The Decision Matrix: Healthcare-Specific Criteria
| Criteria | LangGraph | CrewAI | Temporal | Custom |
|---|---|---|---|---|
| HIPAA audit trail | Good (checkpointing) | Weak (manual) | Excellent (event history) | Depends on build |
| Human-in-the-loop | Excellent (native) | Moderate | Good (signals/queries) | Depends on build |
| Fault tolerance | Good (checkpoints) | Weak | Excellent (durable) | Depends on build |
| EHR integration | Moderate (via tools) | Moderate (via tools) | Moderate (via activities) | Excellent (direct) |
| Learning curve | Steep (2-4 weeks) | Gentle (days) | Steep (3-4 weeks) | None (but build time) |
| Time to first agent | 1-2 weeks | 2-3 days | 2-3 weeks | 1-3 days (simple) |
| Multi-agent support | Strong | Excellent | Good (child workflows) | Manual |
| Production observability | Good (LangSmith) | Limited | Excellent (native UI) | Build with OpenTelemetry |
Recommended Patterns by Use Case
Pattern 1: Temporal + LangGraph (Production Revenue Cycle)
Use Temporal as the durable execution backbone for the end-to-end revenue cycle pipeline. Use LangGraph inside Temporal activities for the AI-powered steps (clinical documentation analysis, denial categorization, appeal letter generation). Temporal guarantees the pipeline completes; LangGraph handles the complex reasoning within each step.
Pattern 2: CrewAI for Prototyping, LangGraph for Production
Start with CrewAI to validate the multi-agent concept with stakeholders in 1-2 weeks. Once the concept is proven, rebuild in LangGraph for production with proper state management, audit trails, and human-in-the-loop. The CrewAI prototype informs the LangGraph graph structure.
Pattern 3: Custom Python + Temporal (Infrastructure-Heavy Workflows)
For workflows that are more data pipeline than AI agent—FHIR data ingestion, CDC from EHR systems, batch claim processing—use custom Python activities orchestrated by Temporal. The AI component is minimal; the workflow reliability is critical.
Pattern 4: Custom Python (First Agent, Simple Scope)
For your first healthcare agent—a scheduling assistant, a patient FAQ bot, a simple clinical alert—build custom. Get it to production. Learn from production. Then decide if the second agent needs a framework.
The Production Stack
Regardless of which orchestration framework you choose, the production stack for healthcare agents includes these layers:
- Data layer: FHIR data store, EHR APIs (SMART on FHIR), claims databases, terminology services
- Orchestration layer: Your chosen framework (LangGraph, Temporal, CrewAI, or custom)
- Agent layer: Individual agents with defined capabilities, tools, and guardrails
- Observability layer: OpenTelemetry instrumentation, drift detection, monitoring dashboards
- Governance layer: HIPAA audit logs, regulatory compliance, human-in-the-loop approval workflows
The framework choice matters, but it is one layer in a five-layer stack. Teams that obsess over the framework while neglecting observability, governance, or data quality will fail regardless of whether they chose LangGraph, Temporal, or custom Python. As we detailed in our analysis of pilot-to-production traps, monitoring and data quality are the layers that determine production success.
Making the Decision: A Practical Flowchart
Answer these four questions:
- Question 1: Does the workflow run longer than 1 hour? If yes, Temporal or LangGraph (with persistent checkpointing). Not CrewAI, not custom without significant state management work
- Question 2: Does the workflow have more than 3 decision branches? If yes, LangGraph's graph model handles this naturally. Temporal can do it but requires more boilerplate. CrewAI and custom struggle with complex branching
- Question 3: Is this your team's first agent? If yes, start with custom Python or CrewAI. Learn the domain complexity before adding framework complexity. You can always migrate later
- Question 4: Does the workflow cross system boundaries? (EHR + payer API + claims system + document store) If yes, Temporal's durable execution across distributed systems is the strongest choice. LangGraph handles this but requires more infrastructure work
At Nirmitee, we have built healthcare agent systems on all four of these patterns. We help engineering teams choose the right orchestration approach for their specific use case, build the initial implementation, and establish the production stack that keeps agents running reliably in clinical environments. Talk to our engineering team about your agent architecture.


