If you've worked in healthcare IT for any length of time, you've encountered Mirth Connect. Created by Mirth Corporation, now maintained by NextGen Healthcare as NextGen Connect Integration Engine, Mirth Connect is the most widely deployed open-source healthcare integration engine in the world.
It's free. It's battle-tested. It runs in hospitals, health systems, labs, and healthtech startups across every US state. And for organizations that need to connect healthcare systems without a six-figure software license, it's often the first — and best — choice.
This guide covers everything you need to know: architecture, channel design, deployment, use cases, performance tuning, and how Mirth compares to enterprise alternatives.
If you're evaluating Mirth from the leadership seat rather than the engineering one, start with our What Is Mirth Connect? guide for healthcare leaders — this guide takes the technical view.
Mirth Connect Architecture
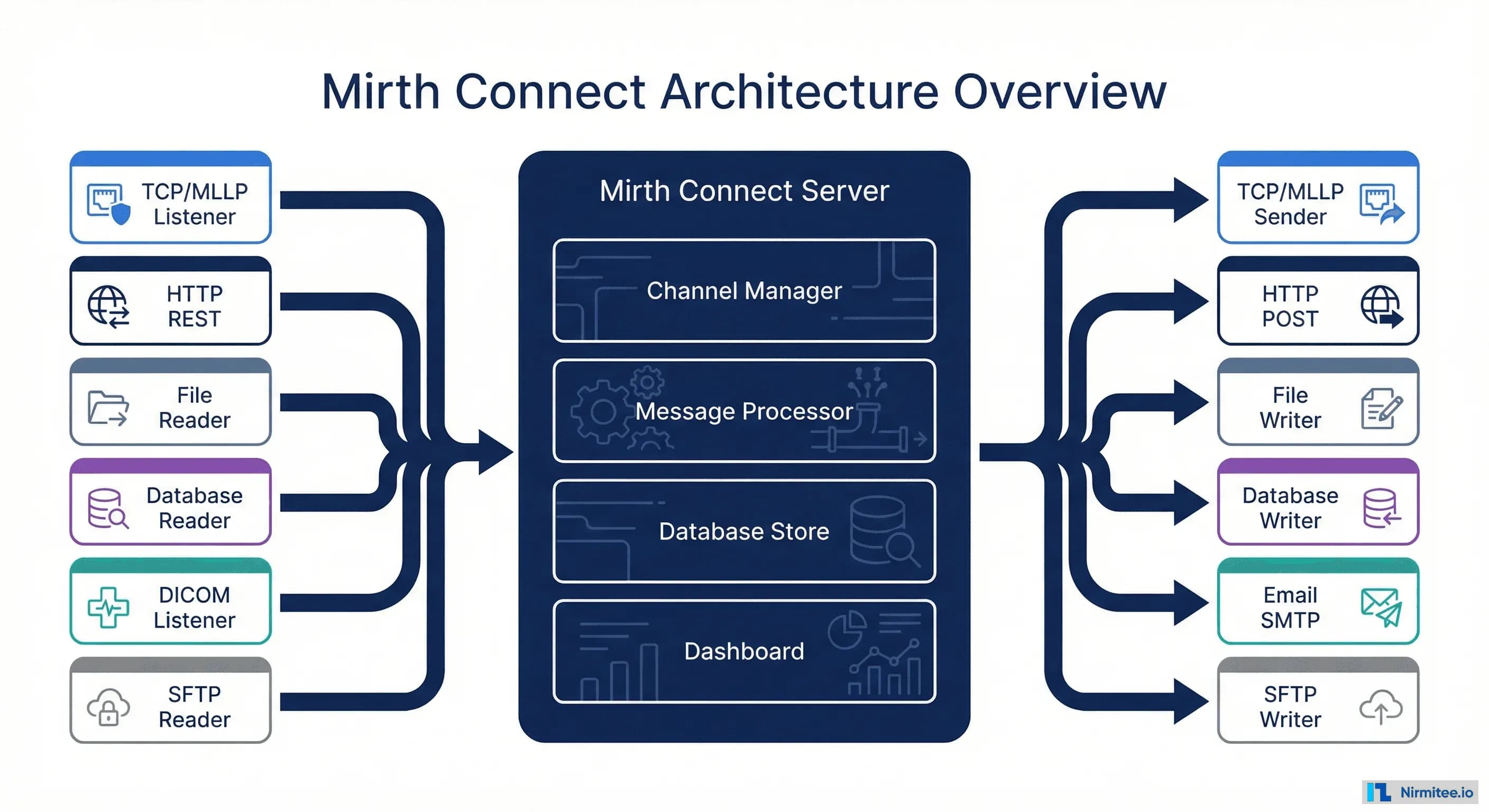
Mirth Connect is a Java-based integration engine that acts as the central hub for all healthcare data traffic. It receives messages from source systems, transforms them, and routes them to destination systems — handling HL7 v2, FHIR, XML, JSON, CSV, DICOM, and virtually any healthcare data format.
The architecture centers on three components:
- Channel Manager — Where you design, configure, and deploy integration channels. Each channel represents one integration flow (e.g., "Lab Orders to LIS" or "ADT Feed to All Systems").
- Message Processor — The runtime engine that receives, transforms, and routes messages in real-time. Handles queuing, retry logic, and error management.
- Database Store — PostgreSQL, MySQL, or Oracle database that stores message history, channel configurations, and metadata for auditing and replay.
Mirth supports a wide range of inbound connectors (TCP/MLLP, HTTP/REST, file readers, database polling, DICOM, SFTP) and matching outbound connectors. This flexibility is why a single Mirth instance can handle lab integrations, radiology workflows, billing feeds, and public health reporting simultaneously.
Anatomy of a Mirth Connect Channel
The channel is the fundamental unit of work in Mirth Connect. Understanding channel architecture is essential for anyone who designs, builds, or troubleshoots integrations.
Every channel follows this flow:
- Source Connector — Receives the raw message. For HL7 v2, this is typically a TCP/MLLP listener on a specific port. For FHIR, it's an HTTP listener.
- Source Filter — Optional validation step. You can filter messages by type (only process ADT^A01, ignore ADT^A08), by content (only patients in department X), or by any custom criteria.
- Source Transformer — Maps and transforms the message from the source format to an intermediate format. This is where most of the integration logic lives — field mapping, value translation, data enrichment.
- Destinations — A channel can have multiple destinations. Each destination has its own filter and transformer, allowing a single inbound message to be routed to different systems in different formats simultaneously.
- Response Transformer — Handles the acknowledgment (ACK/NAK) sent back to the source system.
- Error Queue — Messages that fail processing are sent to the error queue for manual review and replay.
Key insight: The multi-destination architecture is what makes Mirth powerful. A single ADT message from the registration system can be simultaneously routed to the EHR, lab, pharmacy, and billing — each receiving the data in its own required format.
Writing Transformers That Hold Up in Production
Most of the integration logic in any Mirth deployment lives in JavaScript transformers, and most production incidents trace back to transformer code that assumed every message looks like the test message. Three rules keep transformers stable: access fields defensively, externalize value mappings, and push searchable identifiers into the channel map.
// Defensive field access: msg['PID']['PID.5'] may not exist on every message type
var lastName = '';
var firstName = '';
if (msg['PID'] && msg['PID']['PID.5']) {
lastName = msg['PID']['PID.5']['PID.5.1'].toString();
firstName = msg['PID']['PID.5']['PID.5.2'].toString();
}
// Value translation with an explicit map - never inline magic strings
var genderMap = { 'M': 'male', 'F': 'female', 'O': 'other', 'U': 'unknown' };
var rawGender = msg['PID']['PID.8'].toString();
tmp['patient']['gender'] = genderMap[rawGender] || 'unknown';
// Route metadata for downstream filtering and dashboard search
channelMap.put('patientId', msg['PID']['PID.3']['PID.3.1'].toString());
channelMap.put('eventType', msg['MSH']['MSH.9']['MSH.9.2'].toString());Two habits worth adopting from day one. First, keep transformer logic in code templates (Channels → Edit Code Templates) so shared functions like genderMap or date normalization live in one place instead of being copy-pasted across 40 channels. Second, version your channel XML exports in Git — Mirth has no built-in version control, and being able to diff a channel against last week's export is the fastest way to answer “what changed?” during an incident. For teams running large estates, our guide to managing 100+ Mirth channels covers naming conventions, code template strategy, and CI/CD for channel deployments.
Common Healthcare Use Cases
Mirth Connect handles the full spectrum of healthcare integration scenarios. Here are the six most common deployments.
1. Lab Integration (ORM/ORU)
The most common Mirth deployment. Channels receive ORM^O01 orders from the EHR, transform to the lab system's format, and route ORU^R01 results back. Mirth handles the bidirectional flow, including abnormal result alerting.
2. ADT Distribution
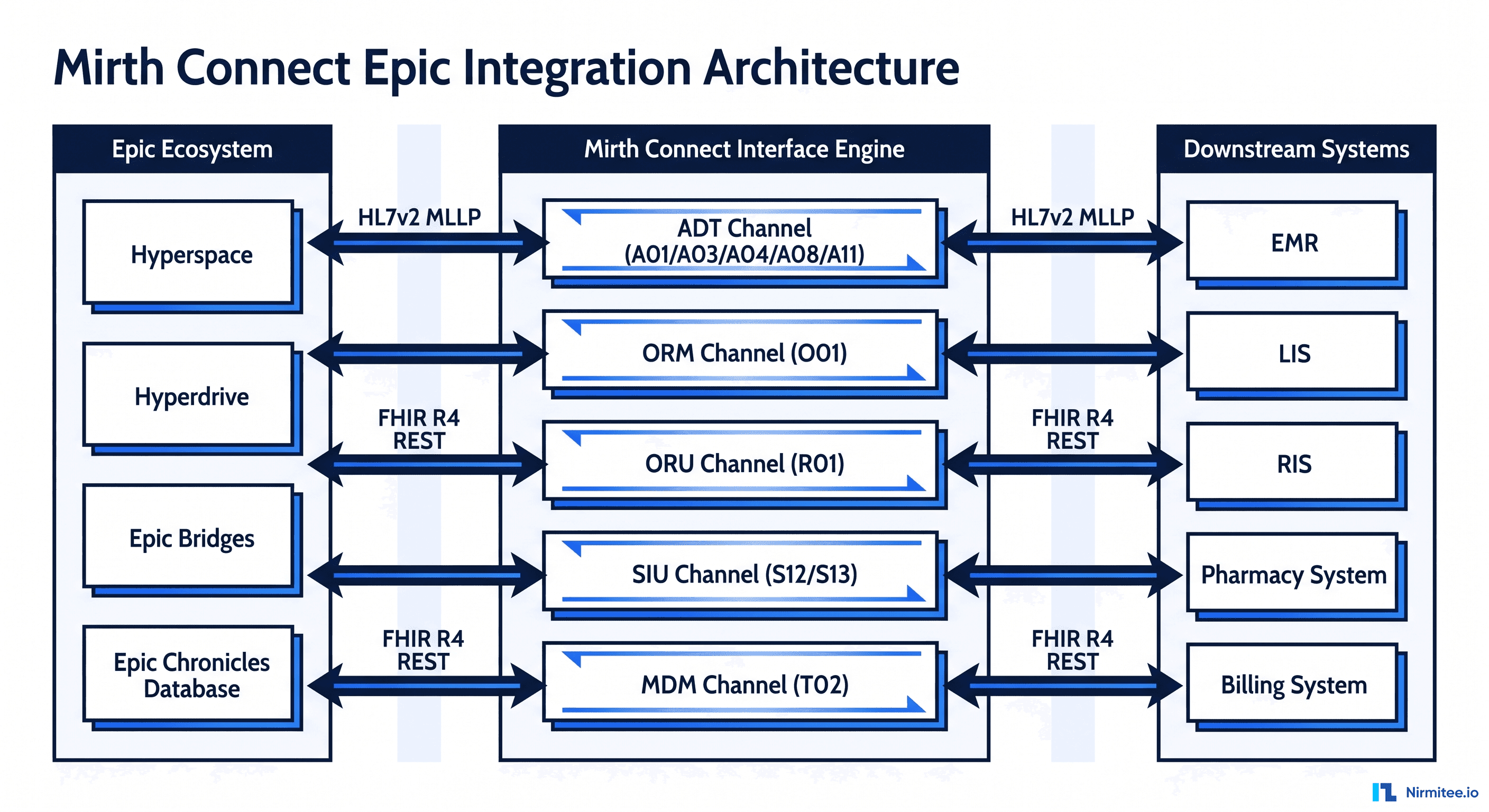
A single ADT channel receives admission, discharge, and transfer messages from the registration system and fans them out to every downstream system — lab, pharmacy, billing, nursing, dietary. This is the backbone of hospital data flow.
For a worked example of this pattern against the most widely deployed EHR, see our Mirth Connect + Epic integration production playbook.
3. Radiology Orders and Results
ORM orders flow from EHR to PACS/RIS, and diagnostic reports flow back. Mirth also handles DICOM metadata if needed.
4. Pharmacy Interface
Prescription orders (RDE messages) from the EHR to the pharmacy system, with dispensing confirmations flowing back.
5. Billing Bridge
DFT charge messages from clinical systems to the revenue cycle platform. Mirth ensures every billable event is captured and correctly coded.
6. Public Health Reporting
Immunization records, syndromic surveillance data, and reportable conditions sent to state health departments and CDC registries in the required HL7 formats.
Setting Up Your First Mirth Channel
Getting from zero to a working HL7 interface takes about 30 minutes with Mirth Connect. Here's the step-by-step.
The critical steps:
- Install Mirth Connect — Download from NextGen, requires Java 11+. Available for Windows, Linux, and macOS.
- Launch the Dashboard — Open your browser to
https://localhost:8443. Default credentials: admin/admin (change immediately).
- Create a New Channel — Give it a descriptive name like "ADT Listener - Registration to Lab".
- Configure the Source Connector — Set a TCP Listener on a port (e.g., 6661) with MLLP framing for HL7 v2 messages.
- Add a Transformer — Use the drag-and-drop mapper or write JavaScript to transform fields between source and destination formats.
- Configure the Destination — Set a TCP Sender pointing to the target system's IP and port.
- Deploy and Test — Click Deploy, send a test HL7 message, and verify it arrives at the destination.
Production Deployment Architecture
Running Mirth in development is easy. Running it in production — with the reliability, security, and auditability that healthcare demands — requires careful architecture.
Production best practices:
- High Availability — Run two Mirth instances in an active-passive configuration with a load balancer. If the primary fails, the secondary takes over within seconds.
- Database — Use PostgreSQL (recommended) or Oracle in a clustered configuration. Never use the embedded Derby database in production.
- Environments — Maintain separate Development, Staging, and Production instances. Promote channel configurations through a formal release process.
- Monitoring — Integrate with Grafana/Prometheus for real-time dashboards and PagerDuty for alerting on message failures, queue buildup, or system health issues.
- Security — TLS for all MLLP connections, encrypted database connections, and audit logging for HIPAA compliance.
Running Mirth in Docker
Containerized Mirth is now the default for new deployments — it makes environment parity (dev/staging/prod) trivial and removes the “works on the interface server” class of problems. A minimal production-shaped compose file:
services:
mirth:
image: nextgenhealthcare/connect:4.5
environment:
- DATABASE=postgres
- DATABASE_URL=jdbc:postgresql://db:5432/mirthdb
- DATABASE_USERNAME=mirth
- DATABASE_PASSWORD=${DB_PASSWORD}
- VMOPTIONS=-Xmx4g
ports:
- "8443:8443" # Administrator / API
- "6661:6661" # HL7 MLLP listener
depends_on:
- db
db:
image: postgres:16
environment:
- POSTGRES_DB=mirthdb
- POSTGRES_USER=mirth
- POSTGRES_PASSWORD=${DB_PASSWORD}
volumes:
- mirth_pgdata:/var/lib/postgresql/data
volumes:
mirth_pgdata:Key detail: externalize the database. The container is disposable; your message store and channel configs are not. Map every listener port explicitly — each MLLP channel needs its own port published. For the full walkthrough including volume strategy and upgrade paths, see our Mirth Connect Docker setup guide and the AWS/Azure cloud deployment guide.
The Go-Live Checklist
Before any channel touches production traffic, verify:
- Default credentials changed and admin access restricted to the ops network — the number of Mirth dashboards reachable from the open internet is genuinely alarming.
- TLS on every MLLP and HTTP listener. Plain-text HL7 over hospital networks fails most HIPAA risk assessments.
- Message pruning configured per channel — not globally — with retention matched to your audit policy (typically 7–30 days of content, longer for metadata).
- Failover tested, not just configured. Kill the primary deliberately and watch the secondary take over. See our high-availability setup guide for the active-passive pattern that survives this test.
- Alerting wired to a human. A queue that has been growing for six hours is an outage nobody noticed. Alert on queue depth and error-rate deltas, not just process health.
- A replay plan. When a destination is down for a day, someone must know how to safely replay messages in order. Document it before you need it.
Mirth Connect vs Enterprise Alternatives
Mirth Connect is powerful, but it's not the only option. Here's how it compares to the enterprise alternatives for organizations evaluating their options.
When to choose Mirth Connect:
- You have technical staff who can manage and configure the engine
- Budget is constrained — Mirth's open-source model saves $50K-$200K/year in license fees (our true cost breakdown covers licensing, staffing, and the hidden expenses)
- Your integration needs are primarily HL7 v2 with some FHIR
- You want full control over your integration infrastructure
When to consider alternatives:
- You need 24/7 vendor support with guaranteed SLAs → Rhapsody or Corepoint
- You're processing 10M+ messages/day and need enterprise scaling → Rhapsody
- You're cloud-native with primarily FHIR workloads → AWS HealthLake or HAPI FHIR
- You have no integration expertise in-house → Consider a managed service
Troubleshooting Common Issues
Every Mirth administrator encounters the same issues eventually. This decision tree covers the most common failure scenarios and their fixes.
The top issues and quick fixes:
- Messages not arriving: Check firewall rules and verify the source port is open. Use
netstat -an | grep PORTto confirm Mirth is listening. - Messages rejected: Invalid HL7 format. Use Mirth's message template viewer to validate the raw message structure.
- Transformer errors: JavaScript errors in the transformer. Check the channel's error log for stack traces. Most common: null pointer when accessing a field that doesn't exist in all message types.
- Destination queue growing: Target system is down or slow. Check destination connectivity. If the target is temporarily unavailable, Mirth's built-in retry queue handles automatic redelivery.
- Performance degradation: The message database is growing too large. Enable message pruning and archiving.
- HTTP calls failing after a Java upgrade: Mirth on Java 17 has known issues with outbound HTTP calls from transformers — the fix is documented in our Mirth Connect HTTP API calls on Java 17 guide.
Performance Optimization
A well-tuned Mirth instance can handle thousands of messages per minute. A poorly tuned one struggles with hundreds. These eight optimizations make the difference.
The highest-impact optimizations:
- Enable message pruning — Set channels to prune message content after 7-30 days. Without pruning, the database grows unbounded and queries slow to a crawl.
- Use connection pooling — For database destinations, configure connection pools instead of creating new connections per message.
- Archive to files, not database — Store raw message content in compressed files rather than database BLOBs. This is the single biggest performance improvement for high-volume channels.
- Index custom metadata — If you use custom metadata columns for searching messages, add database indexes. Without indexes, the dashboard search becomes unusable at scale.
- Tune Java heap — Set Mirth's JVM heap to 2- 4 GB for production workloads. The default is too low for sustained high-volume processing.
JVM Heap and Garbage Collection
Mirth ships with a 256 MB default heap — fine for a demo, fatal for production. Set initial and max heap to the same value to avoid resize pauses, and use G1GC for predictable pause times on heaps above 2 GB:
# mcserver.vmoptions (Linux) / mcservice.vmoptions (Windows service)
-Xms4g
-Xmx4g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:+HeapDumpOnOutOfMemoryError
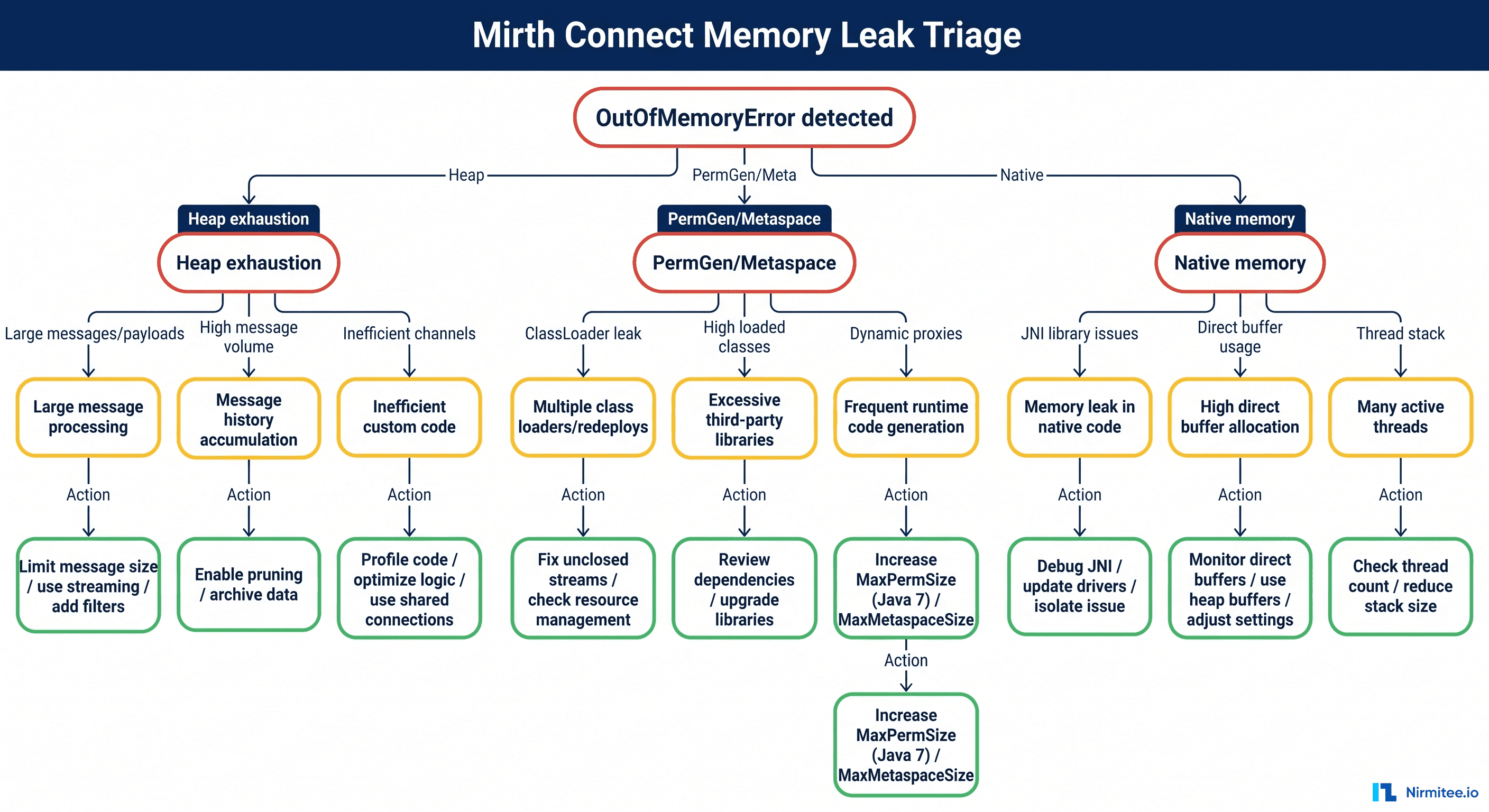
-XX:HeapDumpPath=/opt/mirthconnect/logsSizing rule of thumb: 2–4 GB covers most hospital workloads up to a few hundred thousand messages per day; go to 6–8 GB only if you process large batch files or attachments. Bigger is not automatically better — oversized heaps lengthen GC cycles. If you're seeing java.lang.OutOfMemoryError: Java heap space, the cause is usually a channel holding large payloads in memory, not an undersized heap — our memory leak triage guide walks through finding the offending channel from a heap dump.
Channel Threading and Queue Settings
The settings that actually move throughput numbers:
- Source queue ON for high-volume listeners. With the queue off, the sender waits for the full pipeline before getting its ACK — upstream systems time out under load. With it on, Mirth ACKs on receipt and processes asynchronously.
- Destination queue threads. Default is 1 thread per destination — serial delivery. Raise to 4–8 threads for slow HTTP/database destinations, but only where the target system tolerates out-of-order delivery. ADT feeds usually must stay serial; lab result fan-out usually doesn't.
- Max processing threads (channel source setting). Raising this from 1 lets a channel process multiple messages concurrently — again, only safe when message order doesn't matter.
- Attachment handling. Strip large embedded payloads (PDFs, images in OBX segments) into the attachment store instead of carrying them through every transformer step.
Database Tuning for the Message Store
At sustained volume the bottleneck is almost always the message store, not Mirth itself. PostgreSQL defaults assume a tiny machine; on a dedicated 16 GB database host start here:
# postgresql.conf starting points for a dedicated Mirth DB (16 GB host)
shared_buffers = 4GB
effective_cache_size = 12GB
work_mem = 32MB
maintenance_work_mem = 512MB
checkpoint_completion_target = 0.9
random_page_cost = 1.1 # SSD storage
max_connections = 150 # Mirth pools + dashboard + monitoringCombine this with aggressive per-channel pruning and the file-based attachment strategy above, and a single well-tuned Mirth instance comfortably sustains thousands of messages per minute. For the complete methodology — baseline, measure, tune, re-measure — see Mirth Connect performance tuning: scaling to 10,000 messages/hour.
Observability: Knowing It's Slow Before Users Do
Tuning without measurement is guessing. At minimum, export queue depth, messages/minute per channel, error counts, and JVM heap usage to Prometheus and graph them in Grafana. Mirth's REST API exposes channel statistics that make this a small scripting exercise (review the seven undocumented REST API gotchas before automating against it); for a richer approach with distributed tracing across channels, see instrumenting Mirth with OpenTelemetry. In one engagement, this kind of disciplined deployment let our team connect 15 hospital systems through Mirth with zero lost messages — the full architecture is in this case study.
Where Mirth Fits in a Modern Healthcare Stack
A fair question in 2026: with FHIR APIs, event streaming, and AI agents reshaping healthcare architecture, is an HL7 v2 interface engine still relevant? The answer from production environments is an unambiguous yes — but its role has shifted from “the integration platform” to “the v2 edge of the integration platform.”
Three patterns dominate modern Mirth deployments:
- The v2-to-FHIR bridge. Hospital systems still emit HL7 v2; modern applications consume FHIR. Mirth sits between them, parsing ADT/ORM/ORU streams and producing FHIR R4 resources. Our guide to turning HL7 v2 streams into FHIR APIs with Mirth covers this pattern end to end, and the production pipeline with mapping tables and business rules shows what it looks like at scale. If your clinical data layer is openEHR rather than FHIR, the same bridge pattern applies — see Mirth Connect + openEHR: HL7v2 to FLAT composition.
- The event source for streaming platforms. Mirth receives clinical events and publishes them to Kafka, where downstream analytics, alerting, and ML pipelines consume them. The engine handles healthcare protocol mess; Kafka handles distribution. The same orchestration strength applies to analytics workloads — FHIR bulk data export with Mirth uses the engine to drive population health pipelines end to end. See healthcare integration architecture with Mirth and Kafka for the reference design.
- The data layer under AI agents. AI agents that act on clinical events need a reliable, ordered, validated event stream — exactly what a well-run Mirth estate produces. Teams building agentic workflows on hospital data almost always discover that the integration layer, not the model, determines whether the system is trustworthy.
The takeaway: Mirth isn't competing with FHIR or AI tooling — it's the workhorse that feeds them. Organizations that treat their interface engine as legacy plumbing consistently struggle to ship modern capabilities on top of unreliable data flow.
Conclusion
Mirth Connect is the best starting point for healthcare integration — it's free, well-documented, and has the largest community of any healthcare integration engine. Whether you're connecting two systems or twenty, it can handle the job.
For foundational context on the standards Mirth supports, read What is HL7? and What is FHIR?.
Need help setting up Mirth Connect or migrating from another engine? Our healthcare integration team has deployed Mirth at scale for hospitals and health systems across the US.