Reading time: 14 min | Last updated: March 2026
A clinician asks your AI assistant about a drug dosage. The model confidently returns a number that is three times the safe maximum. Without guardrails, that response reaches the clinician in under a second. With the wrong guardrails, it takes four seconds—an eternity in a clinical workflow that no one will tolerate.
This guide covers the complete architecture for building real-time AI guardrails that keep healthcare AI safe without destroying the user experience. We cover framework selection, healthcare-specific validation rules with code, production deployment patterns, and monitoring strategies that satisfy both clinicians and compliance officers.
The 200-Millisecond Challenge: Why Healthcare AI Needs Real-Time Guardrails
Healthcare AI occupies a uniquely difficult design space. Clinicians operate under severe time pressure—an emergency physician makes roughly 10,000 decisions per shift. Any AI tool that adds latency will be bypassed or abandoned. Studies on clinical decision support systems consistently show that response times above 500 milliseconds lead to sharp drops in adoption, and anything above two seconds is effectively ignored.
At the same time, the stakes for incorrect outputs are existentially high. A 2025 survey by the American Medical Informatics Association found that 64% of healthcare organizations delayed AI deployment specifically because of hallucination and safety concerns. A separate analysis by KLAS Research in late 2025 showed that only 23% of health systems that piloted clinical AI assistants moved them into production—with "uncontrolled output quality" cited as the top blocker.
The core tension: you cannot run a three-second LLM-as-judge evaluation on every output in a real-time clinical workflow. GPT-4-class models used as evaluators add 1.5 to 4 seconds of latency per evaluation call, plus the cost scales linearly with volume. For a system handling 10,000 clinical queries per hour across a health system, that means $2,000+ per day in evaluation costs alone.
The solution is a tiered guardrails architecture that combines fast rule-based checks (under 50ms) with smart routing that sends only ambiguous or high-risk outputs through deeper evaluation. The goal: a total pipeline under 200 milliseconds for 85%+ of requests, with a 1–3 second deep evaluation path for the remainder.
This is not theoretical. Organizations like Kaiser Permanente and Mayo Clinic have published on tiered safety architectures for their clinical AI systems, and the pattern is converging across the industry. Here is how to build it.
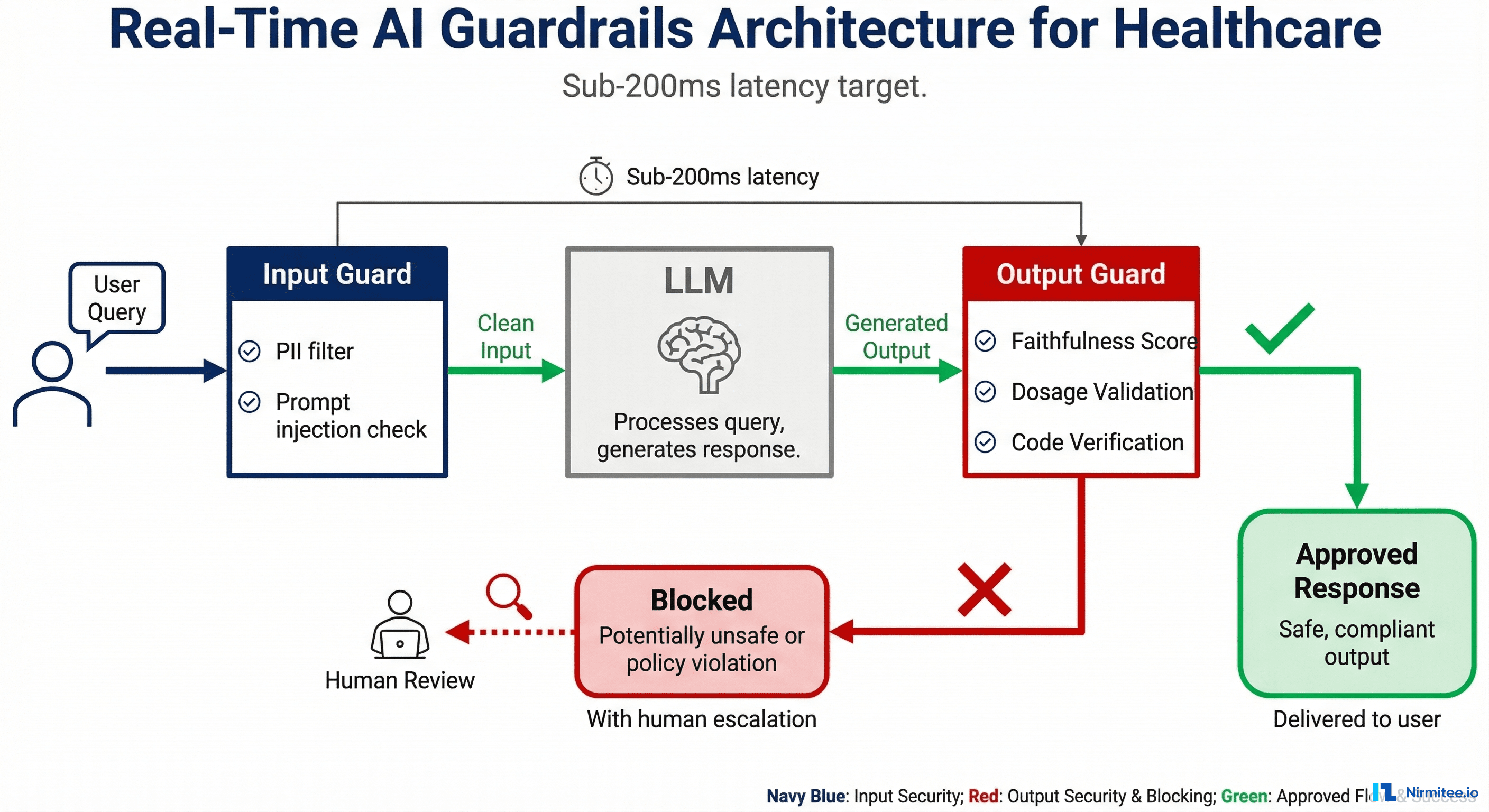
Guardrails Architecture: Input Guards, LLM, Output Guards

The architecture has three stages, each with a strict latency budget. Think of it as a pipeline where every request flows through input guards, then the LLM, then output guards before reaching the clinician.
Stage 1: Input Guards (Target: Under 50ms)
Input guards run before the prompt reaches the LLM. Their job is to block dangerous inputs, redact sensitive data, and ensure the request is within scope.
- PII/PHI Detection and Redaction: A hybrid approach combining regex patterns (SSN, MRN, phone numbers) with a lightweight Named Entity Recognition model (such as a fine-tuned distilBERT). The regex layer runs in under 5ms; the NER model adds 15–30ms. A 2025 paper from Stanford's Clinical NLP group showed this hybrid approach achieves F1 = 98.4% on PHI detection, compared to 94.1% for regex-only and 96.8% for NER-only.
- Prompt Injection Detection: A classifier trained on known injection patterns (jailbreaks, role-play attacks, instruction override attempts). Open-source options include Rebuff and the Lakera Guard API. Critical for healthcare because a successful injection could cause the model to ignore safety constraints.
- Input Sanitization: Strip control characters, enforce maximum token length, normalize encoding. Simple but prevents a class of edge-case failures.
- Topic Guardrails: A fast classifier (or keyword + embedding approach) that ensures the query is within the AI system's defined scope. A dermatology AI should not answer cardiology questions. This prevents the model from operating outside its validated domain—a key FDA expectation for SaMD (Software as a Medical Device).
Stage 2: LLM Processing
The actual AI model performs inference. The guardrails architecture is model-agnostic—it works with GPT-4, Claude, Llama, Mistral, or any model behind an API. The key design principle: guardrails are external to the model. System prompts and fine-tuning are useful but insufficient; they are probabilistic, not deterministic. External guardrails provide the deterministic safety layer.
Stage 3: Output Guards (Target: Under 150ms)
Output guards validate the LLM's response before it reaches the user. This is where healthcare-specific logic lives.
- Faithfulness Scoring (Fast Model): A lightweight model (such as Galileo's Luna-2 or a fine-tuned DeBERTa) scores whether the output is grounded in the provided context. This catches hallucinations. Luna-2 achieves this in under 100ms at 97% lower cost than using GPT-4 as a judge.
- Medication Validation: Cross-reference any drug names mentioned in the output against the FDA National Drug Code (NDC) directory. Flag unknown drugs immediately.
- Dosage Range Checking: Compare any dosage values against known therapeutic ranges from clinical pharmacology databases. Flag values outside safe ranges.
- ICD-10 / CPT Code Validation: If the output contains diagnostic or procedure codes, validate format and existence against the current code sets.
- Toxicity and Bias Filter: A lightweight classifier that catches harmful, biased, or inappropriate content. Important for patient-facing applications.
- Confidence Scoring: Aggregate the scores from all checks into an overall confidence score. This determines routing.
Two Paths from Output Guards
Path A — Approved (confidence above threshold): Deliver the response to the clinician. Total pipeline time: under 200ms beyond the LLM inference itself.
Path B — Blocked or Uncertain (confidence below threshold): Route to a human reviewer queue with a structured explanation of which guardrails triggered. The clinician sees a message like "This response is being reviewed for accuracy" rather than a potentially unsafe output. For non-urgent workflows, this adds 0–30 minutes. For urgent workflows, the system falls back to a conservative, pre-approved response template.
Framework Comparison: NeMo Guardrails vs Guardrails AI vs Galileo vs Custom

Four viable approaches exist today. The right choice depends on your organization's size, technical maturity, and specific use case.
NVIDIA NeMo Guardrails
NeMo Guardrails is open-source and uses Colang, a domain-specific configuration language for defining "rails"—programmable rules that control LLM behavior. You can define topical rails (keep the AI on-topic), safety rails (block harmful outputs), and security rails (prevent prompt injection).
Strengths: Highly programmable, active open-source community, good documentation, NVIDIA backing ensures longevity. The Colang 2.0 release in 2025 significantly improved expressiveness and reduced configuration complexity.
Limitations for healthcare: No built-in healthcare-specific rails. You must build medication validation, dosage checking, and clinical code validation yourself. Latency can reach 200–500ms for complex rail configurations because Colang evaluation involves LLM calls for some rail types.
Best for: Teams with strong engineering capacity that want full control and are comfortable building healthcare-specific extensions on top of a solid foundation.
Guardrails AI
Guardrails AI takes a schema validation approach. You define the expected output structure and attach "validators" that check individual fields for quality, accuracy, and safety. The open-source library includes validators for topics like PII detection, toxicity, and factual consistency.
Strengths: Excellent for structured output validation (JSON schemas, forms, clinical templates). The validator ecosystem is growing, with community-contributed healthcare validators appearing in late 2025. Easy to integrate into existing Python applications.
Limitations for healthcare: Less mature than NeMo for conversational guardrails. The validator approach works best for structured outputs; free-text clinical narratives require more custom work. Performance varies by validator complexity.
Best for: Applications that produce structured clinical outputs (lab reports, coding suggestions, form completions) where schema validation is a natural fit.
Galileo
Galileo is an enterprise platform that provides production-grade LLM evaluation and guardrails. Their Luna-2 family of specialized evaluation models delivers sub-200ms evaluations at 97% lower cost than GPT-4-as-judge. As of January 2026, they report 100+ enterprise deployments and introduced Agentic Evaluations for multi-step AI agent workflows.
Strengths: Purpose-built for production. Luna-2 models are trained specifically for evaluation tasks (hallucination detection, instruction adherence, context relevance), so they outperform general-purpose models used as judges. The platform includes pre-built dashboards, alerting, and drift detection. Their healthcare customers include multiple health systems and health-tech companies.
Limitations for healthcare: Enterprise pricing (not publicly disclosed). Requires sending data to Galileo's infrastructure unless you negotiate on-premise deployment. Less flexibility than open-source options for exotic guardrail logic.
Best for: Mid-to-large healthcare organizations that want production-grade guardrails without building evaluation infrastructure from scratch. The fastest path to reliable, low-latency output evaluation.
Custom Pipeline (RAGAS + Rule Engine + Routing)
Build your own using open-source evaluation frameworks (RAGAS, DeepEval) for faithfulness and relevancy scoring, a custom rule engine for healthcare-specific checks, and routing logic to direct outputs to the appropriate path.
Strengths: Maximum flexibility. Full control over every component. No vendor lock-in. You can optimize each piece independently. Integrates with your existing infrastructure exactly as needed.
Limitations for healthcare: Highest development and maintenance cost. You own the entire evaluation pipeline, including keeping medical databases current. Requires deep expertise in both ML evaluation and clinical informatics.
Best for: Organizations with strong ML engineering teams building differentiated AI products where guardrails are a core competency, not a bolt-on.
Recommendation Matrix
| Scenario | Recommended Approach | Rationale |
|---|---|---|
| Startup, MVP stage, <10 engineers | Guardrails AI + custom healthcare validators | Fastest time to value, low cost, sufficient for structured outputs |
| Mid-size health-tech, production AI products | Galileo + custom rule engine for clinical checks | Production-grade evaluation without building infrastructure; add clinical rules on top |
| Large health system, multiple AI applications | NeMo Guardrails as foundation + Galileo for evaluation | NeMo provides the programmable framework; Galileo provides fast, accurate evaluation models |
| AI-first company, guardrails as differentiator | Custom pipeline | Full control is worth the investment when guardrails are your product |
For a deeper dive on evaluation metrics and scoring approaches, see our guide on how to test LLM outputs at scale for healthcare.
Healthcare-Specific Guardrail Rules You Must Implement

Regardless of which framework you choose, these seven guardrail rules are non-negotiable for clinical AI. Each includes Python pseudocode you can adapt to your stack.
1. Medication Validation Against FDA NDC
Every drug name in an AI output must be verified against the FDA National Drug Code directory. Unknown drug names are a strong hallucination signal.
import re
from typing import Tuple
# Pre-loaded: FDA NDC drug name set (updated monthly)
# Source: https://open.fda.gov/apis/drug/ndc/
FDA_NDC_DRUGS: set = load_fda_ndc_drug_names()
def validate_medications(output_text: str) -> Tuple[bool, list]:
"""Check all medication names against FDA NDC directory."""
# Extract drug names using medical NER or pattern matching
mentioned_drugs = extract_drug_names(output_text) # MedSpaCy or scispaCy
unknown_drugs = []
for drug in mentioned_drugs:
normalized = drug.lower().strip()
if normalized not in FDA_NDC_DRUGS:
# Fuzzy match to catch misspellings
closest_match = find_closest_ndc_match(normalized, threshold=0.85)
if closest_match is None:
unknown_drugs.append(drug)
is_valid = len(unknown_drugs) == 0
return is_valid, unknown_drugsImplementation note: The FDA NDC database contains ~300,000 entries. Load it into memory as a hash set for O(1) lookups. Update monthly via the openFDA API. The fuzzy matching step (Levenshtein distance or Jaccard similarity) catches model misspellings like "metformine" while still flagging fabricated drug names.
2. Dosage Range Checking
Flag any dosage value that falls outside established therapeutic ranges. This is the single highest-impact guardrail for patient safety.
THERAPEUTIC_RANGES = {
"metformin": {"min_mg_day": 500, "max_mg_day": 2550, "unit": "mg"},
"lisinopril": {"min_mg_day": 2.5, "max_mg_day": 80, "unit": "mg"},
"warfarin": {"min_mg_day": 1, "max_mg_day": 10, "unit": "mg"},
"insulin_glargine": {"min_units_day": 1, "max_units_day": 80, "unit": "units"},
# ... extend from clinical pharmacology database
}
def check_dosage_ranges(output_text: str) -> Tuple[bool, list]:
"""Flag dosages outside therapeutic ranges."""
dosage_mentions = extract_dosages(output_text) # Returns: [(drug, value, unit)]
violations = []
for drug, value, unit in dosage_mentions:
drug_key = normalize_drug_name(drug)
if drug_key in THERAPEUTIC_RANGES:
range_info = THERAPEUTIC_RANGES[drug_key]
if value > range_info["max_mg_day"]:
violations.append({
"drug": drug,
"mentioned_dose": f"{value} {unit}",
"max_safe_dose": f"{range_info['max_mg_day']} {range_info['unit']}/day",
"severity": "CRITICAL"
})
elif value < range_info["min_mg_day"]:
violations.append({
"drug": drug,
"mentioned_dose": f"{value} {unit}",
"min_effective_dose": f"{range_info['min_mg_day']} {range_info['unit']}/day",
"severity": "WARNING"
})
return len(violations) == 0, violationsCritical detail: The therapeutic range database must account for pediatric vs adult dosing, renal impairment adjustments, and indication-specific ranges (metformin for PCOS has a different range than for Type 2 diabetes). Start with adult ranges and expand. Sources include DailyMed, Lexicomp, and First Databank.
3. Drug Interaction Detection
Cross-reference any combination of medications mentioned in the output against known interaction databases.
# Pre-loaded: Interaction pairs from DrugBank or RxNorm
KNOWN_INTERACTIONS: dict = load_drug_interactions() # {(drug_a, drug_b): severity}
def check_drug_interactions(output_text: str, patient_medications: list = None) -> Tuple[bool, list]:
"""Detect potential drug interactions in AI output."""
mentioned_drugs = extract_drug_names(output_text)
# Combine with patient's current medication list if available
all_drugs = set(mentioned_drugs)
if patient_medications:
all_drugs.update(patient_medications)
interactions_found = []
drug_list = list(all_drugs)
for i in range(len(drug_list)):
for j in range(i + 1, len(drug_list)):
pair = tuple(sorted([normalize_drug_name(drug_list[i]),
normalize_drug_name(drug_list[j])]))
if pair in KNOWN_INTERACTIONS:
interactions_found.append({
"drug_a": drug_list[i],
"drug_b": drug_list[j],
"severity": KNOWN_INTERACTIONS[pair],
"action": "BLOCK" if KNOWN_INTERACTIONS[pair] == "major" else "WARN"
})
has_critical = any(i["severity"] == "major" for i in interactions_found)
return not has_critical, interactions_found4. PII/PHI Detection (Hybrid Approach)
The hybrid regex + NER approach that achieves F1 = 98.4% on PHI detection, as documented in Stanford's 2025 Clinical NLP benchmark.
import re
from transformers import pipeline
# Lightweight NER model fine-tuned on i2b2 PHI dataset
phi_ner = pipeline("ner", model="obi/deid_bert_i2b2", device=0)
PHI_PATTERNS = {
"SSN": r"\b\d{3}-\d{2}-\d{4}\b",
"MRN": r"\b(?:MRN|mrn)[:\s]*\d{6,10}\b",
"PHONE": r"\b(?:\+1[-.\s]?)?\(?\d{3}\)?[-.\s]?\d{3}[-.\s]?\d{4}\b",
"EMAIL": r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b",
"DOB": r"\b(?:DOB|dob|Date of Birth)[:\s]*\d{1,2}[/\-]\d{1,2}[/\-]\d{2,4}\b",
}
def detect_phi(text: str) -> Tuple[bool, list]:
"""Hybrid PHI detection: regex patterns + NER model."""
findings = []
# Layer 1: Fast regex (< 5ms)
for phi_type, pattern in PHI_PATTERNS.items():
matches = re.findall(pattern, text)
for match in matches:
findings.append({"type": phi_type, "value": match, "method": "regex"})
# Layer 2: NER model (15-30ms) - catches names, addresses, dates
ner_results = phi_ner(text)
for entity in ner_results:
if entity["score"] > 0.85:
findings.append({
"type": entity["entity_group"],
"value": entity["word"],
"method": "ner",
"confidence": entity["score"]
})
return len(findings) == 0, findingsHIPAA note: PHI detection in outputs is critical even when inputs are de-identified. LLMs can "re-identify" patients by combining context clues, or hallucinate PHI-like strings that coincidentally match real individuals. The guardrail must run on both inputs and outputs.
5. Clinical Code Validation (ICD-10 and CPT)
# Pre-loaded: valid ICD-10-CM and CPT code sets
VALID_ICD10: set = load_icd10_codes() # ~94,000 codes
VALID_CPT: set = load_cpt_codes() # ~10,000 codes
ICD10_PATTERN = r"\b[A-TV-Z]\d{2}(?:\.\d{1,4})?\b"
CPT_PATTERN = r"\b\d{5}\b"
def validate_clinical_codes(output_text: str) -> Tuple[bool, list]:
"""Validate ICD-10 and CPT codes mentioned in output."""
invalid_codes = []
# ICD-10 validation
icd_matches = re.findall(ICD10_PATTERN, output_text)
for code in icd_matches:
if code not in VALID_ICD10:
invalid_codes.append({"code": code, "type": "ICD-10", "status": "INVALID"})
# CPT validation (context-aware to avoid false positives on random 5-digit numbers)
cpt_context_pattern = r"(?:CPT|procedure code|billing code)[:\s]*(\d{5})"
cpt_matches = re.findall(cpt_context_pattern, output_text, re.IGNORECASE)
for code in cpt_matches:
if code not in VALID_CPT:
invalid_codes.append({"code": code, "type": "CPT", "status": "INVALID"})
return len(invalid_codes) == 0, invalid_codes6. Demographic Bias Detection
def check_demographic_bias(query: str, output: str) -> Tuple[bool, dict]:
"""Ensure AI responses don't vary inappropriately based on demographics."""
# Generate counterfactual queries with swapped demographics
demographic_axes = ["race", "gender", "age_group", "insurance_type"]
variations = generate_counterfactual_queries(query, demographic_axes)
responses = [get_llm_response(v) for v in variations]
# Compare clinical recommendations across variations
# Flag if treatment recommendations differ based solely on demographics
clinical_actions = [extract_clinical_actions(r) for r in responses]
variance_score = calculate_action_variance(clinical_actions)
is_fair = variance_score < BIAS_THRESHOLD # Typically 0.15
return is_fair, {"variance_score": variance_score, "axis_scores": per_axis_scores}Note: Bias detection is computationally expensive and typically runs asynchronously (batch evaluation) rather than in the real-time pipeline. Run it on a sample of outputs daily and alert if bias scores trend upward.
7. Confidence Thresholds and Human Routing
def route_output(guardrail_results: dict) -> str:
"""Determine output routing based on aggregate guardrail scores."""
# Any critical failure = immediate block
if guardrail_results.get("dosage_violation_critical"):
return "BLOCK_IMMEDIATE"
if guardrail_results.get("unknown_medication"):
return "BLOCK_REVIEW"
# Aggregate confidence from all checks
scores = [
guardrail_results.get("faithfulness_score", 0.5),
guardrail_results.get("phi_clean", 1.0),
guardrail_results.get("codes_valid", 1.0),
]
aggregate_confidence = sum(scores) / len(scores)
if aggregate_confidence >= 0.90:
return "APPROVE"
elif aggregate_confidence >= 0.70:
return "APPROVE_WITH_DISCLAIMER"
else:
return "ROUTE_TO_HUMAN"For more on building the AI agents that these guardrails protect, see our architecture guide on building HIPAA-compliant AI agents.
Production Deployment Patterns
How you deploy guardrails matters as much as what guardrails you implement. Three patterns dominate production healthcare AI deployments, each with distinct trade-offs.
Pattern 1: Sidecar Architecture
Guardrails run as a separate container alongside the LLM service in the same pod (Kubernetes) or task definition (ECS). The application sends requests to the LLM container; the sidecar intercepts and validates both inputs and outputs via a local network call.
Pros: Clean separation of concerns. Guardrails can be updated independently of the LLM service. Scales horizontally with the LLM pods. Minimal latency overhead (local network, typically under 2ms for the inter-container call).
Cons: More complex deployment configuration. Requires orchestration (Kubernetes, ECS). Each LLM instance gets its own guardrail instance, which can increase resource usage.
HIPAA consideration: Data never leaves the pod boundary, which simplifies BAA scoping. Both containers share the same network namespace, so PHI is not transmitted over external networks during validation.
Best for: Kubernetes-native healthcare platforms running multiple AI services. This is the most common pattern among health systems we work with.
Pattern 2: API Gateway Integration
Guardrails run as middleware in your API gateway (Kong, AWS API Gateway + Lambda, or a custom gateway). Every request to any LLM service passes through the guardrails middleware layer.
Pros: Single guardrails deployment covers all LLM services. Centralized policy enforcement. Easy to add rate limiting, audit logging, and access control at the same layer. Ideal for organizations running multiple AI models (e.g., one for clinical documentation, another for coding, another for patient communication).
Cons: The gateway becomes a bottleneck and single point of failure. Adds network hop latency (10–30ms per hop). More complex to implement model-specific guardrails since all traffic flows through one layer.
HIPAA consideration: The gateway processes all PHI, so it must be included in BAA scope and audit logging. Ensure TLS 1.2+ between all components. The centralized logging is actually an advantage for compliance—one place to audit all AI interactions.
Best for: Multi-model environments where consistent policy enforcement across all AI services is the priority.
Pattern 3: Embedded Library
Guardrails run as a Python library called directly within the application code. No separate service, no network calls for validation.
Pros: Simplest deployment. Zero network overhead for guardrail checks. Easiest to debug (everything is in one process). Lowest operational complexity.
Cons: Guardrails are coupled to the application. Updates require redeploying the application. Resource contention—guardrail computations (especially NER models) compete with the application for CPU/memory. Harder to enforce consistent guardrails across multiple applications.
HIPAA consideration: Simplest compliance story—PHI never leaves the application boundary. But ensure the guardrail library's dependencies are included in your vulnerability scanning and software bill of materials (SBOM).
Best for: Single-application deployments, monolithic architectures, or MVP/pilot stage where operational simplicity matters more than scalability.
Whichever pattern you choose, the guardrails must integrate with your broader agentic AI workflow architecture. Multi-step agent workflows need guardrails at each step, not just at the final output.
Monitoring and Alerting for Guardrails
Deploying guardrails without monitoring is like installing a smoke detector without connecting it to an alarm. The guardrails will catch problems, but no one will know about systemic patterns until it is too late.
Key Metrics to Track
| Metric | What It Tells You | Target Range |
|---|---|---|
| Block rate (% of outputs blocked) | Overall model quality; sudden increases signal model degradation or prompt drift | 2–8% (below 2% suggests guardrails are too loose; above 8% suggests model issues) |
| False positive rate (valid outputs incorrectly blocked) | Guardrail precision; high FPR means clinicians lose trust and seek workarounds | Under 1% for medication checks; under 3% for faithfulness scoring |
| Latency P50 / P95 / P99 | User experience impact; guardrails adding too much latency | P50 under 80ms, P95 under 200ms, P99 under 500ms (excluding LLM inference) |
| Block reason distribution | Which guardrails fire most often; guides model improvement efforts | No single reason should exceed 40% of blocks unless a known issue |
| Human override rate | How often reviewers approve blocked outputs (indicates FP issues) | Under 20% of reviewed blocks |
| Guardrail evaluation agreement | Agreement between fast guardrails and deep evaluation on same outputs | Above 92% agreement |
Alert Conditions
- Block rate spike (>2x baseline over 1 hour): Likely cause is model degradation, prompt template change, or data distribution shift. Immediate action: investigate recent deployments, check model provider status page, review sample of blocked outputs.
- False positive rate rise (>5% over 24 hours): Guardrails are becoming too aggressive, possibly due to a database update (new drug names being flagged) or model output format change. Action: review recent guardrail configuration changes, sample false positives for pattern analysis.
- Latency P95 exceeds 300ms: Guardrail infrastructure is under strain. Check NER model inference times, database lookup latency, and resource utilization. Consider scaling guardrail instances.
- Human override rate exceeds 30%: Guardrails are blocking too many valid outputs. Clinicians will start ignoring or bypassing the system. Urgent recalibration needed.
Dashboard Design for Compliance Officers
Healthcare compliance officers need a different dashboard than engineers. Design theirs around these four panels:
- Safety Event Log: Every blocked output with timestamp, guardrail that triggered, severity, and resolution status. Filterable by date range, department, and AI application. This is your HIPAA audit trail.
- Trend Analysis: Week-over-week block rate, false positive rate, and latency trends. Compliance officers look for systemic patterns, not individual events.
- Risk Heatmap: Which clinical domains (medication, diagnosis, procedure) generate the most guardrail triggers. Helps prioritize model improvement investments.
- Regulatory Readiness Score: An aggregate score combining guardrail coverage (% of outputs evaluated), detection rates, and response times. Map this to ONC certification criteria and FDA SaMD expectations for executive reporting.
For systems where the AI agent reads and writes clinical data, guardrails must also validate the FHIR resources being generated. Our guide on building AI agents that read and write clinical data via FHIR covers the data validation layer in detail.
Frequently Asked Questions
How much latency do AI guardrails add to healthcare applications?
With a well-architected tiered system, rule-based guardrails (medication validation, code checking, PII detection) add 30–80ms. Fast evaluation models like Galileo's Luna-2 add 80–150ms. The total guardrail overhead for the fast path is under 200ms, which is imperceptible in most clinical workflows. Only the deep evaluation path (used for 5–15% of outputs) adds 1–3 seconds.
Do I need all seven guardrail types from day one?
No. Start with the three highest-impact guardrails: dosage range checking, medication validation, and PII/PHI detection. These catch the most dangerous failure modes. Add faithfulness scoring and clinical code validation in your second iteration. Bias detection and drug interaction checking can be implemented as batch evaluations before being promoted to real-time.
Can I use the same guardrails for patient-facing and clinician-facing AI?
The core guardrails (medication validation, dosage checking, PHI detection) apply to both. Patient-facing applications need additional guardrails: reading-level appropriate language, empathy scoring, explicit disclaimers to consult a provider, and stricter topic guardrails that prevent the AI from providing anything that could be interpreted as a diagnosis. Clinician-facing applications can be more technical but need higher faithfulness thresholds because clinicians may act on the information directly.
How do guardrails interact with FDA SaMD regulations?
The FDA's 2025 draft guidance on AI-enabled SaMD emphasizes "total product lifecycle" monitoring, which includes output quality monitoring. Guardrails serve as your real-time post-market surveillance system. Document your guardrail architecture, thresholds, and monitoring dashboards as part of your SaMD submission. The FDA has signaled that robust guardrails can support a less burdensome regulatory pathway, particularly for AI systems that include human-in-the-loop review for edge cases.
What is the cost of running guardrails at scale?
For a system processing 50,000 clinical AI queries per day: rule-based guardrails (medication, dosage, codes, PHI) cost approximately $200–400/month in compute (primarily the NER model inference). Adding a fast evaluation model like Luna-2 for faithfulness scoring adds $500–1,500/month depending on volume and SLA. Using GPT-4 as a judge for all outputs would cost $15,000–30,000/month for the same volume—which is why tiered architecture matters. The deep evaluation path should handle no more than 15% of total volume to keep costs manageable.
Build Your AI Safety Layer
Real-time guardrails are not optional for healthcare AI—they are the difference between a pilot that stays a pilot and a system that earns clinical trust at scale. The architecture patterns, framework comparisons, and implementation code in this guide give you a concrete starting point.
At Nirmitee, we build production healthcare AI systems with guardrails engineered into the architecture from day one—not bolted on after deployment. Our team has implemented tiered guardrails for clinical documentation, prior authorization, and patient communication systems across US health systems.
Talk to our healthcare AI engineering team about building a guardrails architecture tailored to your clinical workflows, compliance requirements, and performance SLAs.