
The $67 Billion Trust Problem: Why Most AI Outputs Still Cannot Be Trusted in 2026
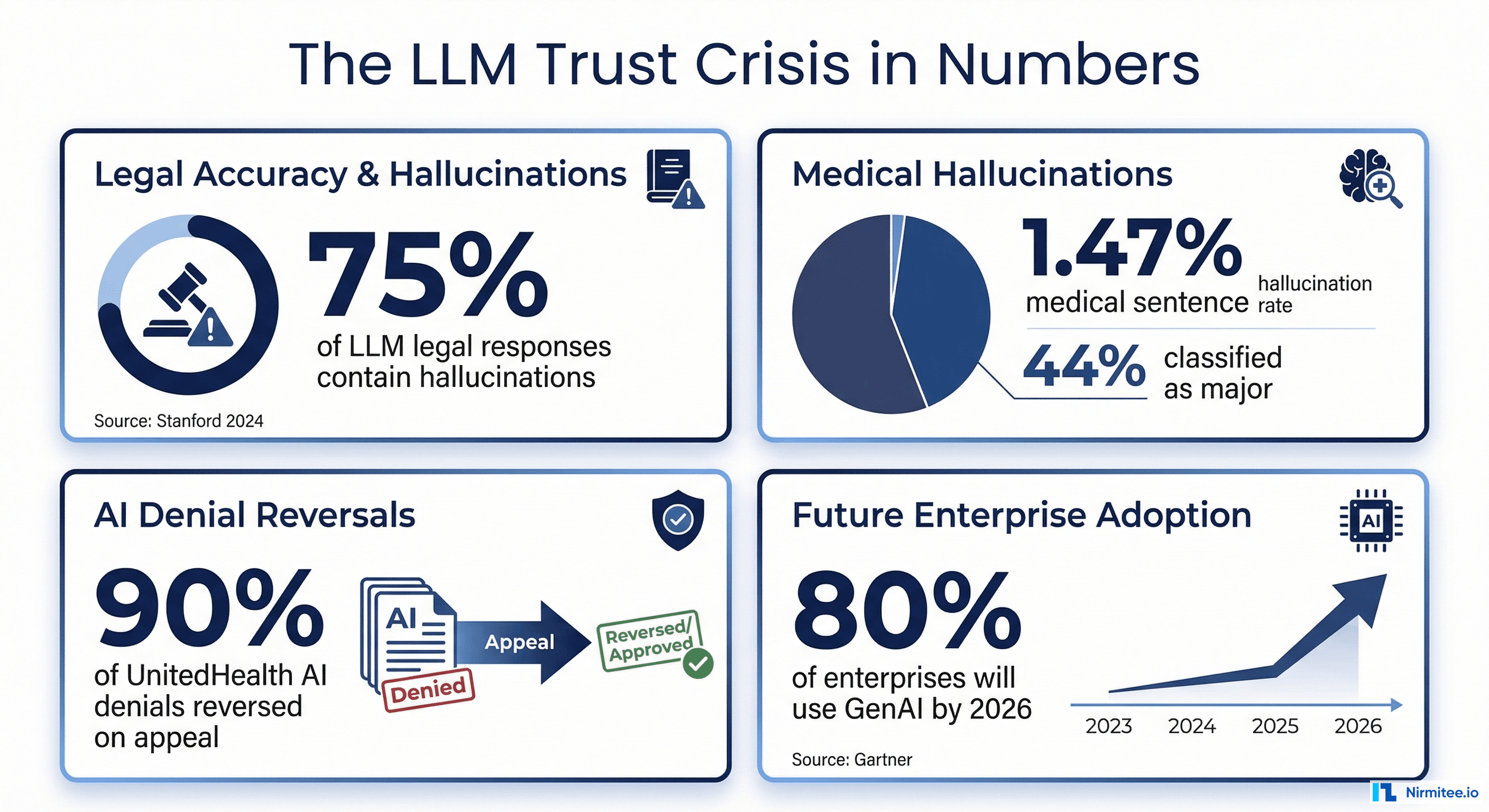
AI hallucinations cost businesses $67.4 billion in losses in 2024 alone, according to industry analysis. And despite rapid model improvements, the problem is far from solved. As of 2025 benchmarks, even the best models still hallucinate: GPT-5 at approximately 8%, Claude Sonnet 4 at 12%, and Gemini Ultra at 16%, per AllAboutAI's 2026 Hallucination Report.
In healthcare, the stakes are life-or-death. A 2025 study in npj Digital Medicine examining 12,999 medical sentences found a 1.47% hallucination rate, but 44% of those hallucinations were classified as major, meaning they could directly harm patients through incorrect dosages, fabricated contraindications, or invented treatment protocols. When researchers deliberately tested clinical decision support systems with adversarial inputs, hallucination rates jumped to 50-82% depending on the model, according to a 2025 Nature Communications Medicine study.
A global survey of 70 clinicians across 15 specialties found that 91.8% had encountered medical hallucinations and 84.7% considered them capable of causing patient harm.
The financial consequences are playing out in courtrooms right now. UnitedHealth Group is facing a class action lawsuit over its nH Predict algorithm, which plaintiffs claim has a 90% error rate on appealed denials. A federal court in February 2025 allowed breach of contract claims to proceed, ruling UnitedHealth may have violated policy language requiring coverage decisions to be made by physicians, not AI. Cigna's PXDX algorithm reportedly denied 300,000 claims in two months, with physicians spending 1.2 seconds per claim.
Meanwhile, Gartner reports worldwide AI spending will reach $2.5 trillion in 2026, with 40% of enterprise applications featuring task-specific AI agents by year-end (up from less than 5% in 2025). Healthcare AI spending alone hit $1.4 billion in 2025, nearly tripling from the prior year. The LLM observability market reached $672.8 million in 2025 and is projected to reach $8.08 billion by 2034.
The solution is not to slow down AI adoption. It is to build systematic, data-backed evaluation pipelines that catch hallucinations before they reach patients, clinicians, or claims processors. This guide shows you exactly how.

What Is LLM Evaluation? Moving from Blind Trust to Data-Backed Confidence
LLM evaluation is the systematic process of measuring whether AI outputs are accurate, relevant, grounded in source data, and safe to act on. It is the difference between hoping your AI works and proving it works with numbers.
Traditional software testing checks whether code returns the expected output for a given input. LLM evaluation is fundamentally harder because the outputs are non-deterministic: the same prompt can produce different responses each time. You need a framework that scores outputs across multiple quality dimensions simultaneously.
The Three Layers of LLM Evaluation
1. Output Quality Evaluation — Does the response answer the question correctly? Is it complete? Is it relevant? This layer uses metrics like answer relevancy, completeness, and coherence to score whether the AI response actually helps the end user.
2. Faithfulness Evaluation — Is every claim in the response grounded in the source data? This is where hallucination detection lives. The system decomposes the AI response into individual factual claims and checks each one against the provided context. If the AI says the patient's A1C was 7.2%, that number must exist in the source records.
3. Safety and Compliance Evaluation — Does the response contain harmful content, bias, or information that violates regulatory requirements? In healthcare, this includes checking for contraindication errors, off-label medication suggestions, and HIPAA-relevant information leakage.
The key insight is that all three layers must run simultaneously. An AI response can be relevant and coherent while being completely fabricated. It can be factually grounded while being clinically dangerous. Only multi-dimensional evaluation catches the failures that matter.
The Evaluation Stack: Key Metrics You Need to Track in 2026
Choosing the right metrics is the first and most important decision in your evaluation pipeline. Here is what each metric measures, when to use it, and what score thresholds to target.
RAG-Specific Metrics (For Retrieval-Augmented Generation Systems)
If your AI system retrieves documents or data before generating responses, which is the standard architecture for healthcare AI agents working with clinical data, these five metrics from the RAGAS framework are essential:
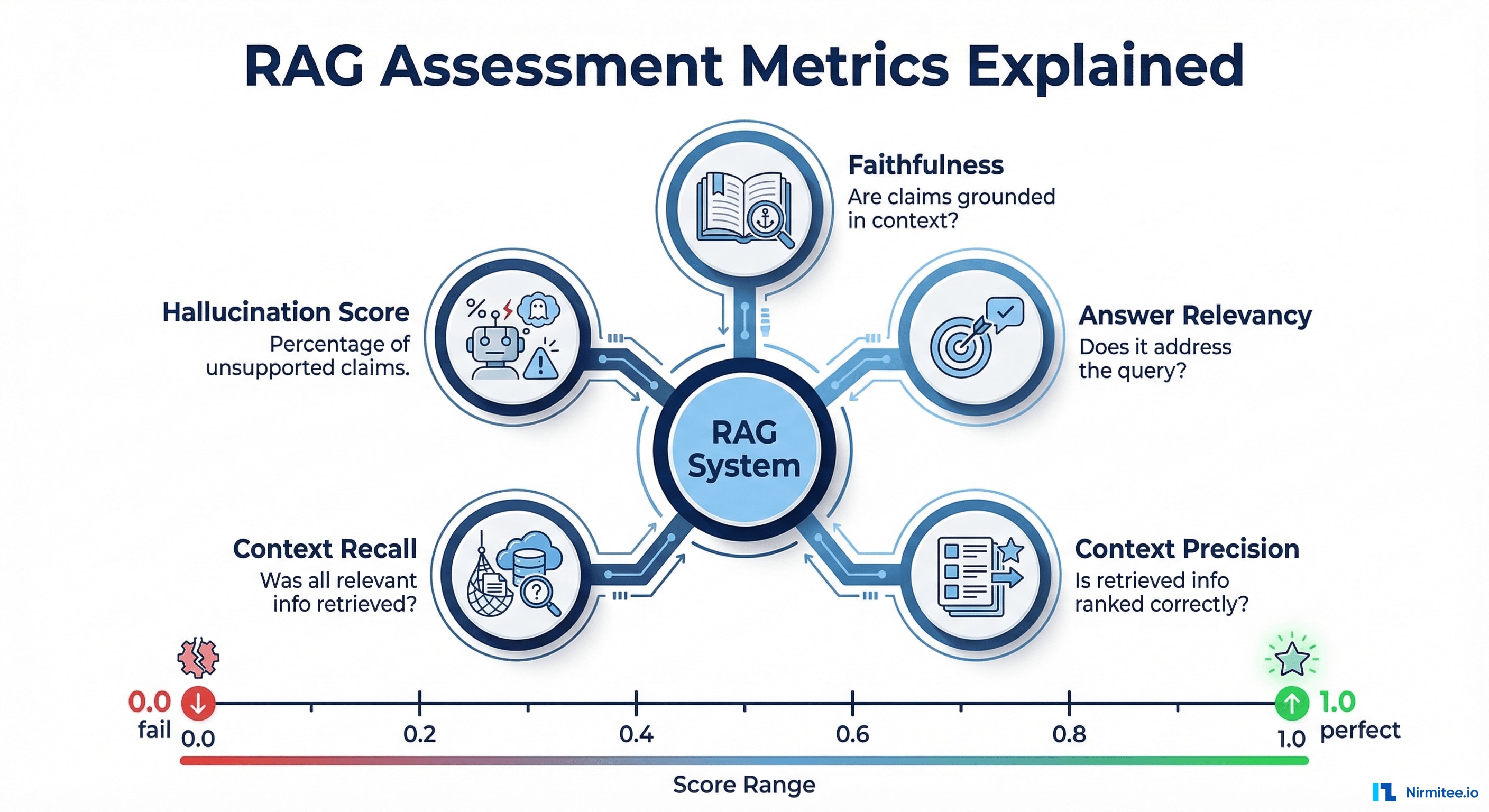
- Faithfulness (0.0 to 1.0) — The percentage of claims in the AI response that are supported by the retrieved context. Target: 0.95 or higher for healthcare. A faithfulness score of 0.8 means 20% of claims are unsupported, which is unacceptable for clinical applications.
- Answer Relevancy (0.0 to 1.0) — How well the response addresses the actual query. A response can be faithful to the source data but completely miss the user's question. Target: 0.85 or higher.
- Context Precision (0.0 to 1.0) — Whether the most relevant documents were retrieved first. Poor context precision means the AI is working with noisy, low-relevance data. Target: 0.80 or higher.
- Context Recall (0.0 to 1.0) — Whether all relevant information was retrieved. If the system misses critical data like a known drug allergy, it cannot produce a safe response. Target: 0.90 or higher for healthcare.
- Hallucination Score — The inverse of faithfulness, measuring the percentage of unsupported claims. For healthcare, anything above 2% should trigger automatic human review.
Traditional NLP Metrics (For Baseline Comparisons)
- BLEU — Measures precision of n-gram overlaps between generated text and reference text. Useful for translation and summarization, but misses semantic equivalence.
- ROUGE — Measures recall of n-gram overlaps. Better for summarization because it checks whether key information from the reference appears in the output.
- BERTScore — Uses BERT embeddings to measure semantic similarity rather than surface-level word matching. Catches correct paraphrases that BLEU and ROUGE miss. Significantly more reliable for healthcare text where terminology varies.
LLM-as-Judge Metrics (For Nuanced Assessment)
G-Eval, introduced in Liu et al. (EMNLP 2023) and now widely adopted, uses a powerful LLM to evaluate outputs against a structured rubric using chain-of-thought reasoning. A comprehensive 2024 survey (updated through October 2025) confirmed that when properly calibrated, LLM-as-judge correlates with human judgment at 85-90%, while costing 10-100x less. The newer RevisEval approach (ICLR 2025) further improves accuracy by creating adaptive references from responses, outperforming both reference-free and reference-based paradigms.
LLM-as-a-Judge: Using AI to Check AI (And Why It Works in 2026)
The idea of using one AI to evaluate another sounds circular. But the methodology has matured dramatically and is now used in production by Datadog, OpenAI, Galileo, and dozens of enterprises processing millions of evaluations daily.
How It Works
- Decomposition — The evaluator LLM breaks the response into individual factual claims. For example, "The patient was prescribed metformin 500mg twice daily for Type 2 diabetes" becomes three claims: (a) metformin was prescribed, (b) dosage was 500mg twice daily, (c) diagnosis is Type 2 diabetes.
- Verification — Each claim is checked against the source context using a structured rubric. The evaluator provides evidence: the specific passage that supports or contradicts the claim.
- Aggregation — Individual claim scores are combined into dimensional scores (faithfulness, relevance, safety) with confidence intervals.
Known Limitations and 2025-2026 Mitigations
The December 2024 comprehensive survey identified biases across four categories (presentation, social, content, cognitive):
- Position bias — LLM judges systematically favor responses based on presentation order. In pairwise code judging, swapping order shifts accuracy by over 10%. Mitigation: run evaluations twice with swapped order and average results.
- Verbosity bias — Judges prefer longer, more fluent responses regardless of accuracy. Mitigation: include explicit rubric criteria penalizing unnecessary verbosity.
- Self-preference bias — Models rate their own outputs higher. The CLEVER framework (JMIR AI, December 2025) validated this: GPT-4o as a judge significantly favored its own clinical responses. Mitigation: Use a different model family for evaluation than for generation.
- Alignment gaps in expert domains — In healthcare, LLM judges agree with human experts only 60-68%. Mitigation: combine LLM-as-judge with domain-specific rule-based checks and periodic human calibration.
A breakthrough came with the Trust or Escalate paper (ICLR 2025 Oral), which introduced selective evaluation: LLM judges assess their own confidence and decide whether to trust their verdict or escalate to a stronger model or human. This achieves over 80% human agreement with approximately 80% test coverage, even with cost-effective models like Mistral-7B.
Building an LLM Evaluation Pipeline: The Technical Deep-Dive
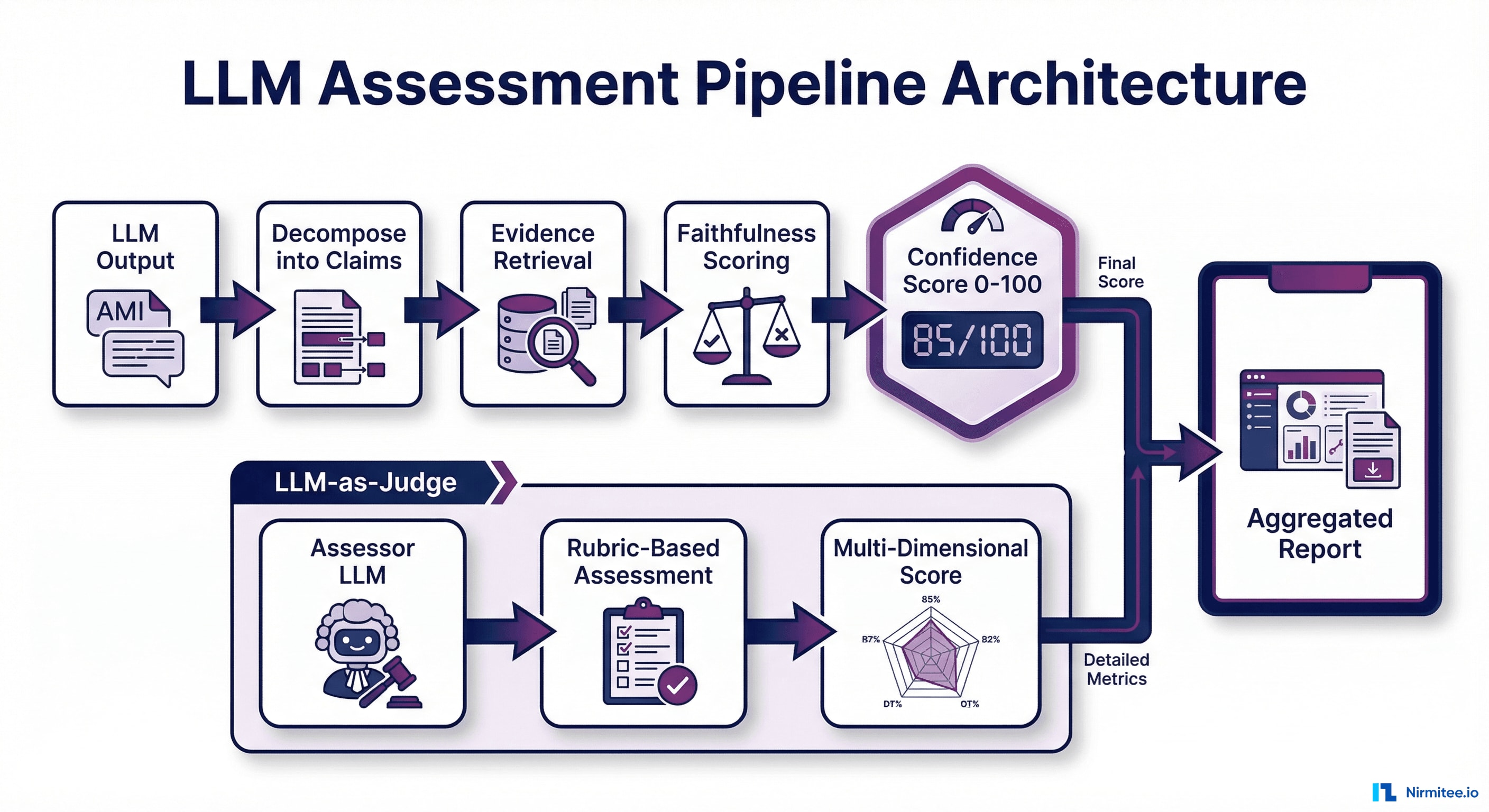
Step 1: Define Evaluation Criteria Tied to Business Outcomes
| Business Risk | Metric | Threshold | Action on Failure |
|---|---|---|---|
| Patient safety | Faithfulness | 0.95 or higher | Block output, escalate to clinician |
| Clinical accuracy | Hallucination Score | 0.02 or lower | Flag for human review |
| User experience | Answer Relevancy | 0.85 or higher | Log and retrain |
| Regulatory compliance | PII Detection | Zero tolerance | Block and alert |
| Data completeness | Context Recall | 0.90 or higher | Retry with expanded retrieval |
Step 2: Build Reference Datasets with Domain Experts
- Clinical validation sets — 500+ examples reviewed by board-certified physicians. OpenAI's HealthBench (2025) set the standard: 5,000 multiturn clinical conversations with 48,562 clinician-developed criteria from 262 physicians across 60 countries.
- Adversarial test cases — Inputs designed to trigger hallucinations. Google's 2025 practical evaluation guide recommends hallucination probing with fictitious entities to stress-test models.
- Regression test suites — Every hallucination caught in production gets added. This dataset grows over time and becomes your most valuable evaluation asset.
For organizations building HIPAA-compliant AI agents, a 2025 architecture paper demonstrated that hybrid PHI sanitization (regex at 98.2% precision + BERT-based NER at 89.8% recall) achieves an F1-Score of 98.4% with only 3 residual PHI instances per 500 clinical notes.
Step 3: Implement Multi-Layer Automated Scoring
Fast Layer (under 100ms) — Rule-based checks on every output: medication name validation against FDA drug formulary, dosage range checking, ICD-10 and CPT code validation, PII/PHI detection using regex plus NER models, toxicity filters.
Deep Layer (1-3 seconds) — LLM-based evaluation: RAGAS faithfulness and relevancy scoring, G-Eval coherence and consistency, cross-reference checking against clinical guidelines, LLM-as-judge with structured rubric.
# Example: Two-step evaluation pipeline using RAGAS
from ragas.metrics import faithfulness, answer_relevancy, context_precision
from ragas import evaluate
def fast_check(response, context):
"""Rule-based checks: PII, medication validation, dosage ranges"""
flags = []
if detect_pii(response): flags.append("pii_detected")
if not validate_medications(response): flags.append("invalid_medication")
if not check_dosage_ranges(response): flags.append("dosage_out_of_range")
return {"pass": len(flags) == 0, "flags": flags}
def deep_check(question, response, contexts):
"""LLM-based scoring via RAGAS"""
result = evaluate(
dataset={"question": [question], "answer": [response], "contexts": [contexts]},
metrics=[faithfulness, answer_relevancy, context_precision]
)
return {
"faithfulness": result["faithfulness"],
"relevancy": result["answer_relevancy"],
"pass": result["faithfulness"] >= 0.95
}
Step 4: Add the LLM-as-Judge Layer for Explainability
This is where data-backed confidence comes from. The LLM judge does not just score, it explains why:
JUDGE_PROMPT = """You are evaluating a healthcare AI response for accuracy.
SOURCE CONTEXT: {context}
AI RESPONSE: {response}
For each factual claim:
1. Extract the claim
2. Find supporting evidence in the source context
3. Rate: SUPPORTED, PARTIALLY_SUPPORTED, or UNSUPPORTED
4. Provide the exact source passage as evidence
Overall assessment:
- Faithfulness score (0.0 to 1.0)
- Confidence level (HIGH / MEDIUM / LOW)
- Recommendation: APPROVE / REVIEW / REJECT"""
This structured output gives clinicians, compliance officers, and auditors a clear chain of evidence for every AI decision.
Step 5: Monitor in Production with Drift Detection
- Rolling evaluation windows — Score a random 5-10% sample of production outputs daily.
- Metric dashboards — Track faithfulness, relevancy, and hallucination rates over time. Set alerts for threshold breaches.
- A/B evaluation — Run both old and new model versions through the pipeline before switching traffic.
- Human feedback loops — Clinician corrections feed back into the evaluation dataset, continuously improving ground truth.

Healthcare-Specific: Why Clinical AI Demands Stricter Evaluation Than Any Other Domain

The Regulatory Imperative in 2026
The FDA has authorized over 1,250 AI/ML-enabled medical devices as of July 2025. Their December 2024 final guidance on Predetermined Change Control Plans (PCCP) requires manufacturers to document anticipated AI modifications, validation protocols, and impact assessments. A January 2025 draft on AI-Enabled Device Software Functions: Lifecycle Management further emphasizes continuous monitoring. In August 2025, the FDA joined Health Canada and the UK MHRA in publishing five joint PCCP principles: Focused, Risk-based, Evidence-based, Transparent, and Lifecycle-oriented.
The EU AI Act entered into force in August 2024. Healthcare AI is classified as high-risk, and the full regulation becomes applicable in August 2026, requiring risk-mitigation systems, high-quality training datasets, transparency, lifecycle logging, and third-party conformity assessments.
Healthcare organizations deploying agentic AI workflows must maintain audit trails showing how each AI decision was evaluated, what scores it received, and why it was approved.
The Epic Sepsis Model Warning
Epic's widely deployed sepsis prediction model detected only one-third of sepsis cases across 38,000 encounters while producing frequent false alarms. A University of Michigan study found the model achieved an AUC of just 0.63, far below Epic's claimed 0.76-0.83. Researchers discovered the model was cueing on whether diagnostic tests had already been ordered, not predicting sepsis independently.
The CLEVER Framework: Healthcare-Specific Evaluation Done Right
Published in JMIR AI (December 2025), the CLEVER framework evaluated 500 novel clinical test cases using blind expert review. Key finding: a healthcare-specific 8B parameter model outperformed GPT-4o on clinical factuality (47% vs 25%), demonstrating that domain-specific models with proper evaluation can beat general-purpose giants. This aligns with Gartner's prediction that enterprises will use small, domain-specific models three times more than general LLMs by 2027.
Healthcare-Specific Evaluation Checklist
- Validate medication names against the FDA's National Drug Code directory
- Check dosage ranges against clinical guidelines (UpToDate, DynaMed)
- Verify ICD-10 and CPT codes against the current CMS code sets
- Test for demographic bias across age, gender, race, and ethnicity
- Run evaluation against FHIR resource validation when generating structured clinical data
- Run adversarial tests with known drug interactions and contraindications
- Maintain a clinical safety board that reviews evaluation methodology quarterly
- Log all evaluation scores with HIPAA-compliant audit trails (6-year retention per 45 CFR Section 164.316)
Tool Comparison: Choosing the Right LLM Evaluation Framework in 2026

| Framework | Best For | Key Metrics | Healthcare Suitability | Pricing |
|---|---|---|---|---|
| RAGAS | RAG system evaluation | Faithfulness, Context Recall, Answer Relevancy | Strong: purpose-built for grounding evaluation | Open source (free) |
| DeepEval | CI/CD integration | 50+ metrics including Hallucination, Bias, Toxicity, DAG builder | Strong: pytest-style, deterministic evaluation | Open source + Confident AI cloud |
| LangSmith | LangChain ecosystem | Agent trajectory capture, Human Feedback, Insights Agent | Moderate: good tracing, limited healthcare-specific metrics | Free 5K traces/mo, $39/user paid |
| Galileo | Production guardrails | Luna-2 fast evals, Agentic Evaluations (Jan 2025) | Strong: sub-200ms at 97% lower cost, 100+ deployments | Free 5K traces/mo, Enterprise tier |
| Arize Phoenix | Observability | OpenTelemetry traces, 7,800+ GitHub stars, full agent traces | Strong: self-hosted for HIPAA compliance | Open source (free) |
| Promptfoo | Red teaming + eval | 50+ vulnerability types, NIST AI RMF presets | Strong: security-focused, joined OpenAI March 2026 | Open source (MIT) |
| W and B Weave | Experiment tracking | Online evals (2025), any-language tracing via OTLP | Moderate: excellent for R and D | Free tier + paid |
Our recommendation for healthcare: Start with RAGAS + DeepEval for development and CI/CD (both open source). Add Arize Phoenix for production observability (self-hosted for HIPAA). Consider Galileo for real-time blocking guardrails. Use Promptfoo for adversarial testing and red teaming. Organizations building AI agents for healthtech should prioritize frameworks supporting multi-step agent trace evaluation.
From Blind Trust to Data-Backed Confidence: The 5-Step Implementation Roadmap
Whether you are evaluating a clinical documentation AI, an agentic RCM automation system, or a patient-facing chatbot:
- Week 1-2: Define Metrics Tied to Business Risks — Map every metric to a specific risk. Use the 5 D's framework from Google's 2025 practical guide: Defined, Demonstrative, Diverse, Decontaminated, Dynamic.
- Week 3-4: Build Reference Datasets — Curate 500+ ground truth examples with domain experts. Include edge cases. Use de-identified data following HIPAA Safe Harbor (all 18 identifiers removed). Statistical rigor: approximately 246 samples needed for 95% confidence with 5% margin of error.
- Week 5-6: Implement Automated Scoring — Deploy the two-layer pipeline. Integrate into CI/CD so every model change triggers evaluation. Use bootstrap confidence intervals with False Discovery Rate correction.
- Week 7-8: Add LLM-as-Judge for Explainability — Configure structured evaluation prompts producing auditable evidence chains. Consider the Trust or Escalate approach for confidence-based routing to human reviewers.
- Ongoing: Monitor, Alert, Improve — Run production sampling, set drift alerts, feed human corrections back into datasets. Your evaluation pipeline is a living system.
From predictive models to clinical AI, our Healthcare AI Solutions practice helps healthcare organizations deploy AI that delivers real outcomes. We also offer specialized Agentic AI for Healthcare services. Talk to our team to get started.
Frequently Asked Questions
How much does it cost to implement LLM evaluation at scale?
Open-source tools (RAGAS, DeepEval, Arize Phoenix) are free. The primary cost is LLM inference for the judge layer: $0.01 to $0.05 per evaluation using GPT-4o or Claude. At 10,000 evaluations per day, that is $100-500 per month.
Galileo's Luna-2 models reduce this by 97%. The LLM observability market hit $672.8 million in 2025 and is growing at 31.8% CAGR, reflecting enterprise demand for these capabilities.
Can you really use AI to evaluate AI?
Yes. The evaluator performs a fundamentally different task than the generator. Research shows LLM-as-judge achieves 85-90% correlation with human judgment.
The ICLR 2025 "Trust or Escalate" paper demonstrated that even Mistral-7B can achieve over 80% human agreement when equipped with confidence-based escalation. The key is using a different model family for evaluation and implementing bias mitigation like swap-and-tie testing.
What faithfulness score should we target for healthcare AI?
Clinical-facing applications: 0.95 or higher with automatic escalation. Administrative AI (scheduling, billing): 0.90 is acceptable. Patient-facing AI: 0.95 or higher with human review for flagged outputs. The CLEVER framework (December 2025) demonstrated that these thresholds are achievable with domain-specific models.
How does LLM evaluation relate to FDA compliance?
The FDA's December 2024 final guidance on Predetermined Change Control Plans and January 2025 draft on AI-Enabled Device Software Lifecycle Management both emphasize continuous performance monitoring. With 1,250+ AI devices authorized and the EU AI Act becoming fully applicable in August 2026, documented evaluation methodology is no longer optional.
What is the best open-source LLM evaluation framework for healthcare?
RAGAS plus DeepEval for development and CI/CD. Arize Phoenix for production observability with self-hosted HIPAA compliance. Promptfoo for red teaming (joined OpenAI March 2026, still open-source MIT). For real-time blocking guardrails, Galileo delivers sub-200ms evaluations at 97% lower cost than GPT-4.
How do I handle evaluation for multi-agent AI systems?
Multi-agent systems require evaluation at both agent and orchestration levels. Each agent's output becomes the next agent's input, creating compounded hallucination risk. Gartner predicts 40% of enterprise apps will feature AI agents by the end of 2026. Use frameworks supporting full trace evaluation (Arize Phoenix, Galileo) to score the entire chain. This is critical for healthcare workflows where multiple AI agents collaborate on prior authorization or care coordination.
The Bottom Line: Evaluation Is Not Optional. It Is the Foundation of Trust.
The healthcare organizations that will win with AI are not the ones deploying the most powerful models. They are the ones who can prove their models work, with data, not hope.
Every hallucination your evaluation pipeline catches before it reaches a clinician is a lawsuit avoided, a patient protected, and trust preserved. Every evaluation score you log is evidence for your next regulatory audit. Every drift alert that fires is a quality problem caught before it becomes a crisis.
Building healthcare AI that needs to be trustworthy? Talk to our team about implementing production-grade LLM evaluation pipelines that deliver data-backed confidence for every AI output.