If you have ever trained a machine learning model that performed brilliantly in a Jupyter notebook but never made it to production, you have encountered the exact problem that MLOps solves. Machine Learning Operations — MLOps — is the discipline of deploying, monitoring, and maintaining ML models in production environments. Think of it as DevOps for machine learning, but with additional complexity that makes traditional DevOps look straightforward by comparison.
Related reading: FHIR Developer Learning Path: Zero to Production.
In healthcare, this complexity is not just an engineering inconvenience. A model that silently degrades in a hospital setting does not just cause a poor user experience — it can lead to missed diagnoses, delayed treatments, and patient harm. According to a 2025 JMIR scoping review, fewer than 15% of healthcare ML models in academic research ever reach clinical production, and of those that do, most lack systematic monitoring for ongoing performance.
This article is your comprehensive introduction to MLOps from a healthcare developer's perspective. We will cover what it is, why healthcare needs it more than any other industry, how it differs from traditional DevOps, the complete ML lifecycle, the key tools you need to know, and the healthcare-specific compliance requirements that make this space uniquely challenging.
Why Healthcare Needs MLOps More Than Any Other Industry
Every industry benefits from operationalizing ML models, but healthcare has four characteristics that make MLOps not just beneficial, but essential:
1. Regulatory Compliance Is Non-Negotiable
Healthcare AI operates under HIPAA, FDA 21 CFR Part 11, and increasingly the EU AI Act (for models deployed in Europe). Every model decision must be auditable. Every training dataset must have a documented provenance chain. Every model version must be traceable back to its exact training data, hyperparameters, and validation results. Without MLOps, maintaining this documentation manually is unsustainable at scale. For a deeper look at HIPAA's evolving requirements, see our guide on the 2026 HIPAA Security Rule overhaul.
2. Patient Safety Makes Model Failures High-Stakes
When a recommendation engine at an e-commerce company degrades, customers see irrelevant products. When a sepsis prediction model at a hospital degrades, patients die. The PMC study on equitable AI in healthcare found that models deployed without continuous monitoring showed accuracy drops of 8-15% within 6 months — often without any alerts to clinical teams. MLOps provides the monitoring and alerting infrastructure that catches degradation before it causes harm.
3. Clinical Data Shifts Constantly
Healthcare data is uniquely volatile. New treatment protocols change prescribing patterns. Pandemics like COVID-19 completely redefined what "normal" vital signs look like. Scanner hardware upgrades alter imaging characteristics. Seasonal flu patterns shift patient demographics. A sepsis model trained on pre-COVID ICU data saw its positive predictive value drop from 82% to 61% during the pandemic, because the baseline definition of respiratory distress had fundamentally changed.
4. Bias Detection Requires Continuous Monitoring
Healthcare AI models can develop or amplify disparities across patient populations over time. A model that performs well on aggregate metrics might systematically underperform for specific racial groups, age cohorts, or socioeconomic segments. MLOps provides the infrastructure for continuous fairness monitoring and stratified performance tracking across demographic dimensions.
DevOps vs. MLOps: What Makes Machine Learning Operations Different
If you come from a DevOps background, MLOps will feel familiar in structure but fundamentally different in execution. The core difference is this: in DevOps, code is deterministic — given the same input, the same code produces the same output. In MLOps, models are probabilistic, dependent on training data, and they degrade over time even without any code changes.
Here is a detailed comparison:
| Dimension | DevOps | MLOps |
|---|---|---|
| Versioning | Code (Git) | Code + Data + Model artifacts + Hyperparameters |
| Testing | Unit tests, integration tests, E2E tests | Data validation, model performance, bias testing, A/B testing |
| CI/CD Focus | Build code, run tests, deploy | Ingest data, train model, validate, deploy, monitor |
| Monitoring | Uptime, latency, error rates | Accuracy, precision/recall, data drift, concept drift |
| Deployment | Containers, VMs, serverless | Model serving endpoints + feature stores + shadow mode |
| Rollback | Git revert, deploy previous tag | Model version rollback + potentially retrain on earlier data version |
| Degradation | Only from code bugs or infra failures | From data drift even with zero code changes |
| Reproducibility | Same code = same output | Requires exact data + code + environment + random seeds |
| Compliance | SOC2, ISO 27001 | FDA 510(k), HIPAA, EU AI Act, model cards |
The Three Versioning Dimensions
The single biggest conceptual shift from DevOps to MLOps is versioning. In DevOps, Git handles code versioning. In MLOps, you need three parallel versioning systems:
- Code versioning (Git) — your training scripts, preprocessing pipelines, serving code
- Data versioning (DVC, LakeFS, Delta Lake) — your training datasets, feature definitions, data splits
- Model versioning (MLflow Model Registry, Weights & Biases) — your trained model artifacts, hyperparameters, metrics, and lineage
Every production model must trace back to the exact combination of code version + data version + hyperparameters that produced it. Without this traceability, you cannot reproduce results, debug failures, or satisfy regulatory audits.
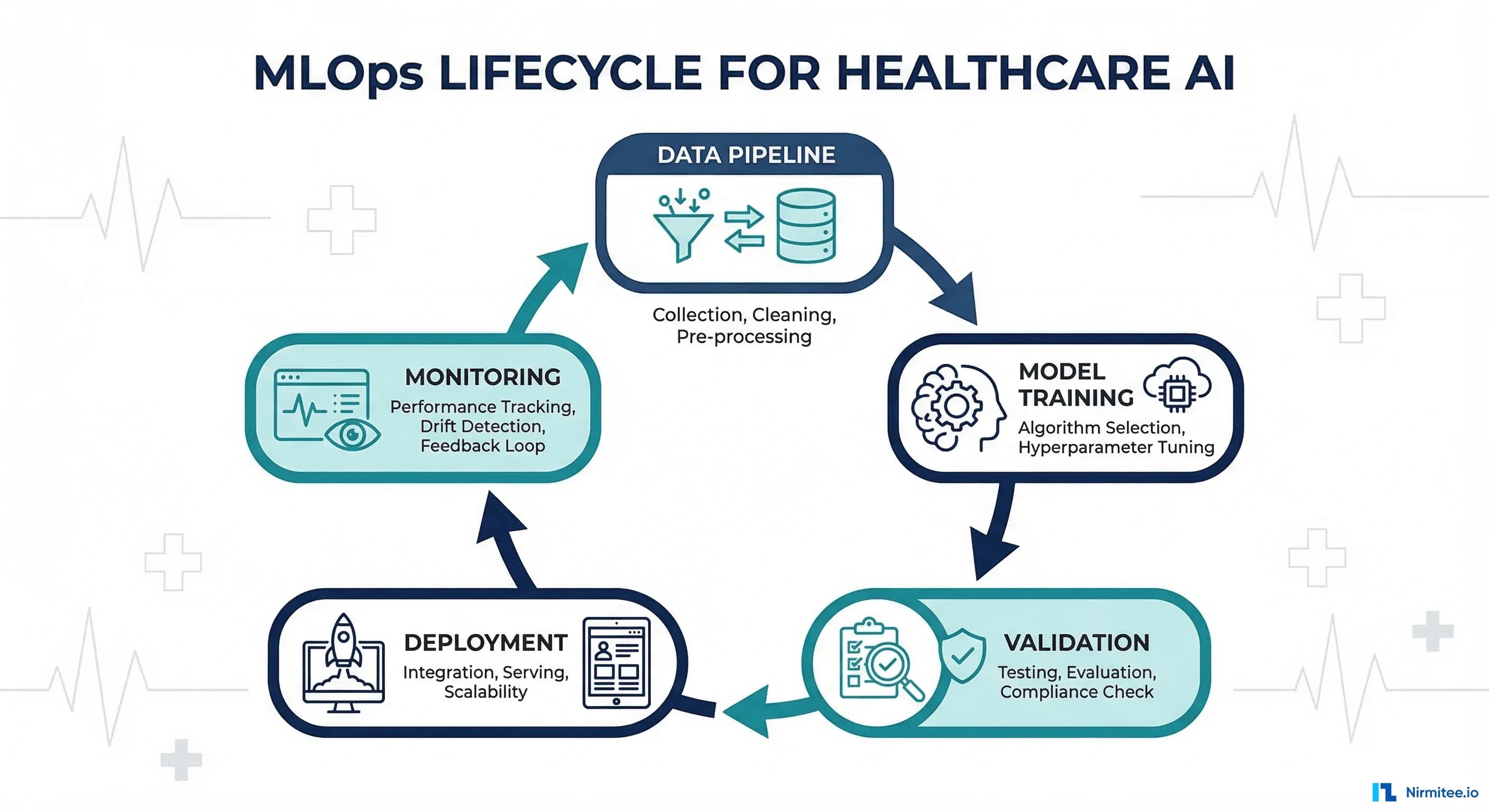
The ML Lifecycle: Six Stages from Data to Production
The ML lifecycle is a continuous loop, not a linear pipeline. Understanding these six stages is essential before selecting tools or designing your MLOps infrastructure. For a deeper dive into how clinical data pipelines feed into this lifecycle, see our guide on building clinical data pipelines with FHIR for AI/ML.
Stage 1: Data Collection and Preparation
Clinical data arrives from EHRs (via FHIR or HL7v2), lab systems, imaging archives, claims databases, and IoT devices. This stage involves:
- Data ingestion from multiple source systems
- De-identification and PHI stripping (see our article on de-identifying healthcare data for AI)
- Data quality validation — missing values, outlier detection, format consistency
- Feature engineering — transforming raw clinical data into model-ready features
- Train/validation/test splits with temporal awareness (no future leakage)
# Example: FHIR data extraction for ML pipeline
import requests
from datetime import datetime
def extract_patient_features(fhir_server, patient_id):
"""Extract clinical features from FHIR resources for ML training."""
headers = {"Accept": "application/fhir+json"}
# Fetch observations (vitals, labs)
obs_url = f"{fhir_server}/Observation?patient={patient_id}&_count=1000"
observations = requests.get(obs_url, headers=headers).json()
features = {
"patient_id": patient_id,
"vital_signs": {},
"lab_results": {},
"timestamp": datetime.utcnow().isoformat()
}
for entry in observations.get("entry", []):
resource = entry["resource"]
code = resource["code"]["coding"][0]["code"]
value = resource.get("valueQuantity", {}).get("value")
if code in ["8867-4", "8310-5", "8480-6"]: # HR, Temp, SBP
features["vital_signs"][code] = value
elif code in ["2160-0", "2823-3"]: # Creatinine, Potassium
features["lab_results"][code] = value
return features
Stage 2: Model Training and Experimentation
This is where data scientists iterate on model architectures, hyperparameters, and feature selections. Every experiment should be tracked with parameters, metrics, and artifacts logged systematically — not in spreadsheets or notebooks.
# Example: MLflow experiment tracking for clinical model
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import roc_auc_score, precision_score, recall_score
mlflow.set_experiment("sepsis-prediction-v2")
with mlflow.start_run(run_name="gbm-clinical-features"):
# Log parameters
params = {
"n_estimators": 200,
"max_depth": 6,
"learning_rate": 0.1,
"data_version": "v2.3-post-covid",
"feature_set": "vitals+labs+demographics",
"train_size": 45000,
"positive_rate": 0.08
}
mlflow.log_params(params)
# Train model
model = GradientBoostingClassifier(**{k: v for k, v in params.items()
if k in ["n_estimators", "max_depth", "learning_rate"]})
model.fit(X_train, y_train)
# Log metrics (NEVER log patient IDs as params)
y_pred = model.predict_proba(X_test)[:, 1]
mlflow.log_metrics({
"auc_roc": roc_auc_score(y_test, y_pred),
"precision_at_90_recall": precision_score(y_test, y_pred > 0.3),
"recall": recall_score(y_test, y_pred > 0.3),
"specificity": 0.87 # from confusion matrix
})
# Log model artifact
mlflow.sklearn.log_model(model, "sepsis-model")
Stage 3: Validation
In healthcare, validation is not just a statistical exercise — it requires clinical review. This stage includes:
- Statistical validation: AUC-ROC, sensitivity/specificity at clinically meaningful thresholds, calibration curves
- Fairness testing: Stratified performance across race, age, sex, and insurance status
- Clinical review board: Clinicians evaluate model outputs for clinical plausibility
- Edge case testing: Performance on rare conditions, pediatric patients, and comorbid patients
Stage 4: Deployment
Deploying a model means packaging it as a service that accepts inputs and returns predictions with low latency. In healthcare, this involves containerization (Docker), orchestration (Kubernetes), and rigorous health checks. The model should first run in shadow mode — receiving real inputs and making predictions that are logged but not shown to clinicians — to validate production performance before going live.
Stage 5: Monitoring
Once deployed, the model must be continuously monitored for accuracy degradation, data drift, and prediction distribution changes. This is where most healthcare ML deployments fail — teams deploy and forget, only discovering problems when clinicians start complaining about false alarms. For teams building observability infrastructure, see our guide on observability dashboards for healthcare AI.
Stage 6: Retraining
When monitoring detects drift or degradation, the model enters a retraining cycle — new data is collected, a new model is trained, validated through the same clinical gates, and deployed to replace the degraded version. This loop should be automated with human-in-the-loop approval at key gates.
Key MLOps Tools: A Healthcare Developer's Toolkit
The MLOps tool landscape is vast. Here are the categories and leading tools you need to understand:
Experiment Tracking: MLflow
MLflow is the most widely adopted open-source MLOps platform. It provides experiment tracking (log parameters, metrics, artifacts), a model registry (version and promote models through stages), and model serving. It is the foundation of most healthcare MLOps stacks because it is self-hostable — critical for HIPAA compliance since experiment metadata must stay within your security boundary.
Pipeline Orchestration: Kubeflow and Airflow
Kubeflow runs ML pipelines on Kubernetes, providing reproducible, containerized training runs. Apache Airflow is more general-purpose but widely used for data pipeline orchestration. For healthcare teams already running Kubernetes, Kubeflow is the natural choice.
Data Versioning: DVC
DVC (Data Version Control) extends Git to handle large datasets and model files. It stores metadata in Git while the actual data lives in S3, GCS, or Azure Blob Storage. This enables you to check out any historical data version the same way you check out a code commit.
Monitoring: Evidently AI
Evidently provides data drift detection, model performance monitoring, and test suites for ML models. It generates visual reports that non-technical stakeholders (clinical leadership) can understand — crucial in healthcare where model governance involves clinical informatics teams, not just engineers.
# Example: Evidently drift detection for clinical model
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset, TargetDriftPreset
# Compare current production data against training data
drift_report = Report(metrics=[
DataDriftPreset(),
TargetDriftPreset()
])
drift_report.run(
reference_data=training_data, # Original training set
current_data=production_data, # Last 30 days of production data
column_mapping=column_mapping
)
# Export report for clinical review
drift_report.save_html("drift_report_march_2026.html")
# Programmatic drift check for alerting
report_dict = drift_report.as_dict()
dataset_drift = report_dict["metrics"][0]["result"]["dataset_drift"]
if dataset_drift:
send_alert("Data drift detected in sepsis model - clinical review required")
Containerization and Serving: Docker + Kubernetes
Docker packages your model with its exact dependencies. Kubernetes orchestrates serving at scale with auto-scaling, health checks, and rolling deployments. For GPU-intensive models (imaging, NLP), NVIDIA's Triton Inference Server on Kubernetes provides optimized serving.
Healthcare-Specific MLOps Requirements
Beyond the standard MLOps practices, healthcare demands an additional compliance layer that sits between your ML pipeline and production:
HIPAA Compliance in the ML Pipeline
- Training data: Must be de-identified or used under a Data Use Agreement with minimum necessary access
- Experiment tracking: Never log patient IDs, MRNs, or PHI as experiment parameters. Use hashed identifiers only
- Model artifacts: Stored in encrypted-at-rest storage (S3 with SSE-KMS, not SSE-S3)
- Inference logs: Prediction inputs/outputs may contain PHI and must be handled under BAA-covered infrastructure
- Access control: RBAC on MLflow/experiment tracking — data scientists see experiment metrics, not raw patient data
Clinical Validation Gates
Healthcare models require human-in-the-loop approval gates that do not exist in standard MLOps:
- Clinical Review Board sign-off before any model moves from staging to production
- Prospective validation: Shadow mode deployment with blinded clinician comparison
- Bias review: Mandatory stratified performance reporting before deployment approval
- Threshold calibration: Sensitivity/specificity thresholds set by clinical stakeholders, not engineers
FDA Documentation Requirements
If your model is classified as a Software as a Medical Device (SaMD), the FDA requires:
- Predetermined change control plans (what triggers retraining and what validation is required)
- Algorithm descriptions with training data characteristics
- Performance evaluation across intended patient populations
- Continuous real-world performance monitoring plans
# Example: MLOps pipeline config with healthcare compliance gates
pipeline:
name: sepsis-prediction-pipeline
version: "2.3"
stages:
- name: data_preparation
validation:
- check: phi_scan
description: "Verify no PHI in training features"
blocker: true
- check: data_quality
min_completeness: 0.95
- name: training
tracking: mlflow
encryption: AES-256-GCM
- name: validation
gates:
- statistical:
min_auc_roc: 0.85
min_sensitivity: 0.90
max_false_positive_rate: 0.15
- fairness:
max_disparity: 0.05
stratify_by: [race, sex, age_group]
- clinical_review:
required_approvers: 2
roles: [CMIO, clinical_informaticist]
- name: deployment
strategy: shadow_first
shadow_duration: 14_days
auto_promote: false # Always require human approval
- name: monitoring
drift_check_interval: 24h
accuracy_alert_threshold: 0.80
retraining_trigger: drift_score > 0.3
Getting Started: A Practical First Step
If you are a healthcare developer looking to introduce MLOps into your workflow, here is where to start:
- Start with experiment tracking: Install MLflow locally and log your next model training run. This single step eliminates the "which notebook version produced the best model?" problem
- Version your data: Initialize DVC in your project and track your training dataset alongside your code
- Add a basic monitoring script: Write a weekly cron job that compares your model's prediction distribution against its training distribution using Evidently
- Document your model: Create a model card for every model you deploy — who trained it, what data it used, what populations it was validated on, what its known limitations are
- Automate one gate: Add a CI check that blocks deployment if model AUC drops below a threshold
These five steps, implemented incrementally, will take you from ad-hoc model deployment to a basic MLOps practice. From there, you can build toward full pipeline automation, clinical review workflows, and continuous monitoring. For teams building the broader AI agent infrastructure that these models plug into, our guide on the 6 layers between notebook and clinic covers the complete production architecture.