Reading time: 15 min | Last updated: April 2026
In 2023, a handful of health systems piloted ambient AI scribes. By early 2026, 62.6% of US hospitals running Epic have adopted ambient clinical documentation. Over $1 billion in venture capital flooded ambient AI companies in 2025 alone. The technology moved from experiment to standard infrastructure in under three years—faster than any previous wave of health IT adoption.
That is healthcare AI's "iPhone moment." But the device was never the real story. The real story was the app ecosystem and platform economy that followed. Ambient scribes are the iPhone. What comes next—AI agents that do not just listen but act—is the app store. Most health systems are not prepared.
Today, 69% of healthcare organizations report using generative AI in some capacity, but only 22% have deployed AI agents. Just 3% have deployed agentic AI in live clinical or operational workflows, according to BCG's 2026 healthcare AI survey. That gap—between passive AI adoption and agentic AI maturity—is the most consequential strategic divide in healthcare technology today.
This article introduces a five-level Healthcare AI Maturity Ladder: a framework for understanding where your organization sits, what capabilities exist at each level, and how to climb deliberately rather than reactively.
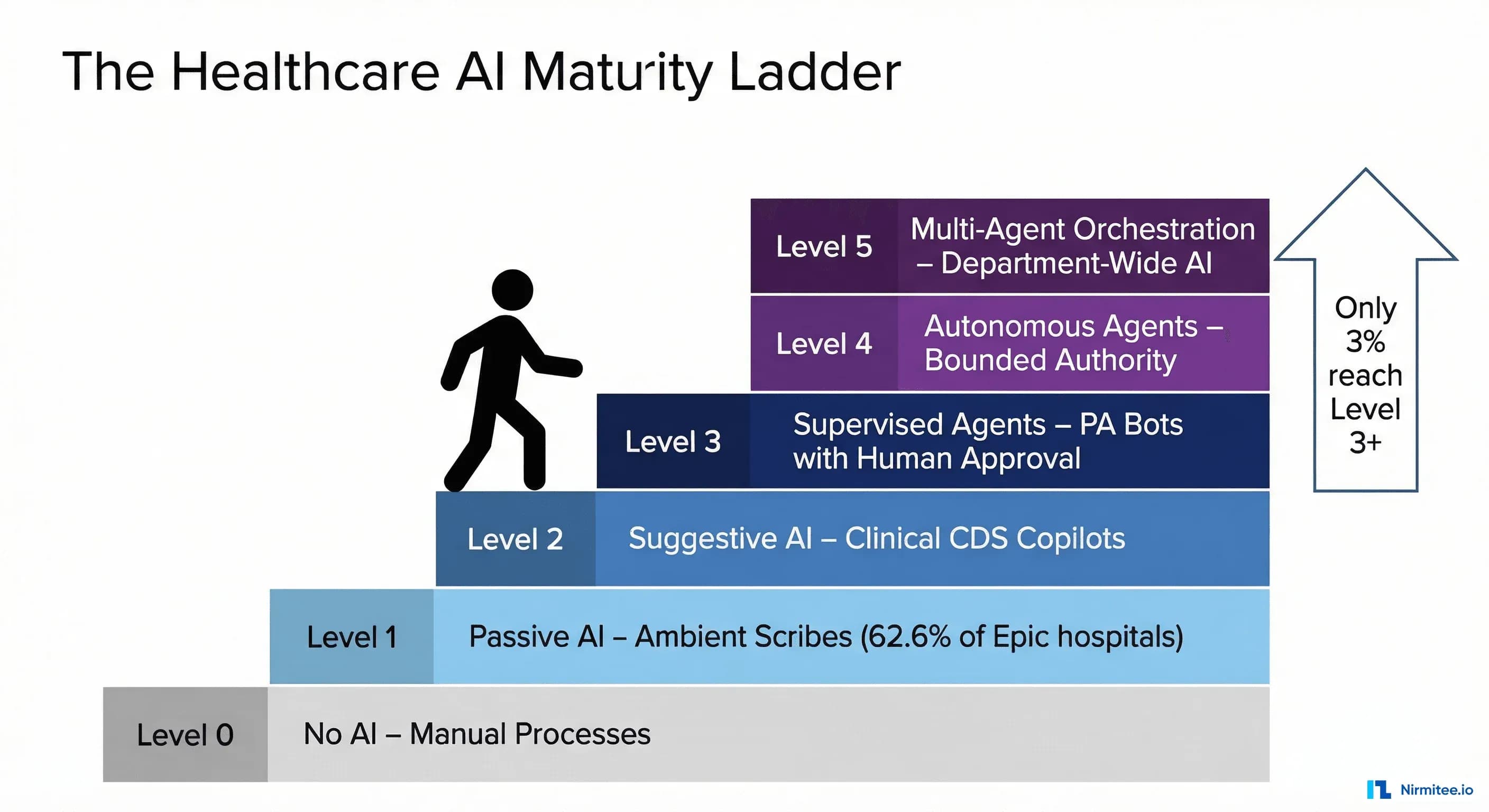
The Healthcare AI Maturity Ladder: A Five-Level Framework
The framework divides healthcare AI maturity into six distinct levels (0 through 5), each defined by the degree of autonomous action the AI takes. The critical distinction between levels is not the sophistication of the underlying model—it is the scope of authority the organization grants the AI system.
A Level 1 system can have an identical large language model to a Level 4 system. The difference is whether the AI is permitted to observe, suggest, or act—and under what governance structure.
Level 0: Manual Operations. No AI involvement. Paper, fax, phone. Roughly 15-20% of US physician practices still operate here for significant portions of their workflow.
Level 1: Passive AI (Observe and Transcribe). AI listens, transcribes, and summarizes—but takes no action. The clinician reviews, edits, and signs everything. Ambient scribes and note summarizers. This is where the majority of health systems sit today.
Level 2: Suggestive AI (Analyze and Recommend). AI analyzes clinical data and surfaces recommendations, but the clinician decides whether to act. CDS alerts, coding suggestions, drug interaction warnings. Read access to clinical data; no write access.
Level 3: Supervised Agents (Act with Human Approval). AI takes concrete actions—but every action requires explicit human approval. A prior authorization agent that assembles documentation, fills the payer form, and queues it for one-click clinician approval. Read and write access, with writes gated by human-in-the-loop confirmation.
Level 4: Autonomous Agents (Act Within Bounded Authority). AI acts independently within defined boundaries without per-action approval. A claims processing agent that auto-adjudicates standard claims, escalating only exceptions. Operates under a policy framework with comprehensive audit trails.
Level 5: Multi-Agent Orchestration (Coordinate Across Systems). Specialized agents coordinate across departments through an orchestration layer that routes tasks, resolves conflicts, and optimizes system-wide. The hospital operating system of the future.
Each level builds on the one below. You cannot deploy supervised agents (Level 3) without Level 2's decision support infrastructure. Skipping levels creates fragile deployments that collapse under regulatory scrutiny.
Level 1 — The Ambient Era: Where Most Health Systems Are Today
Ambient clinical documentation has gone from a niche experiment to the dominant healthcare AI use case in under 36 months. The numbers tell a remarkable adoption story.
Of the approximately 2,785 US hospitals running Epic as their primary EHR, roughly 1,744—62.6%—have adopted ambient AI in some form. Nuance's DAX Copilot, deeply integrated with Microsoft's infrastructure, holds the largest market share. Abridge, the most aggressively funded independent player, raised a $250 million Series D and a subsequent $300 million Series E in 2025, reaching a $5.3 billion valuation. The total ambient clinical documentation market is approaching $600 million in annual revenue, with nearly $1 billion invested in the sector in 2025 alone.
The clinical ROI data from early adopters is compelling. Houston Methodist, one of the most-studied ambient AI deployments, has published results showing a 40% reduction in documentation time, a 27% increase in direct patient face time, and a 33% cut in after-hours charting—the "pajama time" documentation that is the single largest driver of physician burnout. These are not incremental improvements; they represent a fundamental restructuring of how clinical time is allocated.
But Level 1 has a ceiling. Ambient scribes generate text. They do not close care gaps, submit orders, file authorizations, or coordinate across departments. A physician who saves 90 minutes per day on documentation still spends 45 minutes on prior authorizations, 30 minutes on inbox management, and 20 minutes on prescription refills—all tasks that require action, not transcription.
The ambient era solved the documentation burden. It did not solve the administrative burden. For that, healthcare needs agents.
For a deeper analysis of how ambient scribes work under the hood—and where they fall short—see our technical breakdown: Building an AI Clinical Scribe: From Weekend Prototype to Production Challenges.
Level 2 — The Suggestion Layer: AI as Clinical Co-Pilot
Level 2 represents a meaningful jump in capability: the AI is no longer just recording what happened—it is analyzing clinical data and surfacing recommendations in real time. The AI reads the patient's chart, the current encounter context, and relevant medical literature, then presents actionable suggestions to the clinician.
The most significant recent development at this level is Microsoft's integration of Wolters Kluwer's UpToDate clinical evidence database into its Copilot platform. This gives clinicians real-time, context-aware clinical recommendations grounded in peer-reviewed evidence—a retrieval-augmented generation (RAG) architecture that connects the LLM to a curated clinical knowledge base rather than relying on the model's training data alone. This is significant because it addresses the hallucination problem that has plagued clinical AI: the model's outputs are anchored to specific, citable evidence.
The medication safety data at this level is particularly striking. A 2025 study published in the Journal of the American Medical Informatics Association demonstrated that an LLM-based co-pilot achieved a 1.5x accuracy improvement in detecting medication errors compared to traditional rule-based alert systems. The model caught drug-drug interactions, dosage errors, and contraindications that the legacy alerting system missed—largely because the LLM could process free-text clinical context that structured alerts could not.
Google's release of MedGemma in January 2026—an open-source medical LLM that scored 87.7% on the MedQA benchmark—lowered the barrier for health systems to build Level 2 applications on their own infrastructure rather than depending on commercial APIs. MedGemma is not a finished product, but it is a foundation model that health system data science teams can fine-tune on their own clinical data, creating institution-specific clinical co-pilots.
Companies operating at this level include Wolters Kluwer, Elsevier (ClinicalKey AI), and a growing startup ecosystem. Wolters Kluwer's 2026 trends report called this the "year of governance"—reflecting the recognition that suggestive AI requires more oversight than passive transcription. The FDA's March 2026 draft guidelines proposed classifying AI health chatbots as medical devices, signaling that any system providing clinical recommendations will face increasing scrutiny.
For a detailed look at how clinical decision support systems are evolving with AI, see our analysis: AI-Driven Clinical Decision Support Systems.
Level 3 — Supervised Agents: The 2026 Frontier
Level 3 is where healthcare AI transitions from advisory to operational. The AI does the work and asks you to approve it. This is the 2026 frontier.
Glen Tullman, CEO of Transcarent and the founder who built Livongo into a $18.5 billion acquisition, declared in January 2026 that "the healthcare chatbot is dead." His argument: patients and clinicians do not want to chat with AI—they want AI to do things. A chatbot that says "your prior authorization requires these documents" is Level 2. An agent that gathers those documents, assembles the submission, and presents a single "Submit" button is Level 3.
The three highest-ROI supervised agent use cases emerging in 2026: prior authorization agents (a $31 billion annual burden per the AMA—agents that assemble documentation, fill payer forms, and queue for one-click approval; companies like Cohere Health and Olive AI have built production systems here); prescription refill agents (turning a 4-6 minute task into a 15-second review by pre-evaluating requests against clinical criteria); and scheduling agents (reading clinical context to propose optimized appointments and referrals). See: 5 Healthcare Workflows Agentic AI Will Transform by 2027.
Level 3 agents require a critical technical foundation: FHIR and CDS Hooks. A supervised agent needs to read the patient's chart (FHIR R4 APIs), reason about clinical context (the LLM), and write proposed actions back to the EHR (FHIR write operations and CDS Hooks). Without a robust FHIR API layer, agents are limited to proprietary integrations that do not scale. For a technical deep dive: Agent on FHIR: Building AI Agents That Read and Write Clinical Data.
Level 4 — Autonomous Agents: Where the Industry Is Heading
Level 4 is the inflection point where AI operates independently within defined boundaries—what we call the bounded autonomy pattern. The human is no longer in the loop for every action; instead, the human defines the policy framework, and the AI operates within it. Humans handle exceptions, edge cases, and policy updates.
This is where the stakes—and the potential—increase dramatically.
Hippocratic AI, which raised $141 million at a $1.64 billion valuation, is building autonomous healthcare AI agents designed to handle patient-facing tasks independently: medication reminders, post-discharge follow-up calls, chronic disease management check-ins, and care navigation. Their model is trained specifically for safety-critical healthcare interactions, with built-in guardrails for clinical boundaries.
Color Health's partnership with Google to build an agentic breast cancer screening system represents another Level 4 application: the AI independently processes screening results, identifies patients requiring follow-up, and initiates the appropriate care pathway—escalating to a human oncologist only for complex or ambiguous cases.
The bounded autonomy pattern has three defining characteristics: policy-defined authority (explicit rules governing what the agent can do, when, and with what constraints); comprehensive audit trails (every action logged with input data, reasoning, and the policy rule that authorized it); and exception escalation (well-defined paths for situations outside the agent's authority, with full context transfer). At Level 4, mistakes reach the real world before a human sees them—demanding robust testing, continuous monitoring, and governance that can withstand regulatory scrutiny.
For a detailed architecture of the bounded autonomy pattern—including the policy engine, audit system, and escalation framework—see: Bounded Autonomy: Healthcare AI Compliance Architecture.
The workforce implications at Level 4 are significant. With a projected shortage of over 100,000 healthcare workers by 2028, autonomous agents are not replacing workers—they are filling positions that cannot be staffed. The economic argument for Level 4 is not cost reduction; it is capacity creation in a system that is structurally unable to hire enough humans.
Level 5 — Multi-Agent Systems: The Hospital of 2030
Level 5 is the destination, not the present. No health system operates here today. But the technical foundations are being laid, and the organizations that understand the architecture now will be positioned to build it first.
In a multi-agent system, specialized AI agents—each operating at Level 3 or Level 4 maturity in their domain—coordinate through an orchestration layer to execute complex, cross-departmental workflows. No single agent has the full picture. The orchestrator holds the system-level view and routes tasks, resolves conflicts, and optimizes for global outcomes rather than local ones.
Consider a patient discharge. Today, this involves six or more people, three or more IT systems, and typically takes 4-8 hours from discharge decision to actual departure. Delays cost hospitals an estimated $500-700 per hour in bed-day costs. In a Level 5 system, a discharge orchestrator agent receives the physician's discharge decision and coordinates specialized agents for medication reconciliation, care transition, scheduling, patient communication, billing, and bed management—all operating in parallel, communicating through standardized protocols.
The orchestrator tracks dependencies (discharge instructions cannot be generated until the medication list is finalized), resolves conflicts (the preferred post-acute facility is full—route to the next option), and handles exceptions. The technical requirements include inter-agent communication protocols, shared state management, conflict resolution logic, and enterprise governance that spans all agents.
For an in-depth look at multi-agent architectures in healthcare, including orchestration patterns and the role of deterministic workflow engines, see: BPMN, DMN, and Agentic AI: Building Deterministic Workflow Engines for Healthcare.
Assessment: What Level Is Your Organization?
Most organizations overestimate their AI maturity because they conflate having AI tools with having AI capability. Running an ambient scribe in 20% of your exam rooms does not make you a Level 1 organization across the board—it makes you Level 1 in outpatient documentation and Level 0 everywhere else.
True maturity assessment requires evaluating six dimensions. Use this scorecard to assess your organization honestly. Score each dimension from 0 (not started) to 5 (enterprise-grade), then look at your lowest score—that is your actual maturity level, because the chain is only as strong as its weakest link.
| Dimension | Level 1 (Passive AI) | Level 3 (Supervised Agents) | Level 5 (Multi-Agent) |
|---|---|---|---|
| Data Infrastructure | EHR deployed; data accessible but not curated for AI | Real-time data pipelines; data governance enforced; labeled training datasets available | Unified data fabric across all systems; real-time event streams; cross-institutional sharing |
| Technical Platform | Vendor-provided AI tools (ambient scribe) as SaaS; no internal AI platform | AI platform with model serving and versioning; FHIR R4 API layer; CDS Hooks; agent framework | Multi-agent orchestration platform; inter-agent communication; enterprise-wide optimization |
| Governance Framework | Basic AI use policy; vendor security reviews; privacy impact assessments | Agent-specific governance: HITL protocols, action authorization, audit logging; clear accountability | Enterprise AI governance board; cross-agent oversight; real-time dashboards; external audit readiness |
| Workforce Readiness | Clinicians trained on ambient tools; basic AI literacy; change management started | Staff trained to supervise agents; protocols for reviewing AI-proposed actions documented | Organization-wide AI fluency; roles redefined around multi-agent systems |
| Clinical Buy-In | Early adopters engaged; positive sentiment around documentation relief; champions identified | Clinicians comfortable supervising agents; trust demonstrated through pilot results | Organization-wide trust; clinicians in strategic oversight roles; continuous feedback loops |
| Interoperability Stack | Basic FHIR R4 read APIs; patient access API compliant with CMS rules | FHIR read and write APIs; CDS Hooks integrated; real-time event subscriptions; agent-accessible API layer | Enterprise integration platform; cross-institutional FHIR exchange; real-time event mesh; TEFCA-ready |
Score each dimension from 0 (not started) to 5 (enterprise-grade) using the level descriptions in the maturity ladder above. The intermediate levels (2 and 4) represent the transition states between the benchmarks shown.
How to read your score: Your overall maturity level equals your lowest dimension score. An organization scoring 3 on Data Infrastructure, 3 on Technical Platform, 1 on Governance, 3 on Workforce, 2 on Clinical Buy-In, and 2 on Interoperability is effectively at Level 1—because the governance gap prevents safe deployment of anything above passive AI.
For a comprehensive readiness assessment framework with deeper diagnostic questions, see: Agentic AI Readiness Assessment for Healthcare.
The Climbing Playbook: Moving Up One Level at a Time
The most common mistake organizations make is trying to jump from Level 1 to Level 4. It fails every time. Each transition requires building specific capabilities that the next level depends on. Here is what each transition demands.
Level 0 to Level 1: Deploy Ambient (3-6 Months)
Select a vendor (Nuance DAX, Abridge, or Nabla for smaller practices), pilot in 2-3 high-volume departments for 30-60 days, and measure documentation time, after-hours work, and clinician satisfaction against a pre-deployment baseline. Assign a physician champion per department and establish a basic AI use policy covering data privacy and output review.
Critical success factor: Physician trust. Target 95%+ note accuracy within the first 30 days or adjust vendor configuration before scaling.
Level 1 to Level 2: Add Intelligence (6-12 Months)
Build your clinical data platform for real-time AI access. Implement FHIR R4 read APIs across core clinical domains. Deploy clinical decision support within existing workflows (not in a separate app). Establish a clinical AI validation committee and begin tracking recommendation acceptance rates and clinical outcomes.
Critical success factor: Alert fatigue management. Kill any alert with less than a 5% acceptance rate. Use ML-based prioritization to ensure 80%+ of suggestions are clinically actionable.
Level 2 to Level 3: Enable Agents (12-18 Months)
Implement FHIR write APIs and CDS Hooks. Build an agent governance framework defining what actions agents can propose and how approvals work. Select a single high-ROI use case for your first supervised agent—prior authorization is the most common choice because the ROI is immediately measurable and the downside risk is administrative, not clinical. Build a one-click approval workflow with full context displayed.
Critical success factor: Interoperability. Agents that cannot read from and write to clinical systems through standardized APIs are glorified scripts. Invest in FHIR infrastructure before agent capabilities.
Level 3 to Level 4: Grant Autonomy (18-24 Months)
Build a policy engine defining bounded authority. Implement comprehensive audit logging for every autonomous action. Run shadow mode for 90+ days (the agent acts autonomously but every action is human-reviewed after the fact) before going fully autonomous. Develop a regulatory strategy that satisfies FDA, CMS, and state regulators.
Critical success factor: Trust through transparency. Every action must be explainable, traceable, and auditable. For the observability architecture, see: Observability for Agentic AI in Healthcare.
Level 4 to Level 5: Orchestrate (24-36 Months)
Build a multi-agent orchestration platform with inter-agent communication, shared state management, and conflict resolution. Start with a single cross-departmental workflow (discharge management is the most common candidate). Define cross-agent governance and establish an enterprise AI governance board with C-suite representation.
Critical success factor: Organizational alignment. The technology is the easier part; cross-departmental change management is the harder part. Start with governance before you start building.
Frequently Asked Questions
How long does it take to move from Level 1 to Level 3?
For a well-resourced health system with strong IT infrastructure and executive sponsorship, 18-24 months is realistic. The bottleneck is rarely the AI technology—it is the interoperability infrastructure (FHIR APIs, CDS Hooks), governance framework, and clinical change management. Organizations that underinvest in these foundations take 36+ months and often stall at Level 2.
What is the ROI difference between Level 1 and Level 3?
Level 1 delivers ROI through clinician time savings—typically $50,000-$150,000 per physician per year. Level 3 delivers ROI through operational cost reduction: a prior authorization agent saving $30-50 per transaction across 200,000 annual transactions yields $6-10 million in annual savings from a single use case. Level 3 ROI is larger in magnitude and more directly measurable.
Do we need to build or buy agent capabilities?
Hybrid. The ambient layer (Level 1) is almost always purchased. The agent layer (Level 3+) requires custom development because agents need deep integration with your specific workflows, EHR configurations, and clinical protocols. Buy the LLM and transcription engine; build the agent logic connecting AI to your workflows through your FHIR APIs. A systems integrator with deep FHIR and healthcare AI expertise can accelerate this significantly.
What are the biggest risks of deploying autonomous agents (Level 4)?
Three risks dominate. Clinical safety: an autonomous agent acting without human review can harm patients—mitigated by bounded authority and monitoring. Regulatory risk: the FDA's March 2026 draft guidelines signal increasing scrutiny of AI taking clinical actions. Liability: when an autonomous agent errs, the legal framework is still evolving. Work with legal counsel and malpractice insurers early.
How does FHIR fit into the maturity ladder?
FHIR enables Levels 2 through 5. Level 1 needs only audio input. Level 2 needs FHIR read APIs. Level 3 needs FHIR write APIs plus CDS Hooks. Level 4 needs the full FHIR API surface with authorization scoping. Level 5 needs enterprise FHIR infrastructure with event streaming. Organizations that neglect FHIR will find it the single biggest blocker to advancing beyond Level 1.
Is Level 5 realistic, or is it science fiction?
Level 5 is real but distant. The components exist (LangGraph, AutoGen, CrewAI, specialized healthcare models), but no hospital runs a fully orchestrated multi-agent system in production today. The realistic timeline for early Level 5 deployments is 2028-2030. The organizations that will get there first are building their Level 3 and Level 4 capabilities now.
The Strategic Imperative: Start Climbing Now
The gap between where most health systems are (Level 1) and where the industry is heading (Levels 3-4) is not closing on its own. The 3% of organizations that have deployed agentic AI in live workflows are building institutional knowledge, governance frameworks, and technical infrastructure that will compound over time. The longer you wait to start the climb, the wider the gap becomes.
Three things are clear from the data:
- Ambient AI is table stakes, not competitive advantage. When 62.6% of Epic hospitals have ambient tools, deploying an ambient scribe is no longer a differentiator. It is a prerequisite.
- The agent transition is happening faster than predicted. Hippocratic AI's $1.64 billion valuation, Color Health's partnership with Google, and the $600M+ in funding flowing to agent-level companies in 2025-2026 signal that the market has moved past the "should we do agents?" question to "how fast can we deploy agents?"
- Governance is the gating factor, not technology. Wolters Kluwer is right: 2026 is the year of governance. The organizations that build robust AI governance frameworks now—before they need them for autonomous agents—will be able to deploy faster and with less risk when they are ready for Level 4.
The question is not whether AI agents will transform healthcare operations. The direction of travel is unmistakable. The question is whether your organization will be leading that transformation—or scrambling to catch up.
Nirmitee builds the FHIR interoperability layer and agentic AI infrastructure that health systems need to move from Level 1 to Level 3 and beyond. If you are ready to assess your maturity level and build a concrete climbing plan, let's talk.
Related reading
For more insights, explore our guides on what AI agents do in healthcare and FHIR in Modern Healthcare.
You may also find value in EHR Software Development Guide and Building a Healthtech App.