Every healthcare AI company wants to be the next Abridge. Every health system CIO is fielding pitches from vendors promising ambient documentation, automated prior authorization, and AI-powered clinical decision support. None of them want to talk about their FHIR infrastructure. That is why most of them fail.
The uncomfortable truth in healthcare AI is that the models are not the bottleneck. GPT-4, Claude, Gemini, Med-PaLM -- they can all reason over clinical data with impressive accuracy when the data is clean, structured, and accessible. The bottleneck is that clinical data is almost never clean, structured, or accessible. It is trapped in EHR silos, encoded in dozens of incompatible formats, and locked behind authentication systems that were never designed for autonomous agents.
This is the FHIR-first thesis: your healthcare AI strategy will only scale as far as your interoperability infrastructure allows. The organizations that invest in FHIR R4 as their canonical data layer -- not as an afterthought, but as the foundation -- will be the ones that ship production AI. For teams with legacy EHR systems, deploying a FHIR Facade layer is the pragmatic first step: expose a standards-compliant FHIR API surface without ripping out existing systems. Everyone else will spend millions on model fine-tuning and prompt engineering only to watch their AI hallucinate over garbage data.
The Data Readiness Crisis: Why AI Models Starve in Healthcare
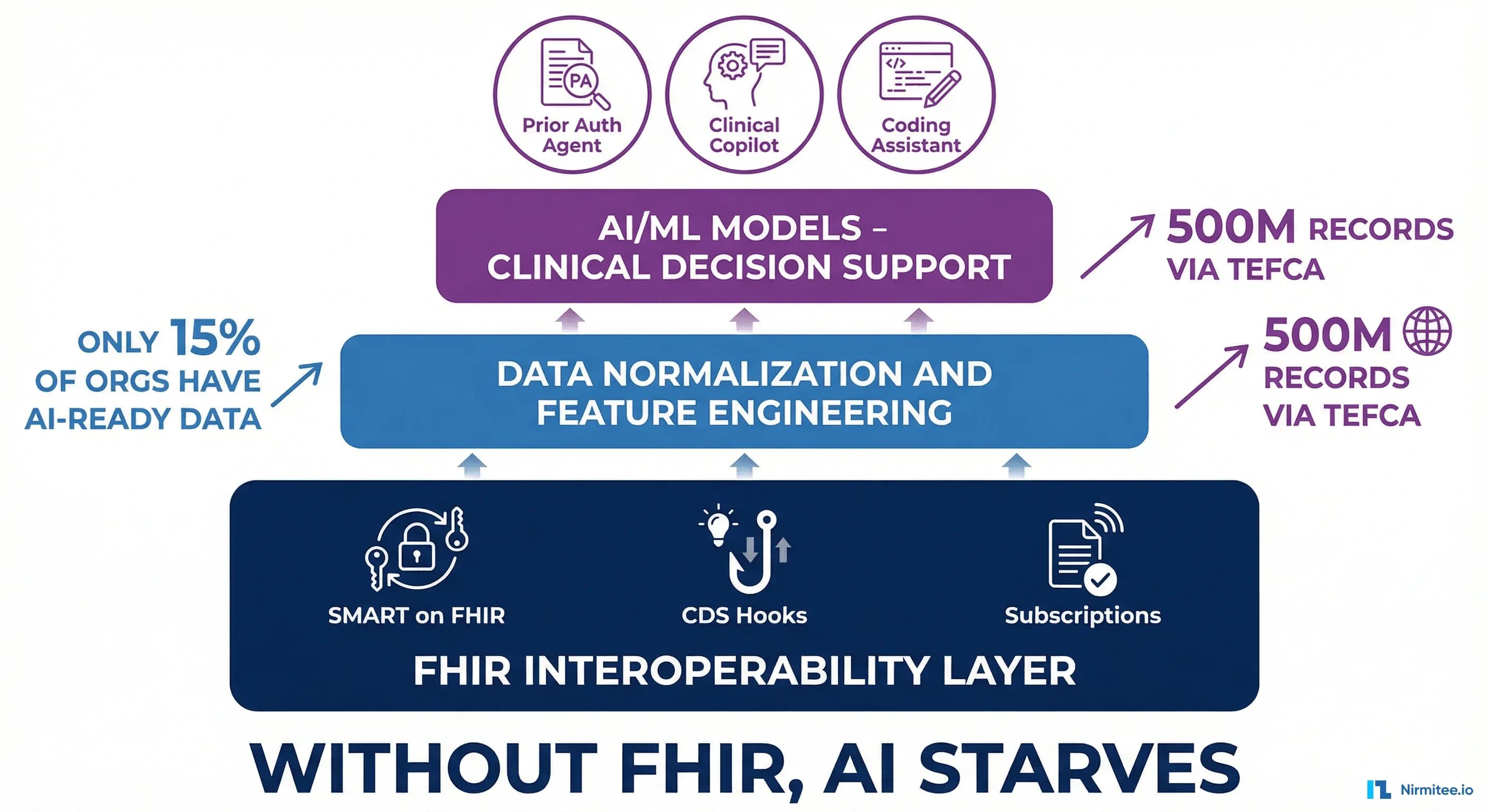
The numbers are stark. According to a BCG analysis, only 3% of healthcare organizations have agentic AI in production, and data readiness is the number one blocker. A separate industry survey found that only 15% of healthcare organizations report their data as fully AI-ready. Not model-ready. Not experiment-ready. Production-ready -- meaning the data is structured, normalized, deduplicated, and accessible through standard APIs at the latency AI workloads require.
That 85% gap is not a model problem. It is a plumbing problem.
Consider what a typical health system's data landscape looks like today:
- EHR data in Epic, Cerner, or MEDITECH -- accessible via proprietary APIs, some FHIR R4 endpoints, and bulk export in varying degrees of completeness
- Lab results coming in as HL7v2 ORU messages from reference labs, with different coding systems (LOINC, local codes, free-text descriptions)
- Claims data in X12 837/835 EDI formats, often stored in data warehouses with schema drift
- Clinical notes as unstructured free text, sometimes in C-CDA documents that embed the narrative in XML blobs, sometimes as PDFs scanned from faxes
- Imaging data in DICOM, with reports as free text or semi-structured SR documents
- Patient-generated data from wearables and remote monitoring devices in proprietary vendor formats
An AI model tasked with something as simple as "determine if this patient is due for a diabetic eye exam" needs to reason across the patient's problem list, medication history, last ophthalmology encounter, and insurance coverage. In a typical health system, that data lives in four different systems, three different formats, and requires two different authentication mechanisms to access. This is the environment most healthcare AI products are built against -- and it is why practitioners observe that "FHIR data is all over the place" and doubt whether "these AI companies have the proper registries to effectively translate this."
The healthcare interoperability solutions market reflects the urgency of this problem: valued at $5.8 billion in 2025 and projected to reach $14 billion by 2032, the infrastructure layer is growing faster than the AI application layer itself. The market is telling us what practitioners already know -- interoperability infrastructure is the prerequisite, not the byproduct, of healthcare AI.
FHIR as the AI Data Layer
FHIR R4 was not designed for AI. It was designed for interoperability -- to give clinical data a common structure, a common vocabulary, and a common API. But those same properties make it the ideal substrate for AI workloads. Here is why.
Typed and Validated Resources
Every FHIR resource has a defined schema. A Patient resource always has a structure for name, birthDate, identifier, and contact information. A Condition resource always has a code (typically SNOMED CT or ICD-10), a clinicalStatus, and a subject reference. An Observation always has a code, a value, and an effectiveDateTime. This is not optional -- FHIR servers validate against these schemas.
For AI, this means the model receives data in a predictable structure every time. No parsing heuristics. No regex to extract a blood pressure from a free-text note. The systolic value is always at Observation.component[0].valueQuantity.value with a unit of mm[Hg].
Cross-Referenced via Resource Links
FHIR resources reference each other through explicit links. A MedicationRequest references the Patient, the prescribing Practitioner, the Encounter where it was ordered, and the Medication resource with the drug details. An AI agent can traverse these references to build a complete clinical picture without joining tables or guessing at foreign keys.
Terminology-Bound
FHIR resources bind to standard terminologies: SNOMED CT for clinical findings, LOINC for lab observations, RxNorm for medications, ICD-10-CM for diagnoses. When an AI model sees "code": {"coding": [{"system": "http://loinc.org", "code": "2339-0", "display": "Glucose [Mass/volume] in Blood"}]}, it can unambiguously identify this as a blood glucose measurement -- not a glucose tolerance test, not a urine glucose, not a note that mentions glucose.
The Format Comparison AI Engineers Need to Understand
The difference in AI utility across data formats is dramatic:
| Dimension | AI over FHIR Bundle | AI over C-CDA XML | AI over Free Text |
|---|---|---|---|
| Data extraction | Deterministic JSON path traversal | XPath with template-specific parsing | NLP/LLM extraction with error rates |
| Accuracy | 98%+ (schema-validated) | 75-85% (template variation) | 60-80% (context-dependent) |
| Audit trail | Full: resource ID, version, lastUpdated | Partial: document-level only | None: no provenance metadata |
| Reproducibility | 100%: same input, same output | Variable: parser-dependent | Non-deterministic: model-dependent |
| Terminology | Bound to SNOMED/LOINC/RxNorm | Often present but inconsistent | Absent: requires entity linking |
| Cross-referencing | Native resource references | Internal document IDs | Manual co-reference resolution |
| Real-time access | RESTful API with search | Document exchange (batch) | Chart review (manual) |
The conclusion is straightforward: AI that reasons over FHIR Bundles produces deterministic, auditable, reproducible outputs. AI that reasons over free text produces probabilistic, opaque, non-reproducible outputs. For clinical applications where a wrong answer can harm a patient, this distinction is not academic -- it is the difference between a product that clears regulatory review and one that does not. For a deeper look at building AI pipelines against FHIR data, see our FHIR AI/ML data pipeline guide.
The Three FHIR Integration Points for AI
FHIR provides three standardized mechanisms for AI systems to interact with clinical data. Each serves a different purpose, and a production AI architecture typically uses all three.
SMART on FHIR: How AI Agents Authenticate and Access Patient Data
SMART on FHIR is the OAuth 2.0-based authorization framework that governs how applications -- including AI agents -- access clinical data. When an AI agent needs to read a patient's medication list or write back a clinical recommendation, it authenticates through SMART on FHIR.
The critical concept for AI is scoped access. A SMART token does not grant blanket access to the EHR. It grants specific permissions on specific resource types for a specific patient or context. Here is what a token scope looks like for an AI prior authorization agent:
// SMART on FHIR token scopes for a prior auth AI agent
scope: "launch/patient
patient/Patient.read
patient/Coverage.read
patient/CoverageEligibilityRequest.read
patient/CoverageEligibilityResponse.write
patient/Condition.read
patient/Procedure.read
patient/MedicationRequest.read
patient/Task.write
patient/ClaimResponse.write"
// The token also includes:
// - patient: "Patient/patient-123" (context: which patient)
// - iss: "https://ehr.example.org/fhir" (which FHIR server)
// - exp: 1712345678 (expiry: short-lived)
This scoping model is essential for AI governance. The AI agent can only access the resource types it needs, only for the patient in context, and only for a limited time. If the agent is compromised, the blast radius is contained. Compare this to an AI system that connects directly to the EHR database -- a single SQL injection gives it access to every patient record in the system.
For a comprehensive guide to building AI agents that read and write clinical data via FHIR, including authentication patterns for autonomous and human-in-the-loop workflows, we have covered this in depth.
CDS Hooks: How AI Gets Triggered at the Point of Clinical Decision
CDS Hooks is the HL7 standard for invoking external decision support services from within the EHR workflow. When a clinician opens a patient chart, orders a medication, or signs a note, the EHR fires a hook to registered CDS services -- including AI-powered ones.
Here is a real-world example: an AI service that checks formulary coverage when a clinician orders a medication.
Hook trigger (EHR sends to AI service):
{
"hookInstance": "d1577c69-dfbe-44ad-ba6d-3e05e953b2ea",
"hook": "order-select",
"context": {
"userId": "Practitioner/dr-smith-456",
"patientId": "Patient/patient-123",
"selections": ["MedicationRequest/pending-rx-789"],
"draftOrders": {
"resourceType": "Bundle",
"entry": [
{
"resource": {
"resourceType": "MedicationRequest",
"id": "pending-rx-789",
"status": "draft",
"intent": "order",
"medicationCodeableConcept": {
"coding": [
{
"system": "http://www.nlm.nih.gov/research/umls/rxnorm",
"code": "861004",
"display": "Metformin 500 MG Oral Tablet"
}
]
},
"subject": { "reference": "Patient/patient-123" }
}
}
]
}
},
"prefetch": {
"patient": {
"resourceType": "Patient",
"id": "patient-123",
"name": [{ "given": ["Jane"], "family": "Doe" }]
},
"coverage": {
"resourceType": "Coverage",
"id": "coverage-456",
"payor": [{ "reference": "Organization/aetna" }],
"class": [
{
"type": { "coding": [{ "code": "plan" }] },
"value": "PPO-Gold-2025"
}
]
}
}
}
AI service response (returned to EHR):
{
"cards": [
{
"uuid": "card-formulary-001",
"summary": "Metformin 500mg is Tier 1 on patient's Aetna PPO Gold plan",
"detail": "No prior authorization required. $5 copay at in-network pharmacy. Generic formulary preferred.",
"indicator": "info",
"source": {
"label": "Nirmitee Formulary AI",
"url": "https://nirmitee.io/cds/formulary",
"topic": {
"coding": [
{
"system": "http://loinc.org",
"code": "52017-7",
"display": "Drug formulary status"
}
]
}
},
"suggestions": [
{
"label": "Accept: Metformin 500mg (Tier 1, $5 copay)",
"isRecommended": true,
"actions": [
{
"type": "update",
"description": "Confirm medication order",
"resource": {
"resourceType": "MedicationRequest",
"id": "pending-rx-789",
"status": "active"
}
}
]
}
]
}
]
}
The power of CDS Hooks for AI is the context injection. The EHR sends the AI service exactly the data it needs -- the draft order, the patient context, the coverage information -- via the prefetch template. The AI does not need to make additional API calls or navigate the EHR. It reasons over the provided FHIR resources and returns a structured card with actionable suggestions. For more on integrating AI agents into clinical workflows via CDS Hooks and SMART launch, see our technical guide on AI-EHR connection patterns.
FHIR Subscriptions: How AI Monitors for Real-Time Events
FHIR R4 introduced topic-based Subscriptions (backported from R5) that allow AI systems to receive real-time notifications when clinical events occur. Instead of polling the FHIR server every few seconds asking "any new lab results?", the AI service registers a subscription and gets notified the moment a relevant resource is created or updated.
Subscription registration (AI service registers with FHIR server):
{
"resourceType": "Subscription",
"status": "requested",
"reason": "AI sepsis surveillance — monitor for critical lab results",
"criteria": "Observation?category=laboratory&code=http://loinc.org|26464-8,http://loinc.org|6690-2,http://loinc.org|2532-0",
"channel": {
"type": "rest-hook",
"endpoint": "https://ai.nirmitee.io/fhir/subscription/sepsis-watch",
"payload": "application/fhir+json",
"header": [
"Authorization: Bearer eyJhbGciOiJSUzI1NiIs..."
]
}
}
Notification payload (FHIR server sends to AI service when a matching Observation is created):
{
"resourceType": "Bundle",
"type": "history",
"entry": [
{
"resource": {
"resourceType": "Observation",
"id": "lab-result-wbc-99012",
"status": "final",
"category": [
{
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "laboratory"
}
]
}
],
"code": {
"coding": [
{
"system": "http://loinc.org",
"code": "6690-2",
"display": "Leukocytes [#/volume] in Blood by Automated count"
}
]
},
"subject": { "reference": "Patient/patient-456" },
"effectiveDateTime": "2026-04-02T14:30:00Z",
"valueQuantity": {
"value": 18.5,
"unit": "10*3/uL",
"system": "http://unitsofmeasure.org",
"code": "10*3/uL"
},
"interpretation": [
{
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v3-ObservationInterpretation",
"code": "HH",
"display": "Critical high"
}
]
}
]
}
}
]
}
The AI sepsis surveillance system receives this notification, sees a critically elevated WBC count (18.5 x 10^3/uL, flagged HH), and can immediately query for additional context -- recent vital signs, blood cultures, lactate levels -- to compute a sepsis risk score. This is event-driven AI, not batch AI. The clinical value of a sepsis alert that fires within 30 seconds of a critical lab result versus one that fires on a nightly batch run is the difference between early intervention and a code blue.
Architecture Pattern: The FHIR-First AI Pipeline
Putting SMART on FHIR, CDS Hooks, and Subscriptions together, here is the end-to-end architecture for a FHIR-first AI system:
- FHIR Server (Source of Truth) -- The EHR's FHIR R4 endpoint (Epic, Cerner, or a standalone HAPI FHIR server) serves as the canonical data source. All clinical data is accessible as typed FHIR resources via RESTful API.
- Event Detection -- FHIR Subscriptions notify the AI pipeline when relevant clinical events occur (new lab result, medication order, encounter admission). This replaces polling and batch ETL.
- Data Normalization -- Incoming FHIR resources are normalized: local codes are mapped to standard terminologies (SNOMED CT, LOINC, RxNorm), missing references are resolved, and data quality checks are applied. This is where you handle the "FHIR data is all over the place" problem -- not in the model, but in the data layer.
- Feature Engineering -- Normalized FHIR resources are traversed to extract features. A sepsis model might extract: WBC count from
Observation, temperature fromObservation, heart rate fromObservation, active antibiotic orders fromMedicationRequest, and recent blood culture status fromDiagnosticReport. Because these are typed FHIR resources, feature extraction is deterministic code, not NLP. - Model Inference -- Features are passed to the AI model (hosted on-premises, in a VPC, or via a privacy-preserving API). The model returns a prediction, classification, or recommendation.
- CDS Hook Response / FHIR Write-back -- The model output is translated back into FHIR. For inline decision support, this is a CDS Hooks card returned to the EHR. For asynchronous workflows, this is a FHIR
Task,Flag, orCommunicationRequestwritten back to the FHIR server. The audit trail is complete: every AI output is a FHIR resource with provenance, timestamp, and the input data it was derived from.
This architecture is fundamentally different from the pattern most healthcare AI companies use today, which is: extract data from the EHR via custom integrations, transform it into a proprietary format, run the model, and push results back via a sidebar app or a PDF. The FHIR-first pattern is standards-based at every layer, which means it works across EHR vendors, survives vendor switching, and satisfies the regulatory requirements coming with HTI-5.
Case Study: Prior Authorization Agent on FHIR
Prior authorization is the highest-value use case for healthcare AI today -- it consumes an estimated $35 billion annually in administrative costs across the US healthcare system. Here is how a FHIR-first prior authorization agent works, step by step.
Step 1: CDS Hook Trigger
A clinician orders an MRI of the lumbar spine for a patient with chronic lower back pain. The EHR fires an order-sign CDS Hook to the prior authorization AI service, including the draft ServiceRequest (CPT 72148), the patient's Coverage, and relevant Condition resources.
Step 2: Clinical Context Gathering
The AI agent, authenticated via SMART on FHIR with scoped access, queries the FHIR server for additional context:
Condition?patient=Patient/123&code=http://snomed.info/sct|279039007-- low back pain historyProcedure?patient=Patient/123&code=http://www.ama-assn.org/go/cpt|97110-- prior physical therapy sessionsDiagnosticReport?patient=Patient/123&category=imaging-- prior imaging studiesMedicationRequest?patient=Patient/123&status=active-- current medications (conservative treatment evidence)
Step 3: Payer Rule Evaluation
The agent matches the gathered clinical data against the payer's coverage rules. For Aetna's lumbar MRI policy, the typical requirements are: (a) documented failure of 6 weeks of conservative therapy, (b) no MRI in the past 12 months, (c) clinical indication beyond "low back pain" (red flag symptoms, radiculopathy, or neurological deficit). The agent evaluates each criterion against the FHIR data:
- Physical therapy
Procedureresources show 8 sessions over 8 weeks -- criterion (a) met - No
DiagnosticReportwith imaging category in the past 12 months -- criterion (b) met Conditionresources include SNOMED code 128196005 (lumbar radiculopathy) -- criterion (c) met
Step 4: FHIR Write-back
The agent writes a CoverageEligibilityResponse back to the FHIR server documenting the determination, and creates a Task resource for tracking:
{
"resourceType": "CoverageEligibilityResponse",
"status": "active",
"purpose": ["auth-requirements"],
"patient": { "reference": "Patient/patient-123" },
"created": "2026-04-02T10:30:00Z",
"insurer": { "reference": "Organization/aetna" },
"insurance": [
{
"coverage": { "reference": "Coverage/coverage-456" },
"item": [
{
"category": {
"coding": [
{
"system": "http://www.ama-assn.org/go/cpt",
"code": "72148",
"display": "MRI lumbar spine without contrast"
}
]
},
"benefit": [
{
"type": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/benefit-type",
"code": "preauth-approved"
}
]
}
}
],
"authorizationRequired": true,
"authorizationUrl": "https://payer.example.org/auth/ref/PA-2026-04-78901"
}
]
}
]
}
Step 5: CDS Card Response
The agent returns a CDS Hook card to the clinician: "Prior auth approved for MRI lumbar spine (CPT 72148). Auth reference: PA-2026-04-78901. Criteria met: 8 weeks conservative therapy documented, no prior imaging in 12 months, radiculopathy diagnosis confirmed." The clinician sees this inline in their ordering workflow, with no phone calls, no fax, no waiting.
The entire process -- from order to approval -- takes under 3 seconds. Every data point the agent used is a FHIR resource with a provenance trail. Every decision criterion is auditable. This is what FHIR-first AI looks like in production.
TEFCA + FHIR: The National Data Network AI Has Been Waiting For
In January 2025, the Trusted Exchange Framework and Common Agreement (TEFCA) network had exchanged approximately 10 million health records. By early 2026, that number reached nearly 500 million health records exchanged -- a 50x increase in roughly one year. TEFCA is quietly building the national health data network that AI has been waiting for.
Here is why TEFCA matters for healthcare AI:
- Cross-organizational data access -- An AI agent at Hospital A can query for a patient's records at Hospital B, Lab C, and Payer D through the TEFCA network. The data comes back as FHIR resources through Qualified Health Information Networks (QHINs). This solves the "data trapped in silos" problem at a national scale.
- Standardized query framework -- TEFCA defines standard query types (individual access, population-level, treatment, payment, operations) with consistent semantics. AI systems do not need custom integrations with each data source.
- Trust framework -- TEFCA provides the legal and technical trust framework for data exchange. When an AI agent requests data through TEFCA, the identity verification, consent management, and permitted uses are handled by the framework.
The HTI-5 proposed rule from ONC reinforces this direction by proposing to remove C-CDA as a required exchange format and mandate FHIR-first. This is a watershed moment: the federal government is signaling that the future of health data exchange is FHIR, period. Organizations still building AI pipelines against C-CDA documents are building against a format that the government is actively moving away from. For a detailed technical breakdown of TEFCA's architecture and what it means for healthcare developers, see our TEFCA developer guide.
Meanwhile, Epic has reported that 62.6% of US hospitals on their platform have adopted ambient AI tools (primarily for clinical documentation). But ambient AI -- transcribing a conversation into a note -- is the easy part. The hard part is what comes after: structuring that note into coded FHIR resources, reconciling it with existing patient data, and making it available for downstream AI systems to reason over. The ambient-to-structured pipeline is where FHIR infrastructure becomes essential.
What "FHIR-First" Means Operationally
Saying "we use FHIR" is not the same as being FHIR-first. Most health systems today use FHIR as an export format -- they store data in proprietary EHR databases and expose a FHIR API as a compliance requirement. FHIR-first means something fundamentally different:
1. Store Clinical Data as FHIR Resources
Instead of storing data in proprietary schemas and converting to FHIR on demand, store the canonical representation as FHIR resources. This means your AI systems read the same data structure that external partners see, eliminating the "internal data looks different from API data" problem that breaks most healthcare AI integrations. Tools like Google Cloud Healthcare API provide managed FHIR stores that make this operationally feasible.
2. Use FHIR Subscriptions for Event-Driven Processing
Replace batch ETL jobs with FHIR Subscriptions. Instead of running a nightly job that pulls all new lab results into your AI pipeline, subscribe to the specific observation codes your models need. This reduces latency from hours to seconds and eliminates the "stale data" problem that plagues batch-oriented AI systems.
3. Expose CDS Hooks for Inline AI
Every AI capability that delivers value at the point of care should be exposed as a CDS Hook. This is not optional -- it is how you get AI recommendations in front of clinicians without requiring them to open a separate application, log into a different system, or change their workflow.
4. Build AI Features Against FHIR APIs, Not Database Queries
This is the most counterintuitive principle for engineering teams. When building an AI feature, the instinct is to write SQL queries against the data warehouse for maximum performance. The FHIR-first approach says: build against the FHIR API. Yes, it is slower. Yes, you lose some query flexibility. But you gain portability (your AI works across any FHIR-compliant system), auditability (every data access is logged through the FHIR server), and compliance (you inherit the FHIR server's access controls).
5. Govern AI Data Access Through SMART Scopes
Every AI agent, every model, every pipeline gets a SMART on FHIR client registration with minimum-necessary scopes. No AI system gets blanket database access. This is not just good security practice -- it is becoming a regulatory requirement under the proposed HTI-5 rule and aligns with emerging healthcare data governance frameworks that require granular access control for AI systems operating on PHI.
The Interoperability Maturity Model for AI Readiness
Not every organization can go FHIR-first overnight. Here is a five-level maturity model that maps interoperability capability to AI readiness:
| Level | Name | Interoperability Capabilities | AI Capabilities Unlocked |
|---|---|---|---|
| 1 | Siloed | Data locked in EHR. Manual CSV/PDF exports. No APIs. Custom point-to-point interfaces for specific use cases. | None. AI requires manual data preparation for each project. No automation possible. Any AI initiative is a one-off consulting engagement. |
| 2 | Connected | HL7v2 ADT/ORU/ORM interfaces. C-CDA document exchange via Direct or HIE. Basic patient matching. Mirth/Rhapsody integration engine. | Batch analytics on structured HL7v2 fields (demographics, lab results). NLP on C-CDA narratives. Accuracy limited by format inconsistency. No real-time AI. |
| 3 | FHIR-Enabled | FHIR R4 API enabled (often read-only via EHR vendor). Patient Access API compliant. Bulk FHIR export available. Limited search parameters supported. | AI can read patient data via API. Population health analytics via Bulk FHIR. Model training on structured FHIR resources. Still requires batch processing; no event-driven triggers. |
| 4 | FHIR-Integrated | SMART on FHIR for app authorization. CDS Hooks registered for clinical workflows. FHIR Subscriptions for event notification. Read and write access. TEFCA participation. | Real-time clinical decision support via CDS Hooks. AI agents with scoped, auditable data access. Event-driven AI pipelines. Cross-organizational data access for AI via TEFCA. Human-in-the-loop AI workflows. |
| 5 | FHIR-Native AI Platform | FHIR as the canonical data store. All clinical data stored as FHIR resources. Full Subscription topic catalog. CDS Hook library for all major workflows. AI-generated resources written back with provenance. SMART scopes govern all AI access. | Autonomous AI agents operating within FHIR governance. Full audit trail from data ingestion to AI output. Portable AI -- models work across any FHIR-compliant system. Closed-loop AI: observe → reason → act → observe. Regulatory-ready AI with complete data lineage. |
Most US health systems today are at Level 2 or 3. The 62.6% of Epic hospitals using ambient AI are effectively operating at Level 3 -- they can read FHIR data, but AI capabilities are limited to documentation assistance and basic alerting. The leap from Level 3 to Level 4 is where the transformative AI use cases unlock: real-time clinical decision support, autonomous prior authorization, AI-powered care gap detection, and predictive deterioration monitoring.
The organizations that reach Level 5 will have a structural advantage that is extremely difficult for competitors to replicate. FHIR-native AI is not a feature -- it is a platform capability that compounds over time as more AI models are deployed against the same data infrastructure.
Handling Unstructured Data in a FHIR-First World
A common objection to the FHIR-first approach is: "But most clinical data is unstructured. Clinical notes, pathology reports, radiology reads -- they are all free text. FHIR does not help with that."
This objection misunderstands the architecture. FHIR-first does not mean ignoring unstructured data. It means structuring it on the way in. The pipeline is:
- Ingest the unstructured document (clinical note, PDF, scanned image)
- Extract structured data using NLP/LLM (diagnoses, medications, procedures, lab values)
- Encode the extracted data as FHIR resources with appropriate terminology bindings
- Store both the original document (as a FHIR
DocumentReference) and the extracted structured resources - Downstream AI reasons over the structured FHIR resources, not the original free text
This is the pattern used by companies like Abridge and Nuance DAX -- ambient AI captures the conversation, but the output is structured FHIR resources (Conditions, MedicationRequests, Procedures) that flow into the EHR's data model. The AI that does the structuring is different from the AI that reasons over the structured data. For a detailed guide to building the unstructured-to-FHIR pipeline for clinical notes and PDFs, we have published a comprehensive technical walkthrough.
The Bottom Line: FHIR Investment Is AI Investment
The healthcare industry will spend billions on AI over the next five years. Most of that spending will be wasted -- not because the models are bad, but because the data infrastructure cannot support them. The organizations that invest in FHIR interoperability infrastructure today are not making a separate investment from their AI strategy. They are making the foundational investment that determines whether their AI strategy succeeds or fails.
The evidence is clear:
- 85% of organizations lack AI-ready data -- the gap is infrastructure, not models
- Only 3% have agentic AI in production -- data readiness is the primary blocker
- 500 million records are flowing through TEFCA -- the national FHIR network is operational
- HTI-5 is mandating FHIR-first -- the regulatory direction is unambiguous
- $14 billion interoperability market by 2032 -- the infrastructure investment is accelerating
FHIR-first is not a technical preference. It is a strategic position. The organizations that build their AI on FHIR will compound their capabilities. The organizations that build AI on custom integrations will rebuild from scratch with every new use case.
At Nirmitee, we build FHIR interoperability infrastructure that makes healthcare AI possible -- from SMART on FHIR authentication to CDS Hooks integration to FHIR-native data pipelines. If your organization is ready to move from AI experiments to AI production, the conversation starts with your FHIR foundation.
Talk to our FHIR interoperability team about building the data infrastructure your AI strategy requires.