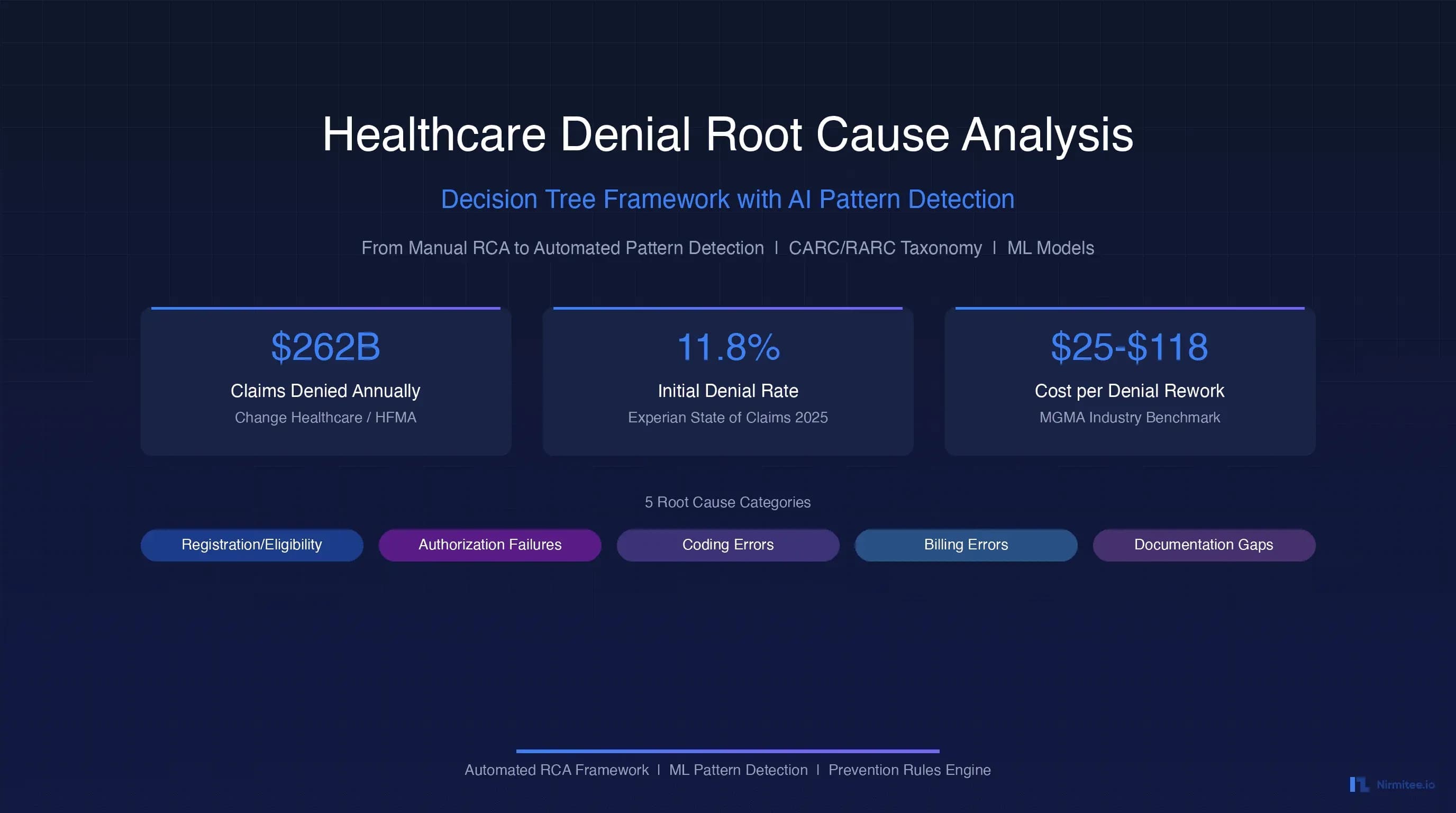
Healthcare claim denials represent one of the most persistent and financially devastating challenges in the revenue cycle. According to Change Healthcare analysis, $262 billion in medical claims are initially denied every year, forcing providers to spend an average of $25 to $118 per claim on rework and appeals. The Experian State of Claims 2025 report shows initial denial rates have climbed to 11.8%, up from 10.2% just a few years earlier. Yet most healthcare organizations still rely on manual root cause analysis (RCA) processes that cannot keep pace with the volume, complexity, or pattern-driven nature of modern denials.
See how this plays out in a real project: Healthcare Fraud Detection Case Study: ML & Graph AI.
Related Reading
For more insights, explore our guides on Healthcare Denial Trends 2026: Data & AI Playbook and FHIR in Modern Healthcare.
You may also find value in EHR Software Development Guide and Building a Healthtech App.
This guide presents a comprehensive, automated RCA framework that replaces ad-hoc manual review with structured decision tree classification, CARC/RARC code taxonomy mapping, and machine learning-powered pattern detection. If you have read our analysis of the $262 billion denial crisis and AI denial management architecture, this article extends that foundation with the specific RCA methodology and ML implementation details your team needs to build an automated denial prevention system.
Why Manual Root Cause Analysis Fails at Scale
Manual RCA was adequate when denial volumes were manageable and patterns were straightforward. Today, three fundamental challenges make manual approaches unsustainable:
Volume Overwhelm
A mid-size health system processing 500,000 claims annually with an 8% denial rate generates 40,000 denials per year, or roughly 770 per week. Manual review of each denial, including code lookup, root cause determination, and action assignment, takes an experienced analyst 8 to 15 minutes per denial. At that rate, a single analyst can process 32 to 60 denials per day, meaning a team of 3 full-time analysts can only review a fraction of incoming denials with the depth needed for meaningful pattern identification.
Pattern Complexity
Modern denials are rarely caused by a single isolated factor. A claim denied with CARC CO-16 (lacks information or medical necessity) may reflect a coding error, a documentation gap, a payer policy change, or a combination of all three. Manual analysts working in silos cannot reliably detect multi-factor patterns, payer-specific behavioral shifts, or temporal trends that emerge only when thousands of denials are analyzed in aggregate.
Inconsistent Classification
Without a standardized taxonomy and decision framework, different analysts classify the same denial differently. One analyst may tag a CO-27 denial (expenses not covered by this payer) as an eligibility issue, while another tags it as a billing error because the wrong payer ID was submitted. This inconsistency makes trend analysis unreliable and prevents the organization from accurately measuring improvement in specific root cause categories.
The solution is a structured, automated RCA pipeline that standardizes classification, scales to any volume, and feeds machine learning models that detect patterns humans cannot see.
Denial Code Taxonomy: CARC and RARC Code Organization
Effective automated RCA begins with a well-organized denial code taxonomy. The healthcare industry uses two standardized code systems that together provide the complete picture of why a claim was denied or adjusted:
CARC: Claim Adjustment Reason Codes
CARCs are the primary denial reason codes defined under the ANSI X12 835 standard. Each CARC consists of a two-letter group code prefix and a numeric identifier. The group code prefixes are:
- CO (Contractual Obligation): Adjustment based on the provider's contractual agreement with the payer. The provider may not bill the patient for this amount.
- PR (Patient Responsibility): The patient is responsible for the adjusted amount (deductible, copay, coinsurance).
- PI (Payer Initiated): Payer-initiated reductions not based on contractual obligation or patient responsibility.
- OA (Other Adjustment): Adjustment reason does not fit the other categories.
RARC: Remittance Advice Remark Codes
RARCs provide additional context for the adjustment beyond what the CARC conveys. They are alphanumeric codes with prefixes indicating their category:
- N codes: Not covered or non-payment reasons
- M codes: Missing or invalid information
- MA codes: Missing additional information needed for adjudication
Together, a CARC+RARC combination tells you both the reason for the denial (CARC) and the specific context or action needed (RARC). For example, CARC CO-16 paired with RARC MA-130 means the claim was denied for insufficient information and specifically requires medical records to support medical necessity.
Root Cause Taxonomy Mapping
The key to automated RCA is mapping every CARC/RARC combination to one of five root cause categories. This mapping forms the foundation of both the decision tree classifier and the ML training data. Here is the mapping structure for the most common denial codes:
| Root Cause Category | Primary CARCs | Common RARCs | % of Total Denials |
|---|---|---|---|
| Registration and Eligibility | CO-4, CO-27, CO-197, CO-204, CO-31 | N-30, N-95, MA-114 | 24% |
| Authorization Failures | CO-15, CO-197, CO-198, CO-227 | N-386, N-657, MA-66 | 19% |
| Coding Errors | CO-4, CO-11, CO-97, CO-16, CO-151 | N-95, N-386, M-76 | 26% |
| Billing Errors | CO-18, CO-29, CO-252, CO-170, CO-242 | N-362, N-620, MA-130 | 18% |
| Documentation Gaps | CO-16, CO-50, CO-167, CO-243 | MA-130, N-115, M-76 | 13% |
Note that some CARC codes appear in multiple categories. CO-16 (lacks information), for example, can indicate a coding error, a documentation gap, or a medical necessity issue depending on the accompanying RARC and claim context. This ambiguity is precisely why a decision tree framework is necessary rather than simple code-to-category lookup.
The Decision Tree Framework
The decision tree framework provides a systematic, repeatable classification process that moves from denial receipt through code parsing, category assignment, root cause identification, and corrective action. Unlike a simple lookup table, the decision tree handles ambiguous codes by incorporating contextual signals from the claim header, provider metadata, and payer-specific rules.
Stage 1: Denial Receipt and Code Extraction
When an 835 ERA (Electronic Remittance Advice) or paper EOB arrives, the system extracts the CARC and RARC codes, group code prefix, claim adjustment amounts, and claim-level metadata including the payer ID, procedure codes, provider NPI, date of service, and place of service. This extraction is the data ingestion step that feeds the decision tree.
Stage 2: Primary Classification by CARC
The first decision node uses the CARC code to make an initial category assignment. Codes with unambiguous mappings (like CO-18 for duplicates or CO-29 for timely filing) are routed directly to their root cause category. Ambiguous codes like CO-16 or CO-4 proceed to the next decision node for RARC-based disambiguation.
Stage 3: RARC Disambiguation
For ambiguous CARCs, the RARC code resolves the root cause. CO-16 with RARC MA-130 (medical records requested) routes to Documentation Gaps. CO-16 with RARC N-386 (requires authorization information) routes to Authorization Failures. CO-16 with RARC M-76 (missing modifier) routes to Coding Errors. This secondary classification resolves roughly 85% of remaining ambiguity.
Stage 4: Contextual Resolution
The remaining 15% of ambiguous denials require contextual analysis. The decision tree examines claim-level attributes: Was the service a new patient visit or an established patient follow-up? Was the claim submitted in-network or out-of-network? What is the payer's historical pattern for this CARC code? This contextual layer uses rules for deterministic cases and feeds the ML model for probabilistic classification.
Stage 5: Action Routing
Once the root cause is identified, the system routes the denial to the appropriate team with the specific corrective action. Eligibility denials go to patient access for coverage verification and resubmission. Coding errors go to the coding team with the specific CCI edit or modifier recommendation. Authorization failures go to the utilization management team for retrospective auth requests or appeal preparation.
The 5 Root Cause Categories with Sub-Causes
Each root cause category contains specific sub-causes that represent the actual operational failure point. Understanding these sub-causes is essential for building targeted prevention rules. For organizations looking to implement this alongside broader AI-driven revenue cycle transformation, our guide on agentic AI for revenue cycle management provides the architectural context for touchless claim processing.
Category 1: Registration and Eligibility Errors (24% of Denials)
Registration and eligibility errors occur when patient coverage information is incorrect, incomplete, or outdated at the time of service. These denials are the most preventable because they can be caught before the clinical encounter even begins.
Sub-causes:
- Wrong payer on file (35% of category): The claim was submitted to a payer that does not cover the patient. This typically occurs when patients change insurance plans without updating their information or when the front desk selects the wrong payer from a dropdown menu.
- Inactive coverage at date of service (28%): The patient's coverage was terminated, lapsed, or not yet effective on the date of service. This is increasingly common with marketplace plans that have annual re-enrollment periods.
- Coordination of Benefits (COB) ordering errors (20%): The claim was submitted to the secondary payer before the primary, or the primary payer is unknown. COB issues are particularly prevalent in dual-eligible Medicare/Medicaid populations and patients with employer-sponsored and spouse-sponsored plans.
- Missing or incorrect demographics (12%): Member ID, date of birth, or subscriber information does not match the payer's records. Even a single digit mismatch in a member ID triggers an automatic denial.
- Non-covered benefits (5%): The service is excluded from the patient's benefit plan. This differs from medical necessity denials in that the service category itself is not covered regardless of clinical justification.
Prevention approach: Implement real-time eligibility verification at three touchpoints: scheduling, 48 hours before the appointment, and at check-in. Automated 270/271 eligibility transactions catch 85% of these issues before service delivery. Organizations that implement three-touch eligibility verification typically reduce this denial category by 60 to 70%.
Category 2: Authorization Failures (19% of Denials)
Authorization failures occur when required prior authorization is missing, expired, or does not match the services rendered. The financial impact per denial tends to be higher than other categories because authorization requirements disproportionately affect high-cost procedures.
Sub-causes:
- Missing prior authorization (42% of category): No authorization was obtained before the service was rendered. This is the single largest sub-cause in this category and often results from workflow gaps where authorization requirements are not checked during scheduling.
- Expired authorization (25%): The authorization was obtained but had expired by the date of service. Authorization validity periods range from 30 days to 12 months depending on the payer and service type.
- Wrong procedure on authorization (18%): The authorization was obtained for a different CPT code than what was billed. This frequently occurs when intraoperative findings change the scope of a surgical procedure.
- Authorization quantity exceeded (10%): The number of authorized visits or units has been exhausted. Common with physical therapy, occupational therapy, and behavioral health services that have visit limits.
- Retrospective authorization denied (5%): A retroactive authorization request was submitted after the service but denied by the payer. Retro auth success rates vary by payer from 20% to 70%.
Prevention approach: Build an authorization tracking system that links every authorization to the patient encounter, tracks expiration dates, monitors remaining units, and alerts schedulers when an auth is needed. Automated auth status verification at 48 hours before service catches expired and quantity-exhausted authorizations before the patient arrives.
Category 3: Coding Errors (26% of Denials)
Coding errors are the largest single root cause category and encompass a wide range of issues from diagnosis code specificity to procedure code bundling violations. These denials require the most technical expertise to resolve and prevent.
Sub-causes:
- Insufficient diagnosis specificity (30% of category): An unspecified or insufficiently specific ICD-10 code was used when a more specific code was required. For example, using M54.5 (low back pain) instead of M54.51 (vertebrogenic low back pain) when the documentation supports the more specific code.
- Bundling and CCI violations (25%): Two or more procedure codes were billed separately when they should have been bundled under the Correct Coding Initiative (CCI) edits. This is particularly common with evaluation and management (E/M) codes billed with procedures performed during the same visit.
- Missing or incorrect modifiers (20%): A required modifier was not appended to the CPT code, or the wrong modifier was used. Modifier -25 (separate E/M on the same day as a procedure) and modifier -59 (distinct procedural service) are the most commonly missed.
- Medical necessity failures (15%): The diagnosis code does not support the medical necessity of the procedure under the payer's Local Coverage Determination (LCD) or National Coverage Determination (NCD) policies.
- Frequency limits exceeded (10%): The service was billed more frequently than the payer allows within a given time period. This is especially common for preventive services, imaging studies, and certain lab panels.
Prevention approach: Deploy pre-submission claim scrubbing that runs CCI edits, diagnosis-procedure crosswalk validation, modifier requirements checks, and LCD/NCD medical necessity verification before the claim leaves the billing system. AI-assisted coding review can reduce coding-related denials by 40 to 55%.
Category 4: Billing Errors (18% of Denials)
Billing errors are operational failures in the claim submission process itself, distinct from coding or clinical issues. These are often the simplest to prevent with proper system configuration and validation rules.
Sub-causes:
- Duplicate claims (30% of category): The same claim was submitted more than once, either through system errors, batch resubmission without proper tracking, or manual re-entry. Payers flag duplicates based on a combination of patient ID, date of service, procedure code, and provider NPI.
- Timely filing limit exceeded (25%): The claim was submitted after the payer's filing deadline. Filing windows range from 90 days (some commercial payers) to 365 days (Medicare). Claims approaching the timely filing threshold should trigger automated priority alerts.
- Wrong place of service (18%): The place of service code on the claim does not match the actual rendering location or does not align with the procedure code. This is common when provider groups operate across multiple facility types.
- Invalid provider or NPI (15%): The rendering or billing provider NPI is not enrolled with the payer, not credentialed for the service type, or has an inactive enrollment. Provider enrollment gaps are a growing cause of denials as payers tighten credentialing requirements.
- Wrong payer format or submission (12%): The claim was submitted in the wrong format, to the wrong clearinghouse endpoint, or with missing required fields specific to the payer's submission requirements.
Prevention approach: Implement automated duplicate detection with configurable matching criteria, filing deadline dashboards with 30/60/90-day aging alerts, provider enrollment status verification, and payer-specific claim format validation. These system-level checks can reduce billing errors by 65 to 80%.
Category 5: Clinical Documentation Gaps (13% of Denials)
Documentation gaps occur when the clinical record does not adequately support the services billed. While this is the smallest category by volume, the per-denial financial impact and appeal complexity make it disproportionately costly.
Sub-causes:
- Missing clinical notes (35% of category): The documentation for the date of service is entirely absent or was not provided when the payer requested supporting records. This is often a workflow issue where clinical notes are not completed before billing submits the claim.
- Insufficient detail (28%): The clinical documentation exists but does not provide sufficient detail to support the level of service billed. This is especially common with E/M coding where documentation must support time-based or complexity-based code selection.
- No medical necessity documentation (22%): The clinical record does not include the specific documentation elements required to establish medical necessity under the applicable coverage policy. Many LCD/NCD policies have explicit documentation requirements that go beyond the standard clinical note.
- Missing signatures (10%): The clinical documentation lacks a required provider signature, co-signature, or attestation. While electronic health records have reduced this issue, it persists in settings with mixed paper and electronic workflows.
- Incomplete operative reports (5%): Surgical procedures lack a complete operative report, or the report does not describe the procedure in sufficient detail to support the CPT code billed. Payers increasingly request operative reports for complex or high-cost procedures.
Prevention approach: Implement a pre-billing documentation completeness checklist that verifies note completion, signature status, and required documentation elements before releasing the claim. CDI (Clinical Documentation Improvement) programs that work concurrently with clinical encounters reduce documentation-related denials by 50 to 65%.
AI Pattern Detection: From Data to Insights
With the decision tree framework generating consistently classified denial data, the next step is deploying machine learning models that detect patterns across thousands of denials to surface insights no human analyst could find manually.
Denial Clustering
K-Means clustering groups denials by similarity across multiple dimensions simultaneously. Instead of analyzing one variable at a time (denials by payer, denials by code, denials by provider), clustering reveals multi-dimensional patterns. For example, a cluster might emerge that shows UnitedHealthcare denials for radiology procedures at outpatient facilities with CPT codes in the 70000-79999 range have a 3x higher denial rate on Mondays and Tuesdays. This pattern, invisible to manual review, could indicate a payer processing queue issue or a staffing pattern at the authorization desk.
Time-Series Anomaly Detection
Time-series analysis on denial rates per root cause category detects sudden shifts that indicate systemic changes. When a payer changes a coverage policy, updates prior authorization requirements, or modifies claim processing rules, the impact appears as a step-change or trend break in the denial time series. Automated anomaly detection using methods like Isolation Forest or Prophet can flag these changes within days rather than the weeks or months it takes manual review to notice a pattern shift.
Payer-Specific Behavioral Modeling
Each payer has distinct denial patterns driven by their adjudication rules, audit priorities, and policy interpretations. ML models trained on payer-segmented data capture these behavioral signatures. For instance, one payer might aggressively deny modifier -25 claims while another auto-adjudicates them. A payer-specific model learns that submitting claims to Aetna with modifier -25 requires appended documentation while the same claim to Cigna does not. These payer behavior models enable proactive claim customization that prevents denials before submission.
Seasonal and Cyclical Patterns
Denial rates exhibit seasonal patterns tied to insurance renewal cycles (January and July spikes from coverage changes), fiscal year budget pressures (Q4 increases from payer cost containment), and regulatory changes (annual ICD-10 and CPT code updates in October). ML models that incorporate seasonal features predict these cyclical patterns and trigger preemptive workflow adjustments, such as scheduling additional eligibility verification staff in January or intensifying coding review in October.
Building the ML Model: Features, Architecture, and Training
The ML model for denial pattern detection and prediction follows a progressive architecture, starting with interpretable decision trees and advancing to ensemble methods as the data volume and accuracy requirements grow.
Feature Set
The model ingests features from five categories:
| Feature Category | Specific Features | Type |
|---|---|---|
| Denial Code Features | CARC code (one-hot encoded), RARC code, group code prefix, denial amount | Categorical + Numeric |
| Payer Features | Payer ID, plan type (HMO/PPO/MA), contract type, historical denial rate | Categorical + Numeric |
| Procedure Features | CPT code family, procedure complexity score, modifier presence, RVU value | Categorical + Numeric |
| Provider Features | Provider specialty, historical denial rate, credential status, rendering vs billing | Categorical + Numeric |
| Temporal Features | Day of week, month, days since enrollment, days from DOS to submission | Numeric + Cyclical |
Model Progression
Stage 1: Decision Tree Classifier (Baseline)
A single decision tree provides the baseline model with full interpretability. Maximum depth is constrained to 8 to 12 levels to prevent overfitting. The decision tree mirrors the manual RCA framework, making it auditable and explainable to revenue cycle leadership. Expected accuracy: 72 to 78%.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# Feature matrix X: [carc_encoded, rarc_encoded, payer_id,
# cpt_family, specialty, day_of_week, submit_lag_days, amount]
# Target y: root_cause_category (0-4)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
dt_model = DecisionTreeClassifier(
max_depth=10,
min_samples_leaf=50,
class_weight='balanced'
)
dt_model.fit(X_train, y_train)
print(f"Baseline accuracy: {dt_model.score(X_test, y_test):.3f}")Stage 2: Random Forest (Ensemble)
A Random Forest ensemble of 200 to 500 decision trees reduces overfitting and captures interaction effects between features. Feature importance scores from the Random Forest directly inform which denial attributes are the strongest predictors of each root cause category. Expected accuracy: 80 to 85%.
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(
n_estimators=300,
max_depth=15,
min_samples_leaf=20,
class_weight='balanced',
n_jobs=-1
)
rf_model.fit(X_train, y_train)
# Feature importance ranking
importances = rf_model.feature_importances_
for feat, imp in sorted(zip(feature_names, importances),
key=lambda x: -x[1])[:10]:
print(f" {feat}: {imp:.4f}")Stage 3: XGBoost (Production)
XGBoost is the production model that maximizes prediction accuracy while maintaining reasonable training times. With hyperparameter tuning via Optuna or grid search, XGBoost consistently achieves the highest accuracy for structured denial data. Expected accuracy: 85 to 92%.
import xgboost as xgb
xgb_model = xgb.XGBClassifier(
n_estimators=500,
max_depth=8,
learning_rate=0.05,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.1,
reg_lambda=1.0,
objective='multi:softmax',
num_class=5,
eval_metric='mlogloss'
)
xgb_model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
verbose=50
)
print(f"XGBoost accuracy: {xgb_model.score(X_test, y_test):.3f}")Model Explainability with SHAP
In healthcare revenue cycle, model interpretability is non-negotiable. Revenue cycle directors and compliance officers need to understand why the model classified a denial as a coding error versus an authorization failure. SHAP (SHapley Additive exPlanations) provides feature-level explanations for each prediction.
import shap
explainer = shap.TreeExplainer(xgb_model)
shap_values = explainer.shap_values(X_test)
# Global feature importance
shap.summary_plot(shap_values, X_test,
feature_names=feature_names)
# Single denial explanation
shap.force_plot(explainer.expected_value[0],
shap_values[0][0],
X_test.iloc[0],
feature_names=feature_names)SHAP explanations enable the revenue cycle team to validate the model's reasoning, build trust in automated classification, and identify edge cases where the model needs additional training data or rules.
Automated RCA Dashboard: Visualization and Drill-Down
The RCA insights generated by the decision tree framework and ML models must be surfaced through a dashboard that enables both executive overview and operational drill-down. Grafana and Metabase are well-suited platforms for this because they connect directly to the denial data warehouse and support interactive filtering.
Executive KPIs
The top-level dashboard presents five key performance indicators that revenue cycle leadership monitors weekly:
- Current Denial Rate: Overall denial rate as a percentage of submitted claims, with trend comparison to the previous quarter.
- Monthly Denial Dollars: Total dollar value of denied claims per month, broken down by root cause category.
- Average Resolution Time: Mean days from denial receipt to resolution (either successful appeal or write-off), tracked by category.
- First-Pass Resolution Rate: Percentage of denials resolved on the first appeal or correction attempt, indicating the quality of the RCA classification and action routing.
- ML Prediction Accuracy: The production model's accuracy on a rolling 30-day basis, ensuring model performance does not degrade as denial patterns evolve.
Operational Drill-Down Views
Below the KPIs, the dashboard provides drill-down capabilities that enable analysts to investigate specific patterns:
- Denial Rate by Root Cause Category (Time Series): A multi-line chart showing how each of the 5 root cause categories trends over 12 months. When one category spikes, analysts can click through to see which specific sub-causes are driving the increase.
- Top 10 CARC Codes by Dollar Impact: A ranked bar chart showing which specific denial codes are costing the organization the most money. This view prioritizes the highest-impact codes for targeted intervention.
- Payer Denial Heatmap: A matrix view with payers on one axis and root cause categories on the other, with color intensity representing denial rate. This instantly surfaces which payers are denying which types of claims at above-average rates.
- Provider Denial Scorecard: Per-provider denial rates broken down by category, enabling targeted education and workflow improvement for providers with above-average denial rates in specific categories.
- Denial Cohort Analysis: ML-generated denial clusters with drill-down into the specific features that define each cluster, exposing multi-dimensional patterns.
Prevention Rules Engine: From RCA Insights to Automated Prevention
The most valuable output of the RCA framework is not just understanding why denials happen but automatically preventing them. The prevention rules engine translates RCA insights into automated pre-submission checks and real-time interventions.
Rule Structure
Each prevention rule follows an IF-THEN-ACTION structure that maps directly to a root cause sub-cause:
| Rule Trigger | Condition | Prevention Action | Status |
|---|---|---|---|
| Pre-Submit Check | CO-27 pattern + UnitedHealthcare claims | Verify eligibility at T-24h before submission | Active |
| Scheduling Alert | CO-15 pattern + surgical procedures | Auto-initiate prior auth request at scheduling | Active |
| Coding Review | CO-97 pattern + CPT 99213 with procedures | Flag for modifier -25 review before release | Active |
| Duplicate Guard | CO-18 pattern + same DOS detected | Hold claim and alert billing team | Active |
| Filing Alert | CO-29 pattern + claim age exceeds 60 days | Escalate to priority filing queue | Active |
| Documentation Check | CO-16 pattern + inpatient claims | Request medical records before submission | Active |
Continuous Rule Optimization
The prevention rules engine is not static. As the ML model identifies new patterns, new prevention rules are proposed automatically and queued for human review. The rule lifecycle follows four stages:
- Detection: The ML model identifies a recurring denial pattern that exceeds a configurable threshold (for example, more than 10 denials per month with the same CARC, payer, and procedure combination).
- Proposal: The system generates a draft prevention rule with the trigger condition, recommended action, and expected impact based on historical denial volume and dollar amounts.
- Review: A revenue cycle analyst reviews the proposed rule, validates the logic, and approves or modifies it before activation.
- Monitoring: Once active, the rule's effectiveness is tracked by comparing denial rates for the targeted pattern before and after rule activation. Rules that do not achieve the expected reduction are flagged for revision.
Implementation Guide: From Zero to Automated RCA
Building an automated RCA system requires a phased approach that delivers incremental value at each stage while building toward the full ML-powered prevention engine.
Phase 1: Data Foundation (Weeks 1 to 4)
Objective: Establish the denial data repository and CARC/RARC parsing pipeline.
- Connect 835 ERA feeds from your clearinghouse or payer portals to a central data store.
- Build the CARC/RARC code parser that extracts denial codes, amounts, and claim-level metadata.
- Create the denial code taxonomy mapping table that maps every CARC/RARC combination to a root cause category and sub-cause.
- Backload 12 months of historical denial data for baseline analysis and ML training.
Data requirements: At minimum, you need the 835 transaction data, claim header data from your practice management system, and provider enrollment data. The 835 provides the denial codes and amounts; the claim header provides the clinical and demographic context; the provider data enables provider-level analysis.
Phase 2: Baseline Analytics (Weeks 5 to 8)
Objective: Deploy the decision tree framework and RCA dashboard.
- Implement the automated decision tree classifier using the CARC/RARC taxonomy mapping.
- Deploy the RCA dashboard with executive KPIs and operational drill-down views.
- Establish manual RCA workflows for the ambiguous denials that the decision tree cannot classify with high confidence.
- Begin tracking root cause category distribution and sub-cause frequency to establish the organization's baseline denial profile.
Phase 3: ML Model Training (Weeks 9 to 14)
Objective: Train and validate the ML models using the classified denial data.
- Engineer the feature set from the denial repository, incorporating denial codes, payer attributes, procedure attributes, provider attributes, and temporal features.
- Train the three-stage model progression: Decision Tree baseline, Random Forest ensemble, and XGBoost production model.
- Implement SHAP explainability and validate model predictions with revenue cycle subject matter experts.
- Deploy the denial clustering and time-series anomaly detection modules.
Phase 4: Prevention Engine (Weeks 15 to 20)
Objective: Activate the automated prevention rules engine and pre-submission risk scoring.
- Deploy prevention rules based on the top 10 highest-impact denial patterns identified by the ML model.
- Implement pre-submission claim risk scoring that assigns a denial probability to each claim before it is submitted.
- Establish the continuous rule optimization lifecycle with automated rule proposal and human review.
- Configure model retraining on a monthly cadence to adapt to evolving payer behavior and denial patterns.
Integration with RCM Systems
The RCA framework integrates with existing revenue cycle management infrastructure at three points:
- Clearinghouse integration: 835 ERA data feeds provide the denial input. Most clearinghouses support automated 835 file delivery via SFTP or API.
- Practice management system: Claim header data, provider enrollment status, and authorization tracking data flow from the PMS into the feature engineering pipeline.
- Billing workflow: Prevention rules and risk scores are surfaced in the billing workflow through API integration, flagging high-risk claims before the billing team submits them.
Measuring Success: ROI and Impact Metrics
Organizations that implement automated RCA frameworks consistently report measurable improvements across four dimensions:
- Denial rate reduction: 40 to 60% reduction in preventable denials within 6 months of prevention engine activation, based on industry benchmarks from HFMA denials management research.
- Resolution time improvement: 50 to 70% reduction in average denial resolution time through automated classification and action routing.
- Cost per denial reduction: 30 to 50% reduction in the cost to rework a denied claim through standardized processes and reduced manual analysis time.
- Revenue recovery: Data-driven denial prevention can recover up to $10 million per $1 billion in patient revenue through early intervention and workflow redesign, according to WhiteSpace Health analysis.
The 20-week implementation timeline delivers a positive ROI within the first year for organizations processing more than 100,000 claims annually. The combination of reduced denial volume, faster resolution, lower rework costs, and recovered revenue typically generates a 3 to 5x return on the implementation investment.
Frequently Asked Questions
What is the difference between CARC and RARC codes in denial management?
CARC (Claim Adjustment Reason Codes) provide the primary reason for a claim denial or adjustment and are mandatory on every 835 remittance transaction per the ANSI X12 standard. RARC (Remittance Advice Remark Codes) provide supplementary context and specific instructions beyond the CARC. Together, they form a complete denial explanation. For example, CARC CO-16 tells you the claim lacks information, while the paired RARC MA-130 specifies that medical records are needed. Effective root cause analysis requires mapping both codes to identify the actual operational failure point.
How does a decision tree framework improve denial root cause analysis compared to manual review?
A decision tree framework provides three key advantages over manual RCA: consistency (every denial is classified using the same criteria regardless of which analyst handles it), scalability (automated classification processes thousands of denials per hour versus 30 to 60 per day for manual review), and pattern detection (standardized classification data enables ML models to detect multi-dimensional patterns across payers, procedures, providers, and time periods that are invisible to manual analysis). Organizations using decision tree frameworks typically achieve 85 to 92% classification accuracy and reduce root cause identification time from 15 minutes to under 500 milliseconds per denial.
What machine learning models work best for healthcare denial pattern detection?
The recommended progression is Decision Tree (72 to 78% accuracy, full interpretability) as a baseline, Random Forest (80 to 85% accuracy, feature importance ranking) as an intermediate step, and XGBoost (85 to 92% accuracy, production-grade performance) as the production model. All three are tree-based methods that work well with the mixed categorical and numerical features in denial data. SHAP (SHapley Additive exPlanations) should be layered on top of any production model to provide feature-level explanations that satisfy compliance and audit requirements in healthcare settings.
How long does it take to implement an automated denial RCA system?
A phased implementation typically takes 20 weeks across four phases: data foundation (weeks 1 to 4), baseline analytics and dashboard deployment (weeks 5 to 8), ML model training and validation (weeks 9 to 14), and prevention engine activation (weeks 15 to 20). Organizations can begin seeing value from Phase 2 onward as the RCA dashboard surfaces denial patterns that were previously invisible. The prevention engine in Phase 4 delivers the largest ROI through automated denial prevention. Prerequisites include access to 835 ERA data, claim header data from your practice management system, and 12 months of historical denial data for model training.
What is the expected ROI from an AI-powered denial prevention system?
Organizations processing more than 100,000 claims annually typically see a 3 to 5x return on investment within the first year of full prevention engine activation. The ROI comes from four sources: 40 to 60% reduction in preventable denial volume, 50 to 70% faster resolution time, 30 to 50% lower cost per denial rework, and up to $10 million in recovered revenue per $1 billion in patient revenue. According to HFMA research, hospitals lose an average of 4.8% of net revenue to denials, and even recovering a fraction of that through automated RCA and prevention represents significant financial impact. The 20-week implementation cost is typically recovered within 6 to 9 months of prevention engine activation.


