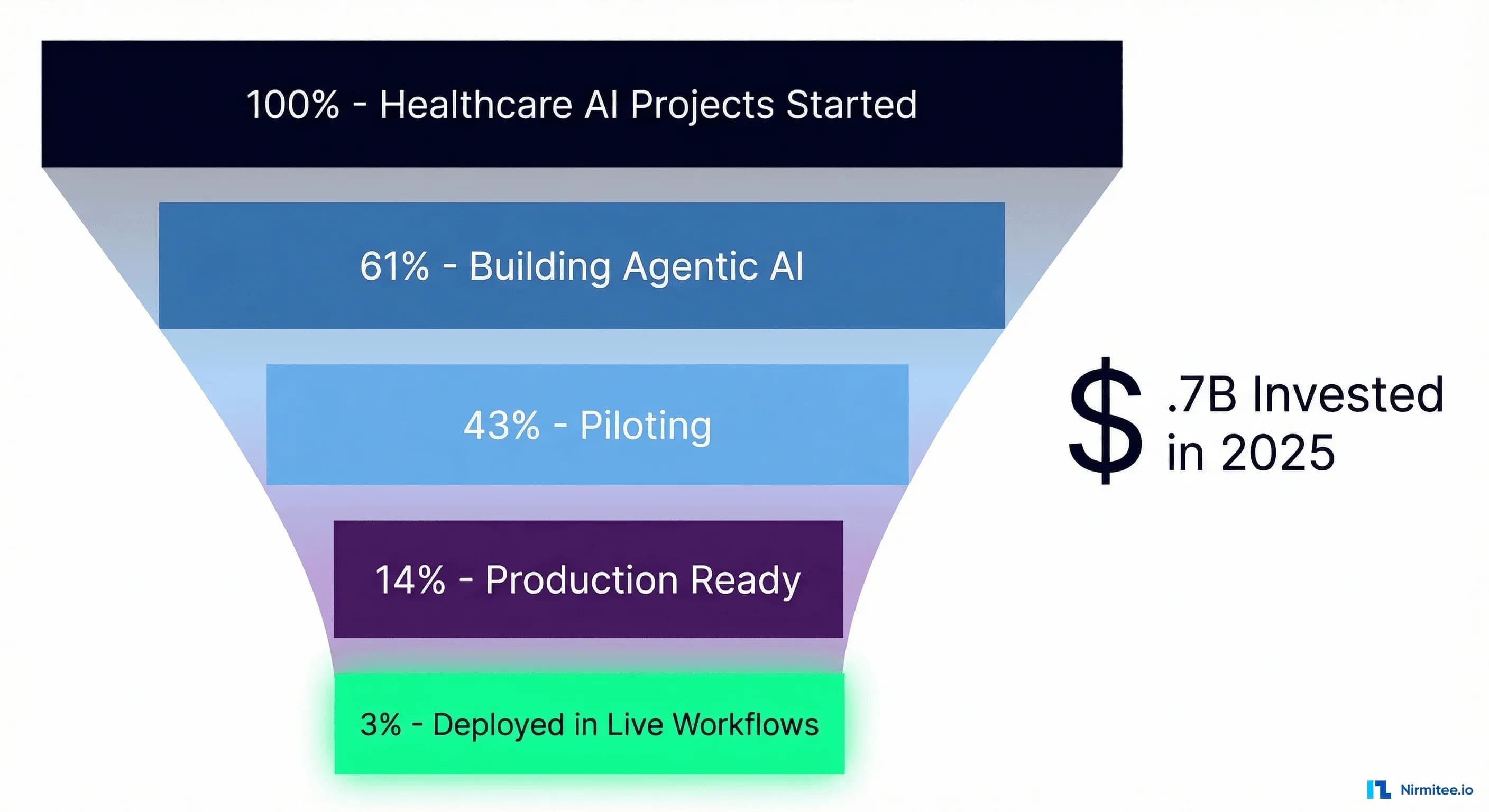
Healthcare just poured $10.7 billion into AI in a single year—a 24.4% jump from 2024, with AI-enabled startups capturing 62% of all digital health venture funding (Crunchbase). Every major health system has an agentic AI initiative. Boards are asking about autonomous clinical workflows. Vendors are promising the moon.
And yet: only 3% of healthcare organizations have deployed agentic AI in live clinical workflows (BCG).
That is not a rounding error. That is a systemic failure of execution—a $10 billion experiment where 97% of projects stall somewhere between a compelling demo and a production deployment that actually touches patients.
This piece is not another breathless take on what agentic AI could do for healthcare. It is a forensic examination of why nearly every project fails to ship, what the 3% do differently, and a concrete production readiness checklist you can use to audit your own initiative before it joins the graveyard of impressive pilots.
Related Reading
For more insights, explore our guides on Why 80% of Healthcare AI Projects Fail After Pilot and FHIR in Modern Healthcare.
You may also find value in EHR Software Development Guide and Building a Healthtech App.
The Numbers Don't Lie: Healthcare's Agentic AI Reality Check
The gap between ambition and execution in healthcare agentic AI is not subtle. It is a chasm, and the data from every major research firm tells the same story.
BCG's 2026 analysis found that 61% of healthcare organizations are actively building agentic AI solutions, with 43% running pilots. But that number collapses when you ask about production: only 3% have agents operating in live workflows. The rest are stuck in what BCG calls the "pilot purgatory"—functional demos that never graduate to clinical reality.
Deloitte's 2026 health care survey adds another dimension: over 80% of executives expect moderate-to-significant value from agentic AI, and 85% plan to increase AI agent investment over the next 2–3 years. The expectation is enormous—98% of executives anticipate at least 10% cost savings, with 37% expecting savings above 20%. But today, only 22% are actually using AI agents, compared to 69% using generative AI. That deployment gap between generative AI adoption and agentic AI deployment is where billions of dollars go to die.
Microsoft and the Health Management Academy assessed agentic AI readiness across health systems and found a pattern: organizations rate their strategic intent highly but score poorly on the infrastructure, governance, and workforce dimensions required to actually deploy. The will is there. The capability is not.
Gartner goes further, predicting that 40%+ of agentic AI projects will be cancelled outright by the end of 2027—not downscaled, not pivoted, but killed. And across all industries, only 14% of enterprises have production-ready agentic AI.
Put these numbers together, and the picture is clear. Healthcare is not suffering from a lack of interest in agentic AI or a lack of funding. It is suffering from a systematic inability to move from proof-of-concept to production—and the reasons are more structural than most leaders want to admit.
The 5 Reasons Healthcare AI Projects Die Before Production
After working with health systems across the US on FHIR interoperability and AI integration, we see the same five failure modes repeat with striking consistency. None of them is about the AI models themselves.
Reason 1: Data Infrastructure Is Not Ready
This is the most common and most underestimated failure mode. Only 15% of healthcare organizations report that their data is fully AI-ready—meaning clean, normalized, accessible through APIs, and governed with clear lineage.
The other 85% are building agentic AI on top of data systems designed for billing, not clinical intelligence. Patient records are fragmented across dozens of systems. Lab results live in one silo, medication lists in another, social determinants nowhere at all. The data exists, but it is trapped in formats that an AI agent cannot reliably access or act on.
Production agentic AI requires data that is not just available but computable—structured, coded, versioned, and accessible through standardized interfaces. A demo can fake this with a curated dataset. Production cannot. For a deeper treatment of what AI-ready data infrastructure actually requires, see our guide on healthcare data governance, lineage, and access control.
Reason 2: FHIR Interoperability Is Treated as an Afterthought
Here is the pattern we see repeatedly: a team builds an impressive agentic AI prototype using a clean, synthetic FHIR dataset. The demo goes well. Leadership greenlights a pilot. And then the team discovers that the actual EHR environment does not expose the FHIR resources they need, the data quality through real FHIR endpoints is inconsistent, and the authorization model for production FHIR access is far more restrictive than their development sandbox.
Interoperability is not a feature you bolt on at the end. It is the foundation that determines whether an AI agent can actually read and write clinical data in a production EHR. The organizations that succeed treat FHIR integration as the first workstream, not the last. They invest in understanding FHIR R4 resource models, SMART on FHIR authorization, and how to map their clinical workflows to FHIR operations before they write a single line of agent logic.
The momentum behind TEFCA—which has facilitated nearly 500 million health records exchanged, up from just 10 million in January 2025—means the interoperability infrastructure is maturing fast. But leveraging it requires deliberate investment in FHIR-native architecture. For a technical breakdown of how AI agents should interact with clinical data through FHIR, see Agent on FHIR: Building AI Agents That Read and Write Clinical Data.
Reason 3: No Governance Framework Exists
Agentic AI, by definition, takes actions. In healthcare, those actions have clinical consequences. And yet most organizations launching agentic AI pilots have no governance framework that addresses the fundamental questions: What can the agent do autonomously? What requires human approval? How are agent actions audited? Who is liable when an agent makes a wrong recommendation?
Without governance, you get one of two outcomes. Either the compliance and legal teams kill the project during the production review (the more common case), or the project deploys without adequate controls and creates an unacceptable risk exposure. Both outcomes are avoidable with a governance-first approach.
The concept of bounded autonomy—defining explicit boundaries for what an agent can do independently versus what requires human-in-the-loop approval—is the pattern that the 3% use to satisfy both clinical leadership and compliance teams. It is also worth understanding when a rules engine is the right choice over an AI agent, because not every clinical workflow benefits from autonomy.
Reason 4: The Pilot-to-Production Gap Is a Chasm
A pilot runs on one unit, with one workflow, with the vendor's engineering team on-site, with a curated patient population, and with clinicians who volunteered. Production means every unit, every workflow variant, no vendor hand-holding, the full diversity of patient presentations, and clinicians who were told to use it.
The technical gap alone is severe. Pilot systems rarely address: high-availability requirements, failover behavior when the AI is unavailable, latency budgets that match clinical workflow expectations, integration with the full spectrum of EHR events, or monitoring and alerting infrastructure. The operational gap is worse: who retrains the model, who reviews edge cases, who handles the 3 AM alert when the agent flags something unusual.
This is why observability for agentic AI—structured logging of every agent decision, real-time performance monitoring, and clinical outcome tracking—is not optional infrastructure. It is the bridge between pilot and production.
Reason 5: The Workforce Is Not Prepared for Human-AI Collaboration
Clinicians are being asked to collaborate with AI agents they did not request, do not fully understand, and cannot easily override. The result is predictable: workarounds, distrust, shadow processes, and eventually abandonment.
The organizations that succeed in co-design workflows with clinicians, create clear escalation paths, and make it trivially simple to see why an agent made a recommendation and to override it. They treat the AI agent as a new team member that needs to earn trust, not a system that clinicians must comply with.
What the 3% Do Differently
The small percentage of healthcare organizations that have successfully deployed agentic AI in production share a recognizable playbook. It is not revolutionary. It is disciplined.
They Start with Interoperability Infrastructure
The 3% do not start with agent logic. They start with data plumbing. They invest in FHIR R4 API coverage across their EHR environment, establish TEFCA connectivity for cross-network data access, and build a normalized clinical data layer that agents can query reliably. This work is unglamorous and takes 6–12 months. It is also the single biggest predictor of production success.
TEFCA's growth to 500 million exchanged records provides a national-scale interoperability backbone, but tapping into it requires a deliberate integration strategy. For a comprehensive overview, see our TEFCA guide for healthcare CTOs.
They Deploy Incrementally
No organization in the 3% started with autonomous agents. They started with ambient documentation—AI that listens to clinical encounters and drafts notes for physician review. This is the lowest-risk, highest-value entry point: the agent has no write access to the medical record, the clinician reviews every output, and the workflow improvement (less documentation burden) is immediately measurable.
From ambient documentation, they graduated to clinical decision support—agents that analyze patient data and surface recommendations, still with mandatory human approval. Only after proving reliability, building clinician trust, and establishing monitoring infrastructure did they move to bounded autonomous actions: agents that can execute pre-approved workflows (scheduling, prior authorization, result routing) within explicit guardrails.
This incremental approach is not timid. It is strategic. Each step builds the infrastructure, trust, and operational muscle that the next step requires.
They Build Governance from Day One
The 3% have a governance framework before they have a production agent. That framework specifies: the agent's scope of autonomous action, the conditions that trigger human-in-the-loop review, audit trail requirements, clinical oversight structure, and incident response protocols.
This is bounded autonomy in practice. The agent operates freely within defined boundaries and escalates everything else. The boundaries start narrow and expand as the agent proves reliability. This turns compliance from a blocker into an enabler—when governance teams have approved the boundaries, engineering can ship with confidence.
They Measure Clinical Outcomes, Not Just Technical Metrics
Pilot projects typically measure latency, uptime, and model accuracy. Production deployments measure: time saved per clinician per day, reduction in documentation burden, clinical decision quality (did the recommendation match expert consensus), patient outcome metrics (readmission rates, time to treatment), and staff satisfaction scores.
The technical metrics still matter, but they are table stakes. The metrics that determine whether a project survives the transition from pilot to permanent budget line are clinical and operational outcomes that map to organizational priorities.
They Invest in Change Management Alongside Technology
For every dollar spent on AI engineering, the 3% spend roughly equal amounts on training, workflow redesign, and change management. They appoint clinical champions who co-designed the agent's workflow and advocate to peers. They run parallel workflows during transitions. They hold weekly feedback sessions. This investment in the human side is what separates a technology project from a transformation initiative—and only transformation initiatives survive in production.
The Production Readiness Checklist
Before committing to a production deployment of agentic AI, score your organization against these 20 criteria. Each item reflects a real failure mode we have observed in healthcare AI projects. A score below 15 out of 20 suggests significant production risk.
| Category | Item | Requirement |
|---|---|---|
| Data | 1. Data Quality Baseline | Measured completeness, accuracy, and freshness scores for all data sources the agent consumes |
| Data | 2. Terminology Standardization | Clinical data coded with SNOMED CT, LOINC, RxNorm, or ICD-10—not free text |
| Data | 3. Data Lineage Tracking | End-to-end traceability from the source system through transformation to the agent input |
| Data | 4. PHI Governance | De-identification, minimum necessary access, and audit logging for all agent data access |
| Integration | 5. FHIR R4 API Coverage | All required clinical resources (Patient, Condition, Observation, MedicationRequest, etc.) available via FHIR APIs |
| Integration | 6. SMART on FHIR Authorization | Scoped OAuth2 tokens with least-privilege access for each agent function |
| Integration | 7. EHR Write-Back Capability | Validated workflow for agents to create/update resources in the EHR with proper provenance |
| Integration | 8. Cross-Network Data Access | TEFCA/Carequality/CommonWell connectivity for data from external providers when clinically required |
| Governance | 9. Bounded Autonomy Policy | Documented and approved scope of autonomous action, with explicit escalation triggers |
| Governance | 10. Human-in-the-Loop Protocol | Defined review workflows for high-risk decisions, with SLAs for human response time |
| Governance | 11. Audit Trail Completeness | Every agent decision, recommendation, and action logged with inputs, reasoning, and outcome |
| Governance | 12. Clinical Oversight Structure | Named clinical lead, regular review cadence, authority to modify or halt agent behavior |
| Deployment | 13. High Availability Architecture | Failover design that maintains clinical workflow continuity when the agent is unavailable |
| Deployment | 14. Latency Budget Compliance | Agent response times validated against clinical workflow requirements (e.g., <2s for CDS, <30s for document generation) |
| Deployment | 15. Observability Infrastructure | Real-time monitoring, structured logging, alerting, and dashboards for agent performance and behavior |
| Deployment | 16. Rollback Capability | Ability to disable, downgrade, or roll back agent behavior within minutes without disrupting clinical operations |
| Measurement | 17. Clinical Outcome Metrics | Defined and baselined metrics that tie agent performance to patient care quality |
| Measurement | 18. Operational Efficiency Metrics | Time savings, throughput improvements, and cost reduction targets with pre-deployment baselines |
| Measurement | 19. Clinician Satisfaction Tracking | Regular measurement of clinician trust, usability perception, and workflow impact |
| Measurement | 20. Continuous Improvement Process | Feedback loops from monitoring data and clinician input back into agent refinement, with defined release cadence |
This checklist is not aspirational. Every item addresses a specific failure mode that has killed a healthcare agentic AI project. Use it as a scoring rubric in your next steering committee meeting. If your team cannot confidently check off an item, that is your next workstream—not more agent features.
Case Study: The Incremental Path to Production
Consider a composite but representative example drawn from patterns we have observed across multiple US health systems.
A 12-hospital health system set out to deploy an agentic AI system for clinical documentation and decision support across its emergency departments. They had strong executive sponsorship, a $4 million first-year budget, and a partnership with a leading AI vendor. The initial timeline was aggressive: pilot in three months, production in six.
It took eighteen months. Here is why that was the right answer.
Months 1–6: Foundation. Instead of building agent features, the team spent six months on interoperability infrastructure. They audited their EHR's FHIR API coverage and found that only 40% of the clinical resources they needed were available through production FHIR endpoints. The remaining data was trapped in proprietary interfaces, HL7v2 feeds, and manual exports. They worked with their EHR vendor to expand FHIR coverage to 92% and built a data quality monitoring layer that measured completeness and freshness for every resource type.
In parallel, a clinical governance committee—the CMIO, chief nursing officer, legal counsel, and two ED physician champions—developed the bounded autonomy policy: what the agent could do autonomously (draft documentation), what required human approval (clinical recommendations), and what was explicitly prohibited (medication ordering, discharge decisions).
Months 7–10: Ambient Documentation Pilot. The first agent deployed was deliberately limited. It listened to ED encounters through ambient capture, generated structured clinical notes using the FHIR-normalized patient context, and presented drafts for physician review. No write-back to the EHR. No clinical recommendations. Just documentation assistance.
Fifteen ED physicians participated voluntarily. The results were immediate: an average of 47 minutes per day saved on documentation. More importantly, this phase built clinician trust, validated the observability infrastructure, and stress-tested the FHIR data pipeline under real clinical load.
Months 11–14: Clinical Decision Support. With a reliable data pipeline and clinician buy-in, the team expanded to four EDs and introduced a diagnostic suggestion agent that surfaced differential diagnoses for physician review—still with mandatory human approval. The governance committee reviewed agent performance weekly. The clinical impact: a 12% improvement in early sepsis detection based on the agent flagging subtle vital sign patterns associated with sepsis onset.
Months 15–18: Production Scale. All twelve EDs went live with ambient documentation and clinical decision support. The team added automated prior authorization—a bounded autonomous workflow where the agent submitted standard prior auth requests without human approval, escalating non-standard cases to staff.
The eighteen-month timeline was double the original plan. The result: a production system running continuously for over a year, delivering a sustained 34% reduction in documentation burden and $2.1 million in annualized savings. The project was funded for year two within weeks of the first quarterly review.
The lesson: the six months spent on foundation work—FHIR infrastructure, data quality, governance—was not a delay. It was the investment that made everything after it possible.
From Pilot Purgatory to Production
The $10.7 billion flowing into healthcare AI is not misspent—it is misallocated. Too much goes to model capabilities and demo polish. Too little goes to the infrastructure, governance, and organizational readiness that determine whether a project ships.
The 97% failure rate is not a commentary on whether agentic AI works. It works. The clinical value is real and measurable when deployed correctly. The failure rate is a commentary on how healthcare organizations approach implementation: skipping the interoperability foundation, underinvesting in governance, treating production engineering as an afterthought, and ignoring the human side of human-AI collaboration.
The path to the 3% is not a secret. It is:
- Build the data foundation first. FHIR APIs, data quality monitoring, and terminology standardization. Boring, essential, non-negotiable.
- Deploy incrementally. Ambient documentation before clinical decision support. Decision support before autonomous action. Each step earns the trust and builds the infrastructure for the next.
- Govern from day one. Bounded autonomy, clinical oversight, audit trails. Make compliance an accelerator, not a blocker.
- Measure what matters. Clinical outcomes and operational impact, not just technical metrics.
- Invest in people. Change management, clinician co-design, feedback loops. The technology is the easy part.
If your organization is evaluating or already building agentic AI for clinical workflows, the production readiness checklist above is a starting point. Score honestly. Address the gaps before investing in more agent capabilities. The organizations that reach production are not the ones with the most sophisticated models—they are the ones that did the unglamorous infrastructure and governance work that makes production possible.
At Nirmitee, we build the FHIR interoperability infrastructure and AI integration layer that healthcare organizations need to move agentic AI from pilot to production. If you are staring at the gap between a working demo and a production deployment,