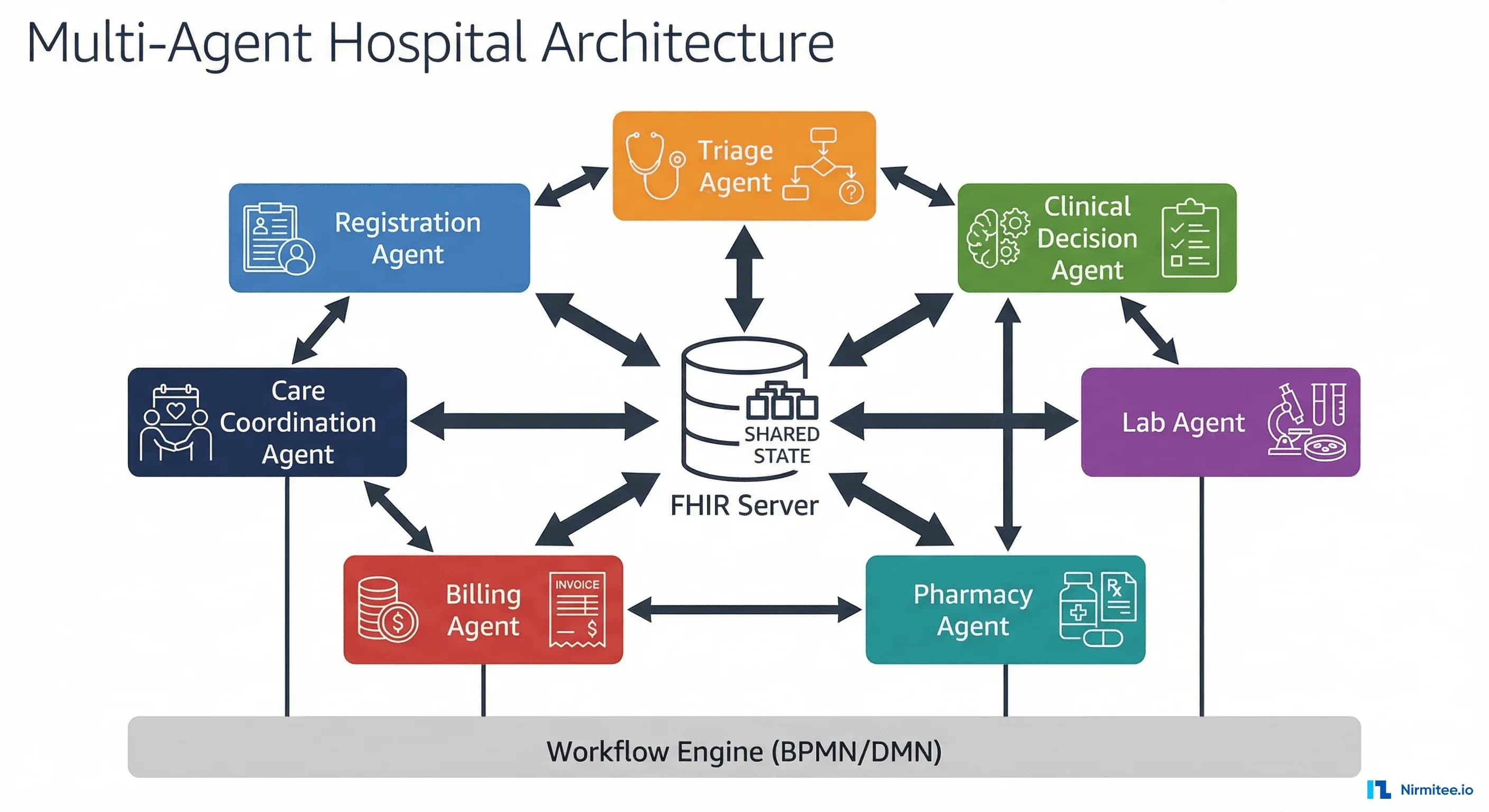
A hospital is already a multi-agent system. The registration clerk verifies insurance. The triage nurse assesses acuity. The physician synthesizes clinical data into a treatment plan. The lab technician flags critical values. The pharmacist checks interactions. The billing specialist generates claims. The care coordinator arranges follow-up.
Each human operates as a specialized agent with bounded responsibilities, defined inputs and outputs, and explicit escalation paths. They communicate through a shared data layer — the EHR — and they are activated by events: a patient arrives, a lab result returns, a medication is ordered.
The question facing healthcare IT leaders in 2026 is not whether to deploy AI. According to BCG's 2026 report, 69% of healthcare organizations are already using generative AI, and 61% are building agentic AI systems. The question is architectural: one monolithic AI that tries to do everything, or specialized agents that mirror how hospitals actually work?
Only 3% have agentic AI in production. The gap is not talent or budget — it is architecture. This article presents the multi-agent pattern that closes that gap, and the FHIR-native data layer that makes it work.
Why Multi-Agent, Not Monolithic?
The instinct to build a single AI system that handles all hospital workflows is understandable. But this approach fails for the same reasons monolithic software architectures fail: the problem space is too large, the failure modes too varied, and the rate of change across domains too different.
Consider what a monolithic clinical AI must handle: insurance eligibility rules that change quarterly, clinical guidelines that update continuously, pharmacy formularies that shift monthly, billing codes revised annually, and triage protocols that vary by facility. A single model cannot be updated for one domain without risking regression in another.
The multi-agent pattern borrows directly from microservices architecture, a paradigm that 52.5% of US healthcare providers are already adopting through composable IT architectures. Each agent is:
- Specialized — trained or fine-tuned on a single domain with domain-specific evaluation criteria
- Independently deployable — updated, retrained, or replaced without affecting other agents
- Bounded in failure — if the billing agent hallucinates, the clinical decision agent is unaffected
- Independently scalable — the lab workflow agent scales during morning blood draw surges without scaling the pharmacy agent
- Auditable — each agent's decisions, inputs, and outputs are traceable for regulatory compliance
Research published in Nature's npj AI (2026) formalized this insight, demonstrating that multi-agent architectures in healthcare settings outperform monolithic models on both accuracy and safety metrics, precisely because specialized agents develop deeper domain competence within narrower boundaries. NVIDIA's GTC 2026 keynote reinforced this, highlighting what they called the "agentic AI inflection" in healthcare — the moment where orchestrated specialist agents surpass generalist models in complex clinical workflows.
The market agrees. The agentic AI healthcare market is projected to grow from $0.79 billion in 2025 to $33.66 billion by 2035, a 45.6% CAGR, driven almost entirely by multi-agent architectures that can be deployed incrementally and validated independently.
The Hospital as a Multi-Agent System
The patient journey through a hospital maps naturally to agent boundaries. Each step involves a distinct domain, distinct data sources, distinct decision logic, and distinct regulatory requirements. Here is how seven specialized agents map to the clinical workflow:
1. Registration Agent
Handles patient identification, demographic capture, and insurance verification. Queries external payer systems for eligibility, validates identity against existing records, detects duplicates, and populates FHIR Patient and Coverage resources. High autonomy for data retrieval; requires human confirmation for new patient creation and identity matching.
2. Triage Agent
Assesses presenting symptoms, calculates acuity scores using standardized protocols (ESI, CTAS), and routes patients to the appropriate department. Reads Patient resources and writes Encounter and Condition resources. Critical design decision: this agent must always escalate to a human triage nurse for high-acuity determinations. It augments speed and consistency but does not replace clinical judgment on severity.
3. Clinical Decision Agent
The most complex agent. Provides evidence-based diagnostic suggestions, drug interaction warnings, order set recommendations, and guideline adherence checking. Reads Condition, Observation, MedicationRequest, and AllergyIntolerance resources. Writes suggested CarePlan and ServiceRequest resources — but every clinical suggestion requires physician approval before becoming an active order. See our guide on clinical decision support system architecture.
4. Lab Workflow Agent
Manages the order-to-result lifecycle: receives ServiceRequest resources, validates specimen requirements, tracks processing status, interprets results against reference ranges, and generates critical value alerts. Writes DiagnosticReport and Observation resources. Critical value alerting always requires immediate human notification.
5. Pharmacy Agent
Validates prescriptions against formulary, checks drug-drug and drug-allergy interactions, verifies dosing against weight-based or renal-adjusted protocols, and manages substitution recommendations. Reads MedicationRequest, writes MedicationDispense. Interaction checking operates autonomously; substitution decisions require pharmacist approval.
6. Billing Agent
Captures charges from completed encounters, maps diagnoses and procedures to ICD-10 and CPT codes, generates claims, and predicts denial probability from historical payer patterns. Reads Encounter, Condition, Procedure resources and writes Claim resources. Denial prediction operates with high autonomy; claim submission requires human review for high-value cases.
7. Care Coordination Agent
Manages discharge planning, referral generation, follow-up scheduling, and post-discharge monitoring. Reads the full Encounter history and writes CarePlan, Appointment, and Communication resources. Particularly effective at identifying readmission risk and ensuring continuity of care documentation is complete before discharge.
Amazon Connect Health has already demonstrated the multi-agent pattern for administrative healthcare tasks — appointment scheduling, insurance verification, and patient communication — using specialized agents that hand off context to one another. The architecture described here extends that pattern into the full clinical workflow.
Technical Architecture Deep-Dive
A multi-agent system is only as good as its communication layer, state management, and orchestration logic. Here is the technical architecture that makes seven independent agents behave as a coherent system.
Agent Communication: FHIR as the Lingua Franca
In many multi-agent AI systems, agents communicate through custom message formats or proprietary APIs. In healthcare, there is a better option: FHIR (Fast Healthcare Interoperability Resources).
FHIR is not just a data standard — it is an agent communication protocol. Each resource is a self-describing, strongly typed data object with a standardized REST API. When the registration agent creates a Patient resource, the triage agent reads it through the same FHIR API it uses with any other agent's output. No custom integration required.
This insight is what most implementations miss: FHIR eliminates the N-squared integration problem. Without a shared standard, seven agents require 42 point-to-point integrations. With FHIR, each agent integrates once with the FHIR server. For a deeper exploration, see our guide on building AI agents that read and write clinical data through FHIR.
Event-Driven Activation: CDS Hooks
CDS Hooks provides the event mechanism that activates agents at the right moment. Rather than polling for changes, each agent subscribes to specific clinical events:
{
"hookInstance": "d1577c69-dfbe-44ad-ba6d-3e05e953b2ea",
"hook": "order-sign",
"context": {
"userId": "Practitioner/dr-smith-456",
"patientId": "Patient/patient-john-smith",
"encounterId": "Encounter/enc-20260402-001",
"draftOrders": {
"resourceType": "Bundle",
"entry": [{
"resource": {
"resourceType": "MedicationRequest",
"medicationCodeableConcept": {
"coding": [{
"system": "http://www.nlm.nih.gov/research/umls/rxnorm",
"code": "197696",
"display": "Warfarin 5mg Oral Tablet"
}]
},
"subject": { "reference": "Patient/patient-john-smith" }
}
}]
}
}
}When a physician signs a medication order, the order-sign hook fires. The pharmacy agent receives this event, checks drug interactions against the patient's current medications and allergies, and returns a CDS Hooks response card — either an informational card confirming safety or a critical alert requiring acknowledgment. The architecture for connecting AI agents to EHR events through CDS Hooks and SMART on FHIR is covered in detail in our AI-EHR connection guide.
Orchestration: Workflow Engine vs. Choreography
Multi-agent systems face a fundamental design choice: centralized orchestration or decentralized choreography.
Orchestration uses a central workflow engine (typically BPMN/DMN-based) that explicitly defines the sequence of agent activations, branching logic, and error handling. The workflow engine is the "conductor" — it knows the full patient journey and directs each agent when to act.
Choreography is event-driven: each agent reacts to events and publishes its own events, with no central coordinator. The patient journey emerges from the interaction of independent agents.
For healthcare, orchestration wins. The regulatory requirement for auditability, the need for deterministic error handling, and the complexity of multi-step approval workflows make a central workflow engine essential. Choreography is elegant in theory but produces audit trails that are nearly impossible to reconstruct. We have written extensively about why BPMN/DMN workflow engines are the right foundation for agentic AI in healthcare.
Human-in-the-Loop: Escalation and Override
Every agent must implement three escalation mechanisms:
- Confidence-based escalation — When the agent's confidence score falls below a domain-specific threshold, the decision routes to a human queue. A billing agent might operate autonomously above 95% confidence but escalate below that. A clinical decision agent might escalate below 99%.
- Rule-based escalation — Certain decisions always require human approval regardless of confidence: high-risk medication orders, code-status changes, controlled substance prescriptions, high-value claim submissions.
- Human override — Any agent decision can be overridden by an authorized human. The override is logged, and the agent learns from the correction through feedback loops that improve future performance.
FHIR Resources as the Agent Data Layer
Each agent in the system reads and writes specific FHIR resources. The Encounter resource is the thread that connects the entire patient journey — created at registration, enriched by each subsequent agent, and closed at discharge.
Here is how the Encounter resource evolves as it passes through the agent pipeline:
{
"resourceType": "Encounter",
"id": "enc-20260402-001",
"status": "in-progress",
"class": {
"system": "http://terminology.hl7.org/CodeSystem/v3-ActCode",
"code": "AMB",
"display": "ambulatory"
},
"subject": {
"reference": "Patient/patient-john-smith",
"display": "John Smith"
},
"participant": [{
"type": [{ "coding": [{ "code": "ATND", "display": "attender" }] }],
"individual": { "reference": "Practitioner/dr-smith-456" }
}],
"period": { "start": "2026-04-02T08:30:00Z" },
"reasonCode": [{
"coding": [{ "system": "http://snomed.info/sct", "code": "29857009", "display": "Chest pain" }]
}],
"diagnosis": [{
"condition": { "reference": "Condition/cond-chest-pain-001" },
"use": { "coding": [{ "code": "billing", "display": "Billing" }] }
}]
}The agent-to-resource mapping:
| Agent | Primary Reads | Primary Writes | Key Operations |
|---|---|---|---|
| Registration | Patient, Coverage | Patient, Coverage, Encounter | Create/update patient demographics, verify insurance eligibility, create encounter |
| Triage | Patient, Encounter, Condition | Encounter, Condition, Flag | Assess acuity, assign priority, route to department |
| Clinical Decision | Condition, Observation, AllergyIntolerance, MedicationRequest | CarePlan, ServiceRequest, MedicationRequest | Suggest diagnoses, recommend orders, check guidelines |
| Lab Workflow | ServiceRequest, Specimen | DiagnosticReport, Observation | Track orders, interpret results, alert on critical values |
| Pharmacy | MedicationRequest, AllergyIntolerance, Patient | MedicationDispense | Validate prescriptions, check interactions, manage substitutions |
| Billing | Encounter, Condition, Procedure, MedicationDispense | Claim, ExplanationOfBenefit | Capture charges, assign codes, generate claims, predict denials |
| Care Coordination | Encounter, CarePlan, Condition | CarePlan, Appointment, Communication | Plan discharge, generate referrals, schedule follow-ups |
This mapping is not arbitrary. Each agent's read/write scope defines its blast radius — the maximum extent of data it can affect if it malfunctions. The registration agent cannot modify clinical observations. The lab agent cannot alter billing claims. This resource-level isolation is a critical safety property of the architecture.
The Bounded Autonomy Pattern
The most important design pattern in multi-agent healthcare AI is bounded autonomy: every agent has an explicit, documented boundary defining what it can do without human approval, what requires human approval, and what it must never do. This pattern is the operational foundation for HIPAA-compliant AI agent architectures.
| Agent | Autonomous (No Human Required) | Supervised (Human Approval Required) | Prohibited (Agent Must Not Act) |
|---|---|---|---|
| Registration | Query insurance eligibility; retrieve existing records; validate demographics; auto-populate forms | Create new patient records; resolve duplicate matches; override insurance denials | Delete patient records; merge identities without confirmation; share data without consent |
| Triage | Calculate acuity scores from structured input; suggest department routing; flag patients matching sepsis/stroke screening criteria | Assign final triage priority (ESI level); override calculated acuity score; route to trauma or critical care | Discharge patients from triage; administer medications; make diagnosis determinations |
| Clinical Decision | Retrieve clinical guidelines; calculate interaction severity; suggest order sets; flag missing preventive care | All medication and procedure orders; diagnosis changes; care plan modifications | Sign orders on behalf of physicians; override allergy alerts; modify completed notes |
| Lab Workflow | Track specimen status; validate order completeness; calculate reference range comparisons; route results to ordering provider | Flag and notify on critical values; cancel or modify pending orders; release results with abnormal interpretations | Change result values; suppress critical value alerts; release results without QC validation |
| Pharmacy | Check drug-drug interactions; verify formulary status; calculate weight-based dosing; suggest therapeutic alternatives | Approve therapeutic substitutions; override interaction warnings; dispense controlled substances; adjust renal-dosed medications | Dispense without pharmacist verification; override allergy contraindications; modify prescriber's intent without consultation |
| Billing | Capture charges; suggest ICD-10/CPT codes; predict denial probability; generate pre-submission reports | Submit claims to payers; write off balances; appeal denied claims | Fabricate charges; upcode diagnoses; alter clinical documentation for billing |
| Care Coordination | Identify readmission risk factors; draft discharge instructions; schedule routine follow-ups | Finalize discharge plans; generate specialist referrals; modify post-discharge medications | Discharge patients; cancel active treatments; override physician discharge criteria |
Each boundary in this matrix should be codified in the agent's configuration — not enforced by the LLM's training, but by hard-coded guardrails in the agent framework. The agent literally cannot call the FHIR API to create a MedicationDispense without a pharmacist approval token in the request context. This is the difference between hoping the AI behaves correctly and architecturally guaranteeing it. For cases where deterministic rules outperform AI-driven decisions entirely, see our analysis of when a rules engine wins over an AI agent.
Implementation Strategy: Start Small, Scale Systematically
The fastest path to failure is deploying seven agents simultaneously. The fastest path to value is deploying one agent in one department and expanding methodically. Here is the four-phase strategy that works.
Phase 1: Single Agent (Months 1-3)
Deploy the billing agent first. This is not arbitrary. The billing agent has four properties that make it the ideal starting point:
- Measurable ROI — Claim denial rates, coding accuracy, and revenue capture are directly quantifiable. You will know within weeks whether the agent is working.
- Low clinical risk — A billing error does not harm a patient. It creates a financial correction, not a safety event.
- High volume — Every encounter generates billing activity. The agent gets production-quality training data immediately.
- Existing structured data — Billing operates on coded, structured data (ICD-10, CPT, HCPCS) that is already in the FHIR server. No NLP or unstructured data processing required.
Phase 1 deliverables: billing agent in production, FHIR server integration validated, monitoring infrastructure deployed, baseline metrics established.
Phase 2: Agent Pair (Months 4-6)
Add the coding agent as a companion to billing. These two agents share FHIR resources (Condition, Procedure, Encounter) and represent the simplest multi-agent interaction. The coding agent suggests codes; the billing agent validates and submits. This phase validates inter-agent communication, shared state management, and conflict resolution before you add clinical complexity.
Phase 3: Department-Wide (Months 7-12)
Expand to a full department — typically a high-volume ambulatory clinic. Deploy registration, triage, clinical decision, and lab agents alongside billing and coding. This phase introduces the full orchestration layer: BPMN workflow definitions, human-in-the-loop approval gates, and cross-agent error handling.
Phase 4: Hospital-Wide (Month 13+)
Extend to all departments with the care coordination agent as the cross-departmental connector. This phase is less about technology and more about organizational change management: training staff, refining escalation thresholds from production data, and optimizing agent-human collaboration patterns.
This phased approach is consistent with BCG's finding that the 22% of healthcare organizations currently using AI agents started with narrow, high-ROI use cases and expanded systematically. The organizations that attempted big-bang deployments are the ones stuck in the 61%-building, 3%-in-production gap.
Monitoring and Observability for Multi-Agent Systems
A multi-agent system without observability is a multi-agent liability. Traditional application monitoring (uptime, latency, error rates) is necessary but insufficient. Agent-specific monitoring requires four additional dimensions.
Distributed Tracing Across Agents
Every patient journey must be traceable as a single distributed transaction across all seven agents. Use OpenTelemetry with a custom span convention:
// OpenTelemetry span convention for multi-agent patient journey tracing
{
"traceId": "ab1c2d3e4f5a6b7c8d9e0f1a2b3c4d5",
"spans": [{
"spanId": "reg-001",
"operationName": "registration-agent.verify-insurance",
"agentId": "registration-agent-v2.3",
"encounterId": "Encounter/enc-20260402-001",
"attributes": {
"agent.confidence": 0.97,
"agent.decision": "insurance_verified",
"agent.autonomy_level": "autonomous",
"agent.escalated": false
}
}, {
"spanId": "tri-001",
"operationName": "triage-agent.assess-acuity",
"parentSpanId": "reg-001",
"attributes": {
"agent.confidence": 0.82,
"agent.decision": "esi_level_3",
"agent.autonomy_level": "supervised",
"agent.escalated": true,
"agent.escalation_reason": "confidence_below_threshold",
"agent.human_response_time_ms": 45000
}
}]
}Agent-Level Metrics
Each agent should expose standardized metrics:
- Decision throughput — Decisions per hour, segmented by autonomy level (autonomous vs. supervised vs. escalated)
- Confidence distribution — Histogram of confidence scores over time. A leftward shift signals model degradation.
- Escalation rate — Percentage of decisions requiring human intervention. Track against baseline to detect drift.
- Override rate — Percentage of agent decisions overridden by humans. Rising override rates indicate the agent's recommendations are diverging from clinical practice.
- Latency per decision — Time from event receipt to decision output, excluding human approval wait time.
- FHIR resource accuracy — Validation error rate on FHIR resources written by the agent.
Drift Detection
Agent performance degrades silently as guidelines update, formularies change, and payer rules shift. Implement continuous drift detection by comparing agent outputs against a rolling window of human-validated ground truth. When drift exceeds a threshold, automatically reduce the agent's autonomy level until it is retrained and revalidated.
For a comprehensive framework covering all four dimensions of agent observability, see our dedicated guide on observability for agentic AI in healthcare.
Building the Future of Hospital AI
The multi-agent architecture mirrors how hospitals already operate: specialized professionals with bounded responsibilities, communicating through shared records, activated by clinical events, escalating when decisions exceed their scope.
The technology to replicate this pattern now exists — FHIR for the shared data layer, CDS Hooks for events, workflow engines for orchestration, and bounded autonomy for safety.
The organizations that will lead are not building the biggest models. They are building the best-architected agent systems — where each agent is small enough to validate, specialized enough to excel, bounded enough to trust, and observable enough to improve continuously.
Start with one agent. Prove the value. Add the next. The patient journey improves not because AI replaced the humans, but because AI agents augmented each specialist with faster data, deeper pattern recognition, and tireless consistency.
At Nirmitee, we build FHIR-native AI agent architectures for healthcare organizations. From single-agent pilots to hospital-wide multi-agent systems, we provide the interoperability layer, the agent framework, and the implementation expertise to move from the 61% building to the 3% in production. Talk to our engineering team about your multi-agent architecture.


