Healthcare organizations generate more data than virtually any other industry. A single mid-size hospital produces roughly 50 petabytes of data annually, spanning electronic health records, medical imaging, claims transactions, genomic sequences, and sensor data from connected medical devices.
Yet the vast majority of this data remains trapped in disconnected systems, inaccessible for the analytics and artificial intelligence applications that could transform patient outcomes.
The healthcare data lake has emerged as the foundational architecture for solving this challenge. Unlike traditional data warehouses that require rigid schemas and struggle with unstructured data, a data lake ingests everything — structured HL7 messages, semi-structured FHIR resources, unstructured clinical notes, and binary DICOM images — into a single, scalable repository that serves both operational and analytical workloads.
This guide walks through the complete architecture: why healthcare specifically needs data lakes, how to implement the medallion architecture pattern for clinical data, ingestion strategies for every major healthcare data format, terminology normalization across SNOMED CT, LOINC, ICD-10, and RxNorm, de-identification approaches for analytics and AI, platform selection, and building production ML pipelines on healthcare data.
Why Healthcare Needs Data Lakes
Traditional healthcare IT architectures were designed for transactional operations: process an order, record a diagnosis, submit a claim. They were never designed for the analytical demands of modern healthcare — population health management, value-based care analytics, clinical AI, and real-time operational intelligence.
The Data Silo Problem
A typical health system operates dozens of disconnected systems. The EHR stores clinical encounters. The revenue cycle management platform handles claims and billing. The laboratory information system manages lab orders and results.
The radiology PACS stores imaging data. The pharmacy system tracks medications. Each system has its own data model, its own identifiers, and its own access patterns.
The result is a fragmented patient record. According to a 2024 study published in the Journal of the American Medical Informatics Association, the average patient's data is spread across 16 different health IT systems. Clinicians spend an estimated 49% of their time on data entry and retrieval rather than direct patient care.
The 80% Unstructured Data Challenge
Perhaps the most critical limitation of traditional data warehouses is their inability to handle unstructured data. Research from the Healthcare Information and Management Systems Society (HIMSS) estimates that 80% of clinical data is unstructured — physician notes, discharge summaries, pathology reports, radiology narratives, and nursing assessments. This is precisely the data that contains the richest clinical insights.
A structured data warehouse cannot store or query free-text clinical notes, scanned documents, or medical images alongside structured lab results and claims data. A data lake can. It accepts data in any format, at any volume, without requiring upfront schema definition.
The Volume and Velocity Challenge
Healthcare data volumes are growing at 36% annually, significantly faster than other industries (IDC Health Insights, 2025). A single genomic sequence is 200 GB. A chest CT scan is 150-300 MB. ADT messages arrive in real-time, 24/7. Claims data arrives in massive batch files. The architecture must handle all of these patterns simultaneously.
Data lakes built on cloud object storage (S3, ADLS, GCS) scale horizontally without capacity planning, support both streaming and batch ingestion, and separate storage costs from compute costs — a critical economic advantage when storing petabytes of clinical data that may be queried infrequently.
Medallion Architecture for Healthcare Data
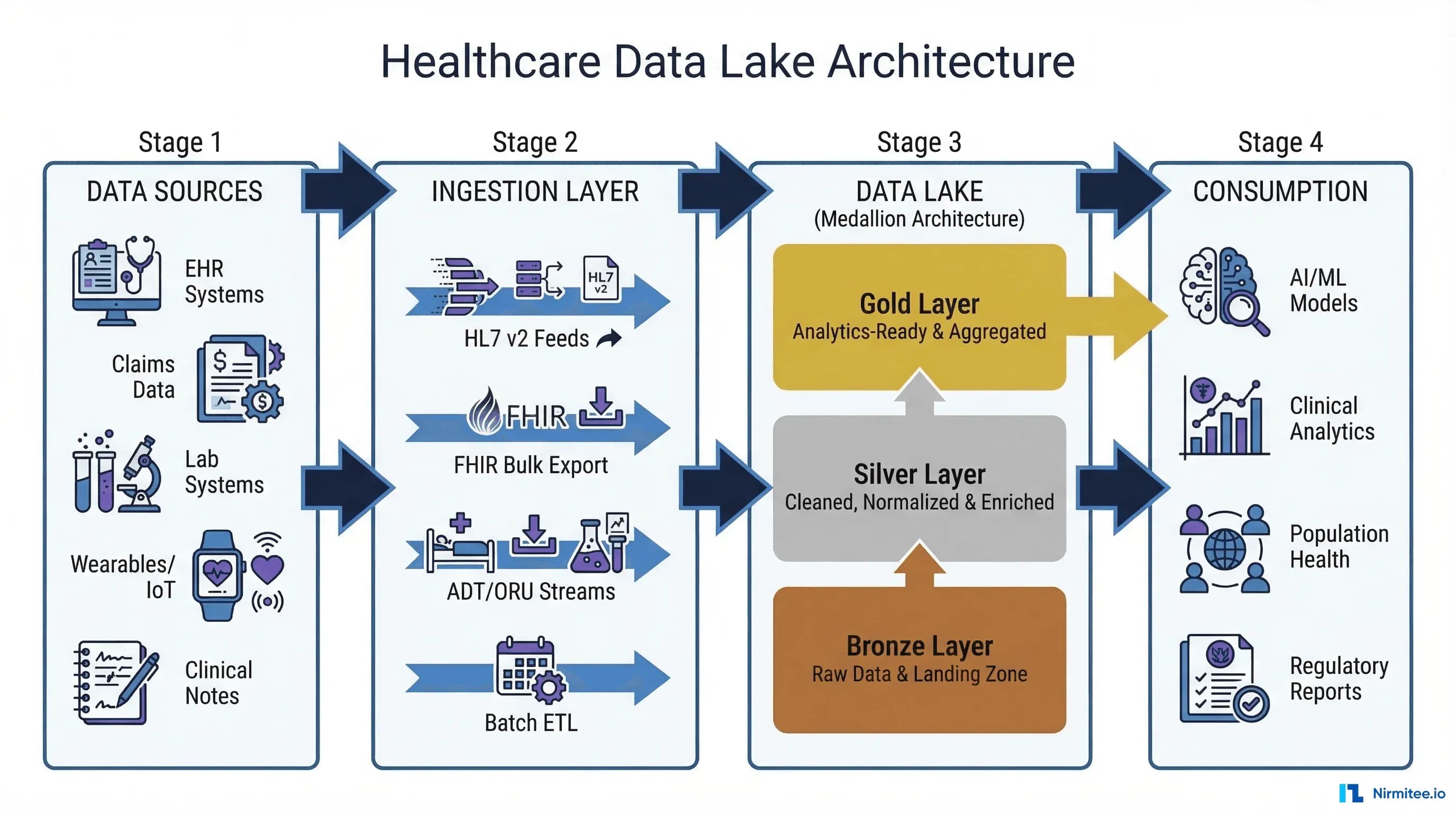
The medallion architecture (also called the multi-hop or lakehouse architecture) organizes a data lake into three distinct quality layers: Bronze, Silver, and Gold. Originally popularized by Databricks, this pattern has become the de facto standard for healthcare data lakes because it addresses the unique challenges of clinical data — messy source formats, inconsistent terminologies, and strict governance requirements.
If you have seen our case study on how medallion architecture improved AI model training for healthcare data, you already know the performance gains this approach delivers. Here, we go deeper into the implementation details.
Bronze Layer: Raw Ingestion
The bronze layer stores data exactly as it arrives from source systems. No transformations, no filtering, no deduplication. This is your system of record — the immutable, append-only truth about what every source system sent.
Healthcare-specific bronze layer patterns:
- HL7 v2 messages — Stored as raw pipe-delimited text with full headers (MSH, PID, OBR, OBX segments). Every ADT, ORU, ORM, and SIU message is preserved with an arrival timestamp.
- FHIR resources — JSON bundles stored as-is from Bulk Data Export or real-time subscriptions. Includes Bundle metadata, entry resources, and server-assigned IDs.
- Claims data — EDI 837/835 files, remittance advice, and eligibility responses stored in their original X12 format alongside any CSV/flat-file extracts.
- Clinical documents — CDA (Clinical Document Architecture) XML documents, PDF discharge summaries, scanned consent forms.
- Medical images — DICOM files with full headers, stored in their original binary format. Metadata extracted to a sidecar JSON file for queryability.
Schema design: Use a partitioning strategy based on source_system/data_type/year/month/day/ — for example, epic/adt/2026/03/19/. This enables efficient pruning when processing specific date ranges or source systems. Store metadata in a catalog (Apache Hive Metastore, AWS Glue Data Catalog, or Unity Catalog) for discoverability.
-- Bronze layer table definition (Delta Lake / Iceberg)
CREATE TABLE bronze.ehr_hl7_messages (
message_id STRING,
message_type STRING, -- ADT^A01, ORU^R01, etc.
source_system STRING, -- epic, cerner, meditech
raw_message STRING, -- Full HL7 pipe-delimited text
received_at TIMESTAMP,
ingestion_batch_id STRING,
_metadata STRUCT<file_path: STRING, file_size: BIGINT>
)
PARTITIONED BY (source_system, message_type, received_date DATE)
TBLPROPERTIES ('delta.enableChangeDataFeed' = 'true');Silver Layer: Cleaned and Normalized
The silver layer is where healthcare data becomes analytically useful. Raw messages are parsed, validated, deduplicated, and — critically — mapped to standard terminologies. This is the most complex and highest-value transformation in the healthcare data lake.
Key silver layer transformations:
- Message parsing — HL7 v2 messages decomposed into structured fields (patient demographics from PID, observations from OBX, visit details from PV1). FHIR resources extracted from bundles into individual resource tables.
- Patient identity resolution — Master Patient Index (MPI) matching using deterministic rules (SSN, MRN) and probabilistic matching (name, DOB, address similarity). This is essential for creating a unified patient record across source systems.
- Terminology standardization — Local codes mapped to standard vocabularies. This is detailed in the next section.
- Data quality validation — Null checks, range validation (is hemoglobin between 0-25 g/dL?), temporal consistency (is the discharge date after the admission date?), referential integrity (does every observation reference a valid patient?).
- Deduplication — Identical messages that arrive via multiple interfaces (e.g., both a real-time feed and a nightly batch) are identified and resolved.
-- Silver layer: parsed and normalized patient observations
CREATE TABLE silver.patient_observations (
observation_id STRING,
patient_id STRING, -- Resolved via MPI
encounter_id STRING,
observation_code STRING, -- LOINC code
observation_display STRING, -- Human-readable name
value_quantity DECIMAL(18,4),
value_unit STRING, -- UCUM unit
value_text STRING, -- For non-numeric observations
effective_datetime TIMESTAMP,
status STRING, -- final, preliminary, amended
source_system STRING,
source_message_id STRING, -- Links back to bronze
_quality_score FLOAT, -- Data quality confidence
_loaded_at TIMESTAMP
)
PARTITIONED BY (observation_date DATE);Gold Layer: Analytics-Ready
The gold layer contains business-level aggregates, KPIs, and ML-ready feature sets. This is what dashboards query, what reports pull from, and what machine learning models train on.
Healthcare gold layer examples:
- Patient 360 profiles — Comprehensive longitudinal record per patient: demographics, active diagnoses, current medications, recent labs, risk scores, care gaps, social determinants of health.
- Quality measures — Pre-computed HEDIS, CMS Stars, and MIPS measures at patient, provider, and facility levels. Ready for regulatory submission and pay-for-performance tracking.
- ML feature store — Pre-engineered features for common healthcare ML tasks: rolling 90-day lab averages, medication adherence scores, comorbidity indices (Charlson, Elixhauser), encounter frequency metrics.
- Financial analytics — Cost-per-episode, DRG-level profitability, denial rates by payer, revenue cycle KPIs aggregated at daily/weekly/monthly grain.
- Population health cohorts — Pre-defined patient segments for care management: rising risk, high utilizers, chronic disease registries, post-discharge follow-up candidates.
Data Ingestion Patterns for Healthcare
Healthcare data arrives through a bewildering variety of interfaces and formats. A production data lake must handle all of them, often simultaneously.
HL7 v2 Message Feeds
Despite being a standard from the 1990s, HL7 v2 remains the dominant real-time messaging format in healthcare. Over 95% of US hospitals use HL7 v2 for system-to-system communication (HL7 International). The most common message types for data lake ingestion are:
- ADT (Admit/Discharge/Transfer) — A01 (admit), A02 (transfer), A03 (discharge), A08 (update). These provide the backbone of encounter tracking.
- ORU (Observation Result) — Lab results, vital signs, radiology reports. R01 is the workhorse — every lab result generates one.
- ORM/OML (Order Messages) — Lab orders, medication orders, imaging orders. Critical for tracking the order-to-result lifecycle.
- SIU (Scheduling) — Appointment booking, cancellation, and rescheduling events.
- MDM (Medical Document) — Clinical document notifications, typically with a pointer to the full document in the document management system.
Ingestion architecture: Deploy an integration engine (Mirth Connect, Rhapsody, or a cloud-native HL7 receiver) that accepts TCP/IP MLLP connections from source systems, acknowledges each message (ACK/NAK), and writes raw messages to the bronze layer via a message queue (Kafka, Amazon MSK, or Azure Event Hubs). This decouples the real-time interface from the batch processing pipeline.
For a deeper dive into real-time data synchronization patterns, see our guide on Change Data Capture (CDC) for healthcare data warehouse and EHR sync.
FHIR Bulk Data Export
The FHIR Bulk Data Access specification (HL7 FHIR IG: Bulk Data, STU2) is the modern standard for extracting large datasets from FHIR-compliant systems. Mandated by the ONC's 21st Century Cures Act, every certified EHR must now support Bulk Data Export.
How it works:
- Client initiates an async export request:
GET [fhir-base]/$exportwith parameters for resource types, date range, and output format. - Server processes the export asynchronously and returns a polling URL.
- When complete, the server provides URLs to download NDJSON (Newline Delimited JSON) files — one file per resource type.
- Client downloads the NDJSON files and loads them into the bronze layer.
# Initiate FHIR Bulk Data Export
curl -X GET "https://ehr.example.com/fhir/\$export" \
-H "Accept: application/fhir+json" \
-H "Prefer: respond-async" \
-H "Authorization: Bearer $ACCESS_TOKEN" \
-H "Content-Type: application/fhir+json" \
-d '{"_type": "Patient,Condition,Observation,MedicationRequest",
"_since": "2026-03-01T00:00:00Z",
"_outputFormat": "application/ndjson"}'
# Poll for completion (returns 202 while processing, 200 when done)
curl -X GET "https://ehr.example.com/fhir/bulkstatus/export-123" \
-H "Authorization: Bearer $ACCESS_TOKEN"
# Download output files (NDJSON format)
curl -o patients.ndjson "https://ehr.example.com/fhir/download/patients-001.ndjson"
curl -o conditions.ndjson "https://ehr.example.com/fhir/download/conditions-001.ndjson"Key consideration: Bulk Data Export uses NDJSON — one JSON resource per line. This is ideal for data lake ingestion because each line can be parsed independently, enabling parallel processing. Schedule nightly exports for full refreshes and use the _since parameter for incremental loads.
Claims and Financial Data
Claims data typically arrives via SFTP as flat files — either EDI X12 837 (professional/institutional claims), 835 (remittance advice), or CSV extracts from clearinghouses and payer portals. Load schedules vary: daily for claims submissions, weekly for remittance, and monthly for membership and eligibility rosters.
The key challenge with claims data is latency: a claim may be submitted, denied, resubmitted, partially paid, and adjusted over a 90-180 day lifecycle. The bronze layer stores every version; the silver layer resolves the current state of each claim through a slowly changing dimension (SCD Type 2) pattern.
Real-time ADT/ORU Streams
For use cases requiring sub-minute latency — sepsis early warning, ED census boards, real-time bed management — a streaming architecture is essential. The pattern combines:
- Stream ingestion — Apache Kafka or cloud-native equivalents (Amazon MSK, Azure Event Hubs, Confluent Cloud) receive HL7 v2 or FHIR messages in real-time.
- Stream processing — Apache Flink, Spark Structured Streaming, or cloud-native tools (AWS Kinesis Analytics, Azure Stream Analytics) apply real-time transformations, alerting rules, and routing logic.
- Dual write — Messages are written simultaneously to the bronze layer (for historical analysis) and to a hot-path store (Redis, DynamoDB) for real-time dashboards.
Data Quality and Terminology Normalization
The silver layer transformation that delivers the most value — and causes the most headaches — is terminology mapping. Healthcare uses multiple overlapping coding systems, and source systems often use proprietary local codes that must be mapped to standards.
The Four Pillars of Healthcare Terminology
| Standard | Purpose | Size | Example |
|---|---|---|---|
| SNOMED CT | Clinical findings, procedures, body structures | 350,000+ concepts | 73211009 = Diabetes mellitus |
| LOINC | Laboratory observations, clinical measurements | 98,000+ codes | 2160-0 = Creatinine [Mass/volume] in Serum or Plasma |
| ICD-10-CM/PCS | Diagnosis classification, procedure classification | 72,000+ codes (CM), 78,000+ (PCS) | E11.9 = Type 2 diabetes without complications |
| RxNorm | Medications (ingredients, brands, doses) | 115,000+ concepts | 311671 = Metformin 500 MG Oral Tablet |
Mapping strategy: Maintain a mapping table in the silver layer that translates source system codes to standard terminologies. For common codes, build deterministic mappings. For ambiguous cases, use the UMLS Metathesaurus API or NLM's RxNorm API for automated lookup. For unmappable codes, flag them for manual review in a data steward queue.
-- Terminology mapping table
CREATE TABLE silver.terminology_map (
source_system STRING,
source_code STRING,
source_display STRING,
target_system STRING, -- 'SNOMED', 'LOINC', 'ICD10', 'RXNORM'
target_code STRING,
target_display STRING,
mapping_confidence FLOAT, -- 1.0 = exact, 0.8 = probable, 0.5 = needs review
mapped_by STRING, -- 'automated', 'manual', 'nlm_api'
reviewed_at TIMESTAMP,
is_active BOOLEAN
);
-- Example mappings
INSERT INTO silver.terminology_map VALUES
('epic', 'GLU', 'Glucose', 'LOINC', '2345-7', 'Glucose [Mass/volume] in Serum or Plasma', 1.0, 'automated', NULL, TRUE),
('cerner', 'HGB', 'Hemoglobin', 'LOINC', '718-7', 'Hemoglobin [Mass/volume] in Blood', 1.0, 'automated', NULL, TRUE),
('lab_local', 'TROP_I', 'Troponin I', 'LOINC', '10839-9', 'Troponin I.cardiac [Mass/volume] in Serum or Plasma', 0.9, 'nlm_api', NULL, TRUE);Data Quality Dimensions
Healthcare data quality is measured across six dimensions, aligned with the AHIMA Data Quality Management Model:
- Completeness — Are all required fields populated? (Patient without DOB, observation without value)
- Accuracy — Do values reflect clinical reality? (Hemoglobin of 500 g/dL is clearly an error)
- Consistency — Do related records agree? (Diagnosis of pregnancy in a male patient)
- Timeliness — Is data available within an acceptable latency? (Lab result from 3 hours ago not yet in the lake)
- Validity — Do values conform to expected formats and ranges? (ICD-10 code format: [A-Z][0-9][0-9].[0-9]+)
- Uniqueness — Is the same data record stored only once? (Duplicate patient records from multiple feeds)
Implement automated data quality checks at the bronze-to-silver boundary. Use frameworks like Great Expectations, Soda, or dbt tests to define and enforce quality rules. Publish data quality scores as metadata alongside every silver table so downstream consumers know the reliability of what they are querying.
De-identification for Analytics and AI
Any healthcare data used for analytics, research, or AI model training must be de-identified under HIPAA's Privacy Rule (45 CFR 164.514). There are exactly two legally recognized methods.
Safe Harbor Method
The Safe Harbor method requires removal of 18 specific identifier categories: names, geographic data below state level, all dates (except year) related to an individual, phone numbers, fax numbers, email addresses, Social Security numbers, medical record numbers, health plan beneficiary numbers, account numbers, certificate/license numbers, vehicle identifiers, device identifiers and serial numbers, web URLs, IP addresses, biometric identifiers, full-face photographs, and any other unique identifying number or code.
Advantages: Deterministic, easy to implement and audit, no expert required.
Disadvantages: Removes a lot of analytically useful data. Date shifting (required for all dates except year) breaks temporal analyses. Geographic removal below the state level limits spatial analytics.
Expert Determination Method
Under Expert Determination, a qualified statistical expert applies methods to demonstrate that the risk of re-identification is "very small" — generally interpreted as a threshold of k < 0.04 (less than 4% probability that any individual could be re-identified). The expert must document the methods, data, and results.
Advantages: Preserves far more data utility. Dates can be retained with appropriate perturbation. Geographic data can be retained at ZIP+3 or even ZIP+5 level in urban areas. Clinical narrative can be retained with entity replacement rather than wholesale removal.
Disadvantages: Requires a qualified expert, must be re-evaluated when data changes, higher upfront cost.
Implementation in the Data Lake
De-identification is implemented as a transformation between the silver and gold layers. The silver layer retains identified data (with strict access controls); the gold layer contains only de-identified data accessible to analysts and data scientists.
Tools:
- AWS Comprehend Medical — NLP-based PHI detection in clinical text. Identifies names, dates, addresses, and medical identifiers with high accuracy.
- Google Cloud Healthcare API DLP — Built-in de-identification service that supports both Safe Harbor and configurable de-id profiles.
- Microsoft Presidio — Open-source PII/PHI detection and anonymization framework. Highly customizable, supports healthcare-specific recognizers.
- ARX Data Anonymization Tool — Open-source tool specializing in k-anonymity, l-diversity, and t-closeness for structured datasets.
Healthcare Data Platform Comparison
Choosing the right platform for your healthcare data lake is a decision with multi-year consequences. Here is an honest comparison of the leading options as of 2026.
Databricks Lakehouse for Healthcare
Databricks pioneered the lakehouse architecture and remains the strongest platform for organizations that prioritize ML/AI workloads and real-time streaming. The Lakehouse for Healthcare solution accelerator provides pre-built notebooks for FHIR ingestion, clinical NLP, and patient cohort building.
Strengths: Best-in-class ML infrastructure (MLflow, Feature Store, Model Serving), Unity Catalog for fine-grained governance, Delta Lake for ACID transactions, excellent real-time streaming via Structured Streaming. Native support for Python, R, SQL, and Scala — critical for data science teams.
Weaknesses: No native FHIR server — you must build or buy the FHIR layer. Compute-based pricing can be expensive for large-scale batch workloads. Steeper learning curve for traditional BI teams.
Snowflake Health Data Cloud
Snowflake's differentiation is data sharing and collaboration. The Health Data Cloud provides curated healthcare datasets (claims, prescriptions, and lab data) from partners like Datavant, Komodo Health, and IQVIA directly in Snowflake's marketplace. For organizations that need to combine internal clinical data with external benchmarking data, Snowflake is compelling.
Strengths: Unmatched data marketplace ecosystem, easy SQL-based analytics, strong governance (Dynamic Data Masking, row-level security), multi-cloud deployment. Snowpark enables Python/Java/Scala UDFs for more complex transformations.
Weaknesses: Limited real-time streaming capabilities (Snowpipe has minutes of latency). ML/AI capabilities are improving, but still behind Databricks. Credit-based pricing can be unpredictable.
AWS HealthLake
AWS HealthLake is the only major platform with a native FHIR R4 data store — it ingests, stores, and serves FHIR resources natively with sub-millisecond latency. The zero-ETL intelligence feature automatically transforms FHIR data into Apache Iceberg tables for analytics without building data pipelines.
Strengths: Native FHIR, built-in NLP (Amazon Comprehend Medical), automatic Iceberg table creation, deep integration with the AWS ecosystem (SageMaker, Athena, QuickSight, Bedrock). HIPAA-eligible out of the box.
Weaknesses: AWS lock-in. Limited to FHIR data — non-FHIR sources (HL7 v2, claims flat files) require separate ingestion pipelines. Per-resource pricing can be expensive at scale.
Google Cloud Healthcare API
Google's Healthcare API provides managed FHIR, HL7 v2, and DICOM stores with native BigQuery integration — FHIR resources are automatically streamed to BigQuery for SQL analytics. The built-in de-identification service is the most mature among cloud providers.
Strengths: Native FHIR + HL7 v2 + DICOM in one service, automatic BigQuery streaming, best-in-class de-identification, integration with Vertex AI for ML. Strong genomics capabilities via Variant Transforms.
Weaknesses: Smaller healthcare partner ecosystem compared to AWS. BigQuery's slot-based pricing requires careful management. Fewer healthcare-specific solution accelerators.
Azure Health Data Services
Microsoft's offering combines a managed FHIR server (evolved from the open-source FHIR Server for Azure) with DICOM and MedTech (IoT) services. The strategic advantage is integration with the Microsoft ecosystem — Power BI, Azure Synapse, Microsoft Fabric, and the recently launched healthcare AI models in Azure AI.
Strengths: Deep integration with Microsoft 365 and Power BI (already in most health systems), managed FHIR + DICOM + IoT, Azure Synapse for unified analytics, strong enterprise security (Azure AD, RBAC). Microsoft Fabric is emerging as a compelling lakehouse alternative.
Weaknesses: FHIR server performance lags behind AWS HealthLake for high-throughput workloads. MedTech/IoT service is less mature. Fabric's healthcare capabilities are still evolving.
Decision Framework
| If your priority is... | Choose | Why |
|---|---|---|
| ML/AI and data science | Databricks | Best ML toolchain, notebook-first workflow, real-time capable |
| Data sharing and marketplace | Snowflake | Unmatched healthcare data marketplace, easy SQL analytics |
| Native FHIR with zero-ETL | AWS HealthLake | Only native FHIR R4 store with automatic Iceberg analytics |
| Multi-format (FHIR+HL7+DICOM) | Google Cloud | Unified API for all three healthcare data standards |
| Microsoft ecosystem integration | Azure | Seamless Power BI, Fabric, Teams, Azure AD integration |
Real-time vs. Batch Processing
Healthcare data lakes must support both processing paradigms. The choice depends on the use case, not a blanket architectural decision.
When Batch Processing Is Sufficient
- Quality measures and regulatory reporting — HEDIS, Stars, MIPS calculations run monthly or quarterly. Batch processing overnight is more than adequate.
- Claims analytics — Claims have inherent latency (30-180 day cycles). Daily or weekly batch loads match the data's natural cadence.
- ML model training — Training on historical data is inherently a batch operation. Even "real-time" ML models are trained on batch data and deployed for real-time inference.
- Population health cohort building — Patient risk stratification refreshed daily is sufficient for care management outreach.
When Real-time Processing Is Essential
- Sepsis early warning — Every hour of delay in sepsis treatment increases mortality by 4-8% (CMS SEP-1 measure). Real-time vital sign and lab monitoring is literally life-saving.
- ED census and bed management — ADT messages must flow to dashboards within seconds for operational efficiency.
- Clinical decision support — Drug interaction alerts, allergy notifications, and order set recommendations must trigger in real-time within the clinical workflow.
- Surveillance and outbreak detection — Public health surveillance (syndromic surveillance, antimicrobial resistance tracking) requires near-real-time data aggregation.
The Lambda and Kappa Architectures
The Lambda architecture runs parallel batch and streaming pipelines, merging results at query time. This provides both real-time responsiveness and batch accuracy but doubles operational complexity.
The Kappa architecture uses a single streaming pipeline for everything — real-time messages are processed as they arrive, and historical reprocessing is handled by replaying the stream from a durable log (Kafka). This is simpler to operate but requires careful design to handle the full range of healthcare workloads.
In practice, most healthcare data lakes adopt a pragmatic hybrid: streaming for high-priority real-time use cases (ADT, critical lab results, sepsis alerts) and batch for everything else (claims, quality measures, ML training). The medallion architecture accommodates both — streaming writes to bronze and silver layers in micro-batches (every 1-5 minutes), while gold layer aggregates refresh on batch schedules.
Building AI/ML Pipelines on Healthcare Data
The ultimate value proposition of a healthcare data lake is enabling AI and machine learning at scale. The gold layer of the medallion architecture — combined with a feature store — provides the foundation for production ML systems.
Common Healthcare ML Use Cases
| Use Case | Model Type | Key Features | Impact |
|---|---|---|---|
| Readmission prediction | Gradient boosting (XGBoost) | Prior admissions, comorbidities, medications, social factors | 15-25% reduction in 30-day readmissions |
| Sepsis early detection | LSTM / Transformer | Vital sign time series, lab trends, medication timing | 18-30% reduction in sepsis mortality |
| Clinical NLP | Fine-tuned LLM (ClinicalBERT, Med-PaLM) | Discharge notes, radiology reports, pathology text | 80%+ reduction in manual chart abstraction |
| Cost prediction | Regression ensemble | Diagnosis mix, procedure codes, LOS, payer type | 10-15% improvement in financial forecasting |
| Population risk stratification | Survival analysis + ML | Demographics, chronic conditions, utilization patterns, SDOH | Targeted interventions for top 5% risk patients |
Feature Engineering for Healthcare
Healthcare feature engineering requires domain expertise. Generic statistical features are insufficient — you need clinically meaningful transformations:
- Temporal features — Days since last admission, trend in hemoglobin over 90 days, medication adherence ratio (PDC — Proportion of Days Covered).
- Comorbidity indices — Charlson Comorbidity Index, Elixhauser Score, HCC (Hierarchical Condition Category) risk adjustment factor.
- Utilization features — ED visits in the past 12 months, inpatient days, specialist referrals, and imaging frequency.
- Medication features — Polypharmacy count, high-risk medication flags (anticoagulants, opioids), drug-drug interaction potential.
- Social determinants — ADI (Area Deprivation Index) from census tract, food desert flag, transportation access score, and insurance coverage stability.
Model Validation and Bias Detection
Healthcare ML models face uniquely high stakes. A biased model can systematically disadvantage specific patient populations. The 2019 Obermeyer study in Science famously demonstrated that a widely-used healthcare algorithm exhibited significant racial bias because it used healthcare spending as a proxy for health needs — Black patients had lower spending at equal levels of illness due to systemic access disparities.
Required validation practices:
- Subgroup analysis — Evaluate model performance across race, ethnicity, age, sex, insurance type, and geography. Performance should be equitable across all subgroups.
- Explainability — Use SHAP (Shapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) to understand which features drive individual predictions. Clinicians will not trust a black-box model.
- Clinical validation — Before deployment, validate against clinical expert review. A model that is statistically accurate but clinically nonsensical will be rejected by care teams.
- Drift monitoring — Healthcare data distributions shift constantly (new CPT codes, coding practice changes, pandemic effects). Monitor input distribution and output distribution drift continuously.
For more on how AI solutions integrate into healthcare workflows, see our healthcare AI solutions page.
Governance, Compliance, and Access Controls
A healthcare data lake without robust governance is a liability, not an asset. HIPAA, state privacy laws, and organizational policies impose strict requirements on how data is stored, accessed, and retained.
HIPAA Technical Safeguards
- Encryption — Data must be encrypted at rest (AES-256) and in transit (TLS 1.2+). All major cloud platforms provide this by default, but verify that encryption extends to temporary storage, caches, and Spark shuffle files.
- Access controls — Implement role-based access control (RBAC) with the principle of least privilege. Column-level and row-level security ensure that analysts see only the data elements they need. A financial analyst does not need access to clinical notes; a researcher does not need patient names.
- Audit logging — Every data access must be logged with who, what, when, and why. Cloud-native audit services (AWS CloudTrail, Azure Activity Log, GCP Audit Logs) combined with lakehouse audit logs (Unity Catalog audit, Snowflake Access History) provide comprehensive coverage.
- Break-glass procedures — Emergency access protocols for when normal access controls are insufficient (e.g., a care team needs broader data access during a patient emergency). These must be logged and reviewed after the fact.
Data Retention and Lifecycle Management
Healthcare data retention requirements vary by data type and jurisdiction:
| Data Type | Federal Minimum | Common State Requirement | Recommended Practice |
|---|---|---|---|
| Adult medical records | 6 years (HIPAA) | 7-10 years (varies by state) | 10 years + litigation hold |
| Pediatric records | 6 years | Until age 21-28 | Until age 28 + 3 years |
| Billing records | 6 years | 7-10 years | 10 years |
| Research data | Varies by protocol | IRB-specified | Protocol period + 7 years |
Implement automated lifecycle policies in the data lake: hot storage for recent data (0-2 years), warm storage for intermediate data (2-7 years), cold/archive storage for long-term retention (7+ years). Cloud object storage tiers (S3 Glacier, Azure Cool/Archive, GCS Nearline/Coldline) reduce storage costs by 60-80% for archived data.
Data Catalog and Lineage
A data catalog is not optional for a healthcare data lake — it is essential for both governance and usability. Every table, column, and pipeline must be documented with:
- Business metadata — What does this data represent? Who is the data owner? What is the refresh frequency?
- Technical metadata — Schema, partitioning, data types, row counts, freshness timestamps.
- Data lineage — Where did this data come from (bronze source), how was it transformed (silver logic), and what consumes it (gold tables, dashboards, ML models)?
- Sensitivity classification — PHI, PII, de-identified, aggregated. This drives access control policies automatically.
Tools like Unity Catalog (Databricks), Purview (Azure), DataZone (AWS), and Dataplex (Google Cloud) provide integrated cataloging with automatic lineage tracking.
Getting Started: A Practical Roadmap
Building a healthcare data lake is a multi-quarter initiative. Here is a phased approach that delivers incremental value:
Phase 1 (Months 1-3): Foundation
- Select a cloud platform and a data lake engine
- Set up a bronze layer with 2-3 high-value data sources (EHR ADT feed, lab results, claims)
- Implement basic encryption, RBAC, and audit logging
- Establish a data catalog with initial documentation
Phase 2 (Months 4-6): Silver Layer
- Build HL7 v2 parser and FHIR resource extractor for the silver layer
- Implement MPI for patient identity resolution
- Begin terminology mapping (start with the top 100 lab codes and diagnosis codes)
- Deploy data quality monitoring
Phase 3 (Months 7-9): Gold Layer and Analytics
- Build a Patient 360 view and initial quality measures
- Implement the de-identification pipeline for analyst access
- Connect BI tools (Power BI, Tableau, Looker) to the gold layer
- Deliver first operational dashboards
Phase 4 (Months 10-12): AI/ML and Scale
- Deploy feature store with clinically engineered features
- Build and validate the first ML model (readmission prediction is the common starting point)
- Add remaining data sources (pharmacy, imaging metadata, SDOH)
- Implement real-time streaming for critical use cases
From architecture to production, our Healthcare Software Product Development team builds healthcare platforms that perform at scale. We also offer specialized Healthcare AI Solutions services. Talk to our team to get started.